↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current auditory attention detection (AAD) struggles with capturing spatial distribution in EEG signals and long-range dependencies, leading to limitations in decoding brain activity. Existing methods often rely on linear models or overlook spatial information, resulting in suboptimal performance, particularly with shorter decision windows.
DARNet addresses these issues by incorporating a spatiotemporal construction module and a dual attention refinement module. The spatiotemporal module constructs expressive features, while dual attention enhances the model’s ability to capture long-range dependencies. Experiments on three datasets (DTU, KUL, MM-AAD) show that DARNet substantially outperforms state-of-the-art models, demonstrating superior performance, especially under short decision windows (0.1 seconds), all while achieving a remarkable 91% reduction in parameters.
Key Takeaways#
Why does it matter?#
This paper is important because it presents DARNet, a novel approach to auditory attention detection that significantly outperforms existing methods, especially with short decision windows. Its efficiency, reducing parameters by 91%, makes it highly practical for real-world applications. The innovative use of spatiotemporal construction and dual attention refinement opens new avenues for research in EEG-based brain-computer interfaces.
Visual Insights#

This figure shows the architecture of the DARNet model. It consists of three main modules: 1) Spatiotemporal Construction Module which takes CSP (Common Spatial Patterns) from EEG signals as input and outputs temporal patterns using temporal and spatial convolutional layers. 2) Dual Attention Refinement Module, which takes the output of the previous module and uses a dual-layer self-attention mechanism to refine features and capture long-range dependencies. 3) Feature Fusion & Classifier Module, which takes the output of the previous module, fuses the features from different levels, and makes final classification using a fully connected layer.
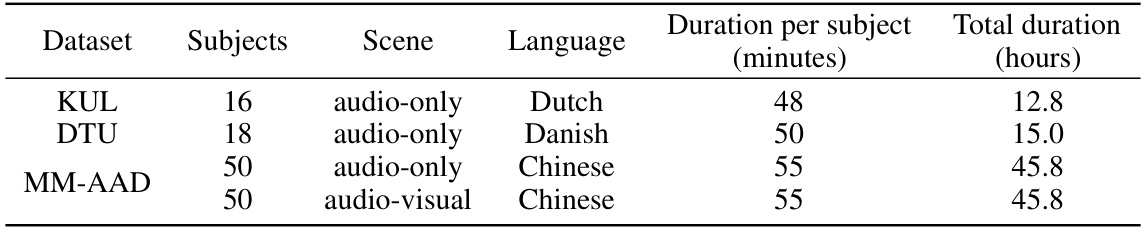
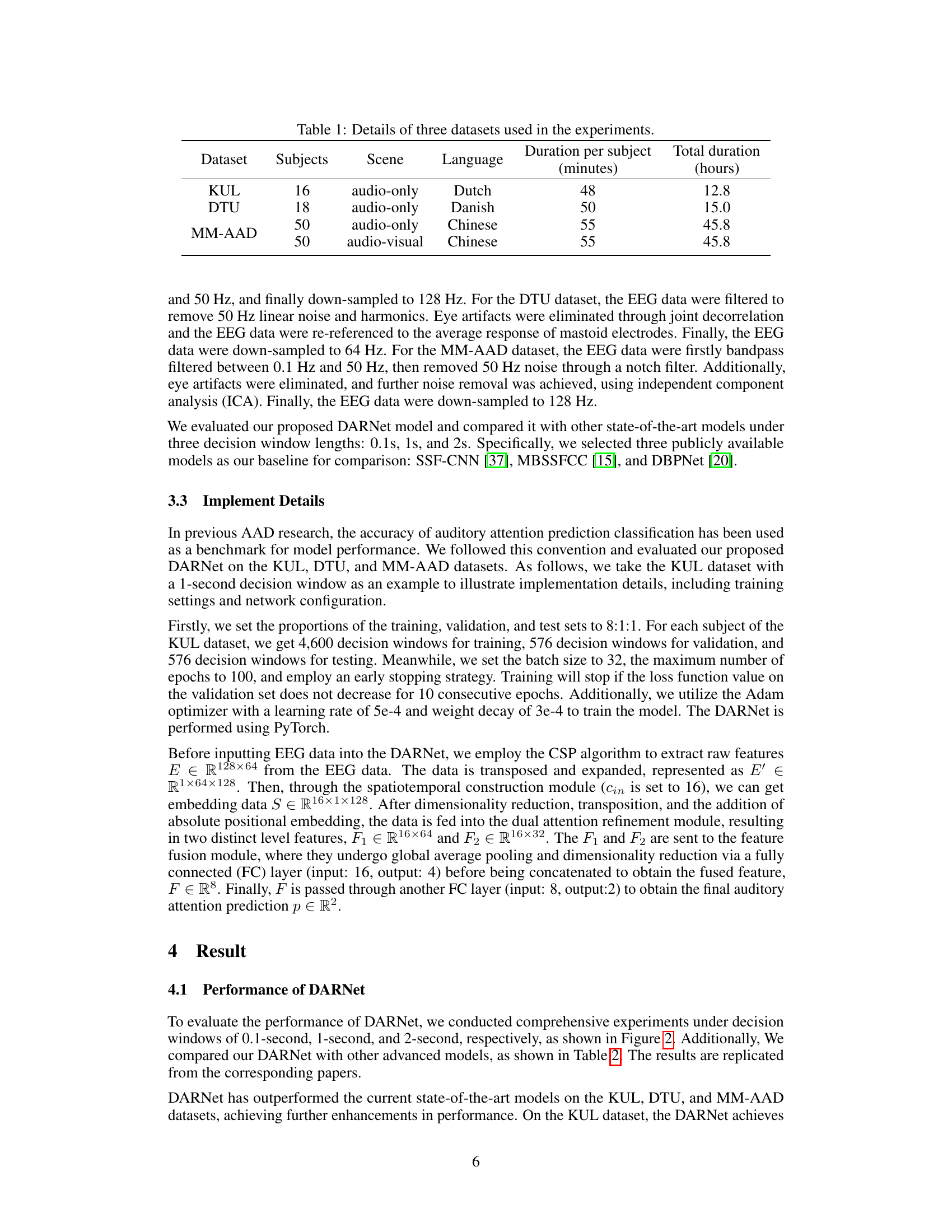
This table summarizes the key characteristics of the three datasets (KUL, DTU, and MM-AAD) used in the paper’s experiments. For each dataset, it provides the number of subjects, the type of scene (audio-only or audio-visual), the language of the auditory stimuli, the duration of each subject’s participation in minutes, and the total duration of the dataset in hours.
In-depth insights#
Auditory Attention#
Auditory attention, the ability to selectively focus on a specific sound amidst background noise, is a complex cognitive process. Research on auditory attention utilizes brain signals, such as EEG, to understand neural activity patterns associated with selective listening. Current AAD (auditory attention detection) algorithms often overlook crucial spatial distribution information within EEG data and struggle to capture long-range dependencies, limiting their effectiveness. DARNet addresses these limitations by incorporating a spatiotemporal construction module to capture both spatial distribution and temporal dynamics of EEG signals. A dual attention refinement module enhances the model’s ability to extract temporal patterns and long-range dependencies, leading to improved performance, particularly under short decision windows. DARNet shows significant parameter reduction compared to current state-of-the-art models while maintaining superior accuracy across various datasets. Future work could explore transferring this model to real-world scenarios and investigating its performance in subject-independent settings to further advance auditory attention research.
DARNet Model#
The DARNet model, a novel dual attention refinement network, is designed for auditory attention detection (AAD) using EEG signals. Its core innovation lies in the spatiotemporal construction module, which effectively captures spatial distribution characteristics and dynamic temporal patterns of EEG data, overcoming limitations of previous methods that focused solely on temporal or spatial aspects. This module lays the groundwork for the dual attention refinement module, enhancing the model’s ability to extract temporal patterns at multiple levels, particularly those exhibiting long-range dependencies. The feature fusion and classification module then aggregates these refined patterns, leading to a robust classification of auditory attention. DARNet’s performance significantly surpasses state-of-the-art models, particularly under short decision windows, all while drastically reducing the number of parameters. This efficiency makes the model suitable for resource-constrained applications, thereby demonstrating considerable potential for real-world implementation in brain-computer interfaces and related fields.
EEG Feature Extraction#
Extracting meaningful features from electroencephalography (EEG) data is crucial for accurate auditory attention detection. Common Spatial Patterns (CSP) is a frequently used technique, effectively highlighting variance differences between brain states related to focused attention. However, CSP alone may not fully capture the intricate temporal dynamics. Therefore, advanced methods often incorporate time-frequency analysis, such as wavelet transforms or short-time Fourier transforms, to unveil latent patterns across different frequency bands and time windows. Convolutional Neural Networks (CNNs), particularly effective at processing spatial information, are frequently combined with temporal processing techniques like recurrent neural networks (RNNs) or self-attention mechanisms to model complex spatiotemporal dependencies. Self-attention, capable of capturing long-range dependencies crucial to understanding brain activity, has emerged as a powerful tool. This rich array of approaches underscores the ongoing quest for sophisticated EEG feature extraction methods that are sensitive to the subtleties of auditory attention processing in the brain.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of this research paper, an ablation study would likely involve removing parts of the DARNet architecture (e.g., the spatial feature extraction module, the temporal feature extraction module, the dual attention refinement module, or the feature fusion module) one at a time to determine how each component impacts overall performance. The results would demonstrate the importance of each module and validate the design choices. By comparing the performance of the full model to the performance of the models with these components removed, researchers can quantitatively evaluate the contribution of each component to the model’s accuracy and robustness. This is crucial for understanding the model’s inner workings and for identifying potential areas for improvement. The ablation study also likely investigates the effect of using a single-layer attention refinement module instead of the dual-layer module, assessing the trade-off between model complexity and performance. The results would inform future model development and provide insights into the most effective components of the DARNet architecture. The ablation study is a critical component in evaluating not only the performance of the DARNet model but also the contribution of each of its individual modules to overall model performance. It allows for a better understanding of the architecture’s strengths and weaknesses and guides further development and optimization.
Future Work#
Future research directions for auditory attention detection (AAD) could explore several promising avenues. Improving the robustness of AAD models to noise and individual variability is crucial for real-world applications. This could involve incorporating advanced signal processing techniques for noise reduction and developing more sophisticated algorithms that adapt to the unique characteristics of individual brain signals. Exploring alternative brain signal modalities, such as fMRI or MEG, in combination with EEG, might offer a more comprehensive understanding of auditory attention. The integration of multimodal data would require innovative algorithms and careful consideration of data fusion techniques. Another critical area is expanding AAD to more complex listening scenarios, such as those involving multiple speakers with overlapping speech or competing sounds. Developing models capable of disentangling these overlapping auditory inputs will be a significant challenge, but could greatly advance the application of AAD in everyday environments. Finally, developing benchmark datasets with diverse auditory stimuli and subject demographics is important to rigorously evaluate AAD models and ensure generalization to real-world populations. This holistic approach will not only refine current algorithms but will push the boundaries of AAD, creating powerful tools for understanding and aiding human auditory attention.
More visual insights#
More on figures

This figure shows the performance of the DARNet model on three different datasets (KUL, DTU, and MM-AAD) across all subjects. The x-axis represents the length of the decision window (0.1s, 1s, and 2s), and the y-axis represents the accuracy of auditory attention detection. The box plots show the distribution of accuracy across all subjects for each dataset and decision window length. The results visually demonstrate the model’s performance across various decision window lengths and datasets.

The figure shows the performance of DARNet across three datasets (KUL, DTU, and MM-AAD) under different decision window lengths (0.1s, 1s, and 2s). The box plots illustrate the distribution of accuracy across all subjects for each dataset and window length. The median accuracy is shown as a point within each box, representing the typical performance. The boxes themselves span the interquartile range (IQR), meaning the middle 50% of the data. The whiskers extend to 1.5 times the IQR from each end of the box, capturing most of the data distribution. Points outside the whiskers represent outliers, indicating exceptional results.
More on tables
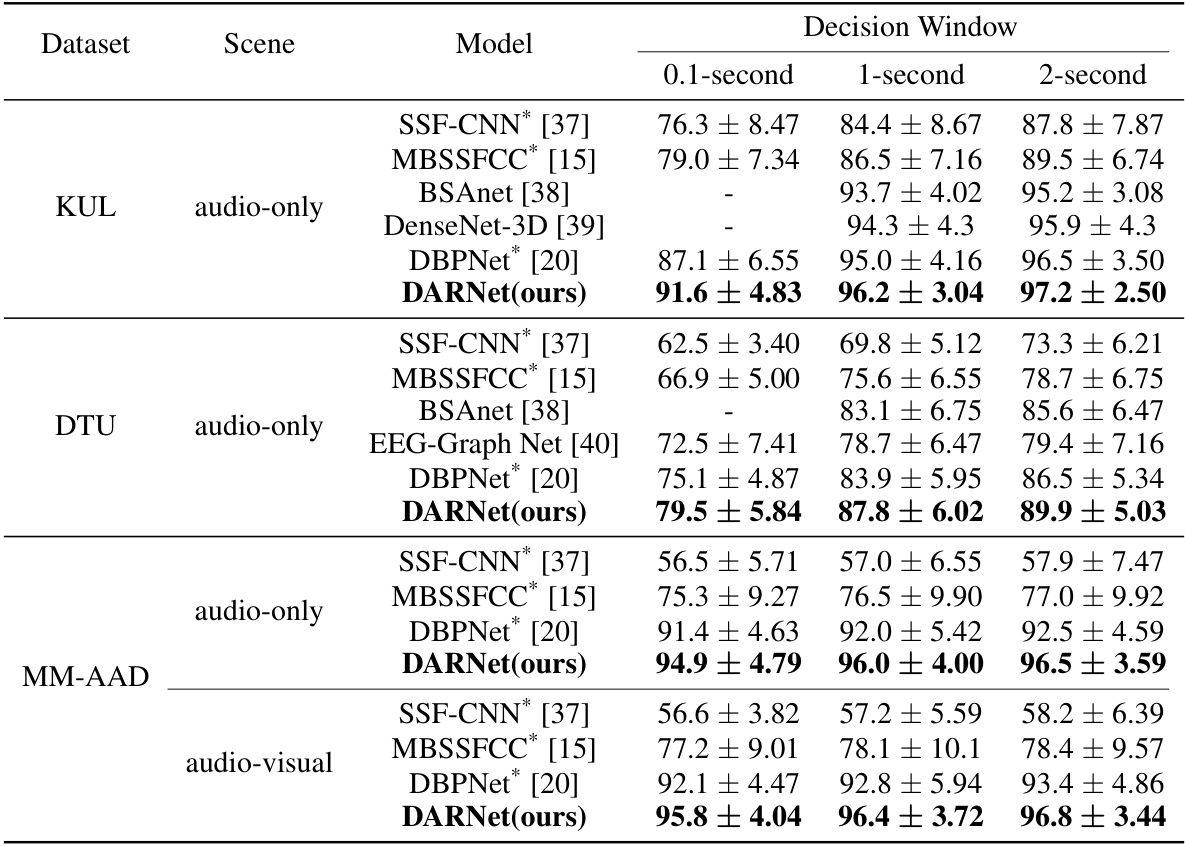
This table compares the performance of DARNet with other state-of-the-art models (SSF-CNN, MBSSFCC, BSAnet, DenseNet-3D, EEG-Graph Net, and DBPNet) on three publicly available datasets (KUL, DTU, and MM-AAD) for auditory attention detection. The accuracy is measured using three different decision windows (0.1-second, 1-second, and 2-second) for audio-only and audio-visual scenes, showing DARNet’s superior performance in all settings.

This table presents the results of ablation experiments performed on three datasets (KUL, DTU, and MM-AAD) to evaluate the impact of different modules in the DARNet model on auditory attention detection accuracy. The table shows the performance of the model with various components removed, such as the spatial feature extraction, the temporal feature extraction, and the feature fusion modules. It also shows the performance of a simplified version of DARNet with only a single layer of self-attention. This helps to understand which components are most important to the overall performance of the model.
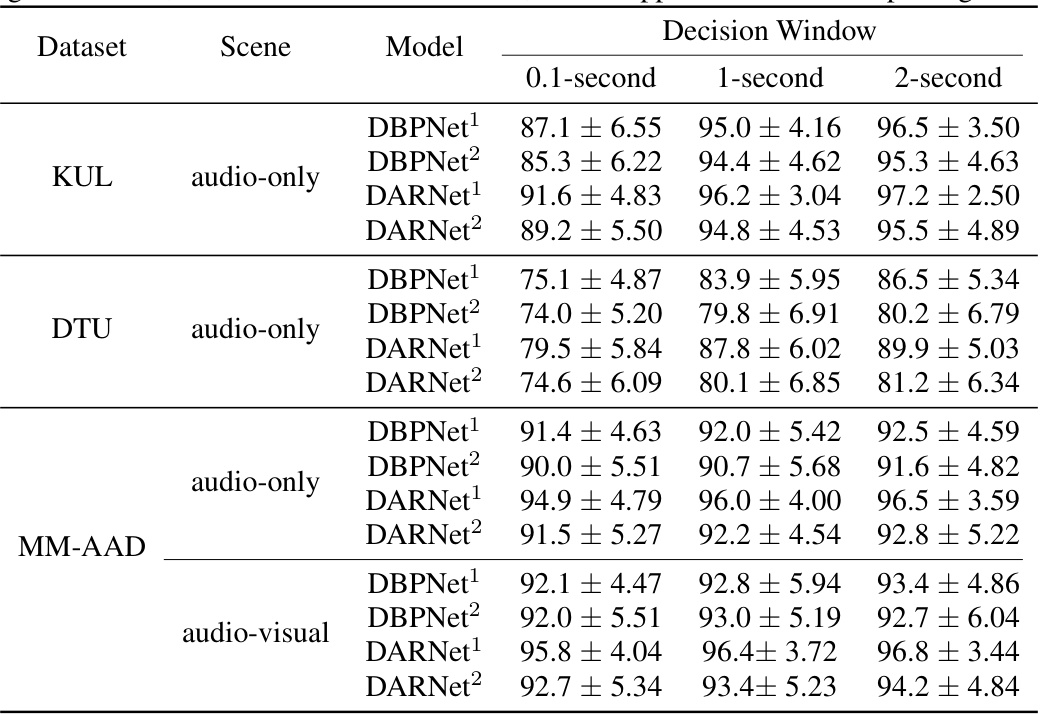
This table compares the auditory attention detection accuracy of the proposed DARNet model against other state-of-the-art models across three different datasets (DTU, KUL, and MM-AAD) under three different decision window lengths (0.1, 1, and 2 seconds). The results show the mean accuracy and standard deviation for each model and dataset. The asterisk indicates results taken from a previous study, ensuring a fair comparison.

This table compares the number of trainable parameters for four different models: SSF-CNN, MBSSFCC, DBPNet, and DARNet. It highlights that DARNet has significantly fewer parameters (0.08 million) compared to the others, demonstrating its computational efficiency.
Full paper#