↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large language and vision models (LLVMs) are rapidly developing, driven by visual instruction tuning, but face challenges in efficiently handling multifaceted information needed for diverse capabilities. Existing approaches often involve scaling up model size or using additional vision encoders, increasing computational costs. This paper addresses these issues.
The paper proposes Meteor, a novel LLVM based on Mamba architecture and a multimodal language model (MLM), which leverages multifaceted rationale to significantly improve vision language performances. Meteor employs a new concept of “traversal of rationale” for efficient embedding of long rationales. This improves performance without increasing model size or employing additional vision encoders. The experimental results demonstrate that Meteor achieves significant improvements in vision-language performance across multiple evaluation benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces Meteor, a novel and efficient large language and vision model that significantly improves vision-language performance across multiple benchmarks. Its efficiency stems from leveraging multifaceted rationale and a Mamba architecture, eliminating the need for additional vision encoders or scaling up model size. This opens new avenues for developing efficient and powerful LLVMs and contributes to current research trends in visual instruction tuning and multimodal learning. The concept of “traversal of rationale” introduced in the paper offers a unique approach to effectively utilize embedded information, providing significant advancements in vision-language tasks.
Visual Insights#
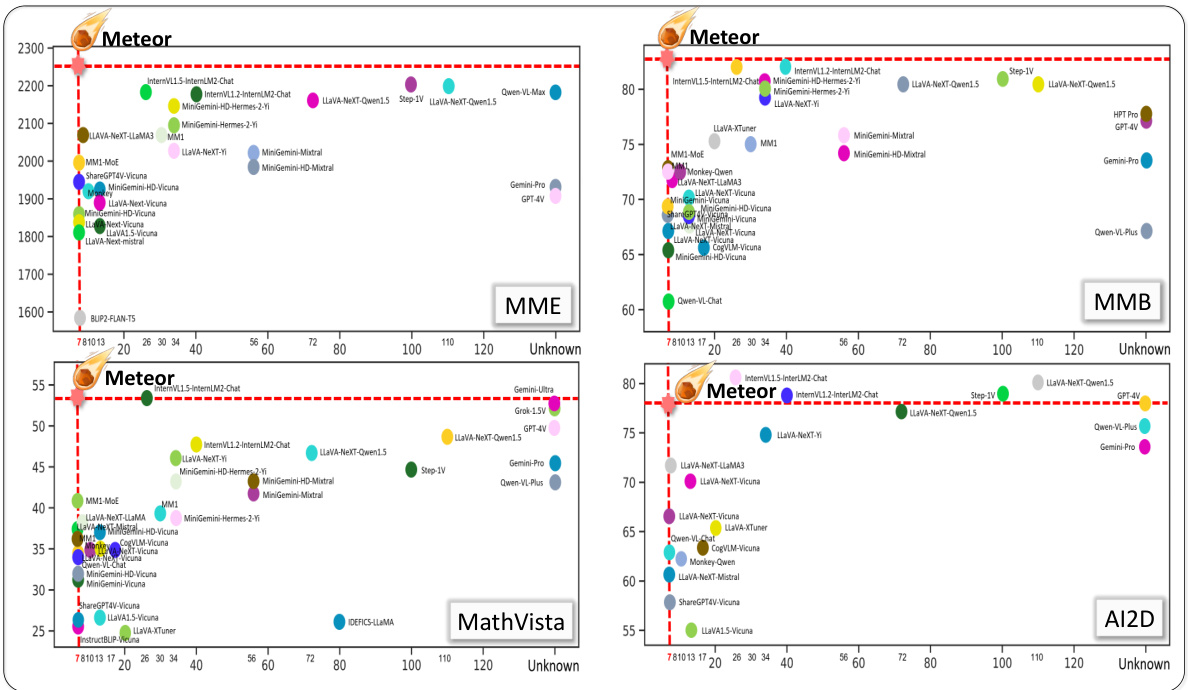
This figure compares the performance of Meteor against various open- and closed-source Large Language and Vision Models (LLVMs) across four different evaluation benchmarks: MME, MMB, MathVista, and AI2D. Each benchmark assesses different aspects of LLM capabilities, including image understanding, common sense reasoning, and non-object concept recognition. The figure shows that Meteor, despite its relatively smaller size, achieves comparable or superior performance to much larger models on these diverse tasks.
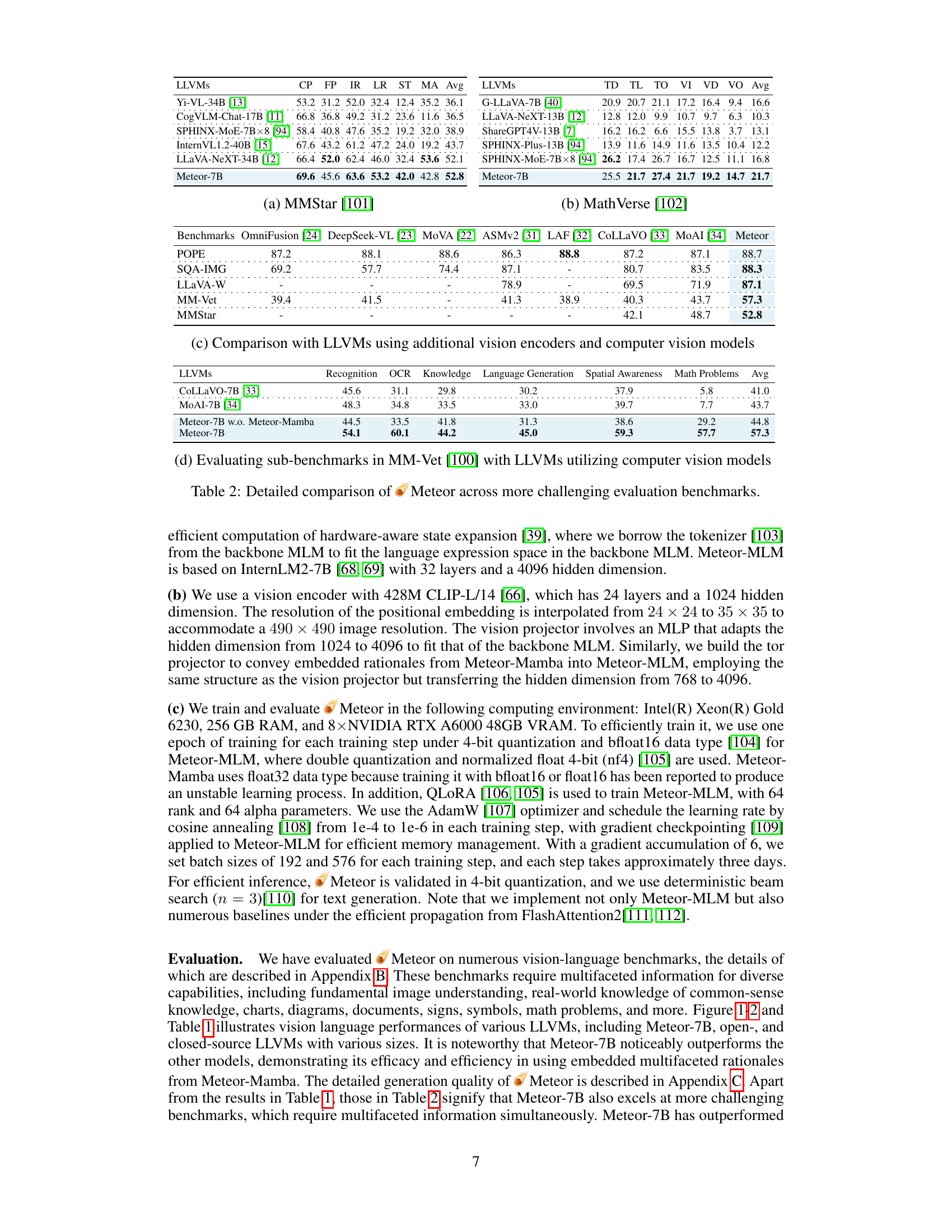
This table compares the performance of the proposed Meteor model with various open-source Large Language and Vision Models (LLVMs) across multiple evaluation benchmarks. The benchmarks test diverse vision-language capabilities, including image understanding, common-sense knowledge, diagram interpretation, and mathematical reasoning. The table highlights Meteor’s improved performance, especially when compared to similar-sized models and those without additional vision encoders or computer vision models. Note that some benchmarks use zero-shot settings for certain models, but Meteor uses the training dataset for a fair comparison.
In-depth insights#
Mamba Rationale#
The concept of “Mamba Rationale” presents an innovative approach to enhance large language and vision models (LLVMs). It leverages the Mamba architecture’s efficiency in processing sequential data to effectively embed lengthy rationales. This multifaceted rationale, enriched with diverse information, including image understanding, real-world knowledge, and step-by-step procedures, is crucial for improved model capabilities. The “traversal of rationale” method cleverly introduces special tokens to guide the model’s access and use of the embedded rationale during inference, without relying on external APIs. This efficient embedding and traversal mechanism, central to “Mamba Rationale,” enables significant performance improvements across various benchmarks. The approach contrasts with existing methods that often rely on scaling up model size or using additional vision encoders. The implicit embedding of rich information within the Mamba architecture makes “Mamba Rationale” a particularly efficient and promising technique for enhancing LLM performance.
Multifaceted Info#
The concept of “Multifaceted Info” in a research paper likely refers to the complex and diverse nature of information required for advanced AI models, particularly large language and vision models (LLVMs). It suggests that these models need more than just basic image recognition or textual understanding; they require common-sense reasoning, knowledge of non-object concepts (e.g., charts, symbols), and step-by-step procedural understanding to solve complex tasks. This multifaceted nature means simply scaling up model size or adding more vision encoders is insufficient. The paper likely proposes a novel approach to integrate this rich, multifaceted information effectively, improving the model’s reasoning and problem-solving capabilities without significant resource increases. Efficient embedding and processing of this diverse information are key challenges addressed, implying innovative architectural designs or training techniques. This concept highlights a shift towards more holistic and human-like understanding in AI, moving beyond the limitations of solely data-driven approaches.
Efficient LLMs#
Efficient LLMs are a crucial area of research, focusing on reducing computational costs without sacrificing performance. Model compression techniques, such as pruning, quantization, and knowledge distillation, are key strategies. Architectural innovations could lead to more efficient designs, possibly through novel attention mechanisms or transformer-like architectures with reduced complexity. Training methodologies also play a critical role. Efficient training algorithms, including techniques that reduce memory footprint and improve parallelization, are vital. Hardware acceleration is another important aspect, involving specialized chips designed to optimize LLM operations and reduce power consumption. Ultimately, developing efficient LLMs involves a multifaceted approach, combining advancements across model design, training, and hardware.
Ablation Studies#
Ablation studies systematically investigate the contribution of individual components within a machine learning model. By removing or altering specific parts (e.g., modules, hyperparameters, datasets), researchers assess their impact on overall model performance. This helps to determine which elements are crucial for success and which are less important or even detrimental. Thoughtful design of ablation experiments is critical. Variations should be controlled and incremental. The results offer valuable insights into the model’s architecture, identifying strengths and weaknesses. Furthermore, ablation studies can guide improvements, such as architectural refinements or optimization strategies, highlighting areas deserving of further investigation and resource allocation. They also provide evidence that the model’s performance is not solely due to a single component but is indeed a result of the synergistic interplay of its individual parts.
Future Work#
Future research directions could explore extending Meteor’s capabilities to handle even more complex reasoning tasks and improving its efficiency on resource-constrained devices. Investigating alternative embedding methods beyond Mamba for handling lengthy rationales would be valuable. Furthermore, researching more robust methods for rationale generation and curation would enhance the quality and diversity of information available to Meteor. A promising area would be to analyze the impact of different rationale structures on model performance and explore techniques for optimizing rationale traversal. Finally, evaluating Meteor’s performance on a wider range of vision-language benchmarks and exploring its potential for applications beyond question-answering, such as image captioning and generation, is critical.
More visual insights#
More on figures

This figure compares the performance of Meteor against various open- and closed-source Large Language and Vision Models (LLVMs) across multiple evaluation benchmarks. These benchmarks (MME, MMB, MathVista, and AI2D) test diverse capabilities, including image understanding, common sense reasoning, and non-object concept comprehension. The figure visually demonstrates Meteor’s performance improvements across a wide range of model sizes.
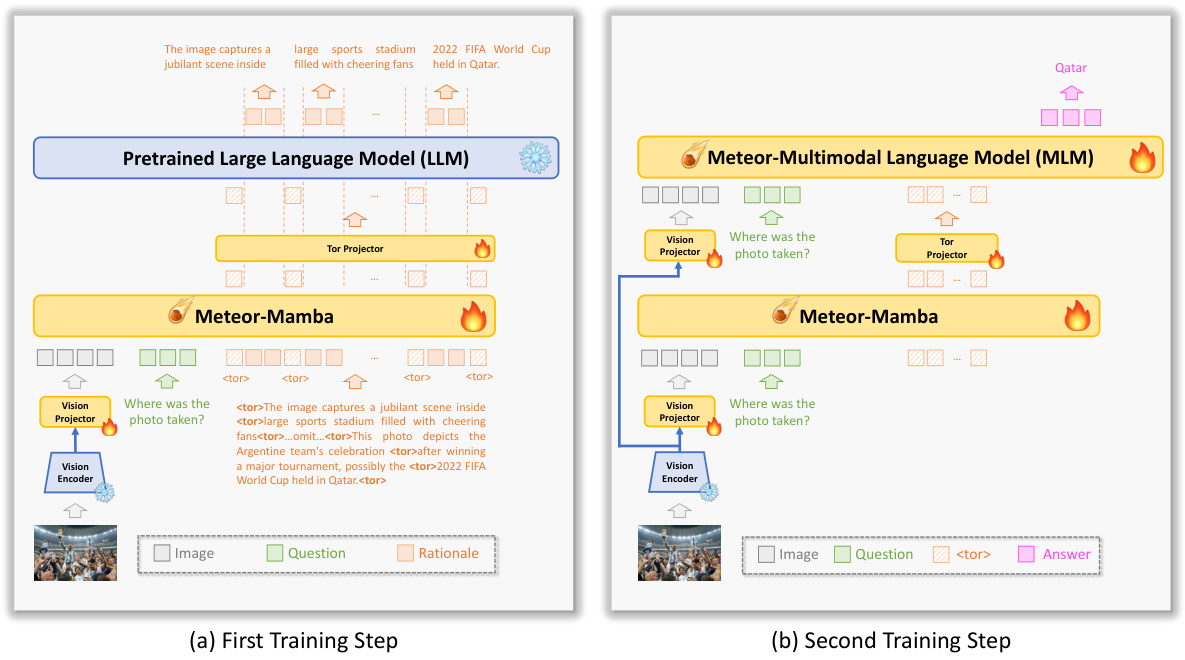
This figure illustrates the architecture of Meteor and its two-step training process. The first step involves training Meteor-Mamba (a Mamba-based architecture) to embed long sequential rationales using question-rationale pairs. The second step trains the entire Meteor model (including Meteor-Mamba and Meteor-MLM, a multimodal language model) on question-rationale-answer triples, leveraging the embedded rationales from the first step. The figure visually represents how the input (image, question, rationale) is processed through the vision encoder, vision projector, Meteor-Mamba, tor projector, and finally the Meteor-MLM to generate the answer. The use of ‘
’ tokens highlights the concept of ’traversal of rationale’ for efficient embedding and passing of information.
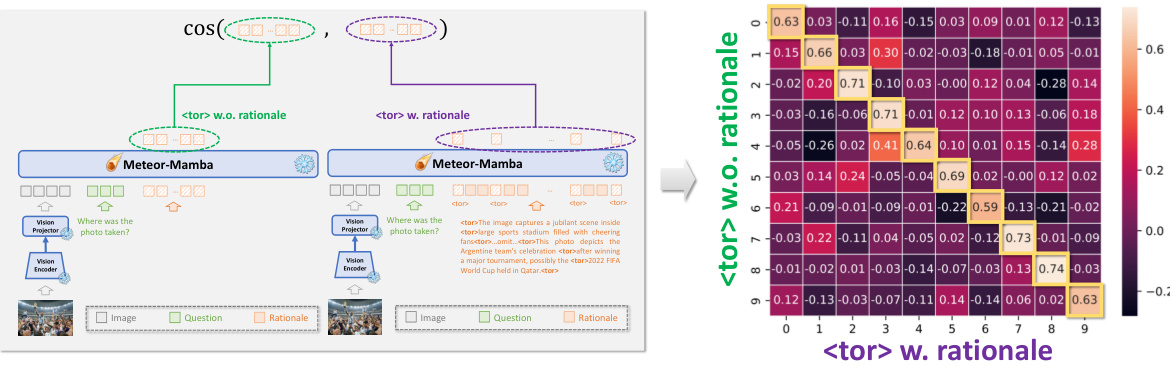
This figure shows the cosine similarity matrix between the feature vectors obtained from Meteor-Mamba with and without rationales. The diagonal values show high similarity, indicating successful embedding of rationales, while off-diagonal values indicate low similarity. This visualization supports the claim that Meteor-Mamba effectively embeds the rationales even without explicit rationales.

This figure compares the performance of Meteor against various open- and closed-source Large Language and Vision Models (LLVMs) across several benchmarks. The benchmarks (MME, MMB, MathVista, AI2D) evaluate diverse capabilities, including image understanding, common sense reasoning, and non-object concept understanding. The figure demonstrates Meteor’s competitive performance across a range of model sizes, highlighting its efficiency in achieving strong results without requiring large model sizes or additional computer vision modules.
This figure compares the performance of Meteor against various open- and closed-source LLMs across different benchmarks (MME, MMB, MathVista, and AI2D). These benchmarks test a range of capabilities, including image understanding, common sense reasoning, and understanding non-object concepts. The figure shows that Meteor achieves significant performance improvements across all benchmarks, even with a smaller model size compared to other LLMs.

This figure compares the performance of Meteor against various open- and closed-source Large Language and Vision Models (LLVMs) across multiple evaluation benchmarks. These benchmarks assess diverse capabilities, including image understanding, common sense reasoning, and non-object concept understanding. The results show Meteor’s performance relative to other LLVMs of varying sizes.

This figure compares the performance of Meteor against various open- and closed-source Large Language and Vision Models (LLVMs) across multiple evaluation benchmarks. These benchmarks test diverse capabilities, such as image understanding, common sense reasoning, and non-object concept understanding. The results show that Meteor achieves significant improvements over the other LLVMs, even those with substantially larger parameter counts, on a range of tasks.

This figure compares the performance of Meteor against various other open- and closed-source Large Language and Vision Models (LLVMs) across multiple evaluation benchmarks. The benchmarks (MME, MMB, MathVista, AI2D) test diverse capabilities including image understanding, common sense reasoning, and non-object concept understanding. The figure shows that Meteor achieves significant improvements, even with smaller model sizes, compared to other models.

This figure compares the performance of Meteor against various open and closed-source Large Language and Vision Models (LLVMs) across four different benchmark datasets: MME, MMB, MathVista, and AI2D. These benchmarks test a wide range of capabilities, including image understanding, common sense reasoning, and non-object concept understanding. The figure showcases Meteor’s performance relative to other models, demonstrating its ability to achieve competitive results without needing larger model sizes or additional vision encoders.

This figure compares the performance of Meteor against various open-source and closed-source large language and vision models (LLVMs) across four different benchmark datasets: MME, MMB, MathVista, and AI2D. Each dataset tests different aspects of LLM capabilities, such as image understanding, common sense reasoning, and non-object concept understanding. The figure demonstrates that Meteor achieves significant improvements across these benchmarks without increasing the model size or using additional vision encoders.
This figure compares the performance of Meteor against various open-source and closed-source Large Language and Vision Models (LLVMs) across multiple evaluation benchmarks (MME, MMB, MathVista, and AI2D). These benchmarks assess diverse capabilities, including image understanding, common-sense reasoning, and non-object concept understanding. The figure demonstrates that Meteor achieves significant improvements compared to other models without increasing model size or using additional vision encoders.
This figure compares the performance of Meteor against various open and closed-source Large Language and Vision Models (LLVMs) across different benchmarks. The benchmarks (MME, MMB, MathVista, and AI2D) test diverse capabilities, including image understanding, common sense reasoning, and non-object concept understanding. The figure shows that Meteor achieves significant improvements compared to other models, even those with substantially larger numbers of parameters.
This figure compares the performance of Meteor against various open-source and closed-source Large Language and Vision Models (LLVMs) across four different benchmark datasets (MME, MMB, MathVista, AI2D). The datasets evaluate diverse capabilities, including image understanding, common sense reasoning, and non-object concept understanding. The x-axis likely represents the model size (parameters) while the y-axis shows the performance scores on each benchmark. The figure demonstrates Meteor’s superior performance across all benchmarks and various model sizes.

This figure compares the performance of Meteor against other open- and closed-source Large Language and Vision Models (LLVMs) across various benchmarks (MME, MMB, MathVista, and AI2D). These benchmarks assess diverse capabilities, including image understanding, common-sense reasoning, and non-object concept comprehension. The figure visually demonstrates Meteor’s performance improvements across different model sizes (7B to over 110B parameters).

This figure compares the performance of Meteor against various open- and closed-source Large Language and Vision Models (LLVMs) across multiple evaluation benchmarks. The benchmarks (MME, MMB, MathVista, and AI2D) test diverse capabilities including image understanding, common-sense reasoning, and non-object concept understanding. The figure demonstrates Meteor’s improved performance across a wide range of model sizes.

This figure compares the performance of Meteor against various open and closed-source Large Language and Vision Models (LLVMs) across multiple evaluation benchmarks. The benchmarks assess diverse capabilities, including image understanding, common-sense reasoning, and non-object concept understanding. The figure shows Meteor’s performance across different model sizes (from 7B to over 110B parameters), highlighting its improvements over other LLVMs without requiring additional vision encoders or computer vision models.

This figure provides a visual representation of the Meteor architecture and training process. It shows two main steps: the first training step focuses on training Meteor-Mamba (the Mamba architecture component) to efficiently embed long sequential rationales. The second training step involves jointly training all components of Meteor (Meteor-Mamba, vision projector, tor projector, and Meteor-MLM) using curated question-rationale-answer triples. The figure highlights the flow of information during training and the role of each component in generating answers.

This figure compares the performance of Meteor against various open- and closed-source Large Language and Vision Models (LLVMs) across different benchmark datasets. The benchmarks (MME, MMB, MathVista, and AI2D) test a range of capabilities including image understanding, common sense reasoning, and non-object concept recognition. The figure demonstrates Meteor’s performance improvement across various model sizes, highlighting its efficiency in achieving strong results without needing to scale up the model size or utilize additional computer vision models.

This figure compares the performance of Meteor against various open- and closed-source Large Language and Vision Models (LLVMs) across multiple evaluation benchmarks. The benchmarks (MME, MMB, MathVista, and AI2D) test diverse capabilities, including image understanding, common sense reasoning, and non-object concept understanding. The figure highlights Meteor’s performance improvements without increasing model size or adding vision encoders.

This figure compares the performance of various open-source and closed-source Large Language and Vision Models (LLVMs) against the proposed model, Meteor, across multiple evaluation benchmarks (MME, MMB, MathVista, AI2D). The benchmarks test diverse capabilities, including image understanding, common-sense knowledge, and non-object concept understanding. The figure shows Meteor outperforming most other models, even those with significantly larger parameter counts.

This figure compares the performance of Meteor against various open- and closed-source Large Language and Vision Models (LLVMs) across multiple evaluation benchmarks. The benchmarks (MME, MMB, MathVista, and AI2D) require diverse capabilities, testing image understanding, common-sense reasoning, and understanding of non-object concepts. The figure visually represents the performance differences, highlighting Meteor’s improved capabilities across different model sizes (7B to 110B+ parameters).
This figure compares the performance of Meteor against various open-source and closed-source Large Language and Vision Models (LLVMs) across multiple evaluation benchmarks. These benchmarks test diverse capabilities, including image understanding, common-sense reasoning, and understanding of non-object concepts. The results show that Meteor achieves significant improvements compared to other models without increasing model size or adding additional vision encoders.

This figure compares the performance of Meteor against various open and closed source Large Language and Vision Models (LLVMs) across a range of evaluation benchmarks that test diverse capabilities like image understanding, commonsense reasoning, and non-object concept recognition. The benchmarks used are MME, MMB, MathVista, and AI2D. The figure shows that Meteor performs competitively even with significantly larger models, highlighting its efficiency in leveraging multifaceted rationales.

This figure illustrates the architecture of the Meteor model and its two-step training process. The first step trains the Meteor-Mamba component (a Mamba architecture module) to embed long sequential rationales. The second step jointly trains all components of Meteor (including Meteor-Mamba, a vision projector, a tor projector, and Meteor-MLM, which is a multimodal language model based on a pretrained LLM) using question-answer pairs. The figure visually explains the flow of information and the roles of each component in the model. The concept of ’traversal of rationale’ is also depicted, showing how lengthy rationales are effectively handled using special tokens.
More on tables

This table compares the performance of Meteor with other open-source Large Language and Vision Models (LLVMs) across various vision-language benchmarks. The benchmarks assess diverse capabilities including image understanding, common-sense knowledge, and non-object concept understanding. Note that some comparisons are made under different testing conditions (zero-shot vs. using a training dataset).

This table compares the performance of Meteor against other LLMs on more challenging benchmarks that require diverse capabilities such as image understanding, real-world knowledge, and non-object concept understanding. It shows Meteor’s performance on several tasks (MMStar, MathVerse, etc.) across various model sizes. The results highlight Meteor’s efficiency and its improvements over various open- and closed-source LLMs, even those using additional vision encoders or multiple computer vision models.

This table presents a detailed comparison of the Meteor model’s performance against other state-of-the-art Large Language and Vision models (LLVMs) across various challenging evaluation benchmarks. It highlights Meteor’s capabilities in different aspects of vision and language understanding and how it compares to other models that employ additional vision encoders or computer vision models. The benchmarks used represent diverse and complex tasks requiring multifaceted information and capabilities.
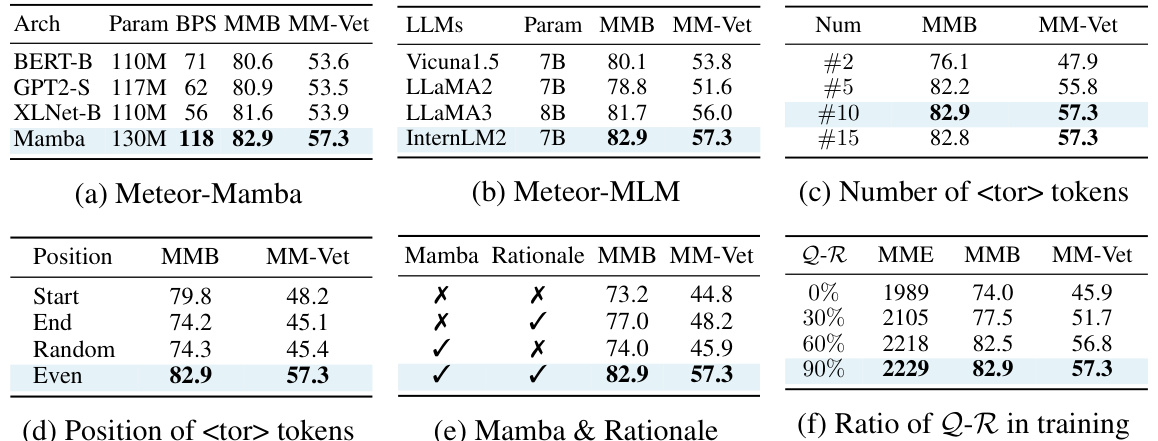
This table presents ablation study results to analyze the impact of different factors on the performance of Meteor, a multimodal language and vision model. The factors include the use of Meteor-Mamba (the embedding module), Meteor-MLM (the main model), the number and distribution of special tokens (
), the inclusion of rationales, and the ratio of question-rationale pairs in the training data. Each row represents a different experimental configuration, demonstrating the relative contribution of each component to the overall performance. The results highlight the importance of the multifaceted rationale, the Mamba architecture, and the appropriate placement of tokens for optimal performance.
This table presents a detailed comparison of the Meteor model’s performance against other LLMs on more challenging evaluation benchmarks. It highlights Meteor’s performance across various tasks requiring diverse capabilities such as image understanding, common-sense reasoning, and non-object concept understanding. The benchmarks used include MMStar, MathVerse, and a comparison against LLMs using additional vision encoders and computer vision models.

This table presents a performance comparison between the proposed model, Meteor, and a variant incorporating the LLaVA-HR model, across six different vision-language benchmarks (AI2D, ChartQA, MathVista, MM-Vet, LLaVAW, and MMStar). Each benchmark assesses various aspects of vision-language capabilities, allowing for a comprehensive evaluation of the models’ performance on diverse tasks.

This table presents the performance results of Meteor-Mamba models with varying sizes (130M, 790M, and 1.4B parameters) across six different vision-language tasks: AI2D, ChartQA, MathVista, MM-Vet, LLaVAW, and MMStar. It shows how the performance on these tasks changes as the model size increases. The results demonstrate the impact of model size on the various vision-language capabilities assessed by these benchmark datasets.

This table compares the token processing speed of five different large language and vision models: Qwen-VL, LLaVA1.5, CoLLaVO, MoAI, and Meteor. The speed is measured in tokens per second. The table shows that Meteor and LLaVA1.5 have similar processing speeds, which are faster than CoLLaVO and MOAI. Qwen-VL has the slowest processing speed.

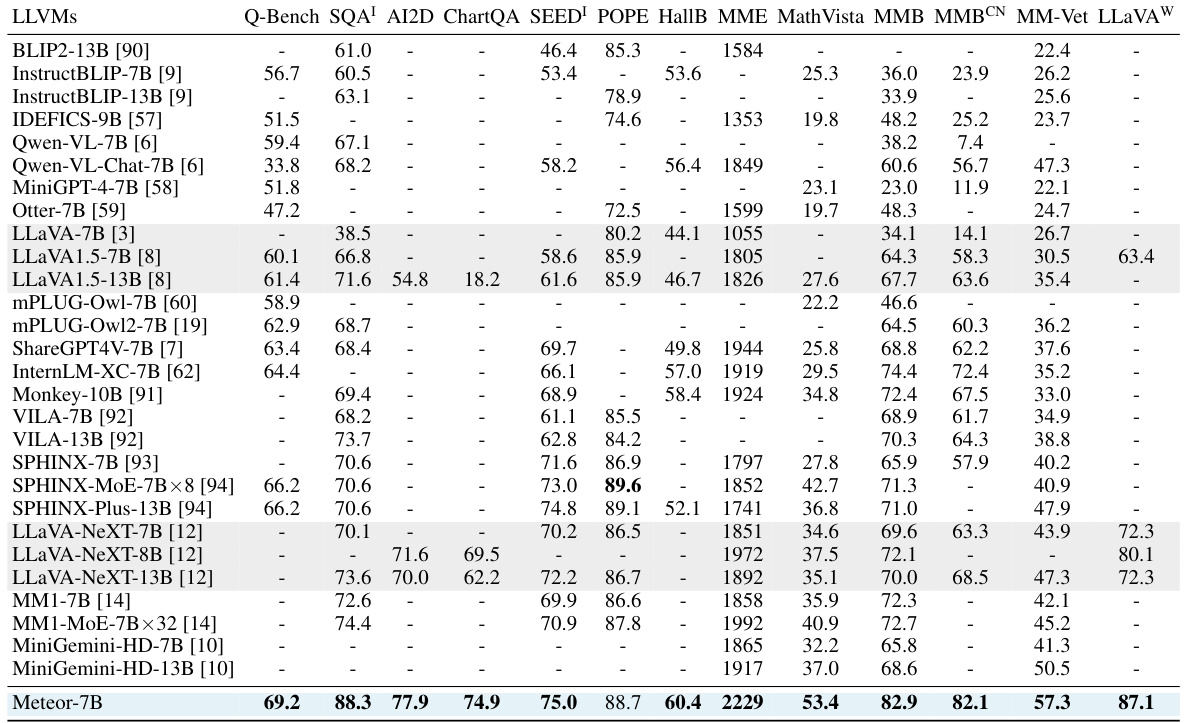
This table compares the performance of various Large Language and Vision Models (LLVMs) across multiple vision-language tasks. The tasks are: VQAv2, GQA, SQA-IMG, TextVQA, POPE, MMB, and MM-Vet. Each task assesses different aspects of visual and language understanding. Meteor is shown to have superior performance in most cases.

This table compares the performance of different Large Language and Vision Models (LLVMs) on three specific tasks within the LLaVAW benchmark: Conversation, Detail Description, and Complex Reasoning. The models compared are CoLLaVO, MoAI, Meteor without the Meteor-Mamba component, and Meteor with Meteor-Mamba. The average performance across all three tasks is also provided. The results show a significant performance improvement when using Meteor with Meteor-Mamba compared to the other models, highlighting the benefit of incorporating multifaceted rationale.
Full paper#