↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Long-tailed image recognition struggles with imbalanced datasets where some classes have far fewer examples than others, leading to biased models that perform poorly on under-represented classes. Conventional methods often rely on re-weighting, re-sampling, or incorporating external data, which may not always be feasible or desirable.
DiffuLT tackles this challenge by utilizing a novel diffusion model trained solely on the imbalanced dataset itself to create a balanced proxy dataset. It identifies and prioritizes the generation of ‘approximately-in-distribution’ (AID) samples which combine information from various classes, improving the generative model’s performance. The generated samples are then used to train a classifier, achieving state-of-the-art results on CIFAR and ImageNet benchmarks, demonstrating the efficacy of this data-centric approach to long-tailed recognition.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a novel approach to the long-tailed recognition problem, a persistent challenge in machine learning. It demonstrates that high-quality synthetic data, generated without external knowledge or data, can significantly improve model performance. This opens new avenues for research in generative models and long-tailed learning, particularly in situations where external data is scarce or inaccessible.
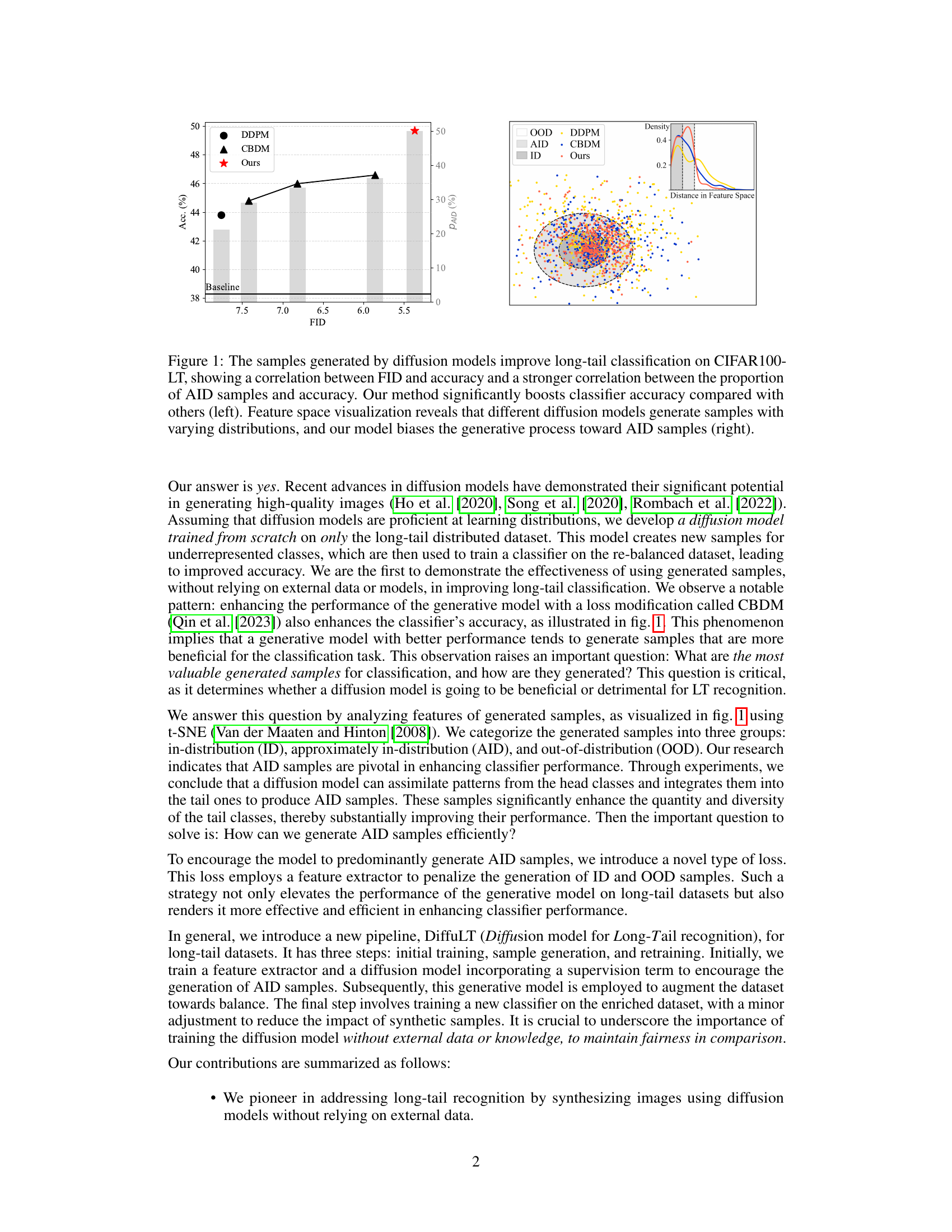
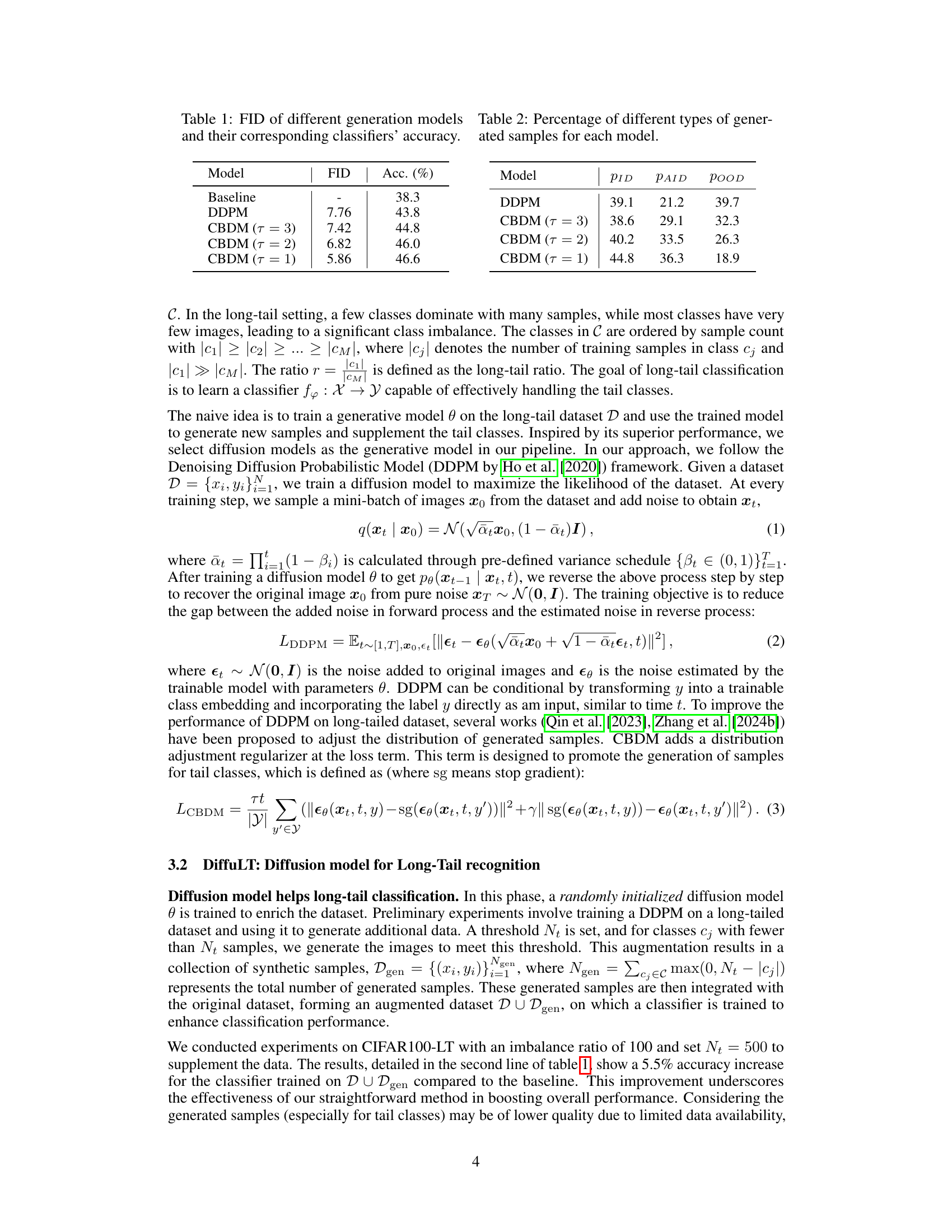
Visual Insights#
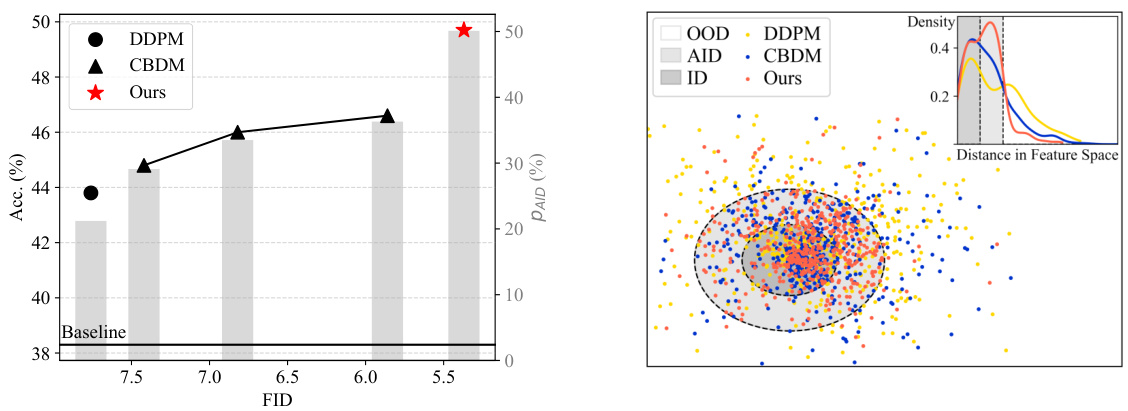
The figure shows two plots demonstrating the effectiveness of the proposed method (DiffuLT) in improving long-tail image classification. The left plot shows a strong correlation between the FID score (a measure of generated image quality) and classification accuracy, with DiffuLT achieving the highest accuracy at the lowest FID. The right plot is a feature space visualization showing how DiffuLT generates samples that are closer to ‘approximately in-distribution’ (AID) samples (samples slightly deviating from the real data distribution but containing blended class information) compared to other methods. AID samples are considered crucial for improving the classifier’s performance on long-tail data.
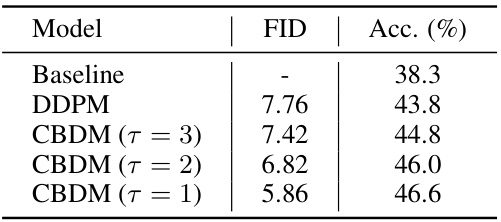
This table presents the Fréchet Inception Distance (FID) scores and the corresponding classification accuracy for different generative models. Lower FID scores indicate that the generated samples are more realistic and closer to the real data distribution. The models compared are a baseline (no generation), a standard Denoising Diffusion Probabilistic Model (DDPM), and variations of the Class-Balancing Diffusion Model (CBDM) with different hyperparameters (τ). The table shows that as the FID decreases (meaning better generation quality), the classification accuracy tends to increase.
In-depth insights#
DiffuLT: LT Recog#
DiffuLT, short for “Diffusion model for Long-Tail recognition,” presents a novel approach to long-tail recognition that significantly diverges from traditional methods. Instead of relying on external data or pre-trained models, it leverages the inherent characteristics of the long-tailed dataset itself to create a balanced proxy dataset. This is achieved by training a diffusion model from scratch, which generates new samples, particularly focusing on approximately in-distribution (AID) samples that bridge the gap between head and tail classes. The key innovation lies in guiding the generation process via a feature extractor to favor AID samples and filter out detrimental samples, thereby significantly improving classifier accuracy. The approach boasts state-of-the-art results on benchmark datasets (CIFAR10-LT, CIFAR100-LT, ImageNet-LT), demonstrating its effectiveness and generalizability, and suggesting a new paradigm for addressing long-tail image recognition challenges. The method’s strength lies in its self-contained nature—no external knowledge is required, making it robust and adaptable to real-world scenarios.
AID Sample Gen#
The concept of ‘AID Sample Gen,’ focusing on generating “Approximately-In-Distribution” samples, is a crucial innovation. AID samples, subtly different from the original data distribution, bridge the gap between head and tail classes, proving particularly valuable for improving the classification accuracy of long-tailed datasets. The method cleverly leverages a diffusion model, trained solely on the imbalanced data itself, without relying on external datasets or pre-trained models. This self-contained approach enhances its generalizability. A key aspect is the introduction of a novel loss function that guides the model towards generating AID samples by penalizing ID and OOD samples. The use of a feature extractor plays a pivotal role in this process, filtering out detrimental samples. This technique demonstrates the potential of generative models in addressing the challenges inherent in long-tailed recognition tasks. The overall approach enhances data diversity and balances class representation for improved classifier performance.
Loss Func Design#
The design of the loss function is crucial for the success of any machine learning model, and this is especially true for long-tail recognition. A standard loss function like cross-entropy can exacerbate the class imbalance problem, as it disproportionately penalizes errors on the majority classes. The authors propose novel loss functions to address this issue. They introduce a loss that incentivizes the generation of ‘approximately in-distribution’ (AID) samples by the diffusion model. These AID samples, while slightly deviating from the training data, bridge the gap between majority and minority classes, effectively balancing the dataset for improved classifier performance. The careful design of this loss is critical for guiding the diffusion model towards generating these helpful AID samples, rather than generating samples that are simply similar to the majority classes or completely out-of-distribution. The effectiveness of this approach is demonstrated through thorough ablation studies that highlight the contributions of each component of the loss function. By carefully balancing the generation of AID, ID, and OOD samples, the proposed loss function plays a pivotal role in improving the overall performance of the long-tail recognition system.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a machine learning model. For the DiffuLT model, this would involve removing or altering parts of the pipeline (e.g., the AID-biased loss, the filtering step, the use of CBDM) one at a time to observe the impact on overall performance. The results of this study would highlight the relative importance of each component, revealing which parts are crucial for the model’s success and which are less essential. By identifying the most critical components, researchers can gain a better understanding of the model’s internal workings, as well as potentially simplify the model by removing unnecessary complexities. Furthermore, the ablation study may expose unexpected interactions between different components. For example, removing the filtering step might unexpectedly improve performance if the generated OOD samples offer some benefit. These findings provide critical insights into the model’s design and its robustness. A well-conducted ablation study significantly enhances the interpretability of the DiffuLT model and provides concrete evidence supporting the choices made in the model’s architecture and training procedure.
Future Work#
The paper’s omission of a dedicated ‘Future Work’ section is notable. However, the concluding paragraph hints at several potential avenues. Improving the efficiency of the diffusion model training and sample generation processes is paramount, as current timescales are considerable. This could involve exploring more efficient diffusion model architectures, optimized training strategies (e.g., incorporating techniques like mixed-precision training), or leveraging pre-trained models in a transfer learning paradigm. Investigating the use of pre-trained diffusion models on long-tailed datasets they haven’t seen before, ensuring fairness, is another promising path. Finally, exploring the integration of their method with other long-tail recognition techniques, such as re-weighting or re-sampling, warrants further study to explore potential synergistic improvements. Addressing these points will enhance the practicality and scalability of their proposed approach.
More visual insights#
More on figures

This figure visualizes the generated samples for class 90 (truck) of the CIFAR100-LT dataset using t-SNE, a dimensionality reduction technique. It shows how different diffusion models generate samples with varying distributions in the feature space. The four subplots represent samples generated by four different models: DDPM, and CBDM with different hyperparameters (τ=3, τ=2, τ=1). The visualization helps understand how modifying the model affects the distribution of generated samples and their proximity to real samples of the same class. The goal is to identify which samples are most beneficial for improving the accuracy of a classifier trained on the generated samples.

This figure shows example images of samples generated by the DiffuLT model, categorized into three groups: In-distribution (ID), Approximately In-distribution (AID), and Out-of-distribution (OOD). The ID samples closely resemble real images from the dataset. AID samples show a blend of features from multiple classes, exhibiting a mix of characteristics from both head and tail classes. OOD samples are significantly different from the original images and appear less realistic or contain significant artifacts. The figure visually demonstrates how the AID samples effectively bridge the gap between head and tail classes, highlighting their importance in improving long-tail recognition performance. This image is part of the explanation of how the AID samples (a blend of head and tail class features) generated by the model are instrumental to the improved classifier accuracy.

This figure illustrates the overall pipeline of the DiffuLT method. It begins with training a feature extractor and an AID-biased diffusion model using the original imbalanced dataset. The trained diffusion model then generates new samples that are subsequently filtered using the feature extractor, resulting in a refined dataset. Finally, a classifier is trained using the augmented dataset, with a weighted cross-entropy loss, to enhance performance. The figure visually represents the flow of the process, highlighting the key steps and components involved.

This figure shows example images generated by the DiffuLT model for CIFAR100-LT. The images represent various classes from the dataset, with a focus on those classes with few examples in the original dataset. This demonstrates the model’s ability to synthesize plausible images even for under-represented categories, effectively augmenting the training data to improve the classification performance of a long-tailed recognition model.

This figure shows example images generated by a diffusion model and categorized into three groups: in-distribution (ID), approximately in-distribution (AID), and out-of-distribution (OOD). The ID samples closely resemble real images from the dataset. AID samples blend features from multiple classes, representing a combination of head and tail class characteristics, demonstrating a fusion of information crucial for improving the classifier’s accuracy. The OOD samples show noticeable deviations or anomalies compared to the real images.

This figure shows example images generated by the DiffuLT model, categorized into three groups: in-distribution (ID), approximately in-distribution (AID), and out-of-distribution (OOD). ID samples closely resemble real images from the dataset. AID samples blend features from both head and tail classes, exhibiting a fusion of characteristics. OOD samples deviate significantly from the original data distribution, often appearing as anomalies or unrealistic combinations of features. The figure visually demonstrates the model’s ability to generate a range of samples with varying degrees of similarity to the real data, highlighting the importance of AID samples for improving long-tail classification performance.
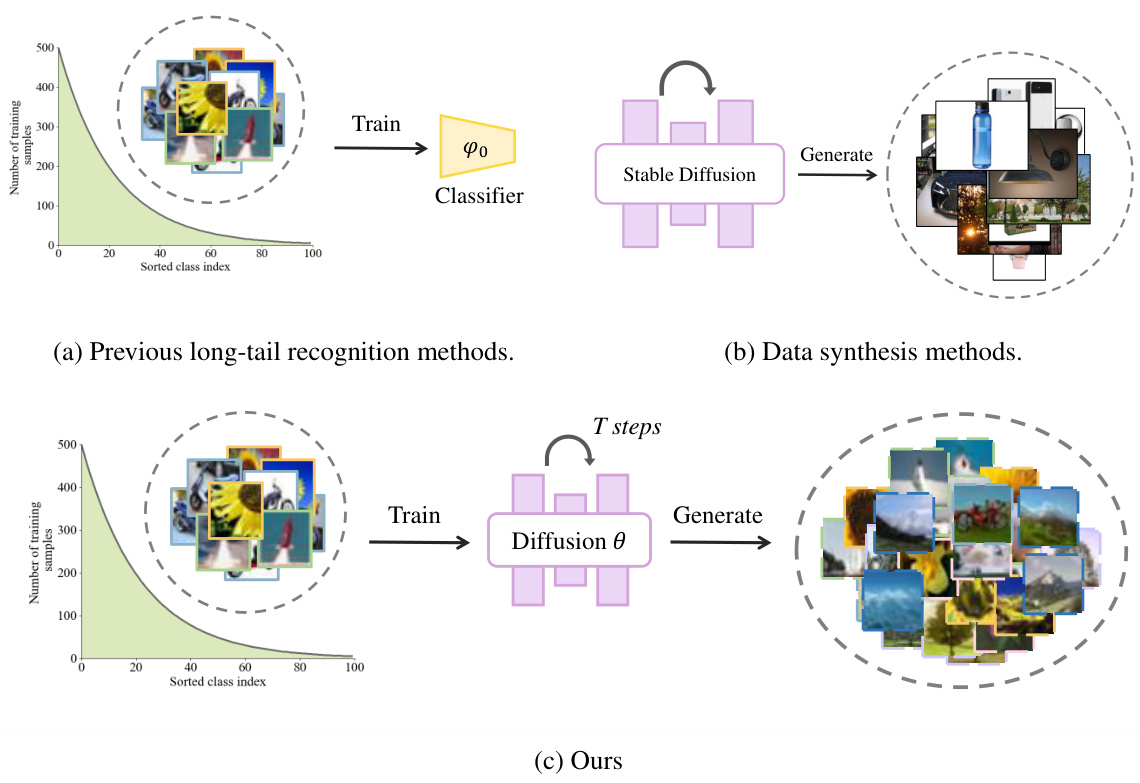
This figure compares three approaches to long-tail recognition. (a) shows traditional methods that focus on training, (b) illustrates data synthesis methods that augment the data with additional images, and (c) presents the proposed DiffuLT method that uses a diffusion model to generate additional AID samples to enhance the classification performance of long-tail datasets. The bar chart shows the imbalanced nature of a long-tailed dataset, highlighting the scarcity of samples in tail classes.
More on tables

This table presents the percentage of In-distribution (ID), Approximately in-distribution (AID), and Out-of-distribution (OOD) samples generated by different models. The models compared are DDPM and CBDM with different tau (τ) values. The results show how the different models’ generated samples are distributed across these three categories, indicating the model’s ability to generate samples that closely resemble the original data distribution.
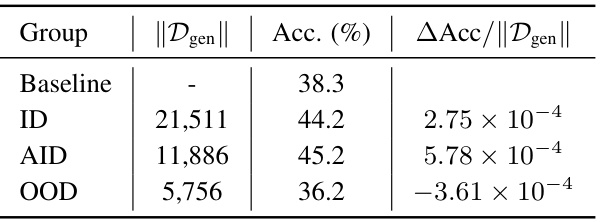
This table presents a quantitative analysis of the impact of different types of generated samples (ID, AID, OOD) on classifier accuracy. It shows the number of samples generated for each category, the resulting classifier accuracy when those samples are added to the training dataset, and the average accuracy improvement per sample. The results highlight the significant contribution of AID samples to improving classifier performance, while OOD samples have a negative impact.
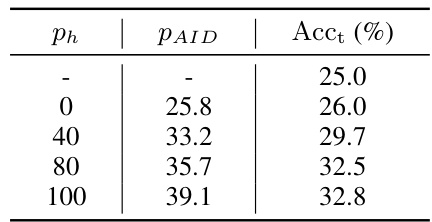
This table presents the results of experiments conducted to investigate how varying the proportion of head class data in the training process affects the generation of AID samples and the performance of the classifier on tail classes. The proportion of head class data (ph) is varied from 0% to 100%, and for each proportion, the proportion of AID samples (pAID) and the accuracy of the classifier on the tail classes (Acct) are reported. The results show a correlation between the proportion of head class data and the performance on tail classes. As the proportion of head class data increases, the proportion of AID samples and the accuracy on tail classes also tend to increase, suggesting that the inclusion of head class data in the generative process can improve the quality and diversity of the samples generated for tail classes.
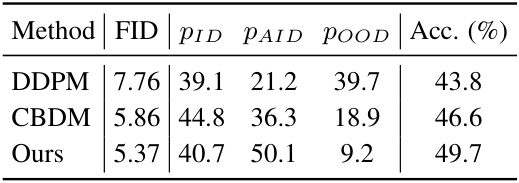
This table presents the percentage of In-distribution (ID), Approximately in-distribution (AID), and Out-of-distribution (OOD) samples generated by different models (DDPM, CBDM with different tau values, and the proposed method). It shows how the proposed method improves the generation of AID samples, which are crucial for enhancing classifier accuracy.
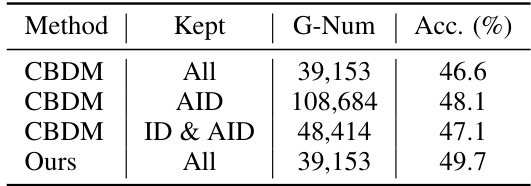
This table compares different methods for retaining generated samples and their impact on classification accuracy. It shows the number of samples kept (after filtering), the total number of generated samples before filtering, and the resulting classification accuracy. The methods compared include CBDM with different sample selection criteria (all, AID only, ID and AID) and the proposed ‘Ours’ method.

This table presents the quantitative results of the proposed DiffuLT model and several baseline methods on CIFAR100-LT and CIFAR10-LT datasets. The performance is evaluated under different long-tail ratios (r=100, 50, 10) and is broken down into three groups based on the number of samples in each class (many, medium, few) for CIFAR100-LT with r=100. The best performing methods are highlighted in bold, with the second best underlined.
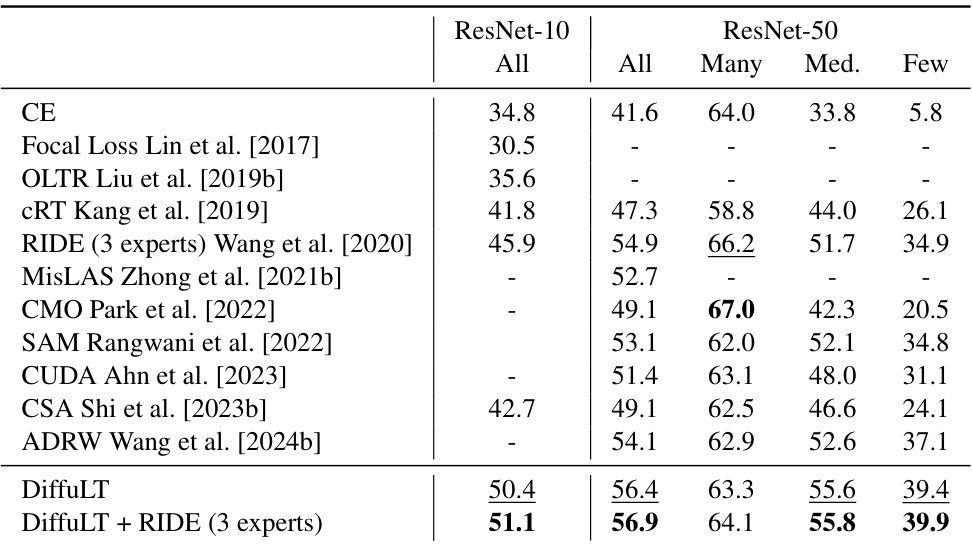
This table presents the performance of different long-tailed recognition methods on the ImageNet-LT dataset. The results are broken down by the classifier backbone used (ResNet-10 and ResNet-50) and further categorized by the number of samples in each class (All, Many, Medium, Few). The top-performing methods are highlighted in bold, while the second-best performers are underlined. This allows for a comparison of various methods across different scales of class imbalance.
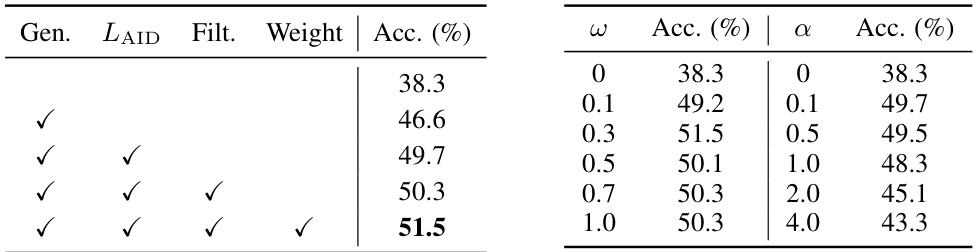
This table presents the ablation study results on CIFAR100-LT with an imbalance ratio of 100. It systematically evaluates the impact of different components of the proposed DiffuLT method, namely the generation of samples (Gen.), the AID-biased loss (LAID), the filtering of OOD samples (Filt.), and the weighting of generated samples in the classification loss (Weight). The accuracy (Acc.) achieved by each configuration is reported, showcasing the significance of each component for improved performance.

This table presents the results of repeated experiments conducted on the CIFAR100-LT and CIFAR10-LT datasets to evaluate the robustness of the DiffuLT method. The experiments were repeated three times (DiffuLT(1), DiffuLT(2), DiffuLT(3)), and the table shows the accuracy achieved for each repetition at different long-tail ratios (r = 100, 50, 10). The consistency of the results across the repetitions demonstrates the robustness and reliability of the proposed method.

This table presents the results of repeated experiments conducted on the ImageNet-LT dataset to evaluate the robustness of the DiffuLT method. Three separate experiments (DiffuLT(1), DiffuLT(2), and DiffuLT(3)) were performed using ResNet-10 and ResNet-50 as classifier backbones. The table demonstrates the consistency of the method’s performance across multiple runs, showcasing its robustness.
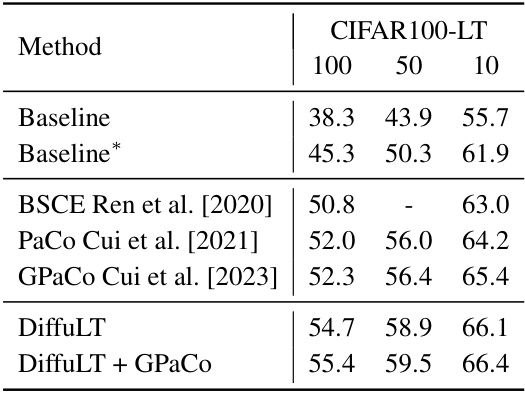
This table presents the results of experiments on the CIFAR100-LT dataset using a modified pipeline. The baseline results are compared to the results obtained using the BSCE, PaCo, and GPaCo methods. The table also shows the performance of the DiffuLT method, both alone and when combined with GPaCo. The imbalance ratio (r) is varied across three levels (100, 50, and 10) to evaluate performance across different levels of class imbalance.
Full paper#