↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Cognitive Diagnosis (CD) aims to assess learners’ knowledge proficiency. Existing CD models primarily focus on individual learner data, neglecting valuable collaborative information. This paper highlights the challenge of identifying implicit collaborative connections and disentangling entangled cognitive factors, hindering explainability and controllability in CD.
The authors propose Coral, a Collaborative cognitive diagnosis model. Coral employs disentangled representation learning to initially disentangle learners’ states, and a collaborative representation learning procedure captures collaborative signals via a dynamically constructed learner graph. Coral achieves co-disentanglement, aligning individual and collaborative states for improved practice performance reconstruction. Experiments demonstrate Coral’s superior performance over existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Coral, a novel approach to cognitive diagnosis that leverages collaborative learning and disentangled representations. This addresses limitations of existing methods and improves diagnostic accuracy. The proposed context-aware collaborative graph learning and co-disentanglement techniques are significant contributions to learner modeling, opening avenues for further research in personalized learning and intelligent tutoring systems.
Visual Insights#
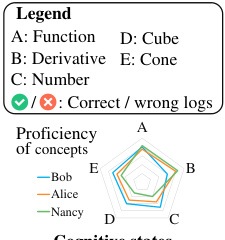
This figure illustrates a scenario of human learning where three learners (Bob, Alice, and Nancy) are working on questions related to different knowledge concepts (Function, Derivative, Number, Cube, Cone). The table shows each learner’s correct/incorrect responses for a set of questions. Each question assesses at least one concept. The figure highlights the idea that learners with similar implicit knowledge states (understanding of concepts) exhibit similar performance on similar questions, which is a key idea that motivates the collaborative learner modeling approach discussed in the paper.
This table presents the statistics for three datasets used in the paper: ASSIST, Junyi, and NeurIPS2020EC. It shows the number of students, questions, knowledge concepts, concepts per exercise, total records, records per student, and the ratio of correct to incorrect records for each dataset. This information is crucial for understanding the characteristics of the data used to evaluate the proposed model and compare it to baselines.
In-depth insights#
Disentangled CD#
Disentangled Cognitive Diagnosis (CD) addresses the challenge of separating entangled cognitive factors within learners. Traditional CD models often struggle to isolate individual knowledge components due to the complex interplay of skills and abilities. Disentanglement aims to represent these factors as independent latent variables, improving the interpretability and diagnostic accuracy of the model. This approach allows for a more nuanced understanding of learner proficiencies, enabling targeted interventions and personalized learning recommendations. A key benefit is improved explainability, as the contributions of each individual cognitive factor become clearer. However, achieving disentanglement requires sophisticated techniques, such as variational autoencoders or other representation learning methods, to effectively separate the latent factors while maintaining strong predictive performance. The success of a disentangled CD model hinges on the careful design of its architecture and the selection of appropriate disentanglement methods, balancing model complexity and interpretability with predictive accuracy. The ultimate goal is to create a system that provides a highly detailed, actionable understanding of a learner’s knowledge gaps, paving the way for effective and targeted instruction.
Collab. Graph Learn#
The heading ‘Collab. Graph Learn’ suggests a method for learning relationships between data points within a collaborative context. This likely involves constructing a graph where nodes represent individual learners and edges signify their collaborative interactions. The learning process aims to disentangle entangled cognitive states of learners by leveraging the collaborative signals embedded within the graph structure. Key aspects would be how the graph is constructed (e.g., based on similarity metrics, explicit interactions, or implicit shared features), the algorithm used for graph learning (e.g., graph neural networks, message passing), and how the learned graph representations are integrated into the main cognitive diagnosis model to improve diagnostic accuracy and interpretability. Context-awareness is crucial, as the connections between learners might vary depending on the task or knowledge concept considered. The objective is likely to enhance cognitive diagnosis by incorporating both individual learning performance and collaborative signals, ultimately leading to more accurate and nuanced learner models.
Coral Framework#
The Coral framework, as described, innovatively tackles collaborative cognitive diagnosis by leveraging disentangled representation learning. Its core strength lies in simultaneously modeling both individual learner states and their implicit collaborative connections. This is achieved through a three-stage process: 1) Disentangled Cognitive Representation Encoding, where initial learner states are disentangled using a variational autoencoder; 2) Collaborative Representation Learning, utilizing a context-aware graph construction and node representation learning to capture collaborative signals; and 3) Decoding and Reconstruction, which aligns and integrates individual and collaborative states for improved diagnosis accuracy. The context-aware graph learning dynamically identifies optimal neighbors for each learner, ensuring that collaborative information is relevant and effective. This framework addresses the challenge of modeling implicit connections, often absent in educational datasets, and disentangling complex learning behaviors to enhance the model’s interpretability and performance. Coral’s key contribution lies in its capacity for co-disentanglement, achieving better understanding of knowledge states through the integration of both individual and collaborative learning patterns. The framework’s potential is highlighted by significant performance improvements across various real-world datasets.
Performance Gains#
Analyzing performance gains in a research paper requires a multifaceted approach. A key aspect is identifying the metrics used to measure improvement. Are these metrics appropriate for the task, and are they consistently applied? The magnitude of the gains should be examined in relation to the baseline performance. Are the gains statistically significant? Any confounding factors must be considered; did changes in other variables influence the results? Generalizability is vital—do the gains hold across different datasets, settings, or populations? Finally, the paper’s analysis of the performance gains should be critical and insightful, offering explanations for both successes and limitations, allowing readers to assess the robustness and reliability of the reported findings. A comprehensive analysis will not only highlight positive results but also acknowledge areas for further research.
Future of Coral#
The future of Coral, a collaborative cognitive diagnosis model, is promising. Its core strength lies in its ability to leverage collaborative signals among learners, improving diagnostic accuracy and offering valuable insights into the learning process. Future development could focus on scalability, addressing limitations in handling massive datasets efficiently. Integration with advanced technologies, such as large language models (LLMs) and multi-modal learning, could enhance Coral’s capabilities for more comprehensive and nuanced understanding of learner proficiency. Further research on disentanglement techniques is warranted to refine the model’s ability to isolate and interpret specific cognitive factors. Finally, investigating fairness and ethical considerations is crucial to ensure equitable and responsible application of such models in educational settings. Exploring real-world impact and developing user-friendly interfaces are important for maximizing Coral’s potential benefits for educators and students alike.
More visual insights#
More on figures

This figure presents a comprehensive overview of the Coral model’s architecture. It illustrates the three main stages: Disentangled Cognitive Representation Encoding, Collaborative Representation Learning, and Decoding and Reconstruction. The Disentangled Cognitive Representation Encoding stage focuses on extracting individual learner features from their practice records. The Collaborative Representation Learning stage involves constructing a graph to model connections between learners, using this graph to learn collaborative representations, and combining those with the individual learner features. Finally, the Decoding and Reconstruction stage utilizes these combined representations to predict learner performance and reconstruct the practice data. The figure effectively visualizes the flow of information and the interplay between individual and collaborative learning signals in the Coral model.

This figure presents four subfigures illustrating the performance of the Coral model under various conditions. Subfigure (a) compares the performance of Coral and other baseline models in scenarios with different levels of sparsity in the data. Subfigure (b) shows the results when the model is trained only on the data for questions that learners had not seen before in the training set, simulating a cold-start scenario. Subfigure (c) shows how the model’s performance varies as the number of neighbors (K) used in the collaborative graph construction is changed. Finally, subfigure (d) displays the relationship between the level of disentanglement in the learned representations and the model’s performance during the training process.

This figure visualizes the results of the collaborative graph learning in Coral. (a) shows the iterative neighbor selection process for two randomly selected learners (in red). Each step’s newly added neighbors are color-coded, illustrating how Coral progressively builds a neighborhood based on cognitive similarity. (b) uses t-SNE to project the disentangled cognitive representations of learners onto a 2D plane, where each point represents a learner and the color corresponds to a knowledge concept. This visualization demonstrates the disentanglement of knowledge concepts in the learned representations.
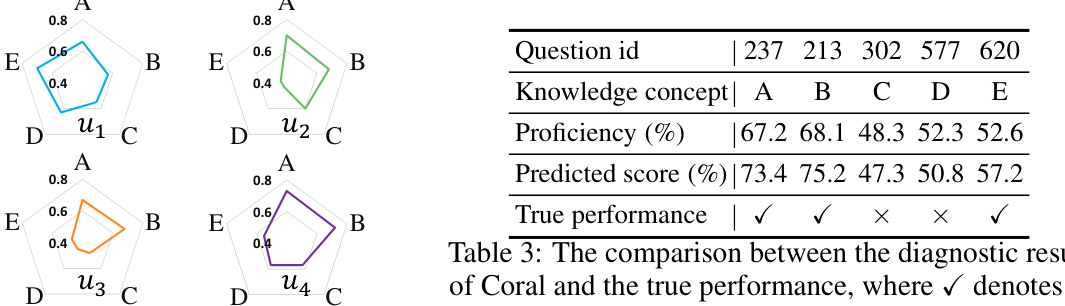
This figure presents the overall architecture of the Coral model, illustrating the three main components: Disentangled Cognitive Representation Encoding, Collaborative Representation Learning, and Decoding and Reconstruction. The Disentangled Cognitive Representation Encoding block takes practice data as input and generates initial disentangled cognitive representations for each learner. This information is then fed into the Collaborative Representation Learning block, which constructs a context-aware collaborative graph of learners based on their cognitive similarities and extracts collaborative information. Finally, the Decoding and Reconstruction block merges the initial cognitive states and collaborative states to achieve co-disentanglement, reconstructing the practice performance and yielding the final cognitive diagnosis.
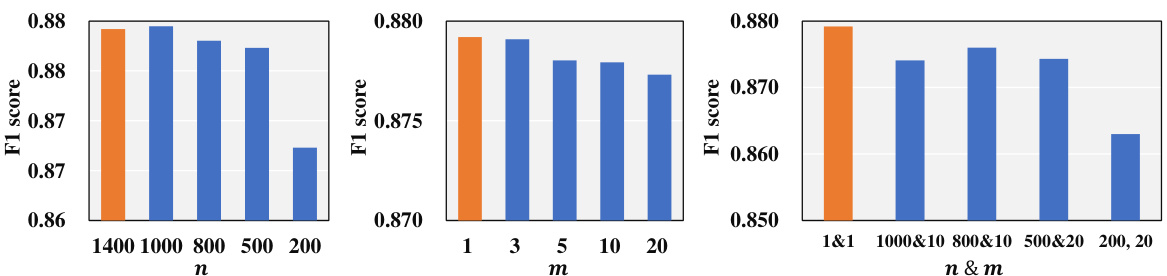
This figure displays the results of experiments conducted to evaluate the efficiency improvements of the Coral model. Three optimization strategies were tested: Coral with n-sample (reducing the number of learners considered in each iteration), Coral with m-selections (increasing the number of neighbors selected per iteration), and Coral with full-kit (a combination of the previous two). The x-axis represents the different configurations of these optimization strategies, and the y-axis shows the F1-score achieved. The orange bar represents the performance of the original Coral model, serving as a baseline for comparison. The results show that while the optimization strategies enhance efficiency, they also impact performance, indicating a trade-off between computational cost and accuracy.
More on tables
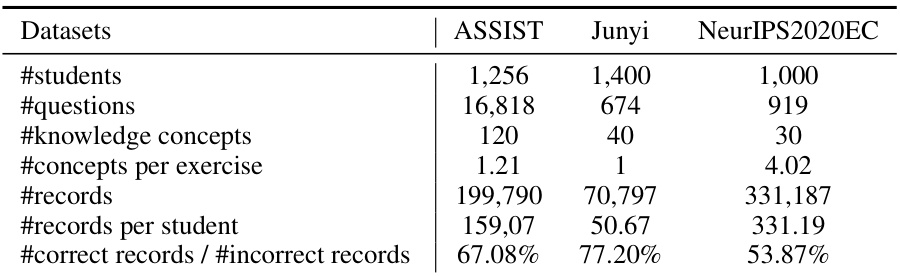
This table presents the key statistics for three datasets used in the paper’s experiments: ASSIST, Junyi, and NeurIPS2020EC. These statistics include the number of students, questions, knowledge concepts, the average number of concepts per exercise, the total number of records, the average number of records per student, and the ratio of correct to incorrect records. This information provides context for understanding the scale and characteristics of the datasets used to evaluate the proposed model.
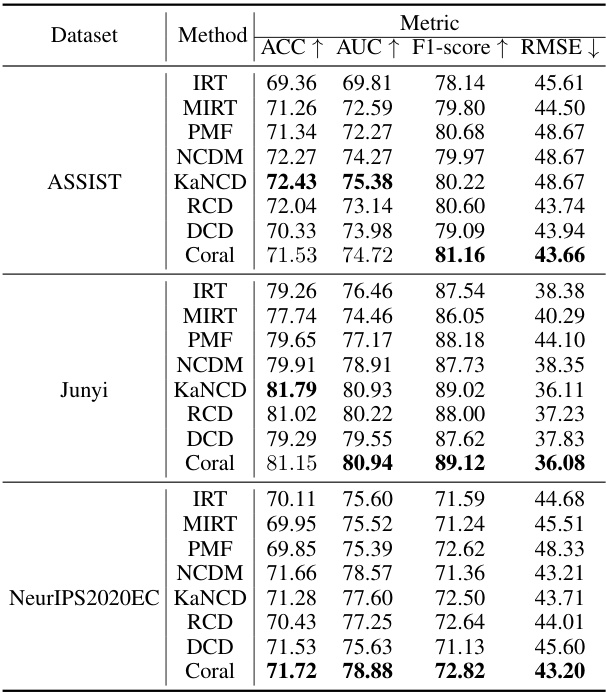
This table presents a comparison of the performance of the proposed Coral model against several baseline models across three different datasets. The performance is measured using four metrics: Accuracy (ACC), Area Under the ROC Curve (AUC), F1-score, and Root Mean Squared Error (RMSE). Higher values for ACC, AUC, and F1-score indicate better performance, while a lower RMSE value indicates better performance. The table highlights the best-performing model for each metric and dataset in bold, demonstrating Coral’s superior performance in most cases.

This table presents the results of an ablation study conducted on the ASSIST dataset to evaluate the impact of different components of the Coral model on its performance. The metrics used are Accuracy (ACC), Area Under the ROC Curve (AUC), F1-score, and Root Mean Squared Error (RMSE). Each row represents a variation of the Coral model: one without the Kullback-Leibler divergence (KL) term; one without the collaborative aggregation during decoding (collar); one using the K-Nearest Neighbors (knn) algorithm instead of the proposed collaborative graph learning method; and finally, the full Coral model. The results show the contribution of each component and the overall effectiveness of the proposed model.
Full paper#



















