↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deep Image Prior (DIP) has shown promise in image reconstruction but suffers from overfitting. Existing solutions often rely on large datasets or pre-trained models, limiting their applicability to data-scarce scenarios like medical imaging. This paper addresses these issues by introducing a novel method called Autoencoding Sequential DIP.
The proposed method sequentially updates network weights and incorporates an autoencoding regularization term, progressively denoising the input. This input-adaptive approach reduces overfitting. The results demonstrate superior performance compared to other DIP methods and even leading diffusion models across various image recovery tasks (MRI, CT, denoising etc.), without requiring extensive training data or pre-trained models, making it particularly valuable for resource-constrained environments.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel method for image reconstruction that outperforms existing techniques while requiring less data. This has significant implications for various fields, including medical imaging where large, high-quality datasets are often unavailable. The introduction of sequential weight updates and an autoencoding regularization technique offer new avenues for improving deep image prior-based methods and inspires future research in data-efficient image recovery.
Visual Insights#

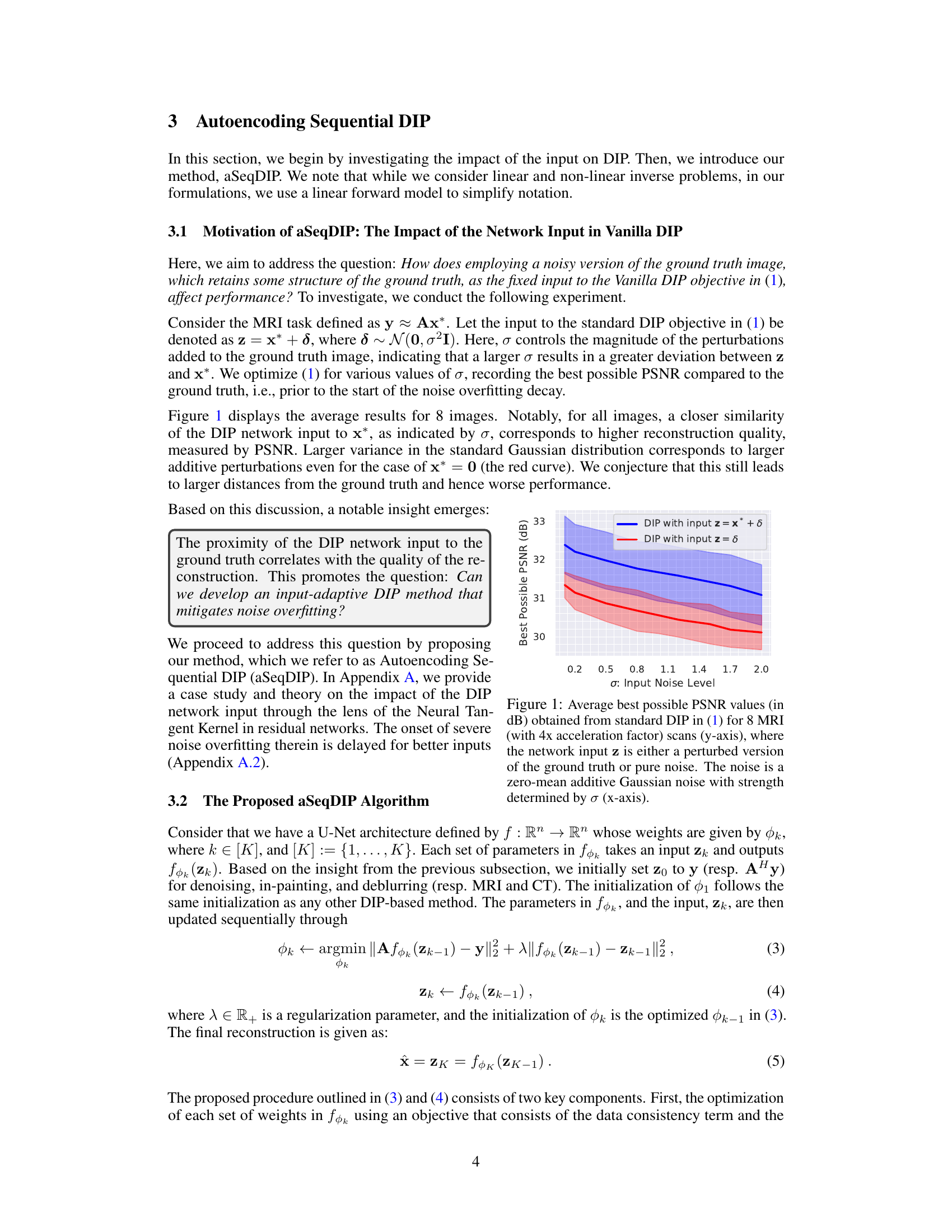
This figure shows the results of an experiment investigating the impact of the network input on the performance of Vanilla DIP. Two scenarios are compared: one where the network input is a noisy version of the ground truth image (blue line), and another where the input is pure noise (red line). The y-axis represents the best possible PSNR achieved before overfitting occurs, and the x-axis represents the standard deviation (σ) of the added Gaussian noise. The results show that a closer similarity between the DIP network input and the ground truth leads to higher reconstruction quality (higher PSNR). This motivates the development of aSeqDIP which aims to mitigate noise overfitting by adaptively changing the network input.
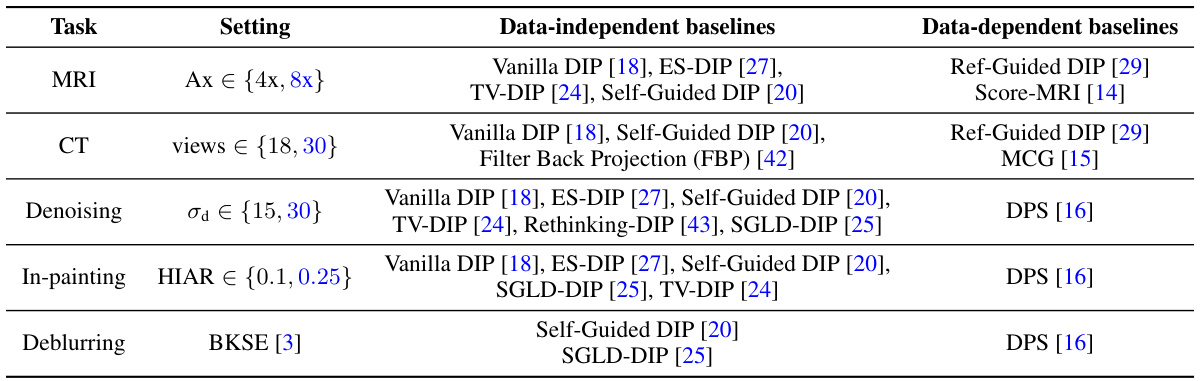
This table summarizes the experimental settings and baselines used in the paper for evaluating the proposed method. It lists five image reconstruction tasks (MRI, CT, denoising, in-painting, and deblurring), their respective settings, data-independent and data-dependent baselines, and references to related work.
In-depth insights#
aSeqDIP: Method#
The core of the aSeqDIP method lies in its sequential and adaptive approach to image reconstruction. Unlike traditional DIP, which uses a fixed random input, aSeqDIP progressively refines its input through sequential optimization of network weights. This is achieved via an iterative process where at each step, network parameters are optimized using an objective that balances data consistency (the fit to the noisy measurements) and autoencoding regularization. The autoencoding term acts as a form of noise overfitting prevention, essentially by encouraging the network’s output to resemble its input, thus avoiding the pitfalls of fitting only to the noise in the measurements. This adaptive input strategy makes aSeqDIP robust and efficient. The sequential nature prevents early overfitting, a significant advantage over standard DIP and several other existing methods. The iterative process, using an input-adaptive DIP objective, leads to improved reconstruction quality while maintaining similar computational costs compared to standard DIP. The autoencoding regularization is a key differentiator, enhancing the quality of results and stability.
DIP Input Impact#
The impact of the Deep Image Prior (DIP) network’s input is a critical yet often overlooked aspect. Early experiments reveal a strong correlation between the input’s similarity to the ground truth and the reconstruction quality. While a random input is conventionally used, initializing the network with a noisy version of the ground truth, retaining structural information, consistently yields superior results. This observation underscores the network’s sensitivity to its initial conditions. The authors cleverly leverage this insight, proposing a novel sequential approach in which the network’s input adapts iteratively, progressively denoising the input itself, and hence leading to improved results. This input-adaptive strategy effectively mitigates the issue of overfitting, a common challenge in DIP methods. Essentially, instead of relying on a fixed random input, they introduce a gradual, structured refinement, moving the method closer to the benefits of diffusion models without requiring the training data. This approach cleverly exploits the underlying architecture’s inherent capacity to learn and reconstruct from partial information, significantly improving noise overfitting mitigation.
Noise Overfitting#
The phenomenon of noise overfitting in deep image prior (DIP) methods is a critical challenge. Overfitting occurs when the network learns the noise present in the input data rather than the underlying image structure. This leads to poor generalization and hinders the accuracy of image reconstruction. The paper introduces autoencoding sequential DIP (aSeqDIP) to mitigate noise overfitting. aSeqDIP achieves this by progressively denoising and reconstructing the image through a sequential optimization of network weights, employing an input-adaptive DIP objective and an autoencoding regularization term. This approach is shown to effectively delay the onset of noise overfitting while maintaining a similar number of parameter updates as vanilla DIP. The autoencoding term is particularly important; it forces the network output to remain consistent with the input, preventing overfitting by promoting learning of the true signal features. Ultimately, aSeqDIP offers a data-independent way to improve the robustness of DIP based methods to noise and improve reconstruction quality.
DM Comparison#
A comparative analysis of the proposed method against diffusion models (DMs) reveals significant advantages. While DMs achieve state-of-the-art results, they often require extensive training data and pre-trained models, limiting applicability to data-scarce scenarios. In contrast, the proposed method is data-independent, requiring only noisy measurements and a forward operator, making it particularly well-suited for applications where large datasets are unavailable. The results demonstrate the proposed method’s competitive performance, often surpassing or matching DMs in various image reconstruction tasks, while maintaining a significantly reduced computational burden. This highlights a key strength: the ability to deliver high-quality reconstruction without the computational overhead associated with training complex diffusion models. Further exploration of this trade-off between data dependency and computational cost is important for future development in the field.
Future works#
The authors suggest several promising avenues for future research. Extending aSeqDIP’s applicability to a wider range of inverse problems is a key goal, potentially broadening its impact across diverse fields. Investigating the integration of a dynamic input update mechanism, allowing for adaptive adjustments to the autoencoding regularization parameter and the number of gradient updates per iteration, could significantly enhance the method’s efficiency and robustness. Exploring the theoretical underpinnings of aSeqDIP further using Neural Tangent Kernel analysis to better understand the training dynamics, particularly in relation to network architecture and input choice, warrants attention. Finally, comparative studies against other state-of-the-art methods on more comprehensive benchmarks and datasets are important steps towards validating the generalizability and potential of aSeqDIP for various real-world applications.
More visual insights#
More on figures

This figure illustrates the aSeqDIP algorithm’s sequential process. It shows how the network weights (φk) and inputs (zk) are updated iteratively across K steps. Each step involves N optimization iterations for the current set of network weights. The initial input, z0, is derived from the measurements, and subsequent inputs are the outputs of the previous steps. This sequential refinement gradually denoises and reconstructs the image.

This figure compares aSeqDIP with other methods for image reconstruction, categorized into data-dependent and data-independent approaches. Data-dependent methods use pre-trained models or reference images, while data-independent methods, including aSeqDIP, do not. The figure highlights the differences in network architecture, procedural steps, and the use of data.
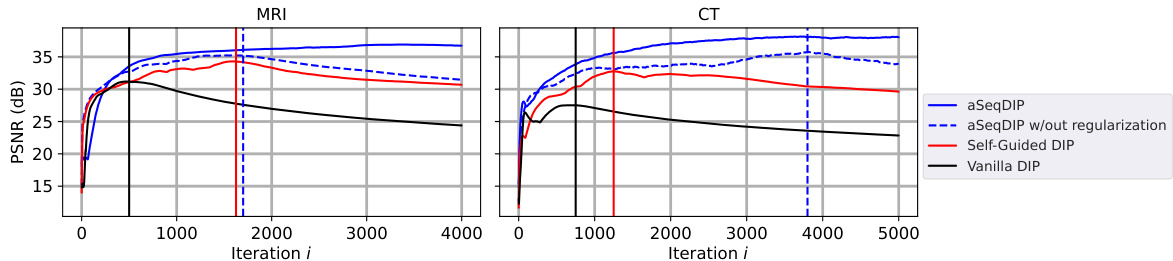
This figure shows the average PSNR over 20 MRI and 20 CT scans for different methods. The left panel shows MRI reconstruction with 4x acceleration, and the right panel shows CT reconstruction with 18 views. The plot shows the PSNR as a function of iteration number (i). The vertical lines indicate where noise overfitting starts for each method. The figure demonstrates that aSeqDIP (with regularization) significantly delays the onset of noise overfitting compared to other methods, including vanilla DIP and Self-Guided DIP. The aSeqDIP method with the autoencoding term disabled shows similar behavior to the Self-Guided DIP, highlighting the impact of the proposed autoencoding term.
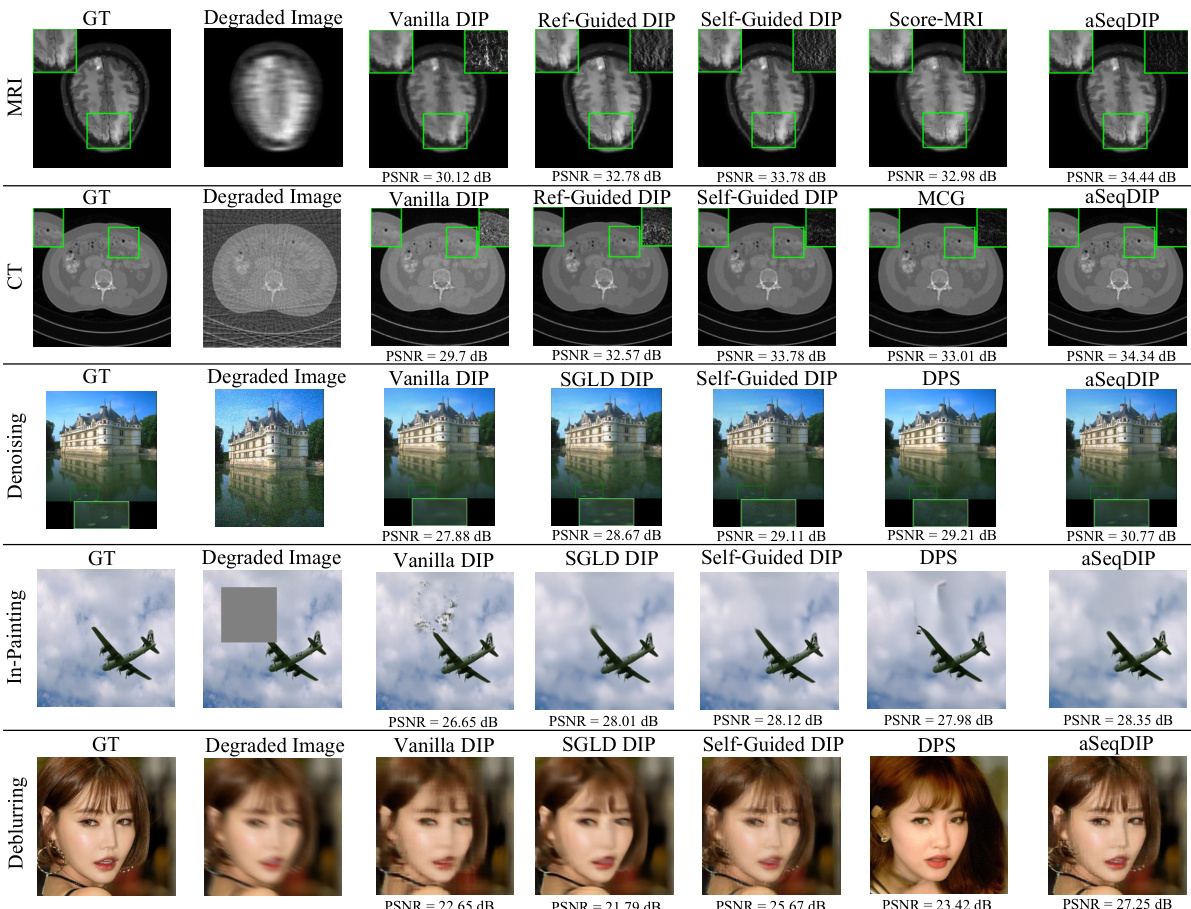
This figure shows visual comparisons of image reconstruction results using different methods (Vanilla DIP, Self-Guided DIP, Score-MRI, Ref-Guided DIP, SGLD-DIP, DPS, and aSeqDIP). The results are shown for five different image reconstruction tasks: MRI, CT, denoising, inpainting, and deblurring. Each row represents one task, showing the ground truth, the degraded image, and the reconstructions produced by each method. The PSNR (Peak Signal-to-Noise Ratio) is included for each reconstruction. The figure highlights that aSeqDIP generally produces sharper and clearer results, particularly in MRI and CT, though there is an exception in deblurring, where DPS produces comparable perceptual quality.

This figure consists of two subfigures. The left subfigure shows a 1D sinusoidal signal (ground truth) and its noisy version. The right subfigure presents the results of a denoising experiment using Deep Image Prior (DIP). Three different network inputs are compared: the ground truth signal, the noisy signal, and random noise. The plot shows the l2 norm error of the network output during training. It demonstrates that using the ground truth as input leads to slower convergence and higher resistance to overfitting, while using the noisy signal as input results in rapid convergence to the noise level. Using random noise as input shows typical DIP behavior.
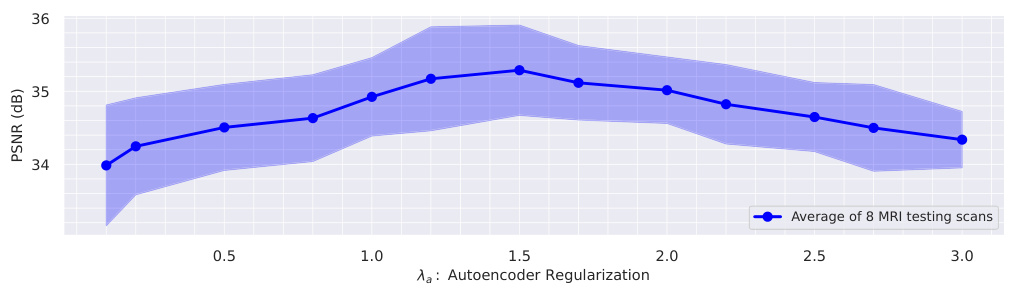
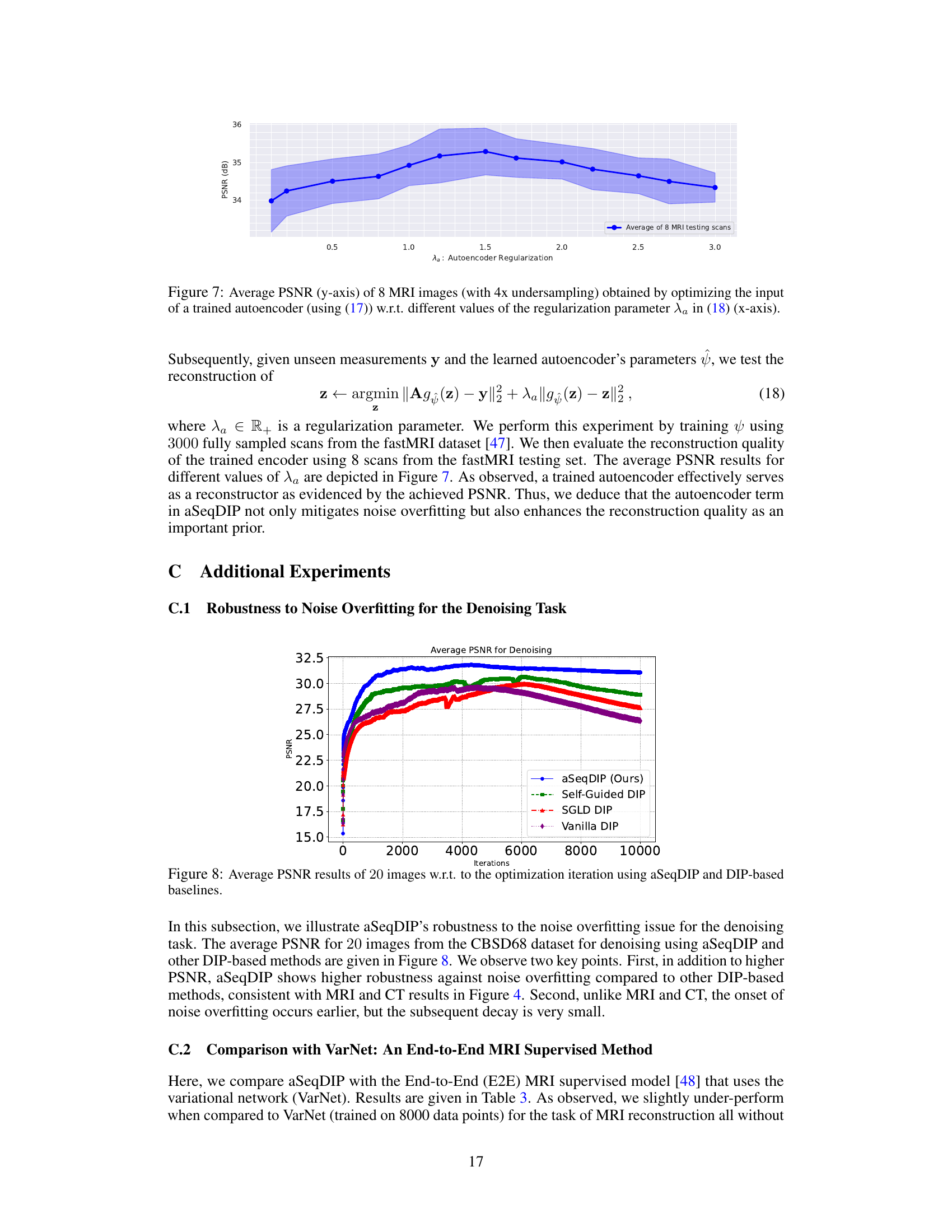
The figure shows the average PSNR achieved on 8 MRI testing scans with 4x undersampling by optimizing the input of a pre-trained autoencoder. The x-axis represents different values of the autoencoder regularization parameter (λλ), and the y-axis shows the resulting average PSNR. The shaded area represents the standard deviation across the 8 scans. The figure demonstrates how the choice of regularization parameter affects the reconstruction quality when using a trained autoencoder as a reconstructor.
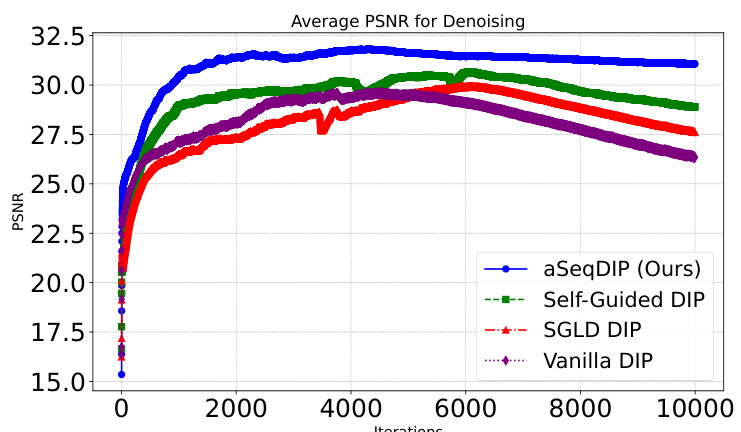
The figure shows the average PSNR over iterations for MRI and CT reconstruction tasks, comparing aSeqDIP with and without the autoencoding regularization term, against Vanilla DIP and Self-Guided DIP. The plot demonstrates the effectiveness of the autoencoding term in delaying noise overfitting, resulting in improved reconstruction quality and a slower decline in PSNR.

The figure shows the average PSNR curves for MRI and CT reconstruction tasks using aSeqDIP with and without the autoencoding regularization term, as well as for Vanilla DIP and Self-Guided DIP. It demonstrates the effectiveness of the autoencoding term in mitigating noise overfitting by delaying the onset of PSNR decay, thus leading to improved reconstruction quality. The vertical lines mark the approximate start of PSNR decay for each method.
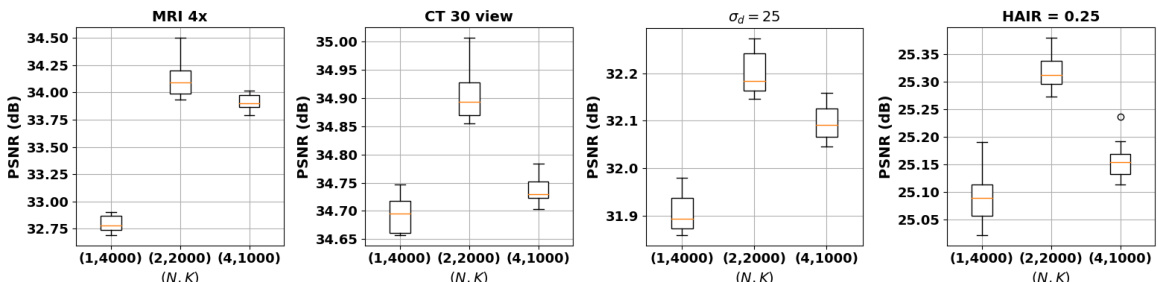
The figure displays the average PSNR (Peak Signal-to-Noise Ratio) results for MRI and CT image reconstruction tasks across different iterations. It compares the performance of aSeqDIP (with and without the autoencoding regularization term) against Vanilla DIP and Self-Guided DIP. The plot shows how the PSNR changes over the iterations, illustrating the impact of the autoencoding term on mitigating noise overfitting. A higher PSNR indicates better image quality. The vertical lines approximate the point where the PSNR starts to decay for each method.
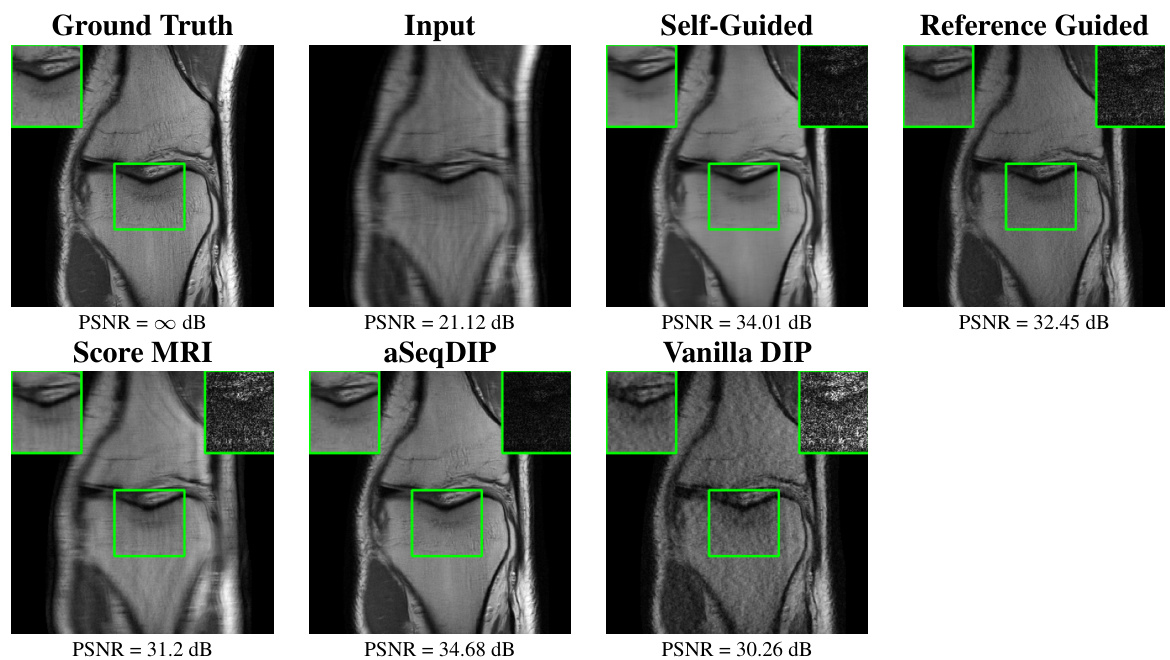
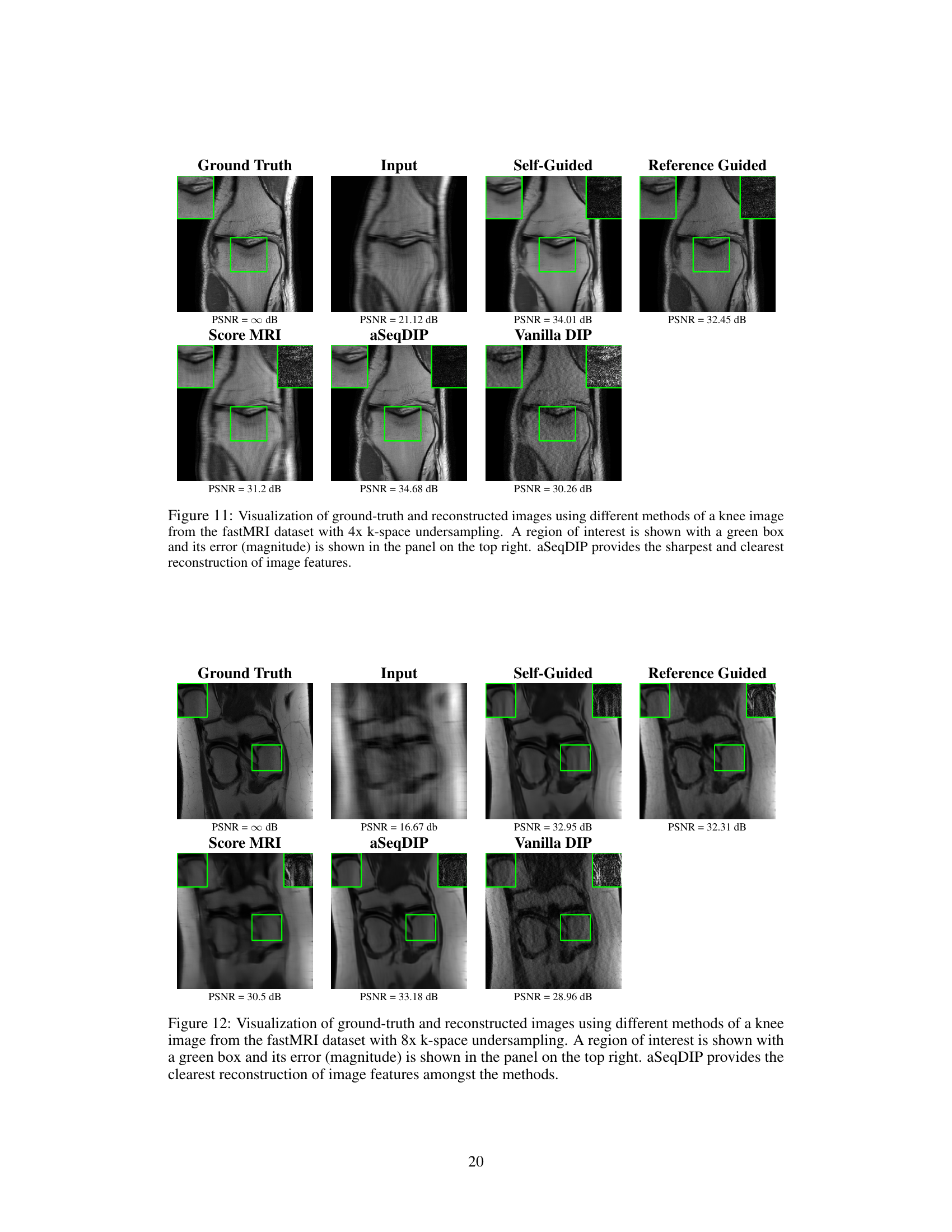
The figure compares the reconstruction results of several methods on a knee MRI image with 4x undersampling. It highlights aSeqDIP’s superior performance in reconstructing sharp and clear image features compared to other methods (Score MRI, Self-Guided DIP, Vanilla DIP, Reference-Guided DIP). A region of interest is zoomed in for detailed comparison.

This figure compares the reconstruction quality of different methods on a knee MRI image with 4x undersampling. It shows the ground truth, the undersampled input, and the reconstructions from Score MRI, aSeqDIP, Vanilla DIP, and Reference-Guided DIP. A zoomed-in region highlights the differences in detail and sharpness between the methods. aSeqDIP shows the best reconstruction with sharpest and clearest features.

This figure compares the image reconstruction results of several methods on a CT scan using 18 views. It shows the ground truth image, the input image with noise and artifacts, and the reconstructions generated by MCG, aSeqDIP, and vanilla DIP. A zoomed-in region highlights the quality differences, showcasing aSeqDIP’s ability to produce sharper and clearer images with fewer artifacts.
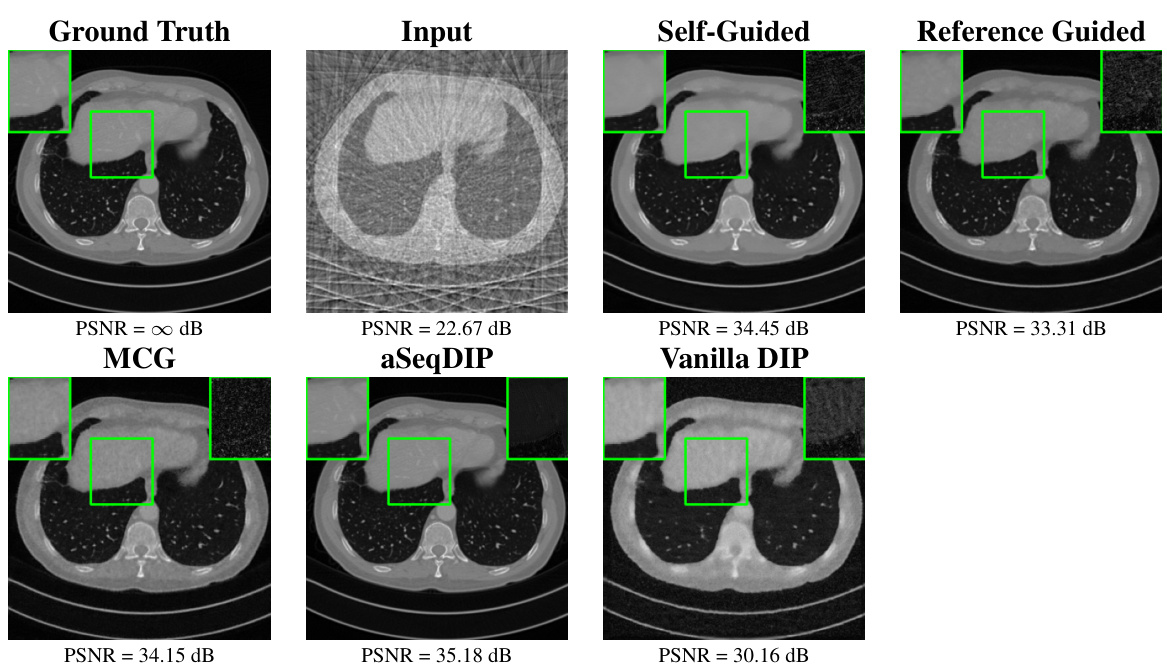
This figure compares the performance of different image reconstruction methods on a CT scan from the AAPM dataset with 18 views. It shows the ground truth, the input (noisy) image, and the reconstructions obtained using MCG, aSeqDIP, Vanilla DIP, and Reference Guided DIP. A region of interest is highlighted, and the corresponding PSNR values are displayed below each image. The figure demonstrates that aSeqDIP achieves the highest PSNR and provides the sharpest and clearest reconstruction, indicating better performance in reconstructing detailed image features.

This figure compares the image reconstruction results of the proposed aSeqDIP method to several baseline methods across five different image reconstruction tasks: MRI, CT, denoising, inpainting, and deblurring. Each row represents a task, with the ground truth and degraded input image shown in the first two columns. Subsequent columns present reconstruction results from several different methods, with the final column showing aSeqDIP’s results. PSNR values are given for each reconstruction to quantitatively assess performance. In MRI and CT, a difference image highlights the discrepancy between the central region of the reconstruction and the ground truth. The figure visually demonstrates that aSeqDIP generally achieves superior image quality.

This figure shows visual comparisons of image reconstruction results from different methods (aSeqDIP and baselines) for five different image processing tasks: MRI, CT, denoising, inpainting, and deblurring. For each task, a ground truth image, a degraded image, and the reconstructions from several methods are displayed. The PSNR values are provided for quantitative comparison. The figure highlights that aSeqDIP generally produces sharper and clearer images, especially in MRI and CT where a zoomed-in section shows that aSeqDIP has lower error compared to other methods.

This figure compares the results of different image deblurring methods applied to a sample image from the FFHQ dataset. It shows the ground truth image alongside the input (blurred) image and the results obtained using DPS, aSeqDIP, Self-Guided DIP, and SGLD. The PSNR values for each method are included below its corresponding image, demonstrating the relative performance in terms of reconstruction quality.
More on tables
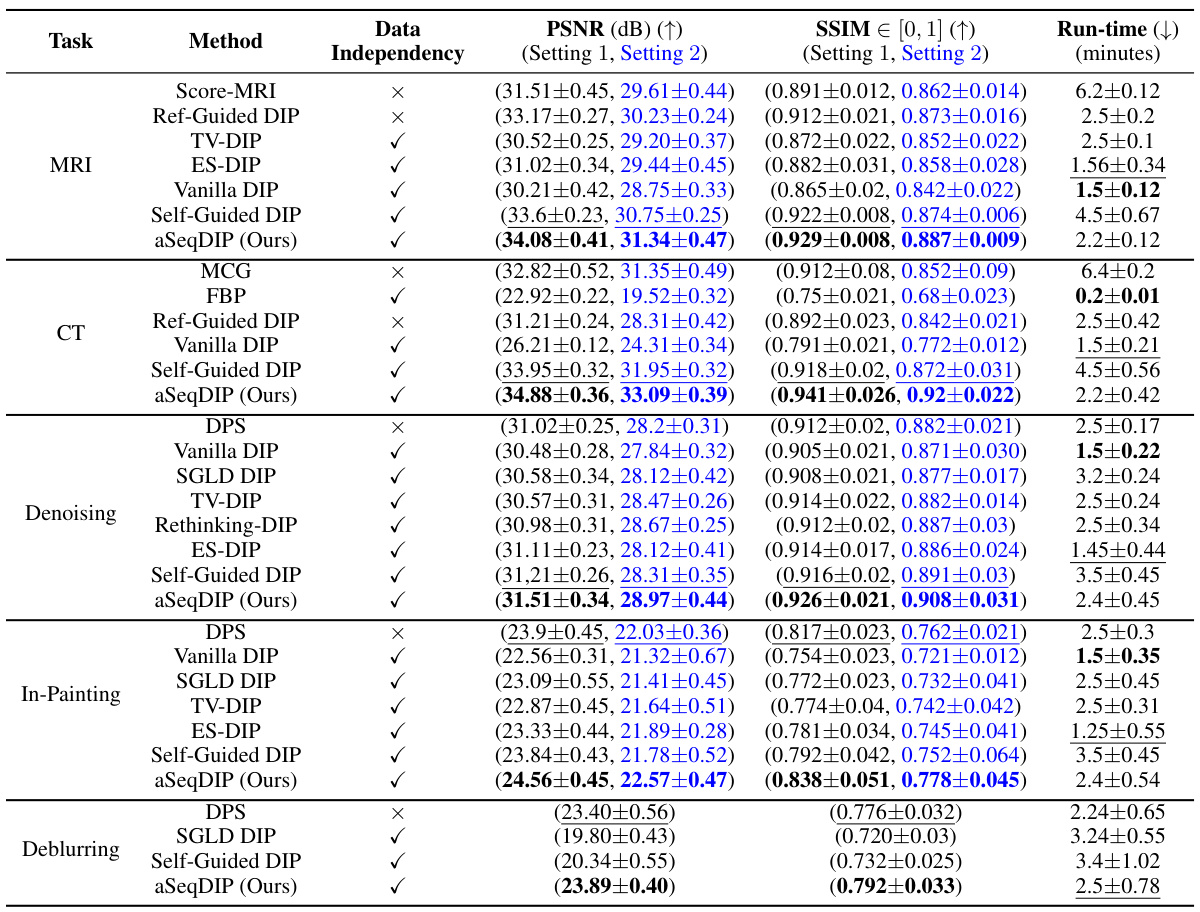
This table compares the performance of the proposed aSeqDIP method against several baselines across five image reconstruction tasks: MRI, CT, denoising, inpainting, and deblurring. It shows the average PSNR and SSIM scores, along with runtimes, for each method and setting. The table also indicates whether each baseline uses pre-trained models or prior data. Setting 1 and Setting 2 refer to specific configurations for each task described in Table 1.

This table compares the performance of aSeqDIP against several baselines across various image reconstruction tasks. It shows the PSNR and SSIM scores, as well as the computation time. It also indicates whether the methods used pre-trained models or prior data, highlighting aSeqDIP’s data-independent nature.
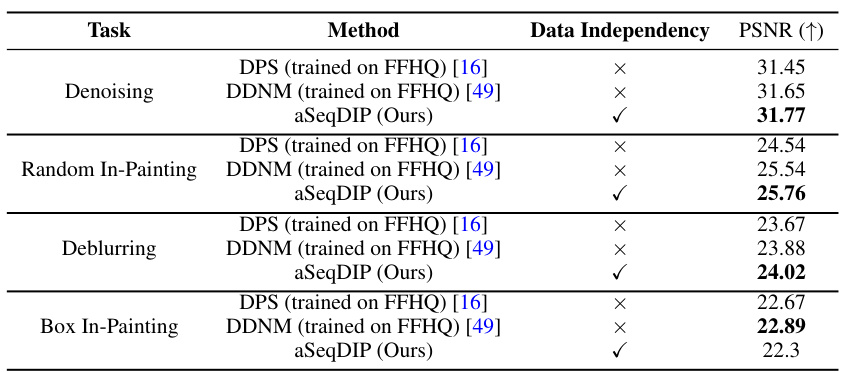
This table compares the performance of the proposed aSeqDIP method against several baselines across five different image reconstruction tasks. The comparison includes metrics such as PSNR and SSIM, along with computational runtime. It also notes whether each method relies on pre-trained models or other external data.
Full paper#