↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current large language models (LLMs) heavily rely on tokenization, which, while improving performance, introduces several issues: performance biases across languages, increased vulnerability to adversarial attacks, and reduced character-level modeling accuracy. This reliance also increases model complexity. These limitations motivate the need for alternative approaches that can maintain or exceed the performance of tokenized models while overcoming these drawbacks.
SpaceByte proposes a solution by introducing a novel byte-level decoder architecture. Instead of relying on fixed patch sizes like previous methods, SpaceByte dynamically adjusts patch sizes according to word boundaries, significantly improving performance. Through controlled experiments, SpaceByte demonstrates superior performance compared to existing byte-level architectures, and it nearly matches the performance of tokenized Transformers. This innovative approach has significant implications for the development of more efficient, robust, and less biased LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models because it directly addresses the limitations of traditional tokenization methods. It offers a novel byte-level approach that improves performance while mitigating known issues like performance biases, adversarial vulnerabilities and decreased character-level modeling performance. By providing a viable alternative to tokenization and offering a well-documented methodology, it paves the way for more efficient and robust language models. The simple patching rule is particularly important for application in various data modalities.
Visual Insights#
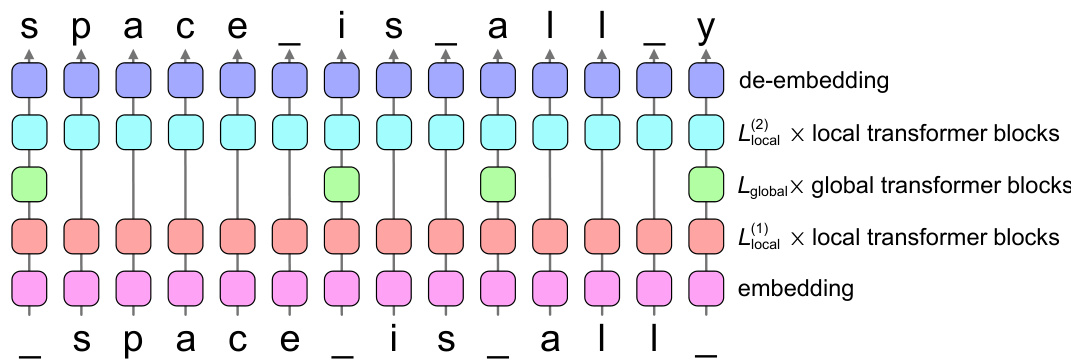
This figure shows the architecture of SpaceByte. It’s a byte-level Transformer decoder with added ‘global’ Transformer blocks inserted between standard Transformer layers. These global blocks are applied selectively after specific bytes (like spaces), aiming to improve prediction accuracy, especially at word beginnings.
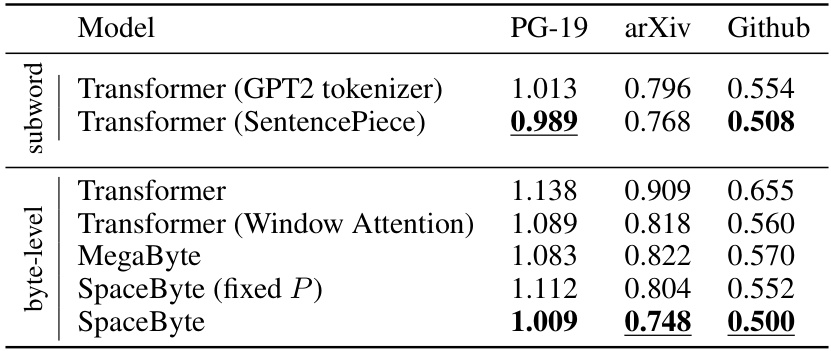
This table presents the best bits-per-byte achieved by different language models across three datasets (PG-19, arXiv, and Github) when trained using a compute budget of 1019 FLOPs. The models include both subword and byte-level transformer architectures, with various modifications (Window Attention, MegaByte, SpaceByte with fixed patch size, and SpaceByte). The lowest bits-per-byte for each dataset is underlined, and values within 2.5% of the lowest are bolded. The table highlights SpaceByte’s superior performance compared to other byte-level models and its comparable performance to the SentencePiece subword transformer, indicating its effectiveness in closing the performance gap between byte-level and tokenized models.
In-depth insights#
Byte-Level Decoding#
Byte-level decoding in large language models offers a compelling alternative to traditional tokenization-based approaches. Eliminating the need for tokenization simplifies the preprocessing pipeline and mitigates biases inherent in tokenization schemes. However, byte-level models typically face challenges in terms of computational cost and context length due to the larger input size compared to subword units. Efficient architectures, such as those employing multiscale modeling or specialized block structures, are crucial to address these challenges. A key consideration is the trade-off between model complexity, computational efficiency, and the ability to capture nuanced linguistic patterns effectively. Successfully balancing this trade-off is critical to realizing the full potential of byte-level decoding, unlocking improved performance while maintaining computational feasibility. Further research is needed to optimize byte-level architectures and develop techniques for efficiently handling long-range dependencies in the context of byte-level representations.
SpaceByte Design#
SpaceByte is designed to address limitations of existing byte-level language models by improving efficiency and performance. Its core innovation lies in a dynamic, rather than fixed, patch size for multi-scale modeling. This dynamic patching aligns with word boundaries, guided by a simple rule identifying “spacelike” bytes. This approach directly tackles the challenge of predicting word beginnings, typically the most difficult part of a word. The architecture incorporates local and global transformer blocks. Global blocks, with higher dimensionality, are strategically placed after spacelike bytes, leveraging the increased model capacity where it is needed most. The combination of local and global blocks, coupled with the dynamic patching, aims to strike an optimal balance between computational efficiency and modeling capacity, thereby bridging the gap between byte-level and subword models. SpaceByte’s innovative design focuses on improving performance while controlling training and inference costs, significantly outperforming existing byte-level approaches.
Dynamic Patching#
Dynamic patching, in the context of large language models, offers a powerful technique to optimize performance and address limitations of traditional fixed-size patching methods. Instead of pre-defining patch sizes, dynamic patching intelligently adjusts patch boundaries based on inherent text structures, such as word boundaries or punctuation. This adaptability significantly improves model efficiency by aligning computational resources with semantically meaningful units. For instance, by prioritizing the splitting of text at word boundaries, the model can better capture contextual information, leading to improved accuracy and reduced computational cost. However, this approach introduces complexity in determining the optimal patch boundaries in real-time. The effectiveness of dynamic patching largely depends on the chosen algorithm for boundary identification, the characteristics of the input text, and the model’s architecture. While promising, further research is needed to explore various boundary detection algorithms and evaluate their performance across diverse language models and datasets. The ultimate success of dynamic patching hinges on striking a balance between computational efficiency and the preservation of crucial semantic information within the dynamically defined patches. Future research directions could explore adaptive patching strategies that further refine patch boundaries based on learned representations and model performance, as well as extend dynamic patching techniques to other sequence modeling tasks beyond text processing.
Performance Gains#
Analyzing performance gains in a research paper requires a multifaceted approach. Firstly, we must identify the benchmark used. Was it a standard dataset, a novel one, or a specific subset? The choice significantly influences the interpretability of results. Secondly, the metrics employed are crucial; were they appropriate for the task and the specific context of the research? A focus on statistical significance helps determine the reliability of reported improvements. Were error bars, p-values, or confidence intervals included? Reproducibility is also paramount; were sufficient experimental details provided to allow others to replicate the results, including hardware and software specifications, hyperparameters, and training procedures? Finally, a critical assessment must consider the generalizability of the findings. Do the results generalize to other datasets or model architectures? Performance gains, when viewed holistically, offer valuable insights only if these aspects are carefully considered and clearly communicated.
Future Extensions#
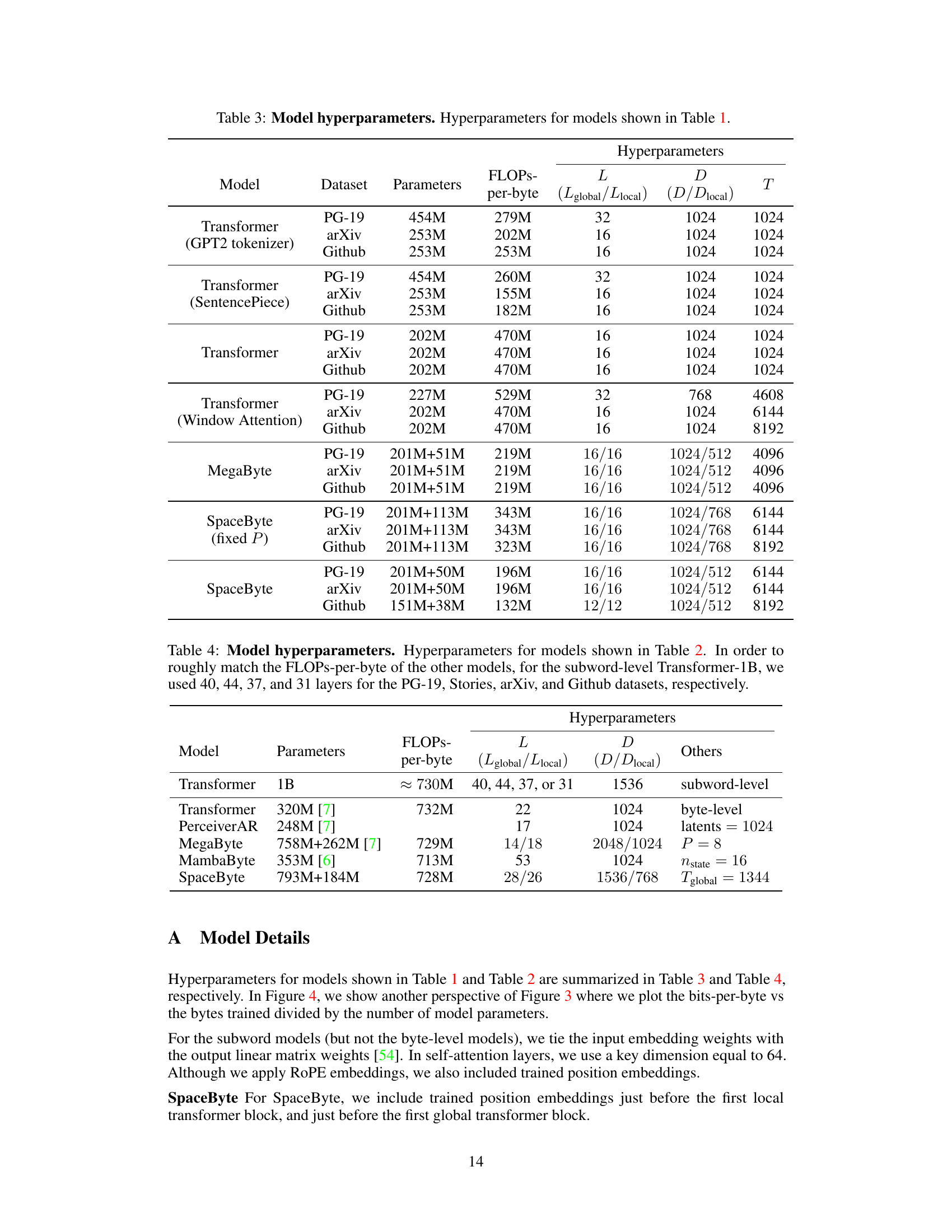
The paper’s “Future Extensions” section would ideally explore several promising avenues. Improving the global block insertion rule is paramount; the current heuristic, while surprisingly effective for certain text types, lacks generalizability. More sophisticated methods, potentially leveraging linguistic features or learned representations, could significantly enhance SpaceByte’s performance across diverse languages and text modalities. Further, investigating recursive application of multiscale modeling is crucial. Expanding beyond byte- and word-level to incorporate sentence or paragraph-level blocks could dramatically improve long-range dependency modeling and context understanding. Finally, a deeper exploration of the interaction between SpaceByte’s architecture and different attention mechanisms warrants further investigation; exploring alternatives to the standard sliding-window attention could further optimize performance and computational efficiency. Incorporating Mamba blocks is another promising direction. Their inherent efficiency and different approach to attention may offer complementary strengths that could be leveraged to create an even more robust and powerful byte-level autoregressive model.
More visual insights#
More on figures
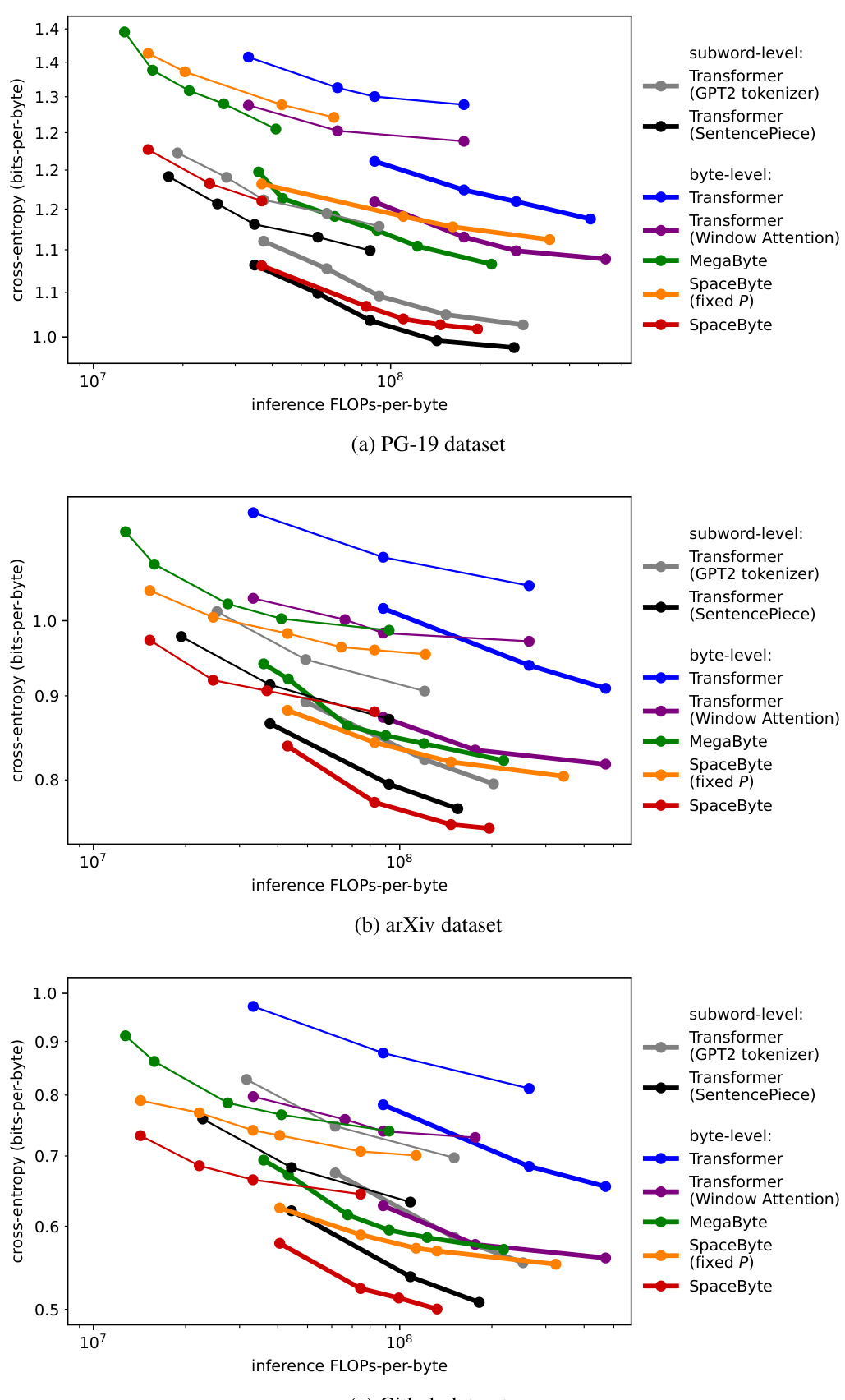
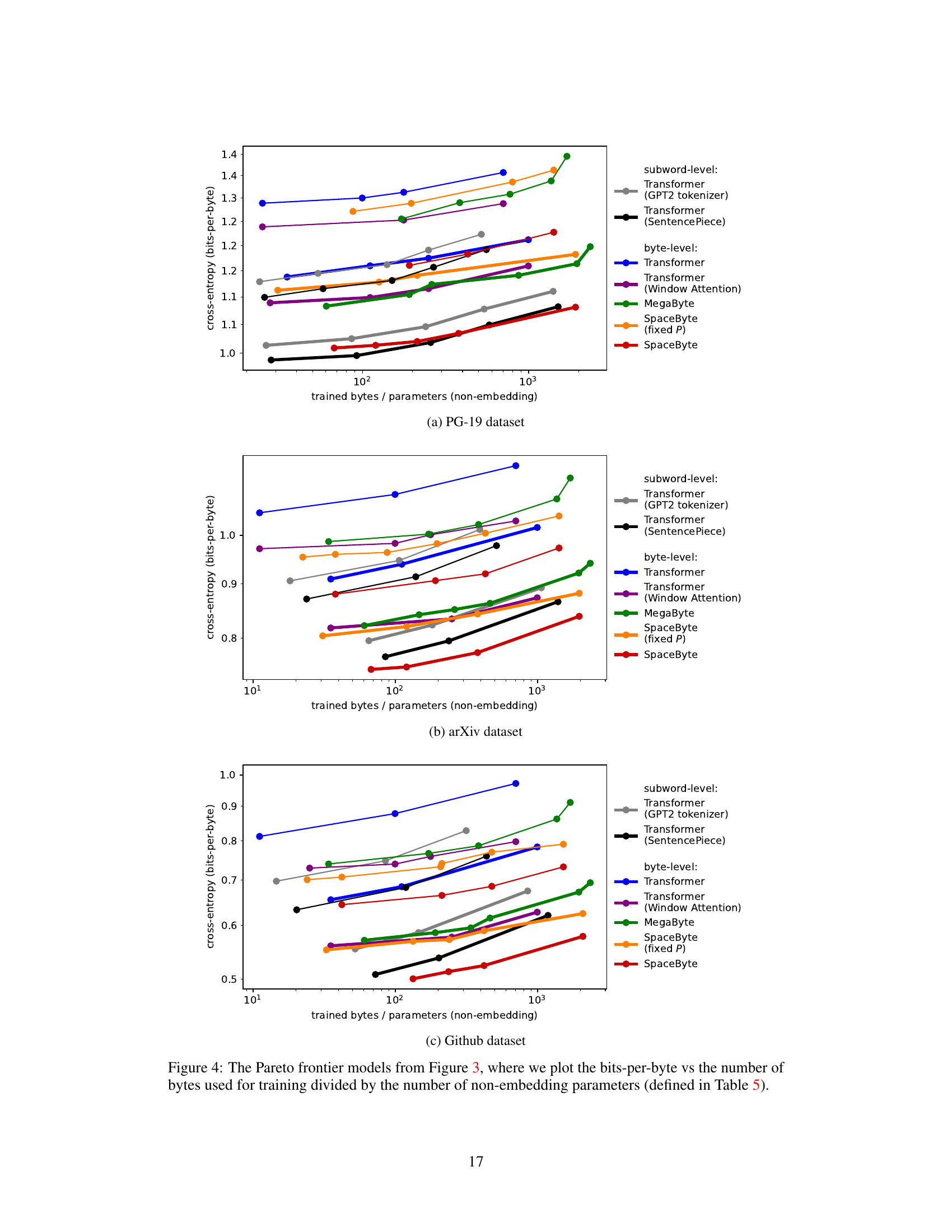
This figure presents the Pareto frontier showing the trade-off between cross-entropy (a measure of model performance) and FLOPs-per-byte (a measure of computational cost) for various language models. Different models are trained with varying compute budgets (10^18 and 10^19 FLOPs). The plot demonstrates that SpaceByte consistently outperforms other byte-level models and achieves performance comparable to subword Transformer models, especially when considering a fixed compute budget.
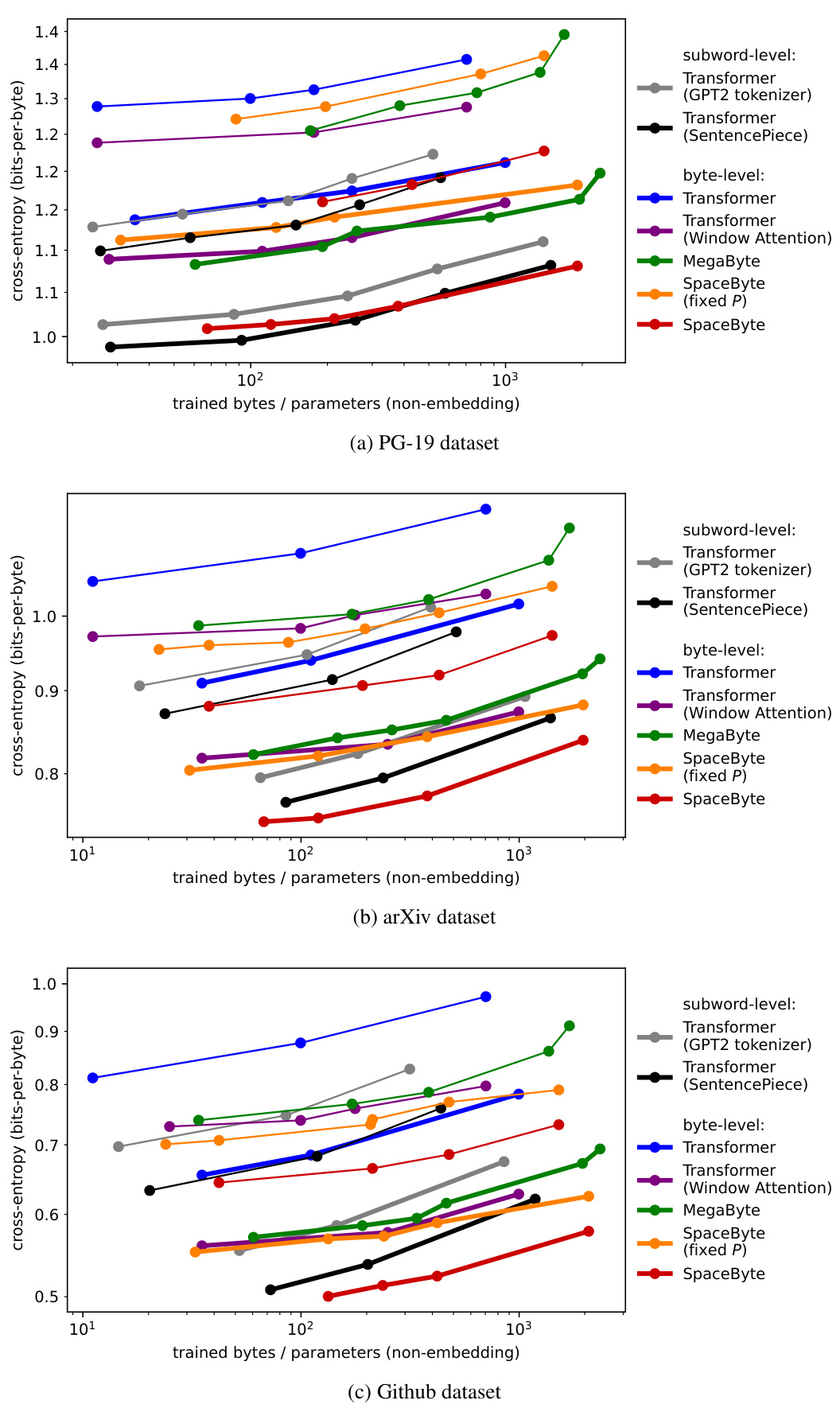
This figure shows the Pareto frontier for different language models trained with varying compute budgets. The x-axis represents the inference FLOPs per byte (a measure of computational cost), and the y-axis represents the cross-entropy (bits per byte), a measure of model performance. Lower values on both axes are better. The figure compares SpaceByte against other byte-level models (MegaByte, byte-level transformer) and subword models. SpaceByte consistently outperforms other byte-level models and achieves similar performance to the best subword model.
More on tables
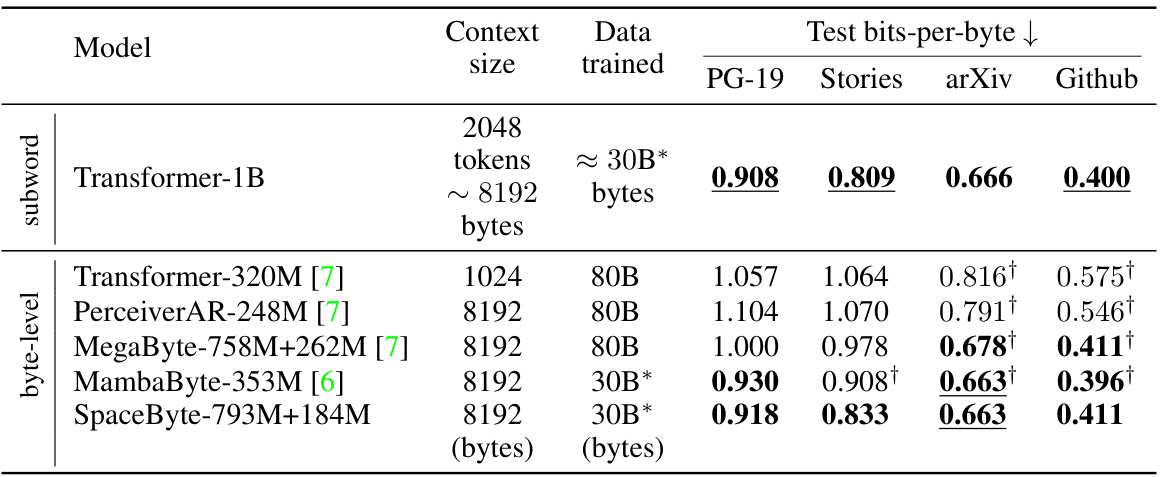
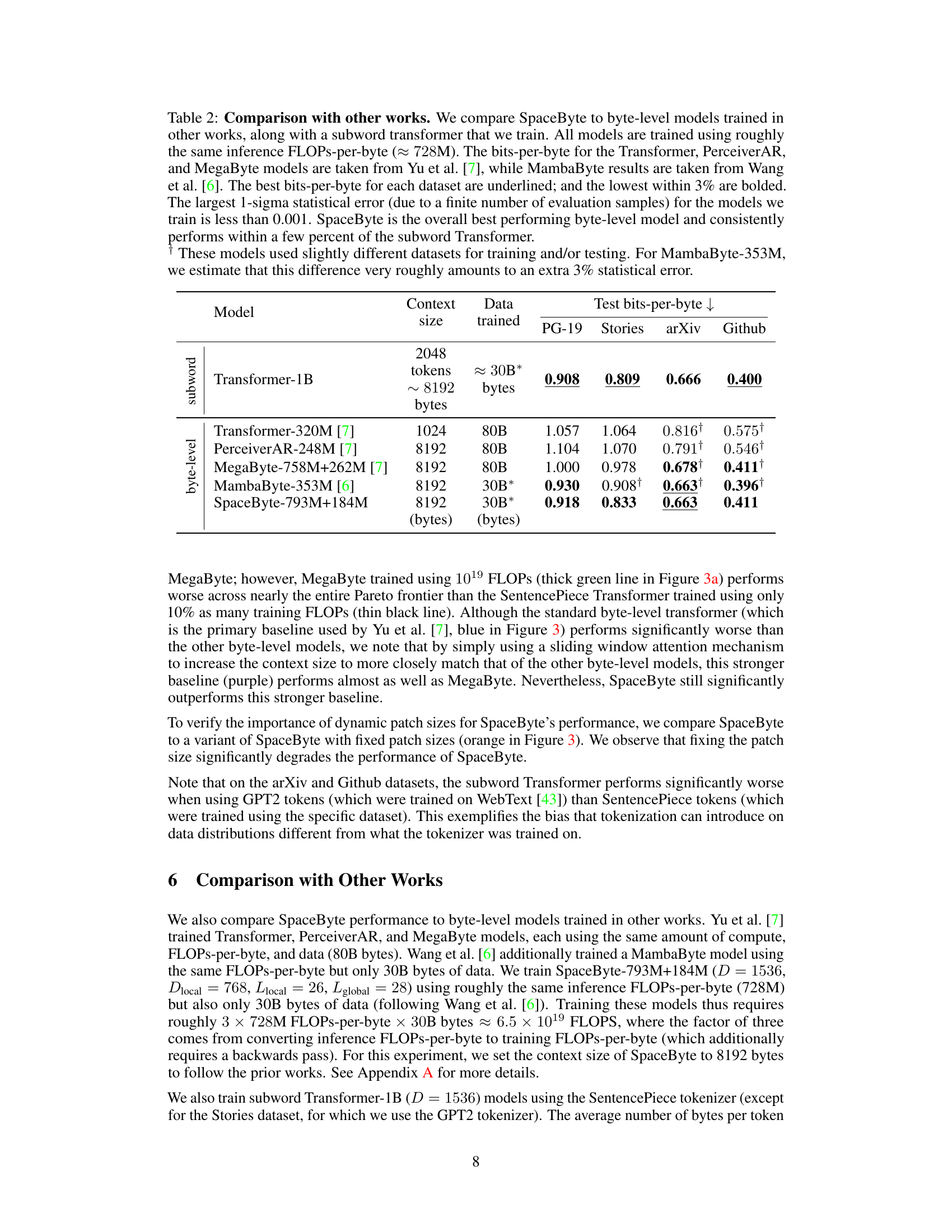
This table compares the performance of SpaceByte against other byte-level models from related works and a subword transformer. The comparison is made using a similar inference compute cost (FLOPs-per-byte), and the best performance (lowest bits-per-byte) is highlighted. It shows that SpaceByte outperforms other byte-level models and achieves performance comparable to the subword transformer.
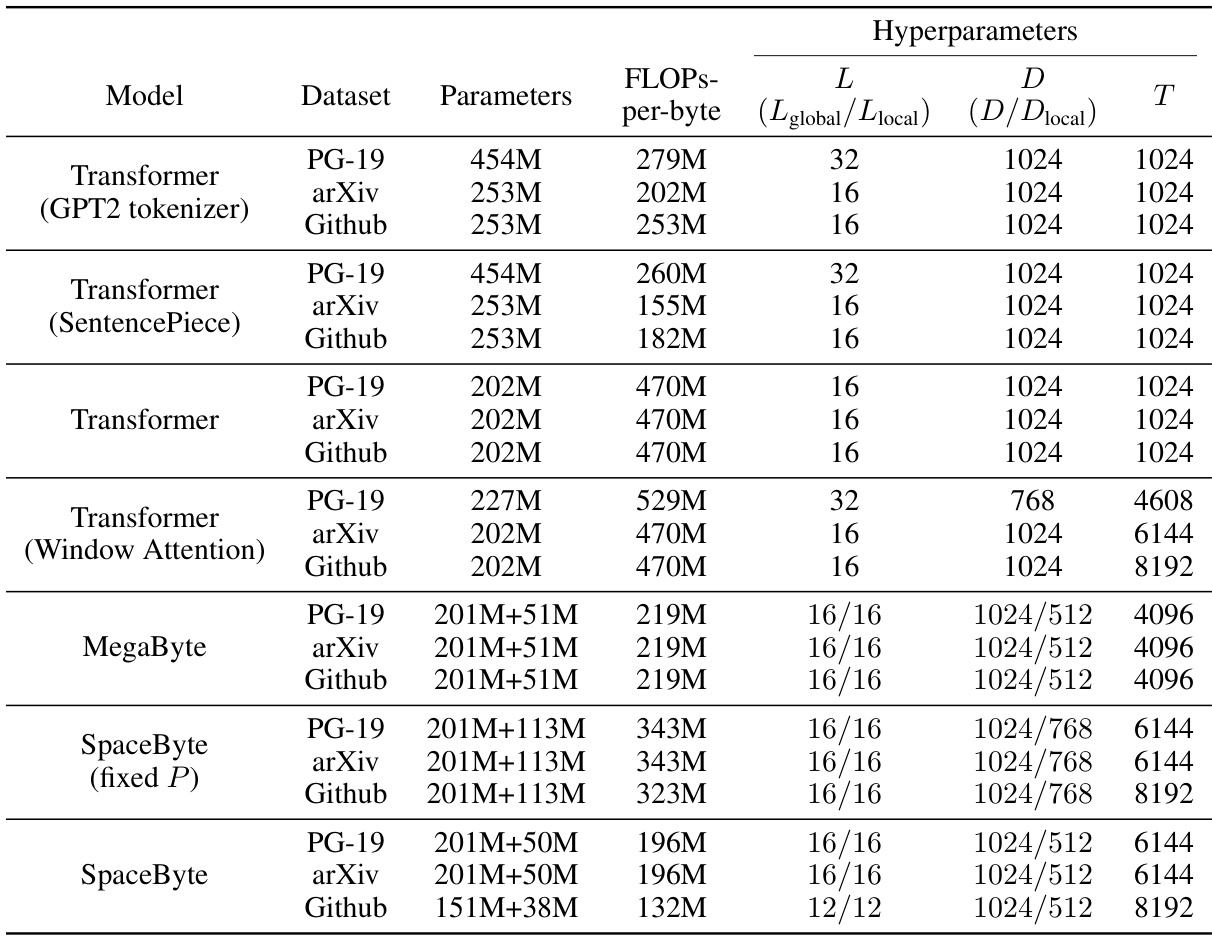
This table presents the best bits-per-byte achieved by different language models on three different datasets (PG-19, arXiv, and Github) when trained with a compute budget of 1019 FLOPs. It compares the performance of SpaceByte against several baselines, including byte-level and subword-level Transformer models, MegaByte, and variations of SpaceByte. The lowest bits-per-byte for each dataset is highlighted, along with those within 2.5% of the lowest. The table demonstrates SpaceByte’s superior performance compared to other byte-level models and its competitive performance with the SentencePiece subword Transformer.

This table compares SpaceByte’s performance with other byte-level models from existing works and a subword transformer. All models are trained with approximately the same inference FLOPs-per-byte, allowing for a fair comparison of their bits-per-byte performance across different datasets. The table highlights SpaceByte’s superior performance compared to other byte-level models and its competitive performance against the subword transformer.

This table shows the best bits-per-byte achieved by different language models on three different datasets (PG-19, arXiv, and Github). The models are categorized into byte-level and subword-level architectures. The lowest bits-per-byte for each dataset is highlighted, along with those within 2.5% of the lowest. SpaceByte demonstrates superior performance compared to other byte-level models and comparable performance to the top-performing subword model.

This table presents the best bits-per-byte achieved by different language models on three datasets (PG-19, arXiv, and Github) when trained with a compute budget of 1019 FLOPs. The models compared include various byte-level and subword-level Transformer architectures. The lowest bits-per-byte for each dataset is highlighted, and those within 2.5% of the lowest are bolded. The table demonstrates SpaceByte’s superior performance compared to other byte-level models and its comparable performance to the SentencePiece subword Transformer.
Full paper#