TL;DR#
Recommender systems are vulnerable to poisoning attacks, where malicious actors inject fake data to manipulate recommendations. Adversarial Collaborative Filtering (ACF) is a defense mechanism that uses adversarial training to improve robustness, but its theoretical understanding and potential for improvement remain unclear. Previous ACF methods lack a comprehensive theoretical foundation and use a uniform perturbation magnitude for all users.
This paper bridges this gap by providing a theoretical analysis showing that ACF can achieve lower recommendation errors compared to traditional CF. It then proposes Personalized Magnitude Adversarial Collaborative Filtering (PamaCF), which applies personalized perturbation magnitudes based on users’ embedding scales to further enhance ACF’s effectiveness. Extensive experiments demonstrate that PamaCF effectively defends against various poisoning attacks while significantly improving recommendation performance.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in recommender systems due to its novel theoretical analysis of adversarial collaborative filtering (ACF). It provides a deeper understanding of ACF’s effectiveness and proposes PamaCF, significantly improving robustness and performance against poisoning attacks. This opens new avenues for developing more resilient and effective recommendation systems, addressing a critical challenge in the field.
Visual Insights#
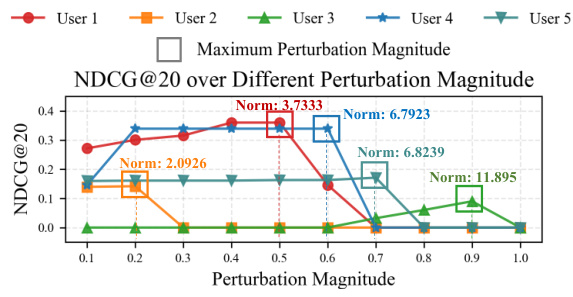
🔼 This figure displays the NDCG@20 (Normalized Discounted Cumulative Gain at 20) scores for five distinct users across a range of perturbation magnitudes. Each line represents a different user, and the x-axis shows the magnitude of the perturbation applied during a random attack. The y-axis represents the NDCG@20 score, indicating the effectiveness of the recommender system’s ranking under the attack. The figure demonstrates that for each user there’s an optimal perturbation magnitude that maximizes NDCG@20, which then decreases as the perturbation level increases further.
read the caption
Figure 1: NDCG@20 across various perturbation magnitudes for five users (subject to Random Attacks [30]).

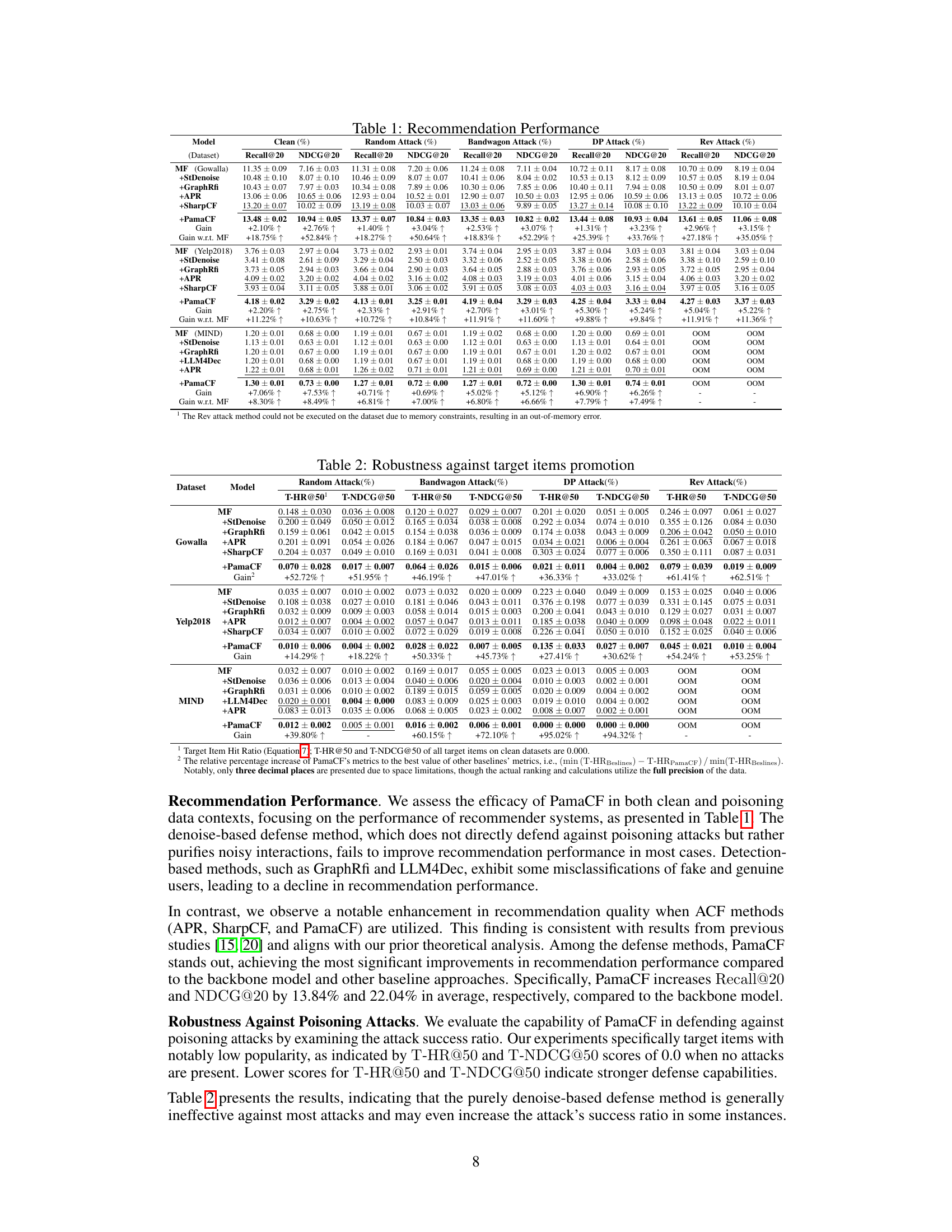
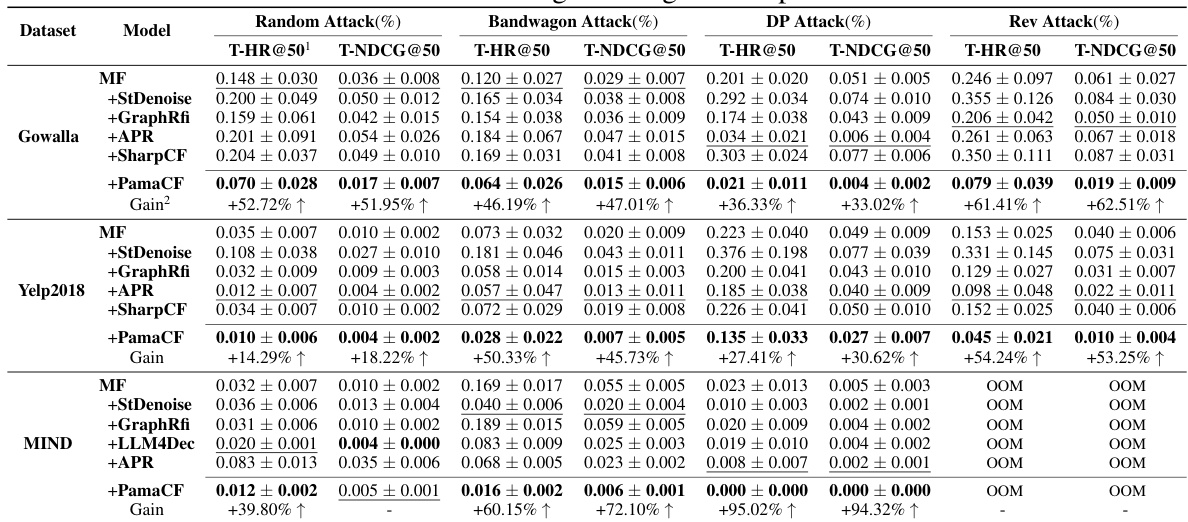
🔼 This table presents the recommendation performance (Recall@20 and NDCG@20) of different models on three datasets (Gowalla, Yelp2018, and MIND) under various attack scenarios (clean data, Random Attack, Bandwagon Attack, DP Attack, and Rev Attack). The models include the base model (MF), and defense methods: StDenoise, GraphRfi, APR, SharpCF, and PamaCF. The table shows the performance gains of each defense method compared to the base model and the previous state-of-the-art methods. It demonstrates PamaCF’s superior recommendation performance and robustness against poisoning attacks.
read the caption
Table 1: Recommendation Performance
In-depth insights#
Adversarial CF Theory#
Adversarial Collaborative Filtering (ACF) enhances robustness against poisoning attacks by incorporating adversarial perturbations during training. Theoretical analysis reveals that ACF can achieve lower recommendation errors compared to traditional CF methods, even under poisoned data conditions. This improvement stems from ACF’s ability to learn more robust user and item embeddings that are less susceptible to manipulation by malicious actors. The theoretical framework also suggests that personalized perturbation magnitudes, adjusted based on user embedding scales, can further enhance ACF’s effectiveness. This personalized approach accounts for varying vulnerabilities among users and leads to better error reduction. Upper and lower bounds on error reduction during ACF optimization provide a rigorous mathematical framework to support these claims. This provides a solid theoretical foundation for understanding the efficacy and potential improvements of ACF in building more robust recommender systems.
PamaCF Algorithm#
The core of the research paper revolves around the proposed PamaCF algorithm, a novel approach to enhancing the robustness of collaborative filtering (CF) recommender systems. PamaCF builds upon the foundation of adversarial collaborative filtering (ACF), improving upon existing ACF methods by introducing a key innovation: personalized perturbation magnitudes. Instead of applying a uniform level of perturbation across all users, PamaCF dynamically assigns perturbation magnitudes based on individual user embedding scales. This personalized approach is theoretically grounded, showing that it leads to tighter bounds on error reduction during the optimization process and thus better performance and robustness against various attacks. The effectiveness of PamaCF is demonstrated through extensive experiments, showcasing significant improvements in recommendation performance and a strong defense against poisoning attacks compared to existing methods. The algorithm leverages theoretical insights into the error reduction bounds to achieve superior performance, establishing its value not only empirically but also from a theoretical perspective. Its dynamic personalization mechanism adapts to varying user influences, making it a robust defense against sophisticated poisoning attacks. The simplicity and intuitive nature of its personalization strategy, combined with its theoretical underpinnings, make PamaCF a promising contribution to improving the resilience of recommender systems.
Robustness Analysis#
A Robustness Analysis section in a research paper would thoroughly investigate the resilience of a proposed model or system. This would involve evaluating its performance under various conditions deviating from the ideal scenario. Key aspects would include assessing the model’s resistance to noisy or incomplete data, evaluating its sensitivity to hyperparameter choices and exploring its ability to generalize to unseen data distributions. The analysis could employ metrics such as precision, recall, F1-score, AUC or others relevant to the specific task. Crucially, the analysis should not only quantify the robustness but also provide insights into the why. For example, by analyzing error patterns the analysis might uncover vulnerabilities in specific model components or identify limitations in data preprocessing techniques. The strength of the analysis lies in its depth and its capacity to both quantify and qualitatively describe robustness, offering actionable recommendations for improvement or deployment strategies that mitigate potential risks.
Hyperparameter Tuning#
Hyperparameter tuning is a critical step in optimizing the performance of machine learning models, and this is especially true for complex models such as those used in adversarial collaborative filtering (ACF). The paper likely explores how the choice of hyperparameters—such as the magnitude of perturbations (p) and the adversarial training weight (λ)—affects the model’s robustness against poisoning attacks and its overall recommendation accuracy. A key aspect to consider is the interaction between these hyperparameters. For example, increasing p might improve robustness but decrease accuracy if λ is not adjusted accordingly. The analysis will likely involve either a grid search or more sophisticated methods like Bayesian optimization to find the optimal parameter settings. The results of this tuning process are crucial for demonstrating the effectiveness of the proposed ACF model, so it is essential that this section clearly articulates the methods used, the rationale behind those choices, and the resulting optimal configuration. In addition to presenting the best performing values, it is important to discuss the range of values that were tested, and to visualize the sensitivity of the model to changes in hyperparameters. This would allow for a better understanding of the robustness of the model’s performance and aid in generalization to different datasets and attack scenarios.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending the theoretical framework beyond the simplified Gaussian model to encompass more realistic CF scenarios, like those employing complex loss functions or dealing with implicit feedback, is crucial. Investigating the interplay between different types of poisoning attacks and their interaction with personalized perturbation strategies would provide a more nuanced understanding of robustness. The impact of varying the learning rate and adversarial training weight on the proposed PamaCF algorithm also warrants further analysis, potentially revealing optimal hyperparameter settings. Finally, empirical evaluation on a broader range of datasets, including those with diverse user behavior patterns and item characteristics, could validate the generalizability of PamaCF’s effectiveness. Furthermore, comparing PamaCF’s performance against other state-of-the-art defense methods using rigorous benchmarks would definitively establish its superiority. Addressing these research questions will contribute significantly to advancing robust recommendation systems.
More visual insights#
More on figures
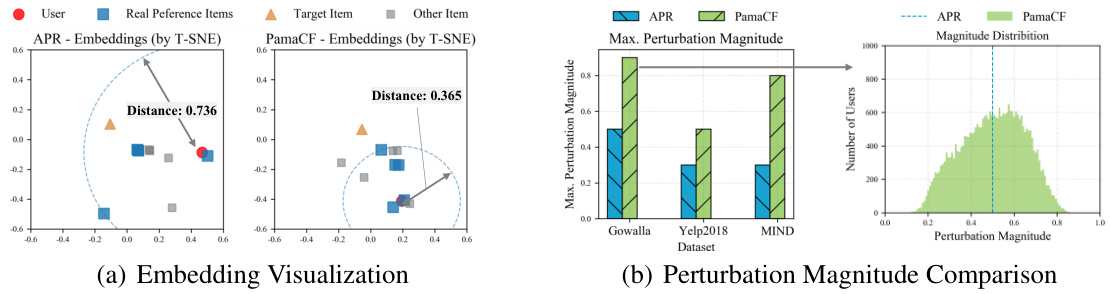
🔼 This figure contains two subfigures. Subfigure (a) shows a t-SNE visualization of embeddings from APR and PamaCF. The visualization shows that PamaCF brings real preference items closer together while pushing the target item further away from the real preference items, which supports the effectiveness of PamaCF in improving recommendation accuracy and robustness. Subfigure (b) compares the maximum perturbation magnitudes used by APR and PamaCF and shows the distribution of perturbation magnitudes used by PamaCF across all users. The results indicate that PamaCF achieves higher maximum perturbation magnitudes and more dynamic perturbation magnitudes across users compared to APR.
read the caption
Figure 2: (a) PamaCF brings real preference items closer; (b) PamaCF achieves larger magnitudes.

🔼 This figure analyzes the impact of hyperparameters (p and λ) on the performance and robustness of PamaCF. The left side shows how varying the uniform perturbation magnitude (p) affects NDCG@20 and T-NDCG@50 across different attack types (clean, random, bandwagon, DP, Rev) with the base MF model on clean data as a reference. The right side shows similar results but this time varying the adversarial training weight (λ). The results illustrate the optimal ranges for p and λ to balance performance and robustness.
read the caption
Figure 3: Left: Analysis of Hyper-Parameters p; Right: Analysis of Hyper-Parameters λ.
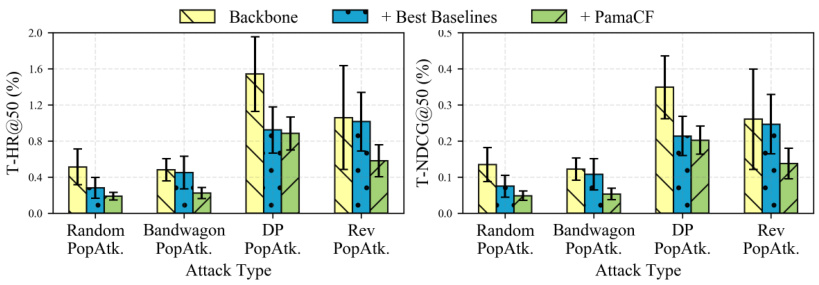
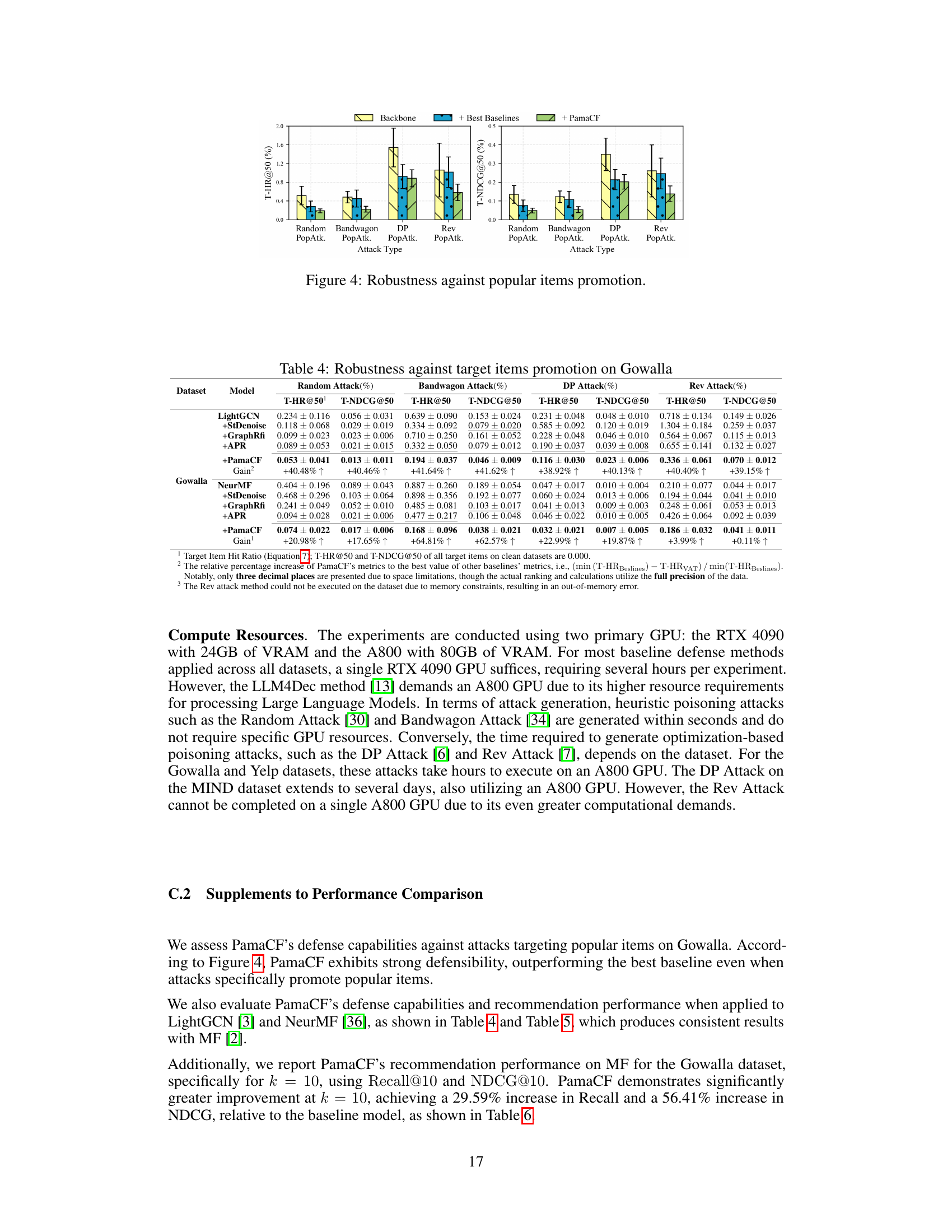
🔼 This figure displays the robustness of different methods against attacks targeting popular items. It shows the T-HR@50 and T-NDCG@50 scores for various attack types (Random, Bandwagon, DP, Rev) on the Gowalla dataset. The baseline is the performance of the recommendation model without any defense mechanism. The ‘Best Baselines’ represent the best-performing defense method other than PamaCF. PamaCF consistently demonstrates superior defense capabilities against these attacks, maintaining significantly lower success ratios for manipulating the ranking of popular items.
read the caption
Figure 4: Robustness against popular items promotion.
More on tables
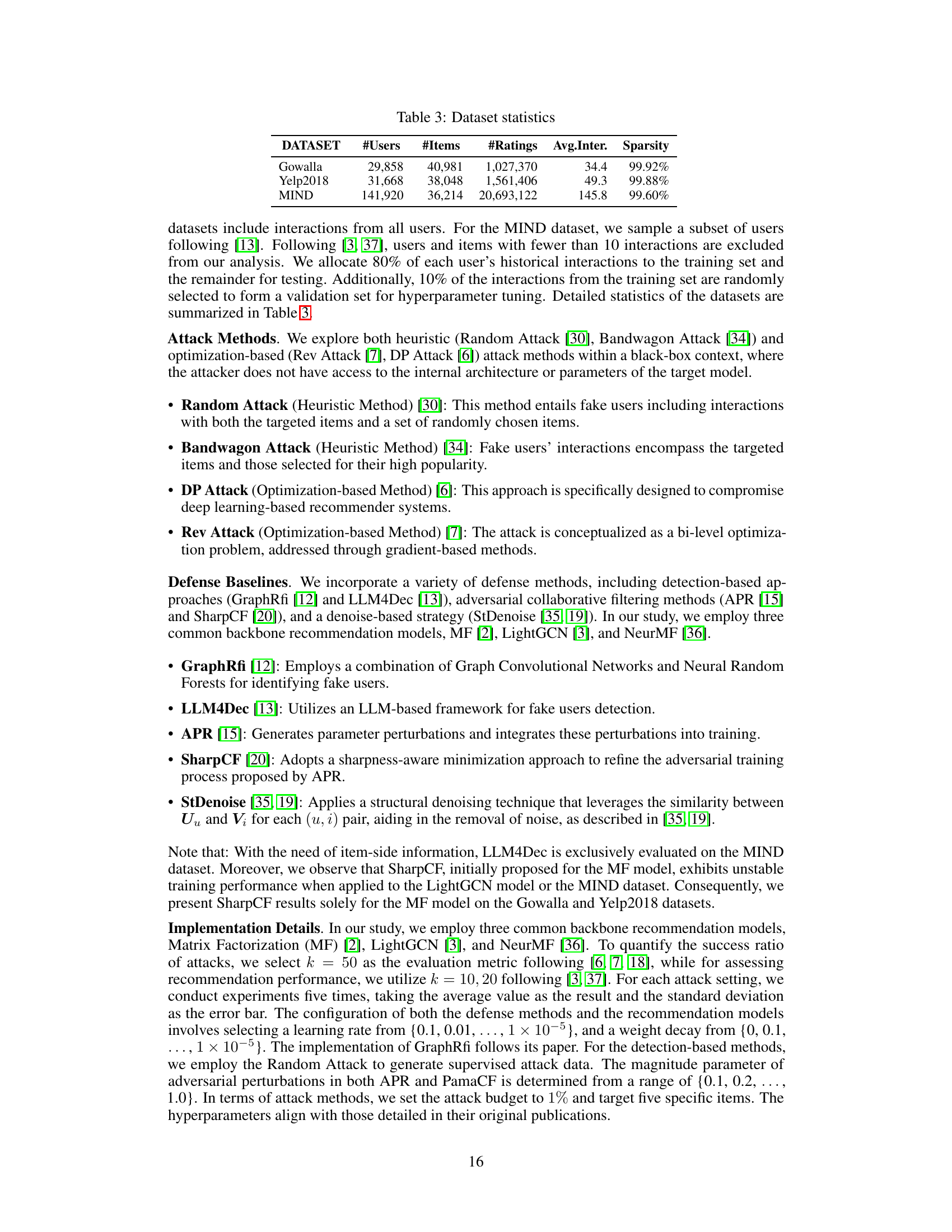
🔼 This table presents the results of evaluating the robustness of different defense methods against poisoning attacks that aim to promote specific target items. It shows the Target Item Hit Ratio (T-HR@50) and Target Normalized Discounted Cumulative Gain (T-NDCG@50) for various attack methods (Random, Bandwagon, DP, Rev) across three datasets (Gowalla, Yelp2018, MIND). Lower scores indicate better defense performance, meaning the attacks were less successful in promoting the target items.
read the caption
Table 2: Robustness against target items promotion

🔼 This table presents the recommendation performance (Recall@20 and NDCG@20) of different methods on three datasets (Gowalla, Yelp2018, MIND) under various attack scenarios (clean data, Random Attack, Bandwagon Attack, DP Attack, Rev Attack). It shows the performance gain of PamaCF compared to traditional CF and other defense baselines, highlighting its effectiveness in improving recommendation quality both in clean and poisoned data contexts.
read the caption
Table 1: Recommendation Performance

🔼 This table presents the results of evaluating the robustness of different defense methods against various poisoning attacks, specifically focusing on attacks aimed at promoting target items. The metrics used are T-HR@50 and T-NDCG@50, which measure the success rate of attacks in the top 50 recommendations. The table shows that PamaCF significantly outperforms other defense methods in terms of reducing the success rate of attacks.
read the caption
Table 2: Robustness against target items promotion

🔼 This table presents the performance of different recommendation models under various attack scenarios. The ‘Clean’ column shows performance on clean data, while the other columns show performance when different poisoning attacks (Random, Bandwagon, DP, Rev) are applied. The models tested include Matrix Factorization (MF) and its enhanced versions using StDenoise, GraphRfi, APR, SharpCF, and the proposed PamaCF. The table reports Recall@20 and NDCG@20, which are common metrics for evaluating recommendation quality. The ‘Gain’ column shows the percentage improvement of each model over the baseline (MF), and the ‘Gain w.r.t. MF’ column indicates the gain compared to the basic MF model. The table helps illustrate how different defense mechanisms affect the robustness and accuracy of recommendation systems in the presence of poisoning attacks.
read the caption
Table 1: Recommendation Performance

🔼 This table presents the recommendation performance (Recall@20 and NDCG@20) of different models on three datasets (Gowalla, Yelp2018, and MIND) under various attack scenarios (clean data, Random Attack, Bandwagon Attack, DP Attack, and Rev Attack). It compares the performance of the proposed PamaCF model with several baseline models such as Matrix Factorization (MF), StDenoise, GraphRfi, APR, and SharpCF. The ‘Gain’ column shows the performance improvement of each model compared to the MF baseline, while ‘Gain w.r.t. MF’ presents the percentage increase in performance relative to MF. The table highlights PamaCF’s superior performance and robustness compared to the baseline models across different attack scenarios.
read the caption
Table 1: Recommendation Performance
Full paper#