TL;DR#
Many real-world applications of reinforcement learning (RL) face the challenge of limited interaction with the target environment due to safety concerns or cost. This often leads to performance degradation when deploying policies trained in a simpler ‘source’ environment. Existing methods typically focus solely on modifying rewards in the source domain to match the target domain’s optimal trajectories. However, this does not guarantee optimal performance in the target domain.
The paper introduces DARAIL, a novel approach that uses reward modification to align the source and target domains, followed by imitation learning to transfer the learned policy to the target. DARAIL uses a reward augmented estimator to improve stability and provides an error bound analysis justifying this approach. Extensive experiments demonstrate that DARAIL significantly outperforms methods relying only on reward modification in various challenging scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on domain adaptation and reinforcement learning, particularly in scenarios with limited access to target domain data. It addresses a critical challenge in applying RL to real-world problems where extensive exploration is costly or impossible, offering a novel solution that combines reward modification with imitation learning to bridge the gap between source and target domains. This approach not only improves performance but also contributes to the theoretical understanding of off-dynamics RL through rigorous error analysis, creating new avenues for future research.
Visual Insights#
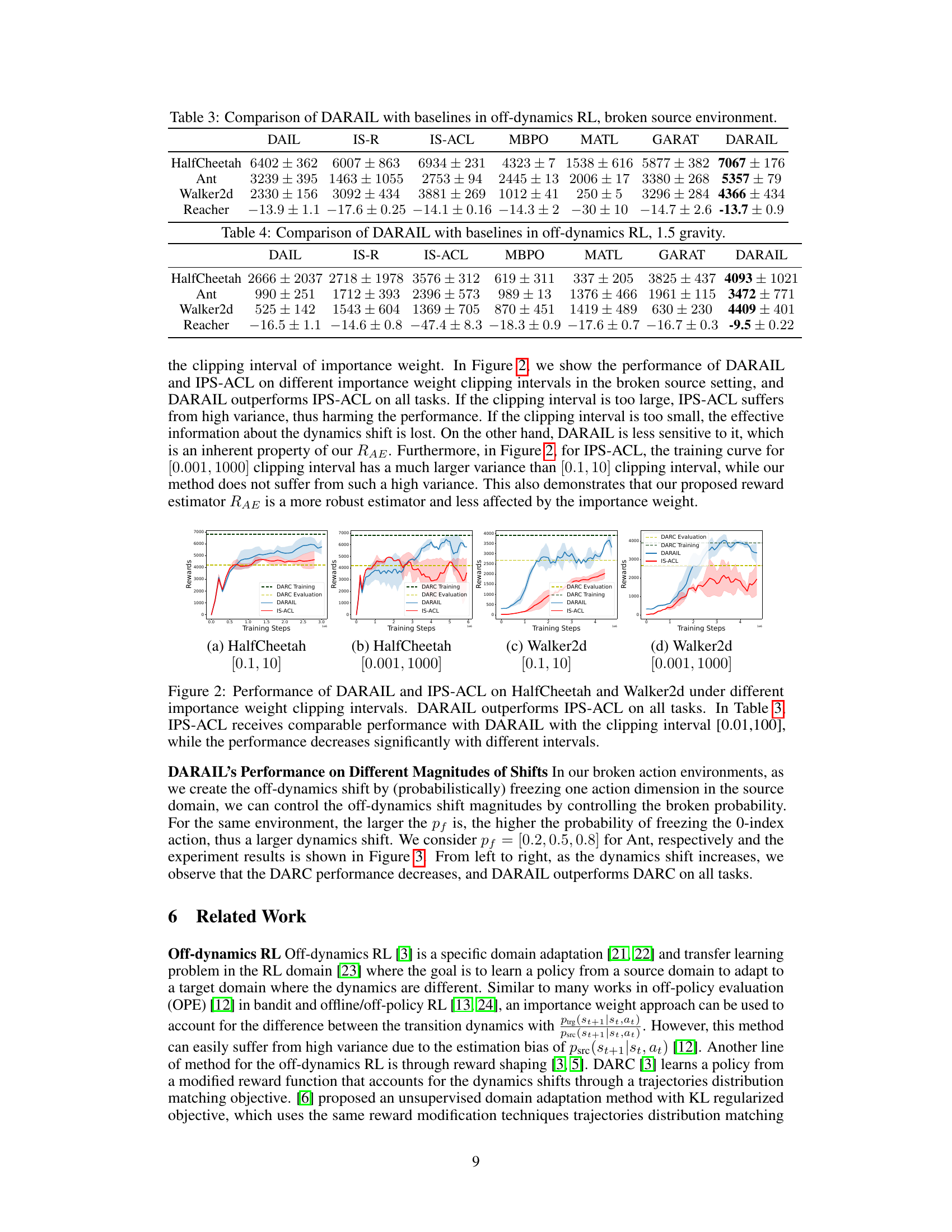
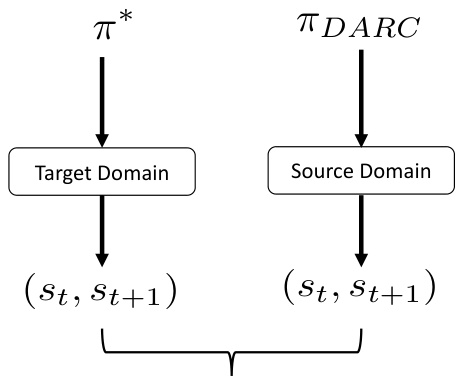
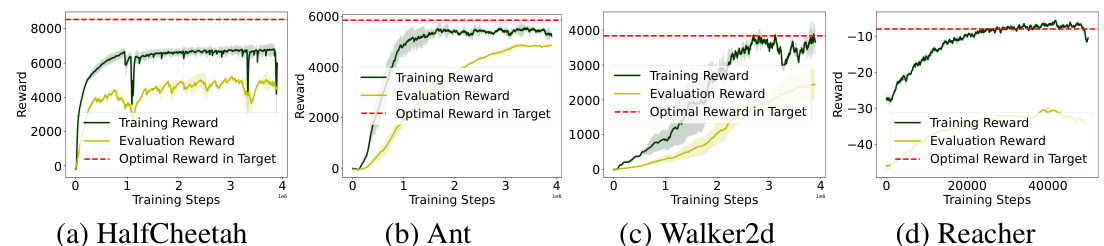
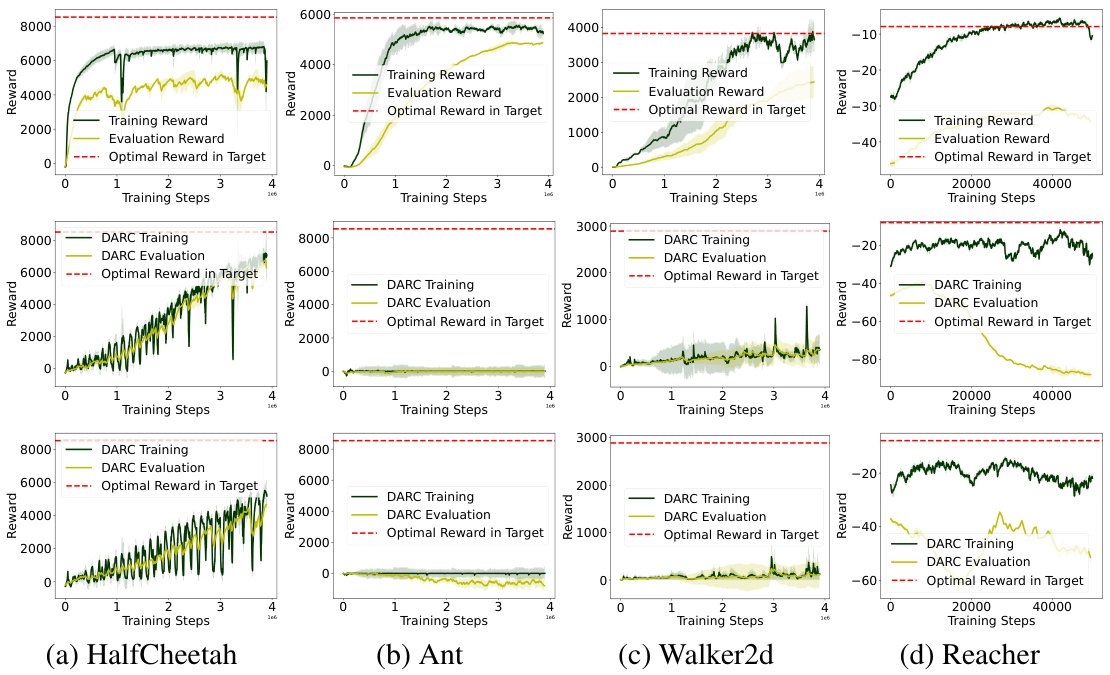
🔼 This figure shows the training reward and evaluation reward of the DARC algorithm in the source and target domains respectively. It also illustrates the performance degradation of DARC when deployed in the target domain due to the dynamics shift. The figure also presents the learning framework of the proposed DARAIL algorithm, showing the training steps of DARC, discriminator, and generator. DARAIL uses reward modification and imitation learning to transfer a policy from the source to the target domain, addressing the suboptimality issues of the reward-only DARC approach.
read the caption
Figure 1: (a) Training reward in the source domain, i.e. ΕDARC, psrc [∑tr(st, at)], evaluation reward in the target domain, i.e. ΕπDARC, Purg [∑tr(st, at)] and optimal reward in target domain, for DARC in Ant. Evaluating the trained DARC policy in the target domain will cause performance degradation compared with its training reward, which should be close to the optimal reward in the target given DARC's objective function. Results of HalfCheetah, Walker2d, and Reacher are in Figure 9 in Appendix. (b) Learning framework of DARAIL. DARC Training: we first train the DARC in the source domain with a modified reward that is derived from the minimization of the reverse divergence between optimal policies on target and learned policies on the source. Details of DARC and the modified reward are in Section 3.1 and Appendix A.1. Discriminator training: the discriminator is trained to classify whether the data is from the expert demonstration (DARC trajectories) and provide a local reward function for policy learning. Generator training: the policy is updated with augmented reward estimation, which integrates the reward from the source domain and information from the discriminator. We first train DARC, collect DARC trajectories from the source domain, and then train the discriminator and the generator alternatively.
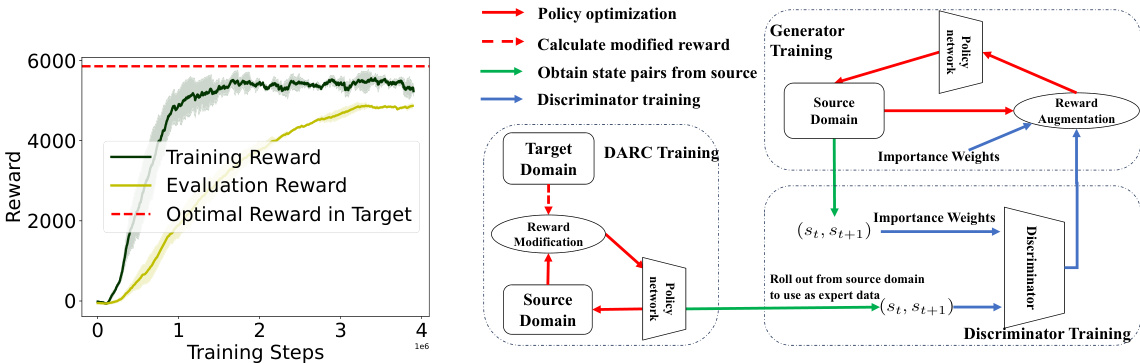
🔼 This table compares the performance of DARAIL and DARC in four MuJoCo environments with a broken source environment. It shows the DARC evaluation reward (performance in the target domain), the DARC training reward (performance in the source domain), the optimal reward achievable in the target domain, and the DARAIL reward (the proposed method’s performance in the target domain). The results demonstrate that DARAIL significantly outperforms DARC in the target domain, mitigating the performance degradation observed when DARC is directly deployed in the target domain.
read the caption
Table 1: Comparison of DARAIL with DARC, broken source environment.
In-depth insights#
Off-Dynamics RL#
Off-Dynamics Reinforcement Learning (RL) tackles the challenge of training RL agents in a source environment and deploying them in a target environment with differing dynamics. This is crucial because direct interaction with the target environment may be impossible, too expensive, or unsafe. The core problem lies in the dynamics shift, where the transition probabilities between states differ between source and target. Existing reward-based approaches attempt to mitigate this by modifying rewards in the source domain to encourage behaviors similar to the optimal policy in the target, but they often fail to guarantee optimal performance in the target due to the inherent limitations of reward shaping. This is where imitation learning comes in, offering a potential solution by enabling the agent to mimic the behavior of an expert policy trained (or imagined) in the target domain, thus bridging the gap between source and target environments. Combining domain adaptation and imitation learning offers a promising avenue to address the inherent limitations of relying solely on reward shaping for adapting to unseen target dynamics.
DARAIL Algorithm#
The DARAIL algorithm ingeniously combines domain adaptation and reward-augmented imitation learning to tackle the challenge of off-dynamics reinforcement learning. It addresses the limitations of prior reward-modification methods by first utilizing a modified reward function to train a policy in the source domain that mimics the behavior of an optimal policy in the target domain. However, unlike previous methods, DARAIL doesn’t directly deploy this policy to the target. Instead, it leverages imitation learning to transfer the policy’s behavior, effectively generating similar trajectories in the target domain. This two-stage approach ensures better generalization to the target environment and improved performance. A key innovation is the reward-augmented estimator, which blends the source domain reward and information from a discriminator to improve policy optimization, leading to superior performance. The theoretical error bound provides a solid foundation, justifying the method’s efficacy.
Reward Augmentation#
Reward augmentation, in the context of reinforcement learning, particularly within the off-dynamics setting, is a crucial technique to bridge the gap between source and target domains. It involves modifying the reward function in the source domain to encourage behaviors that would be optimal in the target domain, thereby mitigating the negative effects of dynamics mismatch. This modification isn’t a simple adjustment; rather, it requires careful consideration of the underlying dynamics and distribution of trajectories in both domains. Effective reward augmentation methods ensure the source agent’s experience closely resembles the target domain’s optimal trajectory distribution. However, relying solely on reward augmentation can be insufficient. Pure reward modification only indirectly influences the policy’s behavior in the target domain, and the learned policy’s performance may still degrade upon deployment, as seen in the limitations of the DARC method. Therefore, many advanced approaches integrate reward augmentation with other techniques like imitation learning, creating a hybrid model that combines the benefits of both strategies for more robust off-dynamics reinforcement learning.
Theoretical Analysis#
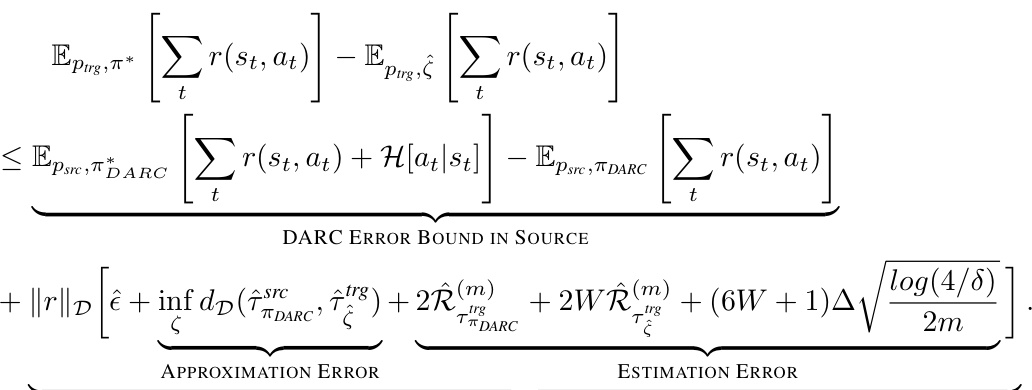
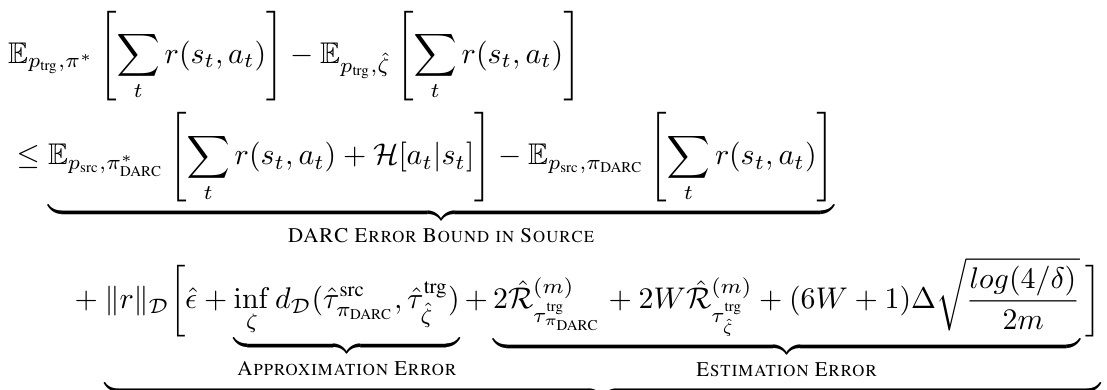
A theoretical analysis section in a research paper provides a formal justification for the proposed method. It often involves deriving error bounds or convergence rates under specific assumptions. This section is crucial for establishing the method’s reliability and predictive power. The analysis might involve proving that the algorithm converges to the optimal solution, bounding the approximation error, or quantifying the impact of various factors. The assumptions made during theoretical analysis should be clearly stated, including any simplifications or limitations. A rigorous theoretical analysis enhances the paper’s credibility, providing a solid mathematical foundation for the empirical results. Well-defined assumptions and a clear and concise presentation of the mathematical derivation are essential for a successful theoretical analysis.
Future Work#
The paper’s “Future Work” section could explore several promising avenues. Extending DARAIL to handle more complex dynamics shifts beyond those tested (e.g., variations in reward function, state space changes) would significantly expand its applicability. Investigating the sensitivity of DARAIL to different amounts of target domain data is crucial; determining the minimum data required for effective transfer learning would improve its practical value. A theoretical analysis of DARAIL’s robustness to model misspecification and noise would enhance the theoretical foundations, addressing potential limitations in real-world applications. Evaluating the effectiveness of DARAIL in more safety-critical reinforcement learning tasks is needed, to assess its potential for applications with high stakes such as autonomous driving. Finally, comparing DARAIL with other advanced off-dynamics RL methods that employ different techniques is important to show its relative performance and contributions.
More visual insights#
More on figures

🔼 This figure shows the training reward of DARC in the source domain and the evaluation reward in the target domain for the Ant environment. It also illustrates the learning framework of the proposed method, DARAIL, which consists of DARC training, discriminator training, and generator training steps. The figure highlights the performance degradation of DARC when deployed in the target domain and how DARAIL utilizes imitation learning to transfer the policy learned from DARC to the target domain.
read the caption
Figure 1: (a) Training reward in the source domain, i.e. EDARC, psrc [∑tr(st, at)], evaluation reward in the target domain, i.e. ΕπρARC, Purg [∑tr(st, at)] and optimal reward in target domain, for DARC in Ant. Evaluating the trained DARC policy in the target domain will cause performance degradation compared with its training reward, which should be close to the optimal reward in the target given DARC's objective function. Results of HalfCheetah, Walker2d, and Reacher are in Figure 9 in Appendix. (b) Learning framework of DARAIL. DARC Training: we first train the DARC in the source domain with a modified reward that is derived from the minimization of the reverse divergence between optimal policies on target and learned policies on the source. Details of DARC and the modified reward are in Section 3.1 and Appendix A.1. Discriminator training: the discriminator is trained to classify whether the data is from the expert demonstration (DARC trajectories) and provide a local reward function for policy learning. Generator training: the policy is updated with augmented reward estimation, which integrates the reward from the source domain and information from the discriminator. We first train DARC, collect DARC trajectories from the source domain, and then train the discriminator and the generator alternatively.
🔼 This figure shows the performance degradation of DARC when deployed to the target domain and the framework of DARAIL, which addresses this issue by using imitation learning to transfer the policy learned from reward modification to the target domain. Panel (a) illustrates DARC’s sub-optimal performance in the target domain despite resembling target optimal trajectories in its source domain training. Panel (b) details DARAIL’s training process: first training DARC in the source domain with modified rewards, then using DARC trajectories as expert data for discriminator and generator training in an imitation learning framework that refines the policy in the target domain.
read the caption
Figure 1: (a) Training reward in the source domain, i.e. EDARC, psrc [∑tr(st, at)], evaluation reward in the target domain, i.e. ΕπρARC, Purg [∑tr(st, at)] and optimal reward in target domain, for DARC in Ant. Evaluating the trained DARC policy in the target domain will cause performance degradation compared with its training reward, which should be close to the optimal reward in the target given DARC's objective function. Results of HalfCheetah, Walker2d, and Reacher are in Figure 9 in Appendix. (b) Learning framework of DARAIL. DARC Training: we first train the DARC in the source domain with a modified reward that is derived from the minimization of the reverse divergence between optimal policies on target and learned policies on the source. Details of DARC and the modified reward are in Section 3.1 and Appendix A.1. Discriminator training: the discriminator is trained to classify whether the data is from the expert demonstration (DARC trajectories) and provide a local reward function for policy learning. Generator training: the policy is updated with augmented reward estimation, which integrates the reward from the source domain and information from the discriminator. We first train DARC, collect DARC trajectories from the source domain, and then train the discriminator and the generator alternatively.
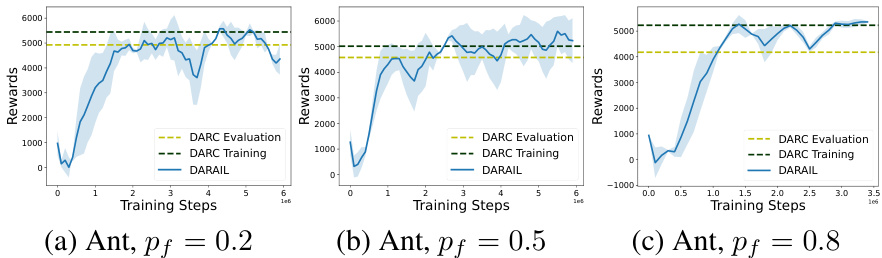
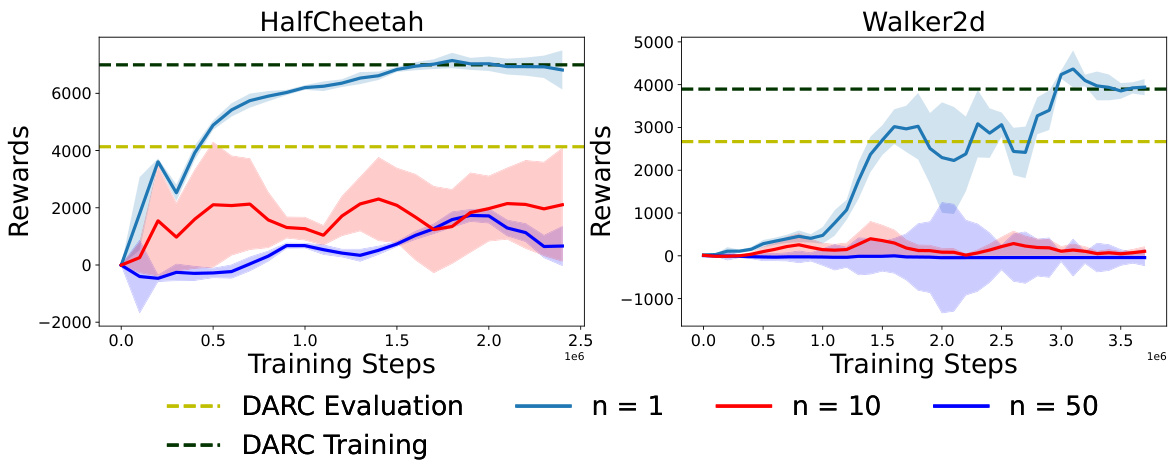
🔼 This figure compares the performance of DARC and DARAIL algorithms on the Ant environment under different levels of dynamics shift, controlled by the probability (pf) of freezing action 0 in the source domain. As pf increases, the dynamics shift between source and target domains grows larger. The figure shows that the reward obtained by DARC in the target domain significantly degrades as the dynamics shift increases, whereas DARAIL consistently outperforms DARC, maintaining a higher reward in the target domain across various shift magnitudes.
read the caption
Figure 3: Performance of DARC and DARAIL under different off-dynamics shifts on Ant. Action 0 is frozen (set to be 0) with probability pf in the source domain. From left to right, the off-dynamics shift becomes larger. As the shift becomes larger, the gap between DARC Training and DARC Evaluation is larger. Our method outperforms DARC on different dynamics shift.
🔼 This figure illustrates the performance degradation of DARC in the target domain and introduces the DARAIL framework. (a) shows the training and evaluation reward curves for DARC on the Ant environment, highlighting the performance gap between the source and target domains. (b) presents a detailed breakdown of the DARAIL algorithm, including the DARC training, discriminator training, and generator training phases, emphasizing the use of imitation learning to transfer the policy from the source to the target domain.
read the caption
Figure 1: (a) Training reward in the source domain, i.e. ΕπDARC, psrc [∑tr(st, at)], evaluation reward in the target domain, i.e. ΕπDARC, Purg [∑tr(st, at)] and optimal reward in target domain, for DARC in Ant. Evaluating the trained DARC policy in the target domain will cause performance degradation compared with its training reward, which should be close to the optimal reward in the target given DARC's objective function. Results of HalfCheetah, Walker2d, and Reacher are in Figure 9 in Appendix. (b) Learning framework of DARAIL. DARC Training: we first train the DARC in the source domain with a modified reward that is derived from the minimization of the reverse divergence between optimal policies on target and learned policies on the source. Details of DARC and the modified reward are in Section 3.1 and Appendix A.1. Discriminator training: the discriminator is trained to classify whether the data is from the expert demonstration (DARC trajectories) and provide a local reward function for policy learning. Generator training: the policy is updated with augmented reward estimation, which integrates the reward from the source domain and information from the discriminator. We first train DARC, collect DARC trajectories from the source domain, and then train the discriminator and the generator alternatively.
🔼 This figure shows the training reward of DARC in the source domain and its evaluation reward in the target domain for the Ant environment. It demonstrates performance degradation when deploying the DARC policy in the target domain, highlighting the limitations of DARC. The second part illustrates the DARAIL framework, which addresses these limitations by using imitation learning to transfer the policy learned from reward modification to the target domain. DARAIL comprises DARC training with a modified reward, discriminator training to classify data and provide a local reward function, and generator training using an augmented reward estimator.
read the caption
Figure 1: (a) Training reward in the source domain, i.e. EDARC, psrc [∑tr(st, at)], evaluation reward in the target domain, i.e. ΕπρARC, Purg [∑tr(st, at)] and optimal reward in target domain, for DARC in Ant. Evaluating the trained DARC policy in the target domain will cause performance degradation compared with its training reward, which should be close to the optimal reward in the target given DARC's objective function. Results of HalfCheetah, Walker2d, and Reacher are in Figure 9 in Appendix. (b) Learning framework of DARAIL. DARC Training: we first train the DARC in the source domain with a modified reward that is derived from the minimization of the reverse divergence between optimal policies on target and learned policies on the source. Details of DARC and the modified reward are in Section 3.1 and Appendix A.1. Discriminator training: the discriminator is trained to classify whether the data is from the expert demonstration (DARC trajectories) and provide a local reward function for policy learning. Generator training: the policy is updated with augmented reward estimation, which integrates the reward from the source domain and information from the discriminator. We first train DARC, collect DARC trajectories from the source domain, and then train the discriminator and the generator alternatively.
🔼 This figure shows the comparison of training and evaluation rewards for DARC in the Ant environment and illustrates the framework of the proposed DARAIL algorithm. Panel (a) highlights the performance degradation of DARC when deployed in the target domain, showing a significant gap between the training reward (close to optimal) and the evaluation reward. Panel (b) details the DARAIL framework, outlining the DARC training phase, discriminator training to classify source and target data, and generator training to optimize the policy using augmented reward estimation from source domain reward and discriminator feedback.
read the caption
Figure 1: (a) Training reward in the source domain, i.e. ΕDARC, psrc [∑tr(st, at)], evaluation reward in the target domain, i.e. ΕπDARC, Purg [∑tr(st, at)] and optimal reward in target domain, for DARC in Ant. Evaluating the trained DARC policy in the target domain will cause performance degradation compared with its training reward, which should be close to the optimal reward in the target given DARC's objective function. Results of HalfCheetah, Walker2d, and Reacher are in Figure 9 in Appendix. (b) Learning framework of DARAIL. DARC Training: we first train the DARC in the source domain with a modified reward that is derived from the minimization of the reverse divergence between optimal policies on target and learned policies on the source. Details of DARC and the modified reward are in Section 3.1 and Appendix A.1. Discriminator training: the discriminator is trained to classify whether the data is from the expert demonstration (DARC trajectories) and provide a local reward function for policy learning. Generator training: the policy is updated with augmented reward estimation, which integrates the reward from the source domain and information from the discriminator. We first train DARC, collect DARC trajectories from the source domain, and then train the discriminator and the generator alternatively.

🔼 This figure shows the training reward and evaluation reward of DARC (Domain Adaptation with Rewards from Classifiers) in the Ant environment. It illustrates the performance degradation of DARC in the target domain when compared to its training reward. The figure also presents the learning framework of DARAIL (Domain Adaptation and Reward Augmented Imitation Learning), highlighting the DARC training, discriminator training, and generator training phases. DARAIL uses imitation learning to address the suboptimality issues of the pure modified reward methods.
read the caption
Figure 1: (a) Training reward in the source domain, i.e. ΕDARC, psrc [∑tr(st, at)], evaluation reward in the target domain, i.e. ΕπDARC, Purg [∑tr(st, at)] and optimal reward in target domain, for DARC in Ant. Evaluating the trained DARC policy in the target domain will cause performance degradation compared with its training reward, which should be close to the optimal reward in the target given DARC's objective function. Results of HalfCheetah, Walker2d, and Reacher are in Figure 9 in Appendix. (b) Learning framework of DARAIL. DARC Training: we first train the DARC in the source domain with a modified reward that is derived from the minimization of the reverse divergence between optimal policies on target and learned policies on the source. Details of DARC and the modified reward are in Section 3.1 and Appendix A.1. Discriminator training: the discriminator is trained to classify whether the data is from the expert demonstration (DARC trajectories) and provide a local reward function for policy learning. Generator training: the policy is updated with augmented reward estimation, which integrates the reward from the source domain and information from the discriminator. We first train DARC, collect DARC trajectories from the source domain, and then train the discriminator and the generator alternatively.

🔼 This figure shows a comparison of the training reward of DARC in the source domain and its evaluation reward in the target domain, highlighting the performance degradation when deploying DARC in a new environment with a dynamics shift. It also illustrates the learning framework of DARAIL, which incorporates DARC training, discriminator training, and generator training to improve policy transfer and performance in the target domain.
read the caption
Figure 1: (a) Training reward in the source domain, i.e. EDARC, psrc [∑tr(st, at)], evaluation reward in the target domain, i.e. ΕπρARC, Purg [∑tr(st, at)] and optimal reward in target domain, for DARC in Ant. Evaluating the trained DARC policy in the target domain will cause performance degradation compared with its training reward, which should be close to the optimal reward in the target given DARC's objective function. Results of HalfCheetah, Walker2d, and Reacher are in Figure 9 in Appendix. (b) Learning framework of DARAIL. DARC Training: we first train the DARC in the source domain with a modified reward that is derived from the minimization of the reverse divergence between optimal policies on target and learned policies on the source. Details of DARC and the modified reward are in Section 3.1 and Appendix A.1. Discriminator training: the discriminator is trained to classify whether the data is from the expert demonstration (DARC trajectories) and provide a local reward function for policy learning. Generator training: the policy is updated with augmented reward estimation, which integrates the reward from the source domain and information from the discriminator. We first train DARC, collect DARC trajectories from the source domain, and then train the discriminator and the generator alternatively.

🔼 This figure shows the training reward in the source domain and evaluation reward in the target domain for the DARC (Domain Adaptation with Rewards from Classifiers) algorithm. It also illustrates the performance degradation of DARC when deployed in the target domain and the framework of the proposed DARAIL (Domain Adaptation and Reward Augmented Imitation Learning) algorithm. DARAIL utilizes reward modification for domain adaptation and generative adversarial imitation learning from observation, incorporating a reward augmented estimator for policy optimization.
read the caption
Figure 1: (a) Training reward in the source domain, i.e. ΕπDARC, psrc [∑tr(st, at)], evaluation reward in the target domain, i.e. ΕπDARC, Purg [∑tr(st, at)] and optimal reward in target domain, for DARC in Ant. Evaluating the trained DARC policy in the target domain will cause performance degradation compared with its training reward, which should be close to the optimal reward in the target given DARC's objective function. Results of HalfCheetah, Walker2d, and Reacher are in Figure 9 in Appendix. (b) Learning framework of DARAIL. DARC Training: we first train the DARC in the source domain with a modified reward that is derived from the minimization of the reverse divergence between optimal policies on target and learned policies on the source. Details of DARC and the modified reward are in Section 3.1 and Appendix A.1. Discriminator training: the discriminator is trained to classify whether the data is from the expert demonstration (DARC trajectories) and provide a local reward function for policy learning. Generator training: the policy is updated with augmented reward estimation, which integrates the reward from the source domain and information from the discriminator. We first train DARC, collect DARC trajectories from the source domain, and then train the discriminator and the generator alternatively.

🔼 This figure shows the performance degradation of DARC when deployed in the target domain due to dynamics shift. It also illustrates the DARAIL framework, which addresses this issue by incorporating imitation learning. DARAIL first trains a DARC policy in the source domain with a modified reward. Then, it uses imitation learning to transfer this policy to the target domain, improving performance.
read the caption
Figure 1: (a) Training reward in the source domain, i.e. EDARC, psrc [∑tr(st, at)], evaluation reward in the target domain, i.e. ΕπρARC, Purg [∑tr(st, at)] and optimal reward in target domain, for DARC in Ant. Evaluating the trained DARC policy in the target domain will cause performance degradation compared with its training reward, which should be close to the optimal reward in the target given DARC's objective function. Results of HalfCheetah, Walker2d, and Reacher are in Figure 9 in Appendix. (b) Learning framework of DARAIL. DARC Training: we first train the DARC in the source domain with a modified reward that is derived from the minimization of the reverse divergence between optimal policies on target and learned policies on the source. Details of DARC and the modified reward are in Section 3.1 and Appendix A.1. Discriminator training: the discriminator is trained to classify whether the data is from the expert demonstration (DARC trajectories) and provide a local reward function for policy learning. Generator training: the policy is updated with augmented reward estimation, which integrates the reward from the source domain and information from the discriminator. We first train DARC, collect DARC trajectories from the source domain, and then train the discriminator and the generator alternatively.
🔼 This figure shows the training reward of DARC in the source domain and evaluation reward in the target domain for the Ant environment. It highlights the performance degradation when a DARC policy trained in the source domain is directly deployed to the target domain. It also illustrates the learning framework of the proposed DARAIL method, which consists of three stages: DARC training with modified rewards to match target trajectory distributions, discriminator training to distinguish between expert (DARC) and generated trajectories, and generator training (policy update) using augmented reward estimation incorporating both source domain rewards and discriminator feedback.
read the caption
Figure 1: (a) Training reward in the source domain, i.e. EDARC, psrc [∑tr(st, at)], evaluation reward in the target domain, i.e. ΕπρARC, Purg [∑tr(st, at)] and optimal reward in target domain, for DARC in Ant. Evaluating the trained DARC policy in the target domain will cause performance degradation compared with its training reward, which should be close to the optimal reward in the target given DARC's objective function. Results of HalfCheetah, Walker2d, and Reacher are in Figure 9 in Appendix. (b) Learning framework of DARAIL. DARC Training: we first train the DARC in the source domain with a modified reward that is derived from the minimization of the reverse divergence between optimal policies on target and learned policies on the source. Details of DARC and the modified reward are in Section 3.1 and Appendix A.1. Discriminator training: the discriminator is trained to classify whether the data is from the expert demonstration (DARC trajectories) and provide a local reward function for policy learning. Generator training: the policy is updated with augmented reward estimation, which integrates the reward from the source domain and information from the discriminator. We first train DARC, collect DARC trajectories from the source domain, and then train the discriminator and the generator alternatively.

🔼 This figure shows the performance degradation of DARC when deployed to the target domain and introduces the DARAIL framework. Panel (a) compares the training reward of DARC in the source domain to its evaluation reward in the target domain, demonstrating performance degradation. Panel (b) illustrates the DARAIL method, which uses DARC to generate initial trajectories, then trains a discriminator and generator to improve policy performance in the target domain via imitation learning.
read the caption
Figure 1: (a) Training reward in the source domain, i.e. EDARC, psrc [∑tr(st, at)], evaluation reward in the target domain, i.e. ΕπρARC, Purg [∑tr(st, at)] and optimal reward in target domain, for DARC in Ant. Evaluating the trained DARC policy in the target domain will cause performance degradation compared with its training reward, which should be close to the optimal reward in the target given DARC's objective function. Results of HalfCheetah, Walker2d, and Reacher are in Figure 9 in Appendix. (b) Learning framework of DARAIL. DARC Training: we first train the DARC in the source domain with a modified reward that is derived from the minimization of the reverse divergence between optimal policies on target and learned policies on the source. Details of DARC and the modified reward are in Section 3.1 and Appendix A.1. Discriminator training: the discriminator is trained to classify whether the data is from the expert demonstration (DARC trajectories) and provide a local reward function for policy learning. Generator training: the policy is updated with augmented reward estimation, which integrates the reward from the source domain and information from the discriminator. We first train DARC, collect DARC trajectories from the source domain, and then train the discriminator and the generator alternatively.

🔼 The figure shows the training reward in the source domain and evaluation reward in the target domain for the DARC algorithm. It also illustrates the learning framework for the DARAIL algorithm, detailing the steps involved in DARC training, discriminator training, and generator training.
read the caption
Figure 1: (a) Training reward in the source domain, i.e. ΕπDARC, psrc [∑tr(st, at)], evaluation reward in the target domain, i.e. ΕπDARC, ptrg [∑tr(st, at)] and optimal reward in target domain, for DARC in Ant. Evaluating the trained DARC policy in the target domain will cause performance degradation compared with its training reward, which should be close to the optimal reward in the target given DARC's objective function. Results of HalfCheetah, Walker2d, and Reacher are in Figure 9 in Appendix. (b) Learning framework of DARAIL. DARC Training: we first train the DARC in the source domain with a modified reward that is derived from the minimization of the reverse divergence between optimal policies on target and learned policies on the source. Details of DARC and the modified reward are in Section 3.1 and Appendix A.1. Discriminator training: the discriminator is trained to classify whether the data is from the expert demonstration (DARC trajectories) and provide a local reward function for policy learning. Generator training: the policy is updated with augmented reward estimation, which integrates the reward from the source domain and information from the discriminator. We first train DARC, collect DARC trajectories from the source domain, and then train the discriminator and the generator alternatively.
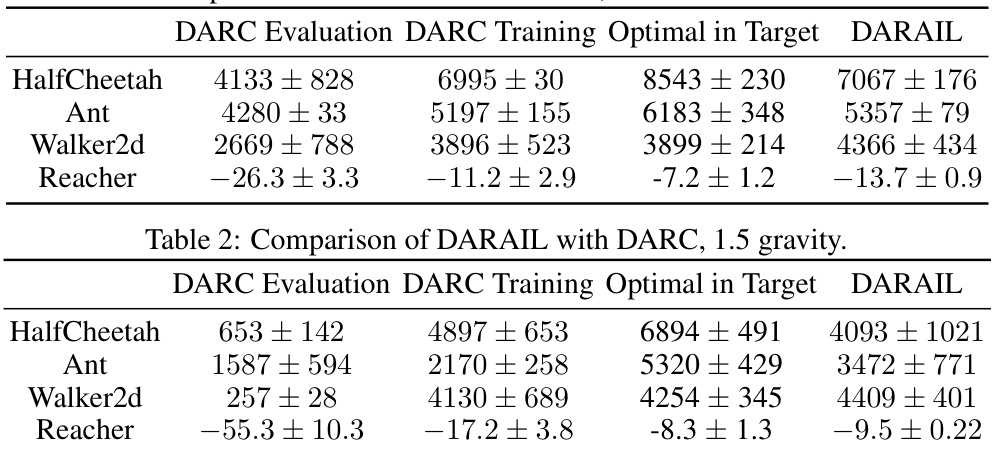
🔼 This figure compares the performance of DARAIL and IPS-ACL on two different environments (HalfCheetah and Walker2d) under various importance weight clipping intervals. The results show that DARAIL consistently outperforms IPS-ACL across all conditions. Notably, IPS-ACL’s performance is sensitive to the choice of clipping interval, achieving comparable results to DARAIL only under a specific interval ([0.01, 100]), while its performance degrades significantly with other intervals.
read the caption
Figure 2: Performance of DARAIL and IPS-ACL on HalfCheetah and Walker2d under different importance weight clipping intervals. DARAIL outperforms IPS-ACL on all tasks. In Table 3, IPS-ACL receives comparable performance with DARAIL with the clipping interval [0.01,100], while the performance decreases significantly with different intervals.

🔼 The figure compares the performance of DARAIL and IPS-ACL algorithms on HalfCheetah and Walker2d environments under various importance weight clipping intervals. It demonstrates that DARAIL consistently outperforms IPS-ACL across all tested intervals. The results highlight DARAIL’s robustness to the choice of clipping interval, unlike IPS-ACL which shows significant performance degradation when the interval is poorly chosen.
read the caption
Figure 2: Performance of DARAIL and IPS-ACL on HalfCheetah and Walker2d under different importance weight clipping intervals. DARAIL outperforms IPS-ACL on all tasks. In Table 3, IPS-ACL receives comparable performance with DARAIL with the clipping interval [0.01,100], while the performance decreases significantly with different intervals.

🔼 This figure shows the comparison of DARC and DARAIL. Subfigure (a) illustrates the training and evaluation reward of DARC in the Ant environment, highlighting the performance degradation when deploying the policy trained in the source domain to the target domain. Subfigure (b) presents the learning framework of DARAIL, which leverages DARC for domain adaptation and incorporates generative adversarial imitation learning for policy transfer, aiming to improve performance in the target domain.
read the caption
Figure 1: (a) Training reward in the source domain, i.e. EDARC, psrc [∑tr(st, at)], evaluation reward in the target domain, i.e. ΕπρARC, Purg [∑tr(st, at)] and optimal reward in target domain, for DARC in Ant. Evaluating the trained DARC policy in the target domain will cause performance degradation compared with its training reward, which should be close to the optimal reward in the target given DARC's objective function. Results of HalfCheetah, Walker2d, and Reacher are in Figure 9 in Appendix. (b) Learning framework of DARAIL. DARC Training: we first train the DARC in the source domain with a modified reward that is derived from the minimization of the reverse divergence between optimal policies on target and learned policies on the source. Details of DARC and the modified reward are in Section 3.1 and Appendix A.1. Discriminator training: the discriminator is trained to classify whether the data is from the expert demonstration (DARC trajectories) and provide a local reward function for policy learning. Generator training: the policy is updated with augmented reward estimation, which integrates the reward from the source domain and information from the discriminator. We first train DARC, collect DARC trajectories from the source domain, and then train the discriminator and the generator alternatively.
🔼 This figure shows the training reward of DARC in the source domain and its evaluation reward in the target domain. It also shows the learning framework of DARAIL, which consists of three stages: DARC training, discriminator training, and generator training. The results highlight the performance degradation of DARC when deployed to the target domain and illustrates how DARAIL aims to mitigate this issue by using imitation learning to transfer the policy learned in the source domain to the target domain.
read the caption
Figure 1: (a) Training reward in the source domain, i.e. EDARC, psrc [∑tr(st, at)], evaluation reward in the target domain, i.e. ΕπρARC, Purg [∑tr(st, at)] and optimal reward in target domain, for DARC in Ant. Evaluating the trained DARC policy in the target domain will cause performance degradation compared with its training reward, which should be close to the optimal reward in the target given DARC's objective function. Results of HalfCheetah, Walker2d, and Reacher are in Figure 9 in Appendix. (b) Learning framework of DARAIL. DARC Training: we first train the DARC in the source domain with a modified reward that is derived from the minimization of the reverse divergence between optimal policies on target and learned policies on the source. Details of DARC and the modified reward are in Section 3.1 and Appendix A.1. Discriminator training: the discriminator is trained to classify whether the data is from the expert demonstration (DARC trajectories) and provide a local reward function for policy learning. Generator training: the policy is updated with augmented reward estimation, which integrates the reward from the source domain and information from the discriminator. We first train DARC, collect DARC trajectories from the source domain, and then train the discriminator and the generator alternatively.
More on tables
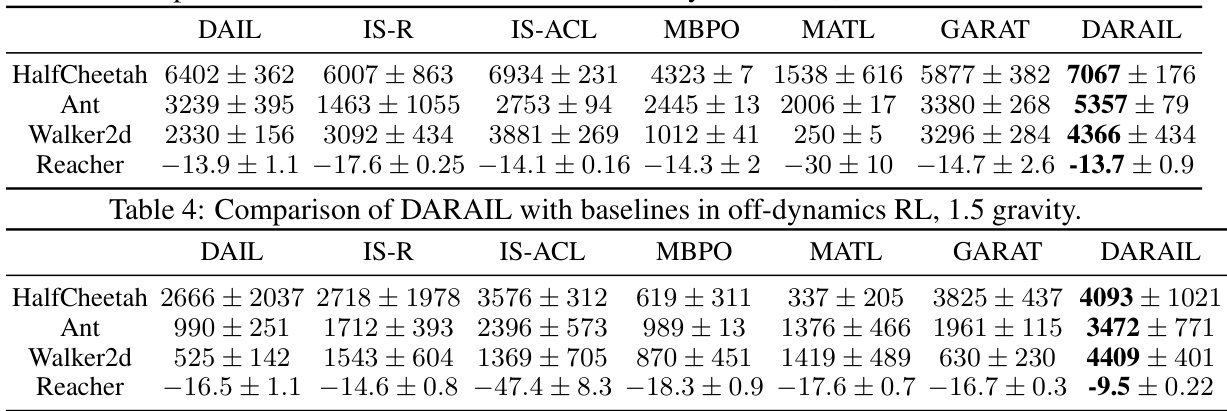
🔼 This table presents a comparison of the DARAIL algorithm’s performance against several baseline methods in off-dynamics reinforcement learning settings with a broken source environment. The results are shown for four MuJoCo environments (HalfCheetah, Ant, Walker2d, and Reacher), each with performance measured by the average cumulative reward and standard deviation. The baseline methods include DAIL, IS-R, IS-ACL, MBPO, MATL, and GARAT. The table allows for a direct comparison of DARAIL’s performance with state-of-the-art methods under challenging conditions.
read the caption
Table 3: Comparison of DARAIL with baselines in off-dynamics RL, broken source environment.

🔼 This table compares the performance of DARAIL and DARC in four MuJoCo benchmark environments (HalfCheetah, Ant, Walker2d, and Reacher) with a broken source environment. The ‘DARC Evaluation’ column shows DARC’s performance in the target domain (where the 0-index in the action is intact). The ‘DARC Training’ column shows DARC’s performance in the source domain (where the 0-index in the action is broken). The ‘Optimal in Target’ column indicates the optimal reward achievable in the target domain. Finally, the ‘DARAIL’ column shows the performance of the proposed DARAIL algorithm in the target domain. The results demonstrate DARAIL’s superior performance compared to DARC when the source domain has limited functionality compared to the target domain.
read the caption
Table 1: Comparison of DARAIL with DARC, broken source environment.

🔼 This table presents a comparison of the DARAIL algorithm’s performance against several baseline methods in off-dynamics reinforcement learning scenarios. The experiments were conducted in environments with a broken source setting, meaning the source environment has limitations. The table shows the average reward obtained by each algorithm across four different MuJoCo environments (HalfCheetah, Ant, Walker2d, and Reacher). The results demonstrate DARAIL’s superior performance compared to the baselines. The metrics reported allow a clear assessment of the relative performance improvements achieved by DARAIL.
read the caption
Table 3: Comparison of DARAIL with baselines in off-dynamics RL, broken source environment.

🔼 This table compares the performance of DARAIL and DARC in four MuJoCo environments (HalfCheetah, Ant, Walker2d, and Reacher) when the source domain has a broken environment (0-index action frozen to 0). It shows the DARC Evaluation (performance in the target domain), DARC Training (performance in the source domain), the optimal reward achievable in the target domain, and the DARAIL performance in the target domain. The results highlight DARAIL’s improved performance over DARC in the target domain, particularly when facing challenging off-dynamics scenarios.
read the caption
Table 1: Comparison of DARAIL with DARC, broken source environment.

🔼 This table presents a comparison of the DARAIL algorithm’s performance against several baseline methods in off-dynamics reinforcement learning scenarios with a broken source environment. The table shows the average reward achieved by each algorithm across four different MuJoCo environments (HalfCheetah, Ant, Walker2d, and Reacher). The results demonstrate DARAIL’s superior performance compared to the baselines, highlighting its effectiveness in handling dynamics shifts between source and target domains when the source domain is compromised.
read the caption
Table 3: Comparison of DARAIL with baselines in off-dynamics RL, broken source environment.

🔼 This table compares the performance of DARAIL and DARC in MuJoCo environments with a 1.5 times gravity setting. It shows the DARC Evaluation (performance of DARC in the target domain), DARC Training (performance of DARC in the source domain), the optimal reward achievable in the target domain, and the performance of DARAIL (the proposed method) in the target domain. The results demonstrate the improvement of DARAIL over DARC, especially considering the significant performance drop of DARC when deployed to the target domain.
read the caption
Table 2: Comparison of DARAIL with DARC, 1.5 gravity.

🔼 This table presents a comparison of the DARAIL algorithm’s performance against several baseline methods in off-dynamics reinforcement learning settings. The source environment is modified to be ‘broken’, meaning a specific action is constrained. The table shows the average reward achieved by each algorithm across four different Mujoco benchmark environments (HalfCheetah, Ant, Walker2d, and Reacher). The results highlight DARAIL’s superior performance compared to the baselines, demonstrating its effectiveness in handling dynamics shifts between source and target domains.
read the caption
Table 3: Comparison of DARAIL with baselines in off-dynamics RL, broken source environment.

🔼 This table compares the performance of DARAIL and DARC when provided with the same number of rollouts from the target domain. The results show that increasing the number of target domain rollouts does not significantly improve DARC’s performance, highlighting its inherent sub-optimality. In contrast, DARAIL consistently outperforms DARC, even with comparable target rollouts. This demonstrates the effectiveness of DARAIL’s imitation learning component in mitigating the limitations of DARC in handling dynamics shifts.
read the caption
Table 11: Comparison with DARC with the same amount of rollout from the target. The number in the columns represents the amount of rollout from the target. More target domain rollout will not improve the DARC's performance further. Experiment on broken source setting.

🔼 This table compares the performance of DARAIL and DARC on the Reacher environment with varying amounts of target domain rollouts. It demonstrates that increasing the number of target rollouts does not significantly improve DARC’s performance because of its inherent limitations. DARAIL consistently outperforms DARC even with comparable target rollouts, highlighting its effectiveness in mitigating the sub-optimality of DARC.
read the caption
Table 12: Comparison with DARC with the same amount of rollout from target, on Reacher. The number in the columns represents the amount of rollout from the target. More target domain rollout will not improve the DARC's performance further. Experiment on broken source setting.
Full paper#