↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Federated learning (FL) offers collaborative model training without sharing raw data, but it’s vulnerable to privacy breaches from shared gradients and malicious attacks where poisoned gradients corrupt the model. Existing defenses often compromise privacy by inspecting gradients directly. This creates a conflict between privacy and robustness.
This paper introduces RFLPA, a novel framework addressing these issues. RFLPA employs secure aggregation, leveraging verifiable packed Shamir secret sharing for enhanced privacy and efficiency. A new dot product aggregation protocol further minimizes information leakage. Experiments demonstrate that RFLPA significantly reduces communication and computation costs while maintaining accuracy even under significant adversarial attacks. This framework offers a crucial balance between privacy and robustness in federated learning.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning because it directly addresses the critical issues of privacy leakage and poisoning attacks, which are major obstacles to the widespread adoption of this technology. By proposing a novel framework (RFLPA) that significantly improves security and efficiency, this work paves the way for more secure and practical federated learning systems. The techniques employed, such as verifiable packed Shamir secret sharing and a new dot product aggregation protocol, are valuable for researchers working on privacy-preserving machine learning.
Visual Insights#

This figure illustrates the overall framework of the robust federated learning algorithm proposed in the paper. It’s a four-round algorithm involving interactions between user devices and a server. Each round involves specific computations, including normalization and quantization of local updates, generation and exchange of secret shares, robust aggregation, and model updates. The figure depicts the flow of information and computations in each round, highlighting the use of secure aggregation techniques to maintain privacy while enhancing robustness against poisoning attacks.

This table compares the computational and communication complexities of the proposed RFLPA framework and the BERA framework. For both frameworks, complexities are broken down for server-side and user-side operations, and expressed using Big O notation in terms of model dimension (M) and number of selected clients (N). The table highlights the significant reduction in computational and communication overhead achieved by RFLPA compared to BERA.
In-depth insights#
SecAgg Poisoning#
Secure aggregation (SecAgg) methods, designed to enhance privacy in federated learning by preventing the server from directly accessing individual updates, are unfortunately vulnerable to poisoning attacks. Poisoning attacks exploit SecAgg’s inherent limitations by allowing malicious clients to inject corrupted data into the aggregation process, potentially skewing the model’s parameters. This can lead to various issues like reduced model accuracy, biased predictions, or even backdoor vulnerabilities that compromise the system’s integrity. Understanding the nature of SecAgg poisoning necessitates analyzing the attack vectors, including how malicious clients manipulate their local updates to maximize their impact on the global model. Effective defense mechanisms are crucial, and research focuses on robust aggregation techniques and outlier detection methods to identify and mitigate the effects of these malicious contributions. Ultimately, the resilience of federated learning models hinges on developing SecAgg protocols that are not only privacy-preserving but also robust against sophisticated poisoning attempts.
RFLPA Framework#
The RFLPA framework presents a robust approach to federated learning, combining secure aggregation with a novel cosine similarity-based robust aggregation rule. This addresses the critical vulnerabilities of traditional federated learning to both privacy leakage and poisoning attacks. By leveraging verifiable packed Shamir secret sharing, RFLPA achieves significant efficiency gains over existing methods, reducing communication and computation overheads. The framework’s innovative dot product aggregation protocol mitigates information leakage inherent in packed secret sharing, further enhancing privacy. The inclusion of a server-side trust score, calculated using cosine similarity, enables effective identification and mitigation of malicious updates. RFLPA’s design strikes a balance between robustness, privacy, and efficiency, making it a promising solution for secure and reliable federated learning deployments.
Dot Product Secrecy#
In federated learning, privacy preservation during model training is paramount. A naive approach to calculating dot products, a crucial operation for cosine similarity and gradient norm computations, could leak sensitive information about individual user updates. A method achieving ‘Dot Product Secrecy’ would cleverly use cryptographic techniques like secure multi-party computation or secret sharing. The goal is to enable the server to obtain the final dot product result without gaining access to the individual components. This requires careful design of the protocol to ensure that intermediate calculations do not inadvertently reveal information. Verifiable secret sharing can further enhance security by enabling the server to verify the validity of received shares, thereby mitigating attacks from malicious clients. Therefore, achieving Dot Product Secrecy necessitates a robust and well-defined protocol that balances computational efficiency with strong privacy guarantees.
Efficiency Analysis#
An efficiency analysis of a federated learning framework should meticulously examine its computational and communication complexities. Computational efficiency hinges on the algorithm’s design, focusing on the number of operations required per iteration, per device, and for the central server. Factors like model size, data volume, and the number of participants significantly influence this aspect. A strong analysis would break down costs into individual components to identify bottlenecks. Communication efficiency is crucial in federated learning due to the distributed nature of the process. The analysis must quantify the amount of data transmitted between participants and the server per round. Optimizing this aspect involves strategies such as gradient compression and efficient aggregation techniques. Overall efficiency combines both computational and communication aspects, ideally aiming for a framework that scales gracefully with increasing model size and the number of participants. Benchmarking against existing solutions provides crucial context for evaluating performance gains and limitations.
Future Work#
Future research directions stemming from this work could explore several key areas. Improving the efficiency of the dot product aggregation protocol is crucial, potentially through advancements in secure multiparty computation or more efficient cryptographic techniques. Further investigation into the robustness of the framework under various attack models is warranted, especially in non-IID settings and with more sophisticated adversarial strategies. A comprehensive comparison against state-of-the-art robust aggregation rules in terms of accuracy, efficiency, and security guarantees is needed, focusing on large-scale datasets and high-dimensional models. Finally, exploring integration with other privacy-enhancing technologies, such as differential privacy, could offer even stronger security and privacy for federated learning frameworks.
More visual insights#
More on figures
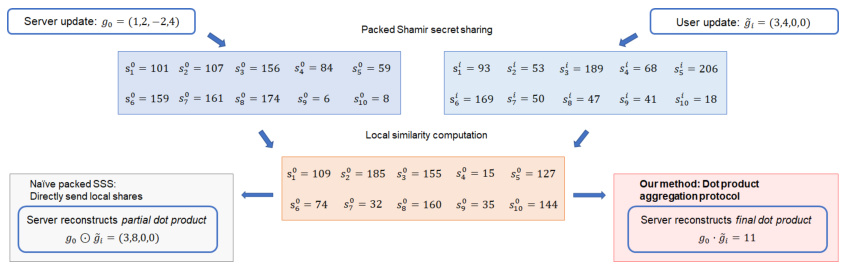
The figure illustrates two different approaches to computing cosine similarity using packed Shamir secret sharing. The naive approach directly sends local shares, resulting in the server reconstructing a partial dot product, which reveals more information than intended. The proposed method, called dot product aggregation protocol, uses a more secure approach that ensures the server only reconstructs the final dot product, thus protecting user privacy. This highlights the increased information leakage risk of a naive approach and the improved privacy protection of the proposed technique.

This figure shows a comparison of communication and computation costs between RFLPA and BREA. The left two graphs show the communication cost, broken down by the number of users and model dimensions. The right two graphs show the computation cost, broken down by the number of users for both the server and individual users. The results clearly demonstrate that RFLPA significantly reduces both communication and computation overhead compared to BREA.
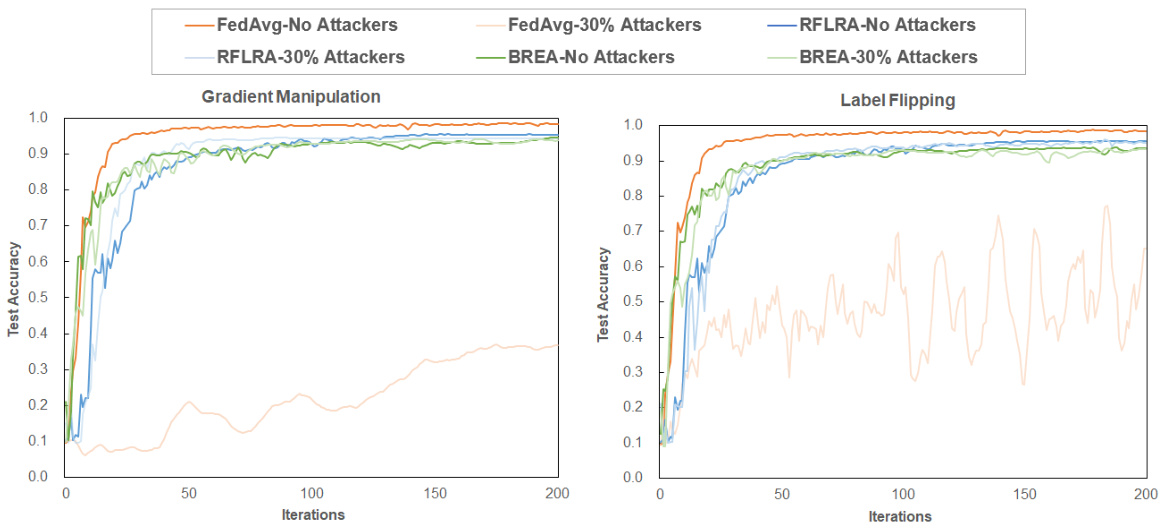
This figure shows the communication and computation overhead comparison between RFLPA and BREA. The left two graphs illustrate communication costs under varying client sizes and model dimensions. The right two graphs present computation costs for users and the server under varying client sizes. RFLPA demonstrates significantly reduced overhead compared to BREA in all scenarios.

This figure compares the original images from the CIFAR-10 dataset with the images reconstructed by the Deep Leakage from Gradients (DLG) attack under the RFLPA framework. The reconstructed images are noisy and bear little resemblance to the originals, demonstrating the effectiveness of RFLPA in protecting the privacy of the training data against inference attacks.

This figure shows the communication and computation overhead of RFLPA and BREA. The left two graphs compare per-iteration communication cost (in MB) for both algorithms across different numbers of participating users (top) and varying model dimensions (bottom). The right two graphs compare the per-iteration computation cost (in ms) for both algorithms under the same conditions as the communication cost comparisons. These graphs illustrate that RFLPA significantly reduces both communication and computation overhead compared to BREA.
More on tables

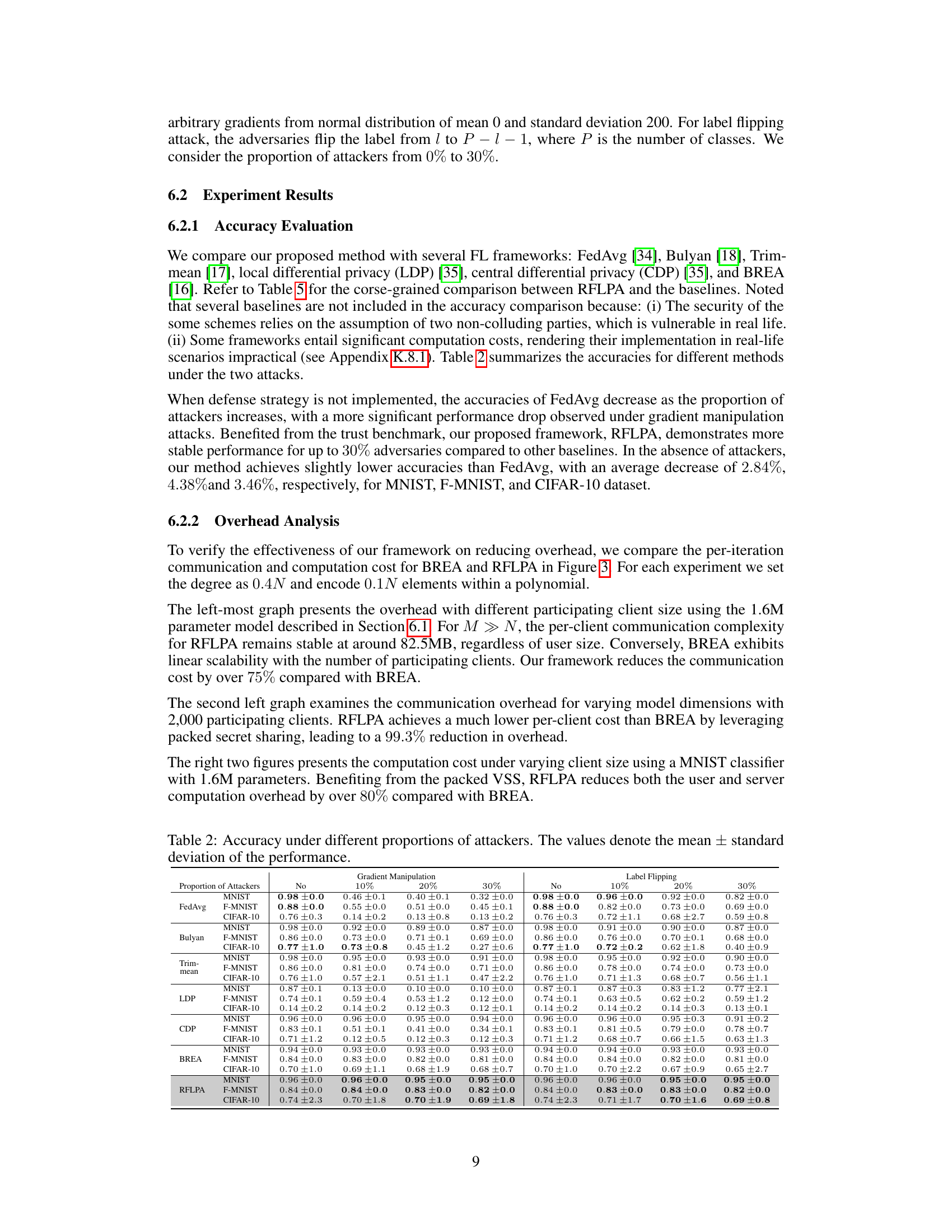
This table presents the accuracy results of different federated learning frameworks (FedAvg, Bulyan, Trim-mean, LDP, CDP, BREA, and RFLPA) under two types of poisoning attacks: gradient manipulation and label flipping. It shows the accuracy for each framework at different proportions of malicious users (0%, 10%, 20%, and 30%) across three datasets (MNIST, Fashion-MNIST, and CIFAR-10). The mean and standard deviation of the accuracy are provided.

This table lists notations used in the paper. It includes notations for model parameters, datasets, learning rates, client sizes, packed secret shares, partial cosine similarities, gradient norms, trust scores, and various matrix operations used within the algorithms. The table is crucial for understanding the mathematical representation and operations described within the paper.

This table compares four different Byzantine-robust aggregation rules: KRUM, Bulyan, Trim-mean, and FLTrust. For each rule, it lists the computation complexity, whether prior knowledge of the number of poisoners is required, the maximum number of poisoners tolerated, and whether the rule is compatible with Shamir Secret Sharing (SSS). The table highlights that FLTrust offers advantages due to its lower computation complexity, lack of prior knowledge requirement, high tolerance for poisoners, and SSS compatibility.
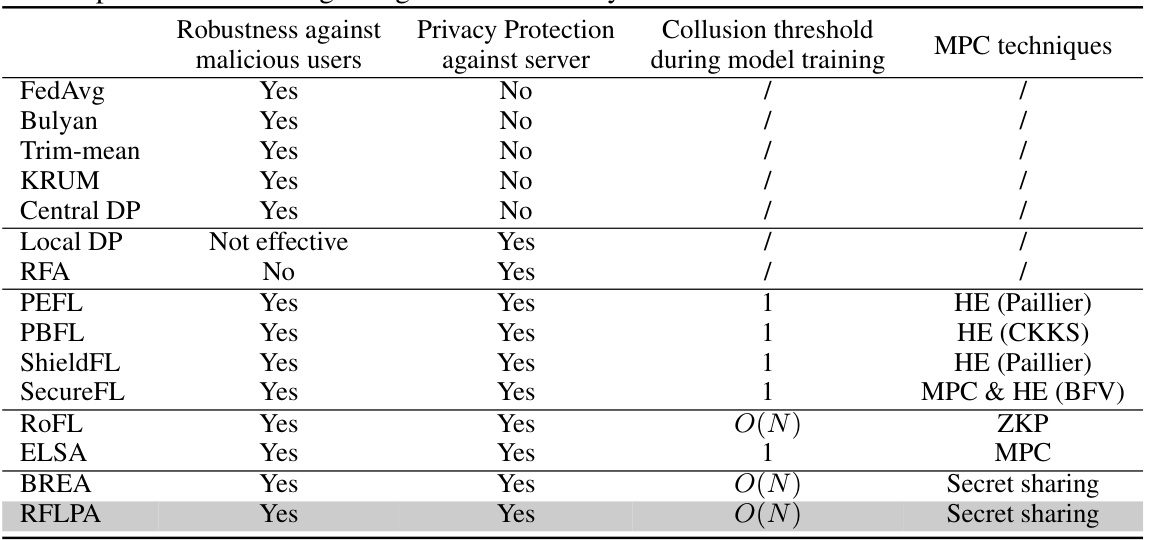
This table compares several federated learning frameworks based on four key aspects: robustness against malicious users, privacy protection against the server, collusion threshold during model training, and the multi-party computation (MPC) techniques used. It highlights the strengths and weaknesses of each framework in terms of its ability to defend against attacks while preserving user privacy, and the computational complexity associated with each approach.

This table compares the accuracies of FedAvg and RFLPA on the CIFAR-10 dataset under different proportions (10%, 20%, 30%) of attackers. It includes results for three types of attacks: KRUM attack (a poisoning attack that targets the model’s robustness), BadNets (a backdoor attack that introduces malicious behavior), and Scaling attack (another type of backdoor attack). For BadNets and Scaling attacks, the table shows both the overall accuracy and the accuracy on the targeted subset of data.

This table presents the accuracy results of three different federated learning frameworks (FedAvg, BREA, and RFLPA) on two natural language processing (NLP) datasets (RTE and WNLI) under varying proportions of malicious attackers (0%, 10%, 20%, and 30%). The results show the robustness of each framework against poisoning attacks by showing how their accuracy changes as the percentage of malicious attackers increases. This allows for a comparison of the resilience of different federated learning approaches to adversarial attacks in NLP tasks.

This table presents the accuracy of the RFLPA and FedAvg models on the CIFAR-100 dataset under gradient manipulation attacks with varying proportions of attackers (0%, 10%, 20%, and 30%). The results show the mean ± standard deviation of the accuracy for each condition. It demonstrates the robustness of RFLPA against these attacks, especially when compared to FedAvg.

This table compares the computation time (in minutes) for RFLPA and three HE-based methods (PEFL, PBFL, ShieldFL) with varying client sizes (100, 200, 300, 400). It shows the per-user cost and the server cost for each method and client size. The results highlight the significant difference in computation time between RFLPA and the HE-based methods, demonstrating the efficiency advantage of RFLPA.

This table presents the communication overhead (in MB) per client for different client sizes (300, 400, 500, 600) when using three different methods: RFLPA, BREA, and RFLPA (KRUM). RFLPA (KRUM) is a variant of RFLPA where the aggregation rule is replaced with KRUM. The results show the communication cost of RFLPA and its KRUM variant are significantly lower than BREA.

This table presents the computation cost for RFLPA, PEFL, PBFL, and ShieldFL with varying client sizes (100, 200, 300, 400). It shows the per-user computation cost and the server computation cost for each algorithm. The table highlights the significant difference in computation time between RFLPA and the HE-based methods (PEFL, PBFL, ShieldFL), demonstrating RFLPA’s efficiency.

This table shows the accuracy of different federated learning frameworks (FedAvg, Bulyan, Trim-mean, LDP, CDP, BREA, and RFLPA) under gradient manipulation and label flipping attacks with varying proportions of malicious users (0%, 10%, 20%, and 30%). The results are presented for three datasets: MNIST, Fashion-MNIST, and CIFAR-10. The table highlights the robustness of RFLPA against poisoning attacks compared to other methods. The mean and standard deviation of the accuracy are reported for each method and attack condition.

This table shows the accuracy of different federated learning frameworks (FedAvg, Bulyan, Trim-mean, LDP, CDP, BREA, and RFLPA) under two types of poisoning attacks (gradient manipulation and label flipping) with varying proportions of malicious users (0%, 10%, 20%, and 30%). The results are presented for three datasets: MNIST, Fashion-MNIST, and CIFAR-10. The table highlights the robustness of each method against poisoning attacks.
Full paper#