↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Training large machine learning models on massive datasets is expensive and resource-intensive. Existing data downsampling techniques often struggle with class imbalance and distributional shifts, resulting in suboptimal performance, particularly for underrepresented classes. This limits the applicability of advanced models to real-world scenarios with noisy or imbalanced data.
The paper introduces REDUCR, a novel online data downsampling technique that uses class priority reweighting. This approach dynamically adjusts weights to prioritize underperforming classes, improving their representation in the training data. Experiments on various vision and text classification datasets show REDUCR consistently outperforms existing state-of-the-art methods, achieving a significant boost (around 15%) in worst-class accuracy and average accuracy, especially in imbalanced settings. This makes training efficient and robust machine learning models more feasible for real-world applications.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical issue of high training costs and poor generalization in modern machine learning, particularly in imbalanced datasets. The robust and efficient data downsampling method proposed, REDUCR, offers a significant advancement over existing techniques. Its superior performance on diverse datasets opens avenues for more efficient and robust model training, particularly relevant to researchers working with large-scale, real-world datasets and dealing with class imbalance issues.
Visual Insights#
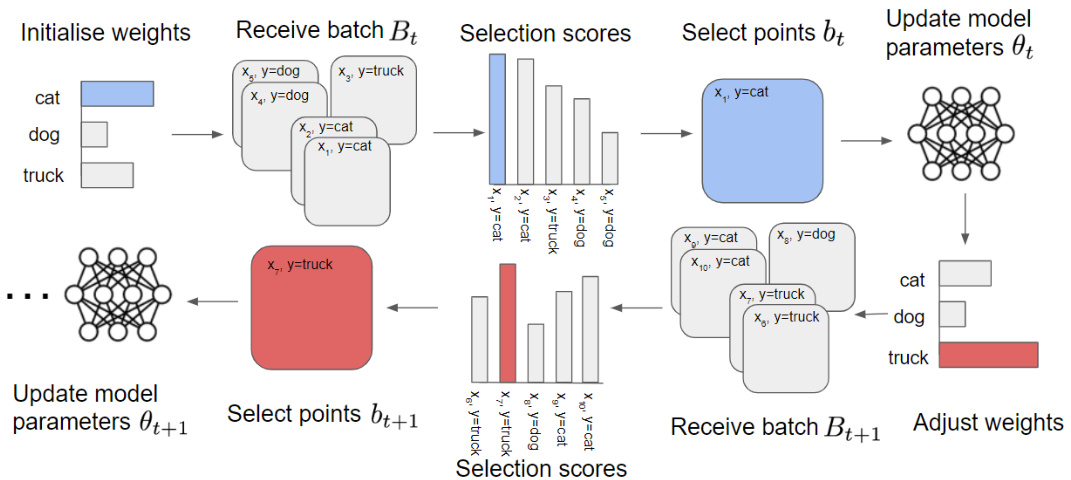
This figure illustrates the REDUCR algorithm’s workflow. It starts with initializing class weights. At each timestep, a batch of datapoints (Bt) is received. The algorithm then calculates selection scores for each datapoint, considering its usefulness to the model and the current class weights. Datapoints (bt) with the highest scores are selected for model training. After model updates based on the selected datapoints, REDUCR adjusts class weights to prioritize underperforming classes, ensuring better generalization performance across all classes.
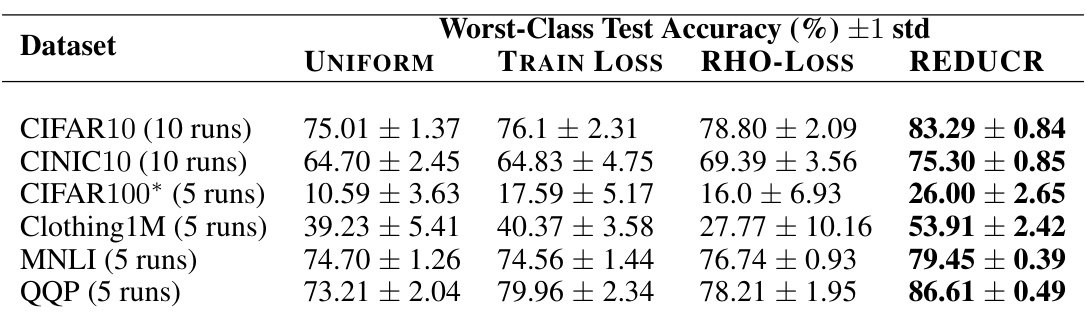
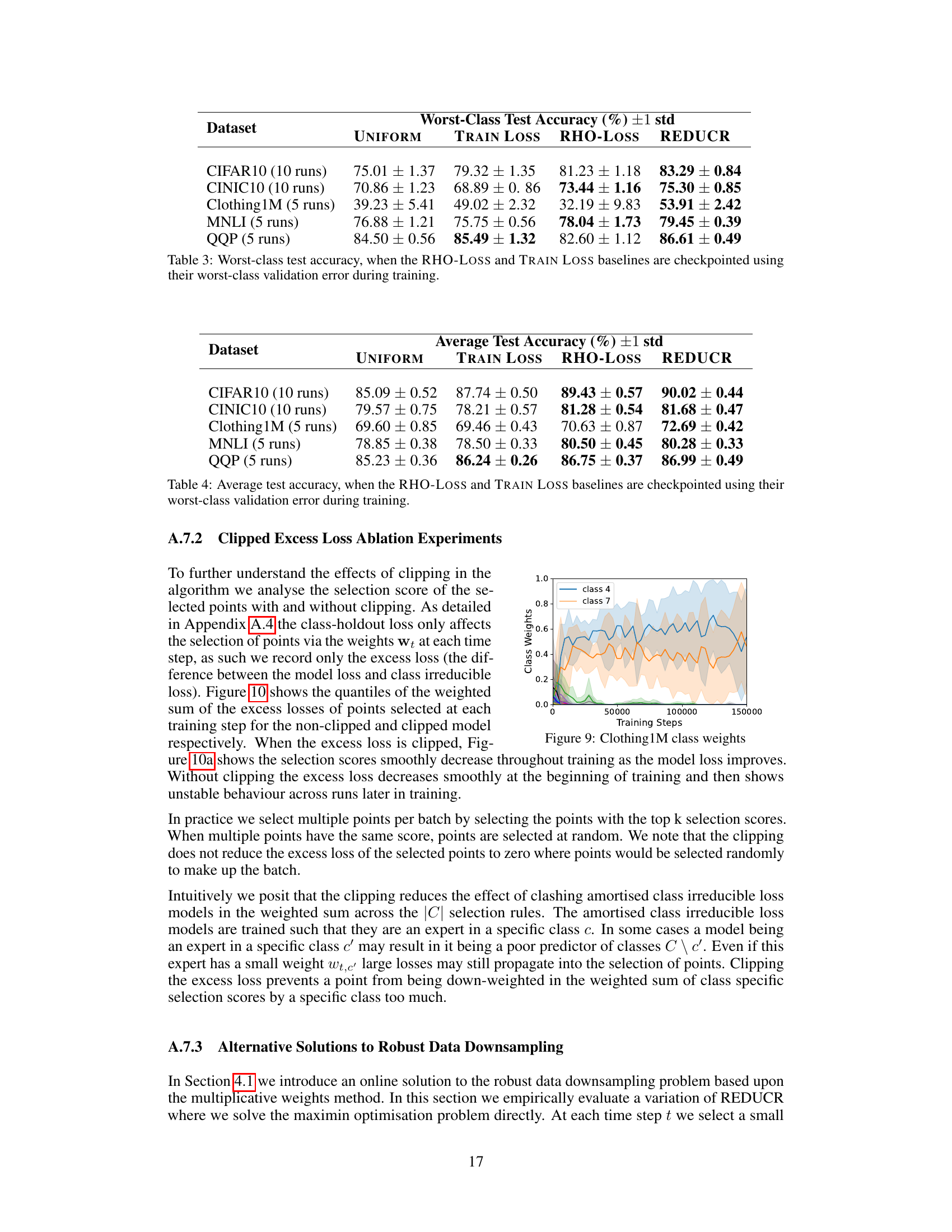
This table presents the worst-class test accuracy results for six different datasets (CIFAR10, CINIC10, CIFAR100, Clothing1M, MNLI, and QQP) using four different methods: UNIFORM, TRAIN LOSS, RHO-LOSS, and REDUCR. The results show that REDUCR consistently outperforms the other methods, particularly on the more challenging datasets like Clothing1M, achieving significantly higher worst-class accuracy. The improved performance is especially noticeable on noisy and imbalanced datasets. Note that the CIFAR100 result is a snapshot at training step 10k.
In-depth insights#
REDUCR Algorithm#
The REDUCR algorithm addresses robust data downsampling by using class priority reweighting. It tackles challenges like class imbalance and distributional shifts in online batch selection, aiming for improved worst-class generalization performance. REDUCR assigns priority weights to data points based on their usefulness to the model and the class weights, dynamically updating these weights to focus on underperforming classes. This mechanism uses an online learning algorithm, making it efficient for large-scale datasets. The algorithm incorporates a novel selection rule that considers each data point’s impact on a specific class’s generalization error. By addressing the maximin problem, REDUCR prioritizes data efficiency while safeguarding the performance of the worst-performing class. This makes it suitable for real-world settings with massive, imbalanced datasets.
Class Imbalance#
Class imbalance, a pervasive issue in machine learning, significantly impacts model performance. It arises when the number of samples in different classes varies drastically, leading to biased models that favor the majority class. This is because models often optimize for overall accuracy, neglecting the minority class. Addressing this requires careful consideration of sampling techniques, cost-sensitive learning, and algorithmic modifications. Resampling methods, such as oversampling the minority class or undersampling the majority class, aim to balance class representation. However, they can introduce noise or lose valuable information. Cost-sensitive learning assigns different misclassification costs to each class, penalizing errors on the minority class more heavily, thereby improving its prediction performance. Algorithmic approaches focus on modifying the learning algorithm itself to handle class imbalance effectively, focusing on improving the generalization ability of the model and reducing bias towards the majority class. The choice of method depends significantly on the dataset characteristics and the specific application context; therefore, a combination of techniques may be necessary for optimal results.
Maximin Problem#
The maximin problem, in the context of robust data downsampling, presents a significant challenge. It aims to find a subset of the training data that minimizes the maximum generalization error across all classes. This contrasts with standard approaches that focus solely on average performance, making the maximin objective much more complex. Solving this problem is computationally expensive due to the need to consider all possible subsets of the training data and the worst-case performance for each class. The inherent difficulty stems from the need to balance the competing demands of optimizing for the worst-performing class while maintaining reasonable performance elsewhere. Robust solutions require carefully crafted algorithms that can handle class imbalance, noise, and potential distributional shifts between training and test data. The introduction of class priority reweighting and online learning techniques helps to mitigate these complexities, by dynamically prioritizing underperforming classes and adapting to changing data distributions.
Robust Downsampling#
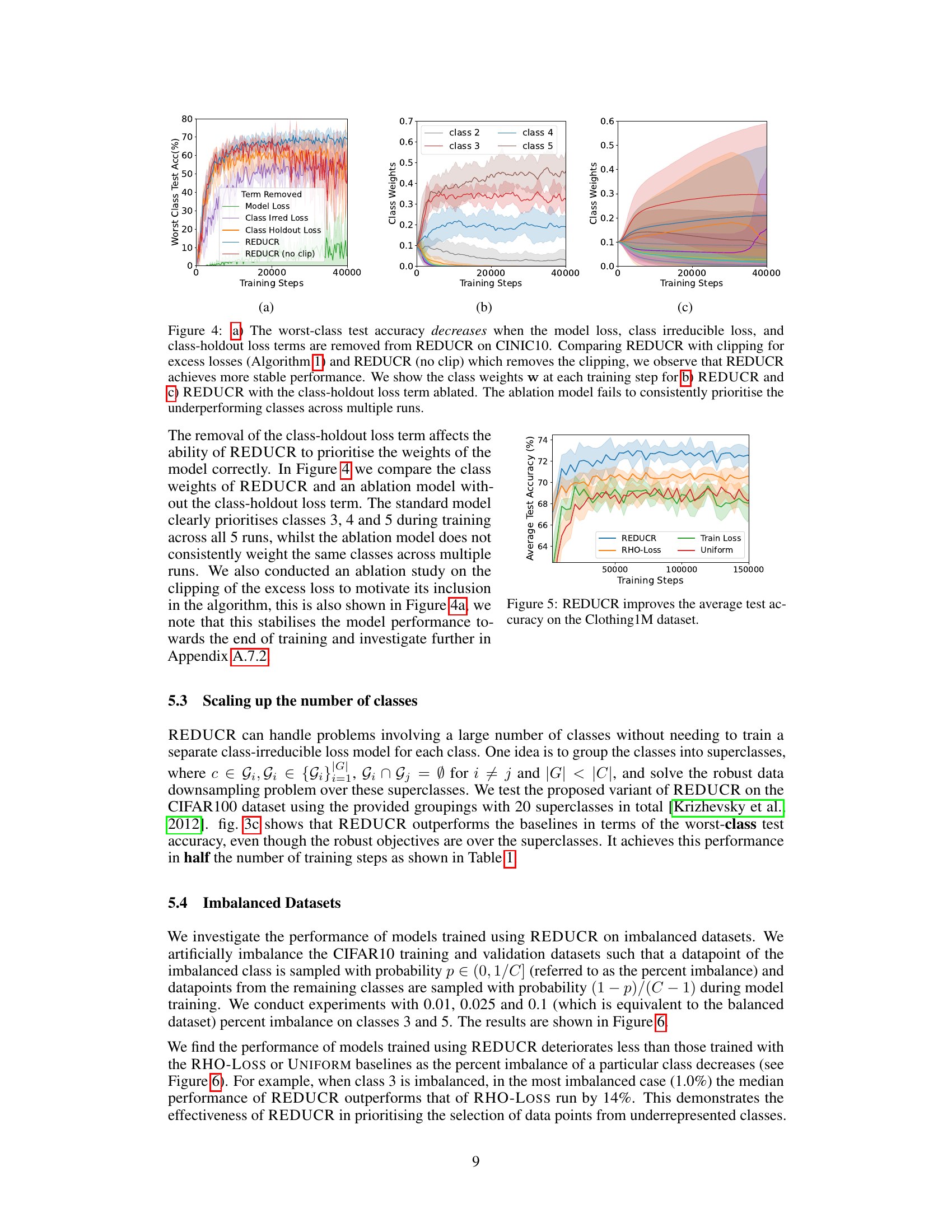
Robust downsampling techniques in machine learning aim to reduce training data size without sacrificing model performance, particularly focusing on handling class imbalance and distributional shifts. These methods are crucial for efficient training of large models on massive datasets and for mitigating the negative impact of noisy or biased data. A robust method should prioritize data points that maximally improve model generalization, especially for under-represented classes. This involves class-aware weighting schemes, or advanced selection criteria beyond simple random sampling or loss-based selection. Online learning algorithms are often employed to adapt to dynamically arriving data streams, offering efficiency and robustness. Successful robust downsampling methods demonstrate superior performance compared to naive approaches, showcasing improved accuracy, especially in worst-case scenarios (e.g., for the least-represented classes), while maintaining overall efficiency.
Future Research#
Future research directions stemming from the REDUCR paper could explore several promising avenues. Improving computational efficiency for a large number of classes is crucial, perhaps through hierarchical class structures or more efficient approximation methods for class-irreducible loss. Investigating the impact of different data distributions beyond those tested (e.g., highly imbalanced scenarios, non-stationary distributions) would enhance the robustness claims. A deeper analysis of the interaction between the selection rule, class reweighting, and model training dynamics is necessary to gain more insights into REDUCR’s performance. Finally, extending REDUCR’s applicability to other machine learning tasks such as regression or sequence modeling, and evaluating performance on diverse real-world datasets would further solidify the method’s practical impact.
More visual insights#
More on figures

The figure is a bar chart comparing the worst-class test accuracy of different online batch selection methods on the Clothing1M dataset. REDUCR significantly outperforms other methods, including Uniform sampling and the state-of-the-art method from Loshchilov and Hutter (2015), demonstrating its robustness and effectiveness in improving the performance of the worst-performing class.
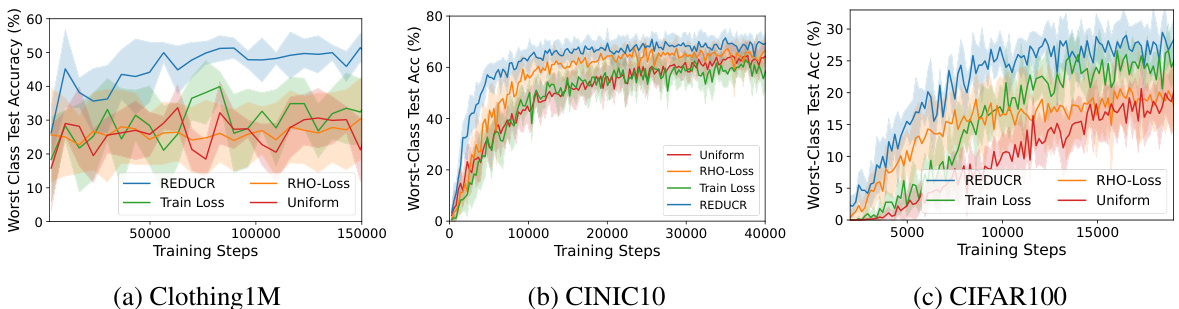
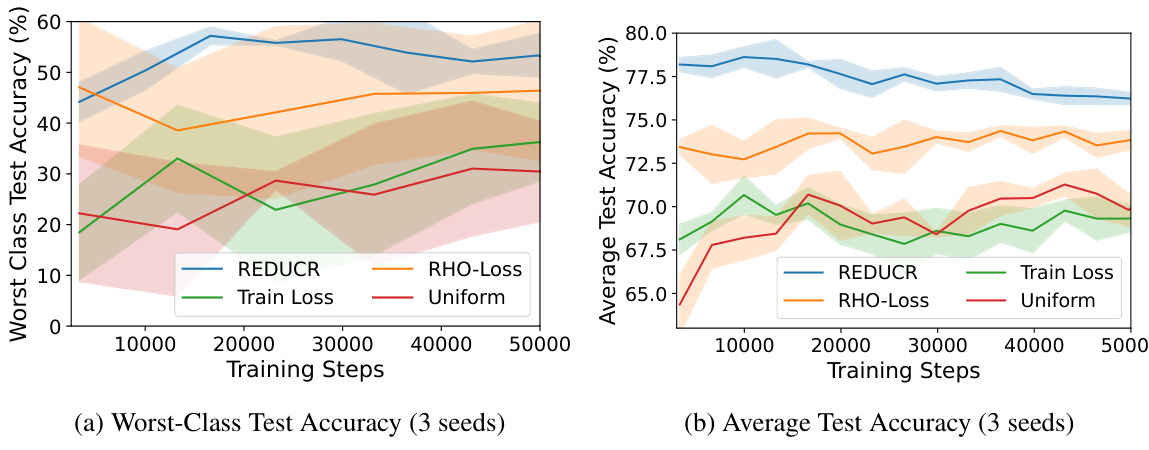
The figure shows the performance of REDUCR compared to three baseline methods (RHO-Loss, Train Loss, Uniform) across three image classification datasets (Clothing1M, CINIC10, CIFAR100). Each subplot displays the worst-class test accuracy over training steps. REDUCR consistently outperforms the baselines, demonstrating improved data efficiency and robustness to class imbalance.
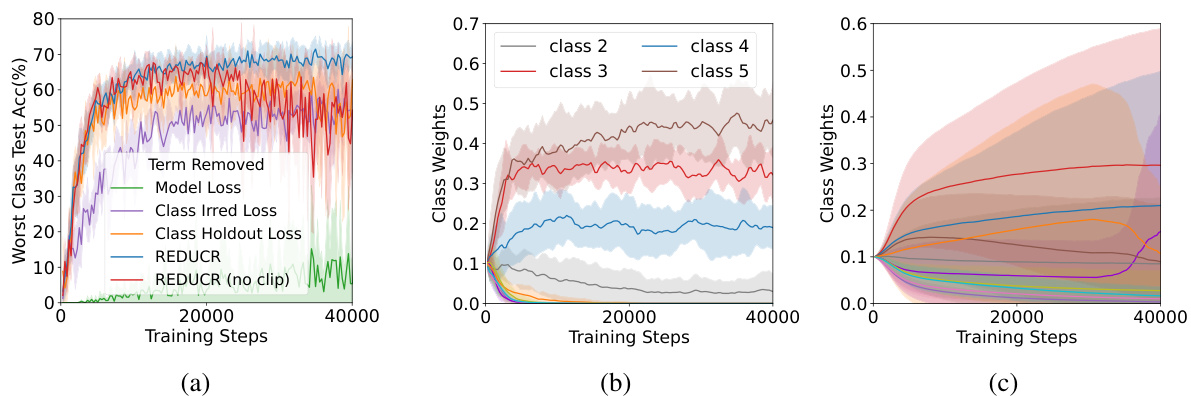
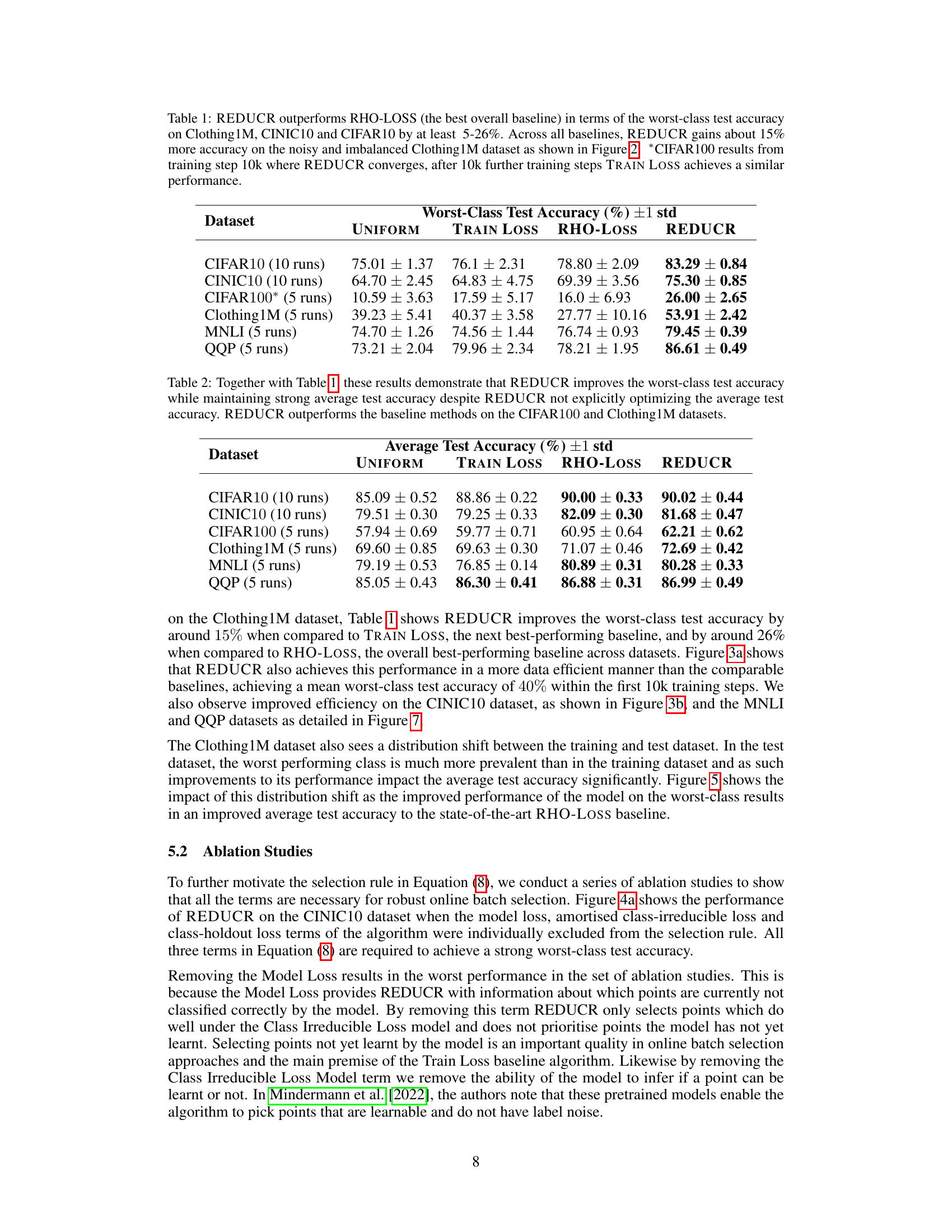
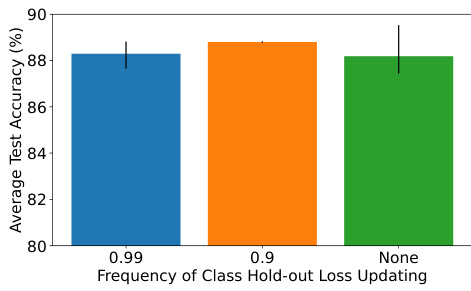
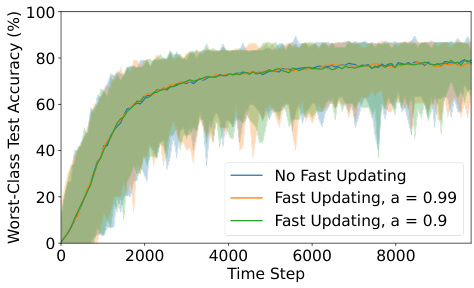
The figure shows the ablation study of the REDUCR algorithm, demonstrating the impact of removing each of its three loss terms (model loss, class-irreducible loss, and class-holdout loss) on the worst-class test accuracy and class weights. The results highlight that all three terms are crucial for optimal performance and stability, as removing any one significantly degrades the results. The comparison between REDUCR with and without clipping of the excess loss showcases the improved stability of the clipping mechanism.

This figure shows the training curves for worst-class test accuracy for three different datasets: Clothing1M, CINIC10 and CIFAR100. The results show that REDUCR consistently outperforms other methods in terms of worst-class accuracy, achieving a significant boost in performance compared to the baselines (RHO-Loss, Train Loss, and Uniform). The plots demonstrate REDUCR’s improved data efficiency by achieving comparable or better accuracy with fewer training steps.

This figure displays the results of comparing REDUCR against three baseline methods (RHO-Loss, Train Loss, and Uniform) using three different datasets (Clothing1M, CINIC10, and CIFAR100). For each dataset, the worst-class test accuracy is plotted against the number of training steps, illustrating REDUCR’s superior performance and efficiency in improving worst-class accuracy.

The figure shows three plots visualizing the performance of REDUCR compared to three baseline methods (RHO-Loss, Train Loss, and Uniform) across three different datasets (Clothing1M, CINIC10, and CIFAR100). Each plot shows the worst-class test accuracy over training steps. REDUCR consistently outperforms the baselines, demonstrating its effectiveness in improving the worst-performing class’s accuracy and data efficiency.

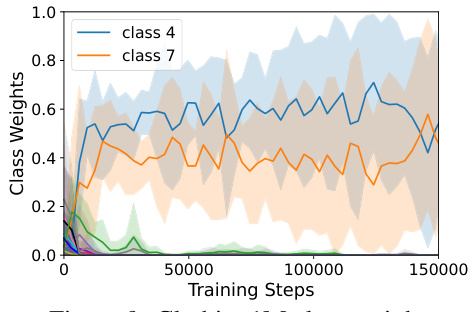
This figure shows the class distribution shift between the training and testing sets of the Clothing1M dataset. It highlights a significant difference in the proportions of certain classes (particularly classes 4 and 7) between the training and testing data, indicating a potential distributional shift that could impact model performance.
This figure compares the performance of REDUCR against three baseline methods (RHO-Loss, Train Loss, and Uniform) across three different datasets (Clothing1M, CINIC10, and CIFAR100). Each subfigure shows the worst-class test accuracy over training steps. REDUCR consistently outperforms the baselines, demonstrating improved worst-class accuracy and efficiency.
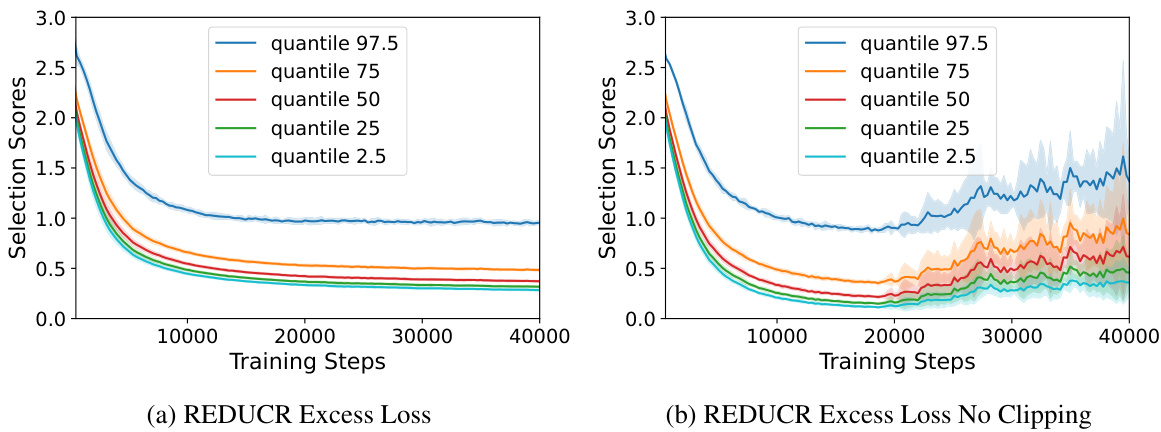
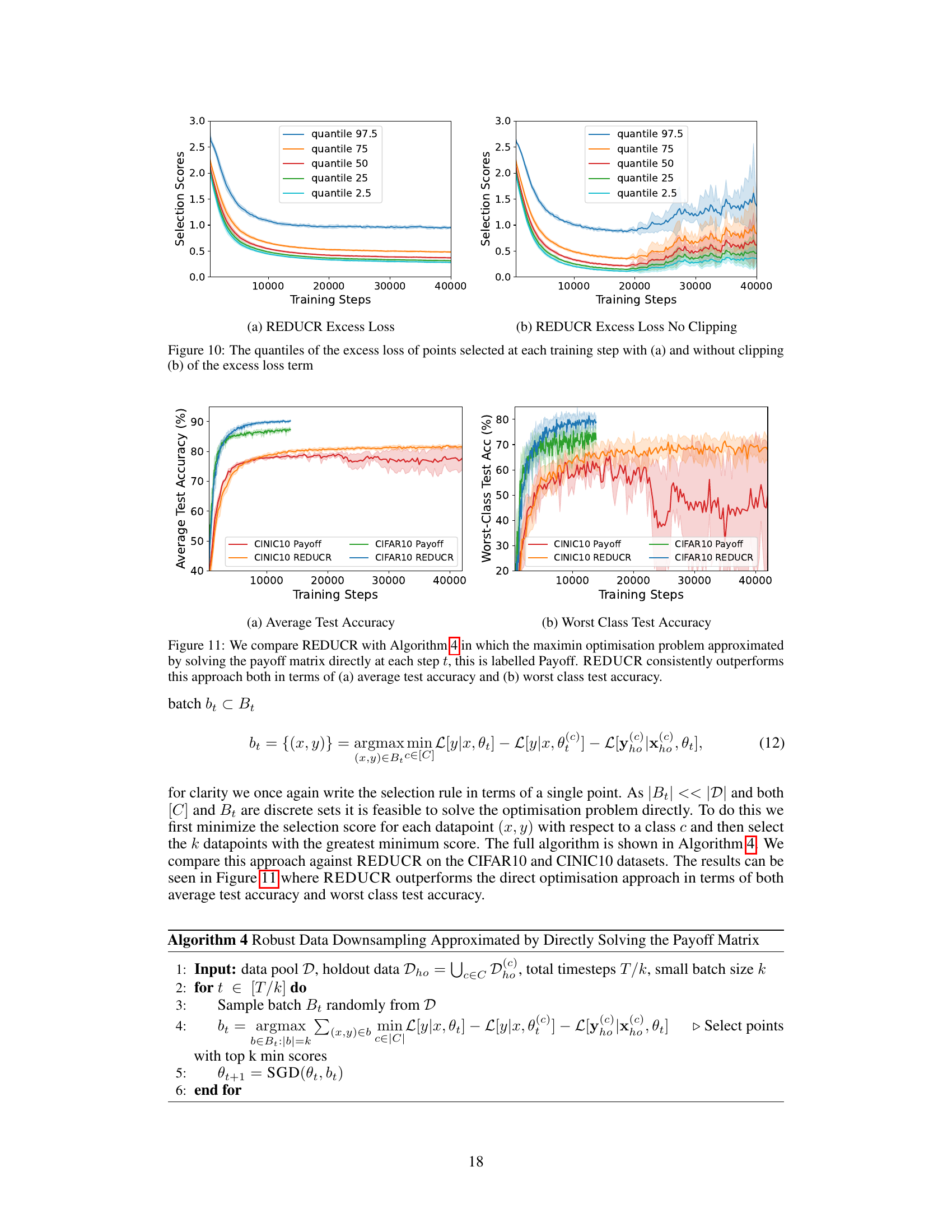
This figure shows the effect of clipping on the excess loss in the REDUCR algorithm. The excess loss is the difference between the model loss and the class-irreducible loss. Clipping helps to stabilize the selection scores during training, making the algorithm more robust. The figure shows the quantiles (2.5th, 25th, 50th, 75th, 97.5th) of the weighted sum of excess losses for each selected point. The left panel shows the effect of clipping the excess loss while the right panel shows the results without clipping. The non-clipped excess loss shows greater volatility towards the end of training while the clipped excess loss remains much more stable.

This figure shows the comparison of REDUCR with three baseline methods (RHO-LOSS, TRAIN LOSS, and UNIFORM) in terms of worst-class test accuracy and training efficiency on three image datasets: Clothing1M, CINIC10, and CIFAR100. Each subfigure (a, b, c) corresponds to one dataset, plotting the worst-class test accuracy over training steps. The results demonstrate that REDUCR consistently outperforms the baselines across all three datasets, achieving higher worst-class accuracy with fewer training steps.
This figure shows the performance of REDUCR compared to three baseline methods (RHO-Loss, Train Loss, Uniform) across three image datasets (Clothing1M, CINIC10, CIFAR100). For each dataset, two subplots are shown: one for worst-class test accuracy and another for training loss. The results demonstrate that REDUCR consistently outperforms the baselines in terms of worst-class test accuracy and achieves this with improved data efficiency (fewer training steps).

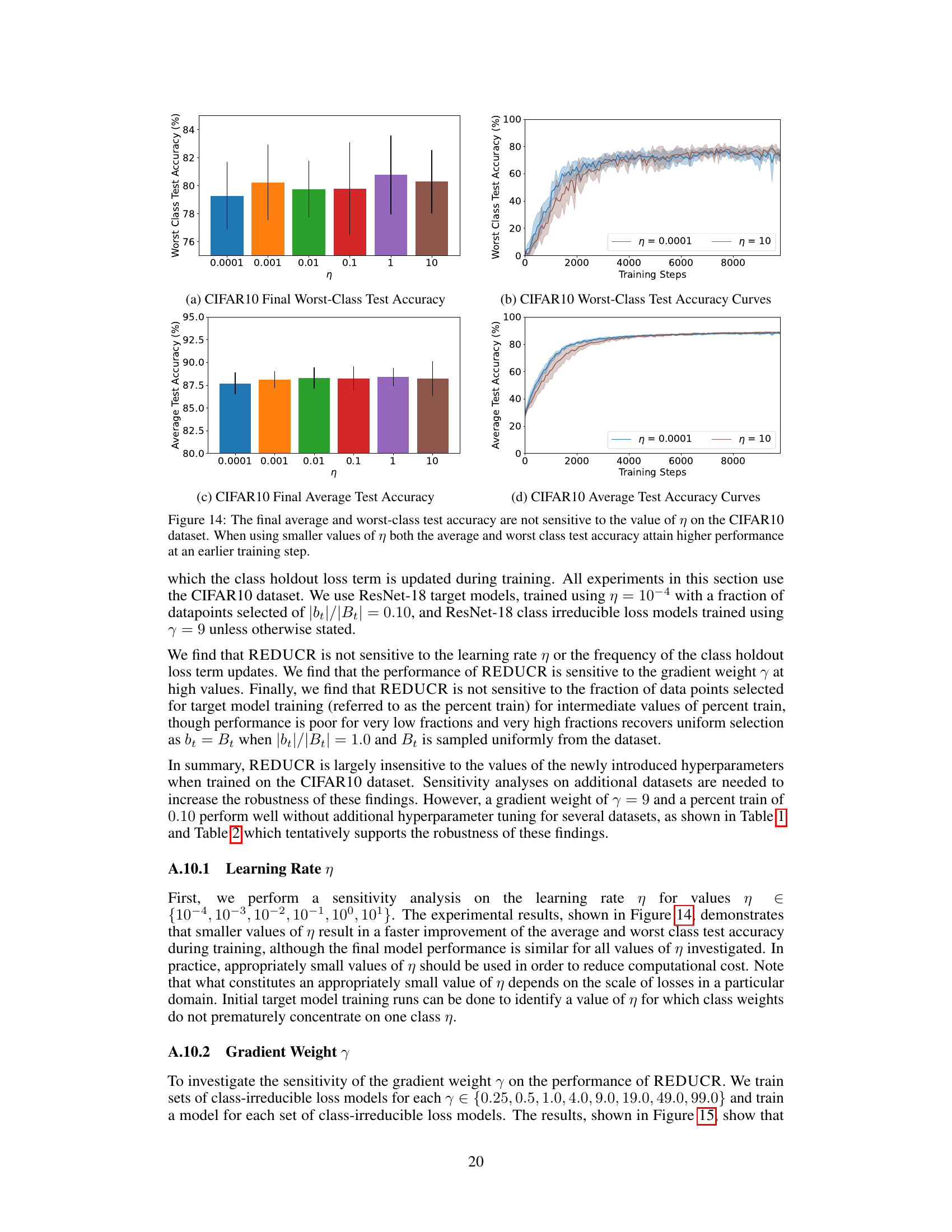
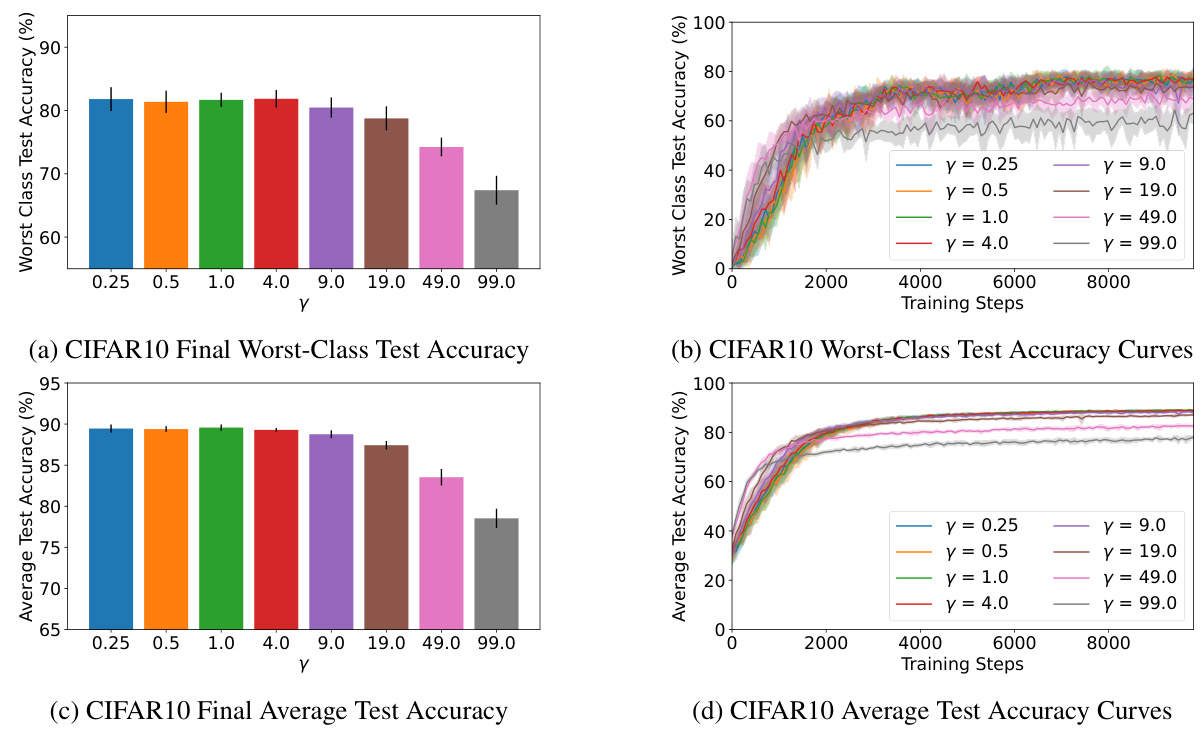
This figure shows the test accuracy of the class-irreducible loss models on CIFAR10. The x-axis represents the gradient weight (γ) used during training, and the y-axis represents the test accuracy. Two sets of bars are shown for each gradient weight: one for the expert class (the class the model is trained to be an expert on) and one for the non-expert classes (all other classes). The figure demonstrates the trade-off between expert class accuracy and non-expert class accuracy as the gradient weight changes. A higher gradient weight leads to better expert class accuracy, but lower non-expert class accuracy.

The figure shows the performance of REDUCR compared to three baseline methods (RHO-Loss, Train Loss, and Uniform) on three different datasets (Clothing1M, CINIC10, and CIFAR100). For each dataset, it plots the worst-class test accuracy over training steps. REDUCR consistently outperforms the baselines, demonstrating improved worst-class accuracy and data efficiency.
The figure shows the performance of REDUCR in comparison to three baseline methods (RHO-LOSS, TRAIN LOSS, and UNIFORM) on three image datasets (Clothing1M, CINIC10, and CIFAR100). For each dataset, three subplots display the worst-class test accuracy over training steps. REDUCR consistently outperforms the baselines, particularly in terms of worst-class accuracy and data efficiency, highlighting its robustness to class imbalance and distributional shifts.

This figure compares the performance of REDUCR against three baseline methods (RHO-LOSS, TRAIN LOSS, and UNIFORM) in terms of worst-class test accuracy and data efficiency across three different datasets: Clothing1M, CINIC10, and CIFAR100. Each subfigure shows the training curves for each method, highlighting REDUCR’s superior performance and faster convergence.

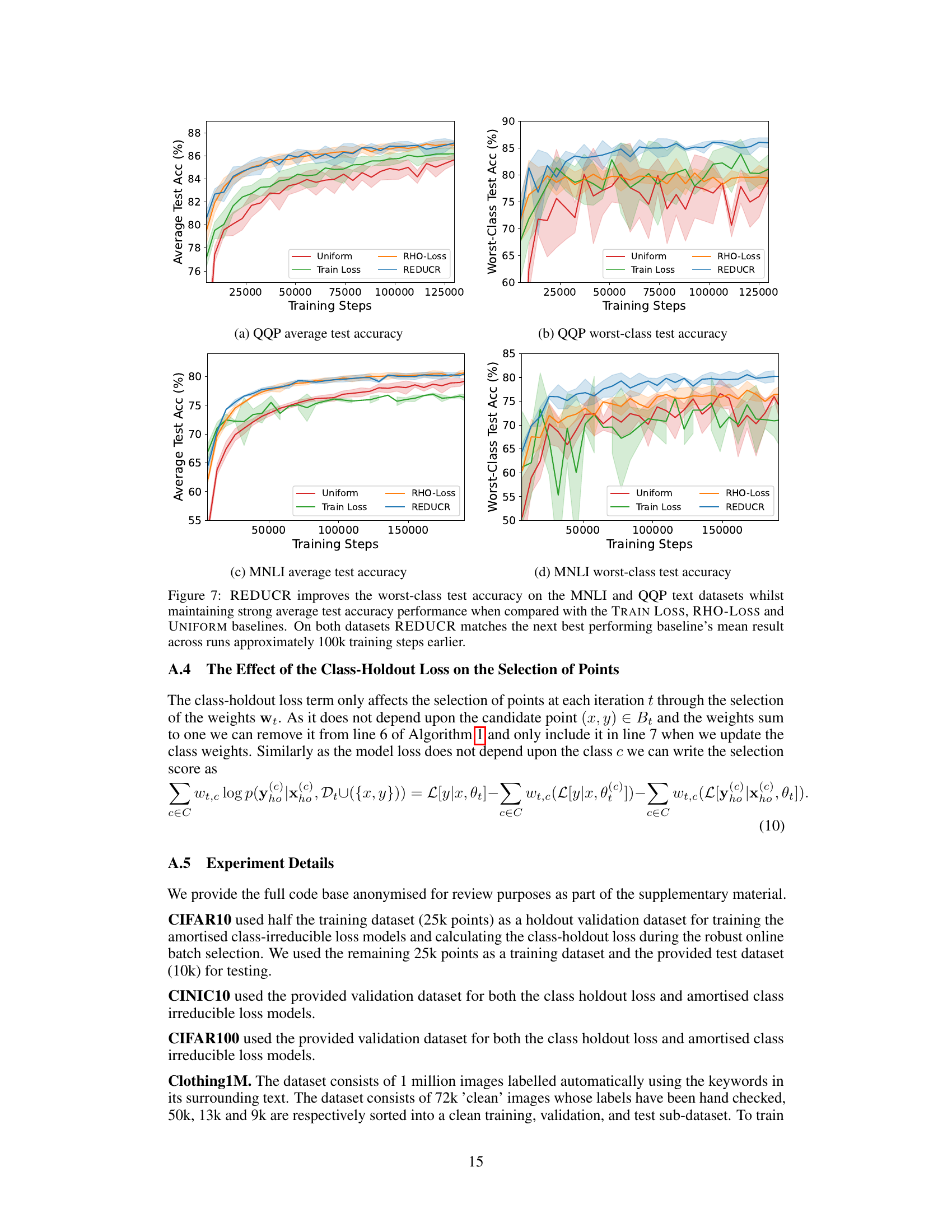
The figure shows the performance of REDUCR against three baseline methods (RHO-LOSS, TRAIN LOSS, and UNIFORM) on three datasets (Clothing1M, CINIC10, and CIFAR100). For each dataset, two graphs are shown: one illustrating worst-class test accuracy and another showing average test accuracy. The x-axis represents the training steps, while the y-axis represents the test accuracy. The graphs illustrate how REDUCR consistently improves both worst-class and average test accuracy across different datasets and training progression, showcasing its superior data efficiency compared to the baseline methods.

This figure shows the performance of REDUCR against three baseline methods (RHO-LOSS, TRAIN LOSS, and UNIFORM) on three different datasets (Clothing1M, CINIC10, and CIFAR100). The x-axis represents the number of training steps, and the y-axis represents the worst-class test accuracy. The plots demonstrate that REDUCR consistently outperforms the baselines in terms of worst-class accuracy and achieves this with greater data efficiency.
This figure compares the performance of REDUCR against three baseline methods (RHO-Loss, Train Loss, and Uniform) across three different datasets (Clothing1M, CINIC10, and CIFAR100). The plots show the worst-class test accuracy over training steps. It demonstrates that REDUCR achieves higher worst-class accuracy and reaches its peak performance more quickly than the baselines.
This figure illustrates the REDUCR algorithm’s workflow. It starts with initializing class weights. At each timestep, a batch of data points is received, and selection scores are computed based on datapoint usefulness and class weights. The algorithm selects the highest-scoring data points, updates the model parameters using them, and then adjusts the class weights to prioritize underperforming classes. This iterative process aims to efficiently downsample data while maintaining good performance even for underrepresented classes.
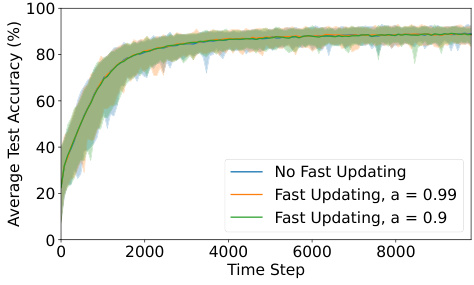
The figure shows three plots that compare REDUCR against three other methods: RHO-Loss, Train Loss, and Uniform. Each plot displays the worst-class test accuracy over training steps for a different dataset: Clothing1M, CINIC10, and CIFAR100. The plots demonstrate that REDUCR consistently achieves higher worst-class test accuracy and often surpasses the other three methods in terms of data efficiency.
More on tables
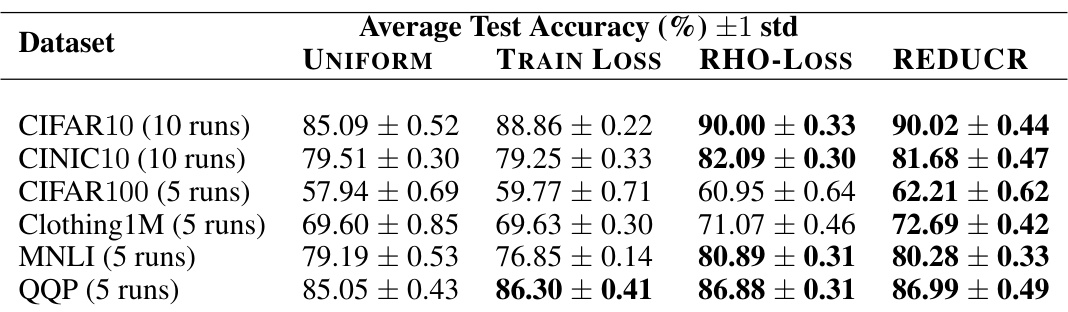
This table shows the average test accuracy for different datasets using various methods including UNIFORM, TRAIN LOSS, RHO-LOSS and REDUCR. The results demonstrate that REDUCR consistently performs well in terms of average accuracy while significantly improving worst-class accuracy, which was its primary optimization target.

This table presents the worst-class test accuracy results for four different datasets (CIFAR10, CINIC10, CIFAR100, Clothing1M) and three baselines (UNIFORM, TRAIN LOSS, RHO-LOSS) in comparison to REDUCR. It highlights REDUCR’s superior performance, particularly on the noisy and imbalanced Clothing1M dataset.

This table presents the worst-class test accuracy achieved by different data downsampling methods on various datasets. REDUCR consistently outperforms other methods, especially on the Clothing1M dataset, which is known for its noise and class imbalance. The results highlight REDUCR’s robustness and efficiency in preserving worst-class generalization performance.

This table presents the average test accuracy for several datasets using different methods: UNIFORM, TRAIN LOSS, RHO-LOSS, and REDUCR. It complements Table 1 by showing that REDUCR’s improvement in worst-class accuracy doesn’t come at the expense of overall average accuracy. In fact, REDUCR often matches or even surpasses the best average accuracy among the baselines.
Full paper#