↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Concept Bottleneck Models (CBMs) aim for interpretable AI by using intermediate concepts to explain model decisions. However, existing CBMs suffer from inaccurate concept predictions and information leakage, where concept values encode unintended information, undermining their reliability. These issues hinder the development of truly trustworthy and interpretable AI.
To address these issues, the paper introduces VLG-CBM, a novel framework that leverages open-domain grounded object detectors to provide visually grounded concept annotation. This enhancement significantly improves the faithfulness of concept prediction and the model’s overall performance. Additionally, they propose a new metric, the Number of Effective Concepts (NEC), to control information leakage and enhance interpretability. Extensive experiments demonstrate VLG-CBM’s superior performance and improved interpretability compared to existing CBMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the critical issue of faithfulness and information leakage in Concept Bottleneck Models (CBMs), a significant challenge in the field of explainable AI. By proposing a novel framework and metric, it directly addresses the limitations of existing methods, paving the way for more reliable and interpretable AI systems. Its findings are relevant to researchers working on explainable AI, computer vision, and NLP, and its approach opens up new avenues for developing more trustworthy and effective CBMs.
Visual Insights#

This figure compares the top 5 concept attributions for different Concept Bottleneck Models (CBMs) on the same image. It highlights that VLG-CBM provides concise and accurate explanations while existing methods (LF-CBM and LM4CV) suffer from inaccurate, less informative, and less transparent explanations due to factual errors in concept predictions, the use of negative concepts, a limited number of concepts, and a significant contribution from non-top concepts.
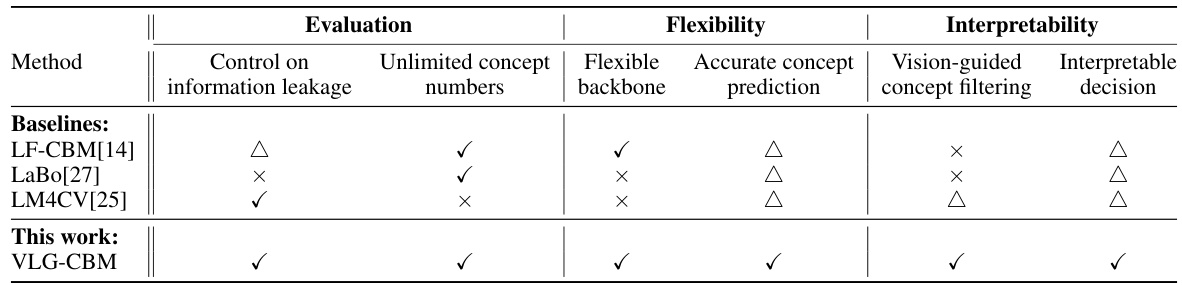
This table compares different concept bottleneck model (CBM) methods based on three key aspects: evaluation metrics, flexibility (e.g., the choice of backbone network), and interpretability. It highlights the strengths and weaknesses of each approach, indicating whether they fully satisfy (✓), partially satisfy (△), or do not satisfy (×) specific criteria related to controlling information leakage, handling various numbers of concepts, using different backbones, achieving accurate concept prediction, incorporating vision-guided filtering, and providing interpretable decisions. The comparison includes three state-of-the-art (SOTA) methods as baselines for the proposed VLG-CBM approach.
In-depth insights#
CBM Limitations#
Concept Bottleneck Models (CBMs) offer a promising approach to enhance model interpretability by introducing an intermediate layer that encodes human-understandable concepts. However, CBMs face critical limitations. A major challenge is the inaccuracy of concept prediction, where predicted concepts often mismatch the input image, undermining the trustworthiness of the interpretation. This can stem from relying on language models which may generate concepts unrelated to visual content, or from limitations in the training data or process. Another significant issue is information leakage, where concept values encode unintended information that aids downstream tasks even if the concepts themselves are irrelevant. This undermines the claim of faithfulness in the interpretation and suggests a potential overfitting to the task. These limitations raise concerns about the overall utility and reliability of CBMs, highlighting the need for improved methods that address concept faithfulness and mitigate information leakage to ensure that the learned concepts genuinely reflect the model’s decision-making process and lead to reliable explanations.
VLG-CBM Method#
The core of the VLG-CBM method lies in its automated approach to training concept bottleneck models (CBMs). This addresses the limitations of existing CBMs that rely on manual concept annotation by leveraging readily available open-domain grounded object detectors. This provides visually grounded and localized concept annotations which significantly enhances the faithfulness of the concept predictions. The method introduces a novel two-stage training process. First, an auxiliary dataset is created by utilizing an off-the-shelf object detection model to annotate images with fine-grained concepts, represented as bounding boxes and concept labels. Second, a concept bottleneck layer (CBL) is trained using this auto-labeled data, followed by a sparse linear layer mapping concepts to class labels. A key innovation is the introduction of the Number of Effective Concepts (NEC) metric. NEC addresses the information leakage problem inherent in CBMs by controlling the number of concepts used in the final prediction. This contributes to both improved accuracy and enhanced interpretability. The combination of vision-language guidance and NEC control allows VLG-CBM to outperform existing methods by a considerable margin while achieving significantly better faithfulness and interpretability.
NEC Evaluation#
The concept of NEC (Number of Effective Concepts) evaluation offers a crucial lens through which to assess the interpretability and performance of Concept Bottleneck Models (CBMs). NEC directly addresses the issue of information leakage, a significant concern in CBMs where high accuracy might arise from unintended information encoded in the concept layer, rather than true semantic understanding. By limiting the number of effective concepts, NEC helps to filter out this spurious information, promoting more faithful and reliable interpretability. The effectiveness of NEC is demonstrated through comparative analysis with baselines, showing improvements in accuracy while maintaining interpretability at lower NEC values. This evaluation method is particularly valuable in showcasing a trade-off between model performance and interpretability. Lower NEC values, while potentially sacrificing some accuracy, enhance the transparency and understandability of CBM decision-making. Therefore, NEC evaluation provides a powerful and nuanced way to gauge not only the predictive capabilities but also the explanatory power and trustworthiness of CBMs, ultimately moving the field towards more reliable and insightful explainable AI.
Experimental Results#
A thorough analysis of the ‘Experimental Results’ section requires careful consideration of several aspects. First, the choice of metrics is crucial; are they appropriate for the research question and do they adequately capture the nuances of the system’s performance? Next, the breadth and depth of the experiments should be examined. Were sufficient experiments conducted to validate claims and account for potential variability? The presentation of results is also important; are the findings clearly displayed and easy to interpret, including error bars or confidence intervals to show statistical significance? Finally, the discussion of results needs to go beyond merely stating the findings. A thoughtful examination should relate the results back to the research hypotheses, acknowledging limitations and discussing any unexpected outcomes. A strong ‘Experimental Results’ section provides not only a numerical report, but a compelling narrative that guides the reader to a sound understanding of the work’s contributions and their limitations.
Future Work#
The paper’s ‘Future Work’ section could explore several promising avenues. Extending VLG-CBM to other modalities such as audio or multi-modal data is a natural next step, potentially leading to even richer and more nuanced interpretations. Investigating the impact of different object detectors and LLMs on the performance and faithfulness of VLG-CBM would help determine the robustness and generalizability of the method. Furthermore, a deeper theoretical analysis of information leakage within the CBM framework is warranted, potentially leading to novel strategies for mitigating this problem. Developing more sophisticated metrics for evaluating interpretability beyond NEC would allow for a more comprehensive assessment of VLG-CBM’s capabilities. Finally, exploring the potential of VLG-CBM for applications beyond image classification, like object detection or video analysis, could unlock significant advancements in various AI fields.
More visual insights#
More on figures

This figure illustrates the pipeline of the Vision-Language-Guided Concept Bottleneck Model (VLG-CBM). It starts with obtaining candidate concepts from Large Language Models (LLMs) based on prompts about the image class. Then, a grounded object detector identifies bounding boxes of these concepts within an input image. This generates an auto-labeled dataset consisting of images, concepts (as detected in bounding boxes), and class labels. This dataset is then used to train a Concept Bottleneck Layer (CBL) and a final learning predictor. The CBL maps image features to concept logits using a multilabel binary cross-entropy loss, while the learning predictor maps concept logits to class labels using a multiclass cross-entropy loss. This entire pipeline demonstrates the automated and guided approach to train the CBM.
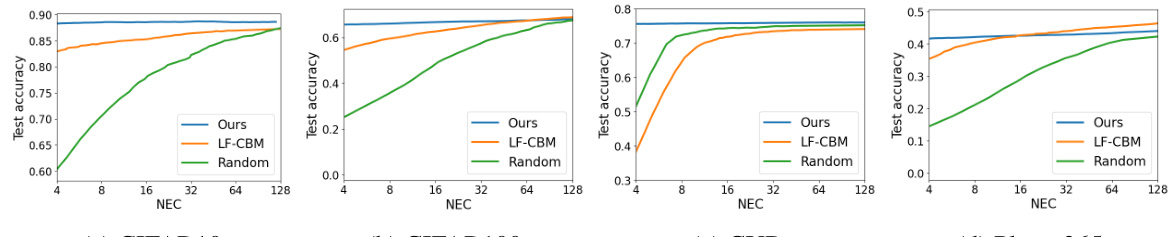
This figure compares the test accuracy of three different models (VLG-CBM, LF-CBM, and a model with a randomly initialized concept bottleneck layer) across varying numbers of effective concepts (NEC). The x-axis represents the NEC, and the y-axis represents the test accuracy. It demonstrates how the accuracy of each model changes as the number of effective concepts increases, highlighting the relationship between interpretability (controlled by NEC) and performance.

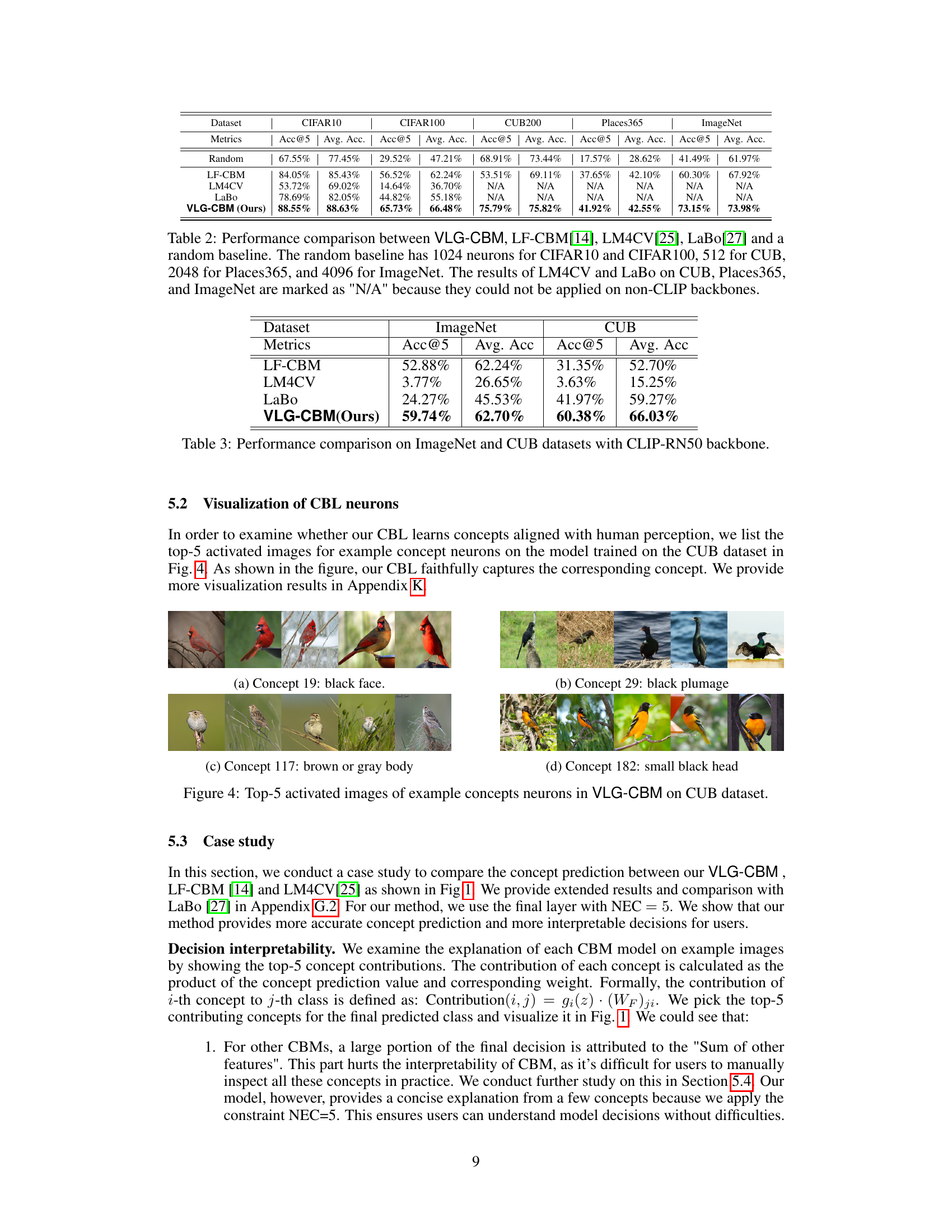
This figure shows the top 5 images that activate the neurons for four example concepts in the VLG-CBM model trained on the CUB dataset. The concepts are: (a) black face, (b) black plumage, (c) brown or gray body, (d) small black head. This visualization demonstrates that the model learns concepts that align with human perception of visual features.

This figure compares the top 5 concept attributions for the decisions of VLG-CBM and three other Concept Bottleneck Models (CBMs): LF-CBM, LM4CV, and a method from Yang et al. VLG-CBM shows concise and accurate concept attributions, while the other methods show less informative negative concepts, inaccurate concepts not matching the image, or a significant portion of contributions from non-top concepts. This highlights VLG-CBM’s improved faithfulness and interpretability.

This figure compares the accuracy of VLG-CBM against LF-CBM and a randomly initialized CBL across different NEC (Number of Effective Concepts) values. It demonstrates that VLG-CBM outperforms the other methods, especially when NEC is small. The graph visually shows how accuracy changes with increasing NEC, highlighting the impact of information leakage in CBMs with higher NEC.

This figure compares the top 5 concept attributions for four different methods (VLG-CBM, LF-CBM, LM4CV, and a random baseline) in explaining their decisions for the same image. It highlights the differences in accuracy, conciseness, and faithfulness of the concept attributions produced by each method. VLG-CBM’s attributions are shown as accurate, concise, and visually grounded, in contrast to the others which often include inaccurate or irrelevant concepts.

This figure compares the decision explanations of VLG-CBM with three other existing methods (LF-CBM, LM4CV, and a method from Yang et al. [27]). The comparison focuses on the top 5 contributing concepts to the model’s decision for each method. It highlights the concise and accurate explanations provided by VLG-CBM compared to the less informative or inaccurate explanations from the other methods. Key differences noted are that VLG-CBM uses only positive concepts, while LF-CBM frequently uses negative concepts; LM4CV uses concepts unrelated to the image; and all three alternative methods have significant contributions from non-top concepts, reducing transparency.

This figure compares the top 5 concept contributions used by four different models (VLG-CBM, LF-CBM, LM4CV, and a baseline) to explain their decisions for a given image. The comparison highlights the differences in accuracy and faithfulness of concept predictions, showing how VLG-CBM provides more concise and accurate explanations aligned with human perception compared to existing methods which often rely on inaccurate, negative, or irrelevant concepts.

This figure compares the top 5 concept contributions used by VLG-CBM and existing methods (LF-CBM, LM4CV) to explain their decisions for a given image. It highlights the differences in the accuracy, conciseness, and faithfulness of concept attributions among these methods, showing that VLG-CBM provides more concise and accurate explanations.

This figure compares the top 5 contributing concepts for the decisions made by VLG-CBM and three other existing methods (LF-CBM, LM4CV, and LaMCV) for a sample image. It highlights that VLG-CBM offers more concise and accurate concept attributions, unlike the others which may use negative concepts, irrelevant concepts, or a significant number of non-top contributing concepts, making the explanation less informative and transparent.
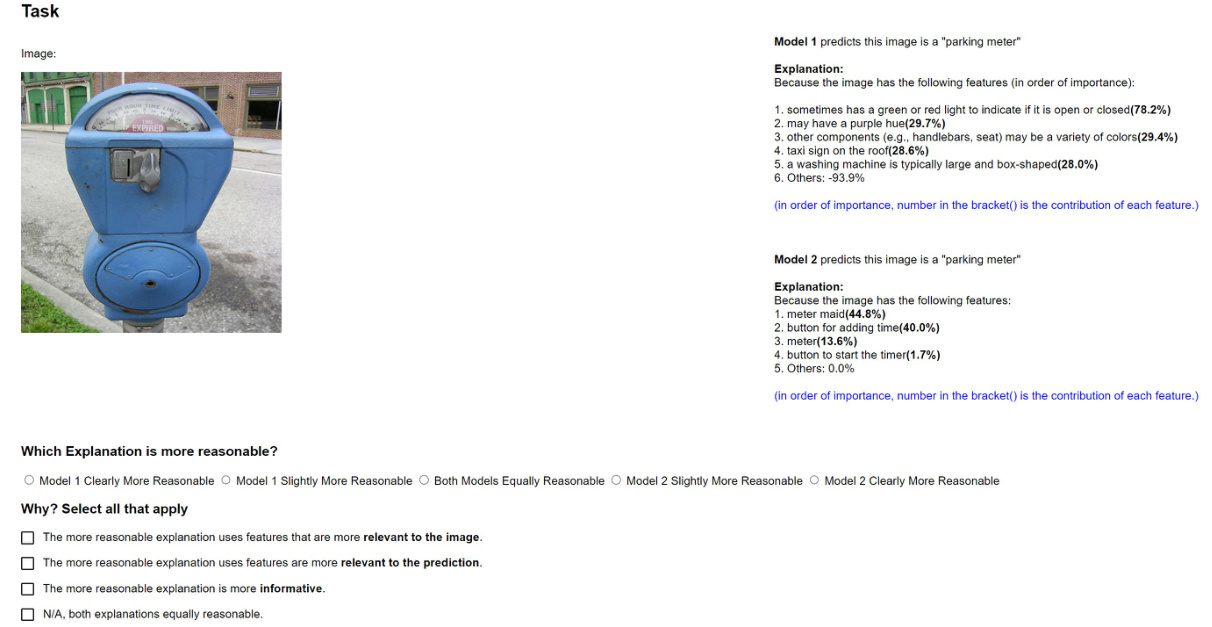
This figure compares the decision explanations of VLG-CBM with three other methods (LF-CBM, LM4CV, and LaBo) by listing the top 5 contributing concepts for each method’s decisions. The comparison highlights that VLG-CBM provides concise and accurate explanations, while the other methods suffer from issues like inaccurate concept predictions, use of negative concepts, and a significant portion of contribution from non-top concepts, which makes their decisions less transparent. The figure demonstrates the superior accuracy and interpretability of the proposed VLG-CBM model.
This figure compares the top 5 contributing concepts to the decision made by VLG-CBM and three other methods (LF-CBM, LM4CV, and LaBo). It highlights that VLG-CBM provides concise and accurate explanations, unlike the other methods which may use negative concepts, irrelevant concepts, or a significant portion of contributions from non-top concepts, thereby hindering the interpretability of the decisions.

This figure compares the top 5 concept contributions used by four different methods (VLG-CBM, LF-CBM, LM4CV, and a baseline) to explain their classification decisions for a bird image. It highlights that VLG-CBM provides more concise and accurate explanations compared to other methods, which often include inaccurate, irrelevant, or non-visual concepts, or rely too heavily on non-top concept contributions for the explanation.

This figure compares the top 5 concept contributions used by VLG-CBM and three other methods (LF-CBM, LM4CV, and LaBo) to explain their decisions for the same image. It highlights that VLG-CBM provides more concise, accurate, and visually grounded explanations compared to the others, which suffer from inaccurate concept predictions, negative concepts, and information leakage from non-visual concepts.

This figure compares the decision explanations of VLG-CBM with three other methods (LF-CBM, LM4CV, and a baseline). It highlights that VLG-CBM provides more concise and accurate concept attributions, unlike the other methods which show various issues like using negative concepts, inaccurate concept predictions, or relying heavily on non-top concepts for the decision. This impacts the interpretability and faithfulness of the explanations.

This figure compares the decision explanations of VLG-CBM with three other concept bottleneck models (LF-CBM, LM4CV, and LM4CV). It shows the top 5 contributing concepts for each model’s decision on the same image. VLG-CBM provides concise and accurate concept attributions, while the other methods show shortcomings such as using negative concepts (LF-CBM), inaccurate concept predictions (LM4CV), and a significant contribution from non-top concepts, leading to less transparent decisions. The figure highlights VLG-CBM’s superior interpretability and accuracy.
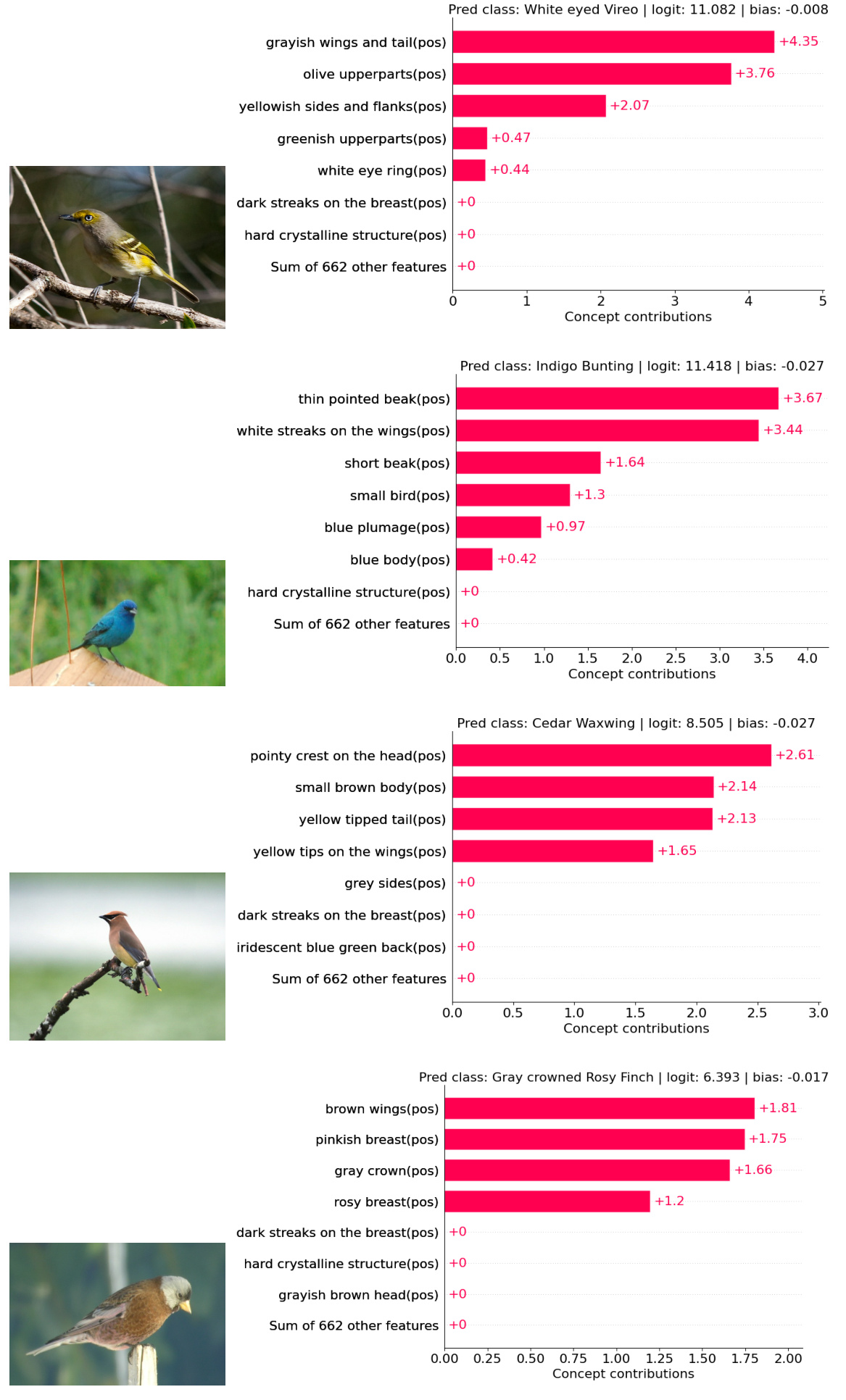
This figure compares the top 5 concept contributions used by VLG-CBM and other existing methods (LF-CBM, LM4CV) to explain their decisions for a bird image. It highlights that VLG-CBM provides concise and accurate explanations, while others use inaccurate, less informative, or non-visual concepts, thus affecting transparency.
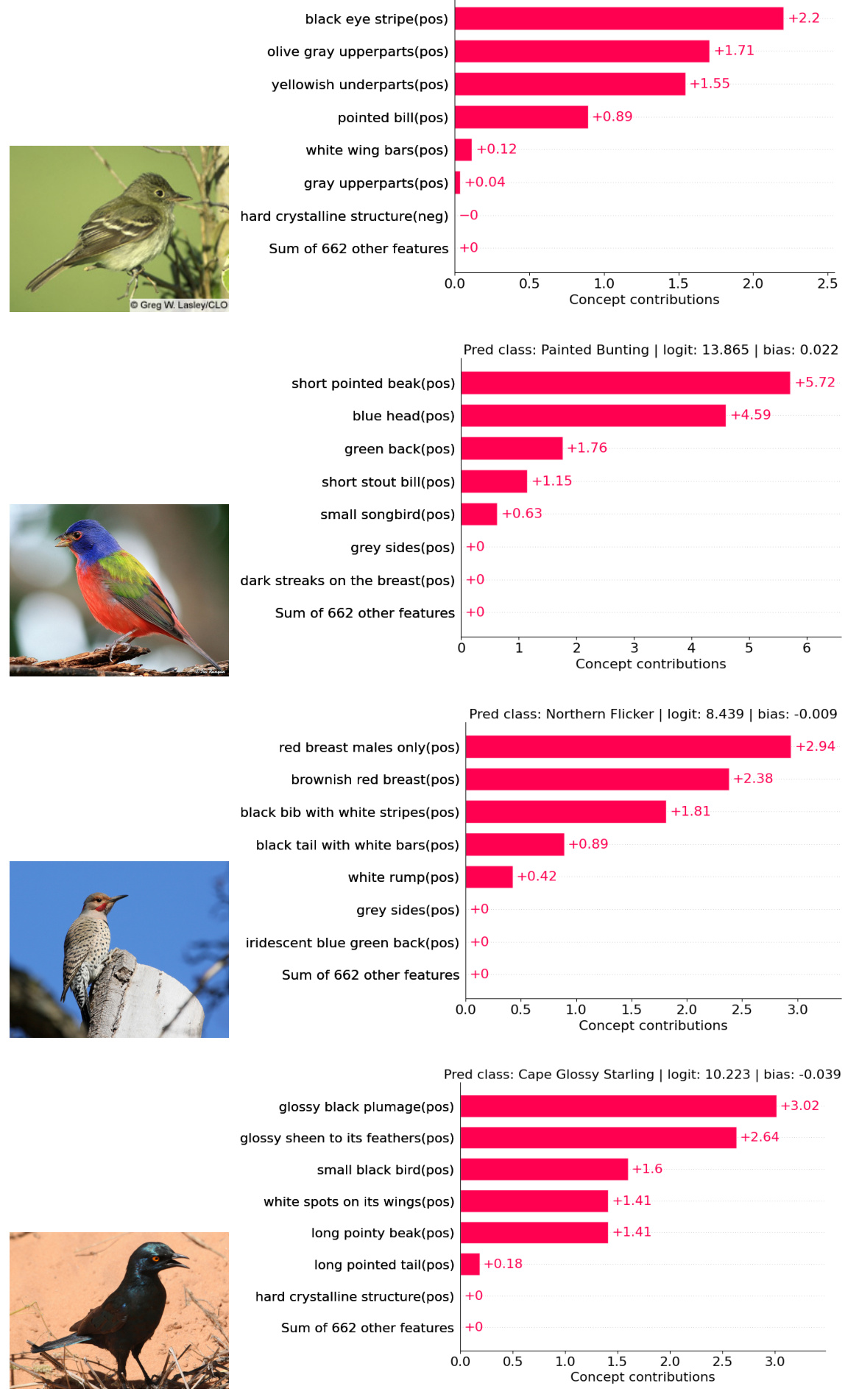
This figure compares the top 5 contributing concepts for decision explanations from VLG-CBM and three other methods (LF-CBM, LM4CV, and LaBo). It highlights the differences in accuracy, conciseness, and faithfulness of concept attribution across these methods. VLG-CBM demonstrates more concise, accurate, and visually grounded explanations compared to the others.
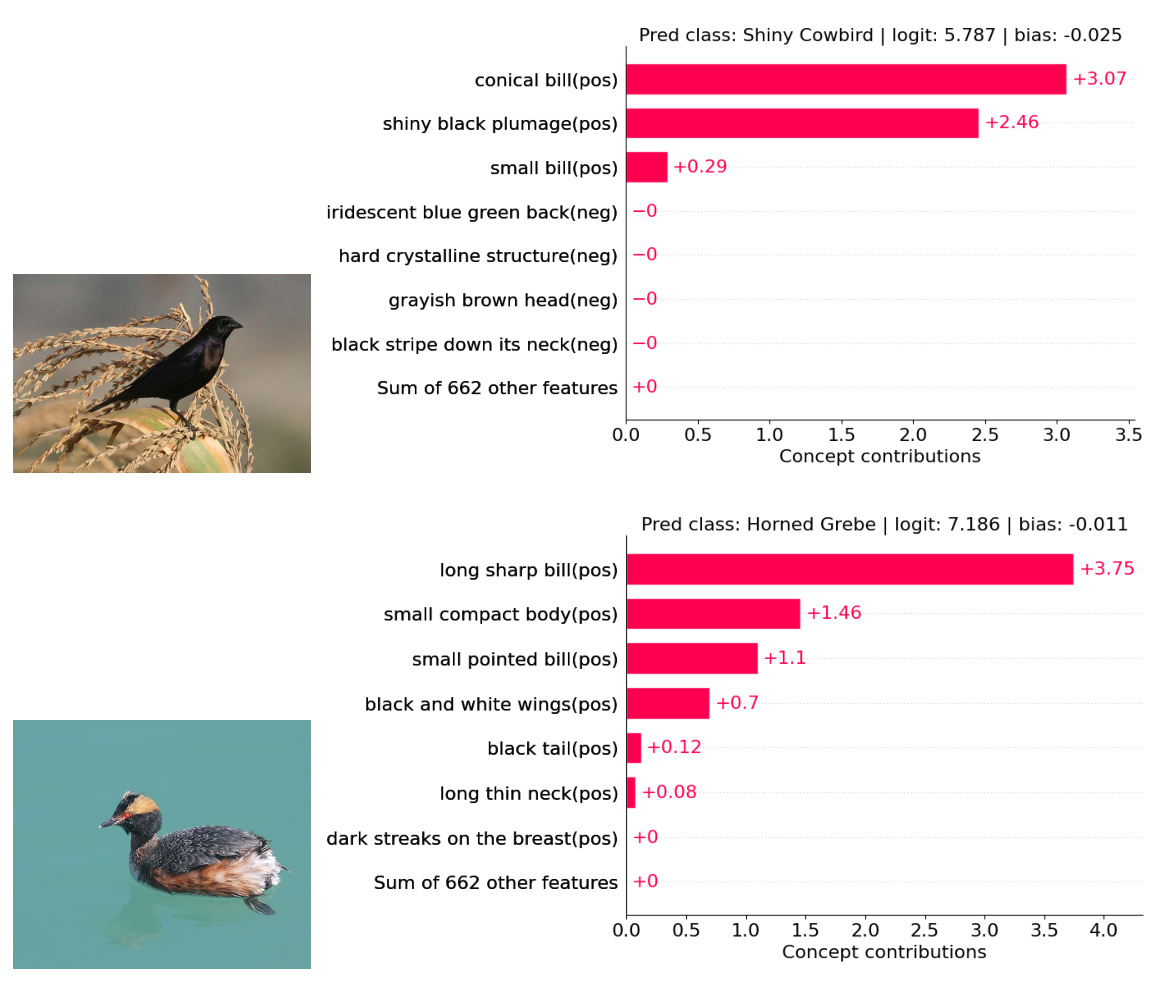
This figure compares the decision explanations of VLG-CBM and three other methods (LF-CBM, LM4CV, and a baseline) by showing the top 5 contributing concepts for each method’s decision on an example image. VLG-CBM provides concise and accurate explanations based on relevant visual concepts. The other methods suffer from problems such as using negative concepts (LF-CBM), using concepts that do not match the image (LM4CV), and having a significant portion of the decision coming from non-top concepts, making explanations less transparent.
More on tables

This table presents a comparison of the performance of the proposed Vision-Language-Guided Concept Bottleneck Model (VLG-CBM) against several state-of-the-art baselines on five image classification datasets. The metrics used are accuracy at NEC=5 (Acc@5) and average accuracy across different numbers of effective concepts (NECs). Note that some baseline methods were not applicable to all datasets due to their reliance on specific architectures or backbones.

This table presents a performance comparison between different methods (LF-CBM, LM4CV, LaBo, and VLG-CBM) on the ImageNet and CUB datasets. The backbone used is CLIP-RN50. The metrics used are Accuracy at NEC=5 (Acc@5) and Average Accuracy (Avg. Acc) across different NEC values. VLG-CBM shows superior performance compared to the baseline methods on both datasets and for both metrics.

This table compares different concept bottleneck model (CBM) methods based on their ability to control information leakage, flexibility in choosing the backbone, accuracy of concept prediction, and overall interpretability. It uses checkmarks (✓), partial checkmarks (△), and crosses (×) to indicate whether each method satisfies, partially satisfies, or fails to satisfy these criteria, respectively. The table highlights the advantages of the proposed VLG-CBM method in comparison to state-of-the-art methods.
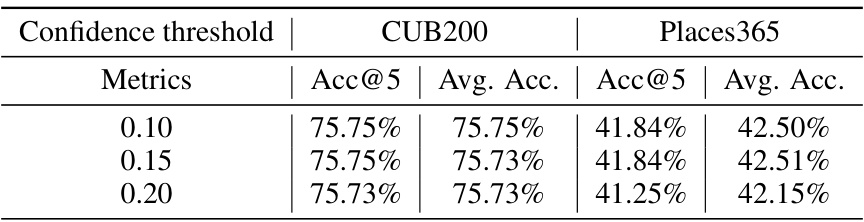
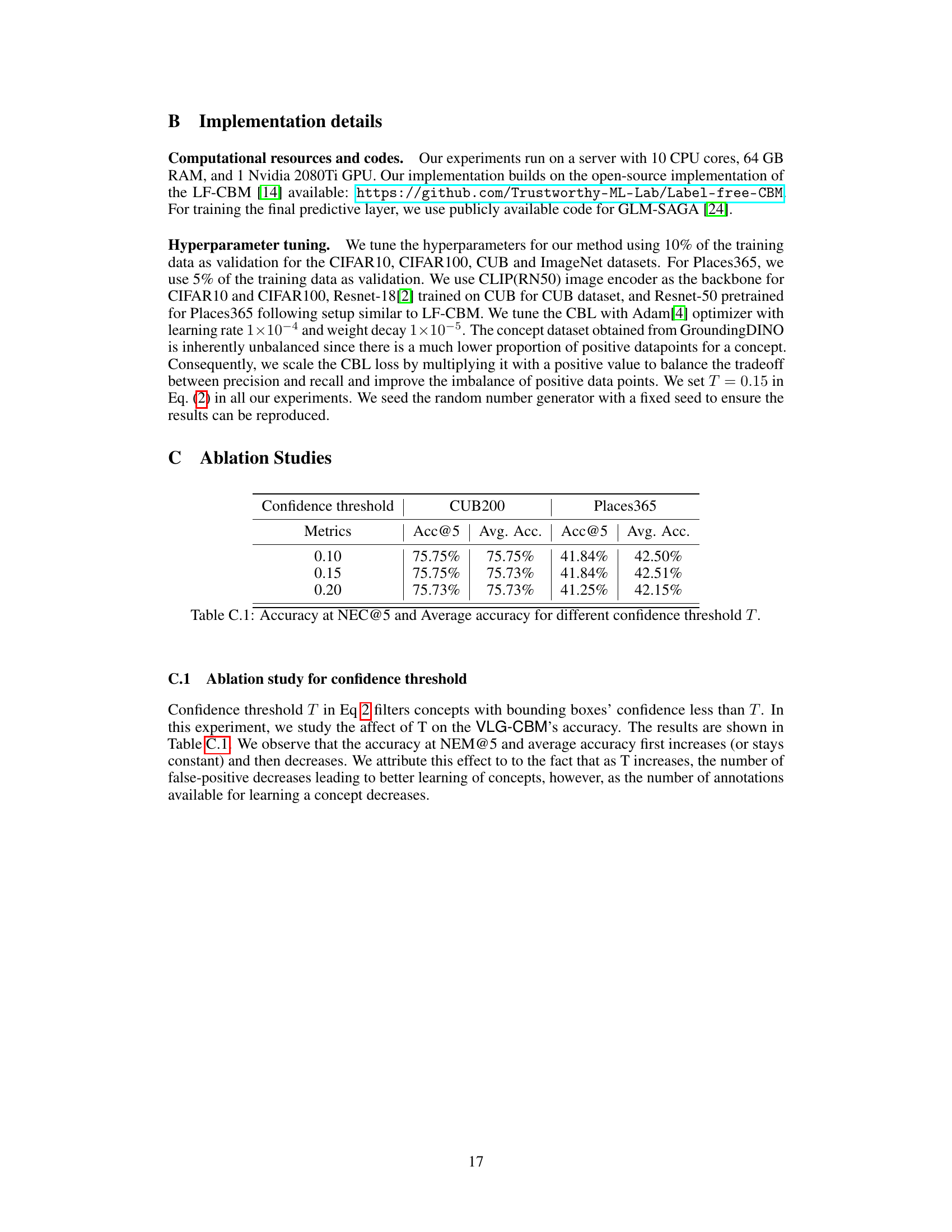
This ablation study analyzes the impact of varying the confidence threshold (T) on the accuracy of the VLG-CBM model. The threshold determines which bounding boxes from the object detector are included in the concept annotations. The table shows that there is minimal change in accuracy at NEC=5 and average accuracy across various values of T, indicating that the model is robust to this hyperparameter.

This table compares different methods for training concept bottleneck models based on their ability to control information leakage, flexibility in choosing a model backbone, accuracy of concept prediction, whether concept filtering is vision-guided, and the interpretability of the final decision. The symbols ✓, △, and × indicate whether a method fully satisfies, partially satisfies, or does not satisfy a given requirement, respectively. The table also includes a comparison to state-of-the-art (SOTA) methods (LF-CBM, LaBo, and LM4CV).

This table compares the performance of the proposed VLG-CBM model against three state-of-the-art concept bottleneck models (LF-CBM, LaBo, LM4CV) and a random baseline across five image classification datasets (CIFAR10, CIFAR100, CUB, Places365, ImageNet). The table presents the accuracy at NEC=5 (Acc@5) and the average accuracy across different NEC values. Note that LaBo and LM4CV are not applicable (‘N/A’) for all datasets, due to limitations in their architecture or availability.

This table compares several methods for training concept bottleneck models (CBMs) based on three key aspects: evaluation (control over information leakage, accurate concept prediction, vision-guided concept filtering), flexibility (flexible backbone, unlimited concept numbers), and interpretability (interpretable decision). Each method (LF-CBM, LaBo, LM4CV, and VLG-CBM) is evaluated using checkmarks representing whether it fully satisfies (✓), partially satisfies (△), or does not satisfy (×) each criterion.

This table compares different methods for training concept bottleneck models (CBM) based on three key aspects: evaluation (control on information leakage, accurate concept prediction, vision-guided concept filtering), flexibility (unlimited concept numbers, flexible backbone), and interpretability (interpretable decision). It shows that VLG-CBM, the proposed method, is superior in all three aspects compared to existing state-of-the-art methods (LF-CBM, LaBo, LM4CV).
Full paper#