TL;DR#
Drag-based image editing, while intuitive, suffers from limitations like producing deterministic results and neglecting image quality. Existing “how-to-drag” approaches overlook the ill-posed nature of the problem, where multiple valid edits are possible. They often prioritize edit accuracy over overall image quality, leading to unsatisfactory results.
LucidDrag innovatively shifts the paradigm to “what-then-how.” It employs an intention reasoner to understand the user’s intent before deciding the “how.” This reasoner leverages a Large Language-Vision Model (LVLM) to identify the editable region and a Large Language Model (LLM) to determine the semantic direction of the edit. A collaborative guidance mechanism ensures high-fidelity results by combining editing guidance with semantic and quality guidance.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the limitations of existing drag-based image editing methods by introducing a novel “what-then-how” paradigm. LucidDrag significantly improves editing accuracy, image fidelity, and semantic diversity, opening new avenues for research in image manipulation and AI-assisted creative tools. It’s relevant to current trends in diffusion models and large language models, demonstrating the power of combining these techniques for advanced image editing.
Visual Insights#

🔼 This figure demonstrates the capabilities of LucidDrag in handling drag-based image editing. The top row shows diverse results generated from the same input image and user-defined drag points, highlighting LucidDrag’s ability to handle the ill-posed nature of this task (multiple valid results). The bottom row showcases LucidDrag’s strong performance in terms of both accuracy (how closely the editing matches the user’s intent) and image fidelity (preserving the quality and realism of the image).
read the caption
Figure 1: Given an input image, the user draws a mask specifying the editable region and clicks dragging points (handle points (red) and target points (blue)). Our LucidDrag considers the ill-posed nature of drag-based editing and can produce diverse results (the first row). Besides, it achieves outstanding performance in editing accuracy and image fidelity (the second row).

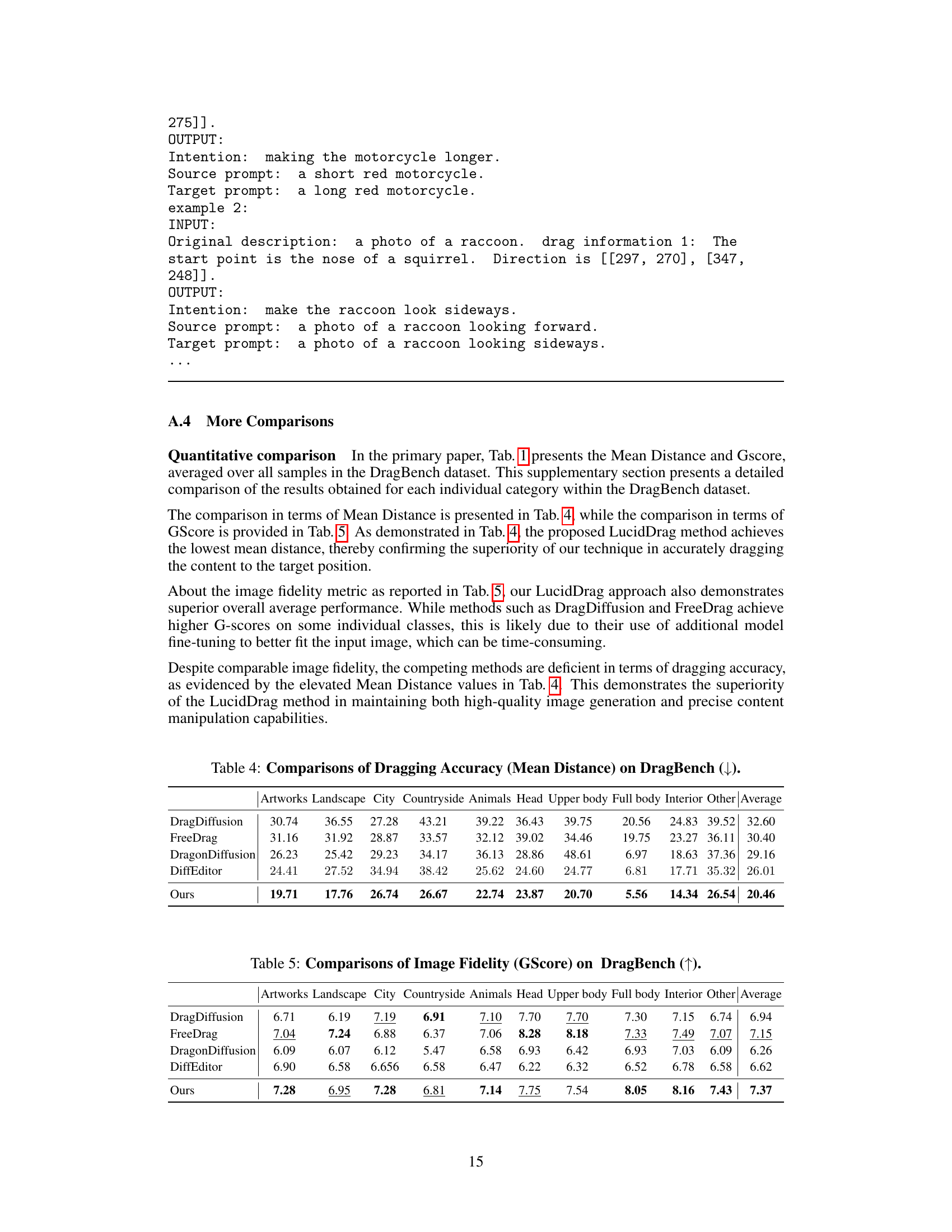
🔼 This table presents a quantitative comparison of different drag-based image editing methods on the DragBench benchmark dataset. It shows the Mean Distance and GScore for each method. Mean Distance measures the average distance between the dragged content and the target location, indicating the accuracy of the dragging process (lower is better). GScore is a human-aligned image quality assessment metric (higher is better). The results demonstrate the superior performance of LucidDrag in both dragging accuracy and image quality compared to other state-of-the-art methods.
read the caption
Table 1: Comparisons of content dragging on DragBench.
In-depth insights#
Semantic Drag Editing#
Semantic drag editing represents a significant advancement in image manipulation, moving beyond simple pixel-based adjustments. It focuses on understanding the user’s intent and performing edits based on semantic meaning rather than just point-to-point movements. This involves sophisticated algorithms that can interpret user input (e.g., drag gestures) in the context of the image content. The core challenge lies in accurately translating abstract intentions into precise image modifications, which necessitates a deep understanding of both image semantics and the underlying generative model. Effective methods require robust semantic segmentation to identify relevant image regions and advanced generative models capable of realistically altering those regions based on the inferred intent. A key benefit is the ability to achieve more natural and intuitive edits, reducing the need for precise control and increasing accessibility for non-expert users. However, the ill-posed nature of semantic drag editing, where multiple valid interpretations of a single drag gesture exist, poses a considerable hurdle. Future research will likely focus on improving the robustness and accuracy of semantic understanding, exploring alternative user input methods, and enhancing the diversity of generated outputs to fully address this promising but complex area of image editing.
Intention Reasoner#
The “Intention Reasoner” module is a crucial component, bridging the gap between user interactions (drag points) and the desired semantic changes in an image. It cleverly decomposes the complex task of drag-based editing into two key steps: identifying what to edit, and then determining how to achieve the desired changes. This two-step approach addresses the inherent ambiguity in drag-based editing, where a single drag gesture could correspond to various semantic intentions. By employing both a Large Vision-Language Model (LVLM) and a Large Language Model (LLM), the Intention Reasoner intelligently infers multiple possible semantic intentions based on the image content, caption and drag points. This is a significant departure from previous methods that focus solely on the ‘how’ aspect, neglecting the inherent ambiguity of the ‘what’. The system’s capacity to output multiple intentions with associated confidence scores allows for diversity in generated results while prioritizing the most reasonable option. This framework enhances the system’s semantic understanding and capacity for precise editing, yielding better results compared to prior methods that lack such semantic awareness.
Collaborative Guidance#
The concept of “Collaborative Guidance” in the context of image editing, as described in the research paper, represents a significant advancement. It moves beyond simply instructing a model on how to perform an edit, towards a more sophisticated approach of intention reasoning and multifaceted guidance. The system infers user intent via a combination of Large Language and Vision Models (LLM/LVLM), translating the user’s drag actions and image metadata into high-level semantic intentions. This understanding is critical; it enables the generation of diverse editing outcomes corresponding to the potential interpretations of the user’s actions. Rather than producing a single deterministic result, it generates multiple editing strategies that better align with the ambiguous nature of drag-based editing. The core of this collaborative approach lies in the simultaneous integration of semantic guidance (directing the change based on inferred user intentions), quality guidance (maintaining image fidelity via a discriminator), and editing guidance (precisely manipulating pixels based on traditional techniques). This fusion of approaches addresses limitations in previous methods, improving the semantic accuracy and image quality of the final results, offering a more robust and intuitive user experience. The inherent ill-posed nature of drag-based editing is acknowledged and addressed through the generation of multiple plausible outcomes, showcasing the power of this collaborative strategy.
Quality & Diversity#
A robust image editing system must produce high-quality results while offering diverse options. Quality in this context refers to the fidelity of the output image—the extent to which it maintains the integrity of the original while incorporating edits. This involves minimizing artifacts, preserving fine details, and ensuring that edits are seamlessly integrated. Achieving high quality requires careful attention to both the editing algorithm and the model’s ability to understand and preserve image structures. Diversity, on the other hand, concerns the system’s capacity to produce multiple valid solutions for a single editing task. This is particularly important when dealing with ambiguous requests, where the user’s intention might be open to multiple interpretations. A system that balances quality and diversity offers the user greater control and flexibility, allowing them to explore a wider range of creative possibilities while maintaining a high standard of visual output. The key lies in finding methods that allow users to specify their intent clearly, but also allow the algorithm to provide creative solutions within the bounds of the user’s intent and image integrity.
Future of DragGAN#
The “Future of DragGAN” suggests exciting avenues for advancement. Improved semantic understanding is crucial; current methods often struggle with nuanced user intentions, leading to inaccurate or unexpected edits. Enhanced control and precision are also needed. While DragGAN allows for impressive manipulations, finer-grained control over the editing process would significantly improve usability and creative potential. This could involve incorporating more sophisticated input mechanisms, such as incorporating 3D models or incorporating additional modalities like audio to guide the edits. Furthermore, exploring diverse application domains is key. DragGAN’s capabilities extend beyond image editing, with potential uses in animation, video production, and even 3D modeling. Addressing ethical considerations is also paramount. The power of DragGAN raises concerns about misuse, such as generating deepfakes or otherwise manipulating media for malicious purposes. Therefore, future research must incorporate safeguards and responsible practices to mitigate potential harm. Ultimately, the future of DragGAN likely rests on a combination of improved technical capabilities, expanded application areas, and a strong ethical framework.
More visual insights#
More on figures

🔼 LucidDrag’s architecture is composed of two main parts: an intention reasoner and a collaborative guidance sampling mechanism. The intention reasoner uses an LVLM and an LLM to identify potential semantic intentions from user input (image, caption, and drag points). The collaborative guidance sampling mechanism combines editing, semantic, and quality guidance to produce semantically-aware and high-quality image edits. The figure visually represents the information flow between these components and the editing process.
read the caption
Figure 2: Overview of LucidDrag. LucidDrag comprises two main components: an intention reasoner and a collaborative guidance sampling mechanism. Intention Reasoner leverages an LVLM and an LLM to reason N possible semantic intentions. Collaborative Guidance Sampling facilitates semantic-aware editing by collaborating editing guidance with semantic guidance and quality guidance.

🔼 This figure demonstrates the ability of LucidDrag to generate diverse results that align with the user’s intentions, even when those intentions are ambiguous. Multiple examples are shown, each beginning with a source image and a user-specified editing task (indicated by drag points and text prompts). The results showcase the variety of outputs generated by LucidDrag for the same input, highlighting the model’s ability to handle the ill-posed nature of drag-based editing.
read the caption
Figure 3: LucidDrag allows generating diverse results conforming to the intention.

🔼 This figure showcases the diversity and semantic awareness of LucidDrag. Given various input images and user-specified drag points, LucidDrag generates multiple diverse results, each adhering to the implied semantic intent. It highlights the model’s ability to interpret the user’s intention and produce results that accurately reflect that intention, even when multiple valid interpretations exist. The images demonstrate differences in how animals and objects are modified based on subtle changes in the dragging points and the source/target prompts determined by the intention reasoner.
read the caption
Figure 3: LucidDrag allows generating diverse results conforming to the intention.

🔼 This figure shows a qualitative comparison of object-moving results between LucidDrag and other methods (DragDiffusion and DiffEditor). Each row presents a different image editing task where an object is moved from one location to another within the image using the various methods. The comparisons highlight LucidDrag’s superior performance in generating images with higher fidelity and more precisely placed objects, while the other methods may struggle with positional accuracy or introduce unwanted artifacts.
read the caption
Figure 4: Qualitative comparison between our LucidDrag and other methods in object moving.

🔼 This figure shows the ablation study results for LucidDrag, comparing the full model against versions without the intention reasoner and without quality guidance. The top row demonstrates the impact on a bicycle image, highlighting how the absence of these components leads to distortions and artifacts. The bottom row shows the effect on a spinning top image, illustrating the loss of detail and fidelity caused by removing quality guidance and the intention reasoner. The results show the importance of both components in achieving high-quality and semantically consistent image editing.
read the caption
Figure 5: Visualization of ablation study.

🔼 This figure shows several examples of diverse results generated by LucidDrag for different image editing tasks. Each row represents a single task, starting with a source image and a user-specified drag interaction (shown as blue and red points). LucidDrag then generates multiple possible output images, all consistent with the user’s intended semantic changes. The results demonstrate LucidDrag’s ability to handle the inherently ill-posed nature of drag-based editing, producing diverse and semantically meaningful outputs while maintaining image fidelity.
read the caption
Figure 3: LucidDrag allows generating diverse results conforming to the intention.

🔼 This figure shows several examples of diverse editing results generated by LucidDrag for different prompts. Each row presents a series of images resulting from applying different editing strategies to the same source image. This demonstrates LucidDrag’s ability to produce a variety of semantically coherent outputs for a single input, highlighting its capacity to handle the ill-posed nature of drag-based editing.
read the caption
Figure 7: LucidDrag allows generating diverse results.

🔼 This figure shows four different outputs from the LLM-driven reasoner module, each with a different confidence score. The input is a picture of a pineapple with drag points indicating a desired change in size. Output 1, with the highest confidence score, correctly interprets the intention and generates an image reflecting a change in size (shorter). Outputs 2, 3, and 4 have lower confidence scores and produce less accurate results, either failing to accurately change the size or interpreting the request incorrectly.
read the caption
Figure 8: Analysis of confidence probabilities. A higher confidence probability indicates that the intention of the output is more reasonable, leading to better editing results.

🔼 This figure visualizes the evolution of gradient maps during the drag-based editing process at different time steps. The top row shows gradient maps generated by the editing guidance (gedit), while the bottom row displays those from the quality guidance (gquality). The visualization demonstrates a gradual convergence as sampling progresses. The activation range of the gradient maps narrows, focusing progressively towards the editing areas.
read the caption
Figure 9: Visualization of the quality guidance and editing guidance.
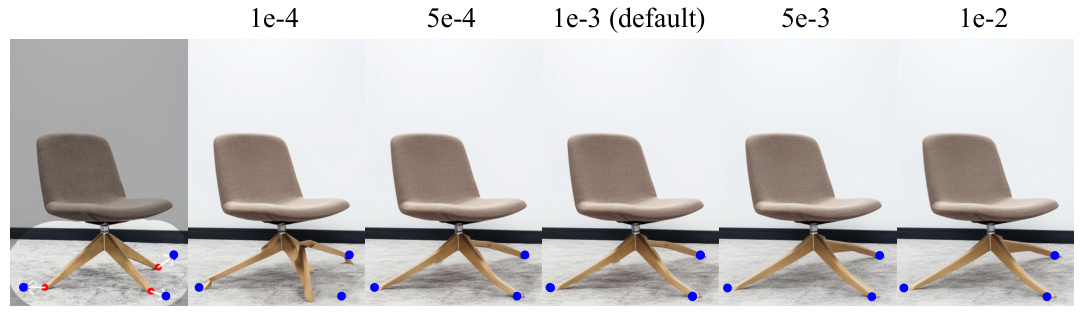
🔼 This figure shows the effect of changing the weight of the quality guidance (Wquality) on the image editing results. As Wquality increases, the importance of maintaining high image quality is emphasized. However, there is a trade-off; overly high weights can lead to overly constrained editing, potentially sacrificing the desired changes in the image. The default setting of 1e-3 is shown to provide a balance between quality and editing fidelity.
read the caption
Figure 10: Analysis of the quality guidance weight.

🔼 This figure shows several examples of diverse results generated by LucidDrag for different image editing tasks. Each example includes the source image, the user’s edits (including source and target prompts), and the results generated by LucidDrag. The results demonstrate the model’s ability to produce multiple plausible outcomes for a given input, highlighting its capacity for handling the inherent ambiguity in drag-based editing.
read the caption
Figure 3: LucidDrag allows generating diverse results conforming to the intention.
More on tables

🔼 This table presents a quantitative comparison of the object moving task, comparing the performance of LucidDrag against DragonDiffusion and DiffEditor. The metrics used are CLIP-score (higher is better, indicating better alignment between the edited image and the target description) and LMM-score (higher is better, representing a human-aligned assessment of overall image quality). LucidDrag shows improved performance across both metrics.
read the caption
Table 2: Comparisons of object moving.

🔼 This table presents the quantitative results of the ablation study conducted on the LucidDrag model. It compares the performance of the full implementation of LucidDrag with two ablated versions: one without the intention reasoner and another without the quality guidance. The metrics used for comparison are Mean Distance and GScore. Lower Mean Distance indicates better dragging precision, while a higher GScore indicates better image quality. The results show that both the intention reasoner and quality guidance contribute significantly to the overall performance of the model.
read the caption
Table 3: Quantitative result of ablation study.

🔼 This table presents a detailed comparison of the dragging accuracy of different methods across various categories in the DragBench dataset. The ‘Mean Distance’ metric is used to evaluate the accuracy of moving contents to target points. Lower values indicate better performance. The table includes results for different categories of images in the DragBench dataset, including Artworks, Landscape, City, Countryside, Animals, Head, Upper body, Full body, Interior, and Other. This allows for a comprehensive assessment of the methods’ performance across different image types and editing scenarios. The table shows that the proposed LucidDrag method achieves the lowest mean distance in almost every category.
read the caption
Table 4: Comparisons of Dragging Accuracy (Mean Distance) on DragBench (↓).

🔼 This table presents a detailed comparison of image quality using the GScore metric across different categories within the DragBench dataset. It compares the performance of LucidDrag against several other drag-based editing methods. Higher GScore indicates better perceived image quality. The results show that LucidDrag achieves a higher average GScore than other methods, demonstrating superior image fidelity in drag-based editing.
read the caption
Table 5: Comparisons of Image Fidelity (GScore) on DragBench (↑).

🔼 This table presents the results of experiments conducted to analyze the performance of different Large Vision-Language Models (LVLMs) and Large Language Models (LLMs) used in the Intention Reasoner module of the LucidDrag model. The models tested are Ferret and Osprey for LVLMs, and Vicuna, Llama 3, and GPT3.5 for LLMs. The table shows the Mean Distance and GScore for each combination of LVLMs and LLMs. The combination Osprey + GPT3.5 represents the default setting for the paper. It demonstrates that all combinations surpass the experiment without an Intention Reasoner, indicating the reliability and effectiveness of using both LVLMs and LLMs in this application.
read the caption
Table 6: Results with different LVLMs and LLMs

🔼 This table compares the inference time and memory usage of LucidDrag against four other drag-based image editing methods: DragDiffusion, FreeDrag, DragonDiffusion, and DiffEditor. The results show that LucidDrag has a relatively fast inference time and comparable memory requirements to the other methods.
read the caption
Table 7: Efficiency of different methods.
Full paper#