↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
High-quality data is crucial for effective instruction tuning of Large Language Models (LLMs), but acquiring it is resource-intensive. Current methods often rely on a single LLM for data generation, limiting diversity and potentially quality. This paper addresses these issues by introducing the Star-Agents framework.
Star-Agents uses multiple LLMs to generate diverse instruction data, rigorously evaluates data quality using a dual-model approach considering complexity and quality, and dynamically refines the process by prioritizing more effective LLMs. Experiments show substantial performance improvements (12% average, 40% on specific metrics) over baselines on benchmarks like MT-bench and Vicuna, demonstrating the framework’s effectiveness and its potential to optimize LLM training data efficiently.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents a novel framework for automatically improving the quality of training data for instruction-tuning large language models. This is crucial because high-quality training data is essential for achieving optimal performance in these models, but obtaining it is typically expensive and time-consuming. The Star-Agents framework offers an efficient and effective solution to this problem, opening up new avenues for research in data optimization and LLM training. The method’s effectiveness is demonstrated through its significant performance gains on several benchmarks, suggesting that this is a scalable approach suitable for various LLMs and datasets.
Visual Insights#
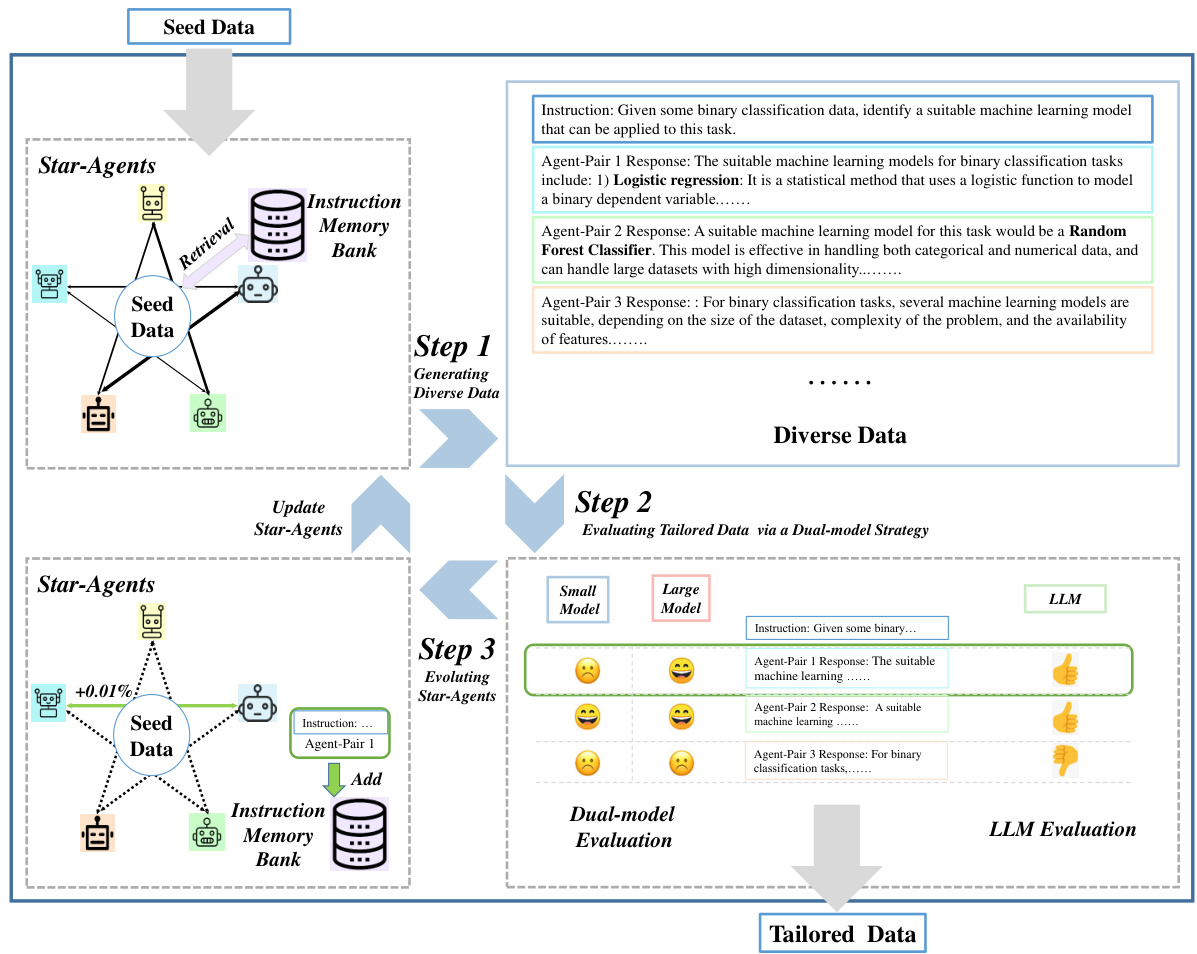
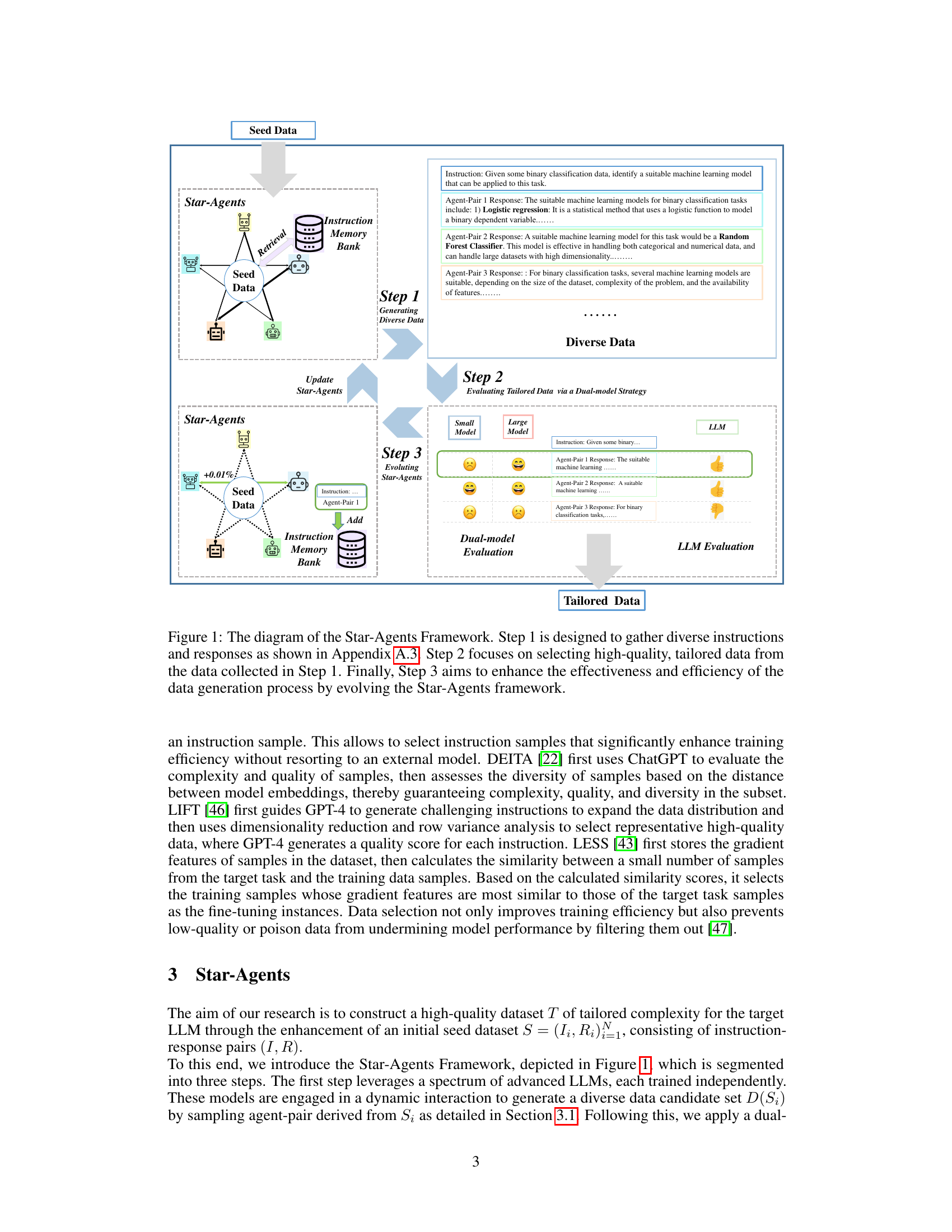
This figure illustrates the Star-Agents framework, a three-step process for automatic data optimization. Step 1 uses multiple LLM agents to generate diverse instruction data. Step 2 evaluates the generated data using a dual-model approach to assess both difficulty and quality, selecting high-quality samples. Step 3 dynamically refines the process by prioritizing more effective LLMs, leading to improved data quality over time. The framework is designed to automate the enhancement of data quality across datasets through multi-agent collaboration and assessment.
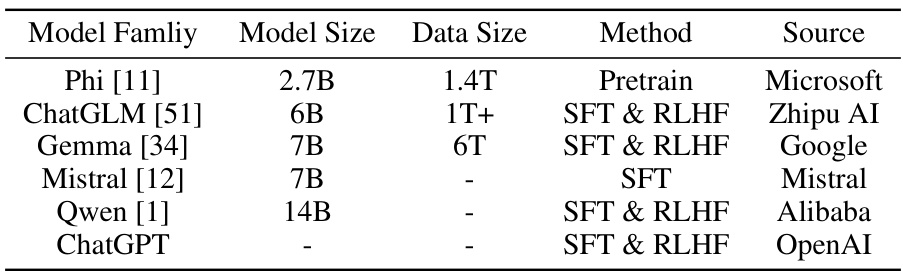
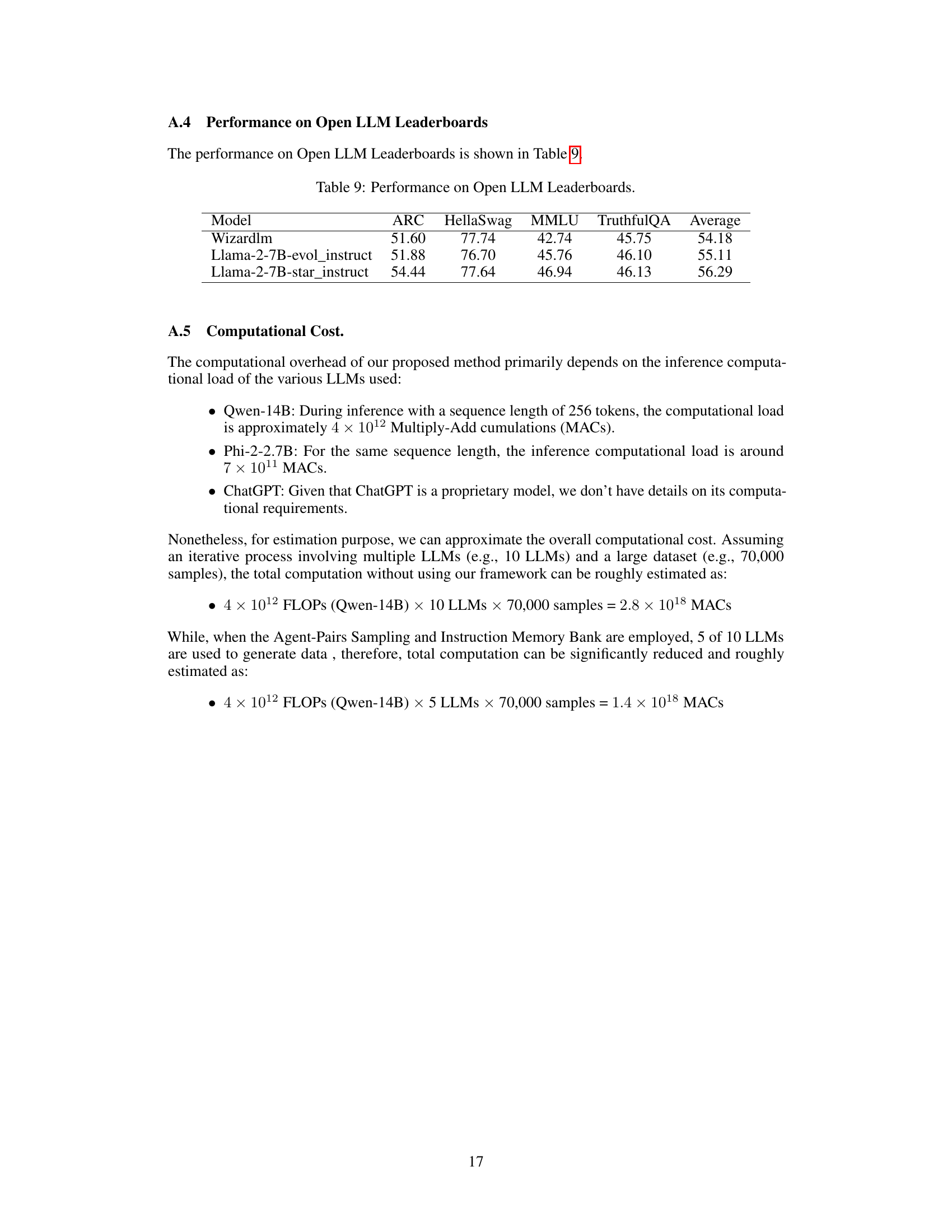
This table lists the Large Language Models (LLMs) used in the Star-Agents framework. It provides details on each model, including its family, size (in parameters), the size of the data it was trained on, the training method used (either solely pretraining or a combination of Supervised Fine-Tuning and Reinforcement Learning from Human Feedback), and the source or developer of the model.
In-depth insights#
Star-Agent Framework#
The Star-Agent framework is a novel approach to data optimization for instruction tuning of large language models (LLMs). It leverages multiple LLM agents in a collaborative manner to generate diverse and high-quality instruction data. A key strength lies in its three-pronged strategy: initial diverse data generation, rigorous dual-model evaluation assessing both difficulty and quality, and a dynamic refinement phase prioritizing effective LLMs. This iterative process ensures continuous improvement in data quality, leading to substantial performance gains in downstream tasks. The framework’s ability to automate data optimization addresses the significant limitations of traditional, manual data creation methods, paving the way for more efficient and effective LLM training. Dual-model evaluation is particularly insightful, enabling the selection of instructions with appropriate complexity to challenge and improve LLMs without overwhelming them. The system’s evolutionary aspect, dynamically adjusting agent selection probabilities based on performance, further optimizes the process, making it adaptive and scalable.
Data Optimization#
The research paper centers around data optimization for instruction tuning of large language models (LLMs). It highlights the challenges of obtaining high-quality, diverse instruction data, emphasizing the limitations of manual annotation. The proposed solution, the Star-Agents framework, uses multiple LLMs to collaboratively generate and refine datasets. A dual-model evaluation strategy is employed to assess both the quality and complexity of the generated data, ensuring that the data is neither too simple nor overly complex for the target model. Dynamic refinement, prioritizing effective LLM agent-pairs based on performance, enhances overall data quality. This iterative approach leads to substantial performance improvements, surpassing baselines on various benchmark datasets.
Multi-Agent Collab#
A hypothetical section titled ‘Multi-Agent Collab’ within a research paper would likely detail a system where multiple independent agents, each with specialized capabilities, work cooperatively to achieve a shared goal. This collaborative approach is crucial when the task is complex and requires diverse skills. The paper might explore different agent architectures, communication protocols, and conflict resolution mechanisms. Key aspects to consider are the efficiency gains from parallel processing, the robustness against individual agent failures, and the overall system performance compared to single-agent approaches. A successful multi-agent system requires careful design and likely involves advanced techniques in artificial intelligence, such as reinforcement learning or distributed consensus algorithms. The paper would likely present experimental results demonstrating the effectiveness of the multi-agent collaboration, potentially quantifying improvements in accuracy, efficiency, or robustness. Challenges and limitations inherent in multi-agent systems, such as communication overhead and the potential for emergent unpredictable behavior, should also be discussed. Ultimately, the value of a multi-agent system hinges on its ability to outperform single agents and offer a scalable solution for increasingly complex problems.
LLM-based Tuning#
LLM-based tuning represents a significant paradigm shift in adapting large language models (LLMs) to downstream tasks. Instead of relying solely on human-annotated data, which is expensive and time-consuming, this approach leverages the capabilities of LLMs themselves to generate, refine, and optimize training datasets. This automation significantly accelerates the tuning process, making it more efficient and scalable. Key strategies within LLM-based tuning involve using one or more LLMs to generate diverse instruction-response pairs, followed by intelligent selection mechanisms to filter out low-quality or redundant samples. The selection process often incorporates metrics assessing both the difficulty and quality of generated data, ensuring the final dataset is both challenging and effective for improving the target model’s performance. Furthermore, iterative refinement loops, where the LLMs themselves adapt based on performance feedback, can further enhance data quality and model effectiveness. This iterative approach is crucial for addressing the limitations of single-pass LLM data generation, leading to superior instruction-following capabilities and improved downstream task performance.
Future Directions#
Future research could explore expanding the Star-Agents framework to handle multi-turn dialogues, a significant area where current instruction tuning methods struggle. Investigating the impact of data augmentation techniques specifically designed for instruction data would also be valuable. Furthermore, a deeper understanding of how different LLM architectures respond to data generated by Star-Agents is needed. This could involve exploring different model sizes and architectural choices and their ability to leverage the tailored data effectively. Finally, comprehensive analysis of the generalization capabilities of models trained with optimized data generated by Star-Agents across diverse downstream tasks, beyond those already evaluated, is crucial for validating the framework’s wider applicability and robustness.
More visual insights#
More on figures

This figure shows the performance of different sized language models (50M, 100M, 150M parameters) on two datasets: Alpaca and Evol-Instruct. The y-axis represents the performance, and the x-axis shows the model size in millions of parameters. The results indicate that the Evol-Instruct dataset, containing more complex tasks, leads to better performance as the model size increases. The Alpaca dataset shows a less significant performance increase with larger models.

This figure illustrates the core concept of the dual-model evaluation strategy used in the Star-Agents framework. It shows two curves representing the Instruction Following Difficulty (IFD) scores as a function of instruction complexity for a small language model (e.g., the target model being trained) and a large language model (used for evaluation). The shaded region highlights the optimal range of complexity: data points falling within this area have a significantly different IFD for the small and large models, suggesting that the instruction is challenging enough for the small model to benefit from but not too difficult to be out of the small model’s scope. This selection strategy aims to improve data quality and enhance the performance of the target model.

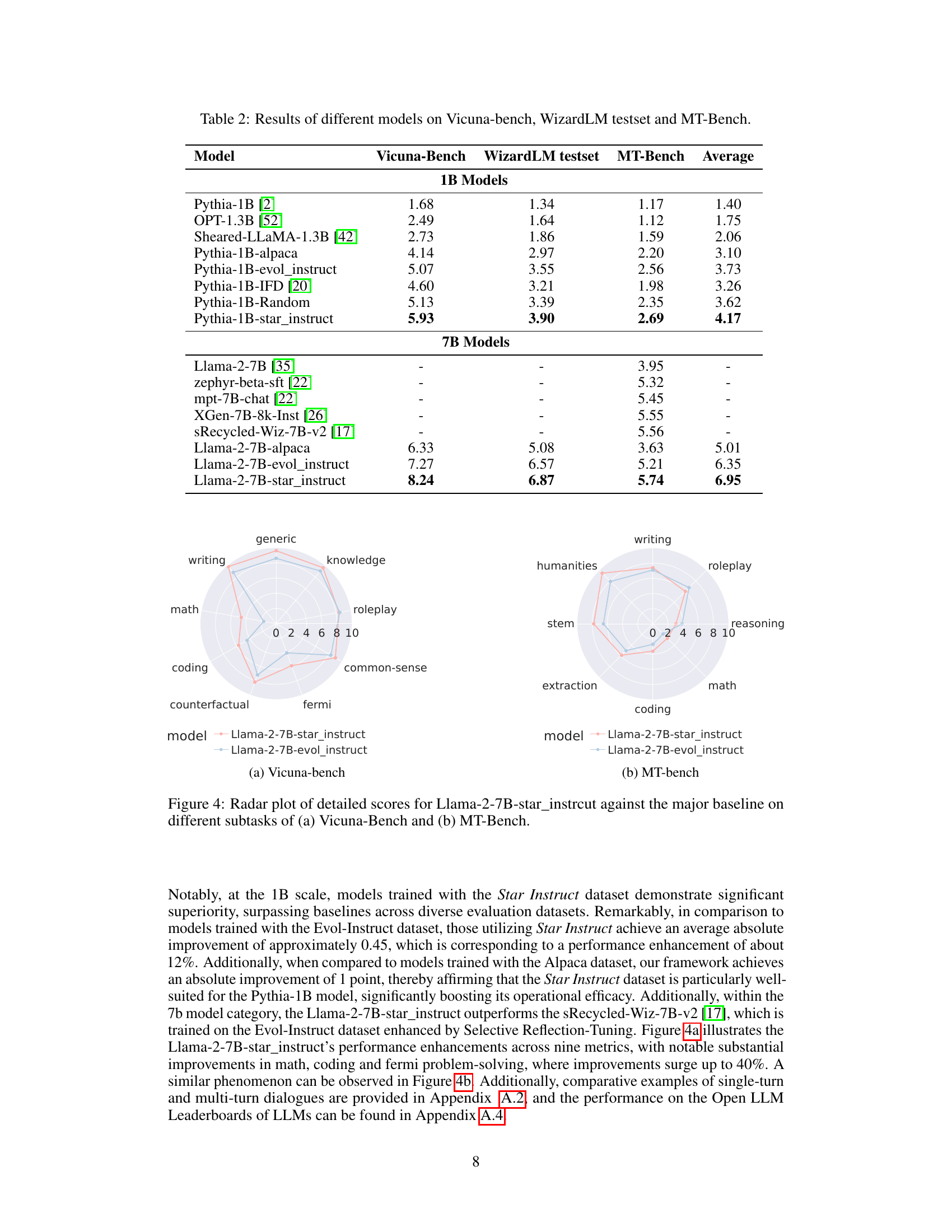
This figure presents a comparison of the performance of the Llama-2-7B model fine-tuned with data optimized by the Star-Agents framework (Llama-2-7B-star_instruct) against the baseline model (Llama-2-7B-evol_instruct) across various subtasks within two benchmark datasets: Vicuna-bench and MT-bench. Each dataset evaluates different aspects of language model capabilities, such as reasoning, coding, and common sense. The radar plots visually represent the performance differences across multiple subtasks for both models. The Llama-2-7B-star_instruct consistently outperforms the baseline across a majority of the subtasks, highlighting the efficacy of the Star-Agents data optimization approach.

This figure shows the evolution of the sampling probability of four different agent-pairs over 70,000 iterations. The sampling probability is adjusted dynamically based on the quality of the data generated by each agent-pair. The Mistral-ChatGPT pair consistently demonstrates high quality, resulting in an increased sampling probability. Conversely, the Phi2-ChatGPT pair shows decreasing probability due to lower-quality data generation. The ChatGLM3-ChatGPT and ChatGPT-0613-ChatGPT pairs exhibit relatively stable trajectories.
More on tables
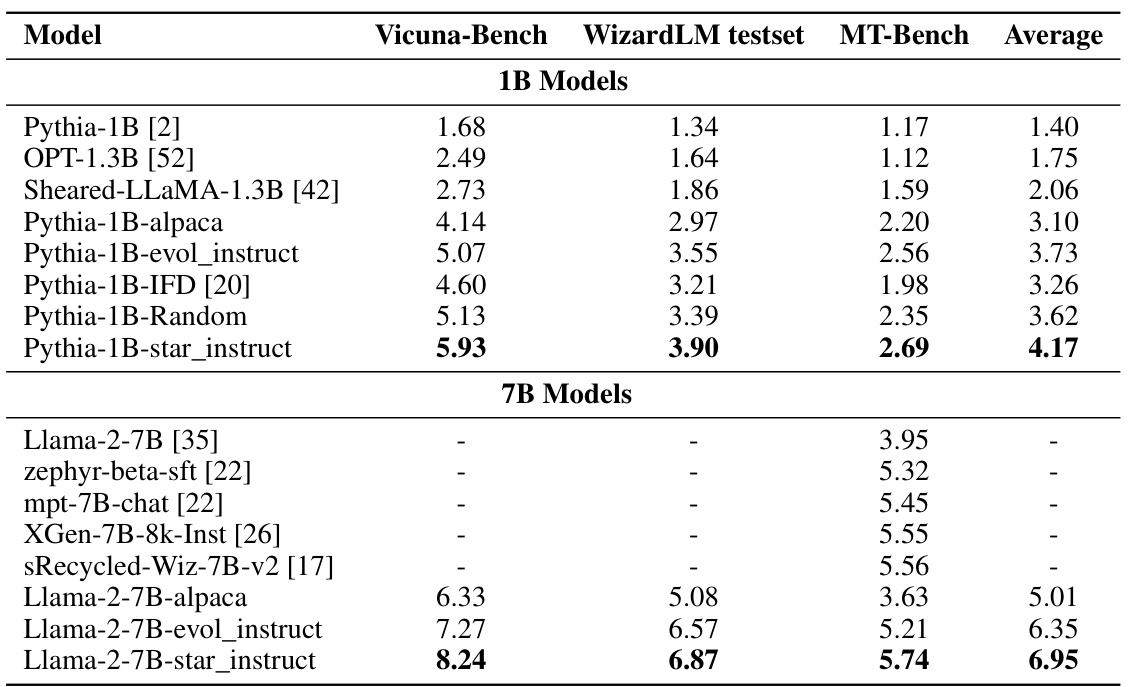
This table presents the performance comparison of various LLMs on three benchmark datasets: Vicuna-bench, WizardLM testset, and MT-Bench. The models are categorized into 1B parameter models and 7B parameter models. For each model, the scores on each benchmark are shown, along with an average score across all three benchmarks. The table allows for a comparison of model performance based on model size and the training data used (Alpaca, Evol-Instruct, and Star-Instruct).
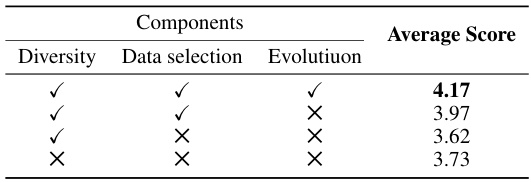
This table presents the average scores achieved by the Pythia-1B model when trained using different data selection methods: Evol-Instruct, IFD, Random, and Star-instruct. The Star-Instruct method, proposed by the authors, significantly outperforms the other methods, demonstrating its effectiveness in improving model performance by selecting high-quality data samples.

This table presents the performance comparison of various LLMs on three different benchmark datasets: Vicuna-bench, WizardLM testset, and MT-Bench. The models are grouped by their size (1B and 7B parameters) and include both baselines (trained on Alpaca and Evol-Instruct datasets) and models optimized using the Star-Agents framework (Star-Instruct dataset). The table shows the average score across all three benchmarks for each model, as well as individual scores for each benchmark. The results illustrate the effectiveness of the Star-Agents framework in improving the performance of LLMs.

This table presents a comparison of various LLMs’ performance across three benchmark datasets: Vicuna-bench, WizardLM testset, and MT-Bench. The models are categorized by their size (1B or 7B parameters). For each model and benchmark, the table shows the achieved score. This allows for a comprehensive evaluation of the models’ capabilities in various tasks, including reasoning, commonsense, and coding. The ‘Average’ column provides an aggregated score reflecting overall performance across the three benchmarks.

This table presents a comparison of various language models’ performance across three benchmark datasets: Vicuna-bench, WizardLM testset, and MT-Bench. The results showcase the average scores achieved by different models (including those trained with different data optimization techniques such as Alpaca, Evol-Instruct, and Star-Instruct) and different model sizes (1B and 7B parameters). The table helps evaluate the effectiveness of the Star-Agents framework in improving model performance on instruction-following tasks.

This table presents the performance comparison of various LLMs across three benchmark datasets: Vicuna-bench, WizardLM testset, and MT-Bench. Models are evaluated based on their instruction-following capabilities. The table shows the average scores for each model across all three benchmarks, allowing for a comprehensive comparison of performance.
Full paper#