↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Linear attention mechanisms, while efficient, often struggle with recall-intensive tasks and require substantial training resources. Existing gated variants, although offering improved performance, still fall short. This paper’s main objective is to address these shortcomings and improve linear attention models’ efficiency.
The paper introduces Gated Slot Attention (GSA), which enhances attention mechanisms using Bounded Memory Control and a novel gating mechanism. GSA leverages the benefits of both softmax operations and gated linear attention, achieving superior performance in in-context recall and finetuning settings, without needing significant memory or training resources. This represents a substantial improvement in linear attention models, offering both better performance and efficiency.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents Gated Slot Attention (GSA), a novel linear attention mechanism that significantly improves efficiency and performance in sequence modeling, especially for tasks requiring in-context recall. It addresses the limitations of existing linear attention methods by incorporating a gating mechanism and bounded memory control, leading to hardware-efficient training and faster inference without sacrificing accuracy. This has important implications for various applications requiring real-time processing of long sequences, such as large language models and time series analysis. Further research inspired by GSA could lead to more efficient and effective sequence modeling architectures.
Visual Insights#
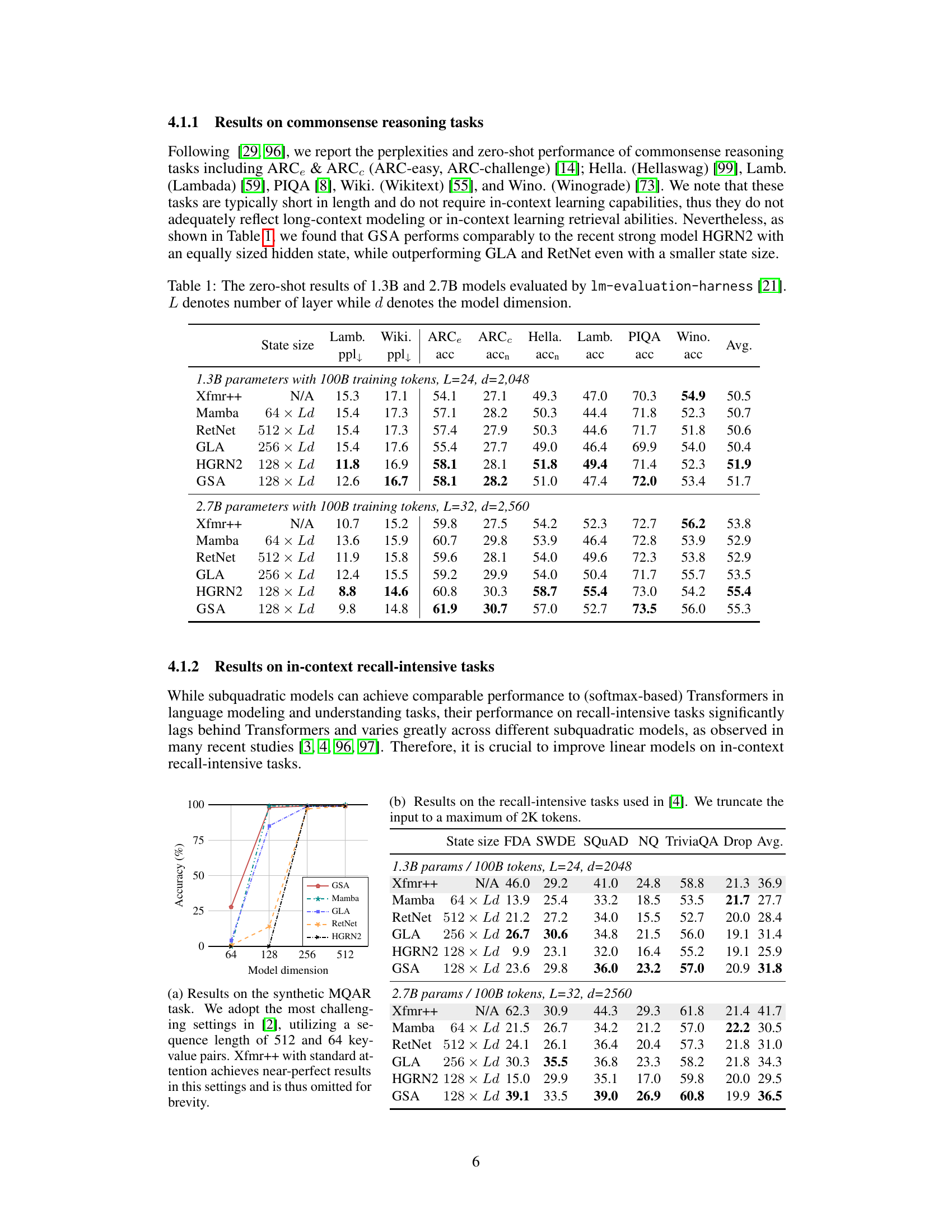
🔼 This figure shows the recurrent representation of the Gated Slot Attention (GSA) model. It illustrates how the model updates its hidden states (K and V) at each time step (t), incorporating a gating mechanism (αt) to control information flow. The model receives input (xt), updates its memory using the input and previous states, then outputs (ot). The gating mechanism helps to selectively retain and forget information, improving efficiency and performance.
read the caption
Figure 1: The recurrent representation of GSA. means taking æt as input.

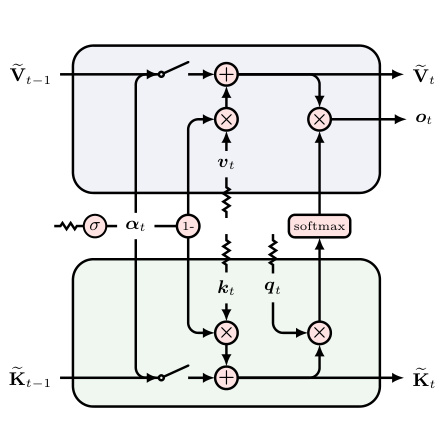
🔼 This table presents the zero-shot performance of 1.3B and 2.7B parameter models on various commonsense reasoning and world knowledge tasks. The performance is measured using perplexity (ppl) and accuracy (acc) and compared across different models (Xfmr++, Mamba, RetNet, GLA, HGRN2, and GSA) with varying hidden state sizes. The table highlights the comparative performance of GSA against other state-of-the-art models in this zero-shot setting.
read the caption
Table 1: The zero-shot results of 1.3B and 2.7B models evaluated by lm-evaluation-harness [21]. L denotes number of layer while d denotes the model dimension.
In-depth insights#
Gated Slot Attention#
Gated Slot Attention (GSA) is presented as a novel approach to enhance the efficiency and performance of linear attention mechanisms in sequence modeling. GSA combines the benefits of Bounded Memory Control (ABC) and Gated Linear Attention (GLA), using a gating mechanism and context-aware memory reading to improve memory capacity while maintaining a compact recurrent state size. This design leads to hardware-efficient training due to GLA’s algorithm and reduced inference costs due to the smaller state size. The authors highlight the particular benefit of retaining the softmax operation, which reduces discrepancies when fine-tuning pretrained Transformers, a cost-effective approach. Superior performance is shown in tasks demanding in-context recall and in scenarios involving fine-tuning pre-trained models to RNNs. Overall, GSA offers a promising approach to balance efficiency and performance in sequence modeling, particularly for tasks that require substantial in-context recall.
Linear Attention#
Linear attention mechanisms offer a compelling alternative to traditional quadratic attention in Transformer networks. They achieve linear time complexity, making them significantly more efficient for processing long sequences. This efficiency is crucial for deployment on resource-constrained devices and handling very long input sequences. However, simplicity comes at a cost: linear attention models often underperform standard attention, especially in tasks requiring rich contextual understanding and long-range dependencies. Recent research focuses on enhancing linear attention with gating mechanisms and other improvements to mitigate this performance gap and improve recall capabilities. These advancements aim to retain the benefits of efficient linear computation while approaching the performance levels of quadratic attention. The choice between linear and quadratic attention often involves a trade-off, balancing speed and accuracy for the specific application needs.
Recall-Memory Tradeoff#
The recall-memory tradeoff is a central challenge in sequence modeling, particularly for linear attention mechanisms. It highlights the inherent tension between a model’s ability to recall long-range information (recall) and its memory capacity (memory). Linear attention models, while efficient, often struggle with recall-intensive tasks because their memory is limited, discarding older information as new data arrives. This contrasts with traditional transformers which, despite their quadratic complexity, have significantly higher memory capacity. This paper’s innovation is introducing Gated Slot Attention (GSA), a mechanism intended to mitigate this limitation. By incorporating a gating mechanism and a bounded memory structure GSA aims to improve both training efficiency and in-context learning performance, reducing the need for extensive training from scratch and thus addressing cost concerns associated with longer sequence processing. The success of GSA suggests potential improvements to the recall-memory tradeoff in scenarios demanding extensive contextual information.
T2R Finetuning#
The concept of “finetuning pretrained Transformers to RNNs” (T2R) offers a compelling approach to leverage the power of pretrained Transformers while mitigating the high computational costs associated with training large recurrent models from scratch. T2R’s efficiency stems from utilizing the knowledge already embedded within the pretrained Transformer weights as a starting point for training a smaller, more efficient recurrent model. This approach significantly reduces the data and computational resources necessary, thereby making it practical to build large-scale recurrent models. However, a key challenge within T2R lies in the potential mismatch between the softmax-based attention mechanism of pretrained Transformers and the linear attention often used in RNNs. This discrepancy can lead to performance degradation and necessitates careful consideration of the adaptation strategy. The research highlighted in the provided text demonstrates that retaining the softmax operation during the T2R finetuning process offers significant advantages. It improves both training efficiency and the model’s performance, particularly in tasks demanding in-context recall. This highlights the importance of careful architecture design to bridge the gap between Transformer and RNN paradigms when implementing T2R finetuning.
Future Directions#
Future research could explore several promising avenues. Extending GSA to genuinely long sequences is crucial, as current evaluations focus on relatively short sequences. Investigating the impact of different architectural choices, such as varying the number of layers or implementing alternative gating mechanisms, would provide valuable insights into GSA’s scalability and performance limits. Addressing the tradeoff between recall and memory efficiency remains a significant challenge. While GSA improves on existing approaches, finding the optimal balance remains an open problem. Therefore, research on sophisticated memory management techniques and novel forgetting mechanisms that better balance recency and relevance is important. Finally, deeper exploration into finetuning strategies is necessary. While the authors demonstrate the effectiveness of finetuning pretrained Transformers to GSA, a more nuanced understanding of the underlying mechanisms and the influence of various hyperparameters is needed to fully unlock this approach’s potential. Further research should investigate potential applications of GSA to various domains. Specifically, exploring applications in areas like video understanding, where long sequences are prevalent, and biological sequence modeling could significantly expand the practical impact of GSA.
More visual insights#
More on figures

🔼 This figure shows the architecture of the proposed Gated Slot Attention (GSA) model. It consists of L GSA blocks stacked together. Each GSA block includes a GSA token mixing layer followed by a Gated Linear Unit (GLU) channel mixing layer. The GSA token mixing layer uses a multi-head attention mechanism. The GSA layer includes two passes of gated linear attention, and it is illustrated in Figure 1.
read the caption
Figure 2: The backbone of our proposed GSA models.

🔼 This figure shows the recurrent representation of the Gated Slot Attention (GSA) model. It illustrates how the model’s recurrent state is updated at each time step using the input token (xt) and gate values. The figure visually represents the flow of information and the calculations involved in the model’s operation. The key components of GSA, including the forget gate (at) and update values, are also depicted. This diagram helps in understanding how GSA uses a two-pass gated linear attention mechanism for more efficient training and inference.
read the caption
Figure 3: The recurrent representation of GSA. means taking æt as input.

🔼 This figure compares the training throughput, memory footprint, and inference latency of different 1.3B parameter models (Xfmr++, Mamba, RetNet, GLA, and GSA) on a single H800 GPU. It shows the impact of batch size and sequence length on training speed, memory usage, and inference time. The ‘GSA w/o recomp.’ line in (a) demonstrates the effect of recomputing hidden states during backpropagation to reduce memory consumption. The results indicate GSA’s relative efficiency and small memory footprint compared to other models.
read the caption
Figure 4: (a) Training throughput of various 1.3B models on a single H800 GPU, with a fixed batch size containing 16K tokens. “GSA w/o recomp.” indicates the use of the GSA kernel without hidden state recomputation during the backward pass. (b) Memory footprint (in GiB) of each 1.3B model during training with a batch size containing 16K tokens. (c) Inference latency (in seconds) of each 1.3B model on a single H800 GPU with 2K prefix tokens and a batch size of 1.

🔼 This figure illustrates the recurrent structure of the Gated Slot Attention (GSA) model. It shows how the input at each time step (xt) is processed through a series of operations involving linear transformations, gating mechanisms, and softmax to update the recurrent states (Kt, Vt) and generate the output (ot). The dashed lines represent the flow of information between different time steps, emphasizing the recurrent nature of the model.
read the caption
Figure 1: The recurrent representation of GSA. means taking æt as input.

🔼 This figure shows a detailed illustration of the recurrent representation of the Gated Slot Attention (GSA) model. It visually depicts how the input at time step t (xt) is processed through the model’s components, including the forget gate (at), to update the hidden state and produce the output (ot). It highlights the recursive nature of the GSA architecture and how information from previous time steps is used to inform the current output.
read the caption
Figure 1: The recurrent representation of GSA. means taking æt as input.
More on tables
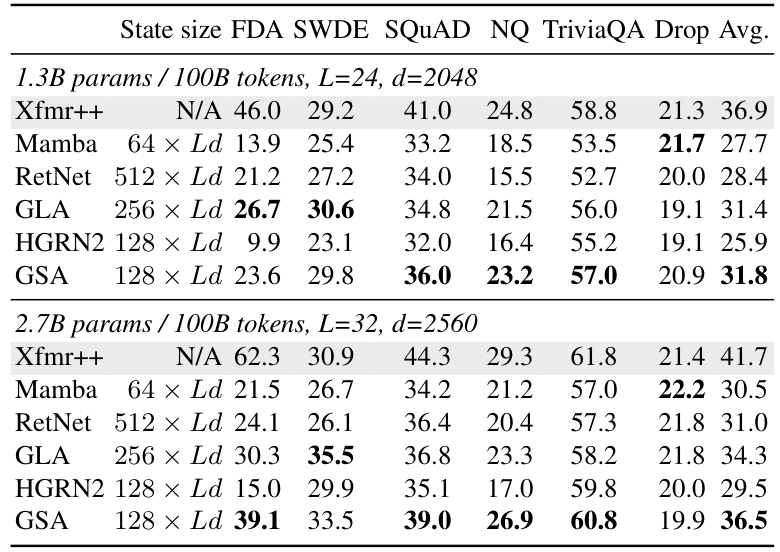
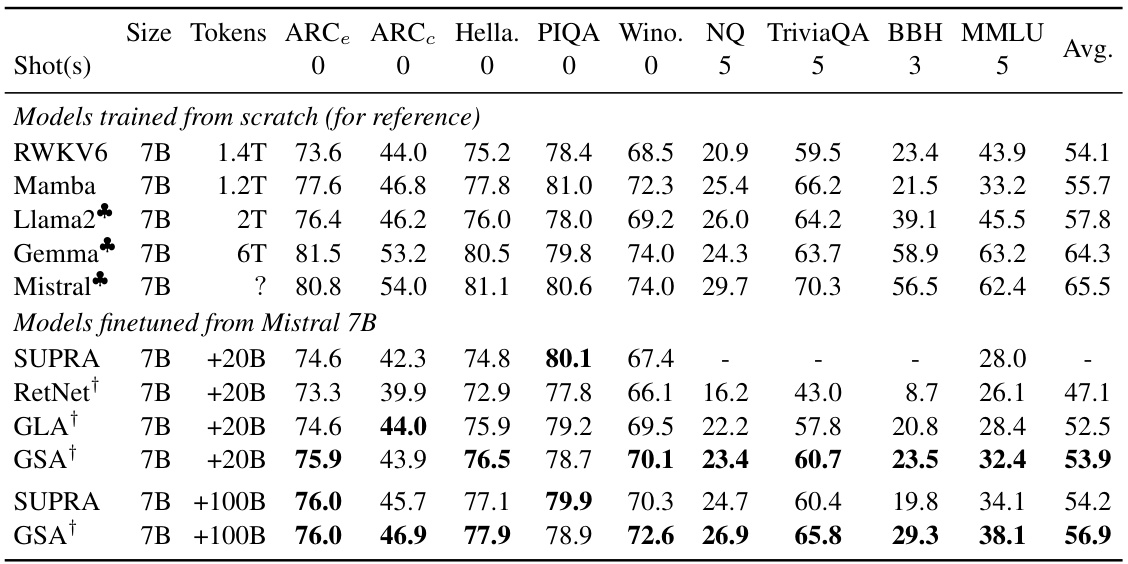
🔼 This table compares the performance of different 7B parameter models (including those trained from scratch and those fine-tuned from Mistral 7B) on various tasks. The tasks assess performance in commonsense reasoning, world knowledge, and aggregated benchmarks. The table highlights the relative performance of GSA compared to other models, focusing on its effectiveness in different model sizes and training data amounts.
read the caption
Table 3: Performance comparison across various 7B models. † denotes models using softmax-attention.
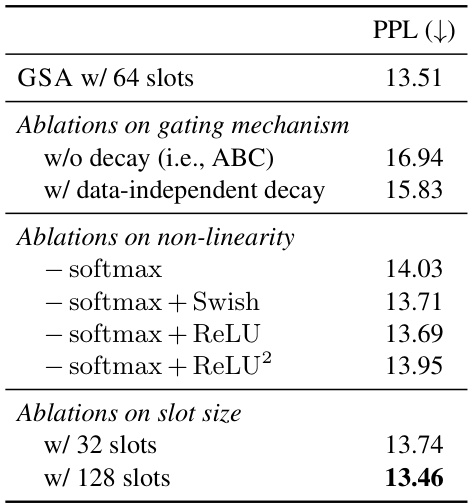
🔼 This table presents the results of ablation studies conducted on a 340M parameter model trained using 10B tokens from the Slimpajama corpus. It shows the impact of different design choices on the model’s performance, measured by perplexity (PPL). Specifically, it examines the effects of removing the gating mechanism (comparing to ABC), using a data-independent decay instead of a data-dependent one, testing different non-linearities (softmax, Swish, ReLU, and ReLU squared), and varying the number of memory slots (32, 64, and 128). Lower perplexity indicates better performance.
read the caption
Table 2: Ablation study results for 340M models trained on 10B Slimpajama tokens.
🔼 This table presents the zero-shot performance of 1.3B and 2.7B parameter models on various commonsense reasoning and knowledge tasks. The results are compared against several other models, showing GSA’s competitive performance, particularly with smaller state sizes. Metrics include perplexity (ppl), accuracy (acc) and are averaged across multiple tasks.
read the caption
Table 1: The zero-shot results of 1.3B and 2.7B models evaluated by lm-evaluation-harness [21]. L denotes number of layer while d denotes the model dimension.
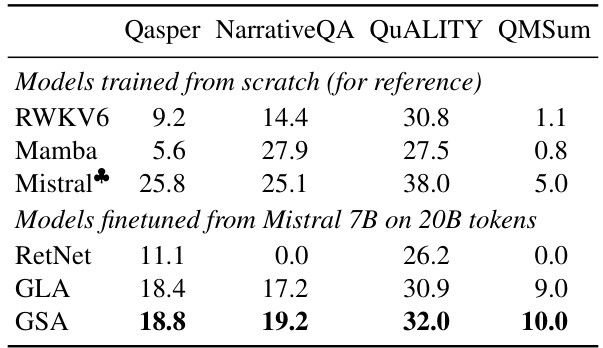
🔼 This table presents a comparison of the performance of various language models on long-context tasks. The models are evaluated on four tasks: Qasper, NarrativeQA, QUALITY, and QMSum. The input for each task is truncated to 16K tokens, which is 8 times the training length. The table shows that GSA consistently outperforms other subquadratic models, and even outperforms RWKV6 and Mamba (which were trained from scratch on >1T tokens) when finetuned from Mistral 7B on only 20B tokens.
read the caption
Table 4: Long-context performance comparison.
Full paper#