↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are powerful but demand significant computational resources, hindering their deployment on resource-constrained devices. Existing optimization techniques like pruning and quantization often involve retraining or fine-tuning, which is resource-intensive. The high cost of multiplication operations in LLMs is a major bottleneck.
This paper introduces ShiftAddLLM, a novel method to accelerate pretrained LLMs using post-training shift-and-add reparameterization. This approach replaces computationally expensive multiplications with hardware-friendly shifts and additions, improving efficiency. A multi-objective optimization method minimizes reparameterization errors and an automated bit allocation strategy further optimizes memory and latency. Experiments demonstrate significantly reduced perplexity and latency across various LLMs and tasks, along with substantial memory and energy savings, exceeding the performance of other state-of-the-art quantized LLMs.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and efficient method for accelerating pretrained LLMs, addressing the critical issue of deploying large language models on resource-constrained devices. The post-training shift-and-add reparameterization technique offers a significant improvement over existing quantization methods, opening new avenues for research in LLM optimization and deployment.
Visual Insights#

This figure illustrates the proposed post-training reparameterization method for ShiftAddLLM. It compares the traditional weight-only quantization method with the ShiftAddLLM approach. The traditional method involves dequantization to FP16 before matrix multiplication, while ShiftAddLLM utilizes binary weight matrices and scaling factors. The scaling factors are used with shift operations on the activations. LUTs (lookup tables) are created to speed up the query and add operations with the binary weights and shifted activations. The overall effect is to replace costly multiplications with efficient shift and add operations, resulting in lower latency and memory usage.

This table presents the hardware costs, in terms of energy consumption (in picojoules) and area (in square micrometers), for different arithmetic operations (multiplication, addition, and shift) under a 45nm CMOS technology. The costs are broken down further by data type (FP32, FP16, INT32, INT8) where applicable. Additionally, the cost of a lookup table (LUT) operation for an 8-bit query is provided.
In-depth insights#
Post-Train Quant.#
Post-training quantization (Post-Train Quant.) methods are crucial for deploying large language models (LLMs) on resource-constrained devices. The core challenge lies in balancing accuracy and efficiency, as aggressive quantization can lead to significant performance degradation. Effective Post-Train Quant. techniques focus on minimizing quantization errors. They must account for the unique distribution of weights and activations within LLMs. Strategies to improve accuracy often involve optimizing the quantized weight matrix to better reflect the original weights or employing activation-aware techniques. Furthermore, automated bit allocation strategies, which assign different bit precisions to various layers based on their sensitivity, can optimize memory and latency. A key area of current research is developing post-training methods that avoid the need for retraining or fine-tuning, significantly reducing computational costs. Successful Post-Train Quant. is essential to bridge the gap between the high performance of LLMs and the limitations of real-world hardware.
ShiftAddLLM#
ShiftAddLLM presents a novel approach to accelerating pretrained Large Language Models (LLMs) by replacing computationally expensive multiplications with significantly cheaper shift and add operations. This post-training reparameterization technique avoids the need for retraining or fine-tuning, making it resource-efficient. The method employs binary-coding quantization (BCQ) to represent weights, further enhancing efficiency. A multi-objective optimization strategy minimizes both weight and activation errors to maintain accuracy. Furthermore, a novel automated bit allocation strategy adapts the number of bits used for reparameterization across different layers based on sensitivity analysis, maximizing accuracy while minimizing memory usage and latency. Experimental results on various LLMs demonstrate significant improvements in perplexity and speed, showcasing the effectiveness of ShiftAddLLM in creating efficient, multiplication-free LLMs.
Multi-objective Opt.#
The heading ‘Multi-objective Opt.’ suggests an optimization strategy that considers multiple, potentially conflicting objectives simultaneously. This approach is crucial when dealing with complex systems, like large language models (LLMs), where optimizing a single metric might negatively impact others. The core idea is to find a balance, a Pareto optimal solution, rather than solely focusing on maximizing or minimizing a single objective. In the context of LLMs, this could involve simultaneously minimizing weight quantization error and output activation error. Weight quantization error relates to the accuracy of representing the model weights with fewer bits, while output activation error reflects the impact of quantization on the model’s predictions. A multi-objective approach acknowledges that these two errors are interconnected and that minimizing one excessively might exacerbate the other. The effectiveness of this strategy is likely demonstrated by showing improved model accuracy and efficiency compared to optimizing only one objective at a time. This balance is especially valuable for deploying LLMs on resource-constrained devices, where both reduced memory footprint (achieved by quantization) and preserved accuracy are highly desirable.
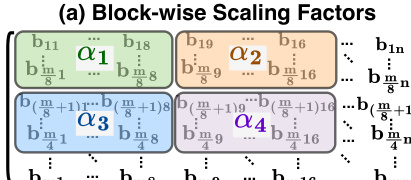
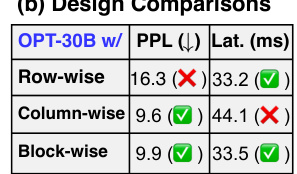
Bit Allocation#
The paper explores bit allocation strategies for optimizing the efficiency and accuracy of its proposed shift-and-add reparameterization technique for large language models (LLMs). A key challenge is that different layers in LLMs exhibit varying sensitivities to quantization. A sensitivity analysis reveals that later layers are more vulnerable to errors introduced by aggressive bit reduction than earlier layers. This observation motivates the use of a mixed bit allocation strategy, which assigns higher precision (more bits) to the more sensitive layers. The authors propose criteria for determining the importance and vulnerability of different layers, formulating an optimization problem to find the optimal distribution of bits. This automated strategy aims to balance accuracy and efficiency by leveraging layer-specific characteristics to achieve optimal model compression and performance. This approach showcases a clear advantage over uniform quantization strategies by reducing accuracy loss while maintaining efficiency gains.
Future Work#
Future research directions stemming from this ShiftAddLLM work could explore several promising avenues. Extending the approach to other model architectures beyond LLMs, such as CNNs and Transformers, is a natural next step, potentially unlocking efficiency gains across a broader range of deep learning applications. Investigating more sophisticated bit allocation strategies that go beyond simple sensitivity analysis, perhaps using reinforcement learning or other advanced optimization techniques, could further improve accuracy-efficiency trade-offs. Exploring alternative reparameterization methods that leverage different hardware-friendly primitives or combinations thereof could lead to even more significant speedups. Finally, a key area for future research is to fully characterize the robustness and limitations of the ShiftAddLLM approach across different tasks and datasets, providing a clearer understanding of its strengths and weaknesses. Additional analysis of the interaction between quantization, reparameterization, and various model architectures would help to guide future development of multiplication-less deep learning models.
More visual insights#
More on figures
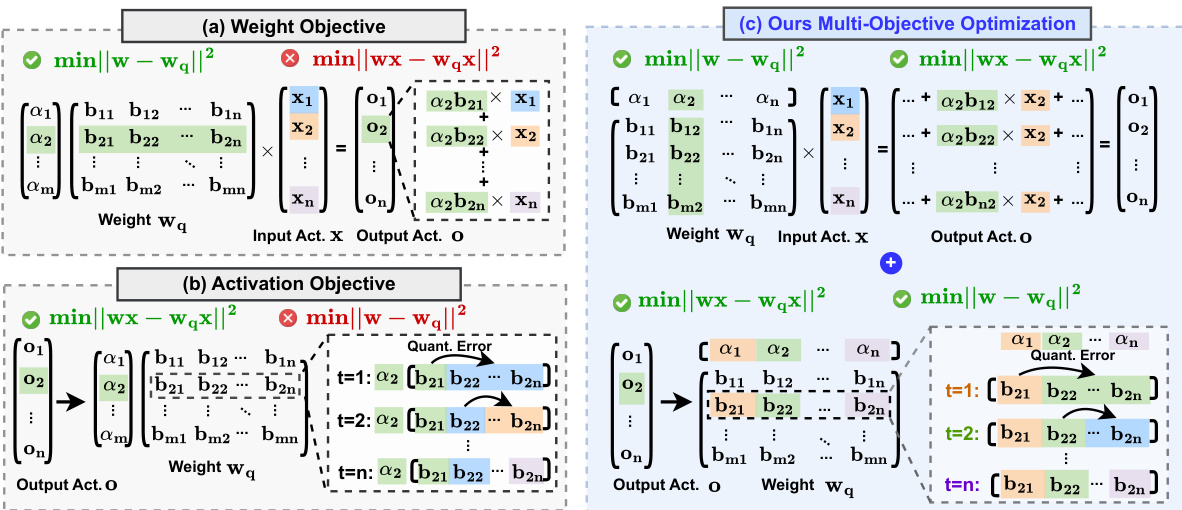
This figure illustrates the proposed post-training reparameterization method for ShiftAddLLM. It compares three approaches: (a) Previous weight-only quantization, which de-quantizes weights to FP16 before multiplication with activations; (b) the proposed ShiftAddLLM method, which directly uses a quantized weight format and replaces multiplications with shift-and-add operations; (c) FP16 shift using multiplication, showing the shift operation using FP16 multiplication; (d) Construct LUTs and Query&Add, illustrating the creation of LUTs (lookup tables) and the query and add operations for efficient computation. This approach reduces the reliance on costly multiplications, leading to improved efficiency in the model.

This figure shows the sensitivity analysis of different layers and blocks in LLMs to shift-and-add reparameterization. The left chart shows the quantization error per parameter for each block in OPT-1.3B model at 2, 3, and 4 bits. The right chart shows the quantization error for different layer types (K, V, Q, Out, FC1, FC2) within a block, also for 2, 3, and 4 bits. The results demonstrate that later blocks and Q/K layers are more sensitive to reparameterization, indicating varying sensitivities across different layers and blocks which motivate the use of a mixed bit allocation strategy.
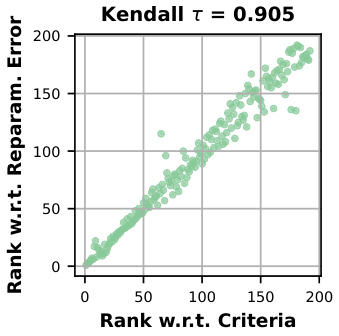
This figure shows a scatter plot comparing the ranking of linear layers in a neural network based on two different criteria: a proposed criterion for estimating the importance of linear weights and the actual reparameterization error. The strong positive correlation (Kendall τ = 0.905) indicates that the proposed criterion effectively estimates the difficulty of reparameterizing linear layers and its potential impact on accuracy.

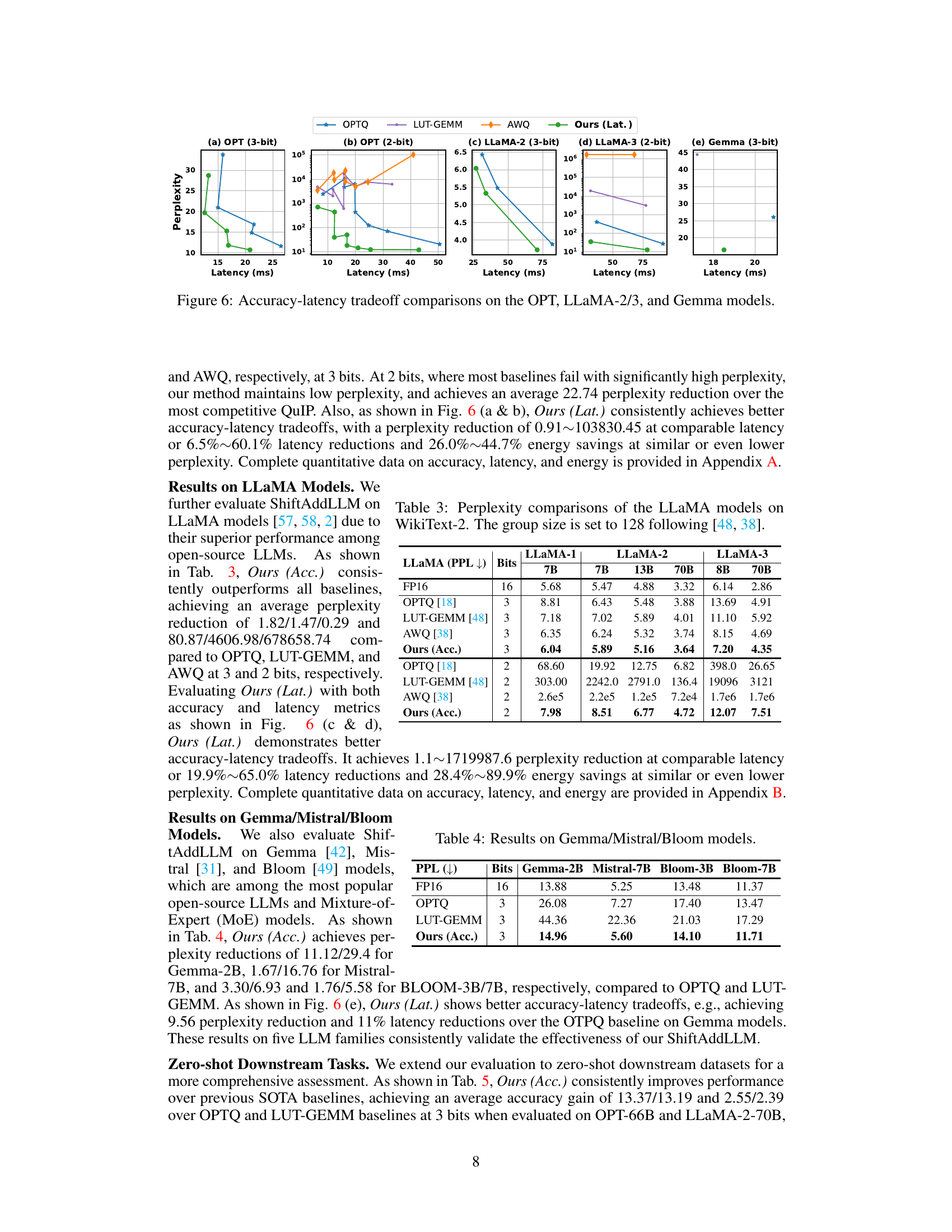
This figure shows the accuracy-latency trade-off comparisons for different LLMs (OPT, LLAMA-2/3, and Gemma) at different bit precisions (3-bit and 2-bit). Each sub-figure presents a comparison of perplexity (y-axis) versus latency (x-axis) for the different LLMs, showing the performance of ShiftAddLLM against state-of-the-art baselines (OPTQ, LUT-GEMM, AWQ). The results demonstrate ShiftAddLLM’s effectiveness in achieving lower perplexity at comparable or lower latency compared to existing methods.

This figure shows the sensitivity analysis of different layers and blocks in LLMs to shift-and-add reparameterization. It illustrates that later blocks tend to incur more quantization or reparameterization errors and that Query/Key layers within each block are generally more sensitive to reparameterization than other linear layers. This varying sensitivity across layers and blocks motivates the use of a mixed bit allocation strategy to optimize the efficiency and accuracy of the ShiftAddLLM.

This figure illustrates the proposed post-training reparameterization method for ShiftAddLLM. It compares three approaches: (a) Previous weight-only quantization, which uses 4-bit weights and FP16 activations and requires de-quantization; (b) the proposed ShiftAddLLM, which uses lower-bit weights and FP16 activations and replaces multiplication with shift-and-add operations; (c) FP16 shift using multiplication, showing how the shift-and-add approach mimics the original multiplication operation; and (d) construction of LUTs and the query-and-add operation in ShiftAddLLM, showing how the shift and add operations and LUTs are used to reduce the computational cost.

This figure shows the accuracy-latency trade-off for different LLMs (OPT, LLaMA-2, LLaMA-3, and Gemma) using 2-bit and 3-bit quantization. The x-axis represents latency (in milliseconds), and the y-axis represents perplexity, a measure of model performance. Each subfigure presents a comparison for a specific LLM and bit precision. The goal is to illustrate the effectiveness of ShiftAddLLM in achieving lower perplexity at comparable or lower latency than other state-of-the-art quantized LLMs.
More on tables

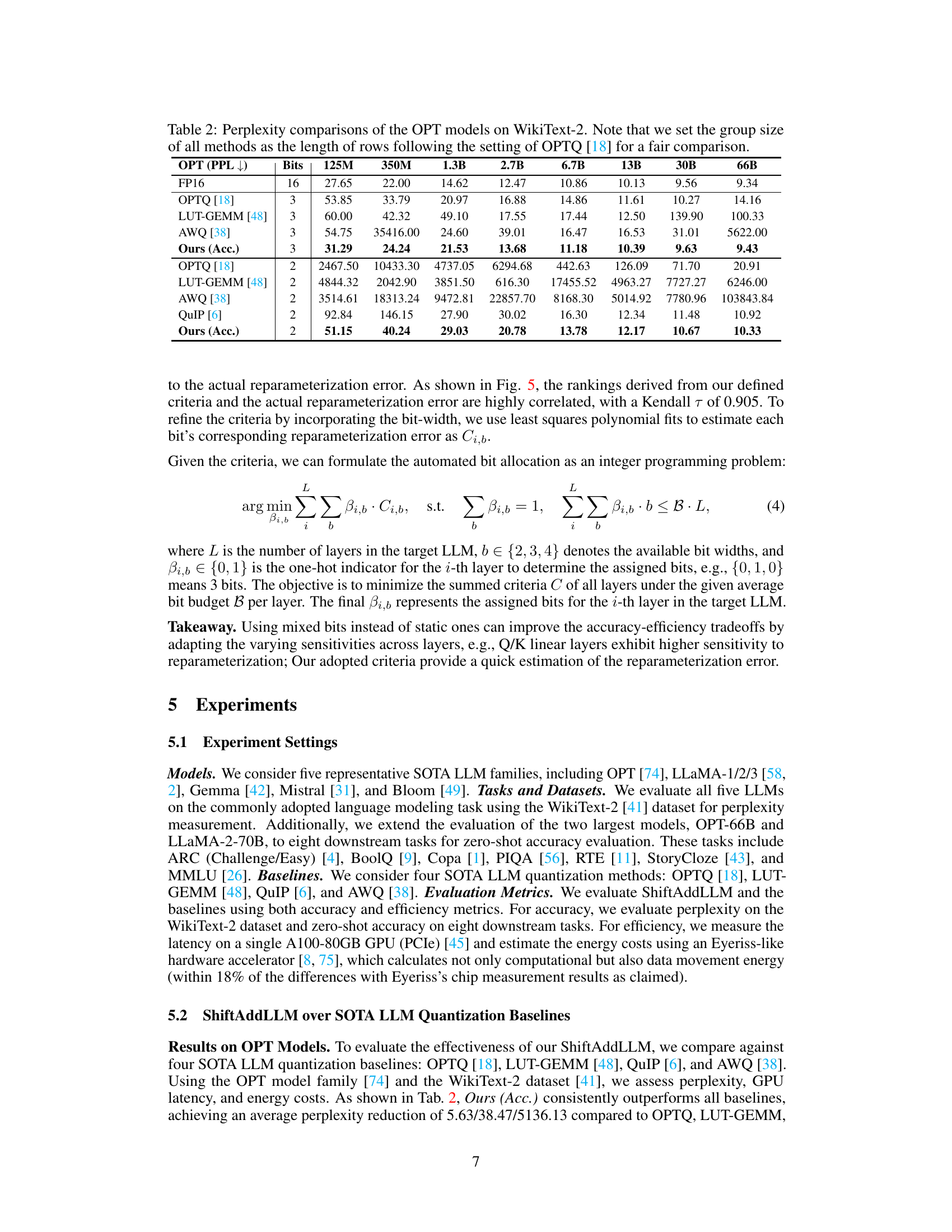
This table compares the perplexity scores achieved by different methods (FP16, OPTQ, LUT-GEMM, AWQ, and ShiftAddLLM) on the WikiText-2 dataset using various OPT models (125M, 350M, 1.3B, 2.7B, 6.7B, 13B, 30B, 66B parameters). The comparison is made for different bit precisions (3-bit and 2-bit). The table shows the superior performance of the proposed ShiftAddLLM method, especially at lower bit precisions where other methods struggle.
This table presents a comparison of perplexity scores achieved by different methods (FP16, OPTQ, LUT-GEMM, AWQ, and ShiftAddLLM) on the WikiText-2 dataset using OPT models of varying sizes (125M, 350M, 1.3B, 2.7B, 6.7B, 13B, 30B, 66B parameters). The comparison is done across different bit precisions (16-bit, 3-bit, and 2-bit) for each method. The group size for all methods is consistent with the setting used in the OPTQ paper for a fair evaluation.
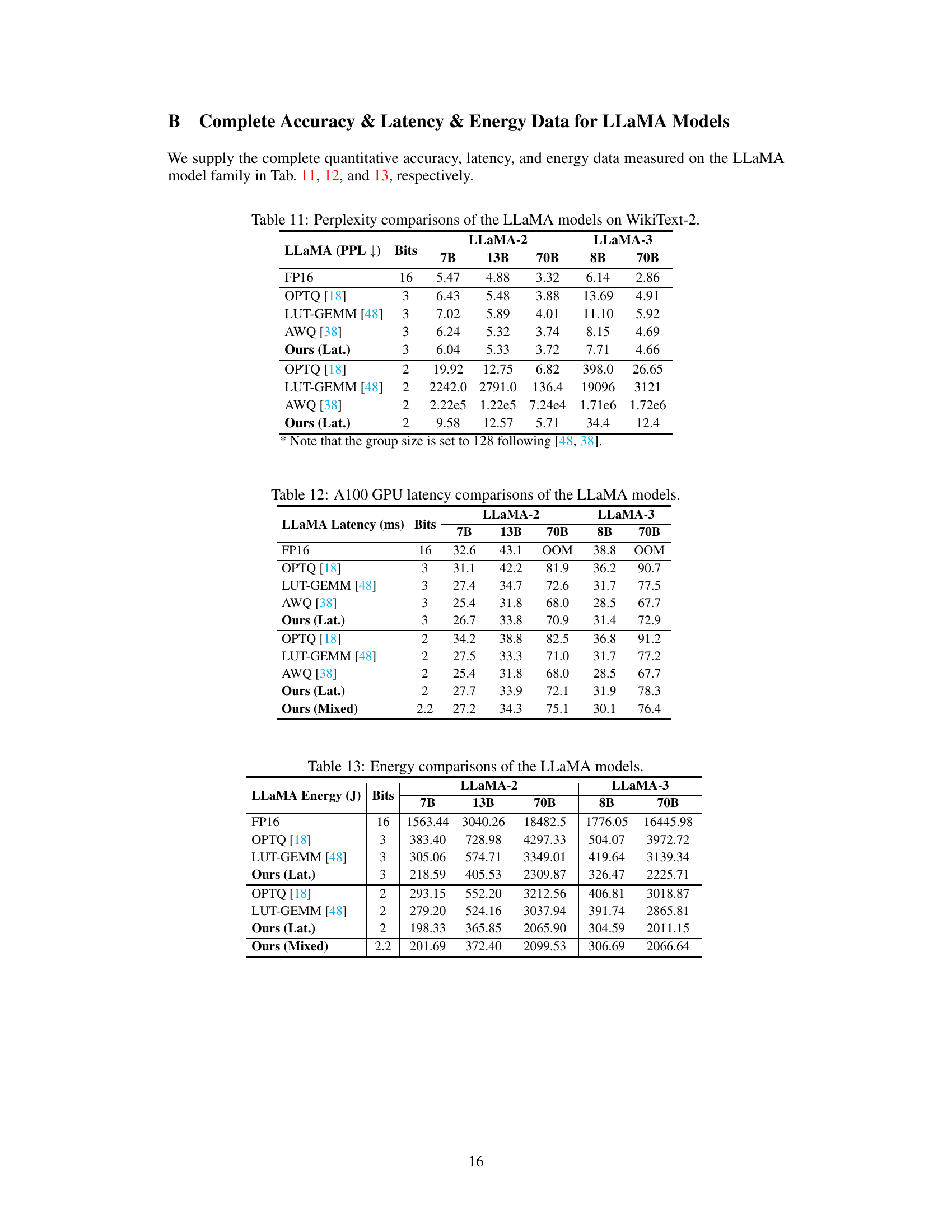
This table compares the perplexity scores achieved by different methods (OPTQ, LUT-GEMM, AWQ, and ShiftAddLLM) on the WikiText-2 benchmark using three different sizes of LLaMA language models (7B, 13B, and 70B parameters). The group size, a parameter in the quantization process, was set to 128, matching the settings of prior work. The table highlights the perplexity results for each method and model size, allowing for a comparison of the effectiveness of different quantization techniques.

This table presents the perplexity scores achieved by different models on the WikiText-2 dataset. It compares the performance of the original FP16 model with several quantization methods (OPTQ, LUT-GEMM, AWQ, and ShiftAddLLM) at both 3-bit and 2-bit precisions. Lower perplexity indicates better performance.
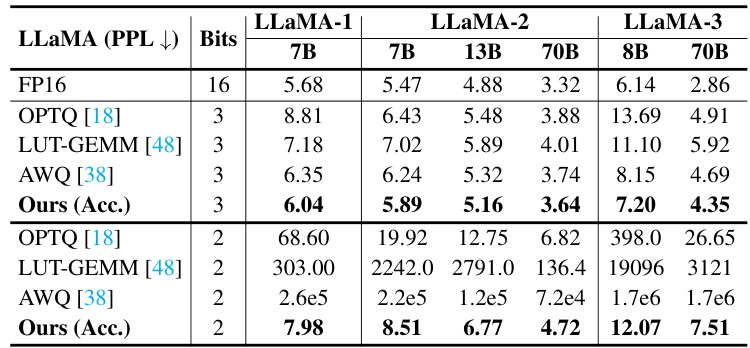
This table compares the perplexity scores achieved by different methods (OPTQ, LUT-GEMM, AWQ, and ShiftAddLLM) on the WikiText-2 benchmark using LLaMA language models of various sizes (7B, 13B, 70B). The group size is kept constant at 128 to ensure a fair comparison. The table shows perplexity results for 3-bit and 2-bit quantization levels.

This table presents the perplexity results for three different open-source LLMs (Gemma, Mistral, and Bloom) using different quantization methods (FP16, OPTQ, LUT-GEMM, and ShiftAddLLM). It shows the perplexity scores at 3-bit precision, comparing the proposed ShiftAddLLM against existing state-of-the-art quantization techniques. The goal is to demonstrate the effectiveness of ShiftAddLLM across various LLMs.
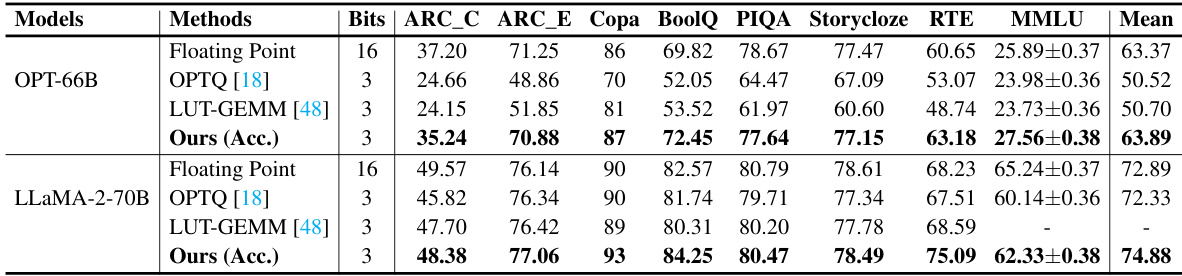
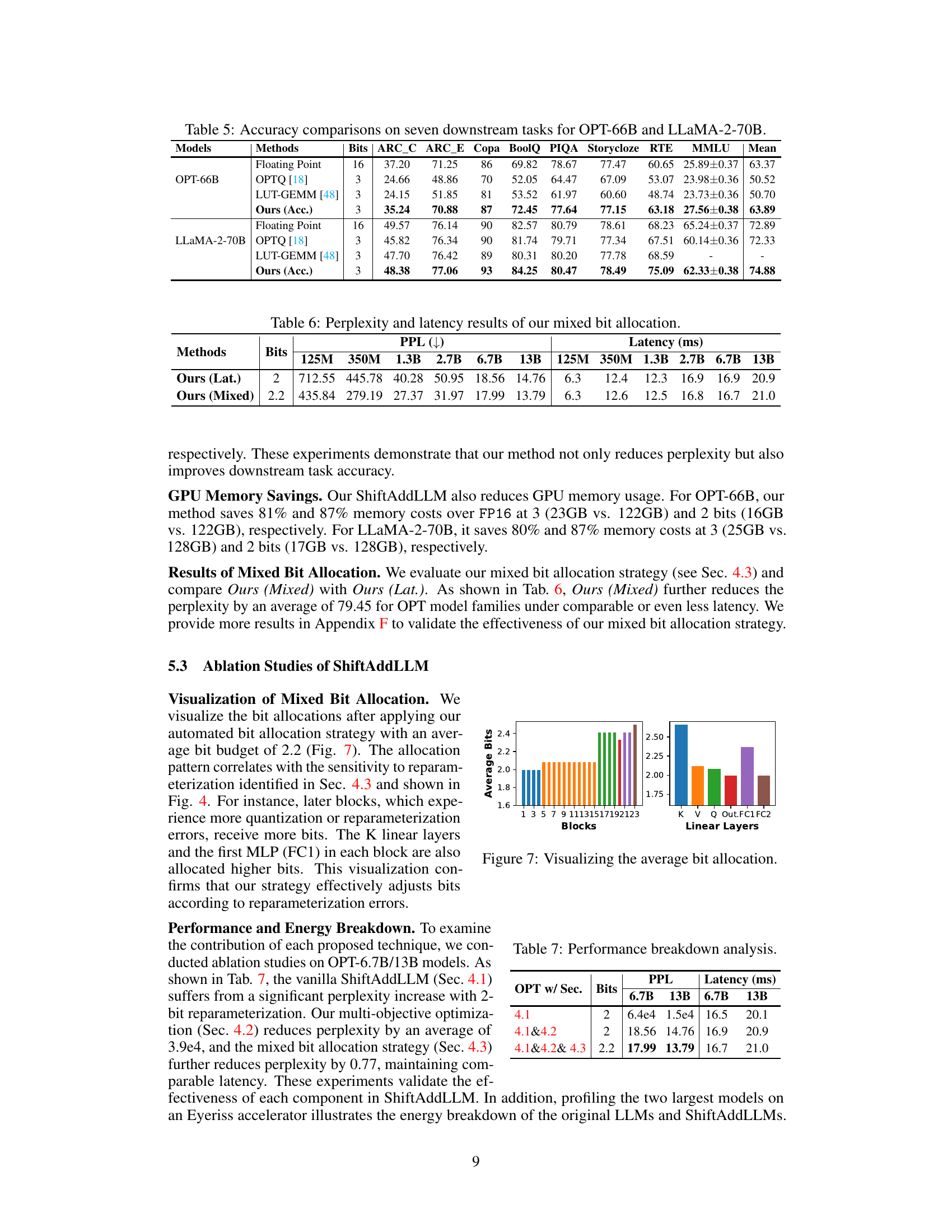
This table presents a comparison of the accuracy achieved by different methods (Floating Point, OPTQ [18], LUT-GEMM [48], and Ours (Acc.)) on seven downstream tasks for two large language models: OPT-66B and LLaMA-2-70B. The accuracy is measured using several metrics (ARC_C, ARC_E, Copa, BoolQ, PIQA, Storycloze, RTE, MMLU), and the mean accuracy across all tasks is also reported. The table shows the results for 3-bit quantized models and compares them against the floating-point baseline, allowing for evaluation of the accuracy trade-off resulting from the quantization techniques.

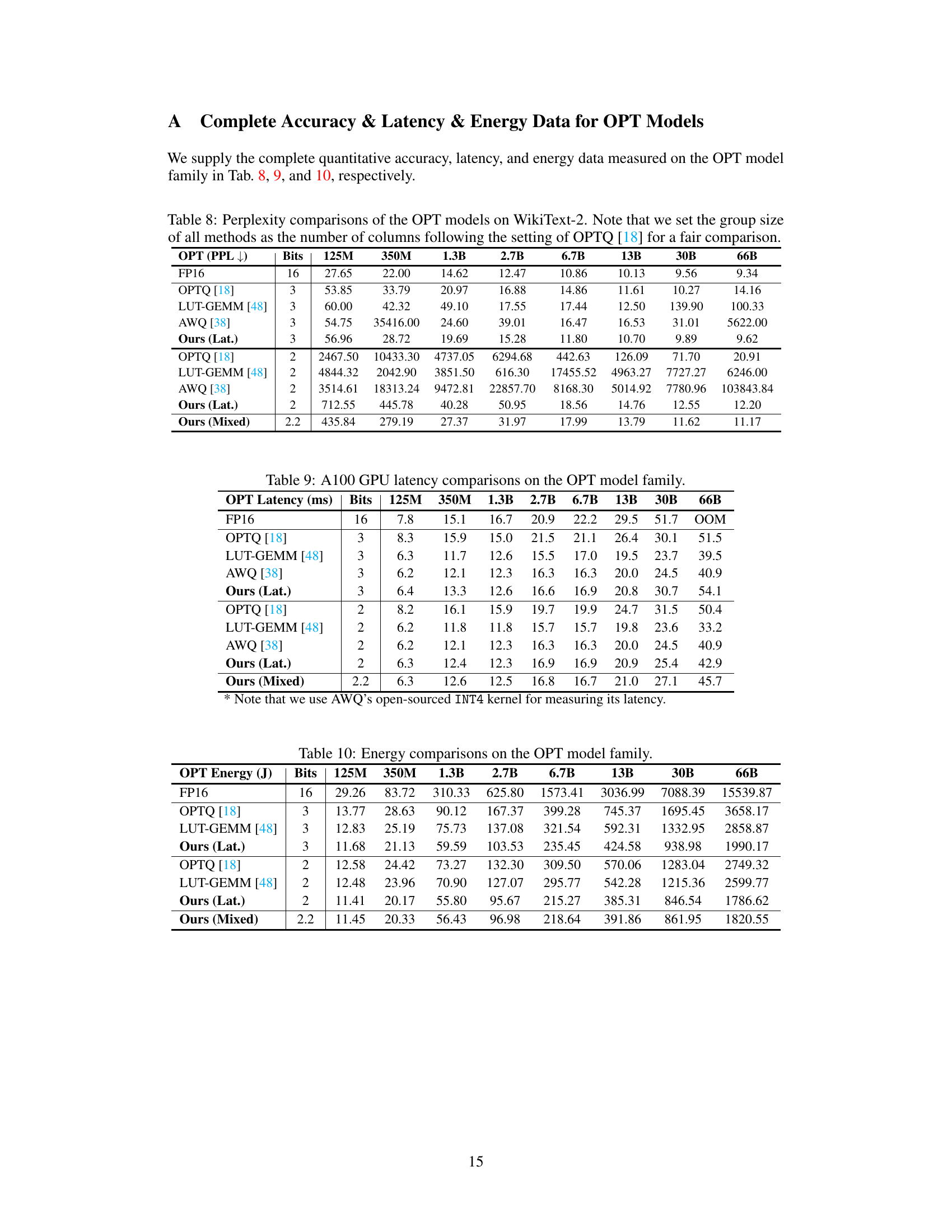
This table presents the latency (in milliseconds) measured on an A100 GPU for different sizes of OPT models (125M, 350M, 1.3B, 2.7B, 6.7B, 13B, 30B, 66B parameters) using various methods: FP16 (full precision), OPTQ, LUT-GEMM, AWQ, Ours (Lat.), and Ours (Mixed) at different bit-widths (2 and 3 bits). The results show the latency trade-offs for different model sizes and quantization approaches. Ours (Lat.) refers to the ShiftAddLLM method optimized for low latency, while Ours (Mixed) denotes the optimized mixed bit allocation strategy.
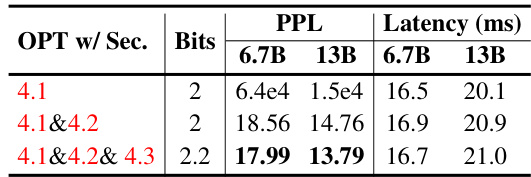
This table presents the results of ablation studies on OPT models (6.7B and 13B parameters) to analyze the impact of each component in ShiftAddLLM. It shows the perplexity and latency for three scenarios: only using the post-training shift-and-add reparameterization (Sec 4.1), incorporating the multi-objective optimization (Sec 4.2), and finally adding the automated bit allocation (Sec 4.3). This allows for a quantitative assessment of how each technique contributes to the overall performance and efficiency of ShiftAddLLM.
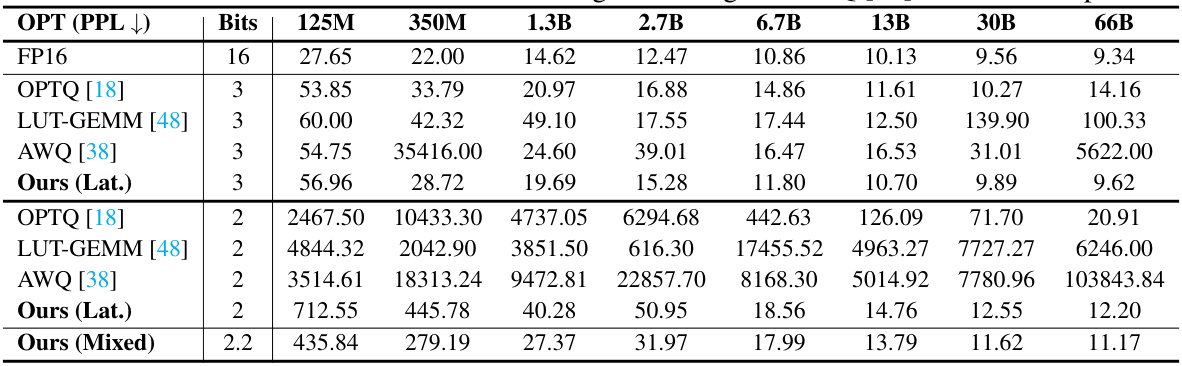
This table presents the perplexity scores achieved by different quantization methods (OPTQ, LUT-GEMM, AWQ, and ShiftAddLLM) on the WikiText-2 dataset using various bit-widths (3-bit, 2-bit). It compares the perplexity of these methods against the full-precision (FP16) results for different sizes of the OPT language model. Lower perplexity indicates better performance.
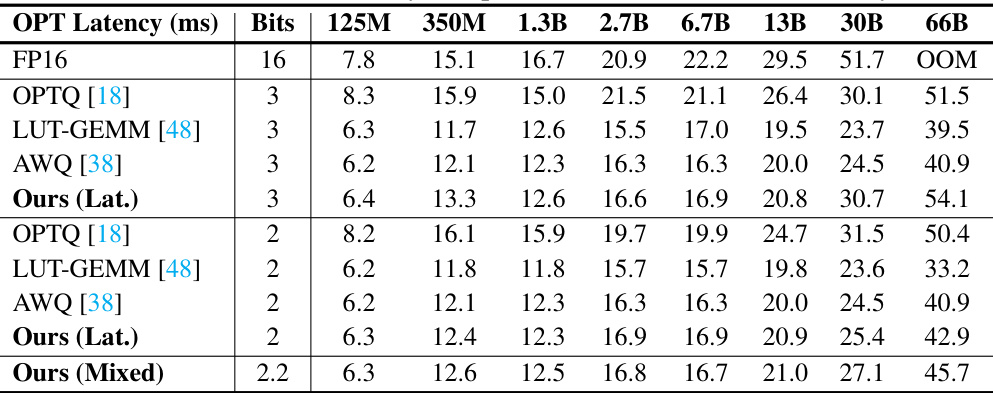
This table presents the latency (in milliseconds) measured on an NVIDIA A100 GPU for different OPT models (125M to 66B parameters) using various quantization methods (FP16, OPTQ, LUT-GEMM, AWQ, Ours (Lat.), and Ours (Mixed)). The latency is shown for different bit precisions (16-bit, 3-bit, 2-bit, and 2.2-bit) and highlights the performance tradeoffs between accuracy and latency. It’s used to demonstrate the speed improvements of ShiftAddLLM over baseline quantization techniques.

This table presents a comparison of energy consumption (in Joules) for different model sizes of the OPT family (125M, 350M, 1.3B, 2.7B, 6.7B, 13B, 30B, and 66B parameters) across various quantization methods: FP16 (full precision), OPTQ [18], LUT-GEMM [48], Ours (Lat.) at 3 bits, OPTQ [18], LUT-GEMM [48], Ours (Lat.) at 2 bits, and Ours (Mixed) at 2.2 bits. It highlights the energy savings achieved by the proposed ShiftAddLLM method compared to existing state-of-the-art quantization techniques. The energy is estimated using an Eyeriss-like hardware accelerator.

This table compares the perplexity scores achieved by different quantization methods (OPTQ, LUT-GEMM, AWQ, and ShiftAddLLM) on various LLaMA models (7B, 13B, and 70B parameters) using the WikiText-2 dataset. The results show the perplexity at 3-bit and 2-bit quantization levels, providing a comparison of accuracy across different methods. The group size is set to 128 following the settings used in prior works for a fair comparison.

This table presents the latency results measured on an A100 GPU for various LLaMA models at different bit precisions. It compares the performance of the proposed ShiftAddLLM against several state-of-the-art quantization methods (OPTQ, LUT-GEMM, AWQ). The latency is presented in milliseconds (ms), and the bit precision is specified for each configuration. The table shows latency across several model sizes (7B, 13B, 70B parameters). The results illustrate the speed improvements of ShiftAddLLM compared to the baseline methods.
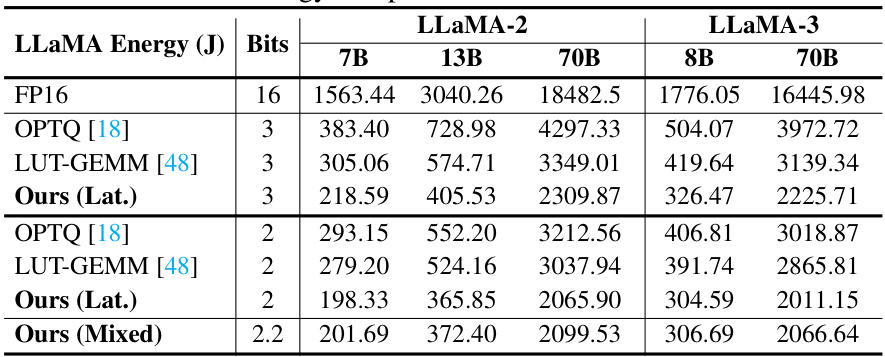
This table presents a comparison of energy consumption (in Joules) for different LLaMA models (7B, 13B, 70B parameters) and configurations using various quantization techniques (FP16, OPTQ, LUT-GEMM, ShiftAddLLM). It shows the energy efficiency improvements achieved by ShiftAddLLM at 3-bit and 2-bit precision, and its mixed-bit allocation strategy.
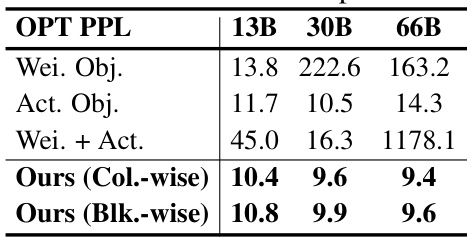
This table presents the results of ablation studies conducted to evaluate the effectiveness of different optimization objectives used in the ShiftAddLLM model. The objectives compared include using only the weight objective, only the activation objective, a combination of both, and the proposed multi-objective optimization approach used in ShiftAddLLM. The evaluation metric is perplexity on the OPT model for three different sizes (13B, 30B, and 66B parameters). The results show the superiority of the multi-objective optimization approach in terms of achieving lower perplexity.
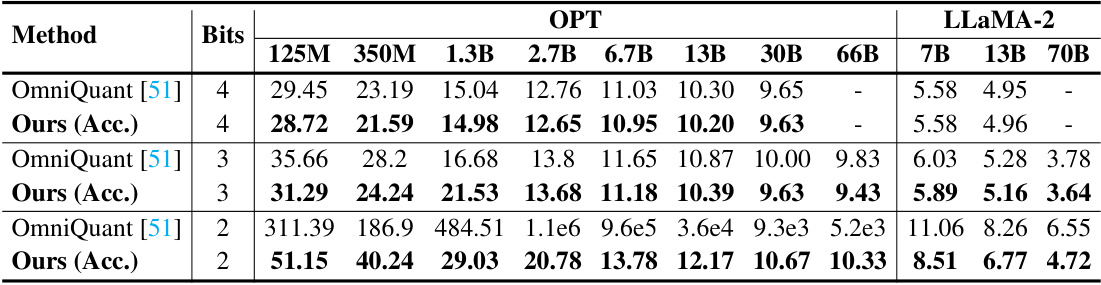
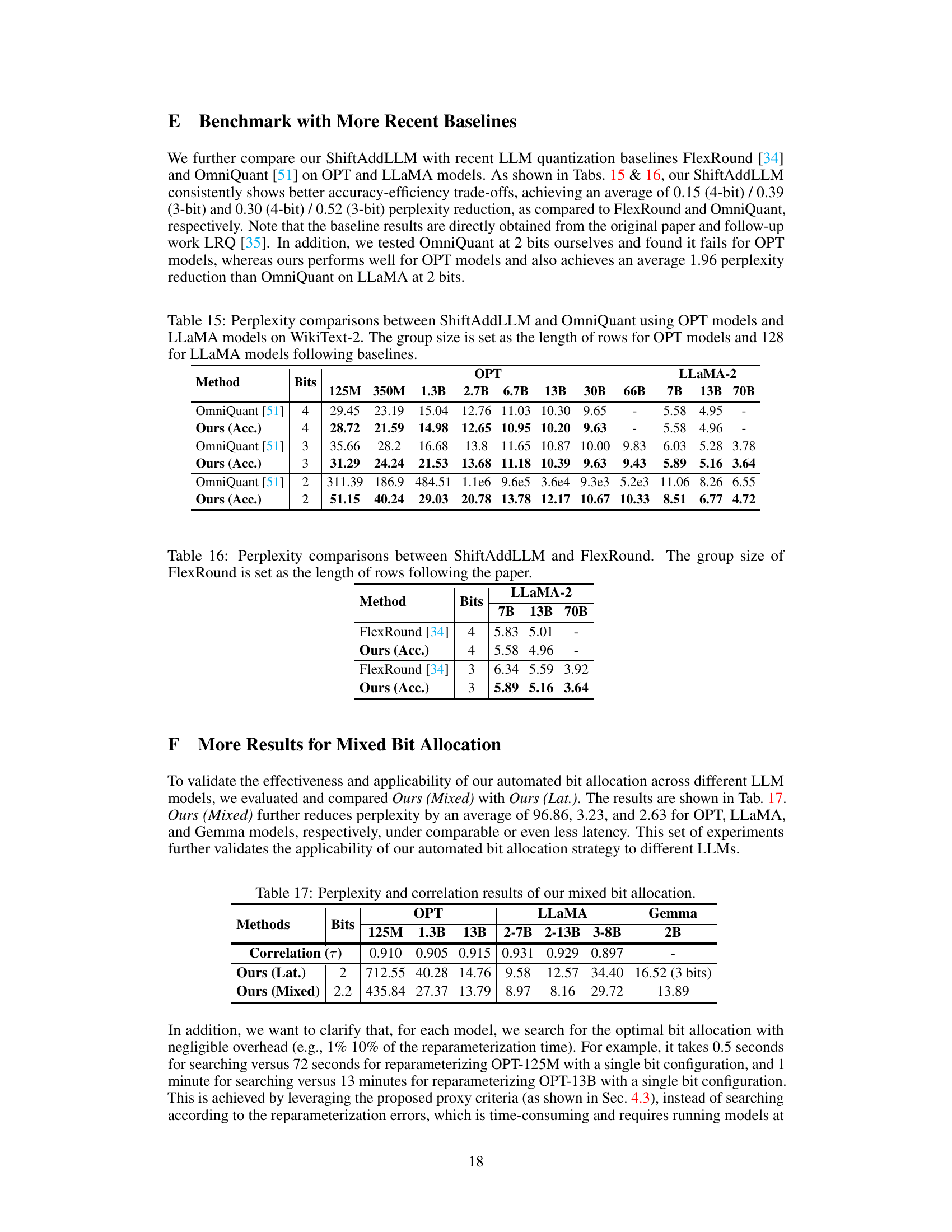
This table compares the perplexity results of ShiftAddLLM and OmniQuant on both OPT and LLaMA models for different bit-widths (4, 3, and 2 bits). It showcases the perplexity achieved on the WikiText-2 dataset for different model sizes within each family. The group size is adjusted to 128 for LLaMA models to maintain consistency with existing baselines.

This table compares the perplexity achieved by ShiftAddLLM and OmniQuant on the WikiText-2 dataset using OPT and LLaMA models with different bit configurations. It shows the perplexity scores for various model sizes (125M, 350M, 1.3B, 2.7B, 6.7B, 13B, 30B, 66B for OPT; 7B, 13B, 70B for LLaMA) and bit depths (4-bit and 3-bit). The group size used for comparison is consistent with the baselines.
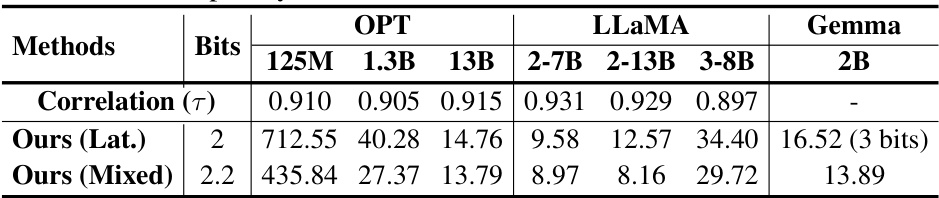
This table presents the perplexity results for different LLM models (OPT, LLaMA, and Gemma) using two bit allocation strategies: Ours (Lat.) and Ours (Mixed). The correlation (τ) values show the high correlation between the proxy criteria and the actual reparameterization error. Ours (Mixed) generally shows lower perplexity than Ours (Lat.) across various model sizes, suggesting the efficacy of the mixed bit allocation strategy.

This table compares the perplexity scores achieved by different methods (OPTQ, LUT-GEMM, AWQ, and ShiftAddLLM) on the WikiText-2 dataset using 4-bit quantization. It shows the perplexity for various sizes of OPT and LLaMA language models. The group size is set to the number of rows for OPT models and 128 for LLaMA models.

This table compares the performance of MSFP and ShiftAddLLM in terms of KL divergence and quantization error at different bit-widths (4, 3, and 2 bits). The results show that ShiftAddLLM consistently outperforms MSFP across all bit-widths, demonstrating lower KL divergence and quantization error.
Full paper#