↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing neuron attribution methods struggle to interpret Multimodal Large Language Models (MLLMs) due to challenges like semantic noise in multi-modal outputs and the inefficiency of existing attribution techniques. These methods also often fail to differentiate between neurons responsible for text and image generation.
The proposed Neuron Attribution Method (NAM) tackles these issues by using image segmentation to remove noise, employing an activation-based scoring system to improve efficiency and decoupling the analysis of neurons responsible for text and image generation. This provides a more accurate and efficient understanding of how MLLMs process information, and offers a method for multi-modal knowledge editing. The effectiveness of NAM and the valuable insights offered by the method are confirmed through theoretical analysis and empirical validation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with Multimodal Large Language Models (MLLMs) because it introduces a novel neuron attribution method (NAM) that addresses the limitations of existing techniques when applied to MLLMs. This method offers valuable insights into the inner workings of MLLMs and provides a framework for knowledge editing, opening exciting avenues for improving MLLM interpretability and functionality.
Visual Insights#
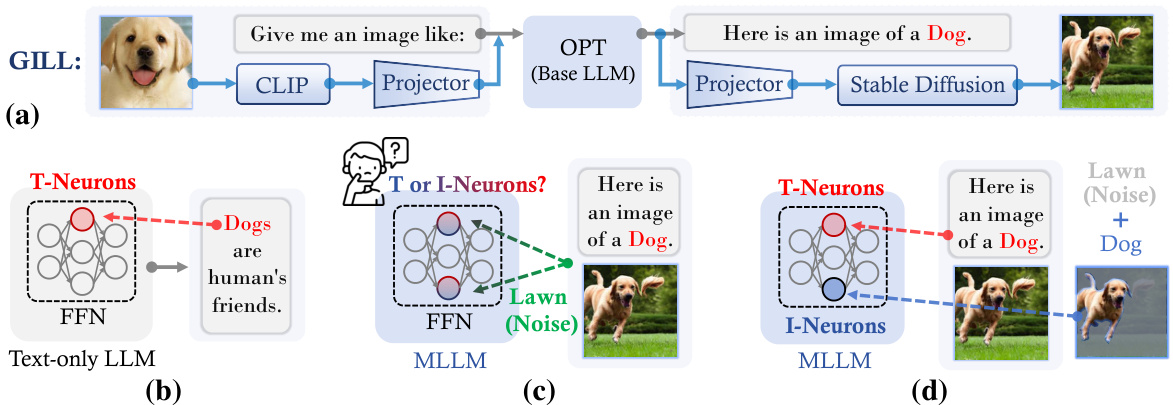
This figure illustrates the differences in neuron attribution methods between text-only LLMs and MLLMs. (a) shows the GILL model architecture, a multimodal LLM. (b) depicts the traditional neuron attribution for text-only LLMs, directly linking neurons to text outputs. (c) highlights the challenges of applying this method to MLLMs, such as noise in generated images and the intermingling of modality-specific neurons. (d) presents the proposed NAM method, which addresses these challenges by using image segmentation to reduce noise and identifying modality-specific neurons.
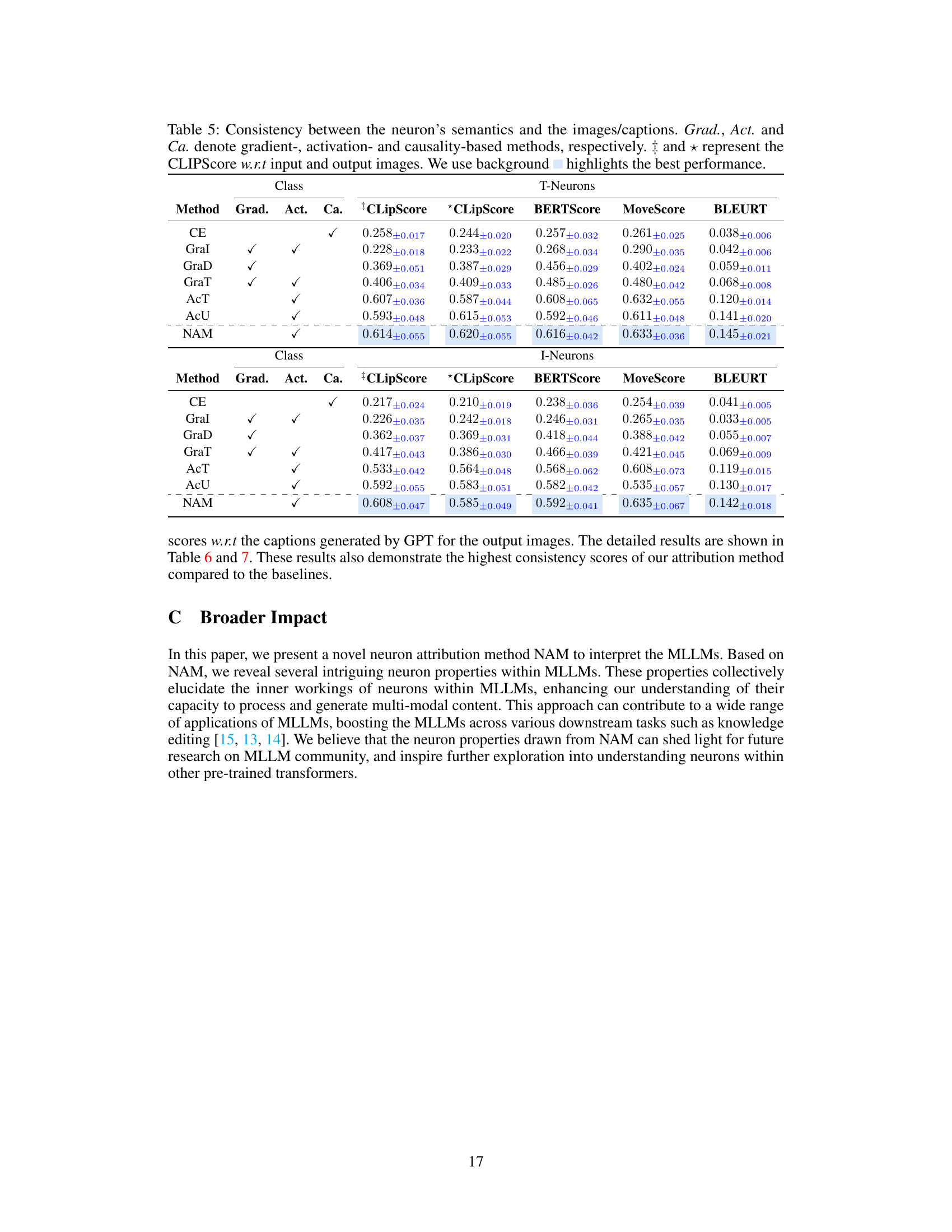
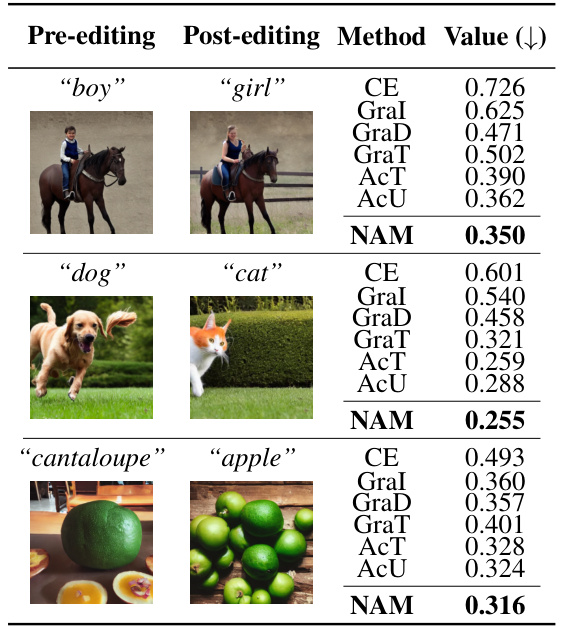
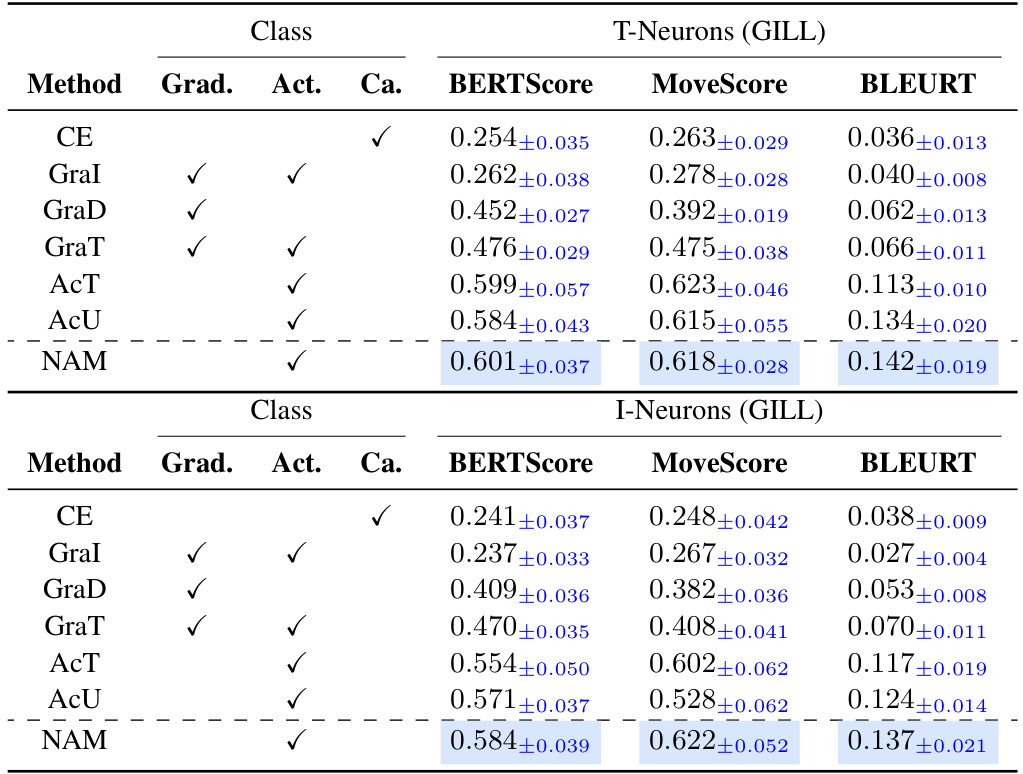
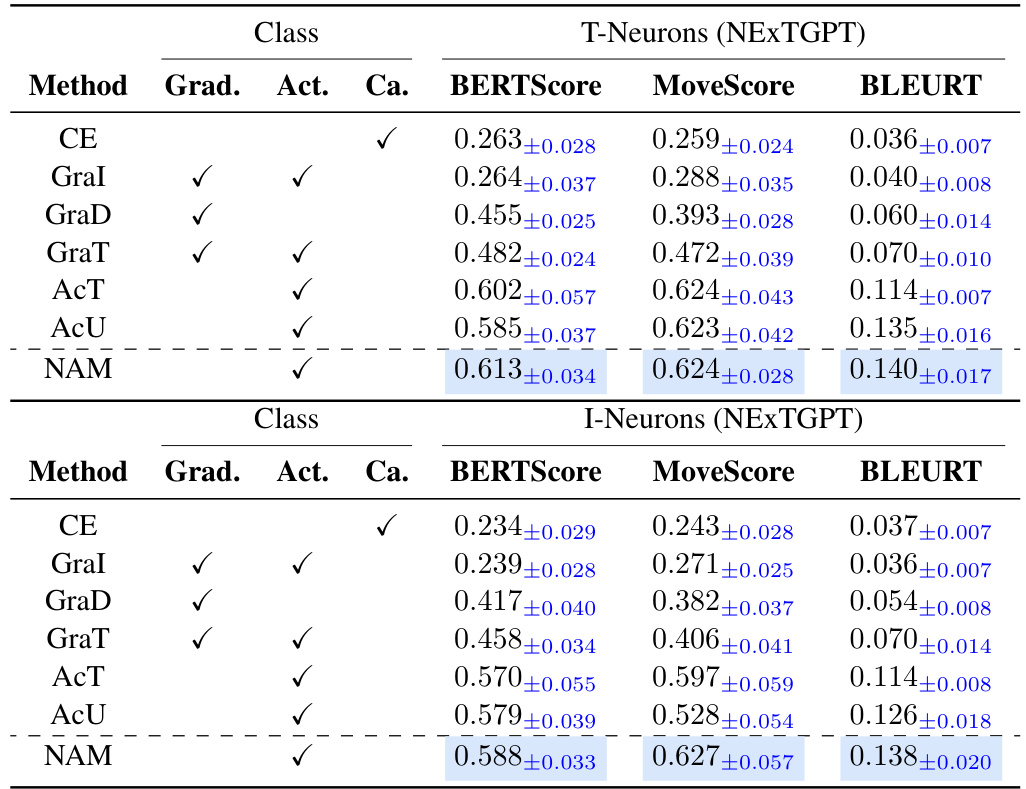
This table presents the quantitative evaluation results of semantic relevance for T-neurons and I-neurons identified by different attribution methods including NAM. It compares the consistency between the semantics of these neurons and the corresponding input/output images and captions using several metrics: CLIPScore (with respect to input and output images), BERTScore, MoverScore, and BLEURT. The table highlights the best-performing method for each metric and class (T-neurons/I-neurons).
In-depth insights#
Multimodal Neuron Attribution#
Multimodal neuron attribution presents a significant challenge and opportunity in understanding large language models (LLMs). It seeks to bridge the gap between the model’s internal representations and its ability to process and generate diverse multimodal content (text, images, audio, etc.). A key difficulty lies in disentangling the contributions of individual neurons across different modalities, as a single neuron might participate in processing information from multiple modalities simultaneously. Effective multimodal neuron attribution methods must account for this cross-modal interaction, which isn’t captured by methods designed for unimodal data. Success in this area would unlock critical insights into the internal workings of MLLMs, revealing how these models integrate and synthesize information from different sources, and ultimately improve their interpretability and trustworthiness. Furthermore, it would pave the way for more sophisticated techniques for editing and manipulating the knowledge embedded within MLLMs, allowing for targeted modifications to the model’s behavior and capabilities.
NAM Methodology#
The core of the NAM methodology centers on attributing multimodal outputs (images and text) to specific neurons within a multimodal large language model (MLLM). This is achieved through a two-step process: Firstly, it uses image segmentation to isolate relevant semantic regions in the generated image, mitigating noise from extraneous elements. Then, a novel attribution score, based on neuron activations, is introduced to identify modality-specific (textual or image) neurons responsible for generating the given semantic concept. This avoids the computational expense of gradient-based methods while enabling detailed analysis of both image generation (I-neurons) and text generation (T-neurons). The methodology also facilitates multimodal knowledge editing, demonstrating practical applications. Addressing the limitations of existing methods for interpreting MLLMs is a significant strength of NAM, providing a more efficient and insightful approach to understanding these complex models.
Image Editing#
The concept of ‘Image Editing’ within the context of multimodal large language models (MLLMs) presents exciting possibilities. The core idea is to leverage the model’s understanding of image semantics to perform targeted edits, moving beyond simple pixel manipulation. This is achieved by identifying the neurons responsible for specific image features (I-neurons) and then carefully adjusting their activation patterns. This approach offers a non-destructive method, avoiding the limitations of traditional image editing techniques. It enables semantic-level changes, affecting the meaning and content of the image rather than just its appearance. However, challenges remain, particularly in ensuring precise control and avoiding unwanted side effects. Further research is needed to better understand and manage the complex interplay of neurons in MLLMs to fully realize the potential of this semantic image editing paradigm.
Limitations of NAM#
The efficacy of NAM, while promising, is contingent upon several factors. Image segmentation accuracy directly impacts the reliability of attribution, as inaccuracies in identifying semantically relevant regions introduce noise. The reliance on activation-based scores, while efficient, might overlook indirect neuronal influences. The method’s current implementation focuses on FFN layers, potentially neglecting the contributions of other architectural components within MLLMs. Furthermore, generalizability across diverse MLLM architectures remains to be fully explored, necessitating further testing and validation on a broader range of models. Bias introduced by the chosen image segmentation and attribution methods also needs careful consideration. Finally, extending NAM to modalities beyond image and text requires careful adaptation of component algorithms, presenting a challenge for future work.
Future Directions#
Future research could explore extending the proposed neuron attribution method to a broader range of multimodal large language models (MLLMs) and modalities beyond text and images. Investigating the dynamics of neuron interactions across different modalities is crucial, particularly the interplay between textual and visual information processing. Furthermore, developing more efficient attribution methods is important, potentially leveraging advancements in computational techniques to reduce the computational cost of current methods. Finally, exploring the applications of this approach to downstream tasks, such as multimodal knowledge editing, generation, and bias mitigation, would be valuable. A deeper analysis of how modality-specific knowledge is learned and integrated could further our understanding of MLLM architectures and improve their performance and interpretability.
More visual insights#
More on figures

This figure illustrates the neuron attribution methods for interpreting LLMs, comparing the traditional approach for text-only LLMs with the challenges and proposed solution for Multimodal LLMs (MLLMs). Panel (a) shows the standard approach for text-only LLMs, focusing on attributing the output text to neurons within the FFN layers. Panel (b) highlights the challenges of applying this method to MLLMs, such as semantic noise (extraneous elements in generated images), inefficiency (computationally expensive methods), and the intermingling of text and image neurons. Panel (c) illustrates the proposed NAM method (Neuron Attribution for MLLMs) which addresses these challenges by using image segmentation to identify target semantic regions, employing activation-based scores for efficiency, and decoupling the analysis of modality-specific neurons.
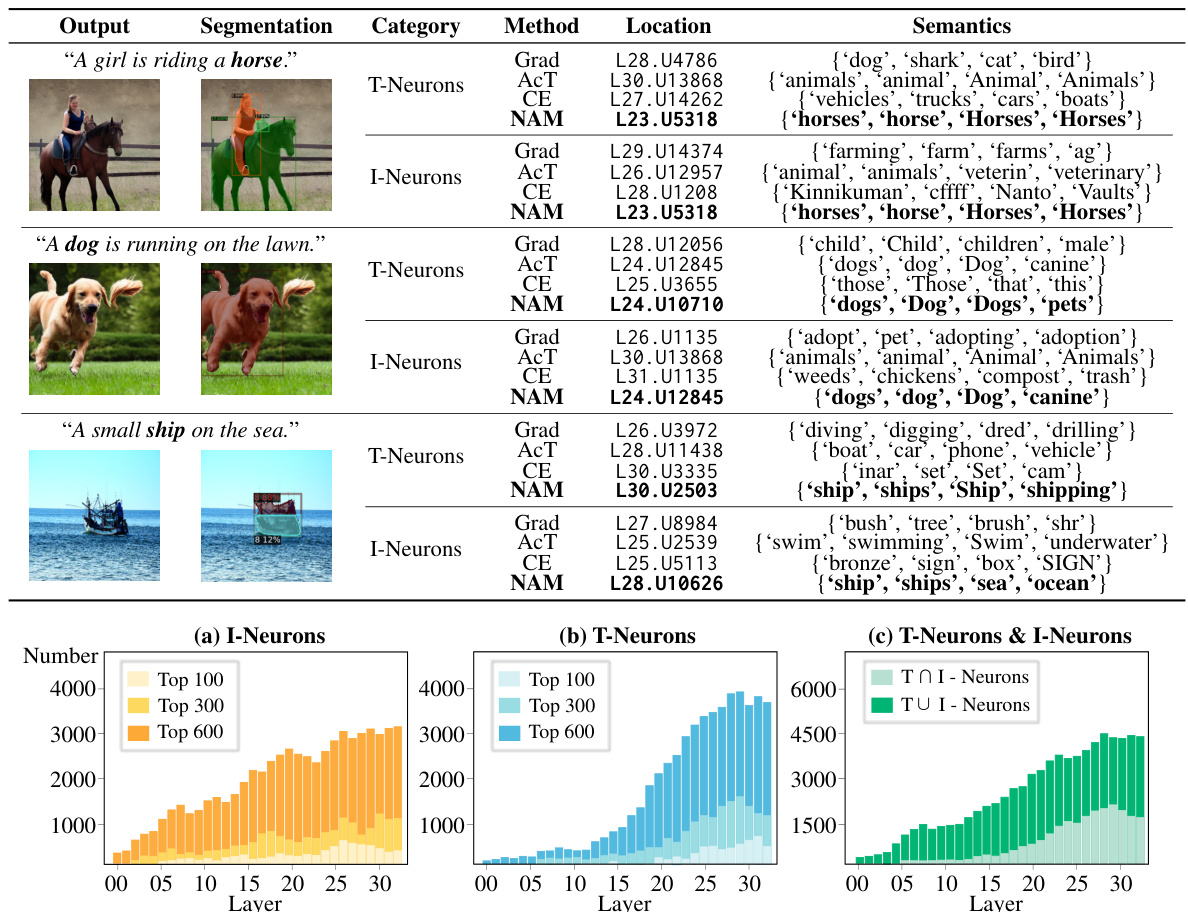
This figure visualizes the distribution of I-neurons (image-related neurons), T-neurons (text-related neurons), and their overlap across different layers of the multi-modal large language model (MLLM). Subfigures (a) and (b) show the distributions of I-neurons and T-neurons respectively, highlighting the concentration of these neurons in the middle and higher layers of the model. Subfigure (c) illustrates the intersection and the subset relationships between these two neuron types, indicating that while some neurons contribute to both image and text generation, many are modality-specific.
This figure illustrates the different paradigms of neuron attribution methods for LLMs. (a) shows the architecture of GILL, a multimodal LLM. (b) depicts current methods for text-only LLMs. (c) highlights the challenges in extending those methods to multimodal LLMs. (d) presents the proposed NAM method, which addresses these challenges.
More on tables
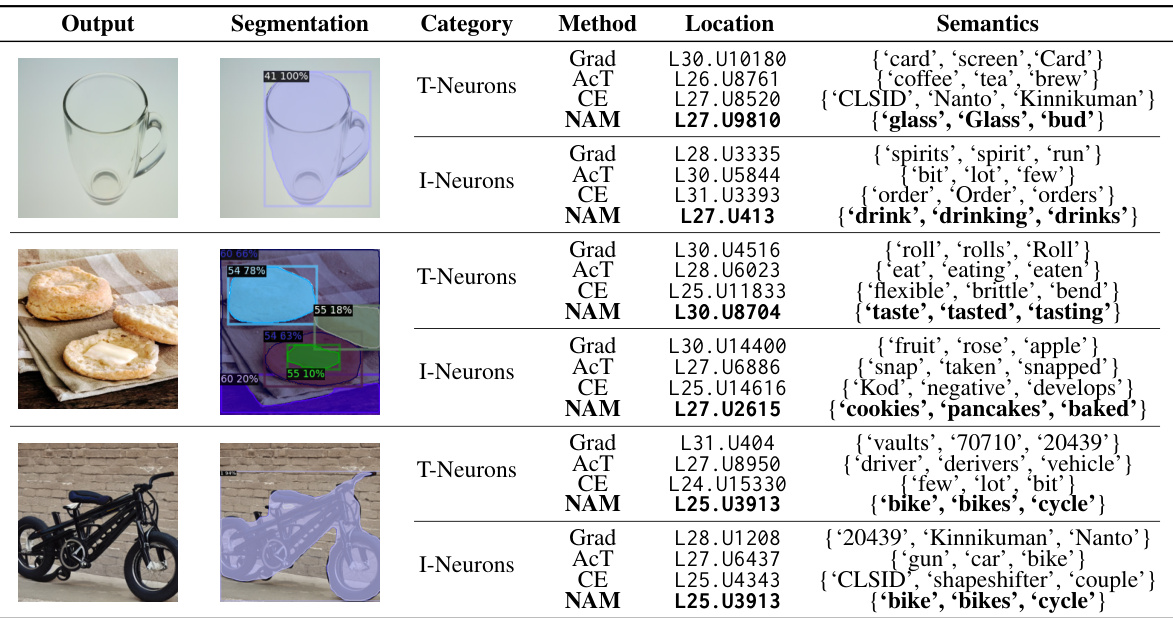
This table presents the top four semantic categories predicted by various neuron attribution methods (Grad, AcT, CE, NAM) for both text (T-neurons) and image (I-neurons) outputs of multi-modal large language models (MLLMs). The location of the most relevant neurons within the model’s layers is also specified. This helps illustrate the modality-specific semantic knowledge learned by different neurons and the effectiveness of the proposed NAM method.

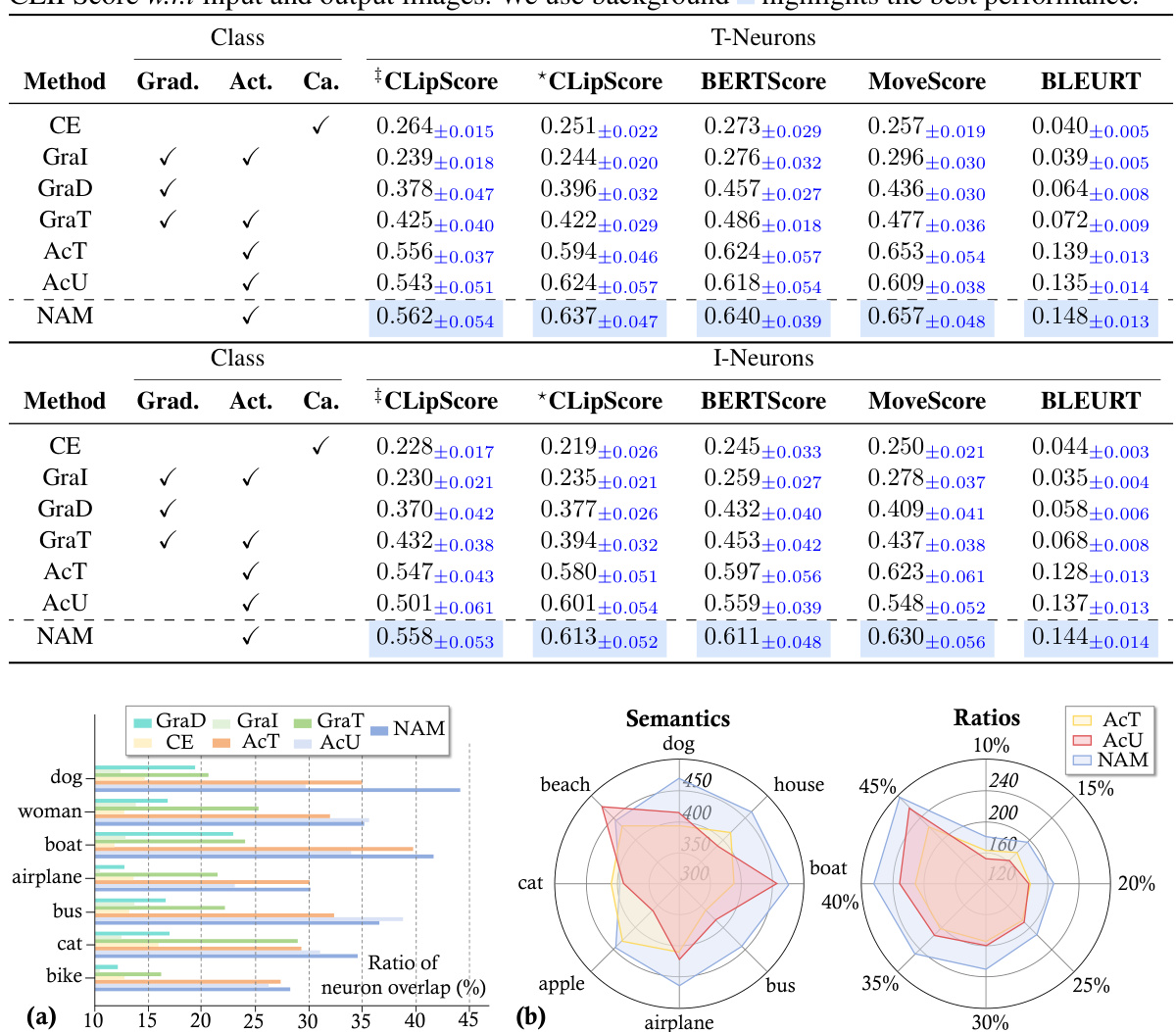
This table presents the quantitative evaluation results of the semantic relevance of neurons identified by different methods (NAM and baselines). The consistency between the semantics of neurons and the input/output images are measured using CLIPScore, BERTScore, MoverScore, and BLEURT. The results show that NAM achieves the highest consistency scores compared to the baselines for both T-neurons and I-neurons across different categories of images and text.
This table presents the top four semantic categories predicted by different neuron attribution methods for both text (T-neurons) and image (I-neurons) outputs of multi-modal large language models (MLLMs). The methods used are Grad, AcT, CE, and NAM. The location of the neurons with the highest attribution scores (layer and neuron index) are provided alongside the predicted semantics.
This table shows the top four semantic categories identified by different neuron attribution methods (Grad, AcT, CE, NAM) for both text (T-neurons) and image (I-neurons) outputs of multi-modal large language models (MLLMs). The location of the neurons (layer and index) are also provided. The results highlight the semantics that are most strongly associated with specific neurons in MLLMs when generating content with specific target semantics (e.g., a horse or a dog).
Full paper#