↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multimodal Large Language Models (MLLMs) currently perceive visual information by aligning visual features with the input space of LLMs and concatenating visual tokens with text tokens. This approach leads to high computational costs due to the extended input sequence. Existing methods attempt to reduce this by various techniques such as vocabulary expansion and using different vision encoders. However, these solutions still maintain the inefficient input space alignment paradigm.
To tackle this issue, the paper proposes a novel parameter space alignment paradigm called VLORA. Instead of aligning visual features with the input space, VLORA merges visual information as perceptual weights directly into the LLM’s weights. This approach significantly reduces the input sequence length, leading to substantial improvements in computational efficiency during both training and inference. Experiments demonstrate VLORA’s comparable performance to state-of-the-art MLLMs, with a significant decrease in computation, paving the way for more efficient and resource-friendly multimodal models.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the computational inefficiency of existing multimodal large language models (MLLMs) by proposing a novel parameter space alignment paradigm. This paradigm reduces computational costs significantly by representing visual information as model weights instead of input tokens, thus making MLLMs more efficient and scalable for real-world applications. It opens avenues for developing more efficient and resource-friendly MLLMs, impacting research in various related fields.
Visual Insights#

This figure compares the traditional input space alignment method with the proposed VLORA method. In the input space alignment method, visual features are aligned with the input space of the LLM and concatenated with text tokens to form a unified input sequence. In the VLORA method, visual features are converted into perceptual weights, which are merged with the LLM’s weights. This reduces the input sequence length and improves computational efficiency.
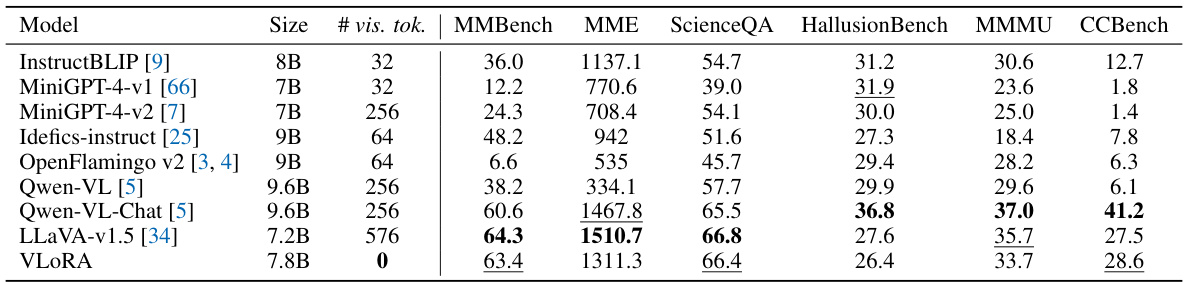
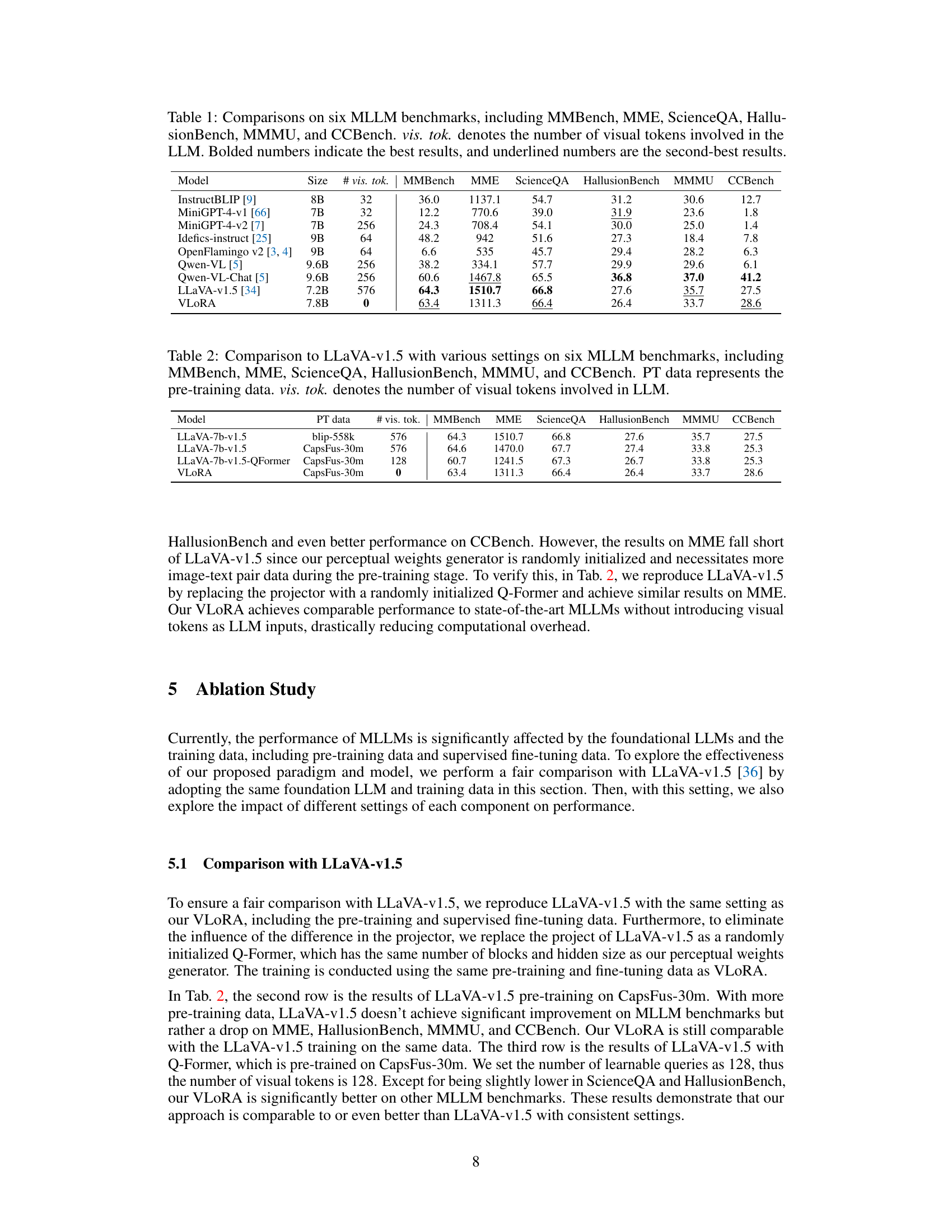
This table compares the performance of VLORA against other state-of-the-art Multimodal Large Language Models (MLLMs) across six different benchmark datasets. The benchmarks assess various aspects of vision-language capabilities. The table shows each model’s size (in billions of parameters), the number of visual tokens used as input (vis. tok.), and its performance score on each benchmark. The best and second-best results are highlighted. Noteworthy is VLORA’s performance with zero visual tokens, highlighting its efficiency.
In-depth insights#
VLORA: A New Paradigm#
VLORA proposes a novel parameter-space alignment paradigm for multimodal large language models (MLLMs), shifting away from the conventional input-space alignment. Instead of aligning visual features with the LLM’s input space and concatenating visual tokens with text, VLORA represents visual information as model weights. This is achieved by using a vision encoder to extract visual features, which are then converted into perceptual weights by a perceptual weights generator. These perceptual weights, designed with a low-rank property similar to LoRA, are directly merged with the LLM’s weights. This innovative approach drastically reduces computational costs by eliminating the need for visual tokens, leading to improved efficiency in both training and inference. The effectiveness of VLORA is demonstrated by achieving comparable performance to state-of-the-art MLLMs on various benchmarks while significantly reducing computational burden. This paradigm shift offers a promising direction for developing more efficient and scalable MLLMs.
Weight-Space Alignment#
Weight-space alignment presents a novel approach to multimodal learning by integrating visual information directly into the model’s weight parameters, rather than the input space. This avoids the need for extra visual tokens, which dramatically reduces computational costs. Instead of aligning visual features to the input embedding space, the method uses a vision encoder to convert image features into a set of perceptual weights. These weights are then added directly to the LLM’s existing weights. The process is made efficient by leveraging a low-rank property, enabling the generation of compact, efficient adjustments to the LLM weights. This innovative paradigm offers significant advantages over input space methods commonly used in multimodal large language models (MLLMs), achieving comparable performance at a fraction of the computational cost. The effectiveness of this strategy is supported by empirical results, demonstrating the potential to significantly improve the scalability and efficiency of future MLLMs.
Perceptual Weight Gen#
The concept of “Perceptual Weight Gen” introduces a novel approach to multimodal learning by representing visual information as model weights, rather than as input tokens. This parameter-space alignment paradigm offers a significant advantage over traditional input-space alignment methods by avoiding the computational burden associated with concatenating lengthy visual token sequences. The “generator” component is crucial; it converts visual features (extracted via an encoder) into a low-rank matrix of perceptual weights. This low-rank property, similar to LoRA, ensures efficiency and feasibility during both training and inference. Efficiency gains stem from the elimination of visual tokens in the LLM input sequence, reducing computational costs for attention mechanisms. The design of the perceptual weights generator itself presents interesting possibilities, including the exploration of different architectural choices, like decoder-only architectures with cross-attention, to effectively map visual features to LLM weights. The effectiveness of this method hinges on how well the generator learns to capture relevant visual information in a compact and suitable format for merging with the model’s existing parameters. Further research could investigate the optimal rank of the perceptual weights, the impact of different vision encoders, and potentially the application of this method beyond visual perception.
Efficiency Analysis#
An efficiency analysis of a large language model (LLM) for visual perception would meticulously examine the computational cost at various stages. Training efficiency would assess the time taken to train the model, comparing different architectures, training data sizes, and optimization techniques. Key metrics include training time, GPU memory usage, and the number of parameters. Inference efficiency is crucial and would analyze the latency (time taken to process an input image) for the LLM. It would evaluate how the LLM’s design choices impact inference speed. Furthermore, it would delve into parameter efficiency by measuring the number of parameters required to achieve a specific performance level. This helps to understand the trade-offs between model size and accuracy. A comparison to state-of-the-art methods is essential to gauge the overall efficiency improvements. Finally, the analysis would consider the scalability of the model, exploring how its computational cost varies with increases in the size and resolution of input images and the complexity of tasks. Real-world applications need efficient LLMs, thus highlighting practical implications is crucial.
Future of MLLMs#
The future of Multimodal Large Language Models (MLLMs) is brimming with potential. Efficiency gains will be crucial, moving beyond current input space alignment limitations. Parameter-efficient fine-tuning methods, like those explored in the paper, will likely become standard, reducing computational costs for both training and inference. Visual perception advancements are needed to handle high-resolution images and complex scenes more effectively, perhaps by integrating advanced vision encoders or exploring alternative paradigms to input space alignment. Improved alignment of visual and textual information will be key to enhanced performance on vision-language tasks. Ultimately, the goal is to achieve more generalized and robust MLLMs capable of handling diverse real-world tasks and challenges. Future research will likely focus on improving the efficiency and generalization abilities of MLLMs while exploring ways to enhance their comprehension of visual input and its integration with language understanding.
More visual insights#
More on figures

This figure compares two different approaches for incorporating visual information into large language models (LLMs): input space alignment and parameter space alignment. Input space alignment involves aligning visual features with the LLM’s input space, creating visual tokens that are concatenated with text tokens before being fed to the LLM. This method, while effective, can be computationally expensive due to the increased input sequence length. In contrast, the parameter space alignment method, used by the proposed VLORA model, merges visual information, represented as perceptual weights generated from visual features, directly into the LLM’s weights. This improves efficiency by avoiding the addition of visual tokens to the input sequence. The figure visually represents these two paradigms, highlighting the difference in how visual information is processed and integrated with the LLM.
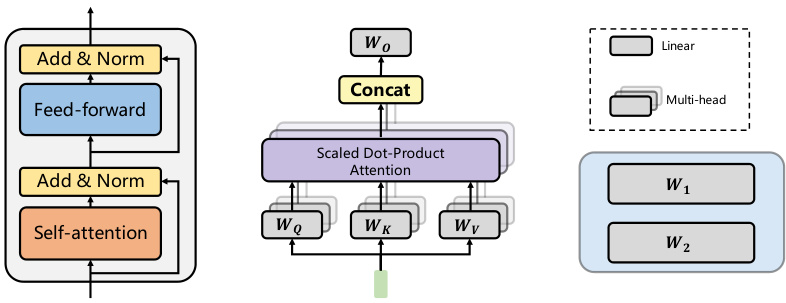
This figure shows a detailed breakdown of the Large Language Model (LLM) decoder block architecture. It’s comprised of three sub-figures: (a) A high-level overview of the decoder block, illustrating its modular components such as the self-attention and feed-forward networks. (b) A zoomed-in view of the multi-head self-attention module within the decoder block, highlighting its four weight matrices: WQ, WK, WV, and Wo. These matrices are crucial for the attention mechanism to perform calculations. (c) A detailed illustration of the feed-forward network, indicating its two weight matrices: W₁ and W₂. These are crucial for sequential processing in the network. In essence, this figure details the internal structure and weight parameters of the LLM’s decoder block.
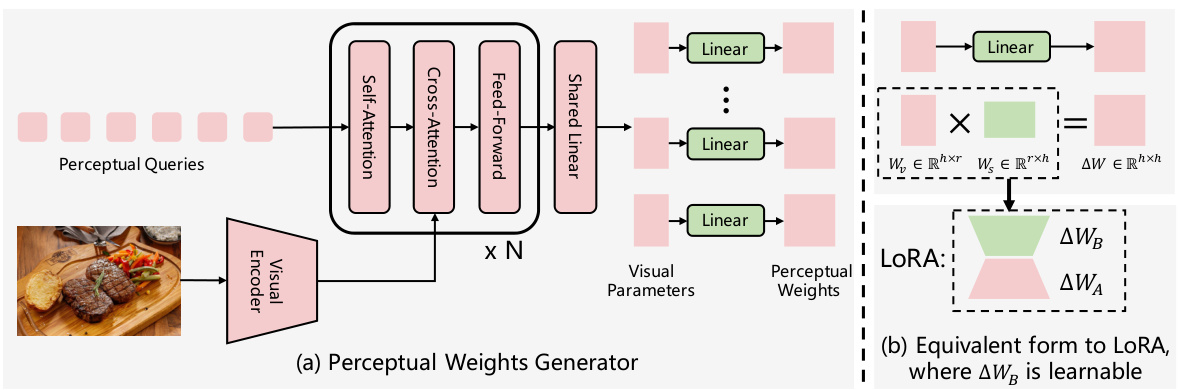
This figure illustrates the architecture of the perceptual weights generator, a key component of the proposed VLORA model. The generator takes visual features as input and produces perceptual weights (ΔW) that are added to the LLM’s weights. The figure shows a decoder-only architecture with cross-attention layers processing perceptual queries and visual features to generate these low-rank perceptual weights, exhibiting a structure similar to LoRA. The right part shows that the generated perceptual weights are equivalent to the LoRA weight.

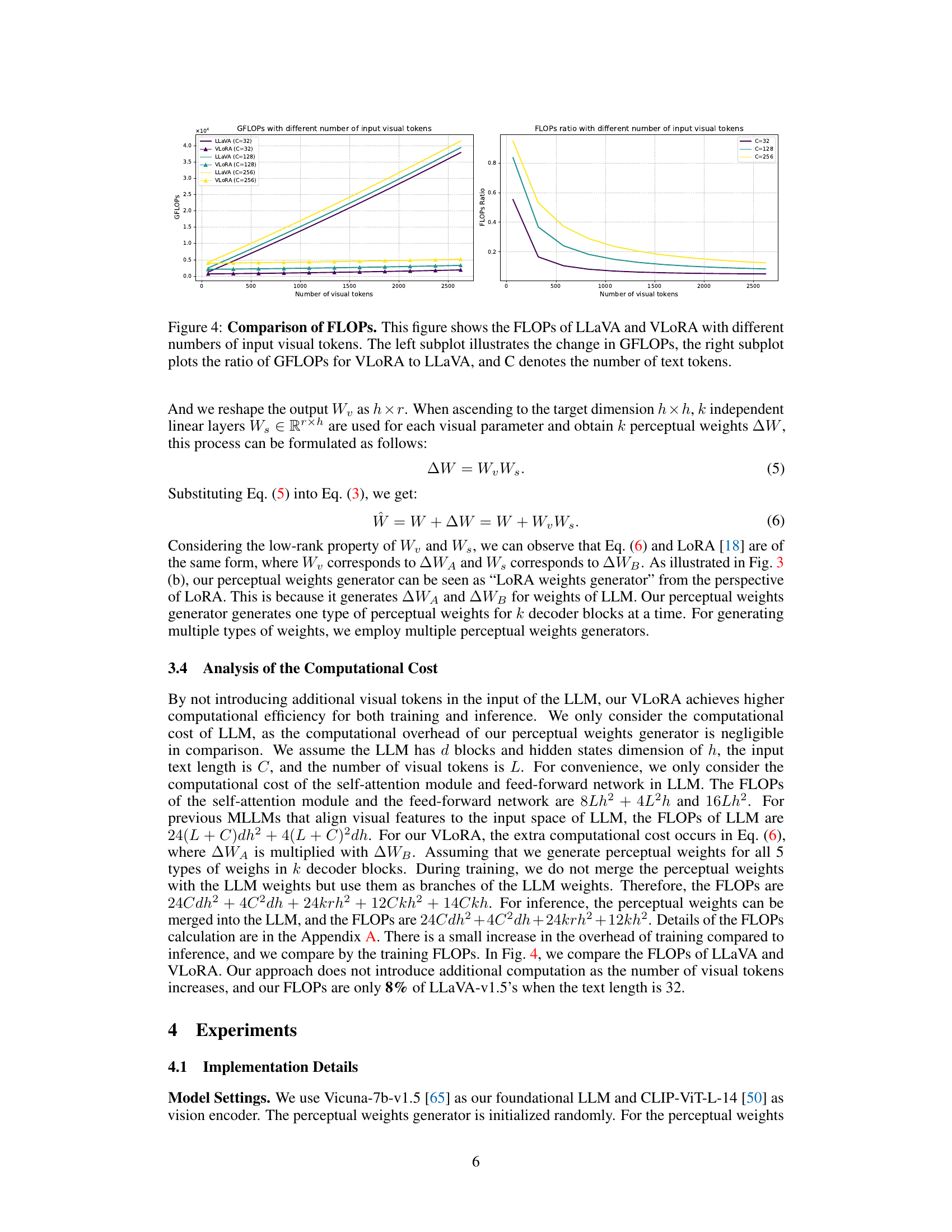
This figure compares the computational cost (GFLOPs) of LLaVA and VLORA for different numbers of input visual tokens and various text token counts (C). The left plot shows the absolute GFLOPs, while the right plot displays the ratio of VLORA’s GFLOPs to LLaVA’s GFLOPs, illustrating VLORA’s significant computational efficiency gains, particularly noticeable when the number of visual tokens increases.

The figure compares three approaches for multimodal large language models (MLLMs): (a) visual feature extraction, (b) input space alignment, and (c) the proposed VLORA method using parameter space alignment. Input space alignment concatenates visual tokens with text tokens, increasing computational cost. VLORA merges perceptual weights (derived from visual features) directly with LLM weights, improving efficiency.
More on tables

This table compares the performance of VLORA against LLaVA-v1.5 across six multimodal large language model (MLLM) benchmarks under different pre-training data and visual token configurations. It highlights VLORA’s efficiency by showing comparable performance with zero visual tokens, contrasting with LLaVA’s use of hundreds of visual tokens.
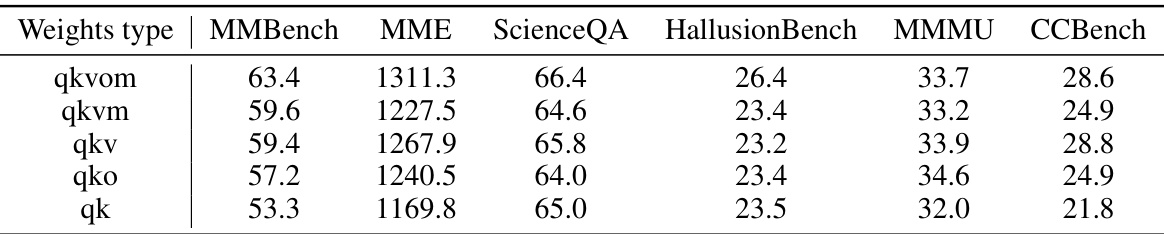
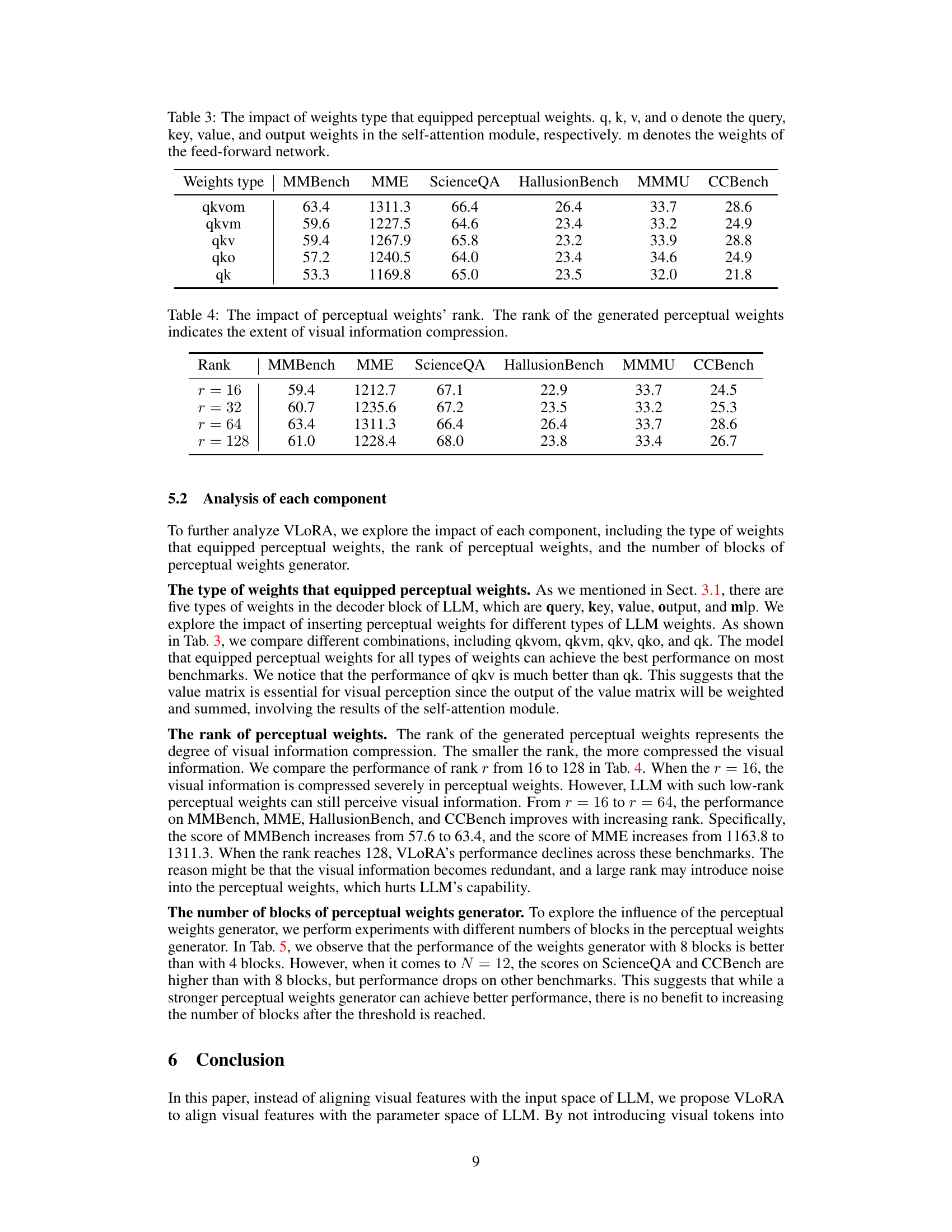
This table shows the impact of using perceptual weights on different types of weights within the LLM’s decoder block. It compares the performance on six benchmarks (MMBench, MME, ScienceQA, HallusionBench, MMMU, and CCBench) when perceptual weights are added to the query (q), key (k), value (v), output (o) weights of the self-attention module, and the weights (m) of the feed-forward network, in various combinations. The results indicate which weight types are most crucial for incorporating visual information into the LLM effectively.

This table presents the results of an ablation study on the VLORA model, investigating the impact of different ranks of the perceptual weights generator on the model’s performance across various benchmarks. The rank parameter controls the level of compression applied to the visual features before they are integrated into the LLM’s weights. The table shows that increasing the rank initially improves performance, suggesting that a higher-rank representation retains more visual information beneficial for the tasks. However, increasing the rank beyond a certain point (r = 64 in this case) leads to a decrease in performance, potentially due to overfitting or increased noise from the less compressed representation.

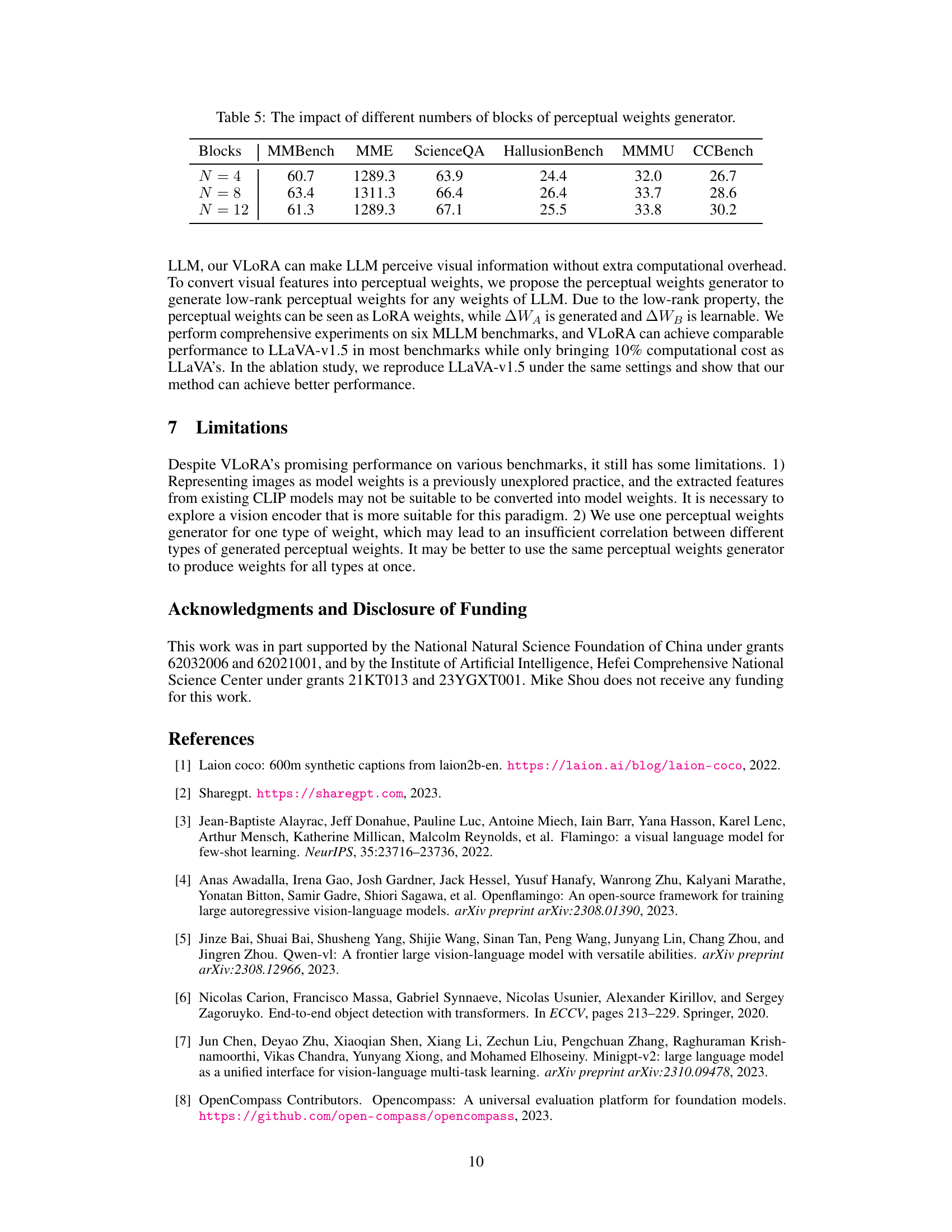
This table presents the results of an ablation study on the VLORA model, investigating the impact of varying the number of blocks in the perceptual weights generator. The table shows the performance of the model on six different benchmarks (MMBench, MME, ScienceQA, HallusionBench, MMMU, and CCBench) when the perceptual weight generator has 4, 8, or 12 blocks. The results indicate the optimal number of blocks for achieving the best overall performance across the benchmarks.

This table compares the performance of VLORA and LLaVA-v1.5 on four fine-grained vision-language benchmarks: TextVQA, DocVQA, InfoVQA, and OCRBench. It shows the average scores for each model on these benchmarks. The number of visual tokens used by each model is also listed. Notably, VLORA uses 0 visual tokens, highlighting its efficiency advantage.

This table compares the training speed and GPU memory usage of VLORA and LLaVA-v1.5 during both pre-training and fine-tuning phases. It shows that VLORA achieves significantly faster training speeds and lower GPU memory requirements during pre-training, while maintaining comparable memory usage during fine-tuning.
Full paper#