↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Federated learning (FL) faces challenges with non-identical and independently distributed (non-IID) data across clients, hindering effective model training. Existing methods struggle to balance global model performance with personalized client-specific accuracy. This often leads to slower convergence and suboptimal results.
This work proposes FLOCO, which uses a solution simplex representing a linearly connected low-loss region in parameter space. Clients are assigned subregions based on gradient signals, allowing for model personalization within these subregions while training a shared global model. Experiments demonstrate FLOCO’s improved speed and accuracy compared to state-of-the-art methods in cross-silo settings, with minimal computational overhead.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the critical challenges of statistical heterogeneity in federated learning. By introducing FLOCO, it offers a novel approach to improve both global and local model accuracy. This is especially relevant given the increasing focus on personalized FL and the need for efficient and robust algorithms in various applications. Further research could explore FLOCO’s scalability and applicability to different data distributions and model architectures.
Visual Insights#
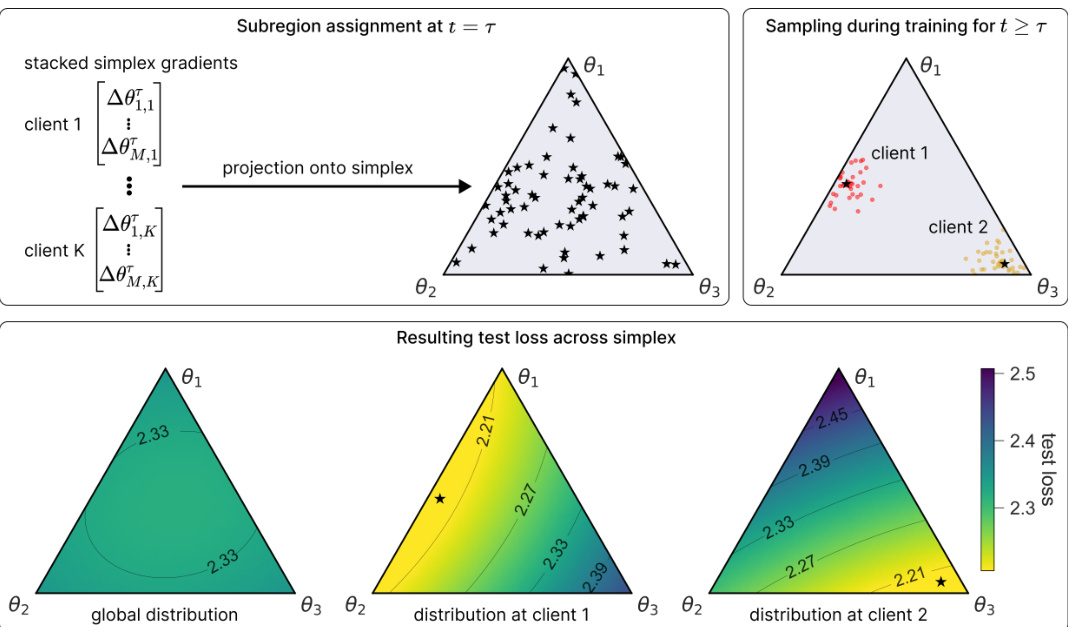
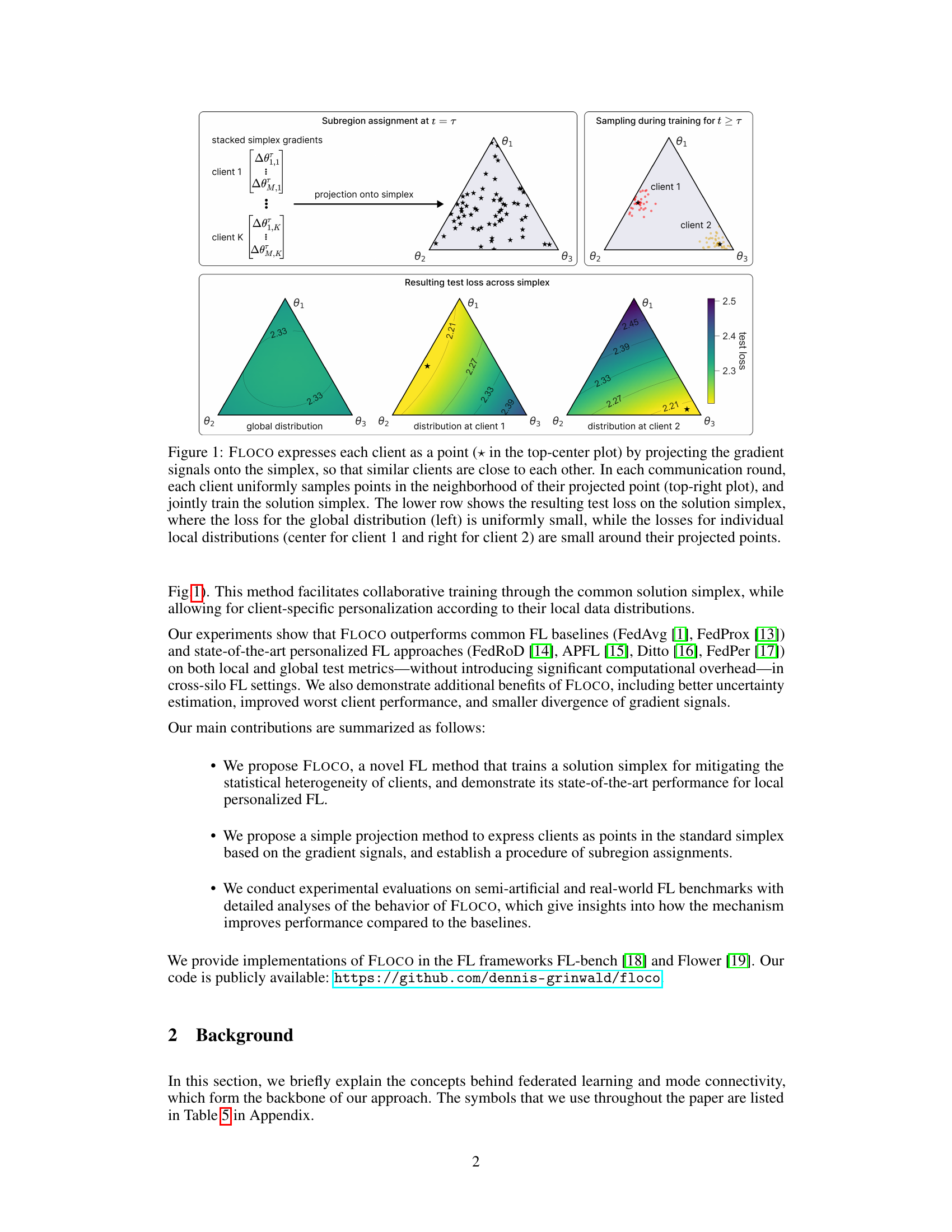
This figure illustrates the core concept of Federated Learning over Connected Modes (FLOCO). It shows how client gradient signals are projected onto a simplex, grouping similar clients together. Each client then samples models from its assigned subregion of the simplex and collaboratively trains the global simplex. The resulting test loss shows good performance for both the global distribution and individual clients’ local distributions.
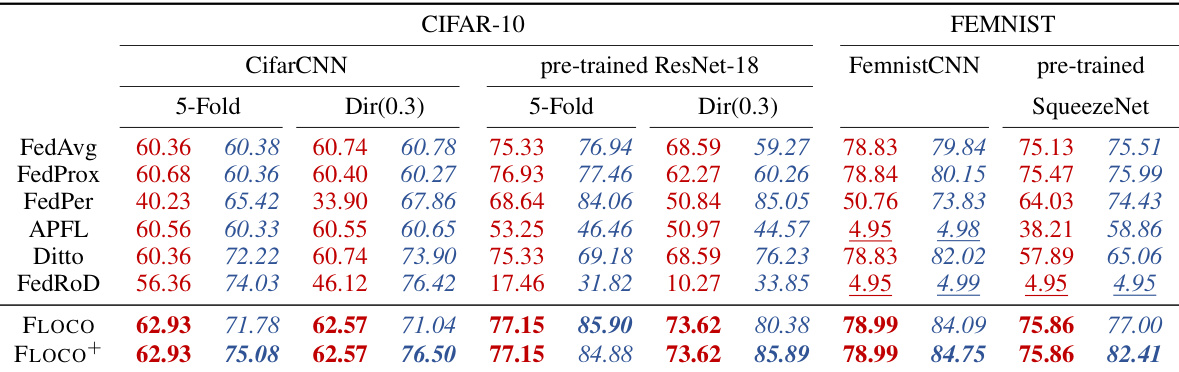
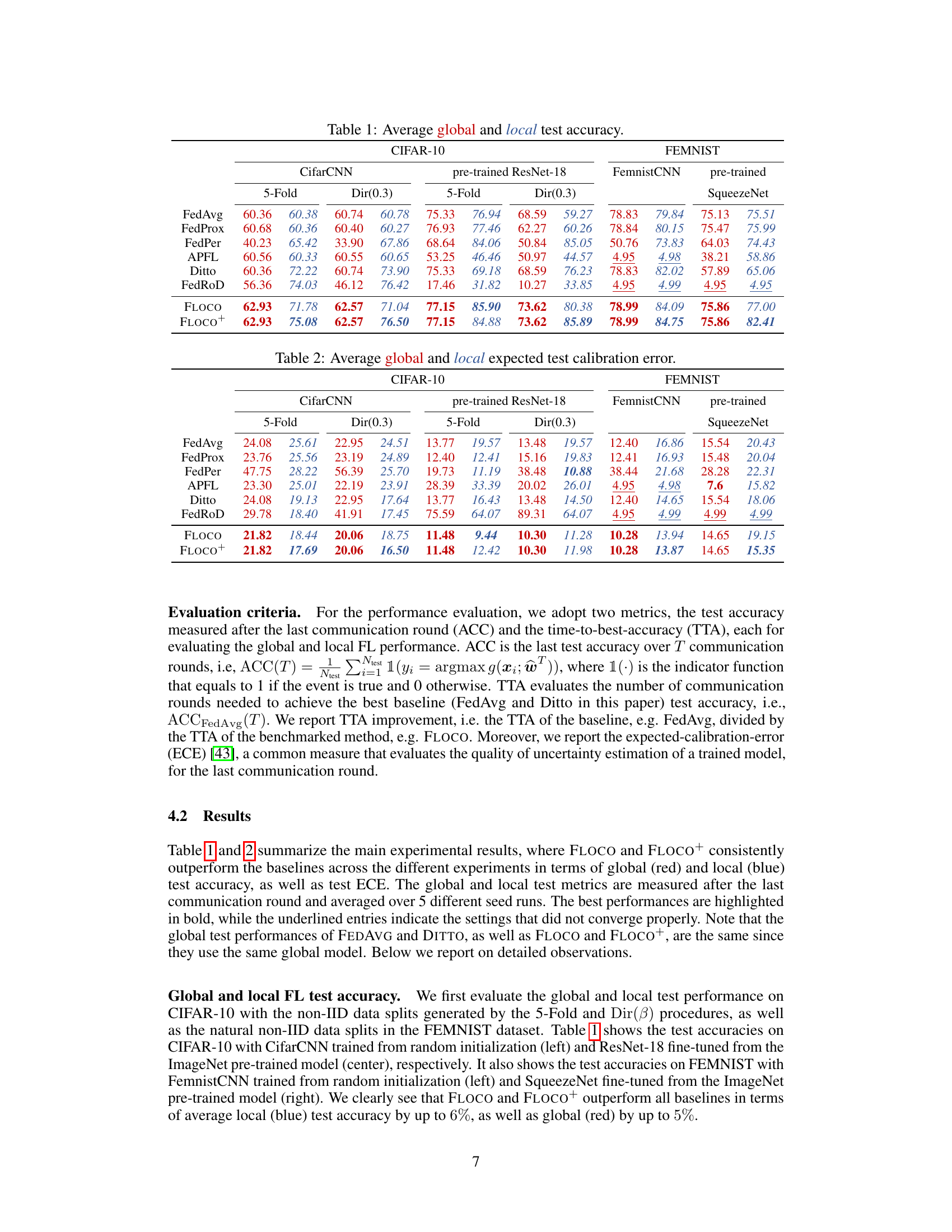
This table presents the average global and local test accuracy for different federated learning methods across various datasets and model configurations. The datasets include CIFAR-10 with two types of non-IID data splits (5-Fold and Dir(0.3)) and FEMNIST. Models used are CifarCNN, pre-trained ResNet-18, FemnistCNN, and pre-trained SqueezeNet. The table compares the performance of FLOCO and FLOCO+ against several baselines such as FedAvg, FedProx, FedPer, APFL, Ditto, and FedRod. Higher accuracy values indicate better performance.
In-depth insights#
Connected Modes FL#
Federated learning (FL) faces challenges with non-IID data, hindering efficient global model training. Connected Modes FL addresses this by leveraging the concept of mode connectivity, identifying low-loss regions (solution simplex) within the model’s parameter space. Clients are assigned subregions of this simplex based on their gradient signals, enabling personalized model updates while maintaining global convergence. This approach allows for personalization adapted to local data distributions, and by creating a shared solution simplex, it homogenizes update signals, accelerating the training and improving overall accuracy. Unlike traditional methods, which focus on either global or personalized models, Connected Modes FL aims to find a balance, achieving improved local accuracy without sacrificing global performance. The technique uses a novel projection method to map clients to the simplex, and carefully manages subregion assignment for effective collaboration. This method promises to improve the efficiency and effectiveness of federated learning, particularly in situations with significant statistical heterogeneity.
Simplex Training#
Simplex training, in the context of federated learning, presents a novel approach to address the challenges of statistical heterogeneity across distributed clients. Instead of directly optimizing individual client models, it focuses on collaboratively training a low-loss region in the model’s parameter space, the solution simplex. This simplex is defined by its vertices, which are collaboratively updated by the clients. Clients are assigned subregions within this simplex based on their gradient signals, allowing for personalization while maintaining a shared global solution. The simplex structure promotes mode connectivity, ensuring that client models remain connected via low-loss paths, thus facilitating efficient collaboration and preventing the conflicting gradient issues common in traditional federated learning. The method offers a balance between global model performance and client-specific personalization. However, further investigation is needed to fully understand its scalability and applicability across diverse datasets and client distributions.
FLOCO Algorithm#
The FLOCO algorithm, proposed for federated learning, tackles the challenges of statistical heterogeneity by leveraging mode connectivity. It identifies a linearly connected low-loss region (solution simplex) in the parameter space of neural networks. Clients are assigned subregions within this simplex based on their gradient signals, enabling personalized model training while maintaining a shared global solution. This approach achieves personalization by allowing clients to adapt within their subregions, and simultaneously promotes global convergence by homogenizing update signals. FLOCO’s key innovation lies in its strategic subregion assignment and collaborative training mechanism across connected modes, leading to accelerated global training and improved local accuracy. The method’s effectiveness stems from its ability to balance personalization and global model convergence, ultimately outperforming existing state-of-the-art techniques. Further research could explore the algorithm’s scalability and robustness in diverse settings and investigate its potential limitations.
Non-IID Data#
In federated learning, Non-IID (non-identically and independently distributed) data poses a significant challenge because client datasets exhibit varying distributions. This heterogeneity hinders the training of effective global models, as conflicting gradient signals from clients with differing data characteristics can slow down convergence or lead to suboptimal solutions. Personalized FL methods attempt to address this by training individual models for each client, but this can sacrifice global performance and increase communication overhead. Clustering techniques group clients with similar data distributions to mitigate some of the issues, but finding effective clusters can be complex. Robust aggregation aims to minimize the impact of outliers or conflicting updates. Advanced techniques leverage concepts like mode connectivity to find low-loss paths in parameter space, allowing for better collaboration across clients with diverse data. These methods try to improve both the global and local accuracy of the models trained, while managing the complexities brought on by Non-IID data.
Future of FLOCO#
The future of FLOCO (Federated Learning Over Connected Modes) appears bright, given its strong performance in addressing the challenges of statistical heterogeneity in federated learning. Future research could focus on enhancing FLOCO’s scalability to handle a significantly larger number of clients and datasets, a critical factor for real-world applications. Investigating the impact of different simplex structures and projection methods would improve the algorithm’s robustness and adaptability to various data distributions. Theoretical analysis to provide stronger convergence guarantees would enhance the algorithm’s reliability. Furthermore, exploring FLOCO’s applicability in diverse applications beyond image classification, such as natural language processing and time-series analysis, would broaden its impact. Incorporating advanced techniques like differential privacy would ensure compliance with data protection regulations, improving trustworthiness and expanding potential use cases. Finally, developing user-friendly implementations and tools to facilitate wider adoption among researchers and practitioners would further solidify FLOCO’s place in the federated learning landscape.
More visual insights#
More on figures

This figure displays the global and average local test accuracy for the CifarCNN model trained on the CIFAR-10 dataset with a 5-fold split. The left panel shows the global test accuracy, the middle panel shows the average local test accuracy across all clients, and the right panel shows the total variance of the gradients (a measure of how consistent the gradient updates are across clients). A key observation is the noticeable jump in average local test accuracy for the FLOCO method around communication round 250, attributed to the subregion assignment. The plot also highlights that FLOCO leads to lower variance in gradients compared to other methods.
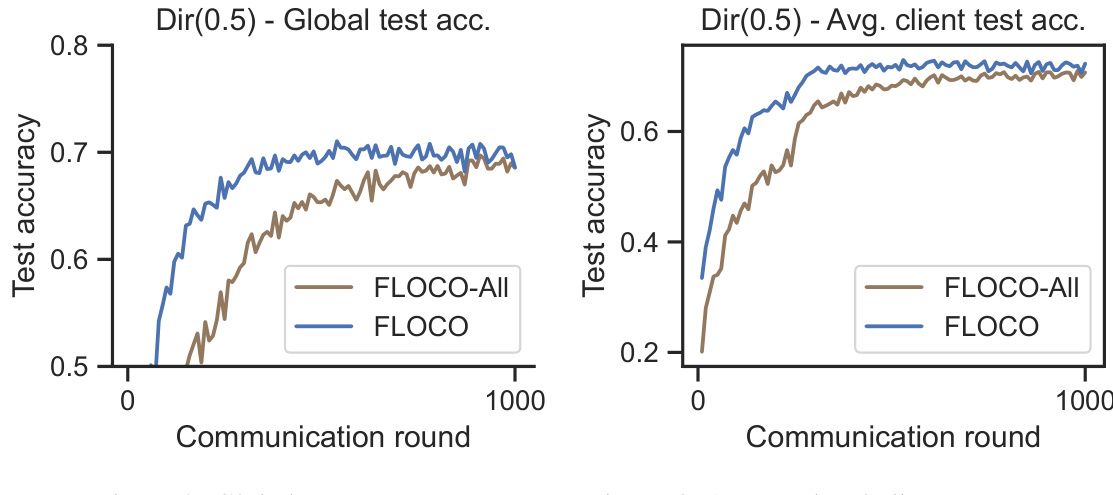
This figure compares the performance of FLOCO and other federated learning methods on CIFAR-10 dataset using a 5-fold split. The left panel displays the global test accuracy, showing that FLOCO converges faster than others, while the middle panel presents the average local test accuracy, illustrating a significant improvement in FLOCO after subregion assignment at T=250. The right panel depicts the total variance of the gradients, indicating that FLOCO effectively reduces gradient variance, leading to more stable training.
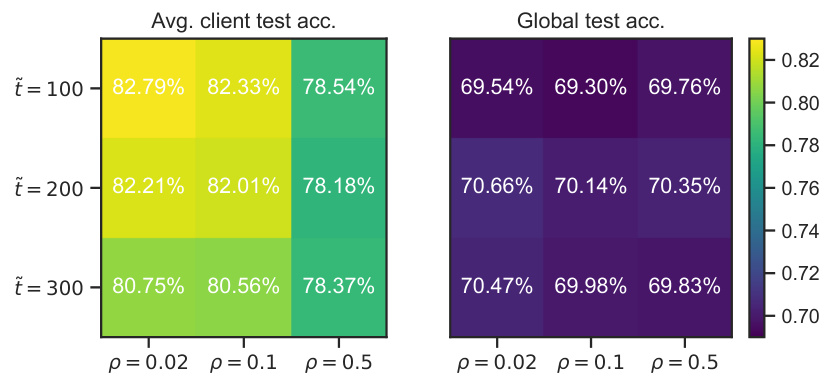
This figure shows the impact of two hyperparameters, τ (subregion assignment round) and ρ (subregion radius), on the performance of FLOCO. The left heatmap displays the average local client test accuracy, while the right heatmap shows the global test accuracy. Different colors represent different accuracy levels, with warmer colors indicating higher accuracy. The results indicate that earlier subregion assignments (smaller τ) and smaller subregion radiuses (smaller ρ) generally lead to better local accuracy, but the impact on global accuracy is less pronounced.
More on tables
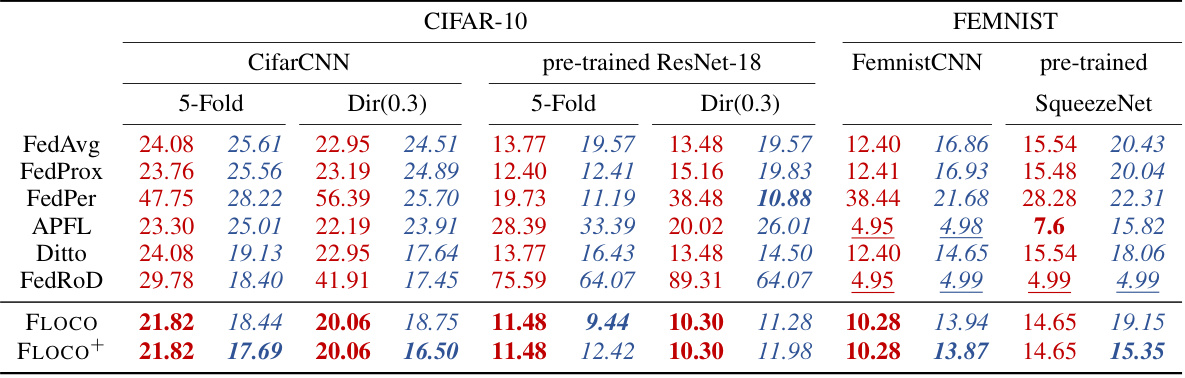
This table presents the average global and local test accuracy results for different federated learning methods on CIFAR-10 and FEMNIST datasets. Different data heterogeneity scenarios (5-Fold and Dir(0.3)) are used for CIFAR-10. The results are broken down by model (CifarCNN, pre-trained ResNet-18, FemnistCNN, pre-trained SqueezeNet) and method (FedAvg, FedProx, FedPer, APFL, Ditto, FedRoD, FLOCO, FLOCO+). It allows for a comparison of the performance of various federated learning approaches under different settings and levels of personalization.
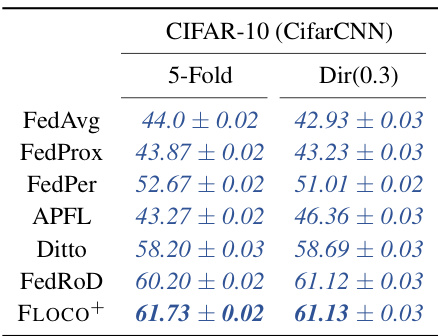
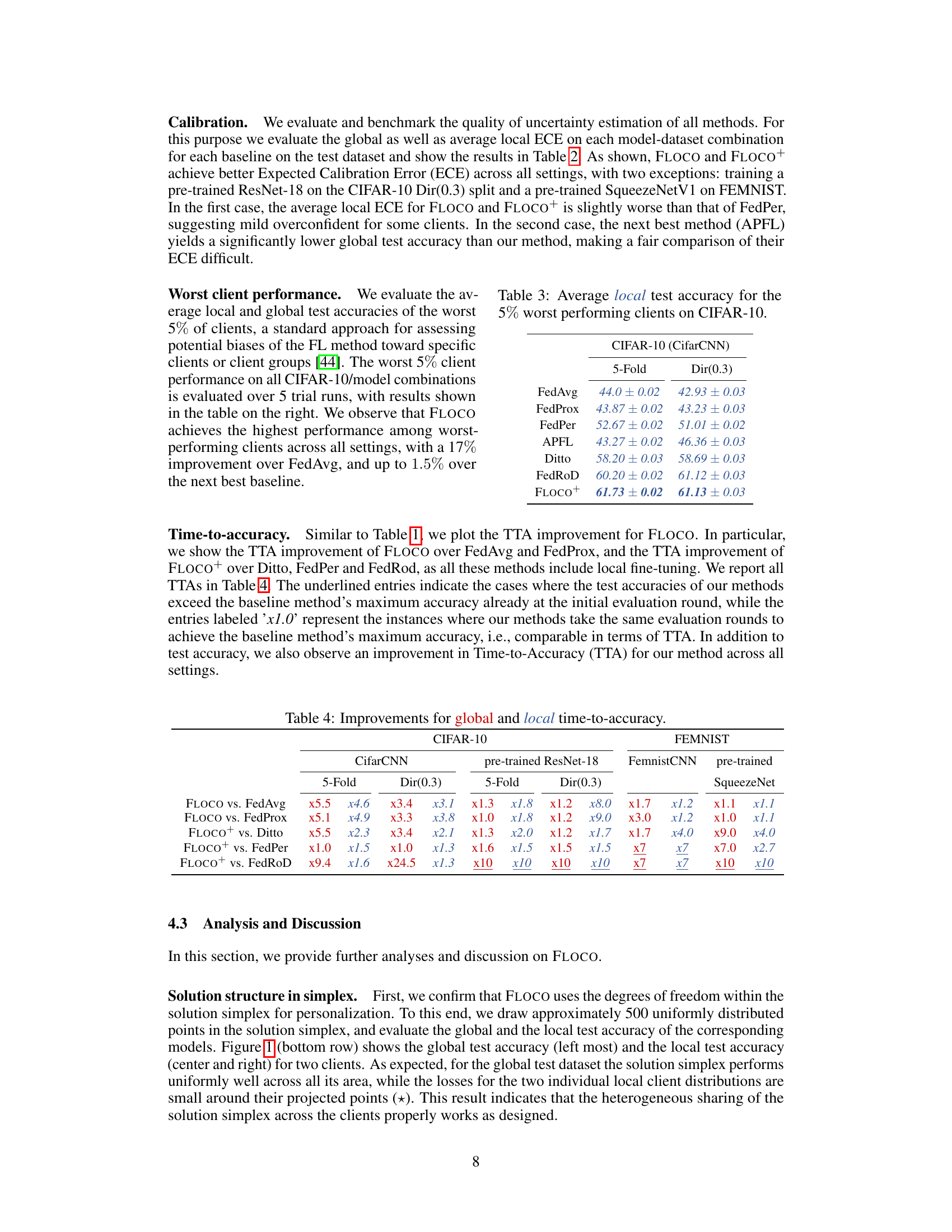
This table presents the average local test accuracy achieved by the 5% worst-performing clients across different federated learning methods. The results are reported for two distinct non-IID data splits of CIFAR-10: 5-Fold and Dir(0.3). It allows for a comparison of various methods’ robustness to outliers and their ability to provide good performance even for the most challenging clients.
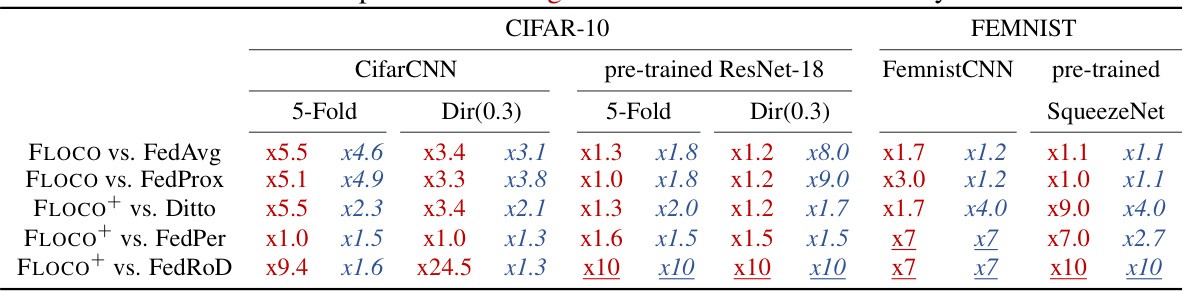
This table presents the time-to-best-accuracy (TTA) improvements achieved by FLOCO and FLOCO+ compared to various baseline methods (FedAvg, FedProx, Ditto, FedPer, and FedRod). It shows how many fewer communication rounds were needed by FLOCO and FLOCO+ to achieve the same test accuracy as the baseline methods for both global and local performance across different datasets and model settings. A value of ‘xN’ indicates that FLOCO or FLOCO+ achieved the same accuracy in 1/N of the communication rounds compared to the baseline methods. For example, ‘x5.5’ means that FLOCO took only 1/5.5 the number of rounds as the baseline method to achieve the same level of accuracy.

This table lists the symbols used in the paper and their corresponding descriptions. It provides a quick reference for understanding the notation used throughout the paper, covering variables related to clients, communication rounds, model parameters, simplex structure, subregions, and gradient updates.

This table presents the hyperparameters used for training different models on various datasets. It shows the number of communication rounds (T), number of clients (K), the size of the client subset selected for each round (|St|), the number of local epochs (e), the number of local epochs for the personalized methods (E/EDITTO), the learning rate (γ), momentum (mom.), weight decay (wd), and proximity regularization parameter (μ). Each row corresponds to a different model-dataset combination.
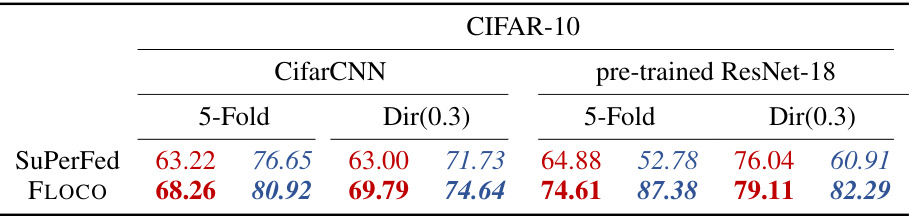
This table compares the performance of FLOCO and SuPerFed on the CIFAR-10 dataset using two different non-IID data splits (5-Fold and Dir(0.3)). It shows the global and local test accuracy for both CifarCNN (trained from scratch) and pre-trained ResNet-18. The results demonstrate FLOCO’s improved performance over SuPerFed.
Full paper#