↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional image restoration methods using diffusion models often begin from Gaussian noise, leading to numerous sampling steps. This inefficiency is especially pronounced when restoring low-frequency information already present in degraded images. Existing solutions like InDI and DDRM attempt to address this by directly restoring images from degraded inputs but struggle with generalizability and interpretability. Previous efforts also suffer from inconsistent forward and reverse processes or require complex noise schedules.
Resfusion tackles these issues by incorporating a weighted residual noise term directly into the diffusion forward process, allowing it to start the reverse process directly from the noisy input image. This novel approach maintains the integrity of existing noise schedules while ensuring consistency between forward and reverse processes through a smooth equivalence transformation. Experimental results show Resfusion achieves competitive performance on standard datasets with significantly fewer sampling steps and strong generalization capabilities across various image restoration tasks, including shadow removal, low-light enhancement and deraining, and readily extends to image generation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image restoration and generation due to its novel framework, Resfusion, which significantly improves performance while simplifying the process. Its versatility and efficiency make it highly relevant to current trends, opening avenues for future research in various image processing tasks.
Visual Insights#

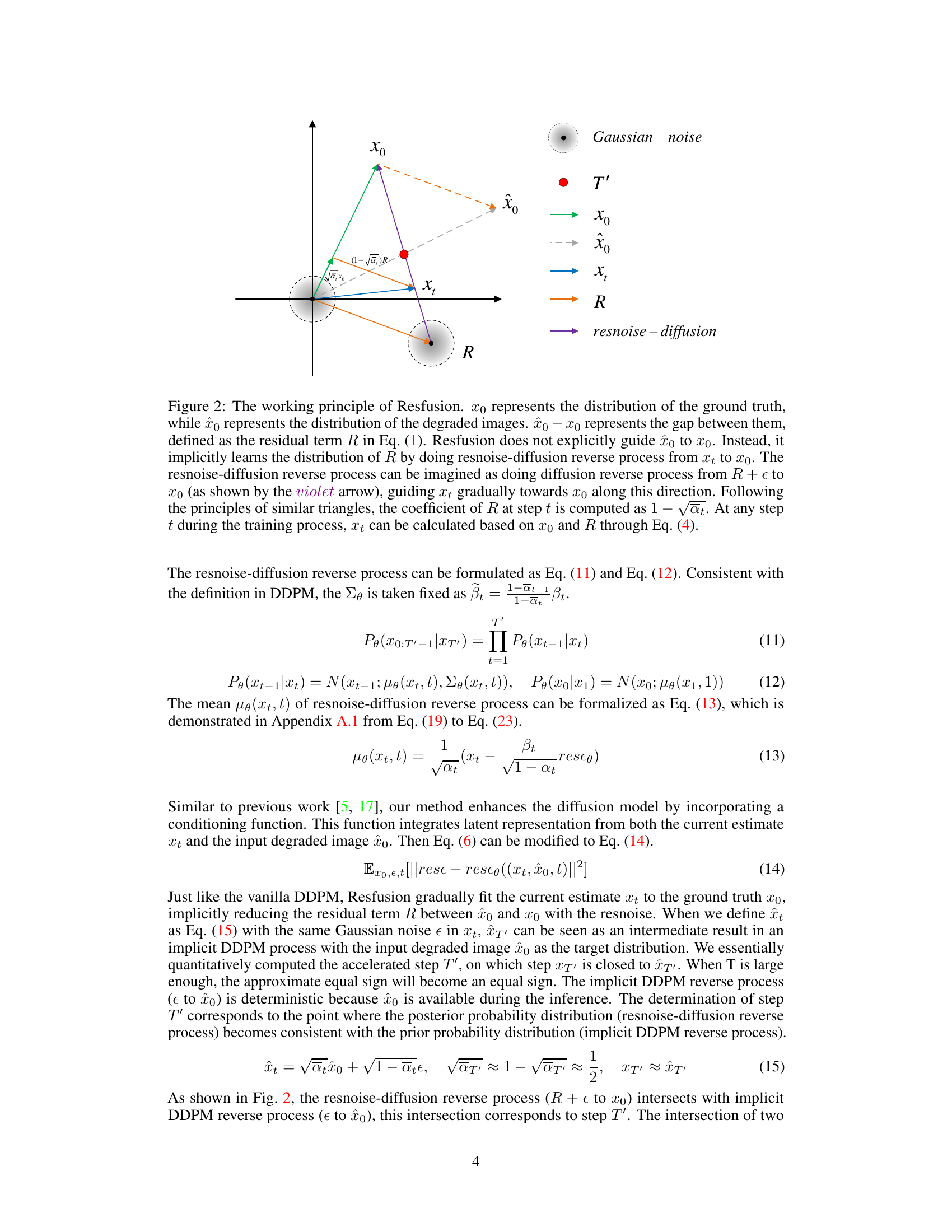
This figure illustrates the Resfusion framework, which incorporates residual noise into the forward diffusion process, allowing the reverse process to start directly from the noisy degraded image. It highlights the smooth equivalence transformation that enables the use of the degraded image as input and unifies the training and inference processes.
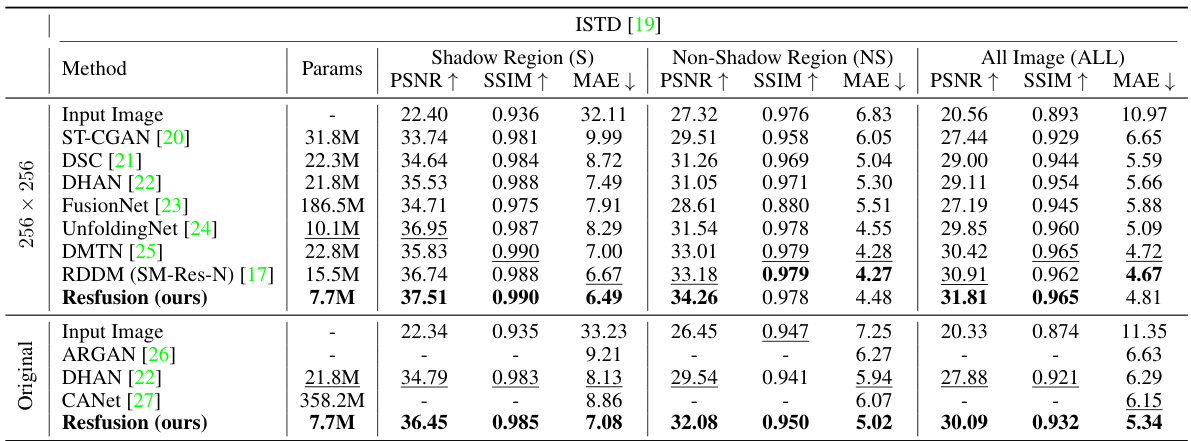
This table presents a quantitative comparison of the proposed Resfusion model with several existing shadow removal methods on the ISTD dataset. The comparison uses three metrics: Peak Signal-to-Noise Ratio (PSNR), Structural SIMilarity index (SSIM), and Mean Absolute Error (MAE). Results are shown separately for the shadow regions, non-shadow regions, and the entire image. The best and second-best performing methods for each metric are highlighted.
In-depth insights#
ResNoise Diffusion#
ResNoise diffusion, a novel approach within the denoising diffusion probabilistic models (DDPM) framework, presents a compelling strategy for image restoration. Its core innovation lies in integrating the residual noise, the difference between a degraded image and its clean counterpart, directly into the forward diffusion process. This clever integration allows the reverse diffusion process to begin directly from the noisy input image, thereby reducing the number of iterative steps required for successful restoration. By explicitly modeling the quantitative relationship between the residual and noise terms, ResNoise diffusion achieves a unification of training and inference procedures. Furthermore, leveraging a smooth equivalence transformation technique allows it to maintain the integrity of pre-existing noise schedules, simplifying its implementation and enhancing its versatility. The method’s strength lies in its ability to directly target and restore high-frequency details while preserving crucial low-frequency information present in the degraded images. Ultimately, the efficiency gains and improved performance of ResNoise diffusion suggest it as a powerful and practical alternative for various image restoration tasks.
Smooth Transform#
A smooth transform, in the context of a denoising diffusion model for image restoration, is a crucial technique to bridge the gap between the degraded input image and the ground truth. It allows the model to start the reverse diffusion process directly from the noisy input, avoiding the inefficient process of starting from pure Gaussian noise. This is achieved by carefully crafting a weighted combination of the residual noise (difference between input and ground truth) and Gaussian noise, which is named as ‘resnoise’ in the paper. The key idea is that a smooth transform enables the determination of an optimal acceleration step, thus significantly reducing sampling steps and improving efficiency. This transformation ensures that the training and inference processes are unified, leveraging the inherent low-frequency information present in the degraded input while maintaining the consistency of the forward and reverse processes. It is crucial for maintaining the integrity and power of existing noise schedules, making Resfusion highly adaptable. The smooth transform elegantly handles the quantitative relationship between residual noise and the actual Gaussian noise, ensuring a stable and effective reverse diffusion process. This is a significant innovation because it allows Resfusion to avoid the computational cost associated with starting from a pure noise image and also addresses the problem of starting the reverse diffusion from pure noise. The methodology avoids unnecessary steps and enhances the overall performance of the model, and is presented as a core component of Resfusion.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a denoising diffusion model for image restoration, this would involve experiments that isolate the effects of different model parts. For example, one might disable the weighted residual noise component to see its impact on image quality, specifically in terms of detail preservation versus semantic shift. Analyzing the results would reveal which components are critical for achieving the desired balance between detail reconstruction and accurate semantic restoration. Similarly, an ablation study might remove the smooth equivalence transformation to measure its effect on the acceleration of the reverse process, potentially revealing a trade-off between computational efficiency and restoration accuracy. The study could also test variations in the network architecture, investigating the importance of specific layers or modules in successfully learning the complex relationship between the residual and noise terms. Through this rigorous examination, the ablation study can provide a precise understanding of the interactions within the model and guide future improvements and refinements. Finally, the impact of different noise schedules on the performance of the model would be another vital part of this analysis.
Image Translation#
The concept of ‘Image Translation’ in the context of diffusion models presents a powerful paradigm shift. Instead of solely focusing on image restoration, it extends the applicability of these models to the more general task of transforming images from one domain to another. This is achieved by reframing the problem: the input image is no longer considered ‘degraded,’ but rather as a starting point for a transformation guided by a target domain representation. Instead of denoising to reconstruct a clean image, the denoising process is repurposed to morph the input image towards the desired target, guided by the latent representation of the target domain. This implies the need for effective methods to bridge the gap between the source and target image domains, likely through a conditional generative process where the target domain representation acts as a strong prior. Furthermore, the choice of network architecture becomes critically important, as it needs to be able to learn and translate the complex features of the source images into the target space efficiently and accurately. The success of image translation via this technique hinges on the effective design of the forward and reverse diffusion processes, ensuring a smooth transformation to avoid artifacts and maintain image quality. Efficient and robust training methods would be essential given the added complexity of such a process.
Future Work#
The authors mention exploring task-specific modifications, improving feature fusion methods, and investigating latent-space diffusion for increased efficiency and improved results. They also note the need for further research into the robustness and generalizability of the method across various datasets and tasks. Specifically, exploring more efficient feature fusion techniques and moving beyond simple concatenation of the noisy images and ground truth will likely be crucial for superior performance. Investigating how Resfusion can be extended to address challenging real-world scenarios, such as handling complex noise patterns, and improving the model’s ability to robustly restore details while preserving semantic information are important next steps. Further work might include an in-depth analysis of the resnoise diffusion process, its properties, and potential improvements for enhanced model optimization and stability. Finally, researching more efficient ways to handle the computational demands of the model will enhance its applicability to large-scale datasets and real-time applications.
More visual insights#
More on figures

This figure illustrates the core idea of Resfusion. It shows how the model bridges the gap between degraded images and ground truth by introducing a residual term into the forward diffusion process. The reverse process starts from the noisy degraded image and gradually approaches the ground truth by removing resnoise, a weighted sum of noise and residual terms. The optimal acceleration step is determined through a smooth equivalence transformation, ensuring efficient sampling.

This figure compares the results of several shadow removal methods on the ISTD dataset. It shows the input image, the results from DSC (2019), DHAN (2020), DMTN (2023), and the proposed Resfusion method, along with the ground truth image. The comparison highlights visual differences between the various methods in terms of shadow removal and overall image quality. Red boxes show specific regions where differences are particularly noticeable.

This figure demonstrates the individual contributions of noise and residual terms in the Resfusion model for low-light image enhancement. By selectively removing either noise or the residual component, or both, it illustrates that the noise term primarily recovers image details, while the residual term handles the semantic shift (transition from low-light to well-lit conditions). The combination of both (removing the resnoise) achieves both detail recovery and semantic correction.

This figure illustrates the working principle of the Resfusion model. It shows how the model bridges the gap between degraded input images and ground truth by introducing a residual term and employing a resnoise diffusion reverse process. The figure highlights the relationship between the residual term, noise term and optimal acceleration step, demonstrating the key aspects of Resfusion.

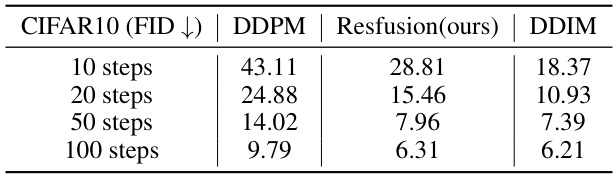
This figure compares the image generation quality of DDPM and Resfusion on the CIFAR-10 dataset using different numbers of sampling steps (10, 20, 50, and 100). It visually demonstrates that Resfusion produces higher-quality images than DDPM at all sampling step counts, showcasing improved semantic generation and detail reconstruction.

This figure visualizes the five sampling steps of the Resfusion model on the LOL web Test and Raindrop-B test datasets. The blue arrow indicates the smooth equivalence transformation, while the red boxes highlight the resnoise-diffusion reverse process. The figure showcases the model’s ability to enhance low-light images and remove rain from images, using pre-trained models without needing ground truth data for the LOL dataset.

This figure shows the results of image translation experiments using the Resfusion model. Four different translation tasks are presented: Dog to Cat, Male to Cat, Male to Female, and Female to Male. For each task, multiple pairs of input and output images are shown, illustrating the model’s ability to translate between different image domains.
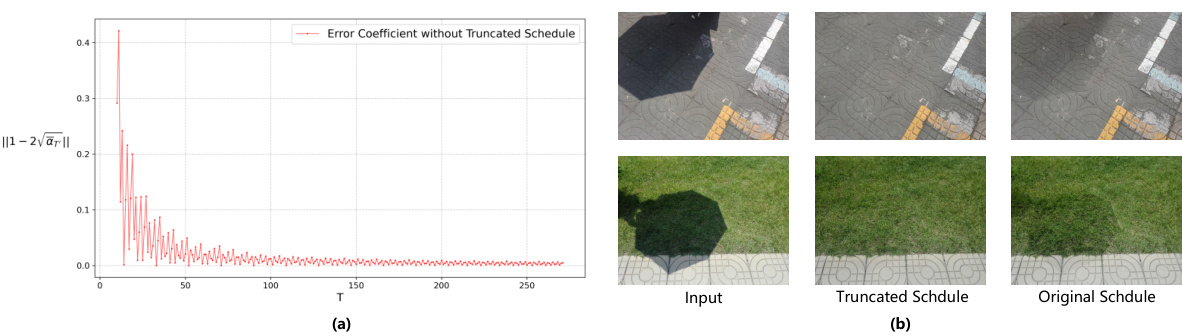
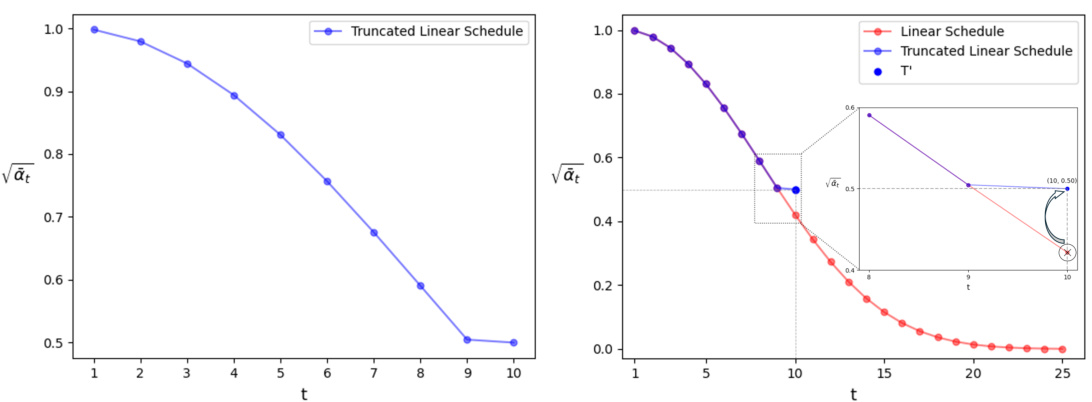
This figure demonstrates the effect of the Truncated Schedule on the error coefficient and the visual results. The left panel shows that the error coefficient decreases exponentially with T; when T is small, the error is not negligible. The right panel shows that the Truncated Schedule effectively removes the shadows which are left by the Original Schedule.
This figure illustrates the working principle of the Resfusion model for image restoration. It shows how Resfusion bridges the gap between the degraded input image and the ground truth by introducing a residual term and using a resnoise diffusion process. The process is shown as a reverse diffusion from a weighted sum of the residual and noise terms (resnoise) toward the ground truth. The optimal acceleration step is also determined graphically.

This figure presents a visual comparison of shadow removal techniques applied to images from the ISTD dataset. It shows the input image, results from several different methods (DSC (2019), DHAN (2020), DMTN (2023), and Resfusion (ours)), and the ground truth. The red boxes highlight areas where the differences between the methods are most apparent, allowing for a visual assessment of each technique’s performance in shadow removal.

This figure shows a visual comparison of shadow removal results from different methods on the ISTD dataset. The figure displays the input image, results from DSC (2019), DHAN (2020), DMTN (2023), and the proposed Resfusion method, along with the ground truth. Each row represents a different image from the dataset, allowing a side-by-side comparison of each algorithm’s performance in removing shadows while preserving image details. This visual comparison helps to assess the effectiveness of each method in removing shadows and maintaining image quality.

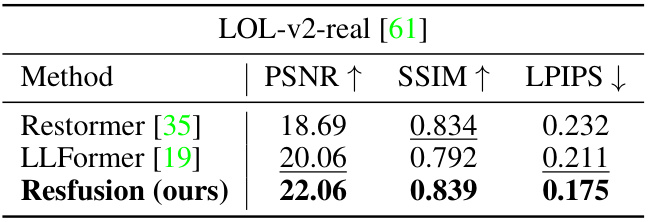
This figure shows a visual comparison of image restoration results using different methods on the LOL and Raindrop datasets. The images demonstrate the performance of each method in handling low-light conditions and rain streaks, highlighting the differences in detail preservation, color accuracy, and overall image quality.

This figure shows a comparison of deraining results from different methods on the Raindrop dataset, highlighting failure cases. The figure presents several image triplets, each consisting of the input rainy image, the results from AttentiveGAN (2018), RaindropAttn (2019), WeatherDiff (2023), and the proposed Resfusion method, alongside the ground truth images. The red boxes in the figure indicate specific regions where the different models exhibit failures in the deraining process, allowing a visual analysis of the strengths and weaknesses of each technique in challenging scenarios.

This figure showcases a visual comparison of shadow removal results obtained using different methods on the ISTD dataset. It highlights the differences in performance between various approaches, demonstrating how Resfusion compares to existing state-of-the-art methods (DSC, DHAN, DMTN) in removing shadows from images while preserving image quality and details.

This figure compares the results of different deraining methods on the Raindrop dataset, showing the input image and the results obtained by AttentiveGAN, RaindropAttn, WeatherDiff, and Resfusion, along with the ground truth. It showcases the visual differences between the methods in terms of rain removal and detail preservation.
More on tables

This table presents a quantitative comparison of Resfusion’s performance against other state-of-the-art shadow removal methods on the ISTD dataset. The metrics used are PSNR, SSIM, and MAE, calculated for three image regions: shadow, non-shadow, and the entire image. The table highlights the best and second-best results for each metric and region, demonstrating Resfusion’s superior performance.

This table presents a quantitative comparison of the performance of Resfusion using different prediction targets for the loss function on three image restoration datasets: ISTD, LOL, and Raindrop. The results, measured in PSNR, SSIM, MAE, and LPIPS, show the impact of choosing different prediction targets (the ground truth image, the residual term, or the weighted sum of the residual and noise terms). The table highlights which choice leads to better performance on each dataset.
This table presents a quantitative comparison of Resfusion against several other shadow removal methods on the ISTD dataset. The metrics used are PSNR, SSIM, and MAE, calculated for the shadow region, non-shadow region, and the entire image. The table highlights the best and second-best performing methods for each metric and region.

This table details the hyperparameters used during the training of the Resfusion model for different image processing tasks. It includes information on the datasets used (ISTD, LOL, Raindrop, CIFAR-10, CelebA-HQ, and AFHQ-V2), batch size, image/patch size, the input image (x0), the number of sampling steps, learning rate, and training epochs for each task. The settings are tailored to each specific task and dataset, reflecting the different requirements of each experiment.

This table presents a quantitative comparison of Resfusion against other state-of-the-art shadow removal methods on the ISTD dataset. The comparison is based on three metrics: Peak Signal-to-Noise Ratio (PSNR), Structural SIMilarity index (SSIM), and Mean Absolute Error (MAE). The results are broken down into three regions: the shadow region, the non-shadow region, and the whole image. The best and second-best results for each metric and region are highlighted.
This table presents a quantitative comparison of Resfusion with other state-of-the-art shadow removal methods on the ISTD dataset. The comparison is based on three metrics: Peak Signal-to-Noise Ratio (PSNR), Structural SIMilarity index (SSIM), and Mean Absolute Error (MAE). Results are provided for three different image regions: shadow region (S), non-shadow region (NS), and the whole image (ALL). The best and second-best results for each metric and region are highlighted.
Full paper#