↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Transformer models are increasingly used in applications demanding low latency, but autoregressive inference is resource-intensive. Existing parallelism techniques introduce expensive collective communication, leading to underutilized hardware and high latency. This necessitates developing new architectures optimized for multi-device inference.
This paper introduces Kraken, a Transformer architecture modification that complements existing parallelism schemes. Kraken introduces model parallelism to allow collective operations to overlap with computations, decreasing latency and increasing hardware utilization. Evaluations show Kraken achieves similar perplexity to standard Transformers while significantly reducing Time To First Token (TTFT) across various model sizes and multi-GPU setups using TensorRT-LLM. Kraken demonstrates a mean 35.6% speedup in TTFT, highlighting its potential for enhancing interactive applications using large language models.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Kraken, a novel Transformer architecture designed for efficient multi-device inference. It directly addresses the critical challenge of high latency in large language model inference by overlapping communication with computation. This work is relevant to researchers working on large language models, parallel computing, and deep learning optimization, offering a new approach to improve inference speed and efficiency, leading to better user experiences in interactive applications.
Visual Insights#
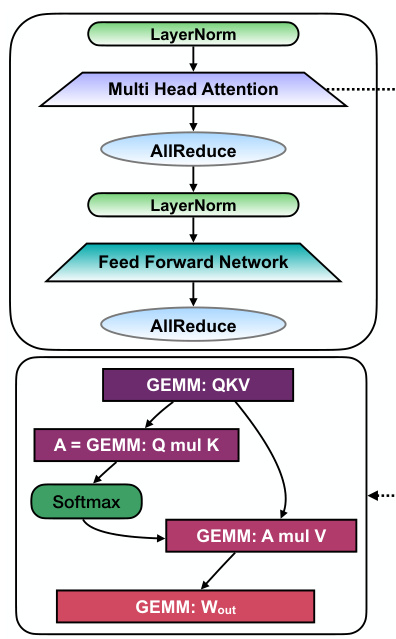
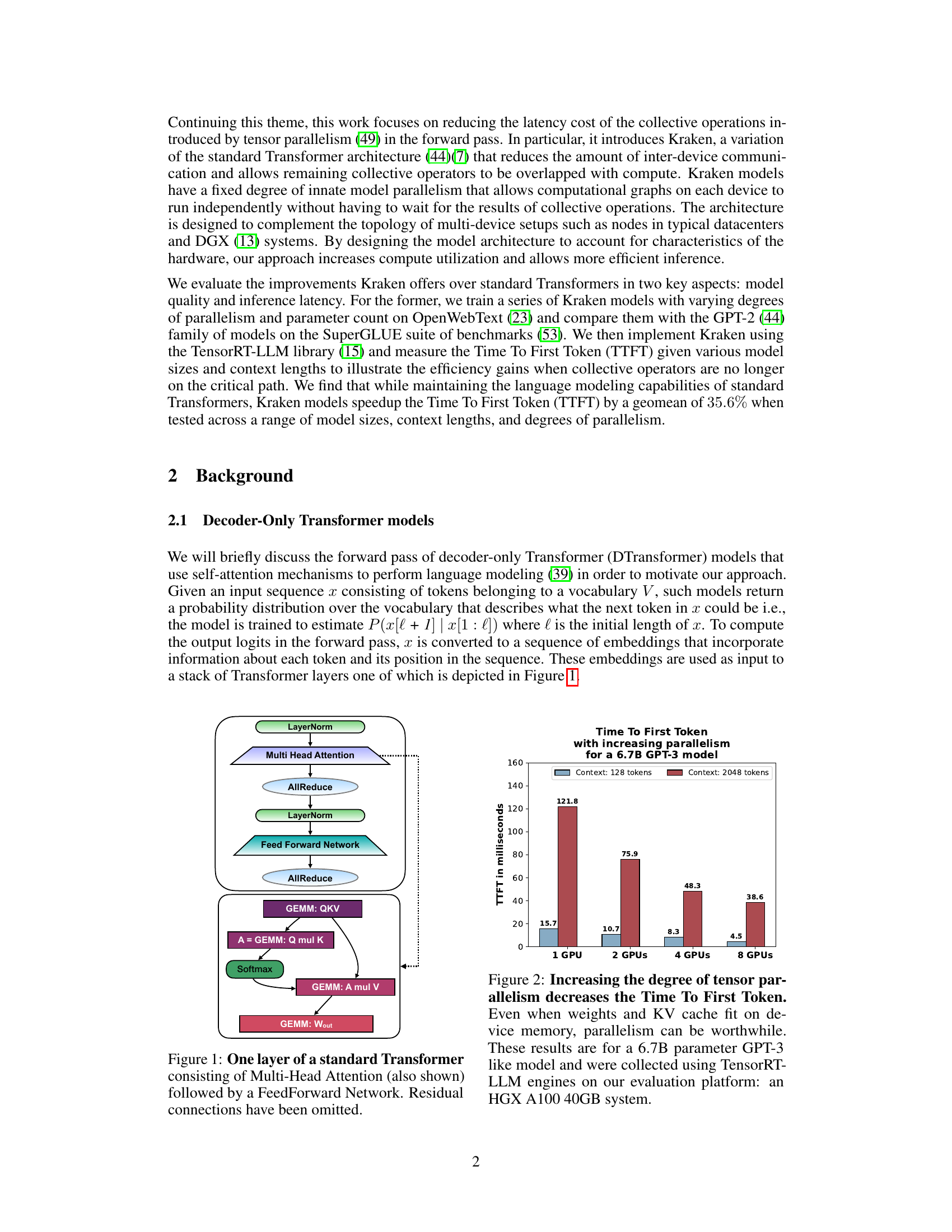
This figure shows a single layer of a standard Transformer architecture. It details the sequence of operations: Layer Normalization, Multi-Head Attention (with a detailed breakdown of its GEMM operations), AllReduce, another Layer Normalization, Feed Forward Network, and a final AllReduce. The diagram highlights the key computational blocks and the data flow between them, illustrating the structure of a single Transformer layer. It omits residual connections for clarity.

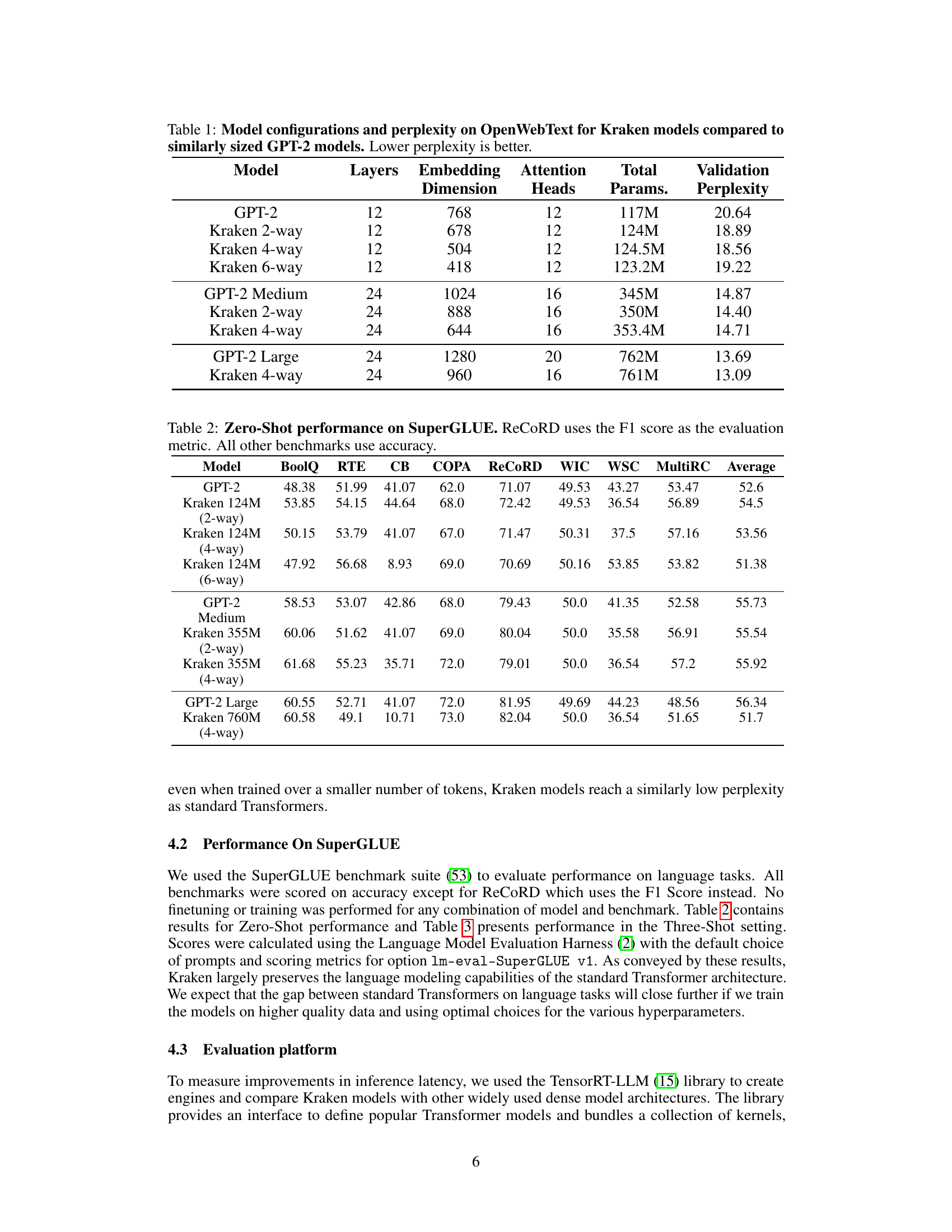
This table compares the performance of Kraken and GPT-2 models on the OpenWebText dataset. It shows different model configurations (number of layers, embedding dimension, attention heads) and the resulting number of parameters and validation perplexity. Lower perplexity indicates better language modeling performance. The table allows comparison of models with similar numbers of parameters but different architectures (Kraken vs. GPT-2) to assess the impact of the Kraken design on language modeling quality.
In-depth insights#
Kraken’s Parallelism#
Kraken introduces a novel form of model parallelism, deviating from standard tensor parallelism. Instead of partitioning layers, Kraken partitions each Transformer layer into smaller, independent sub-layers, executing them in parallel on multiple devices. This approach allows overlapping communication (AllReduce operations) with computation, a crucial optimization to reduce inference latency. The fixed degree of intra-layer parallelism in Kraken is a key design choice, simplifying implementation and aligning with common multi-GPU system topologies. While it may limit adaptability to diverse hardware configurations, it provides a significant advantage in latency reduction by cleverly hiding collective communication costs. The effectiveness is demonstrated across varying model sizes and context lengths, showcasing a mean speedup of 35.6% in Time To First Token (TTFT) compared to standard Transformers using TensorRT-LLM. This inherent parallelism is a substantial contribution towards efficient multi-device inference in large language models.
Multi-Device Speedup#
The research paper’s findings on multi-device speedup are significant, demonstrating a substantial improvement in inference latency for large transformer models. The authors achieve this speedup by introducing Kraken, a modified transformer architecture that complements existing tensor parallelism schemes. Kraken’s key innovation is a fixed degree of intra-layer model parallelism, which allows collective operations to overlap with computation, thereby reducing idle time and increasing hardware utilization. This approach leads to a mean speedup of 35.6% in Time To First Token (TTFT) across various model sizes, context lengths, and degrees of tensor parallelism, showcasing its effectiveness in real-world multi-GPU systems. The improvement is not solely due to reduced collective communication; it also stems from better hardware utilization. The results highlight Kraken as a promising solution for enhancing the efficiency of multi-device inference for large language models. Further research into optimizing Kraken for various hardware configurations and exploring its compatibility with other state-of-the-art transformer optimizations is warranted to unlock its full potential.
Model Architecture#
The core of the proposed Kraken model lies in its novel layer construction. Instead of the standard Transformer’s monolithic layers, Kraken introduces intra-layer model parallelism, dividing each layer into smaller, independent sub-layers. This design is crucial for mitigating the latency penalties of collective communication operations inherent in tensor parallelism schemes. By employing a fixed degree of parallelism, Kraken allows collective operations (such as AllReduce) to be cleverly overlapped with the computations of subsequent layers. This approach, therefore, significantly improves hardware utilization and reduces overall inference latency, making Kraken particularly efficient in multi-device settings. The architecture is specifically designed to complement existing tensor parallelism methods, effectively hiding the runtime impact of collective operations which are typically a major performance bottleneck. Preserving the overall functionality of standard Transformers, the design cleverly integrates the outputs from these sub-layers to maintain the model’s quality and language modeling capabilities, demonstrated by achieving comparable perplexity scores and SuperGLUE benchmarks.
SuperGLUE Benchmarks#
The SuperGLUE benchmark results section likely evaluates the Kraken model’s performance on a diverse range of natural language understanding tasks. High SuperGLUE scores would validate Kraken’s strong language modeling capabilities, demonstrating its ability to generalize well beyond the training data. A comparison to standard Transformer models on this benchmark is crucial; similar or superior performance would highlight Kraken’s efficacy without sacrificing model quality. The results likely detail performance across various tasks, enabling a nuanced understanding of Kraken’s strengths and weaknesses. Analysis of task-specific performance may reveal areas where Kraken excels and areas needing improvement. This detailed breakdown will be key to assessing Kraken’s potential and its advantages over existing Transformer architectures for practical applications.
Future Work#
The authors outline several promising avenues for future research. Improving Kraken’s training efficiency is paramount, as current methods are resource-intensive. Exploring techniques like knowledge distillation from pre-trained models to initialize Kraken weights could significantly reduce training costs. Furthermore, the fixed degree of model parallelism necessitates investigation into adaptive or dynamic parallelism strategies to optimize performance across diverse hardware configurations. Investigating compatibility with existing Transformer optimizations (like FlashAttention and sparse attention mechanisms) is crucial for maximizing efficiency. Finally, exploring the application of Kraken’s inherent parallelism to other large language model architectures (like Mixture-of-Experts models) and other deep learning models beyond Transformers warrants attention, potentially yielding substantial performance improvements. Combining Kraken with existing state-of-the-art training techniques is also an important area for future work.
More visual insights#
More on figures

This figure shows the impact of increasing tensor parallelism on the Time To First Token (TTFT) for a 6.7B parameter GPT-3-like language model. The results demonstrate that even when model weights and the key-value cache fit within the memory of a single GPU, increasing the degree of parallelism (using multiple GPUs) leads to a reduction in TTFT. This is likely due to the improved utilization of compute resources across multiple GPUs, which helps to reduce the latency associated with collective operations such as AllReduce. The experiment was conducted using TensorRT-LLM engines on an HGX A100 40GB system.
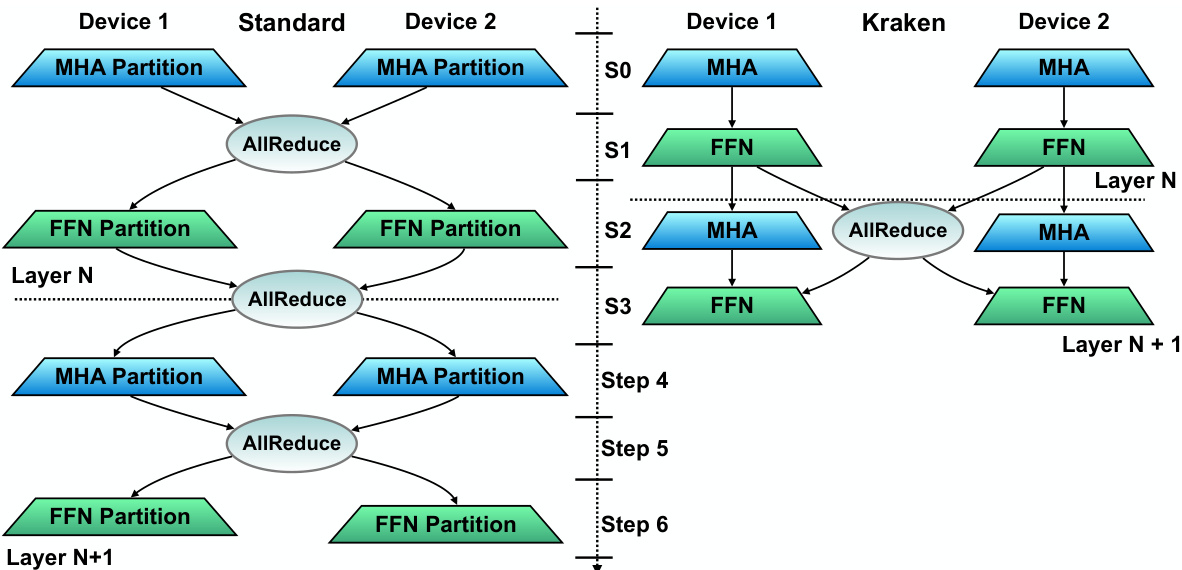
This figure compares the execution of two standard Transformer layers with the execution of two Kraken Transformer layers, both with 2-way parallelism. The figure highlights that Kraken reduces the number of AllReduce operations and enables concurrent execution of these operations with Multi-Head Attention in the subsequent layer, thereby potentially reducing latency.

This figure displays the speedup achieved by Kraken and Parallel Attention + FFN models compared to standard Transformers in terms of Time To First Token (TTFT). The improvements are shown as percentages for various model sizes (1.3B, 6.7B, 13B, 65B, and 175B parameters) and context lengths (128 and 2048 tokens). The system used has NVSwitch for inter-device communication. The results demonstrate that Kraken significantly outperforms standard Transformers and shows competitive performance compared to the Parallel Attention + FFN architecture in reducing TTFT.

This figure compares the speedup in Time To First Token (TTFT) achieved by Kraken models against standard Transformers and models with Parallel Attention + FFN, using 8-way tensor parallelism on a system with NVSwitch. The x-axis shows different model sizes (1.3B, 6.7B, 13B, 65B, 175B parameters) and context lengths (128, 2048 tokens). The bars represent the percentage speedup of Kraken and Parallel Attention + FFN compared to the standard Transformer for each model and context size combination. A geomean of the speedups is also shown.
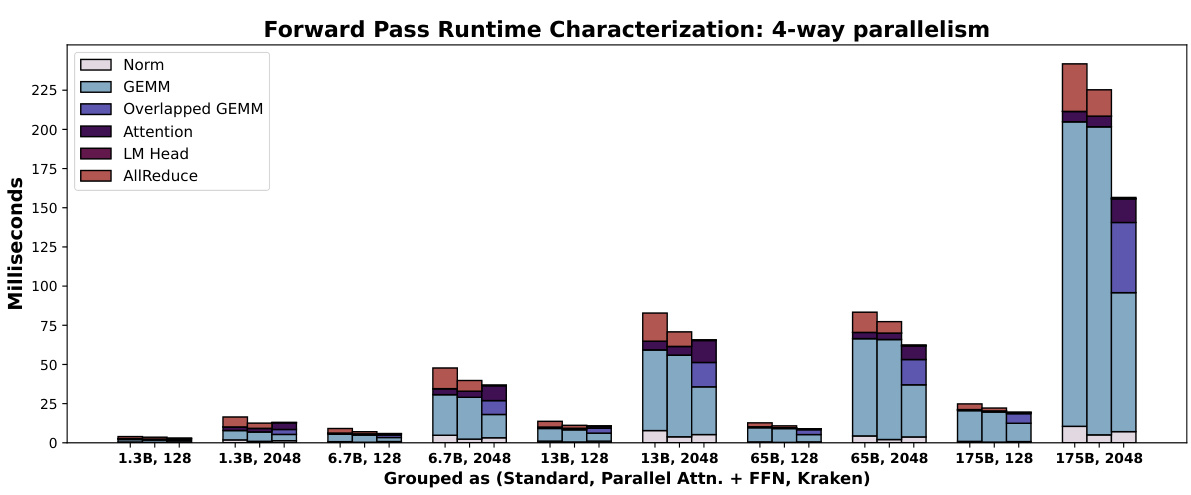
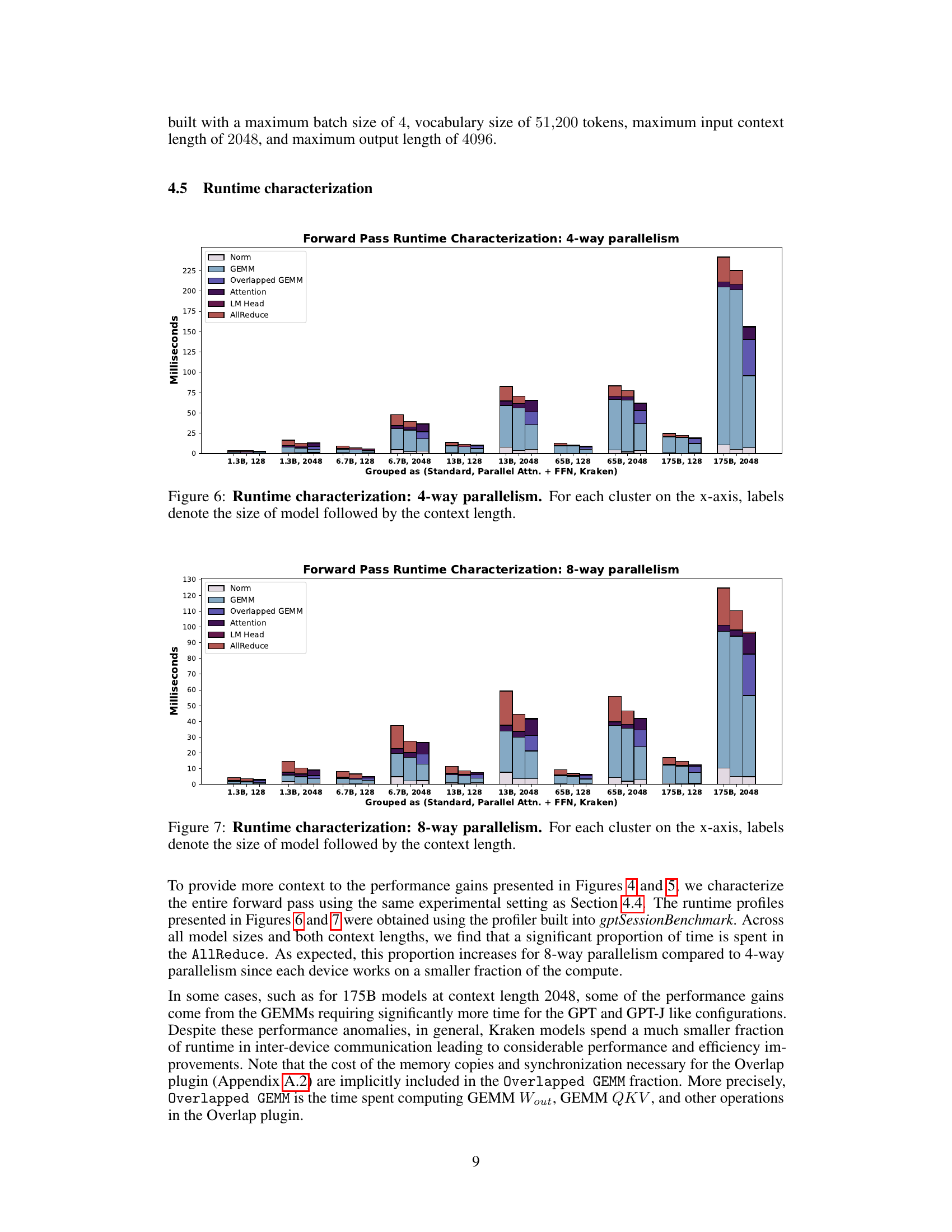
This figure shows a detailed breakdown of the runtime for each operation in the forward pass of Kraken and other Transformer models with 4-way parallelism. It compares the time spent on different operations such as LayerNorm, GEMM (General Matrix Multiply), Attention, and AllReduce, for various model sizes and context lengths. The ‘Overlapped GEMM’ represents the time spent on GEMM operations that are overlapped with communication, showcasing Kraken’s efficiency in overlapping computation and communication.

This figure shows the breakdown of the forward pass runtime for different model sizes (1.3B, 6.7B, 13B, 65B, 175B parameters) and context lengths (128, 2048 tokens) with 8-way parallelism. It compares the runtime of standard Transformers, Transformers with parallel Attention and Feed-Forward Networks, and Kraken Transformers. The runtime is broken down into components: Layer Normalization (Norm), General Matrix Multiplication (GEMM), Overlapped GEMM (where computation and AllReduce are overlapped), Attention, Linear Mapping (LM Head), and AllReduce. The figure helps visualize how Kraken reduces the time spent in AllReduce operations by overlapping them with computation, leading to faster inference.
More on tables
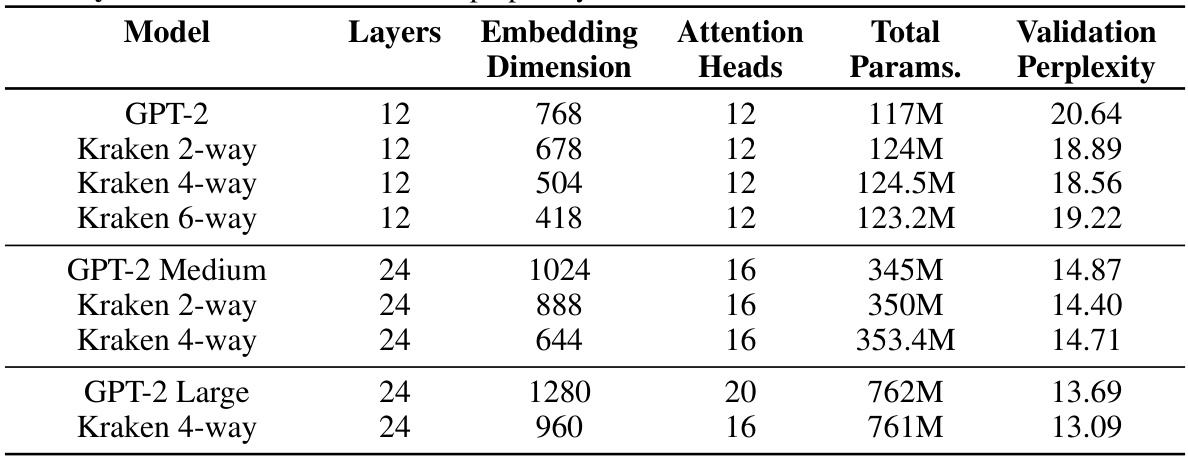
This table presents the configurations and validation perplexity scores for various Kraken and GPT-2 language models trained on the OpenWebText dataset. It shows that Kraken models, with varying degrees of intra-layer parallelism (2-way, 4-way, 6-way), achieve comparable perplexity to similarly sized GPT-2 models, indicating that the Kraken architecture doesn’t compromise model quality while offering potential performance advantages.
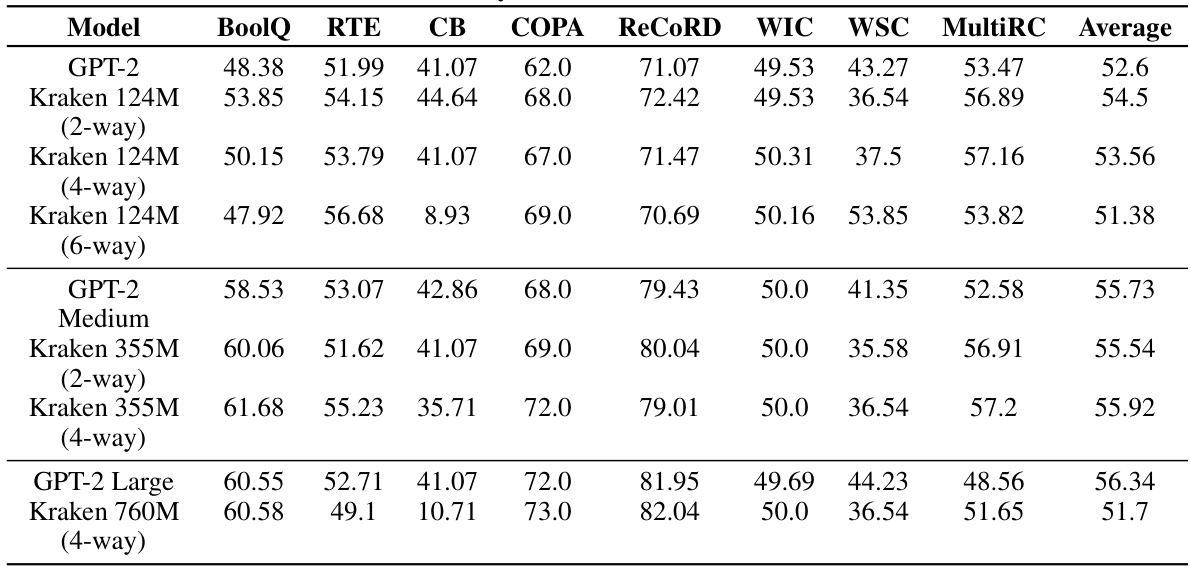
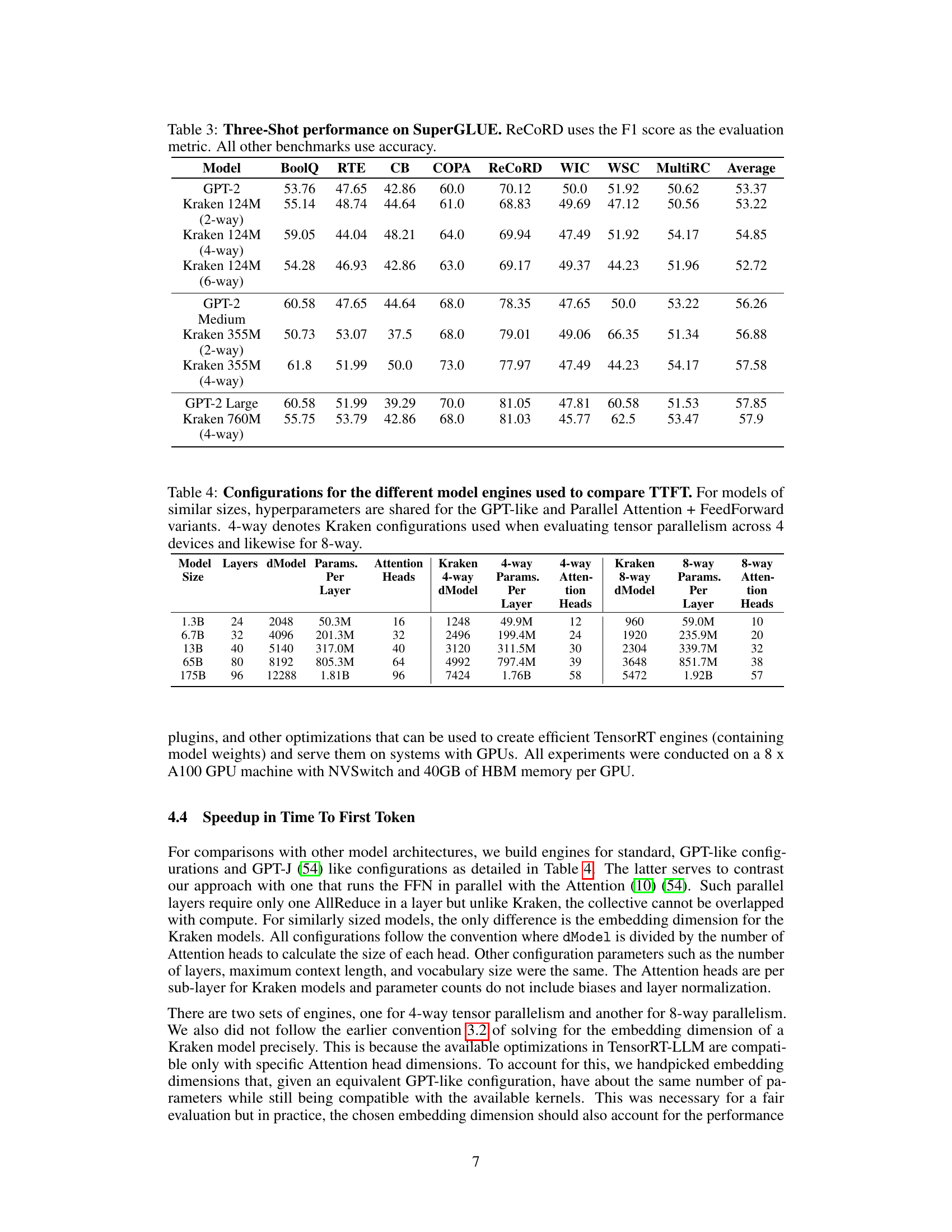
This table presents the zero-shot performance of various language models on the SuperGLUE benchmark. The models include GPT-2 and Kraken models of different sizes and degrees of parallelism. The benchmark consists of multiple tasks, each evaluating a different aspect of language understanding, and the results are reported using accuracy (except for ReCoRD which uses F1-score). The table shows that Kraken models generally achieve comparable performance to GPT-2 models across various tasks, even with different model sizes and degrees of parallelism.
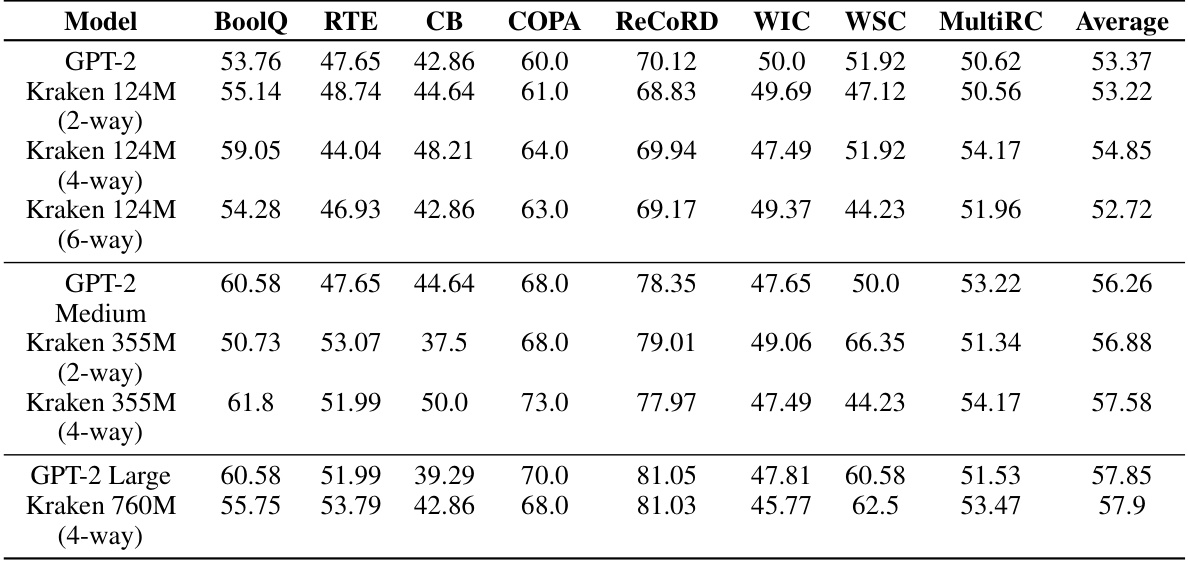
This table presents the zero-shot performance of different language models on the SuperGLUE benchmark. The models compared include various sizes of GPT-2 and Kraken models with different degrees of parallelism. The SuperGLUE benchmark consists of multiple tasks, each assessed using either accuracy or F1 score (for ReCoRD), providing a comprehensive evaluation of language understanding capabilities. The results demonstrate the performance of Kraken models relative to standard GPT-2 models on diverse language tasks without any fine-tuning.

This table shows the configurations used for different model engines in the evaluation of Time To First Token (TTFT). It compares standard, GPT-like, and Parallel Attention + FeedForward models with Kraken models, demonstrating the various hyperparameters (number of layers, embedding dimension, parameters per layer, number of attention heads) used for both 4-way and 8-way tensor parallelism.
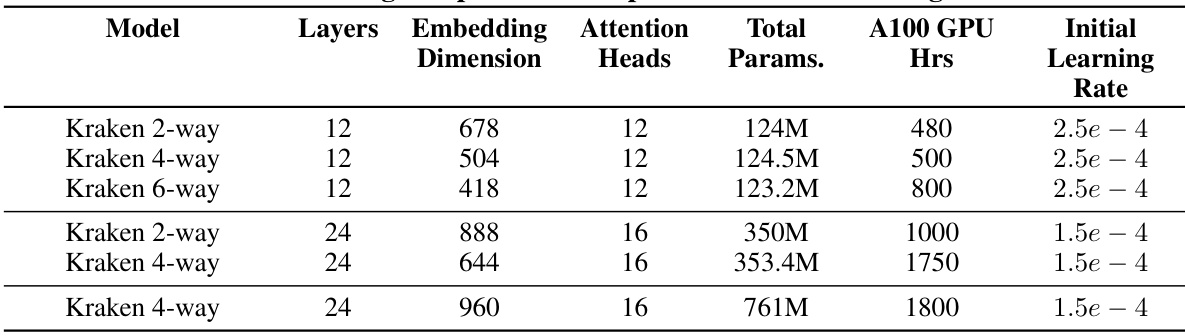
This table presents the hyperparameters used during the pre-training phase for various Kraken model configurations. It details the number of layers, embedding dimension, number of attention heads, total number of parameters, the approximate number of A100 GPU hours required for training, and the initial learning rate used for each configuration. The configurations are differentiated by the degree of parallelism (2-way, 4-way, 6-way) employed. This information allows readers to understand the computational resources and training settings associated with each Kraken model.

This table presents the inference latency in milliseconds for various model sizes (1.3B, 6.7B, 13B, 65B, and 175B parameters) and context lengths (128 and 2048 tokens) using 4-way parallelism. It compares the latency of three different model architectures: Standard Transformer, Parallel Attention + FeedForward, and Kraken. The Kraken architecture aims to reduce latency by overlapping collective operations with compute. The table shows the inference time for each model and architecture, allowing for a direct comparison of their efficiency.
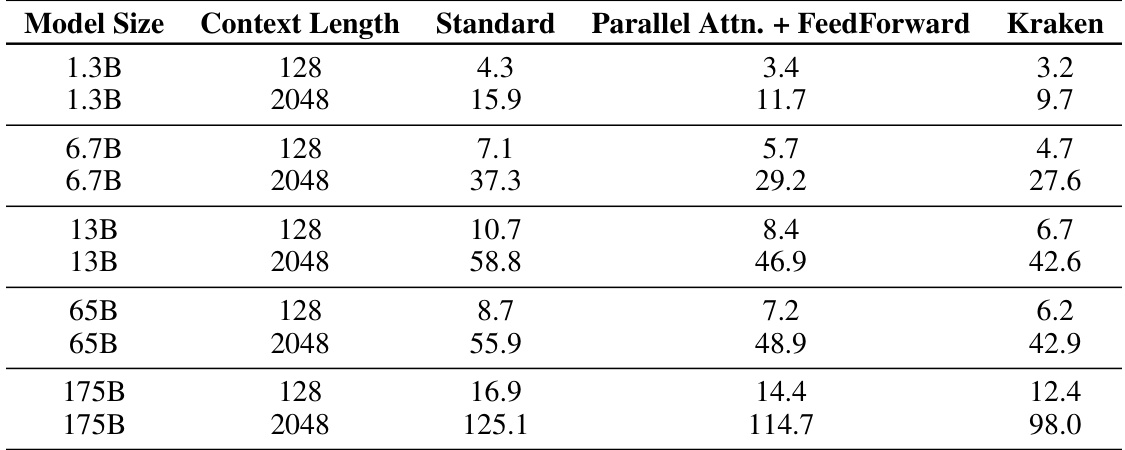
This table presents the inference latency results for 8-way parallelism across different model sizes (1.3B, 6.7B, 13B, 65B, and 175B parameters) and context lengths (128 and 2048 tokens). The latency is measured for three different model architectures: Standard Transformers, Parallel Attention + FeedForward Transformers, and Kraken Transformers. Kraken consistently shows lower latency than the other two architectures.
Full paper#