↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current Vision-Language-Action (VLA) models struggle with complex tasks and high computational costs. These models often lack sufficient reasoning abilities to tackle complex scenarios and require extensive resources for fine-tuning and inference, limiting their applicability in real-world robotic systems. This necessitates developing more efficient robotic VLA models for improved performance and wider adoption.
RoboMamba is proposed as a solution, integrating the efficient Mamba LLM to balance reasoning and action. The authors integrate a vision encoder with Mamba, enabling visual common sense and robotic reasoning. A novel fine-tuning strategy is introduced, requiring only minimal parameter updates to achieve pose prediction abilities. Experiments show RoboMamba outperforms existing models in reasoning and manipulation tasks, with significantly faster inference speeds, making it a promising model for real-world robotic applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in robotics and AI due to its efficient approach to robotic reasoning and manipulation. It addresses the limitations of existing VLA models by introducing a novel architecture that combines reasoning and action capabilities efficiently, significantly reducing computational costs and paving the way for more widespread real-world applications of robotic systems.
Visual Insights#
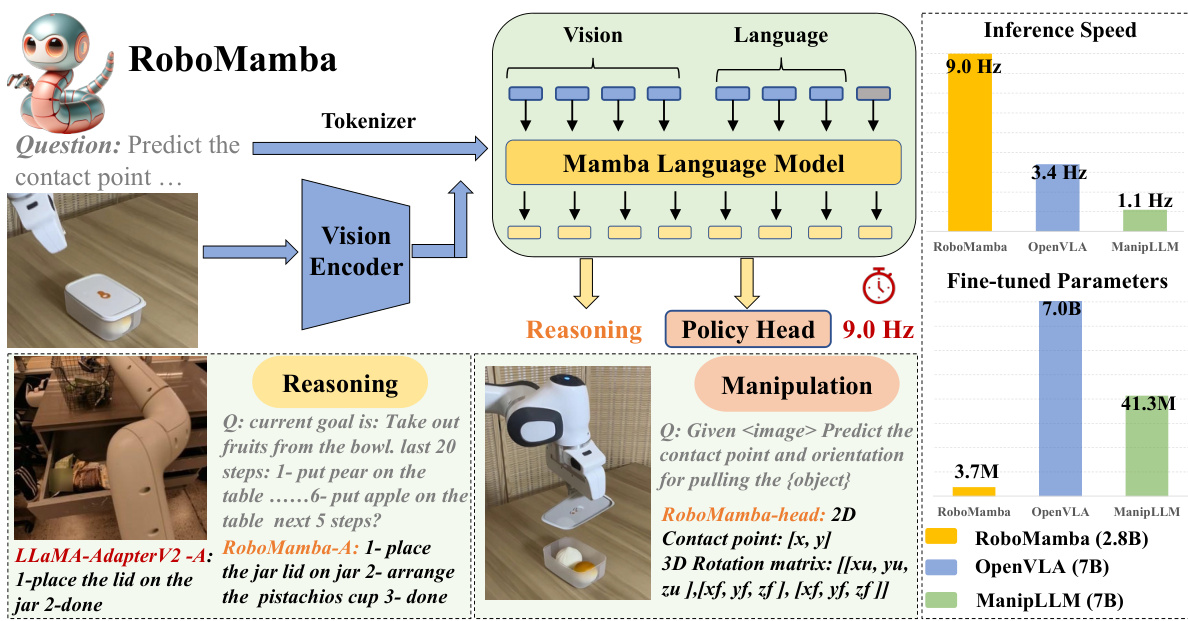
This figure provides a high-level overview of the RoboMamba architecture and its workflow. It shows how RoboMamba integrates a vision encoder with the Mamba language model to achieve both reasoning and manipulation capabilities. The diagram highlights the efficient fine-tuning strategy used, the speed advantage over other VLA models, and previews the real-world applications shown in later figures.
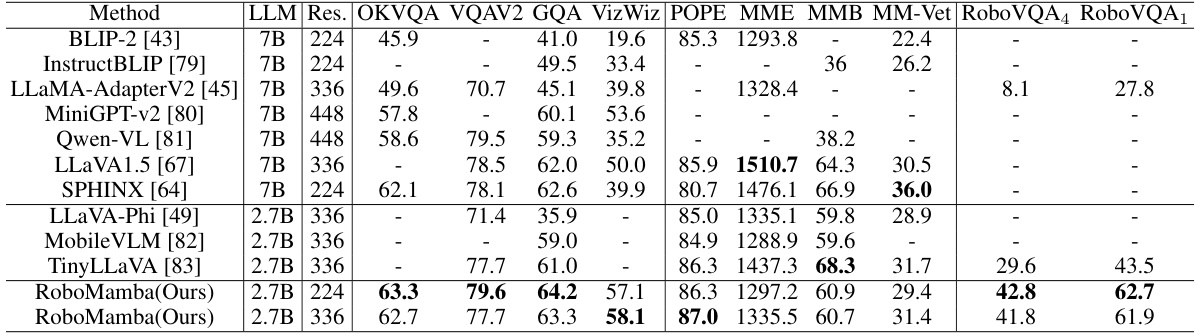
This table compares the performance of RoboMamba against several state-of-the-art Multimodal Large Language Models (MLLMs) across various general reasoning benchmarks and a robotic-related reasoning benchmark (RoboVQA). It highlights RoboMamba’s competitive performance despite using a smaller language model (2.7B parameters). The table includes metrics like OKVQA, VQAv2, GQA, VizWiz, POPE, MME, MMB, MM-Vet, and RoboVQA BLEU scores (1-4). The results for TinyLLaVA and LLaMA-AdapterV2 reflect performance after fine-tuning on RoboVQA, demonstrating RoboMamba’s strong performance without extensive fine-tuning.
In-depth insights#
Vision-Language Fusion#
Vision-language fusion aims to bridge the gap between visual and textual data, enabling machines to understand and reason about the world in a more holistic way. Effective fusion methods are crucial for enabling complex tasks such as visual question answering (VQA), image captioning, and visual dialogue. A key challenge lies in effectively aligning visual and linguistic features, often involving multimodal embeddings or attention mechanisms. Approaches vary from early fusion, which concatenates visual and textual features before processing, to late fusion, which integrates information at a later stage. The choice of fusion method often depends on the specific task and the nature of the data. Success hinges on selecting appropriate feature representations and incorporating contextual information for improved accuracy and robustness. Furthermore, efficient models that balance computational cost with performance are important considerations, particularly for real-time applications such as robotics and autonomous systems. Future research could focus on developing more sophisticated fusion strategies that leverage the power of large language models (LLMs) and incorporate commonsense reasoning. The ultimate goal is to create systems that can truly understand multimodal input and generate meaningful, context-aware outputs.
Mamba Model’s Role#
The Mamba model serves as the backbone for RoboMamba’s efficient and robust reasoning capabilities. Its linear time complexity is crucial, allowing for faster inference speeds compared to traditional transformer-based LLMs. By integrating a vision encoder and aligning visual tokens with language embeddings, Mamba empowers RoboMamba to understand visual scenes and reason about them effectively. This seamless integration of vision and language is key to RoboMamba’s ability to comprehend complex robotic tasks. Furthermore, Mamba’s inherent efficiency enables the model to quickly acquire manipulation skills with minimal fine-tuning parameters, reducing computational costs and training time. In essence, Mamba’s unique architecture and properties are fundamental to RoboMamba’s success in delivering both high reasoning ability and efficient action prediction in robotic applications.
Efficient Fine-tuning#
Efficient fine-tuning in large language models (LLMs) for robotic applications focuses on minimizing computational cost and time while maximizing performance. This typically involves strategies to reduce the number of parameters updated during fine-tuning, such as using smaller, task-specific modules or adapter networks. Parameter-efficient fine-tuning methods are crucial because full LLM fine-tuning is computationally expensive. A key aspect is identifying effective strategies that allow the model to quickly adapt to new robotic tasks and environments with a minimal number of training examples. Transfer learning, leveraging pre-trained models and knowledge from related domains, plays a significant role in efficient fine-tuning. The success of this approach hinges on the careful integration of visual and linguistic information, enabling robots to effectively understand instructions and execute actions. Strategies for aligning visual and textual representations are important for bridging the gap between image data and language instructions. The ultimate goal is to create robotic systems that are not only effective but also computationally practical and cost-efficient.
Reasoning Benchmarks#
The selection of reasoning benchmarks is crucial for evaluating the capabilities of a vision-language-action (VLA) model like RoboMamba. A strong benchmark suite should cover a range of complexities, including both general visual question answering (VQA) tasks and specialized robotic reasoning tasks. The inclusion of benchmarks like VQAv2, GQA, and OKVQA demonstrates an effort to test general reasoning and image understanding. However, the inclusion of RoboVQA is particularly important, as it directly assesses reasoning abilities relevant to robotic manipulation. This blend of general and task-specific benchmarks allows for a more thorough evaluation of the model’s capabilities beyond basic image-text matching and into higher-level cognitive functions vital for robust robotic interaction. The use of multiple benchmarks also helps mitigate the influence of any single dataset’s biases or limitations, offering a more comprehensive and robust understanding of RoboMamba’s performance. However, the paper should explicitly justify the choices of specific benchmarks and ideally provide detailed results for each, showcasing RoboMamba’s relative strengths and weaknesses across different reasoning styles and challenges.
Future Work#
The authors of the RoboMamba paper outline a promising future research direction involving the integration of more advanced linear-complexity LLMs to enhance the model’s reasoning and manipulation capabilities. This suggests a focus on improving efficiency while maintaining or surpassing current performance levels. They also plan to develop a 4D robot VLA model, leveraging both 3D point cloud and temporal data to improve the accuracy and robustness of low-level action predictions, particularly focusing on more complex and nuanced scenarios. This extension into 4D models directly addresses a limitation of existing VLA models that handle primarily 2D or 3D data. The explicit mention of temporal data highlights a commitment to addressing the temporal aspect of robotic manipulation, a key challenge in creating truly adaptable and versatile robotic systems. The emphasis on both efficiency and enhanced capabilities reveals a commitment to creating practical and deployable robotic systems, rather than solely theoretical advancements.
More visual insights#
More on figures
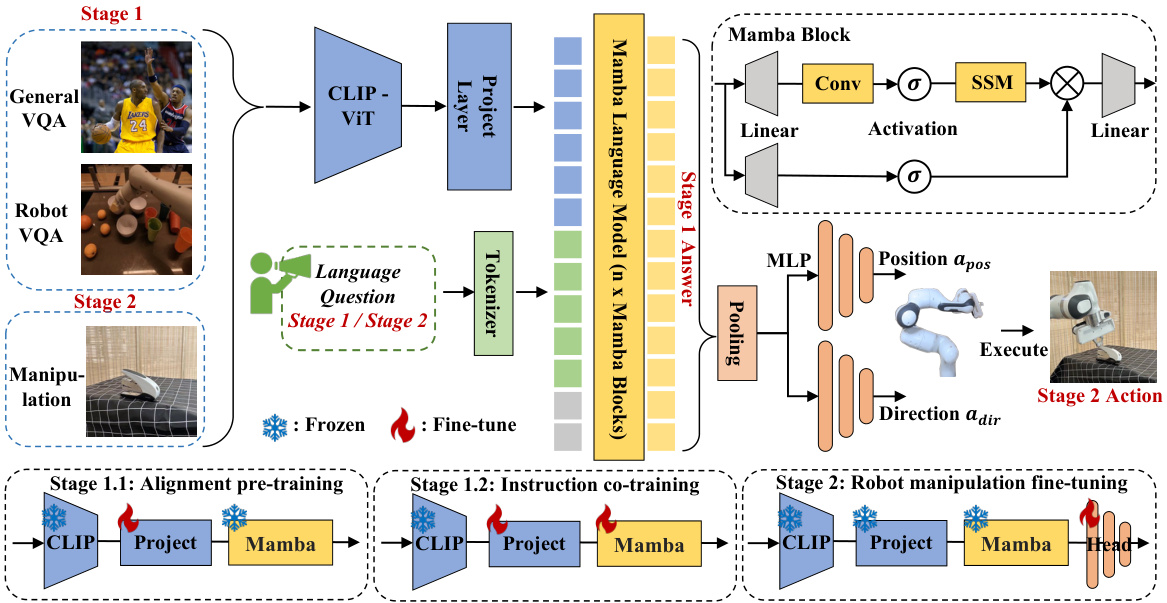
This figure illustrates the architecture of RoboMamba, a robotic VLA model. It shows how visual and language information are processed through a vision encoder, projection layer, and Mamba language model to generate reasoning and actions. The figure details the model’s two-stage training process: Stage 1 focuses on reasoning abilities through alignment and co-training, while Stage 2 adds manipulation capabilities via fine-tuning a policy head. The diagram highlights the flow of information and the key components involved in each stage.

This figure provides a high-level overview of the RoboMamba architecture, highlighting its key components: a vision encoder, the Mamba language model, a reasoning policy head, and a manipulation module. It emphasizes the model’s efficiency in terms of both fine-tuning and inference speed, comparing it to existing VLA models (OpenVLA and ManipLLM). The diagram also shows examples of how RoboMamba processes questions and generates answers, showcasing its reasoning and manipulation capabilities. Finally, it points to further examples of real-world applications in Figures 4 and 5.
This figure provides a high-level overview of the RoboMamba architecture, highlighting its key components: a vision encoder, the Mamba language model, a reasoning policy head, and a manipulation module. It emphasizes the model’s efficiency in terms of both inference speed and fine-tuning requirements. The diagram also shows examples of the reasoning and manipulation tasks RoboMamba can handle.

This figure provides a high-level overview of the RoboMamba architecture, highlighting its key components: a vision encoder, the Mamba language model, a reasoning policy head, and a manipulation module. It emphasizes the model’s efficiency in terms of both training time and inference speed, comparing it favorably to existing VLA models. The image also shows examples of the model’s reasoning and manipulation capabilities.

This figure provides a high-level overview of the RoboMamba architecture, highlighting its key components: a vision encoder, the Mamba language model, a reasoning policy head, and a manipulation module. It emphasizes RoboMamba’s efficiency in terms of both fine-tuning and inference speed, comparing its performance to existing VLA models (OpenVLA and ManipLLM). The figure also points towards Figures 4 and 5 for further examples of real-world applications.

This figure presents the overall architecture of RoboMamba, a robotic VLA model. It shows how the model processes visual and language inputs using a vision encoder, projection layer, and Mamba language model. The diagram also details the two-stage training process: Stage 1 focuses on reasoning abilities through pre-training and co-training, while Stage 2 focuses on manipulation skills via fine-tuning. The figure highlights the model’s components, data flow, and the specific training strategies used to achieve both reasoning and action capabilities.
More on tables
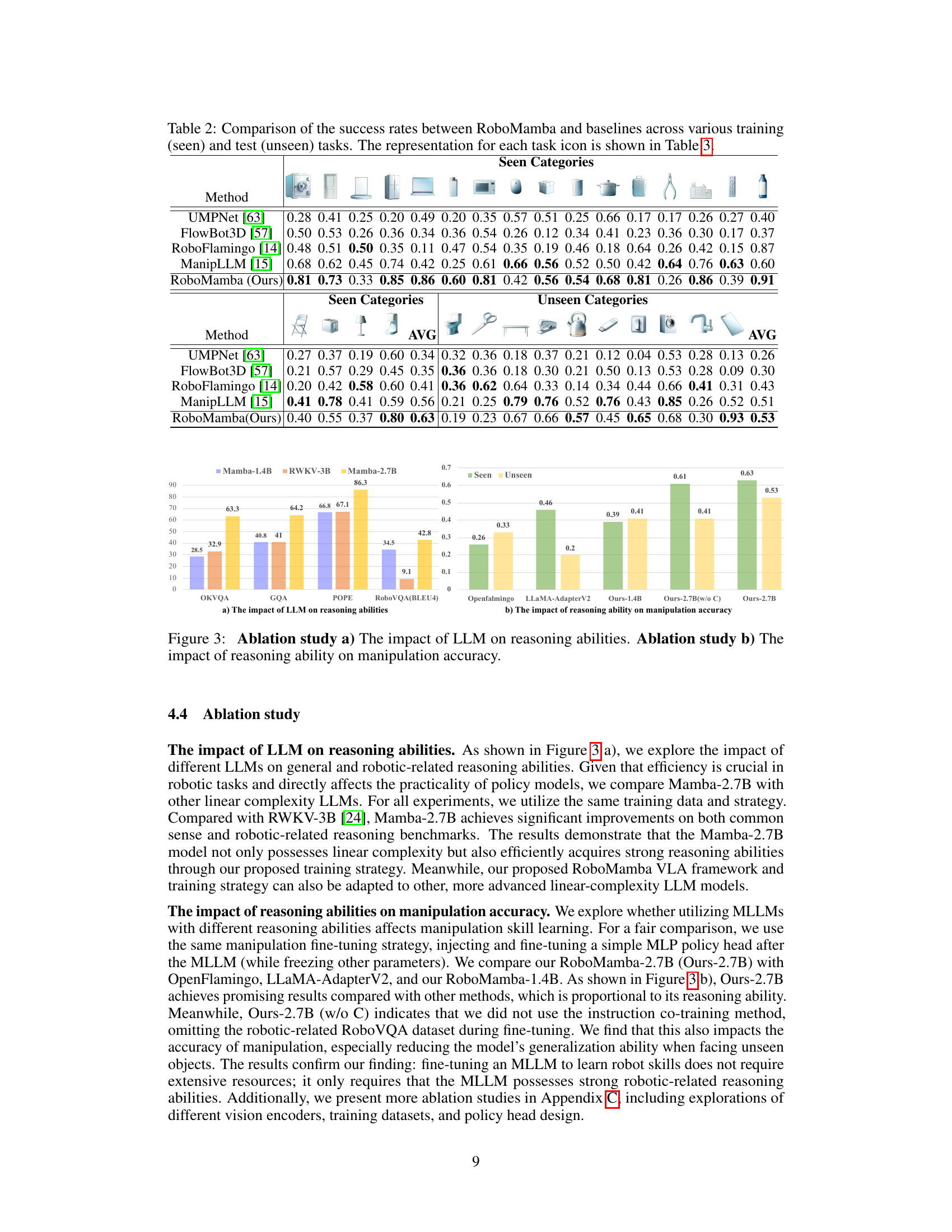
This table presents a comparison of the success rates achieved by RoboMamba and other baseline models on various robotic manipulation tasks. The tasks are categorized into ‘seen’ (those present in the training data) and ‘unseen’ categories. The success rate is a measure of how often the robot successfully completed each task. Table 3 provides a visual key for understanding the icons used in this table to represent each task.

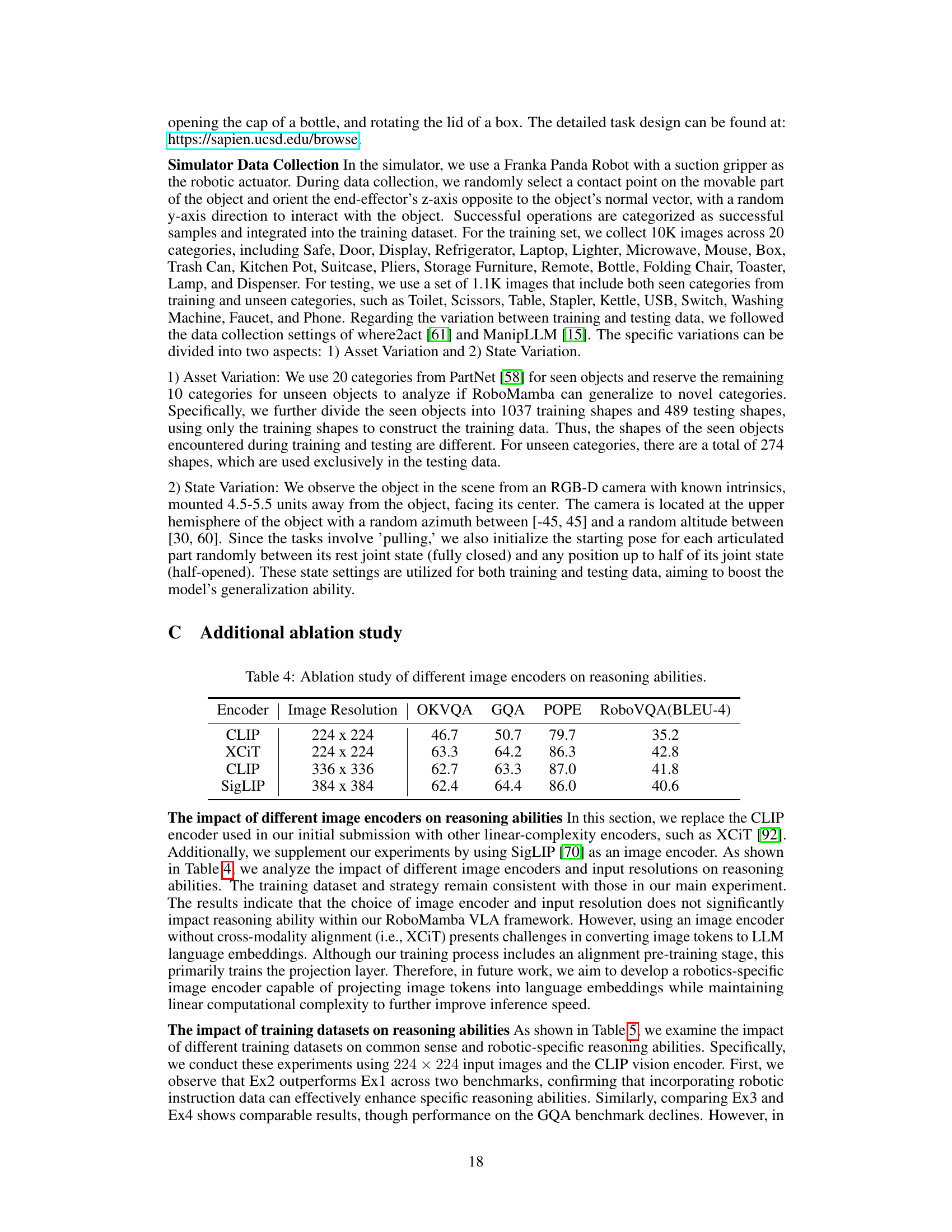
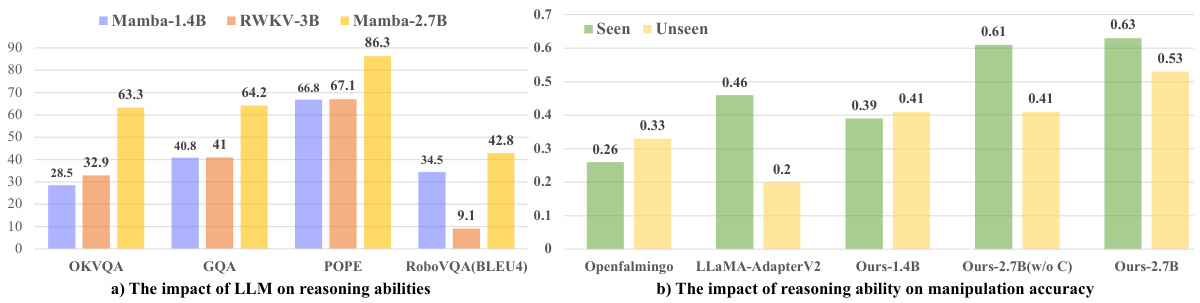
This table presents the results of an ablation study comparing the performance of different vision encoders (CLIP, XCIT, SigLIP) and image resolutions (224x224, 336x336, 384x384) on several reasoning benchmarks (OKVQA, GQA, POPE, RoboVQA). The results demonstrate the impact of the choice of encoder and resolution on the model’s performance. It aims to show the robustness of the proposed model’s reasoning abilities and the contribution of the chosen encoder and resolution.
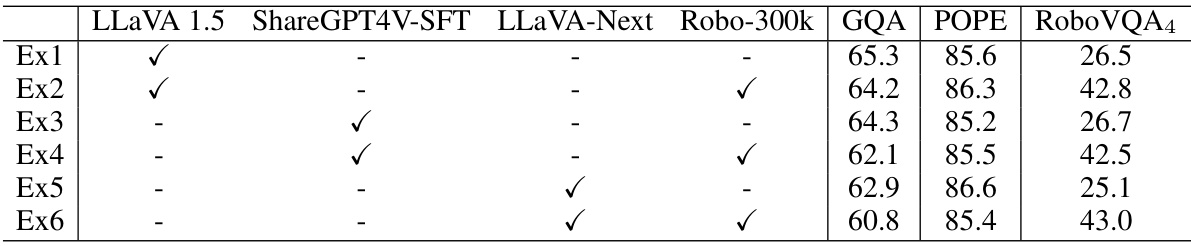
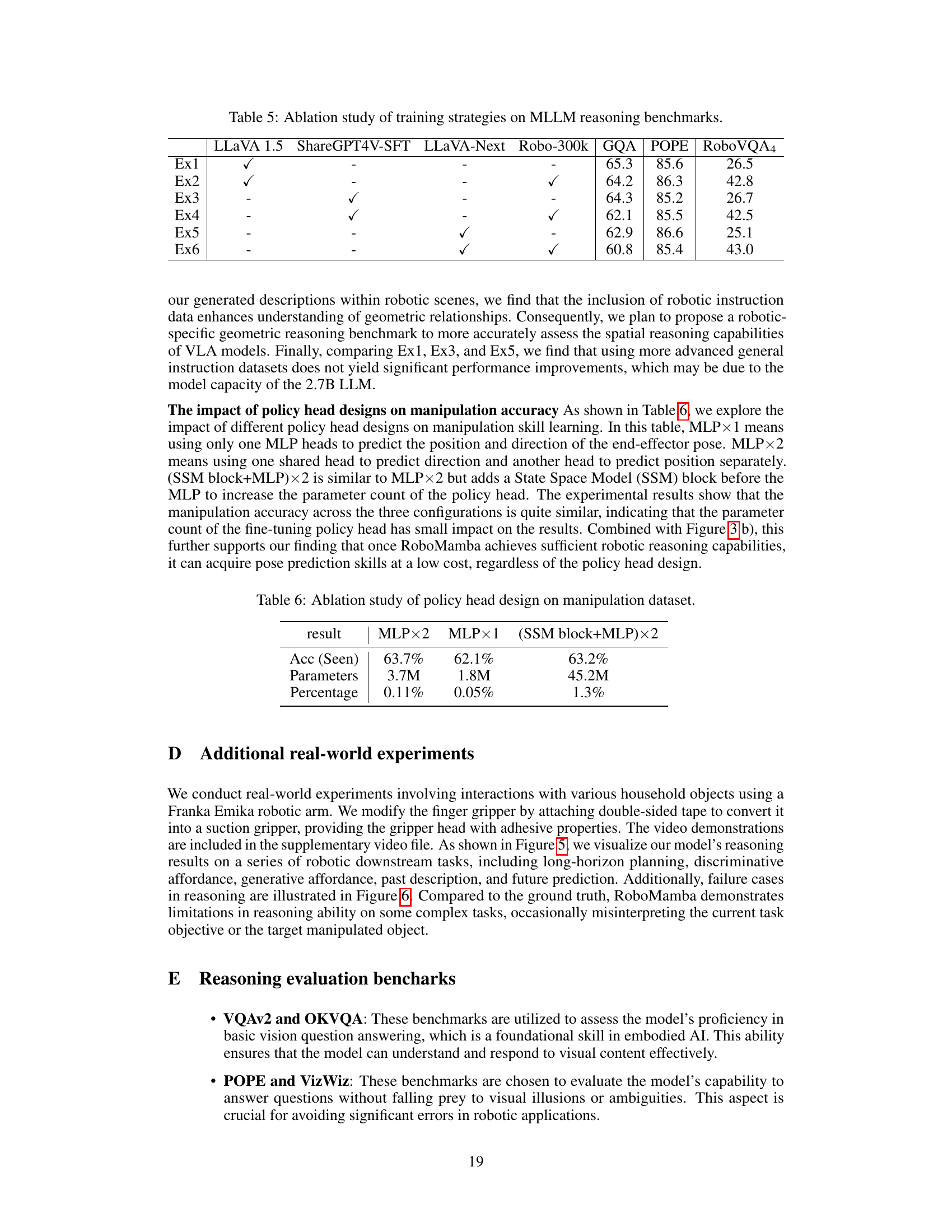
This table presents the results of an ablation study evaluating the impact of different training strategies on the performance of Multimodal Large Language Models (MLLMs) across various reasoning benchmarks. Each row represents a different experiment, indicated by ‘Ex1’ through ‘Ex6’. Each column represents a dataset included in the training: LLaVA 1.5, ShareGPT4V-SFT, LLaVA-Next, and Robo-300k. A checkmark (✓) indicates that the corresponding dataset was used in the experiment’s training. The remaining columns show the performance on the benchmarks GQA, POPE, and RoboVQA4. The results help determine which dataset combinations are most effective for training robust MLLMs.

This table presents the results of an ablation study comparing different policy head designs for robot manipulation. The study evaluates the accuracy (‘Acc (Seen)’) of the models on seen tasks using three different policy head architectures: MLP×2 (two separate MLPs for position and direction prediction), MLP×1 (a single MLP for both), and (SSM block+MLP)×2 (two MLPs preceded by an SSM block). The table also lists the number of parameters in each policy head and its percentage relative to the overall model size. The goal is to demonstrate that minimal fine-tuning parameters are needed to obtain good manipulation performance, suggesting that the reasoning capabilities of the model are more crucial than the complexity of the policy head.
Full paper#