↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Complex Logical Query Answering (CLQA) in knowledge graphs (KGs) is challenging because existing methods are often transductive, meaning they only work well on the KGs they were trained on and struggle with new KGs and queries. This limits their practical applicability. Moreover, existing CLQA methods struggle with complex, compositional queries involving multiple projections and logical operations. A key issue is the multi-source propagation problem in multi-hop queries, where several potential sources might lead to incorrect prediction.
To overcome these issues, this paper introduces ULTRAQUERY, a foundation model that addresses inductive reasoning and zero-shot generalization. ULTRAQUERY derives projections and logical operations as vocabulary-independent functions, enabling generalization to new entities and relations in any KG. By initializing its operations from a pre-trained inductive KG completion model and using non-parametric fuzzy logic operators, ULTRAQUERY achieves state-of-the-art performance in zero-shot inference mode across 23 datasets, demonstrating improved generalization capabilities compared to existing CLQA methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in knowledge graph reasoning and question answering because it introduces ULTRAQUERY, the first foundation model capable of zero-shot logical query answering on any knowledge graph. This addresses a critical limitation of existing methods which are usually trained on specific knowledge graphs and do not generalize well to new ones. This advancement opens new avenues for research, particularly in inductive learning and zero-shot generalization, which are increasingly important trends in AI.
Visual Insights#

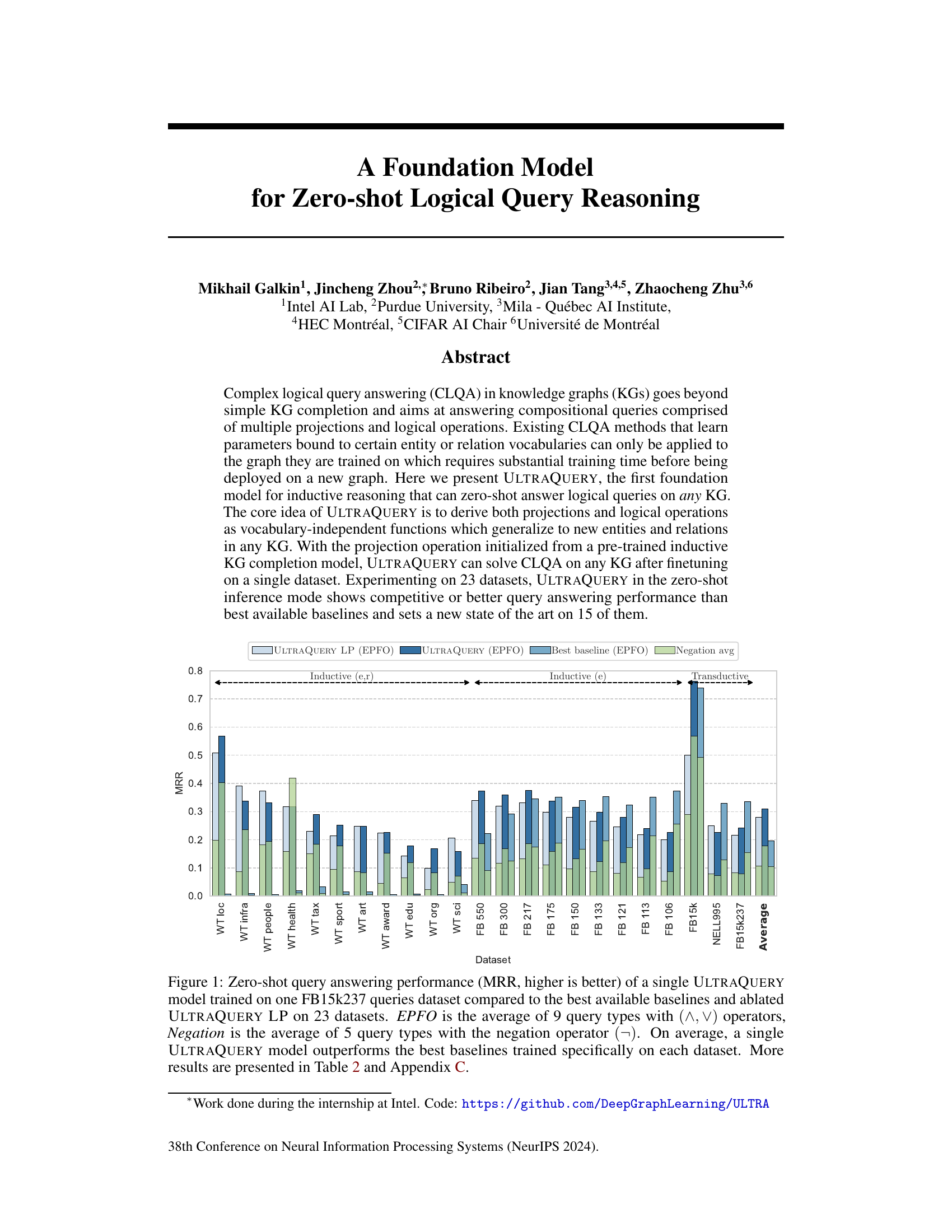
This figure compares the zero-shot query answering performance (measured by Mean Reciprocal Rank or MRR) of the ULTRAQUERY model against various baselines across 23 different datasets. The ULTRAQUERY model was trained only on the FB15k237 dataset. The figure showcases the performance for two types of queries: EPFO (which averages results across 9 query types using conjunction and disjunction) and Negation (averaging 5 query types with negation). It demonstrates that ULTRAQUERY consistently outperforms the best baselines across most datasets, particularly in zero-shot settings where the model has not been specifically trained on the target dataset.

The table compares ULTRAQUERY with existing Complex Logical Query Answering (CLQA) approaches. It highlights whether each method supports inductive generalization to new entities (Ind. e) and new relations (Ind. r) during inference, and the type of logical operators used (parametric or fuzzy). ULTRAQUERY is presented as the first method to achieve inductive generalization for both entities and relations, utilizing fuzzy logical operators.
In-depth insights#
Inductive CLQA#
Inductive Complex Logical Query Answering (CLQA) represents a significant advancement in knowledge graph reasoning. Traditional CLQA methods are largely transductive, meaning they are trained and evaluated on the same knowledge graph, limiting their ability to generalize to unseen data. Inductive CLQA aims to overcome this limitation by training models that can reason about logical queries on knowledge graphs they have never encountered before. This requires innovative techniques for representing both entities and relations in a vocabulary-independent way. A key challenge lies in handling the compositional nature of logical queries, which involve multiple projections and logical operations (conjunction, disjunction, negation). Successfully addressing this necessitates methods capable of generalizing projection operations and logical operations to novel entities and relations. The inductive approach holds considerable promise for building more robust and scalable knowledge graph reasoning systems, as it removes the need for extensive retraining whenever a new graph or query type is introduced. However, achieving truly zero-shot performance remains a substantial challenge, demanding sophisticated architectures that can effectively learn transferable and generalizable representations.
ULTRAQUERY model#
The ULTRAQUERY model is a novel foundation model designed for zero-shot logical query reasoning in knowledge graphs (KGs). Its key innovation lies in its ability to generalize to new KGs with unseen entities and relations, eliminating the need for KG-specific training. This is achieved by representing both projections and logical operations as vocabulary-independent functions, a significant departure from existing CLQA methods. ULTRAQUERY leverages a pre-trained inductive KG completion model, allowing it to handle complex logical queries effectively after finetuning on a single dataset. The model’s inductive nature and its reliance on fuzzy logic for non-parametric logical operations are particularly noteworthy. Evaluated across 23 diverse datasets, ULTRAQUERY demonstrates competitive or superior performance compared to existing baselines, showcasing its potential as a robust and generalizable solution for CLQA tasks. A particularly impressive feat is its ability to achieve zero-shot generalization, performing well on datasets entirely unseen during its training phase. Future research may focus on further enhancing its performance on more complex query structures and investigating its scalability to very large KGs.
Zero-shot inference#
Zero-shot inference, in the context of knowledge graph reasoning, signifies a model’s capability to accurately answer queries on a knowledge graph it has never encountered during training. This is a significant advancement, as traditional models require extensive training on a specific knowledge graph before deployment. ULTRAQUERY’s success in zero-shot inference highlights its generalizability and robustness. By learning vocabulary-independent functions for projections and logical operations, the model effectively transcends the limitations of data-specific parameterizations. This allows ULTRAQUERY to achieve competitive performance across diverse datasets, demonstrating its potential as a foundational model for inductive logical reasoning. The ability to handle unseen entities and relations is crucial for real-world applications where knowledge graphs are constantly evolving. However, challenges persist, particularly concerning multi-source propagation in complex queries. Future work should focus on addressing these limitations to further enhance the model’s capabilities and broaden its applicability.
Multi-source Issue#
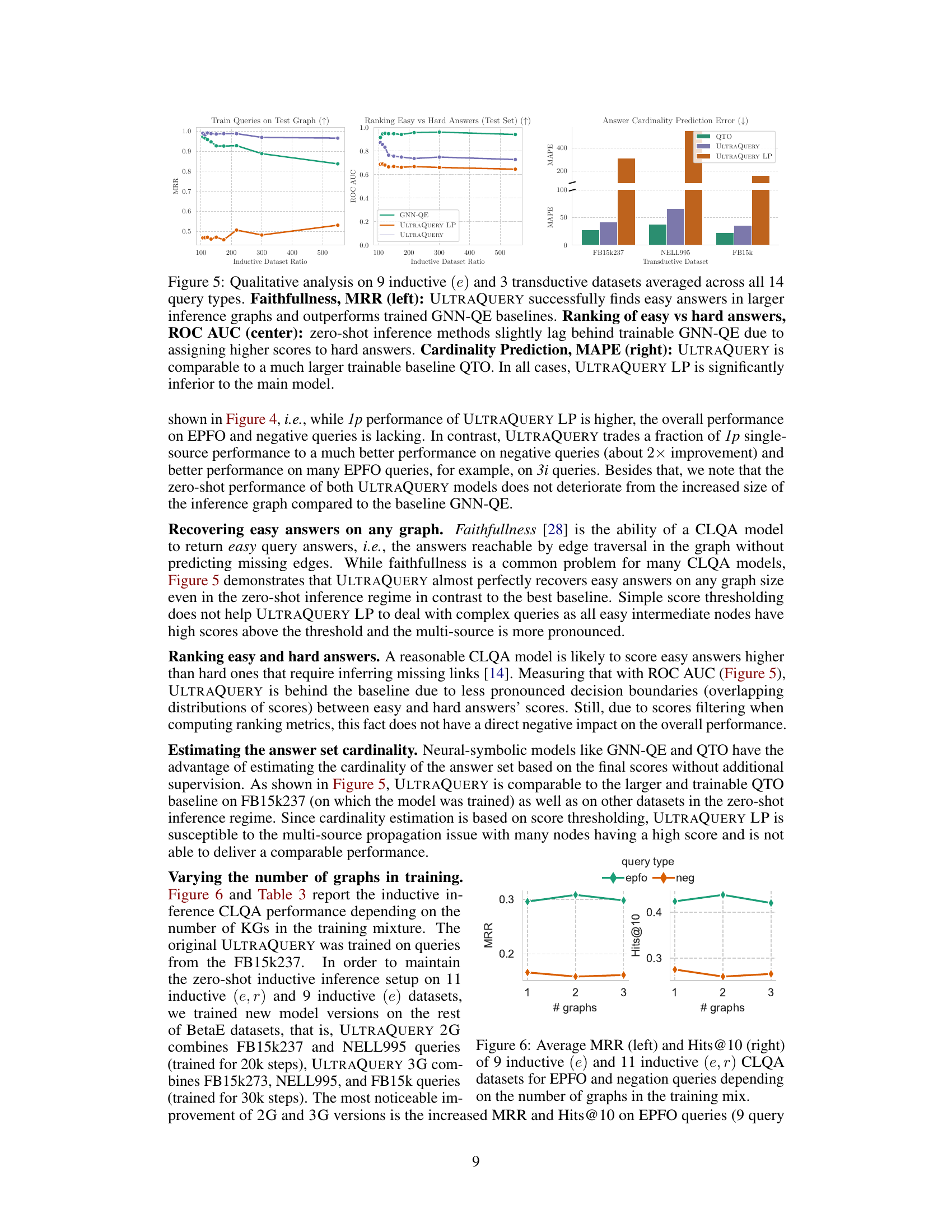
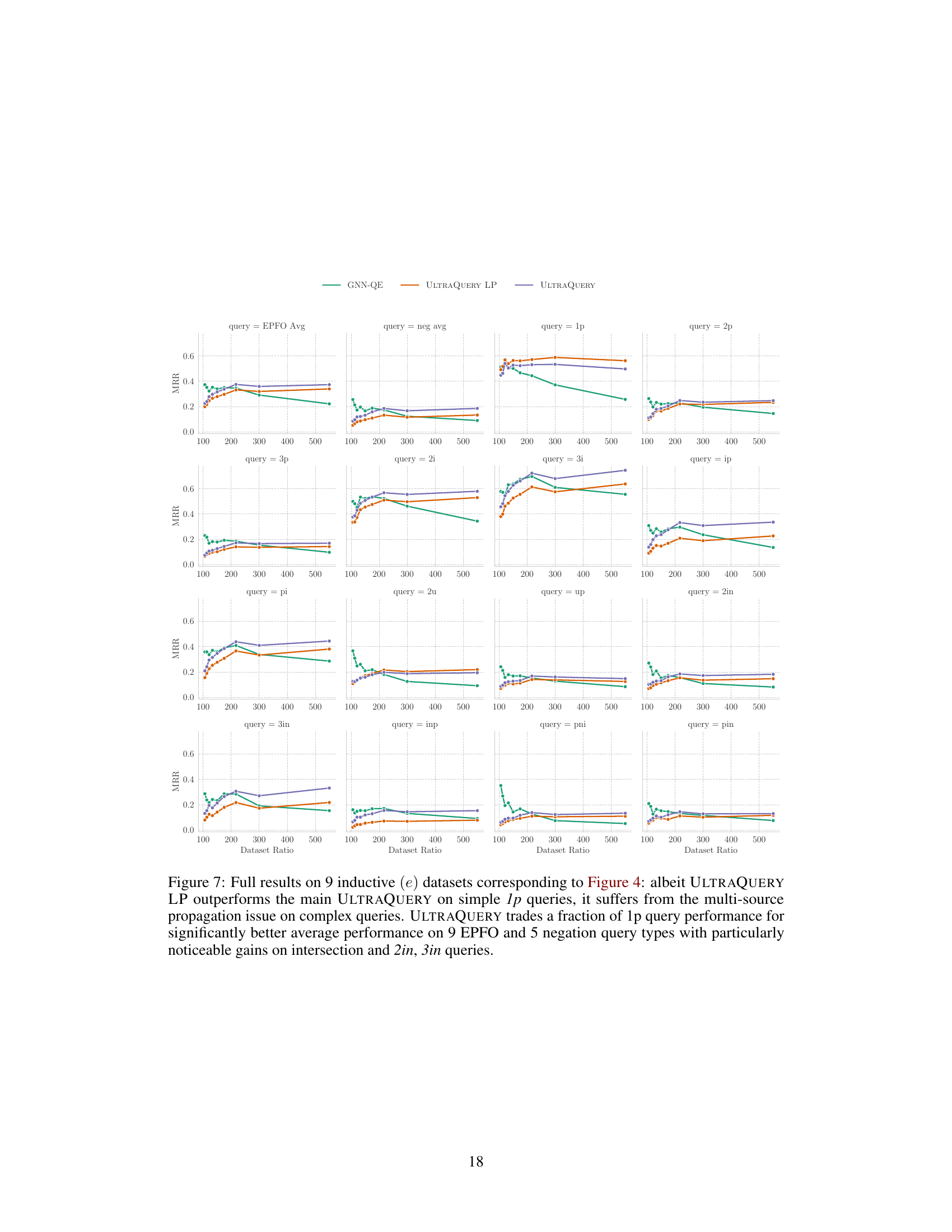
The “Multi-source Issue”, as described in the context of the research paper, highlights a critical challenge in adapting pre-trained models for complex logical query answering (CLQA). Pre-trained models, typically trained on simpler knowledge graph completion tasks, often assume a single-source input—a single query node. However, in multi-hop CLQA queries, intermediate steps can involve multiple plausible “source” nodes, each with varying degrees of relevance. This divergence between the single-source training setup and the multi-source inference scenario leads to performance degradation. The paper explores this issue, revealing how the pre-trained model struggles to handle the uncertainty inherent in multi-source propagation. Two mitigation strategies are investigated: short fine-tuning on complex CLQA queries to adjust the model’s behavior, and a frozen pre-trained model with a thresholding mechanism to limit propagation to a few high-confidence nodes. The results underscore the importance of considering the training data distribution mismatch when transferring models between different tasks and the need for robust mechanisms to address uncertainty in complex reasoning.
Future Directions#
Future research should prioritize enhancing ULTRAQUERY’s scalability and efficiency for handling massive knowledge graphs. Investigating more sophisticated logical operators beyond the current fuzzy logic implementation could significantly improve accuracy and expressiveness. The model’s robustness to noisy or incomplete data needs further exploration. Addressing the multi-source propagation issue, potentially through architectural modifications or advanced training techniques, remains crucial. Expanding the range of supported query types and exploring new applications beyond the datasets used in this research would demonstrate the model’s true potential. Finally, a thorough analysis of the model’s biases and limitations is essential for responsible deployment and further development. The incorporation of external features and contextual information could increase the accuracy and generalizability of the model’s predictions.
More visual insights#
More on figures
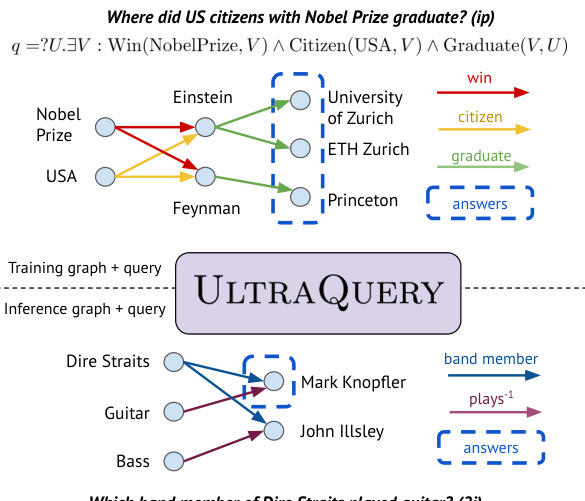
This figure illustrates the inductive logical query answering setup. It shows two knowledge graphs: a training graph and an inference graph. The key difference is that the training and inference graphs have different entities and relations. The goal is to design a single model, ULTRAQUERY, capable of answering logical queries on both graphs without any retraining or fine-tuning on the inference graph, thus demonstrating zero-shot generalization.

This figure illustrates how ULTRAQUERY answers complex logical queries. Panel (a) shows the process, using inductive parametric projection operators and non-parametric logical operators (fuzzy logics) to score entities and aggregate results across multiple relations. Panel (b) highlights the ‘multi-source propagation’ problem, showing how pre-trained models struggle with complex queries where multiple nodes could potentially be sources for further propagation.

The figure shows a bar chart comparing the Mean Reciprocal Rank (MRR) of a single ULTRAQUERY model (trained on one dataset) against various baselines across 23 datasets. The baselines were trained specifically for each dataset. ULTRAQUERY achieves competitive or better performance than existing methods, particularly excelling on 15 of the datasets. The chart also breaks down performance into EPFO (existential positive first-order logic, averaging 9 query types) and Negation (averaging 5 query types).

This figure compares the zero-shot query answering performance (measured by Mean Reciprocal Rank or MRR) of the ULTRAQUERY model against various baselines across 23 datasets. The ULTRAQUERY model is trained only once, on a single dataset (FB15k237), and then tested on the other 22 datasets without further training. The baselines are trained specifically on each dataset. The figure showcases the MRR for two types of queries: EPFO (average of 9 query types using conjunction and disjunction operators) and Negation (average of 5 query types using negation). ULTRAQUERY demonstrates competitive or better performance compared to these specialized baselines across the datasets, outperforming them on average and achieving state-of-the-art results on 15 datasets. Ablation studies using ULTRAQUERY LP (a simplified version) are also included for comparison.
This figure presents a bar chart comparing the zero-shot query answering performance (measured by Mean Reciprocal Rank or MRR) of the ULTRAQUERY model against various baselines across 23 different datasets. The ULTRAQUERY model is trained only on a single dataset (FB15k237) before being evaluated on the remaining 22 datasets in zero-shot mode. The chart showcases the model’s performance on average across 9 different query types involving conjunction and disjunction (EPFO) and on average across 5 query types involving negation. The results demonstrate that the single ULTRAQUERY model consistently outperforms the baselines (which are trained on each dataset individually) across most datasets.
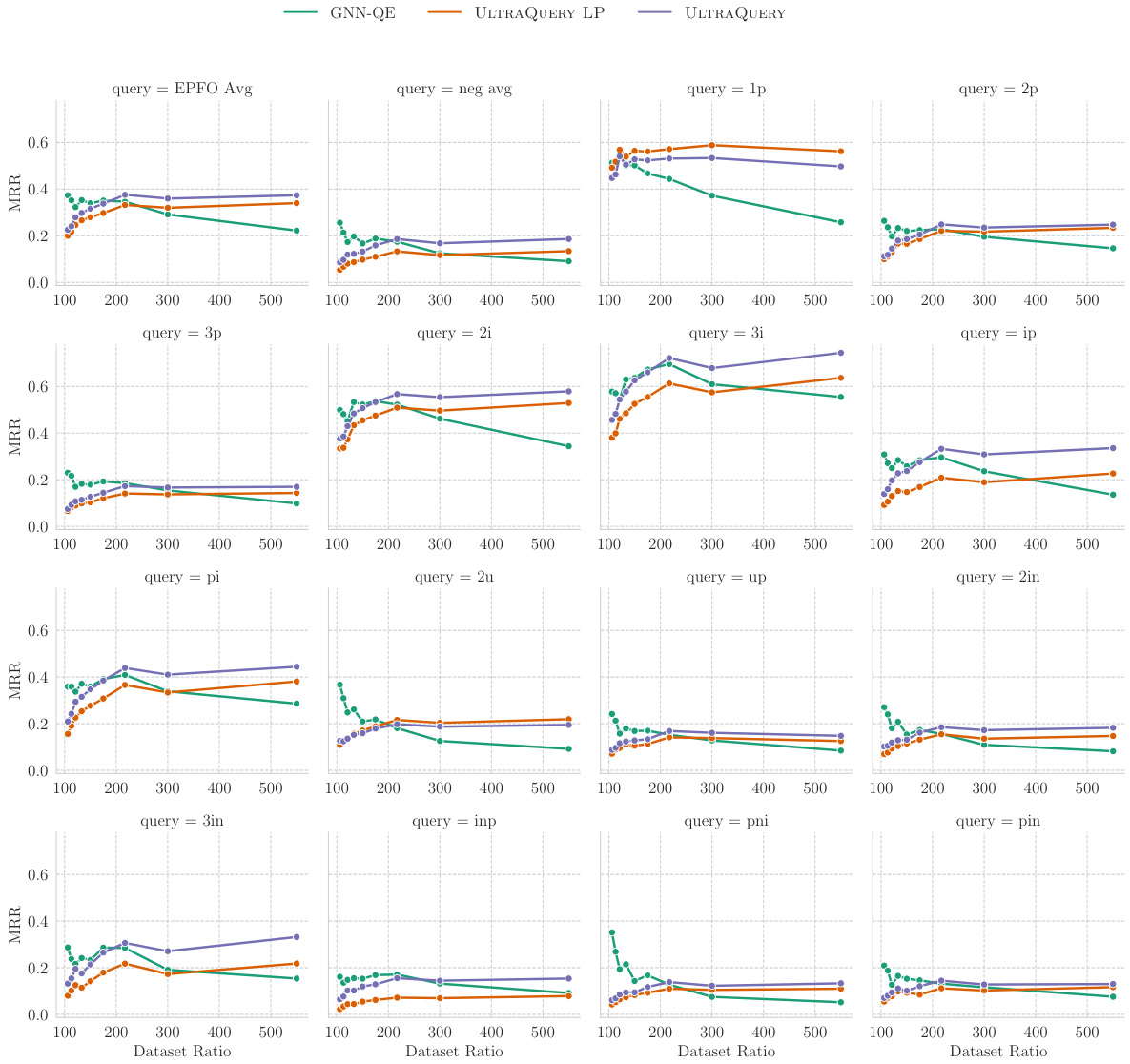
This figure compares the zero-shot query answering performance of the ULTRAQUERY model against several baselines across 23 different datasets. The ULTRAQUERY model was trained only on the FB15k237 dataset. The results are shown in terms of Mean Reciprocal Rank (MRR), a higher MRR indicating better performance. The figure also breaks down the performance into two categories of queries: EPFO (average of 9 query types using conjunction and disjunction operators) and Negation (average of 5 query types using negation). On average, the single ULTRAQUERY model outperforms the best baselines (which were trained specifically on each dataset).
More on tables

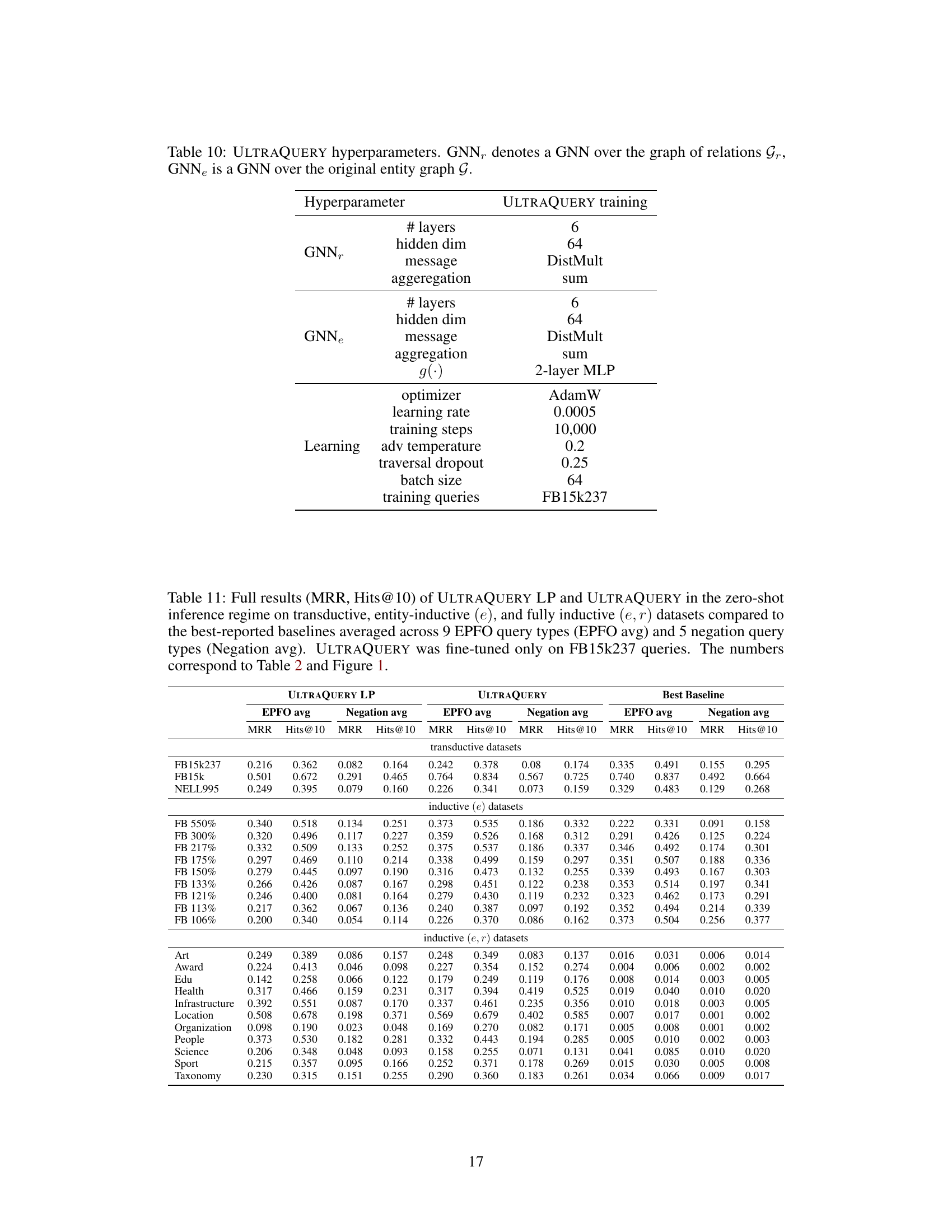
This table presents a comparison of the zero-shot inference performance of ULTRAQUERY and its ablated version (ULTRAQUERY LP) against the best-performing baselines across 23 datasets. It breaks down the results by dataset type (transductive, inductive (e), and inductive (e,r)), showing mean reciprocal rank (MRR) and Hits@10 for EPFO (average of 9 query types) and negation (average of 5 query types). ULTRAQUERY was fully trained on one dataset, while ULTRAQUERY LP only underwent pre-training for KG completion. The ’no thrs.’ variant of ULTRAQUERY LP omits score thresholding during inference. The table highlights the zero-shot capability of ULTRAQUERY, which is trained on only one dataset but tested on many more.

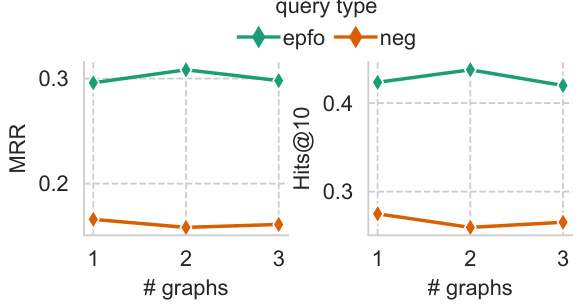
This table presents the results of a zero-shot inference experiment using the ULTRAQUERY model trained on different numbers of datasets (1, 2, and 3). It shows the mean reciprocal rank (MRR) and Hits@10 metrics for both EPFO (average of 9 query types) and negation queries (average of 5 query types) across 20 inductive datasets (11 inductive (e, r) and 9 inductive (e)). The bold values highlight the best performance achieved with training on 2 datasets, indicating that training the model on two datasets gives better performance in this specific experiment.

This table presents the zero-shot inference results of the ULTRAQUERY model and its ablated version (ULTRAQUERY LP) on 23 different datasets. It compares their performance to the best reported baselines for each dataset. The table breaks down the results by dataset type (transductive, inductive (e), inductive (e,r)) and shows the Mean Reciprocal Rank (MRR) and Hits@10 metrics for both EPFO (average of 9 query types) and negation queries (average of 5 query types). It highlights that ULTRAQUERY, trained on a single transductive dataset, achieves competitive or better performance than the best baselines, which are specifically trained on each dataset. ULTRAQUERY LP, a pre-trained model with a scoring thresholding technique, also shows results but with a different performance profile.

This table presents a comparison of the zero-shot inference performance of ULTRAQUERY and its ablated version (ULTRAQUERY LP) against the best-performing baselines on 23 datasets. It breaks down the results by dataset type (transductive, inductive (e), and inductive (e,r)) and shows Mean Reciprocal Rank (MRR) and Hits@10 for both EPFO (average of 9 query types) and negation queries (average of 5 query types). ULTRAQUERY was trained on a single transductive dataset (FB15k237), while ULTRAQUERY LP used a pre-trained model without further training. The table highlights the zero-shot capability of ULTRAQUERY by comparing its performance to baselines that were specifically trained on each dataset. The ’no thrs.’ column refers to a variation of ULTRAQUERY LP that does not employ score thresholding.

This table presents a comparison of the zero-shot inference performance of ULTRAQUERY and its ablated version (ULTRAQUERY LP) against the best-performing baselines on 23 different datasets. It breaks down the results by dataset type (transductive, inductive (e), and inductive (e,r)), showing Mean Reciprocal Rank (MRR) and Hits@10 for both EPFO (average of 9 query types) and negation queries (average of 5 query types). The table highlights ULTRAQUERY’s zero-shot capability by training it on only one dataset (FB15k237) and then testing it on the others. ULTRAQUERY LP uses a pre-trained model without further training, and a ’no thrs.’ version is also included for comparison.
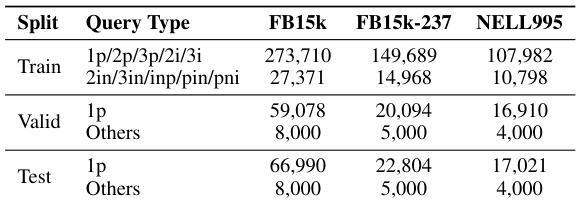
This table presents a comparison of the zero-shot inference performance of ULTRAQUERY and its ablated version, ULTRAQUERY LP, against the best-reported baselines across 23 datasets. The datasets are categorized into transductive, inductive (e), and inductive (e,r) groups. ULTRAQUERY was trained on a single transductive dataset, while ULTRAQUERY LP only underwent pre-training for KG completion. The table shows MRR and Hits@10 metrics for EPFO (average of 9 query types) and negation queries (average of 5 query types). It highlights the differences in performance based on training methodology and thresholding techniques.

This table presents a comparison of the zero-shot inference performance of ULTRAQUERY and its ablated version (ULTRAQUERY LP) against the best-performing baselines on 23 different datasets. It highlights the performance across various types of datasets (transductive, inductive (e), and inductive (e,r)), showcasing the effectiveness of ULTRAQUERY even without training on the target datasets. The table also shows the impact of score thresholding in ULTRAQUERY LP.

This table presents a comparison of the zero-shot performance of the ULTRAQUERY model and its ablated version (ULTRAQUERY LP) against state-of-the-art baselines across 23 datasets. It breaks down the results by dataset type (transductive, inductive (e), and inductive (e,r)) and query type (EPFO average and negation average), showing mean reciprocal rank (MRR) and hits@10. The training methodology for each model (ULTRAQUERY trained on FB15k237, ULTRAQUERY LP pre-trained only) and the baseline training methods are also specified to highlight the zero-shot nature of the ULTRAQUERY evaluation.
This table presents a comparison of the zero-shot inference performance of ULTRAQUERY and its ablated version (ULTRAQUERY LP) against the best-performing baselines on 23 datasets. It highlights the performance across three dataset categories: transductive, inductive (e), and inductive (e,r). The table shows that ULTRAQUERY, trained only on one dataset, achieves competitive or better performance than the baselines which are specifically trained on each dataset. It also illustrates the impact of score thresholding on ULTRAQUERY LP’s performance.

This table presents a comparison of the zero-shot inference performance of ULTRAQUERY and its ablated version (ULTRAQUERY LP) against the best-performing baselines on 23 different datasets. It highlights the performance on three dataset categories: transductive, inductive (e), and inductive (e,r). The table shows MRR and Hits@10 scores for EPFO (average of 9 query types) and Negation (average of 5 query types) queries. ULTRAQUERY was trained on a single transductive dataset (FB15k237), while ULTRAQUERY LP utilized a pre-trained model without further training. The table demonstrates the effectiveness of ULTRAQUERY’s zero-shot generalization capabilities across diverse KG datasets.
Full paper#