↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Image matting, separating foreground from background, is a challenging problem hindered by limited datasets and difficulties in accurately representing semi-transparent objects. Traditional two-stage methods (alpha then foreground prediction) accumulate errors. High-quality foreground color prediction remains elusive, especially for subtle details.
DRIP solves this by jointly predicting foreground and alpha using pre-trained latent diffusion models. A “switcher” mechanism and cross-domain attention ensure consistency. To overcome limitations of the model’s decoder, a transparency decoder was developed. Experiments show that DRIP significantly outperforms state-of-the-art methods across various benchmarks. It demonstrates the power of pre-trained models for improving image matting, particularly for challenging semi-transparent objects.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to image matting that leverages the power of pre-trained latent diffusion models. This significantly improves the accuracy and quality of both foreground and alpha predictions, particularly for challenging scenarios and rare objects. It opens new avenues for research in image editing and computer vision by combining the strengths of diffusion models with traditional matting techniques.
Visual Insights#
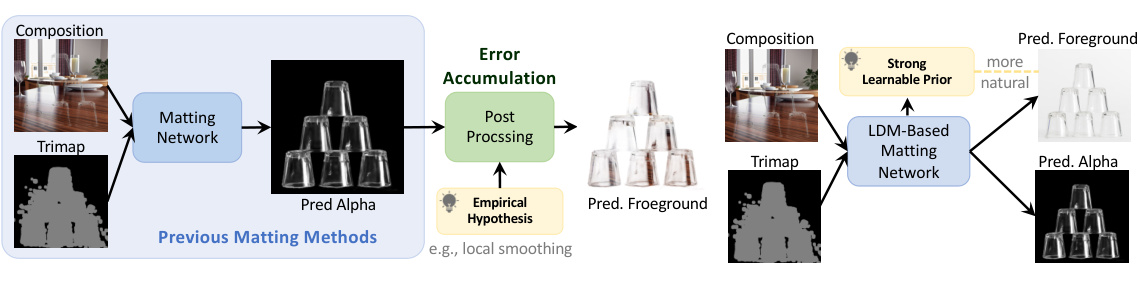
This figure compares traditional two-stage matting methods with the authors’ proposed method. Traditional methods first predict the alpha matte and then estimate the foreground color using post-processing, which may lead to error accumulation. In contrast, the authors’ method, Drip, jointly predicts both foreground and alpha simultaneously, leveraging the prior knowledge embedded in pre-trained Latent Diffusion Models (LDM) for improved accuracy and naturalness.
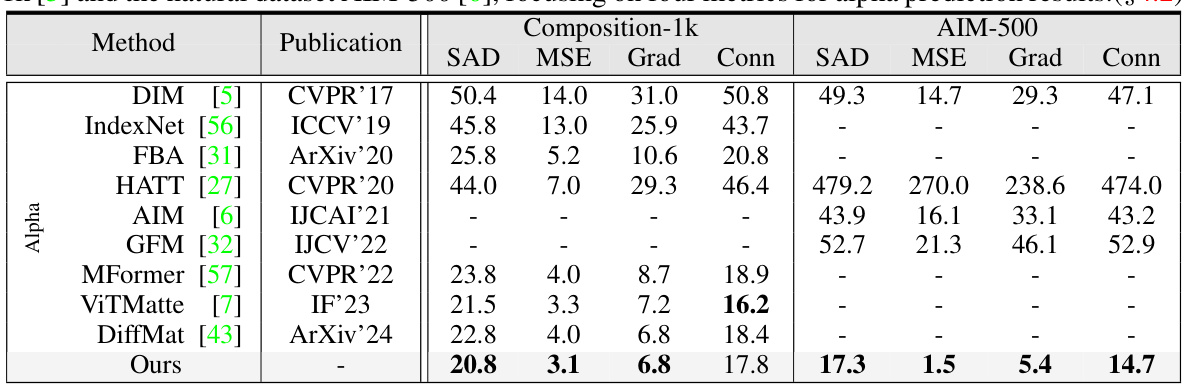
This table compares the performance of the proposed Drip model against other state-of-the-art (SOTA) methods on two benchmark datasets: Composition-1k (synthetic) and AIM-500 (natural). The comparison focuses on alpha prediction quality, using four metrics: SAD, MSE, Grad, and Conn. Lower values indicate better performance. The table provides a quantitative assessment of Drip’s effectiveness in alpha matte generation compared to existing approaches.
In-depth insights#
Diffusion Priors#
The concept of “Diffusion Priors” in the context of image matting is a significant advancement. It leverages the power of pre-trained latent diffusion models (LDMs), which have learned rich representations of natural images from massive datasets. These LDMs encapsulate inherent visual priors that aid in generating realistic foregrounds and alpha mattes, particularly in challenging scenarios involving rare objects or complex semi-transparent regions. Instead of relying solely on limited matting datasets, the method uses the LDM’s knowledge of the visual world to improve generation. This is particularly valuable because high-quality, comprehensively annotated image matting datasets are scarce. The approach cleverly incorporates the LDM’s prior knowledge to tackle the ill-posed nature of image matting, resulting in better and more generalized performance. The incorporation of a ‘switcher’ and ‘cross-domain attention’ mechanisms further enhance the consistency between foreground and alpha predictions, leading to improved visual quality. Finally, the addition of a latent transparency decoder mitigates the reconstruction errors of the LDM’s VAE, ultimately resulting in more accurate and detailed results.
LDM-Based Matting#
The heading ‘LDM-Based Matting’ suggests a novel approach to image matting that leverages the power of Latent Diffusion Models (LDMs). This likely involves using a pre-trained LDM, known for its ability to generate high-quality images from latent representations, as a prior for image matting. Instead of training a model from scratch on limited matting datasets, this method likely utilizes the rich prior knowledge embedded within the LDM, significantly improving performance, especially for challenging scenarios with semi-transparent objects or rare instances. The core idea is to leverage the LDM’s ability to generate both foreground and alpha matte simultaneously, possibly through a conditional generation process guided by the input image and trimap. This joint prediction framework offers a distinct advantage over traditional two-stage approaches (alpha prediction followed by foreground extraction), which often suffer from error accumulation. By directly generating both modalities, the method potentially achieves better consistency and higher fidelity in the final results. The use of LDMs addresses the key challenge of limited training data in image matting by incorporating knowledge learned from massive datasets used to train the LDM. A crucial aspect would be addressing potential reconstruction errors inherent in the LDM’s VAE decoder—a task likely accomplished through novel decoder architectures or loss functions. The success of this approach would greatly depend on the effective integration of the LDM’s capabilities within the matting framework and skillful handling of potential challenges inherent in this novel combination of technologies.
Cross-Domain Attn#
The concept of ‘Cross-Domain Attn,’ or cross-domain attention, is a powerful technique for enhancing the consistency and mutual information exchange between different modalities in a multi-modal model. It elegantly addresses the challenge of aligning representations from disparate data sources, such as foreground and alpha channels in image matting. By using a cross-domain attention mechanism, the model can effectively learn relationships across modalities that might otherwise be missed using independent attention mechanisms. This approach improves performance by enabling information from one modality to inform and refine predictions in the other. The key lies in how the cross-domain attention mechanism is designed, whether it utilizes shared keys and values or employs a more sophisticated method to relate the modalities. Careful consideration of this design choice is critical to achieving the benefits of cross-domain attention without introducing unwanted complexity. Ultimately, the effectiveness depends heavily on the quality of the feature representations fed into the attention mechanism and the extent to which those representations capture salient information relevant to both modalities. Using this approach, the model can more accurately recover high-fidelity foregrounds and high-quality alpha mattes.
Latent Decoder#
A latent decoder, in the context of diffusion models, reconstructs high-dimensional data (like images) from lower-dimensional latent representations. Its role is crucial in generative models, as it bridges the gap between the learned latent space and the real-world data space. In image matting, a latent decoder is essential for generating realistic foregrounds and alpha mattes from their compressed latent representations. However, standard latent decoders often suffer from reconstruction errors, losing fine details present in the original images. To address this issue, the proposed method introduces a novel latent transparency decoder. This modification aims to improve the accuracy and fidelity of the generated foreground and alpha mattes by incorporating additional features and improving alignment with the input image. The inclusion of such a decoder highlights the importance of carefully considering the limitations of latent representations in image generation tasks and improving the decoder architecture to enhance reconstruction quality and detail preservation. The transparency decoder’s effectiveness is experimentally validated by comparing its performance to standard decoder setups.
Future Works#
The paper’s ‘Future Work’ section could explore several promising directions. Extending the model to handle more complex scenarios such as videos or 3D scenes would significantly broaden its applicability. Improving the model’s efficiency is crucial for real-world deployment, especially in resource-constrained environments. This might involve exploring more efficient network architectures or quantization techniques. Addressing the potential biases inherited from the pre-trained LDM by developing methods for bias mitigation or incorporating more diverse datasets during training is vital for ensuring fairness and robustness. Investigating the model’s robustness against various types of noise or image corruptions would also strengthen its reliability. Finally, a thorough investigation into the model’s generalization capabilities across different image domains and object types would be valuable to assess its potential for broader adoption and further development.
More visual insights#
More on figures
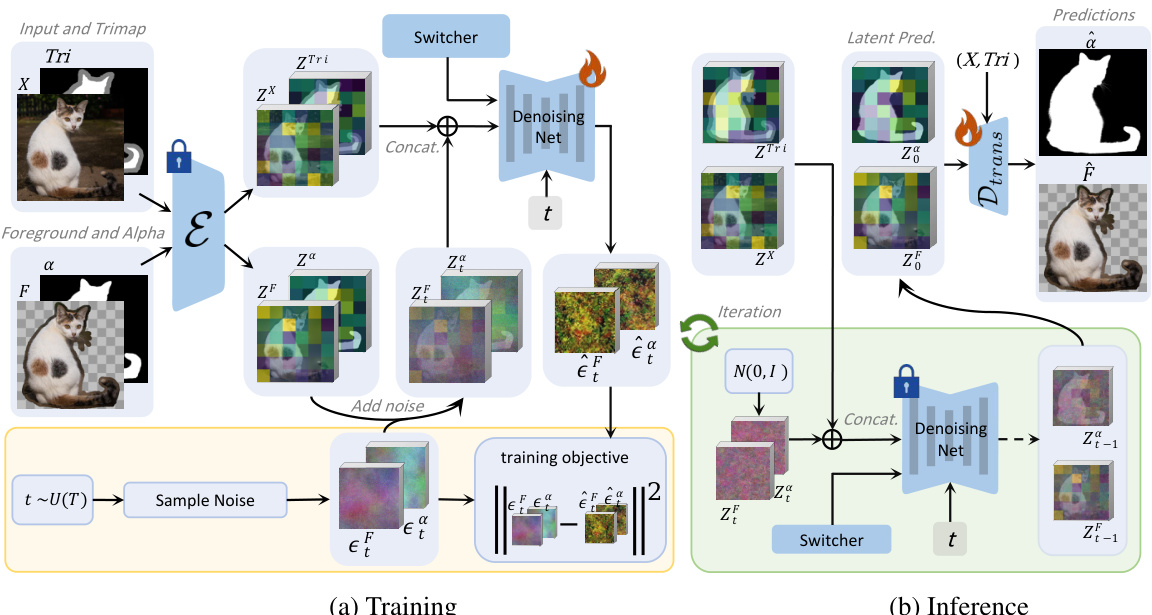
This figure illustrates the training and inference processes of the Drip model. In training (a), input image and trimap are encoded using a VAE, noise is added to the foreground and alpha latent codes, and these are fed to a U-Net for joint generation, guided by a switcher. The U-Net is trained to minimize the standard diffusion objective. In inference (b), after T-step denoising, the generated latent codes are decoded by a transparent latent decoder to produce the final foreground and alpha matte.

This figure illustrates the Cross-Domain Attention mechanism used in the Drip model. It shows how the model uses a cross-domain self-attention layer (instead of a standard self-attention layer) within the U-Net architecture. This modification allows for improved mutual guidance and consistency between the foreground and alpha latent representations during the joint generation process. The input from a residual block is processed through self-attention, then modified to include both alpha and foreground latents, enabling the cross-domain self-attention mechanism to work before finally being processed by a cross-attention layer.
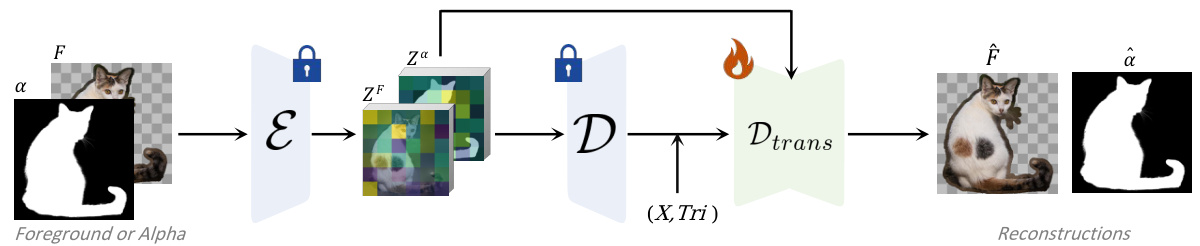
This figure illustrates the architecture of the Transparent Latent Decoder, a component of the Drip model. The decoder addresses the reconstruction loss from the Latent Diffusion Model’s Variational Autoencoder (VAE) by taking the LDM’s outputs (foreground and alpha) and their corresponding latent representations as inputs. It generates refined foreground and alpha predictions that are more aligned with the details of the original composite image, improving overall fidelity.

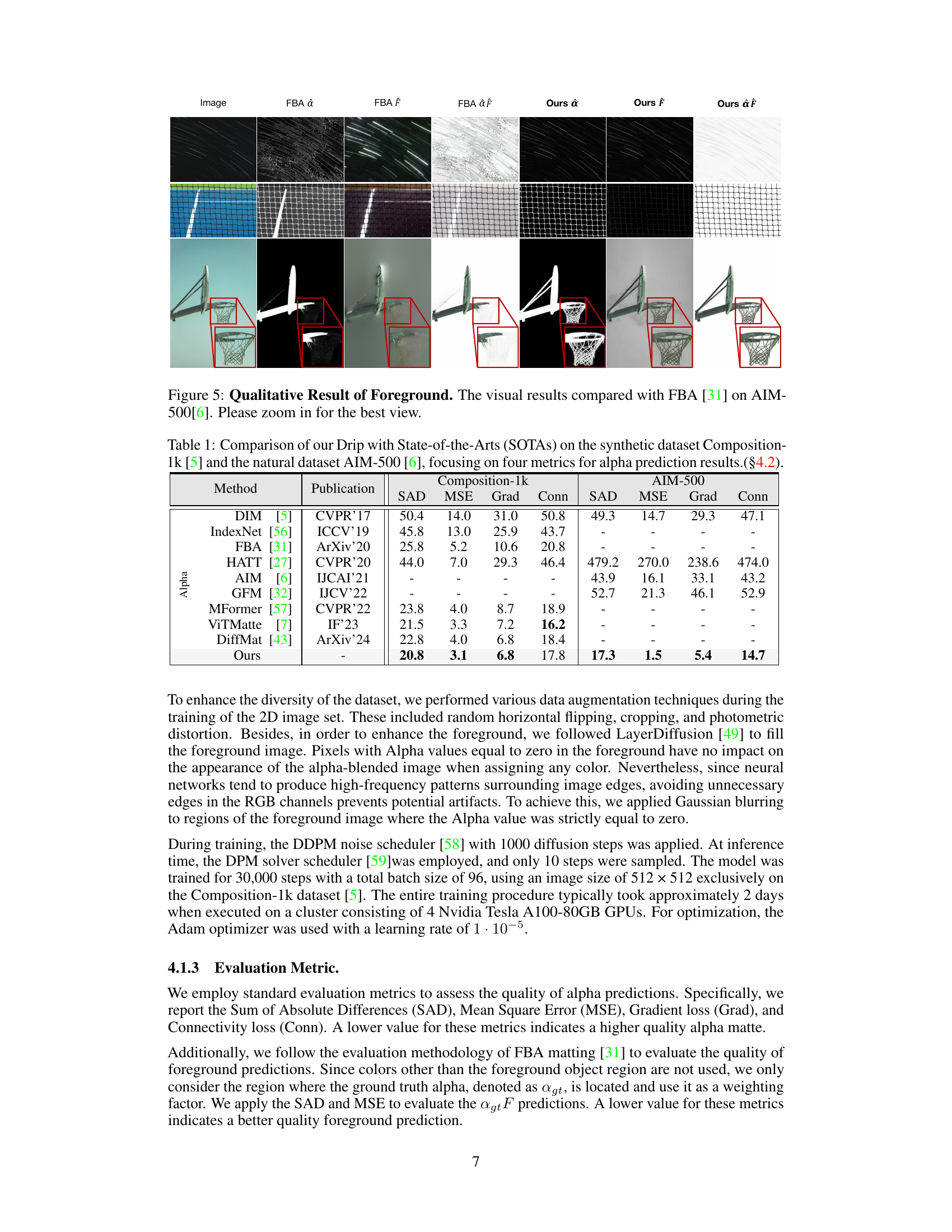
This figure presents a qualitative comparison of the foreground prediction results between the proposed Drip method and the FBA method [31] on the AIM-500 dataset [6]. It shows three example images where the Drip method outperforms FBA, producing more realistic and detailed foreground predictions, especially in challenging scenarios involving complex textures or semi-transparent objects. The improved quality is visually apparent, with Drip’s results demonstrating greater fidelity and reduced artifacts.

This figure showcases a qualitative comparison of foreground prediction results between the proposed Drip method and the FBA [31] method on the AIM-500 dataset. It presents visual examples of image matting results, comparing the ground truth foreground, the results produced by FBA, and those produced by Drip. The figure aims to demonstrate the superior quality and realism of foreground predictions achieved by Drip compared to FBA, particularly in terms of detail preservation and visual fidelity.
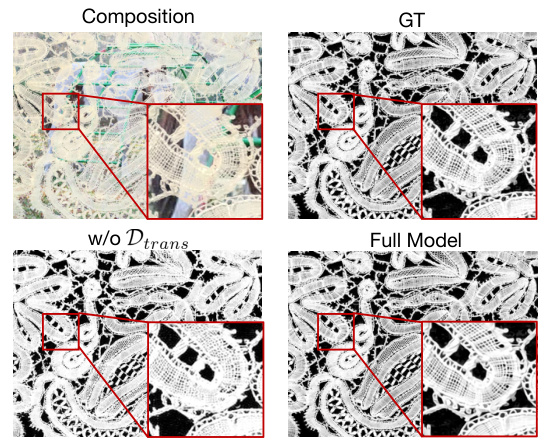
This figure presents a qualitative comparison of the results obtained with and without the proposed latent transparency decoder. The top row shows the original composite image and its ground truth matte. The bottom row shows the results generated by the model without the latent transparency decoder and the full model, respectively. The red boxes highlight regions where the lack of the decoder leads to artifacts and discrepancies in the generated matte, particularly concerning fine details and high-frequency components. This visualization empirically demonstrates the effectiveness of the latent transparency decoder in improving the quality and consistency of the generated matte.
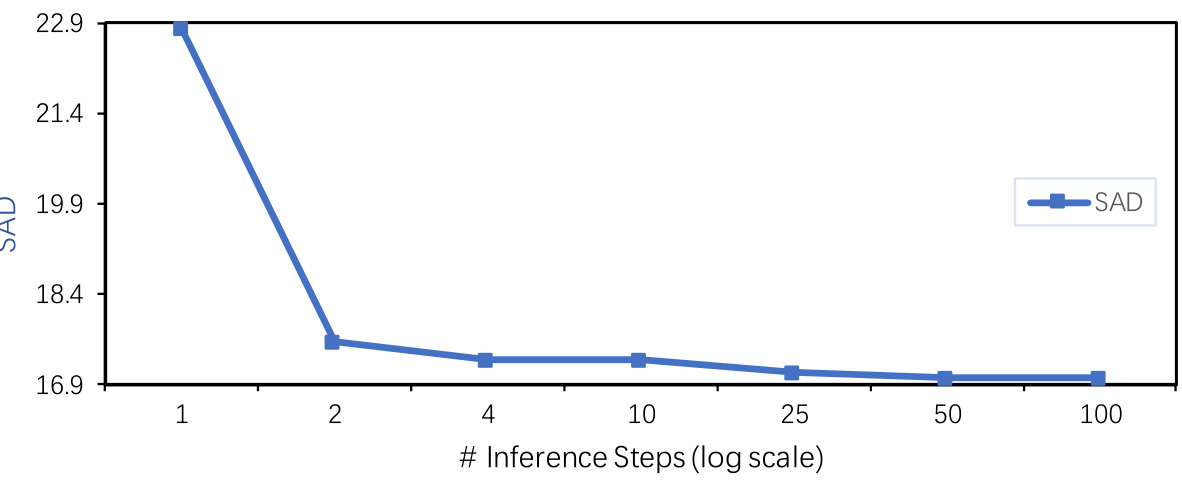
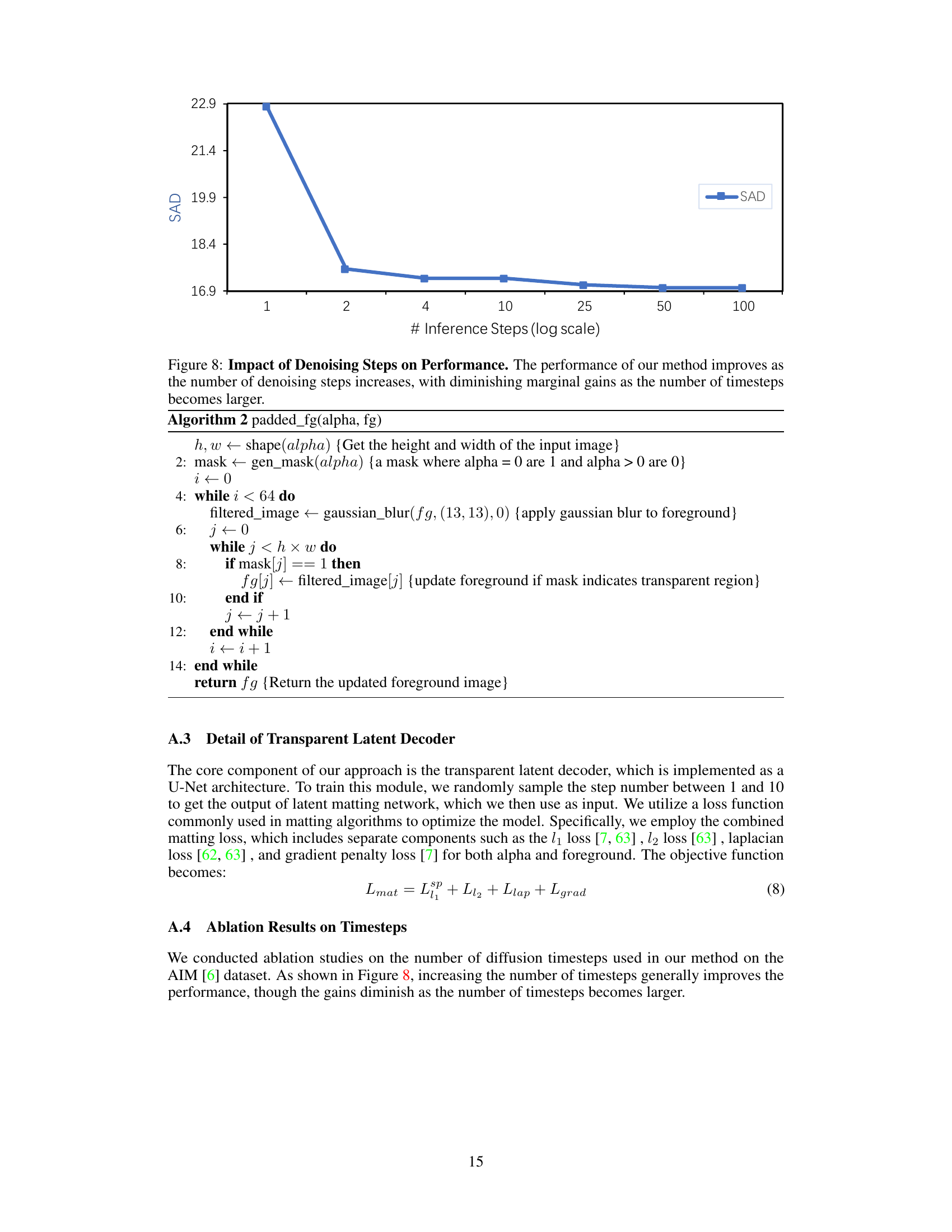
The figure shows a plot of the SAD (Sum of Absolute Differences) metric against the number of inference steps used during the denoising process. The x-axis is presented on a logarithmic scale, showing the number of steps (1, 2, 4, 10, 25, 50, 100). The y-axis represents the SAD values. The plot demonstrates that increasing the number of denoising steps generally leads to improved performance (lower SAD), but the rate of improvement diminishes as the number of steps increases. This suggests a point of diminishing returns where additional steps provide minimal benefit. This is a key result illustrating the efficiency of the proposed method.
More on tables
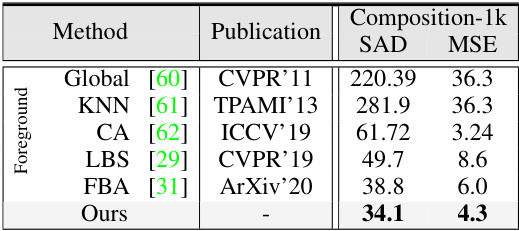
This table presents a quantitative comparison of the proposed Drip method against several state-of-the-art (SOTA) image matting methods on two benchmark datasets: Composition-1k (synthetic) and AIM-500 (natural). The comparison focuses on alpha prediction performance, using four metrics: SAD, MSE, Grad, and Conn. Lower values indicate better performance. The table highlights Drip’s superior performance compared to existing methods on both datasets, particularly regarding SAD and MSE metrics.

This table presents the results of ablation studies conducted on the AIM-500 dataset to evaluate the contributions of different modules in the proposed Drip model. Specifically, it compares the performance (measured by SAD and MSE metrics for alpha (â) and foreground (F)) of variations of the model, systematically removing components such as the switcher, cross-domain attention (CDAttn), and the transparent latent decoder. The table helps quantify the impact of each component on both alpha and foreground prediction accuracy.
Full paper#