↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Existing methods for relightable 3D view synthesis use inverse rendering, which is computationally expensive and prone to errors due to inherent ambiguities. These methods attempt to disentangle object geometry, materials, and lighting from images, often using gradient-based optimization through differentiable rendering which is noisy and unstable. These challenges hinder efficient and reliable 3D relighting for various applications.
The proposed IllumiNeRF method overcomes these issues by employing a two-stage process. First, it preprocesses input images using a relighting diffusion model conditioned on target lighting and estimated geometry to generate multiple plausible relit images. Then, it trains a latent NeRF on these relit images to produce a consistent 3D representation, enabling the rendering of novel views under target illumination. This novel approach improves both efficiency and accuracy, setting a new state-of-the-art in relightable 3D reconstruction.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a novel approach to 3D relighting, avoiding computationally expensive inverse rendering methods. It introduces a simpler, more efficient pipeline that achieves state-of-the-art results, opening up new avenues for research in view synthesis and 3D content creation.
Visual Insights#

This figure provides a visual overview of the IllumiNeRF method. It shows the process from input images and poses (a) through NeRF geometry extraction (b), radiance cue creation (d) based on the target lighting (c), image relighting using a diffusion model (e), and finally, the generation of a consistent 3D representation (g, h) from the relit images (f) using a latent NeRF. The final 3D model can then be used to render novel views under the target lighting.

This table presents a quantitative comparison of the IllumiNeRF method against three other state-of-the-art methods on the TensoIR benchmark dataset. The metrics used for comparison are PSNR, SSIM, LPIPS, and wall-clock time. The benchmark consists of four objects, each rendered under five different target lighting conditions with 200 poses each, resulting in a total of 4000 renderings. The table highlights the superior performance of IllumiNeRF in terms of image quality metrics and efficiency. It also breaks down the wall-clock time for IllumiNeRF into three components: geometry optimization, diffusion sampling, and latent NeRF optimization.
In-depth insights#
Inverse Rendering#
Inverse rendering, a core concept in computer graphics and vision, aims to infer the 3D scene properties (geometry, material, lighting) from observed 2D images. It’s an inherently ill-posed problem, as multiple combinations of these factors can produce the same image. Existing methods often tackle this by formulating it as an optimization problem, using physically-based rendering techniques within differentiable rendering frameworks. However, this approach is computationally expensive and susceptible to local optima, leading to unstable and potentially inaccurate results. The ambiguity inherent in inverse rendering makes disentangling geometry, material, and lighting exceptionally challenging, highlighting the need for alternative, more robust approaches that are both effective and computationally efficient.
Relighting Diffusion#
Relighting Diffusion, as a concept, presents a novel approach to 3D scene relighting. Instead of the traditional inverse rendering methods which attempt to disentangle scene geometry, materials, and lighting, relighting diffusion models directly learn the mapping between input images under unknown lighting and relit images under a specified target illumination. This is achieved by training a diffusion model on a large dataset of images, enabling it to generate plausible relit versions of input images conditioned on target lighting. The inherent ambiguity of the inverse rendering problem is elegantly circumvented by leveraging the generative nature of diffusion models, producing multiple plausible relit images for a single input. These diverse outputs effectively represent the uncertainty inherent in the relighting task, allowing for more robust and realistic results. The effectiveness of this approach relies heavily on the quality of the training data and the sophistication of the diffusion model’s architecture. Future research directions could explore different diffusion model architectures and conditioning strategies to further improve the realism and efficiency of relighting diffusion.
Latent NeRF#
The concept of “Latent NeRF” involves using a latent code to condition a Neural Radiance Field (NeRF). This allows the NeRF to represent not just a single scene, but a family of scenes, each differing based on variations encoded by the latent code. In the context of relighting, this approach enables the generation of novel views under diverse lighting conditions. Instead of explicitly modeling materials and lighting, the latent code implicitly captures these aspects. This is advantageous as inverse rendering approaches, which attempt to explicitly disentangle object geometry, materials, and lighting, are often computationally expensive and susceptible to ambiguities. By learning a mapping from latent codes to relit NeRFs, a more efficient and robust relighting process is achieved. The method is particularly interesting because it sidesteps the difficulties of traditional inverse rendering, offering a generative approach which leverages the expressive power of neural networks to effectively capture the complexities of light transport and material properties.
Benchmark Results#
A thorough analysis of benchmark results within a research paper requires a multifaceted approach. It’s crucial to understand the specific metrics used, their relevance to the research question, and how they reflect the overall performance. The selection of benchmarks themselves is critical, as they should represent a fair and comprehensive evaluation of the proposed method. It is important to look for a comparison against a diverse range of existing methods, not just the state-of-the-art, to establish the relative strengths and weaknesses. Qualitative aspects, such as visual results or error analysis, must also be considered alongside quantitative measures to provide a complete picture. Furthermore, a detailed examination of any limitations or caveats in the benchmarking process, including potential biases or sources of error, is necessary for accurate interpretation. Finally, attention should be paid to the experimental setup, ensuring that the parameters and conditions are clearly defined and reproducible. Only then can the benchmark results be meaningfully interpreted, providing valuable insights into the contribution of the research.
Future Work#
Future research directions stemming from IllumiNeRF could explore several promising avenues. Improving the robustness of the method to noisy or incomplete input data is crucial for real-world applications. This could involve incorporating more sophisticated geometry estimation techniques or developing methods for handling missing or corrupted image regions. Extending the model to handle dynamic scenes would significantly broaden its applicability. This is a very challenging problem, as it requires the model to account for changes in object pose and lighting over time. Investigating alternative relighting strategies, such as those based on physics-based rendering or neural rendering approaches, may lead to improved accuracy and efficiency. Further development of the single-image relighting diffusion model to better handle materials with complex appearance and fine-grained details would enhance the overall performance of the system. Lastly, exploring the use of IllumiNeRF for novel applications, such as augmented and virtual reality, interactive 3D content creation and novel view synthesis, will create significant impact. These improvements would likely involve exploring more advanced deep learning architectures and training strategies.
More visual insights#
More on figures

This figure shows the overview of the IllumiNeRF model. It takes as input a set of images and camera poses. It first uses NeRF to reconstruct the 3D geometry of the scene. Then, it generates radiance cues based on the geometry and target lighting. These cues are used to condition a Relighting Diffusion Model, which produces multiple relit images for each input view. Finally, these relit images are used to train a Latent NeRF, which can be used to render novel views under the target lighting.

This figure compares the results of using the Relighting Diffusion Model and the Latent NeRF model to relight images. The left side shows various samples generated by the diffusion model for the same target lighting condition, illustrating the diversity of possible explanations for the scene’s appearance. The right side displays renderings produced by the optimized Latent NeRF for a fixed latent code, demonstrating how the model effectively combines the different latent interpretations into consistent and high-quality results. This highlights the effectiveness of the Latent NeRF in reconciling multiple plausible explanations generated by the diffusion model into a single coherent 3D representation.

This figure displays four images illustrating the radiance cues used in the IllumiNeRF model. The images show a rendered view of a hot dog on a plate under different material properties. The first image shows a diffuse material, while the remaining three images show specular materials with varying roughness values (0.34, 0.13, and 0.05). These cues help to encode lighting information and are used as conditioning input for the single-image relighting diffusion model within the IllumiNeRF pipeline. They provide information about the effects of specularities, shadows, and global illumination without requiring the diffusion network to learn these effects from scratch.
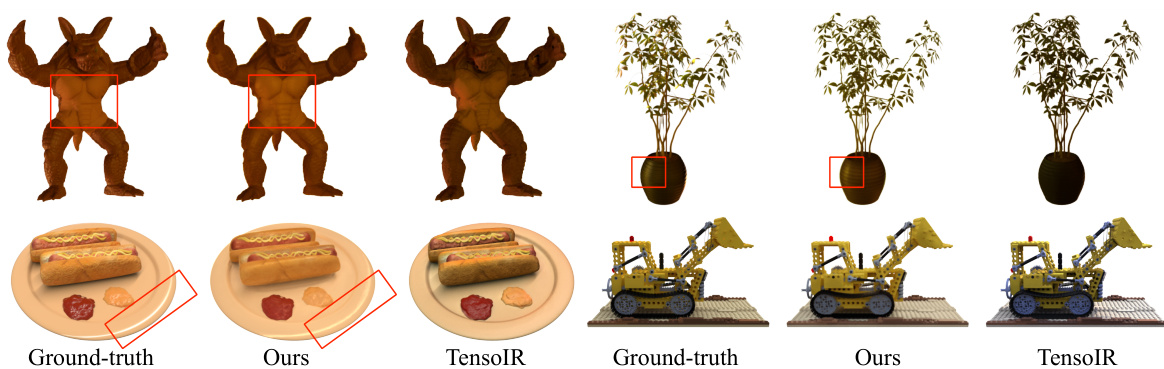
This figure shows a qualitative comparison of relighting results on the TensoIR benchmark dataset. It includes ground truth images alongside images generated by the proposed IllumiNeRF method and the TensoIR baseline method. The red boxes highlight areas where IllumiNeRF excels in recovering specular highlights and accurate color reproduction, showcasing its superior performance compared to the baseline. The overall aim is to demonstrate the superior quality of relighting achieved by the proposed method.

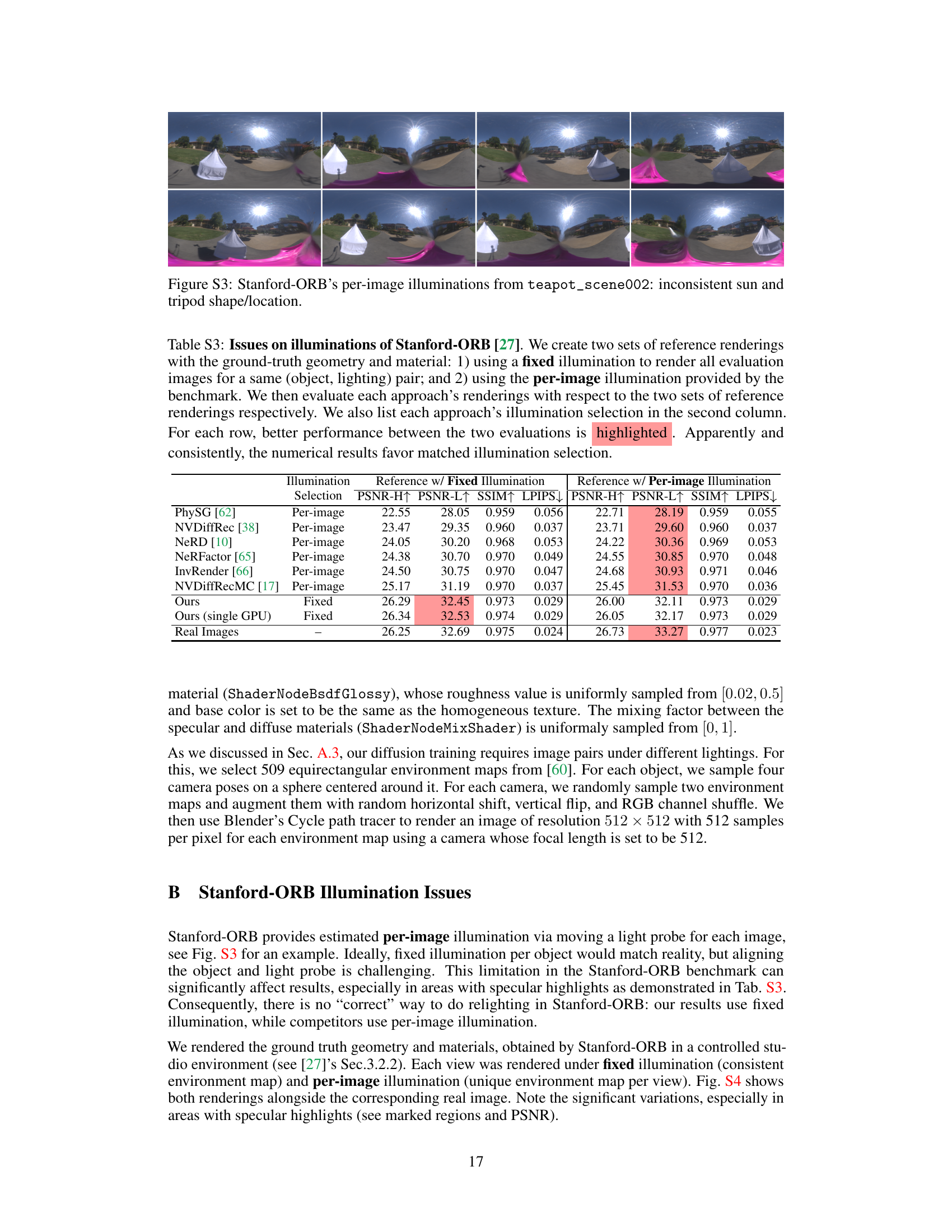
This figure shows a qualitative comparison of different relighting methods on the Stanford-ORB dataset. Each row represents a different object and lighting condition. The first column shows the ground truth image; the subsequent columns show relighting results generated by various methods, including the proposed IllumiNeRF. The red boxes highlight regions where IllumiNeRF demonstrates superior performance, especially in capturing specular highlights and realistic material appearances.

This figure displays qualitative results of the TensoIR benchmark. It compares renderings from various methods with ground truth images. The red highlights in the image emphasize areas where the proposed method (IllumiNeRF) stands out by accurately capturing specular highlights and colors.
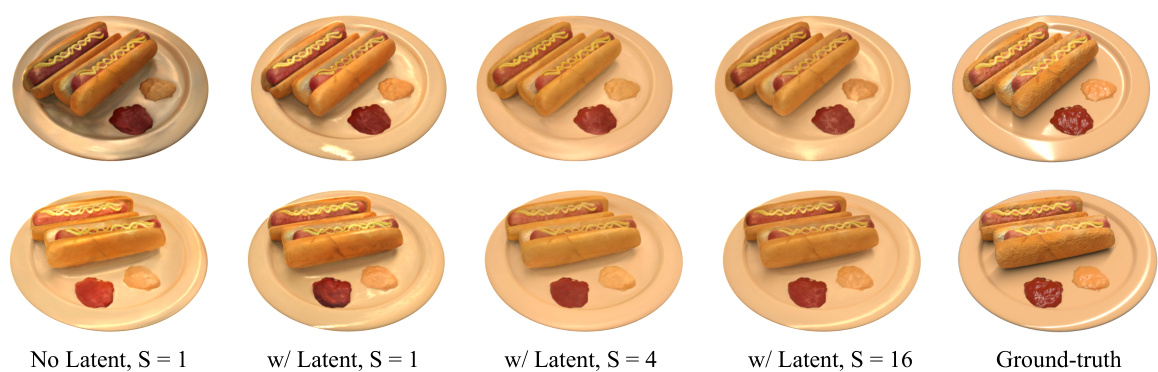
This figure compares the results of using a standard NeRF versus a latent NeRF, and varying the number of samples (S) used from the Relighting Diffusion Model (RDM) for training the NeRF. It demonstrates that using a latent NeRF, and increasing the number of samples, significantly improves the quality of the rendered images, especially in terms of the accuracy of specular highlights.

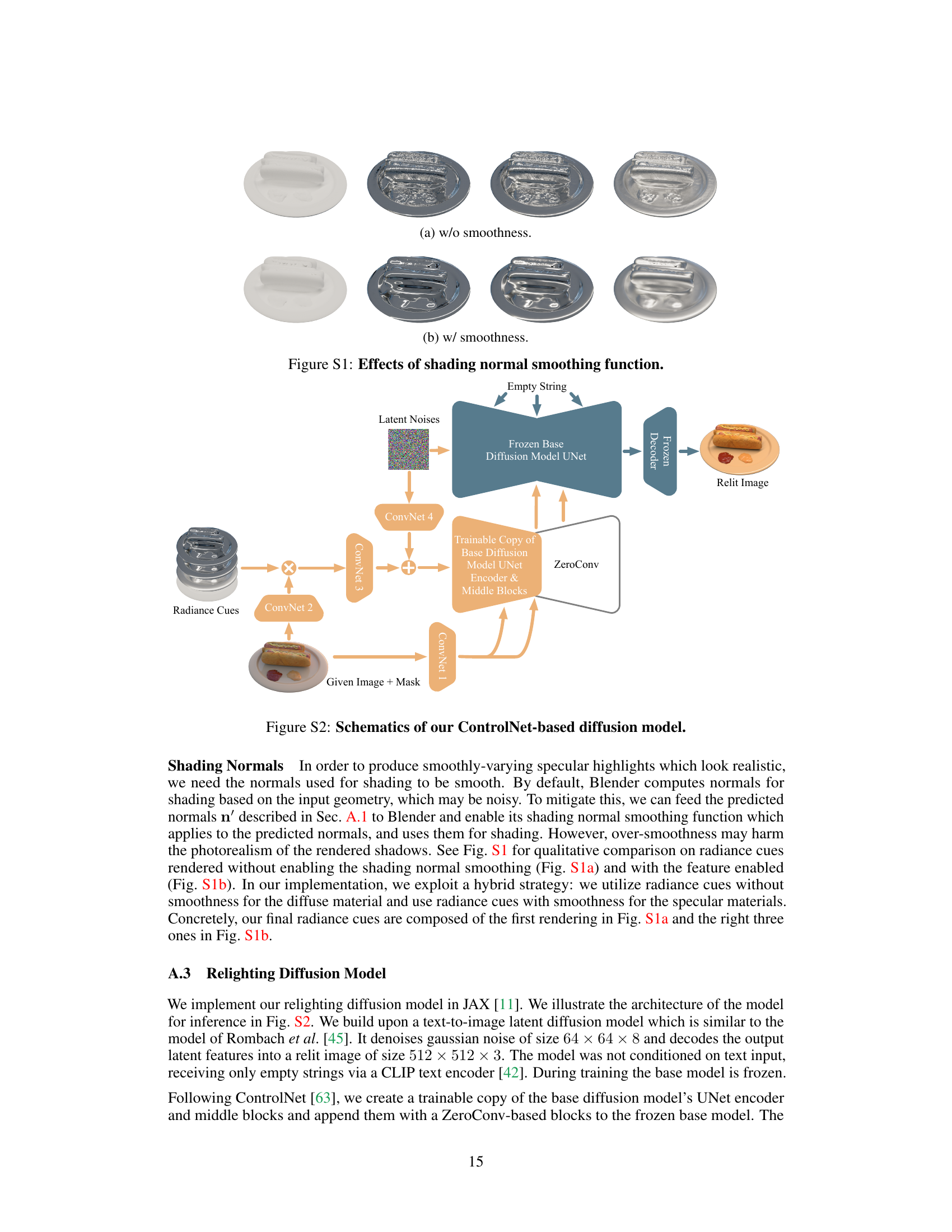
This figure shows a comparison of radiance cues rendered with and without the shading normal smoothing function enabled in Blender. The leftmost image in each row shows a diffuse material, while the remaining images show progressively rougher specular materials. The top row (a) shows the results without smoothness enabled, while the bottom row (b) shows the results with smoothness enabled. The comparison highlights that while smoothness helps to create more realistic-looking specular highlights, over-smoothness can negatively impact the photorealism of shadows.
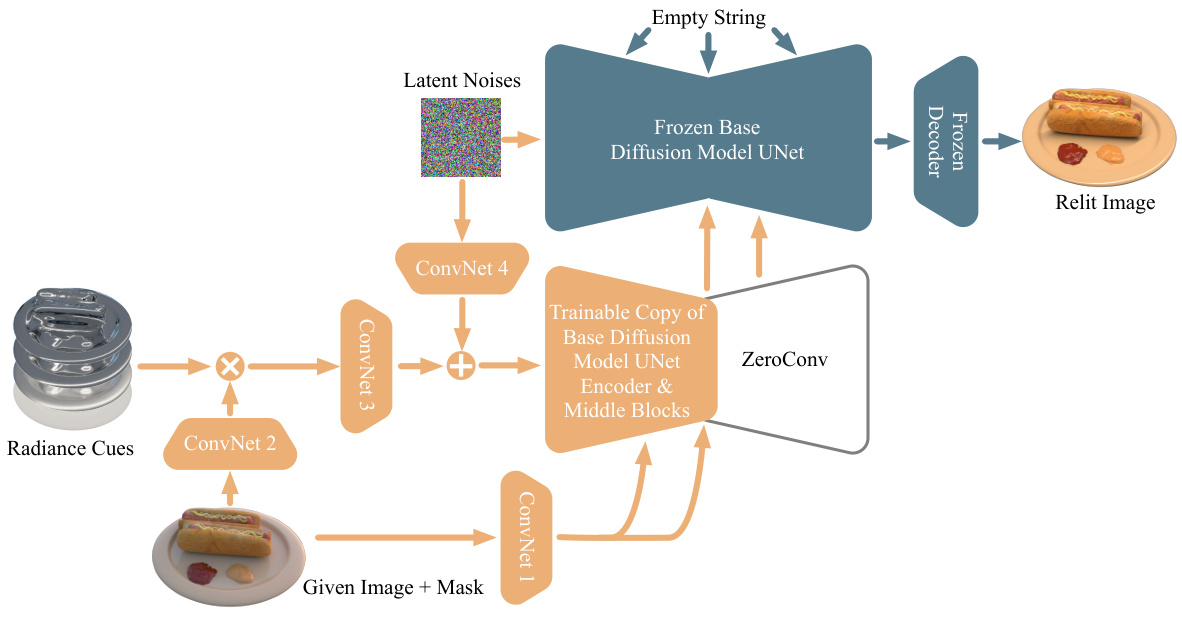
This figure illustrates the overall pipeline of the IllumiNeRF method. Starting with input images and camera poses (a), it first reconstructs a 3D representation using NeRF (b). Then, it generates radiance cues based on the 3D geometry and target lighting (c, d). Next, it uses a single-image relighting diffusion model to relight each input image, producing multiple plausible relit images (e, f). Finally, it trains a latent NeRF on these relit images to produce a consistent 3D model that can be rendered under the target lighting (g, h).

This figure provides a visual overview of the IllumiNeRF pipeline. It shows how input images and poses are used to first extract a 3D geometry using NeRF. Then, radiance cues are generated based on the geometry and target lighting, which are then used to relight input images using a single-image relighting diffusion model. Finally, the relit images are used to train a latent NeRF to create a 3D representation that can be used for novel view synthesis under the target lighting.

This figure compares samples from the Relighting Diffusion Model with renderings from the optimized Latent NeRF for the same target environment map. The diffusion model produces samples representing different latent explanations of the scene (different interpretations of material, geometry, lighting). The latent NeRF optimization combines these diverse interpretations to produce consistent and coherent 3D renderings.
More on tables
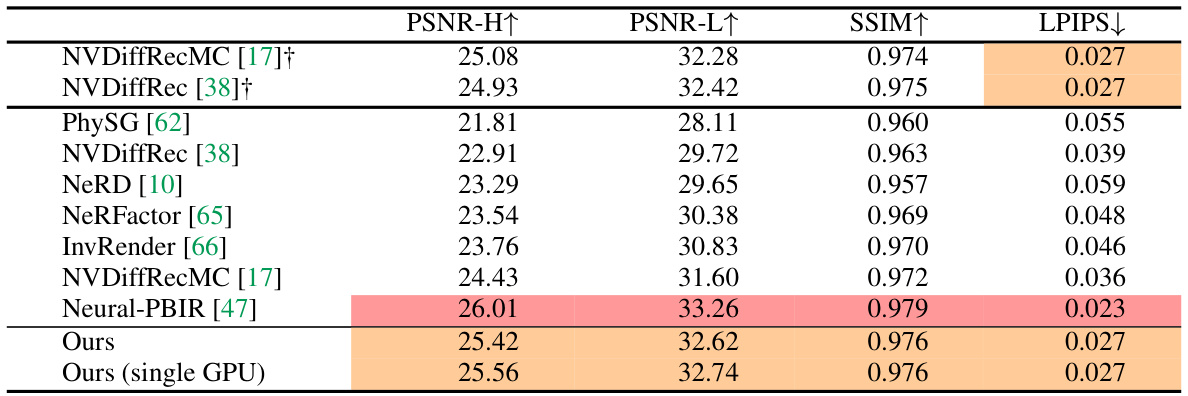
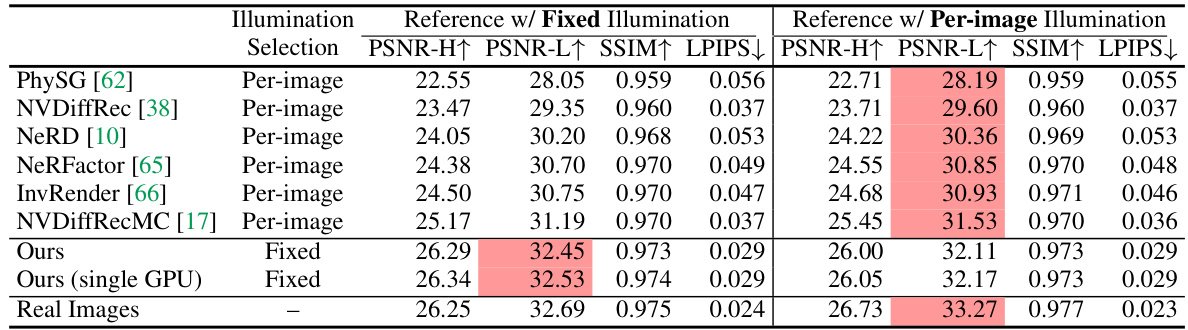
This table presents the quantitative results of the IllumiNeRF model and several baseline models on the Stanford-ORB benchmark dataset for relightable 3D reconstruction. The results are based on 14 real-world objects, each captured under three different lighting conditions. The table reports PSNR-H (Peak Signal-to-Noise Ratio for HDR images), PSNR-L (PSNR for LDR images), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity) scores, evaluating the quality of the relit images. The models marked with † used ground-truth 3D scans and pseudo materials.
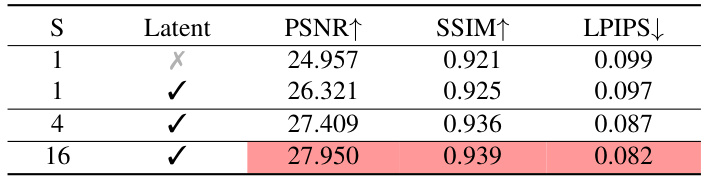
This table presents the ablation study results on the ‘hotdog’ scene from the TensoIR benchmark. It shows the impact of using a latent NeRF, and the number of samples (S) from the Relighting Diffusion Model on the performance metrics (PSNR, SSIM, LPIPS). The results demonstrate that using a latent NeRF is crucial for good performance, and increasing the number of samples improves the results.
This table presents the quantitative results of the IllumiNeRF model and several baselines on the TensoIR benchmark dataset. The benchmark consists of four objects rendered under five different target lighting conditions, each with 200 poses, resulting in 4000 renderings in total. The table shows the PSNR, SSIM, LPIPS, and wall-clock time for each model. The best and second-best results are highlighted. The authors’ method’s timing is broken down into three stages: geometry optimization on GPU, diffusion sampling on TPU, and latent NeRF optimization on GPU.
This table presents quantitative results on the TensoIR benchmark [23], a synthetic dataset. It shows a comparison of the proposed IllumiNeRF method against several baselines, evaluating four objects under five different target lightings (each with 200 poses, for a total of 4000 renderings). The metrics used are PSNR, SSIM, LPIPS, and wall-clock time. The table highlights the best and second-best performing methods.
This table presents a quantitative comparison of the IllumiNeRF model against several baselines on the TensoIR benchmark dataset. The benchmark consists of four objects, each rendered under five different target lighting conditions, with 200 poses per lighting condition. The table shows the PSNR, SSIM, and LPIPS metrics for each method, along with the total runtime. The runtime for IllumiNeRF is broken down into three stages: geometry optimization on GPU, diffusion sampling on TPU, and latent NeRF optimization on GPU. The best and second-best performing methods for each metric are highlighted.
Full paper#