↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Point cloud analysis is crucial for various applications but faces challenges due to the high computational cost of existing Transformer-based methods, especially when dealing with large datasets. These Transformer-based models rely on the attention mechanism, which has quadratic complexity. This quadratic scaling limits their applicability to resource-constrained environments and large-scale datasets.
This research introduces PointMamba, a novel state-space model that addresses the limitations of Transformer-based methods. PointMamba employs a linear complexity algorithm, making it significantly more efficient than quadratic methods. The model leverages space-filling curves for efficient point tokenization and a simple, non-hierarchical Mamba encoder. Experimental results demonstrate superior performance across several datasets, with significant reductions in GPU memory usage and FLOPs. This makes PointMamba a promising alternative to current methods.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to point cloud analysis that significantly improves performance while reducing computational costs. It bridges the gap between traditional Transformer models and state space models, offering a new perspective that could benefit various computer vision applications. The linear complexity of its method is highly beneficial, enabling applications on resource-constrained devices. This opens avenues for research into efficient 3D data processing and linear complexity models.
Visual Insights#
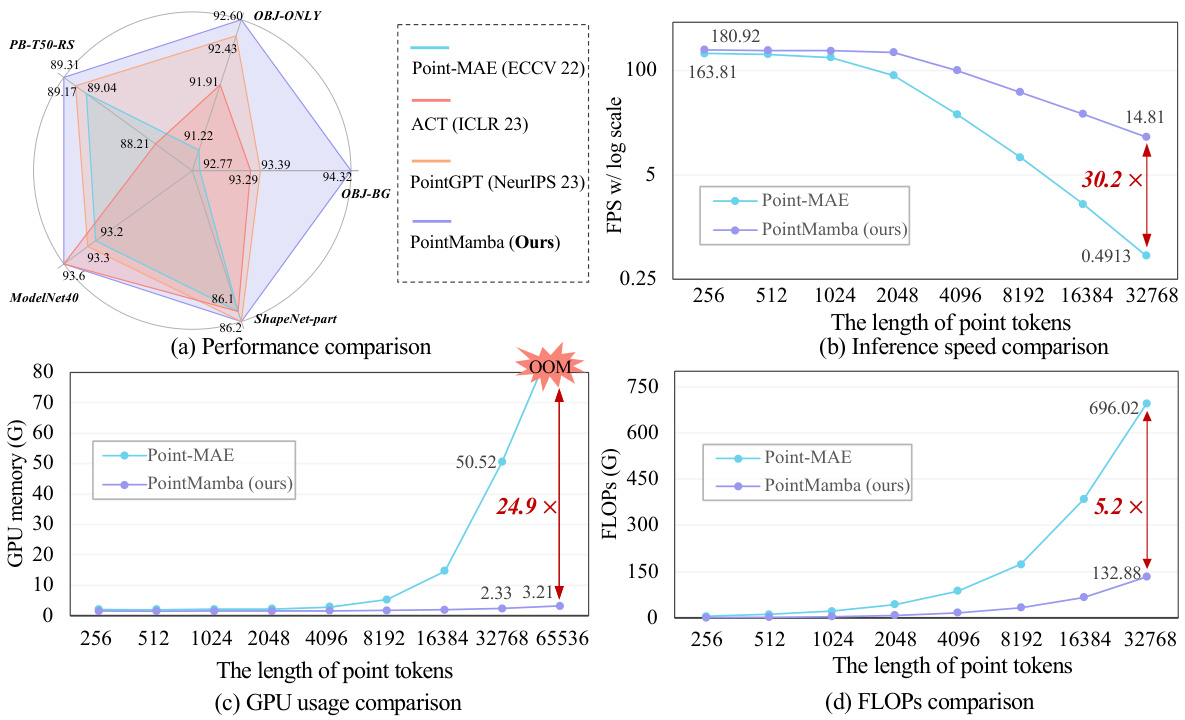
This figure presents a comprehensive comparison of PointMamba against several state-of-the-art Transformer-based methods for point cloud analysis. Subfigure (a) shows the superior performance of PointMamba across different datasets, while subfigures (b), (c), and (d) illustrate its linear time complexity compared to the quadratic complexity of Transformer-based methods. This is shown through significantly reduced GPU memory usage, FLOPs, and faster inference speed as the length of point tokens increases.
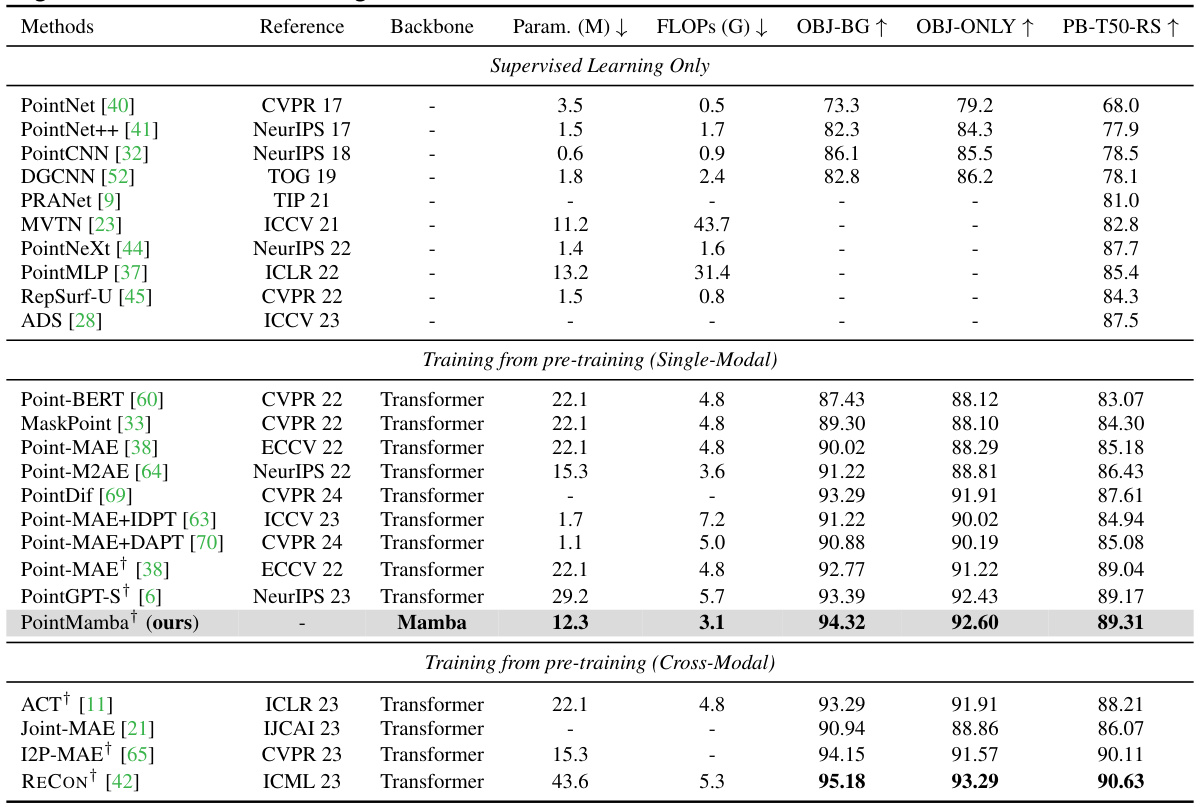
This table presents a comparison of various point cloud analysis methods on the ScanObjectNN dataset. The methods are categorized into those using only supervised learning, those trained from a single-modal pre-training approach, and those trained from a cross-modal pre-training approach. The table shows the model’s backbone architecture, the number of parameters, the number of GFLOPs, and the overall accuracy on three different versions of the ScanObjectNN dataset with increasing complexity (OBJ-BG, OBJ-ONLY, PB-T50-RS). The table highlights the superior performance of PointMamba, especially in the more challenging PB-T50-RS setting.
In-depth insights#
Mamba’s Linearity#
The core innovation of PointMamba hinges on leveraging the inherent linearity of the Mamba model. Unlike Transformers, which suffer from quadratic complexity due to self-attention, Mamba’s recursive state-space structure processes sequential data with linear time complexity. This crucial difference allows PointMamba to efficiently handle long point sequences typical in point cloud datasets, a significant advantage over Transformer-based methods that experience computational bottlenecks with increasing data size. The paper doesn’t explicitly detail Mamba’s internal workings but highlights its linear nature as a key differentiator enabling efficient global modeling. This linear complexity directly translates to faster inference speeds and reduced memory consumption, as demonstrated by the experimental results comparing PointMamba with its Transformer counterparts. The effectiveness of this linear processing is especially evident when dealing with larger point clouds, making PointMamba particularly well-suited for resource-constrained applications or real-time processing scenarios where Transformer-based models might falter.
Point Tokenization#
Effective point tokenization is crucial for successful point cloud analysis. The choice of method significantly impacts downstream performance. Space-filling curves, such as Hilbert and Trans-Hilbert curves, offer a compelling approach by transforming unstructured 3D point clouds into ordered sequences while preserving spatial locality. This structured representation is key, enabling efficient processing by models like the Mamba encoder. The selection of key points before tokenization, often via farthest point sampling (FPS), also influences the quality of the resulting tokens. Furthermore, the method used to generate tokens from the sampled points, such as a lightweight PointNet, impacts feature extraction. The authors’ use of dual scanning strategies (Hilbert and Trans-Hilbert) is a notable innovation, providing diverse and complementary perspectives that enhance global modeling. In essence, a robust point tokenization strategy carefully balances the need for efficient representation with the retention of important spatial relationships within the point cloud data.
Mask Modeling#
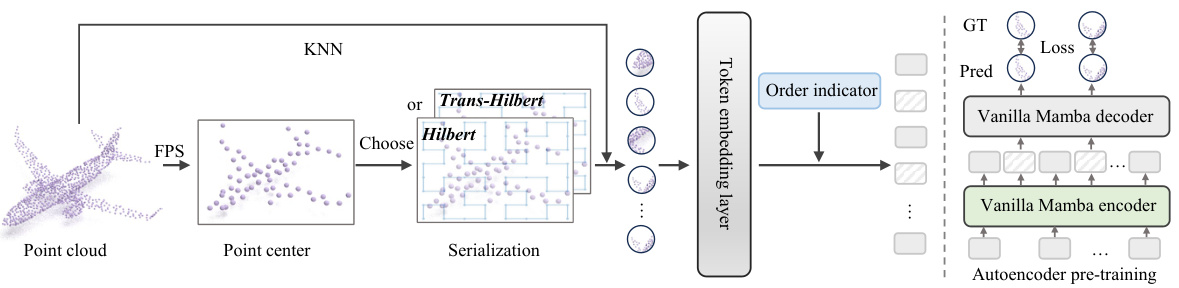
Mask modeling, a self-supervised learning technique, plays a crucial role in training deep learning models, especially in computer vision tasks dealing with point cloud data. By randomly masking or occluding portions of the input point cloud, the model is challenged to reconstruct the missing parts, thereby learning robust and discriminative features. This approach is particularly valuable in scenarios with limited labeled data, making it a powerful technique for pre-training models before fine-tuning on downstream tasks. The effectiveness of mask modeling hinges on the strategy for masking points. A well-designed approach ensures that the masked regions are representative of the data’s complexity, promoting more effective feature learning. The choice of mask ratio and the underlying strategy used for masking (e.g., random, block-wise, or structured) significantly impact the model’s performance. Furthermore, combining mask modeling with other self-supervised learning strategies can further enhance the model’s learning capabilities. Ultimately, the success of mask modeling depends on a thoughtful and careful design tailored to the specific characteristics of the data and model architecture, to strike a balance between challenge and feasibility, ensuring effective feature learning without making the task too difficult to solve. The effectiveness of this technique in point cloud analysis is further enhanced by incorporating space-filling curves, which helps in preserving spatial relationships during the masking process.
Ablation Studies#
Ablation studies systematically remove components of a model to understand their individual contributions. In the context of a research paper, this involves progressively disabling or altering aspects (e.g., specific modules, hyperparameters, or data augmentation techniques) to gauge the impact on the overall performance. A well-designed ablation study provides strong evidence for the necessity and efficacy of each component. It helps to isolate the effects of individual parts, ruling out alternative explanations for observed results and bolstering confidence in the proposed model’s architecture and design choices. Careful selection of what to ablate is crucial. Researchers should focus on key aspects that are hypothesized to be impactful, rather than conducting exhaustive tests on every minor detail. The results of ablation studies are typically presented in a table or graph, clearly showing performance metrics (e.g., accuracy, F1-score) with and without each ablated element. A strong ablation study will demonstrate a clear performance degradation when key components are removed, further supporting the model’s claims and revealing valuable insights into the model’s inner workings. Finally, it’s important to carefully interpret the results, acknowledging limitations and potential confounding factors. Well-conducted ablation studies provide robust evidence for design choices and strengthen the overall credibility and impact of a research paper.
Future of SSMs#
The future of State Space Models (SSMs) in point cloud analysis appears bright, given their demonstrated ability to achieve linear complexity while maintaining strong global modeling capabilities, unlike quadratic-complexity Transformers. PointMamba, showcasing a successful application of SSMs to 3D point clouds, highlights their potential for efficient processing of large-scale datasets and resource-constrained environments. Further research might explore hybrid approaches that combine the strengths of SSMs and Transformers, leveraging SSMs for efficient local feature extraction and Transformers for long-range dependencies. Another avenue is enhancing SSMs with attention mechanisms to directly address specific relational aspects within the data. A key challenge lies in effectively handling the unstructured nature of point clouds, requiring advanced techniques for tokenization and spatial encoding. The development of more sophisticated SSM architectures and training paradigms will be crucial for unlocking the full potential of SSMs in complex 3D vision tasks.
More visual insights#
More on figures
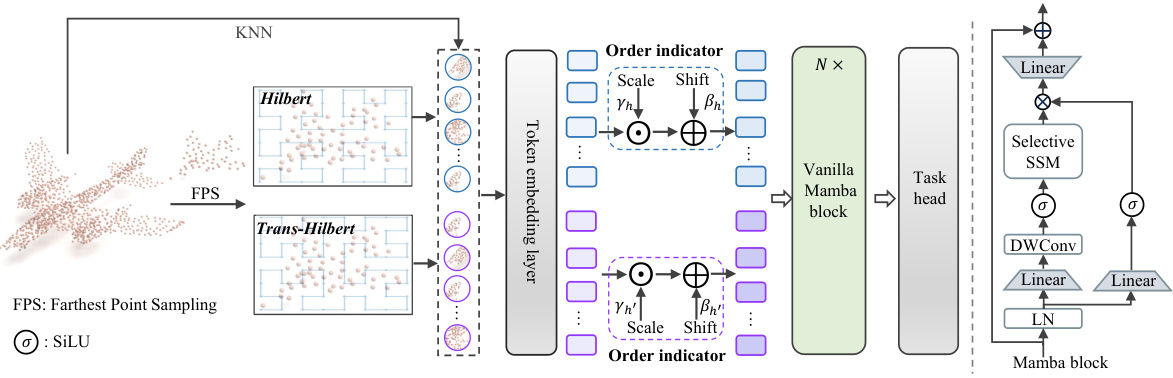
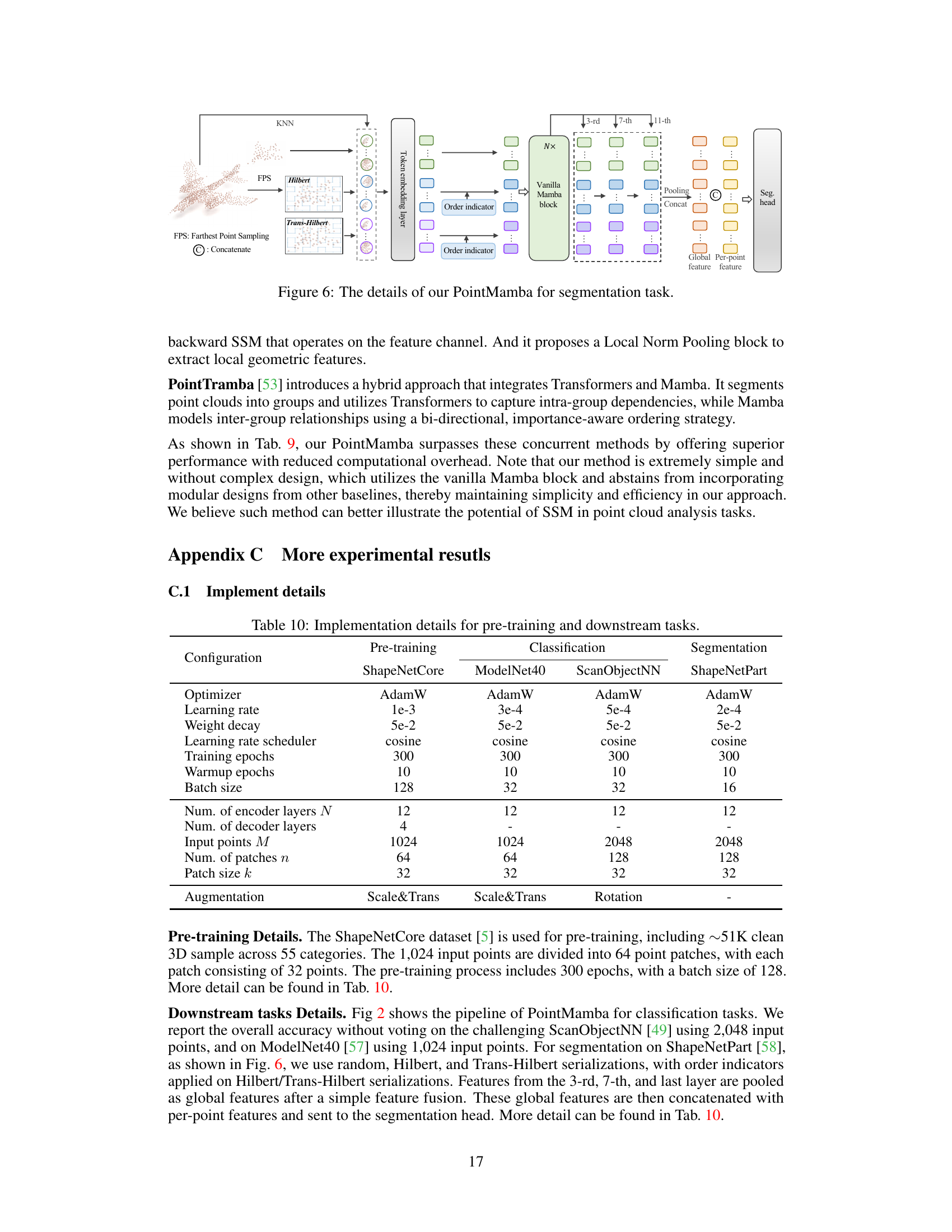
The figure illustrates the architecture of PointMamba, a novel point cloud analysis method. It starts with farthest point sampling (FPS) to select key points and uses Hilbert and Trans-Hilbert curves to serialize these points, maintaining spatial locality. KNN forms point patches, which are then converted to tokens using a token embedding layer. An order indicator distinguishes tokens from different scanning curves. The encoder is a series of plain Mamba blocks.
This figure illustrates the architecture of PointMamba, a simple and efficient point cloud analysis model. It begins by using Farthest Point Sampling (FPS) to select key points from the input point cloud. These key points are then processed using two space-filling curves (Hilbert and Trans-Hilbert) to create serialized sequences. A k-Nearest Neighbors (KNN) algorithm groups nearby points into patches, which are fed into a token embedding layer. An order indicator is added to distinguish between the two space-filling curve sequences. Finally, a series of plain, non-hierarchical Mamba blocks process these tokens to extract features.

This figure illustrates how PointMamba achieves global modeling. The left side shows the processing of point tokens serialized using a Hilbert curve. The right side shows processing of tokens serialized using a Trans-Hilbert curve. The dashed boxes represent the individual processing sequences. The key point is the arrow between the two sequences, indicating that the global information learned from the Hilbert sequence informs the processing of the Trans-Hilbert sequence, resulting in a model that leverages global context from different scanning perspectives.

This figure shows an ablation study on the PointMamba architecture. It compares four variants: (a) a baseline without the selective state space model (SSM); (b) replacing the SSM with a self-attention mechanism; (c) replacing the SSM with a multi-layer perceptron (MLP); and (d) the proposed PointMamba architecture with the selective SSM. The figure visually represents the different components and their connections within the architecture, highlighting the impact of the SSM on PointMamba’s performance.

The figure illustrates the PointMamba architecture. It starts with an input point cloud that undergoes farthest point sampling (FPS) to select key points. These points are then processed using Hilbert and Trans-Hilbert space-filling curves to create serialized sequences. A k-nearest neighbor (KNN) algorithm groups nearby points into patches, which are converted into tokens by a token embedding layer. An order indicator distinguishes tokens from the different space-filling curves. These tokens are then fed into a series of Mamba blocks (the encoder) to extract features before being passed to the task head.

This figure shows the qualitative results of the mask prediction task on the ShapeNet validation set, comparing the input point cloud, the masked point cloud (where a portion of the points have been removed), and the reconstructed point cloud generated by PointMamba. The results demonstrate PointMamba’s ability to effectively reconstruct the missing points, indicating its effectiveness in handling missing data in point cloud analysis.

This figure shows a qualitative comparison of the part segmentation results obtained using the proposed PointMamba model against the ground truth labels. The top row displays the ground truth segmentations for several point cloud objects from the ShapeNetPart dataset, with different parts of the object colored in different colors (e.g., red, green, blue). The bottom row displays the corresponding segmentations predicted by PointMamba. The figure visually demonstrates the model’s ability to accurately segment different parts of the objects.
More on tables
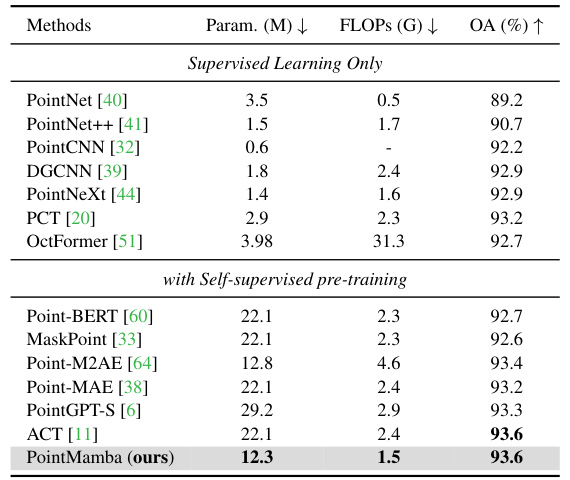
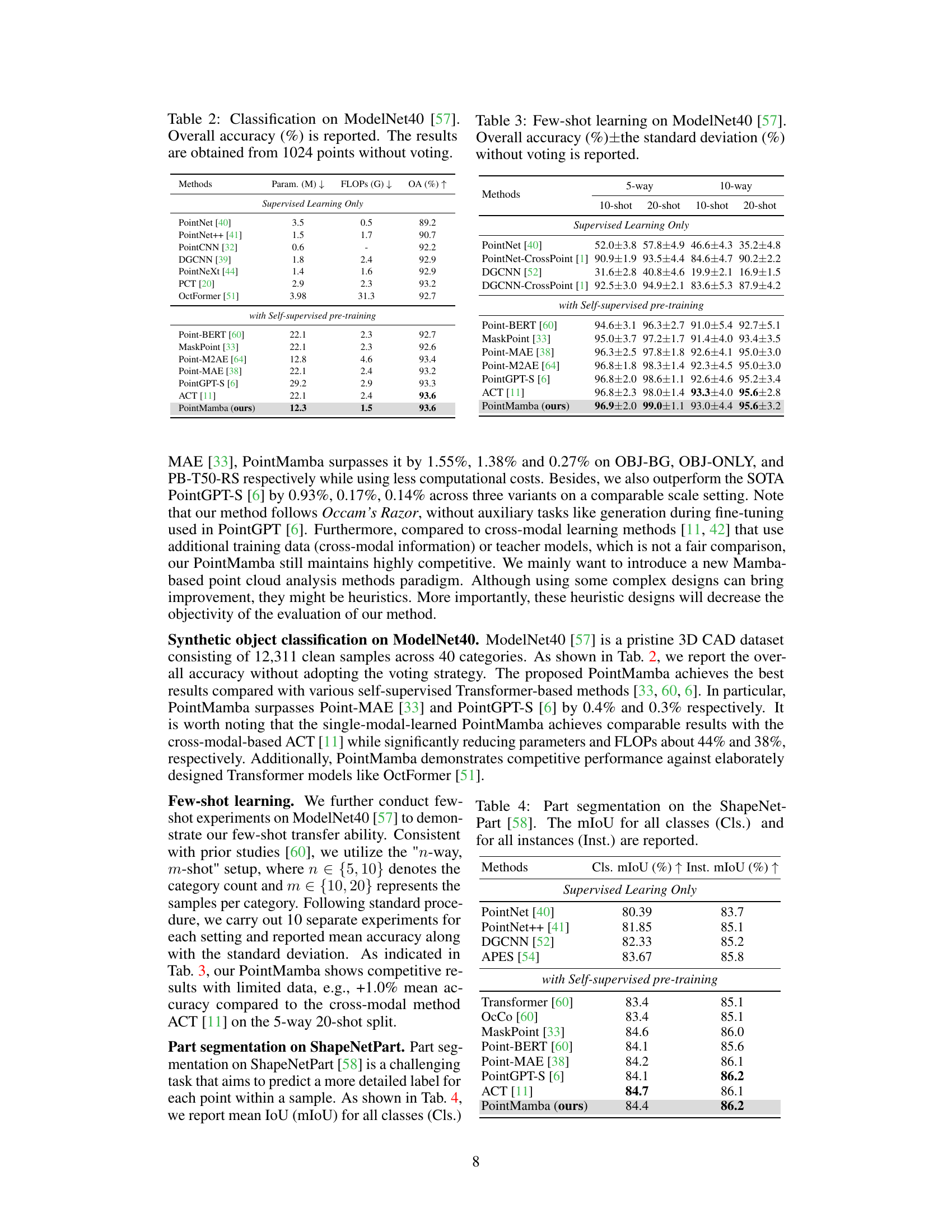
This table presents a comparison of different methods for object classification on the ModelNet40 dataset. The dataset consists of 12,311 CAD models of 40 different object categories. The table shows the overall accuracy achieved by each method, using 1024 points as input and without the use of voting (a common technique to improve accuracy). The results help to benchmark the performance of PointMamba against existing state-of-the-art techniques.

This table presents the results of a few-shot learning experiment on the ModelNet40 dataset. It compares the performance of various methods (both supervised learning only and those with self-supervised pre-training) across different few-shot learning settings (5-way and 10-way, 10-shot and 20-shot). The accuracy and standard deviation are reported for each setting.
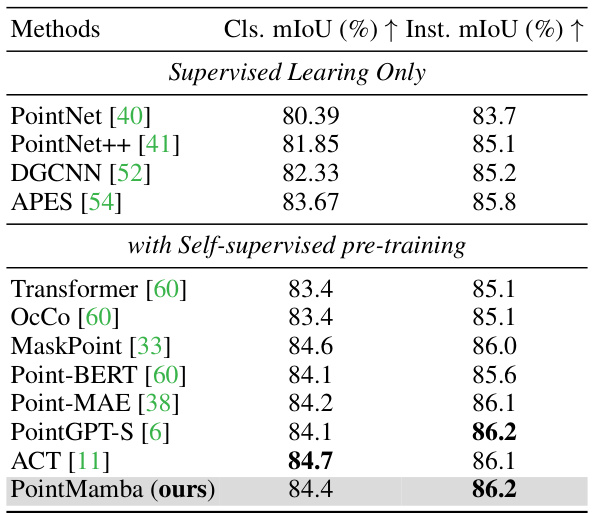
This table presents the performance comparison of different methods on the ShapeNetPart dataset for part segmentation task. The metrics used are mean Intersection over Union (mIoU) for both classes (Cls.) and instances (Inst.). It compares the performance of PointMamba against other methods including supervised learning methods only and methods with self-supervised pre-training.

This table presents the results of an ablation study on the impact of different scanning curves (Hilbert, Trans-Hilbert, Z-order, and Trans-Z-order) on the performance of the PointMamba model. It shows the overall accuracy (%) on the OBJ-BG and OBJ-ONLY subsets of the ScanObjectNN dataset [49], comparing using these different curves alone and in combination. The results demonstrate the impact of the scanning strategy on the model’s ability to capture spatial information in point clouds.
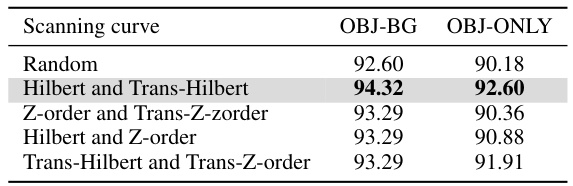
This table presents the results of experiments comparing different combinations of space-filling curves (Hilbert, Trans-Hilbert, Z-order, Trans-Z-order) used for scanning point clouds. The table shows the overall accuracy achieved on the OBJ-BG and OBJ-ONLY subsets of the ScanObjectNN dataset [49]. The results demonstrate that using both Hilbert and Trans-Hilbert curves yields the best performance.
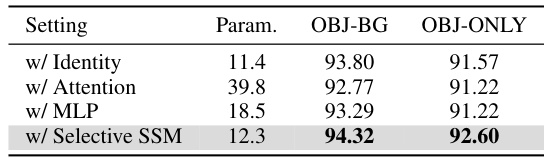
This table presents the ablation study results on the effect of each component in the PointMamba model. The results are evaluated on the ScanObjectNN dataset, measuring performance on ‘OBJ-BG’ and ‘OBJ-ONLY’ metrics. The table compares four variations of the PointMamba architecture, each removing or replacing a different component (Identity, Attention, MLP, Selective SSM) and shows the resulting parameter count and accuracy. It highlights the impact of the Selective SSM, the core of the Mamba architecture, on the overall model performance.

This table presents a comparison of the performance of PointMamba and other state-of-the-art methods on the ScanObjectNN object classification dataset. The results are broken down into three variants of increasing difficulty: OBJ-BG, OBJ-ONLY, and PB-T50-RS. For each method, the table shows the overall accuracy, the number of parameters, and the number of GFLOPs. The table highlights that PointMamba achieves superior performance on all three variants while using fewer parameters and GFLOPs than the most comparable state-of-the-art methods.

This table presents a comparison of different methods for object classification on the ScanObjectNN dataset. The methods are evaluated on three variants of the dataset (OBJ-BG, OBJ-ONLY, and PB-T50-RS), with PB-T50-RS being the most challenging. The table shows the overall accuracy of each method, the number of parameters, and the number of floating point operations (FLOPs). The PointMamba method is highlighted, showing its performance relative to other approaches.

This table presents a comparison of various methods for object classification on the ScanObjectNN dataset. It shows the performance (overall accuracy) of different methods, including PointMamba (the proposed method), and several state-of-the-art Transformer-based methods. The table also includes the number of parameters and FLOPs (floating point operations) for each method to give a sense of their computational complexity. The dataset is split into three variants (OBJ-BG, OBJ-ONLY, and PB-T50-RS), with PB-T50-RS representing the most challenging variant. A † symbol indicates when simple rotational augmentation was used during training.

The table compares the performance of PointMamba with other state-of-the-art methods on the ScanObjectNN dataset for object classification. It shows the overall accuracy, the number of parameters, and the number of floating point operations (FLOPs) for each method. Three variations of the dataset are used, with PB-T50-RS representing the most difficult scenario. The table also indicates whether the models were trained with simple rotational augmentation.

This table presents a comparison of various methods for object classification on the ScanObjectNN dataset, a challenging benchmark with three variants (OBJ-BG, OBJ-ONLY, PB-T50-RS) of increasing complexity. The table shows the overall accuracy achieved by each method, the number of parameters, and the number of GFLOPs. PointMamba is shown to have the best performance on all three variants.
Full paper#