↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current benchmarks inadequately assess LLMs’ real-time strategic decision-making skills. StarCraft II, with its complex dynamics, presents an ideal evaluation setting. However, a lack of language support in existing SC2 environments hinders LLM agent evaluation.
To address these issues, the paper introduces TextStarCraft II, a specialized environment translating SC2 gameplay into an interactive text-based format, and the Chain of Summarization (CoS) method, improving LLMs’ ability to process complex information quickly. Experiments reveal that several LLMs effectively played the game, defeating the built-in AI and performing on par with human players. The results demonstrate LLMs’ capabilities in strategy and decision-making, opening up new possibilities for research on AI in real-time strategy games.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel benchmark and methodology for evaluating LLMs in real-time strategy game environments such as StarCraft II. This addresses a significant gap in current research and opens up new avenues for assessing LLM capabilities in complex decision-making scenarios. It also promotes further development and interaction with the developed environment, fostering the development of AI agents with human-level strategic decision making abilities.
Visual Insights#
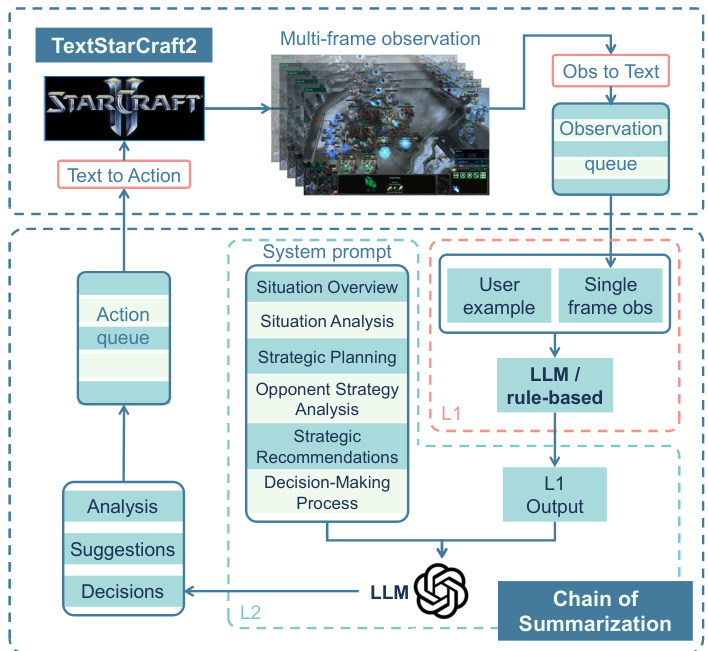
This figure illustrates the interaction process between the LLM and the TextStarCraft II environment using the Chain of Summarization (CoS) method. The process starts with initialization, where initial game data is converted to text for processing. Next, Single-Frame and Multi-Frame Summarization modules refine and summarize observations into actionable insights using advanced LLM reasoning. Then, in Directive Formulation and Action Scheduling, these insights are segmented into specific actions and queued for execution. Finally, Action Retrieval and Execution implement the actions in the game. This cycle continually converts new data into text, enhancing LLM performance in the TextStarCraft II environment. The figure highlights the key components including the Observation-to-Text Adapter, the Text-to-Action Adapter, the Single-Frame Summarization, the Multi-Frame Summarization, the Action Queue, the Chain of Summarization, and the LLM agent.
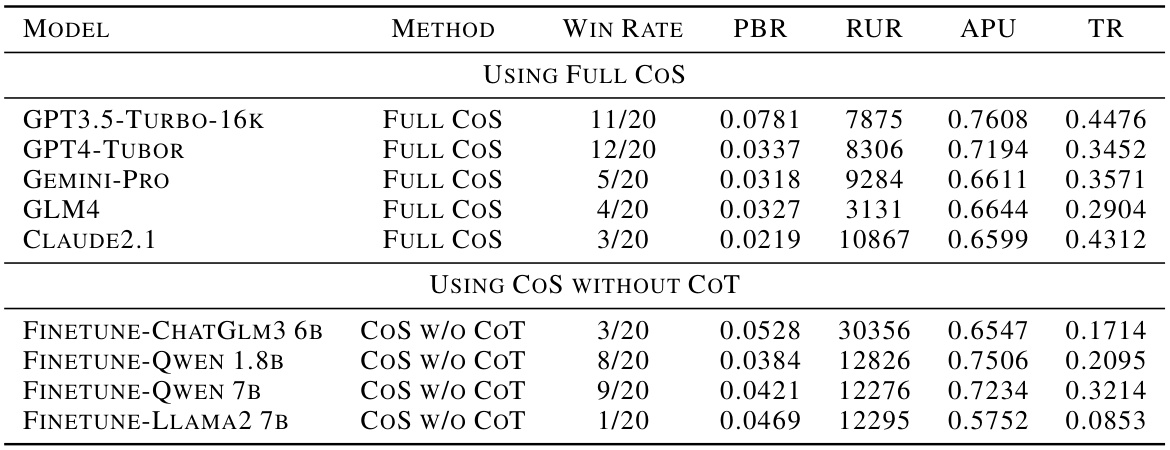
This table presents the performance comparison of various LLMs (Large Language Models) tested in the TextStarCraft II environment against the built-in AI at level 5. The LLMs were evaluated using two different methods: the full Chain of Summarization (CoS) method and the CoS method without Chain of Thought (CoT). The table includes the win rate, Population Block Ratio (PBR), Resource Utilization Ratio (RUR), Average Population Utilization (APU), and Technology Rate (TR) for each LLM and method.
In-depth insights#
LLM-RTS Benchmark#
An LLM-RTS benchmark is a crucial tool for evaluating the capabilities of large language models (LLMs) in real-time strategy (RTS) game environments. It would rigorously assess LLMs’ strategic thinking, decision-making, and adaptability in dynamic and complex scenarios. Key aspects would include resource management, base building, unit production and control, and counter-strategy implementation, all within the time constraints of a real-time setting. The benchmark must be carefully designed to account for the unique challenges of RTS, such as imperfect information, unpredictable opponent actions, and the need for rapid, tactical responses. A robust benchmark would also consider various factors like LLM architecture, prompt engineering, and model size, and should incorporate multiple evaluation metrics to capture a holistic assessment. Furthermore, it is essential to establish clearly defined success criteria against established benchmarks, either from human players or existing AI systems. Finally, the benchmark’s design should focus on both quantitative (win rate, resource efficiency, etc.) and qualitative (strategic clarity, decision rationale, etc.) measurements to provide a comprehensive and nuanced evaluation of LLM performance in RTS games.
Chain of Summary#
The proposed “Chain of Summarization” (CoS) method offers a novel approach to enhance Large Language Model (LLM) performance in real-time strategy games. Unlike traditional Chain of Thought (CoT) methods, CoS leverages summarization techniques to compress complex game information into concise, actionable insights. This compression facilitates faster processing by the LLM, enabling more effective and rapid decision-making within the time constraints of real-time gameplay. The method incorporates both single-frame and multi-frame summarization, providing the LLM with a more comprehensive understanding of the current game state and its evolution. By combining summarization with advanced reasoning, CoS significantly accelerates the inference process and improves the LLM’s ability to make sophisticated strategic decisions. The incorporation of CoS improves the LLM’s performance in both single-frame and multi-frame decision making, leading to better gameplay outcomes.
Human-AI Matches#
The section on Human-AI Matches presents a crucial evaluation of the Large Language Model (LLM) agents’ capabilities. By pitting fine-tuned LLMs against human players in real-time StarCraft II matches, the researchers directly assess the strategic decision-making ability of the AI. This constitutes a significant departure from traditional AI benchmarks focusing on single-player modes or simpler tasks, and provides more realistic and robust evaluation of actual LLM capabilities. The results showing fine-tuned LLMs performing comparably to Gold-level human players is a remarkable achievement and highlight the potential for LLMs to exhibit strategic thinking and competitive performance. Real-time human-computer interaction was essential to this experiment, and is a strength of this approach because the results can more directly measure the LLM agent’s responsiveness and adaptability to dynamic, unpredictable situations. The success of the fine-tuned models against human players strengthens the overall claim that the proposed Chain of Summarization (CoS) method effectively enhances LLMs’ decision-making efficiency. Finally, this testing process likely provided valuable insights into the limitations and strengths of current LLMs, in particular their capacity for complex strategic thinking and long term planning in real time.
Prompt Engineering#
Prompt engineering plays a crucial role in effectively utilizing large language models (LLMs) for complex tasks, such as strategic decision-making in real-time strategy (RTS) games. Careful crafting of prompts is essential to guide the LLM’s reasoning process, ensuring that it generates relevant and actionable insights. The paper highlights the use of two distinct prompt types: a basic prompt, which elicits simple actions, and a complex prompt, which guides the LLM through a more structured reasoning process. The results show that more complex prompts significantly improve the LLM’s performance, showcasing the importance of carefully designed prompts to achieve expert-level capabilities. This demonstrates the crucial interplay between prompt design and LLM effectiveness in achieving desired outcomes, particularly in domains demanding nuanced decision-making.
Future of LLMs#
The future of LLMs in strategic gaming, as exemplified by StarCraft II, is bright. Real-time strategy necessitates adaptability and rapid decision-making, skills where LLMs show promise, particularly with advancements like the Chain of Summarization method. However, current limitations remain, including reliance on textual data and scripted micro-actions, which restricts the full potential of LLM integration into complex, visually rich environments. Overcoming these will involve further research into multimodal LLMs, allowing for visual processing and more nuanced decision-making. Developing more comprehensive benchmarks beyond simple win rates is crucial for accurate evaluation. Additionally, investigating the interpretability of LLM decision-making processes will be key to improving the trustworthiness and utility of LLMs for high-stakes applications, moving towards a more collaborative and human-like interaction in complex domains.
More visual insights#
More on figures
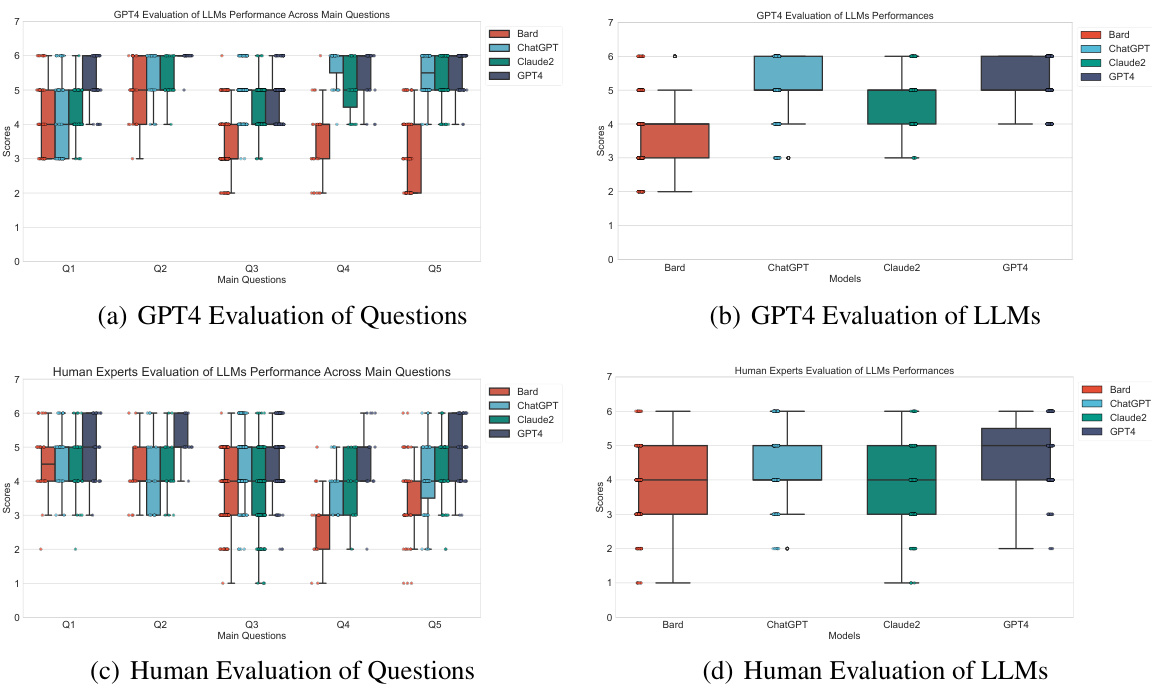
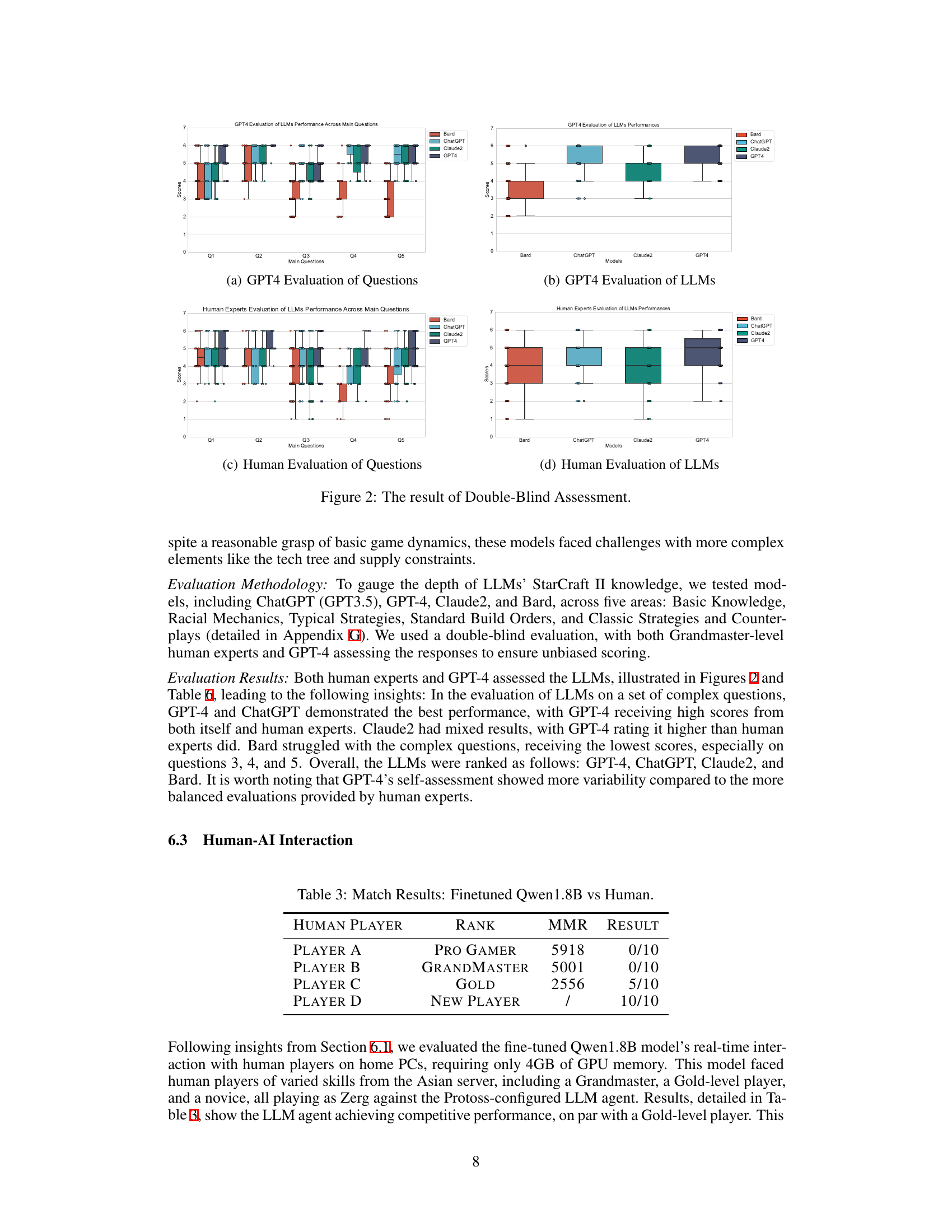
This figure presents the results of a double-blind assessment evaluating the performance of LLMs on StarCraft II knowledge. The assessment involved two sets of evaluations: one by GPT-4 and another by human experts. Each evaluation is represented with two box plots. The first (a and c) shows the scores across five main questions, highlighting GPT-4 and human expert’s assessment of those questions’ difficulty. The second (b and d) displays the scores for various LLMs based on those same five questions, providing a comparison of models in terms of their overall performance as assessed both by GPT-4 and human experts.

This figure compares AlphaStar and the LLM agent’s responses to a potential threat in StarCraft II. AlphaStar fails to build defensive structures to counter the threat, resulting in damage to its base. Conversely, the LLM agent anticipates the threat, builds defensive structures, and presents a structured decision-making process demonstrating strategic planning and proactive decision making.

This figure shows a comparison of AlphaStar and the LLM agent’s ability to anticipate and respond to threats. The left panel (AlphaStar) shows a failure to construct preemptive defensive structures against an oracle attack, leading to significant damage. The right panel (LLM Agent) demonstrates proactive defense by constructing shield batteries ahead of time, indicating its awareness and preparedness for defensive strategies.
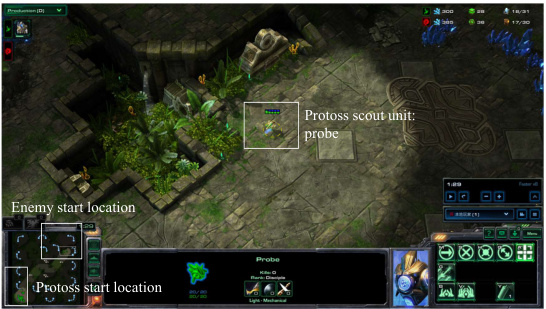
This figure shows screenshots from a StarCraft II game featuring an LLM agent playing as the Protoss race. The screenshots illustrate the agent’s strategic decisions in the early and mid-game stages, highlighting its defensive measures (such as building Shield Batteries) and proactive scouting behavior (dispatching a Probe to scout the enemy’s base). The images provide visual context for the LLM’s strategic thinking and decision-making process within the TextStarCraft II environment.
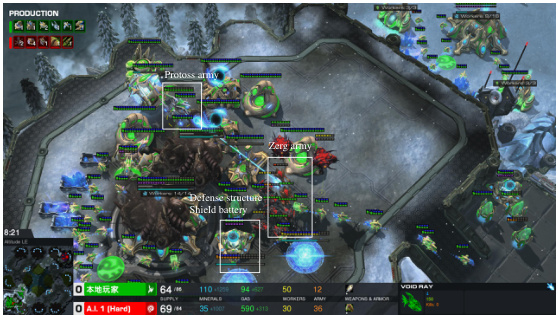
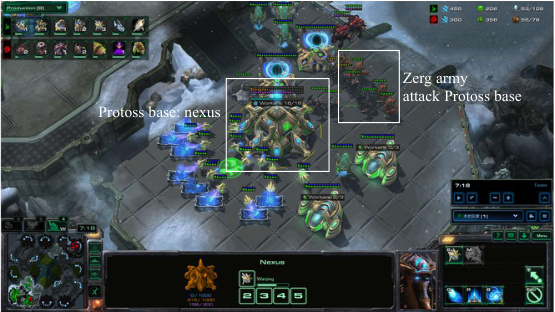
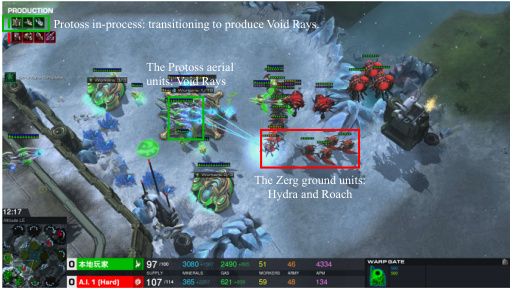
This figure shows two screenshots from a StarCraft II game. The first shows the early game where the Protoss player is using probes to scout the enemy base and build its own base. The second screenshot shows the mid-game, where the Protoss player has built several defense structures (Shield Batteries) and is producing units (Void Rays) to counter the Zerg’s attack. This illustrates the LLM agent’s ability to both scout effectively and build a strong defense.

This figure shows two screenshots from a StarCraft II game. The first image shows the early game where the Protoss (controlled by the LLM agent) is using a probe to scout the enemy’s base. The second image shows the mid-game where the Protoss is actively defending against the enemy’s attack using shield batteries.
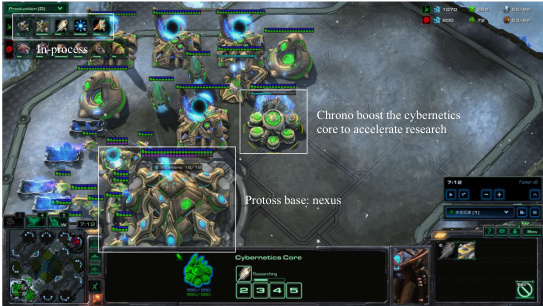
This figure shows two screenshots from a StarCraft II game, illustrating the LLM agent’s actions in the early and mid-game phases. The first screenshot highlights the proactive use of a Probe to scout the enemy’s main base. The second screenshot demonstrates a defensive strategy, emphasizing the construction of Shield Batteries to counter potential enemy aggression.

This figure illustrates the workflow of the Chain of Summarization (CoS) method within the TextStarCraft II environment. It shows how the LLM receives game observations (converted into text), processes these observations through single and multi-frame summarization, utilizes Chain-of-Thought reasoning to formulate actions, and then executes those actions within the StarCraft II game. The cycle repeats continuously, improving LLM performance.

This figure shows screenshots of a StarCraft II game where an LLM agent is controlling the Protoss. The screenshots highlight the agent’s early-game scouting behavior (a probe scouting the enemy base) and its mid-game defensive strategies (shield batteries protecting against Zerg attacks). The figure illustrates the LLM agent’s ability to balance proactive scouting with defensive actions in a dynamic environment.

This figure shows two screenshots from a StarCraft II game. The screenshots illustrate the LLM agent’s strategies in the early and mid-game phases. The first screenshot shows a Protoss probe scouting the enemy’s base to gather intelligence, while the second screenshot shows the Protoss army defending against an attack from the Zerg. In this screenshot, the Protoss army includes several shield batteries to mitigate damage, indicating a defensive strategy.
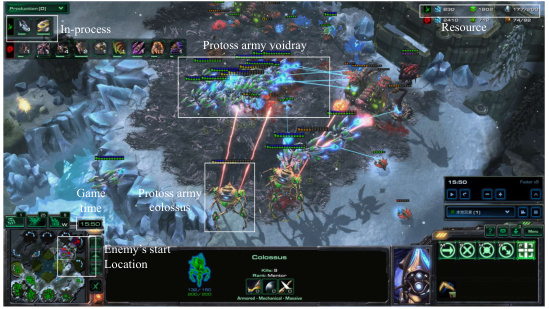
This figure shows two screenshots from a StarCraft II game. The first screenshot shows the early game stage, where the Protoss (controlled by an LLM agent) uses a probe to scout the enemy’s main base. The second screenshot shows a mid-game situation, where the Protoss uses Shield Batteries as a defensive strategy against Zerg aggression. This illustrates the LLM agent’s capability of utilizing scouting to gather information and employing defensive strategies in real-time.

This figure shows screenshots from a StarCraft II game where an LLM agent is playing as the Protoss race. The images highlight key aspects of the agent’s early and mid-game strategies. Specifically, the images showcase the Protoss’s proactive scouting, using Probes to explore the terrain and gain early information about the opponent’s base and army, as well as the construction of defensive structures (Shield Batteries) to protect against early aggression. This combination of proactive scouting and defensive building illustrates the agent’s ability to balance exploration and security.

The figure shows screenshots of a StarCraft II game where an LLM agent controls the Protoss. The screenshots illustrate two key aspects of the early and mid-game phases: defensive strategies and scouting. In the first image, the Protoss are using Probes to scout the enemy base to gather intel. In the second image, the Protoss have constructed Shield Batteries, a defensive structure, to protect their base from Zerg aggression.

This figure shows four screenshots from a StarCraft II game where an LLM agent is playing as the Protoss race. The screenshots illustrate different stages of the early to mid-game, highlighting the agent’s defensive strategies (using Shield Batteries) and its proactive scouting (using Probes and Observers to explore the map).
This figure shows two screenshots from a StarCraft II game illustrating the LLM agent’s strategic decision-making in the early and mid-game. The first image highlights the proactive use of scouting units to gather information about the opponent’s base. The second image shows the construction of defensive structures such as Shield Batteries and Photon Cannons in response to the opponent’s aggression.

This figure shows two screenshots from a StarCraft II game. The first shows the early game where the Protoss (controlled by the LLM) sends out a probe to scout the enemy’s base. The second shows a mid-game scene where the Protoss has constructed defensive structures (Shield Batteries) and uses observers to gain information on the enemy.

This figure shows screenshots of a StarCraft II game featuring an LLM agent playing as Protoss. The images illustrate the agent’s early game strategy focusing on scouting the enemy’s base to gather information and building defensive structures (Shield Batteries) to protect against potential attacks. It highlights the LLM’s capabilities in combining early-game scouting with defensive preparations, crucial for a successful strategy in StarCraft II.
This figure illustrates the interaction process between the LLM and TextStarCraft II environment using the Chain of Summarization (CoS) method. The process starts with the initialization of game data, which is then converted into text for LLM processing. The CoS method refines and summarizes the observations into actionable insights, which are then segmented and scheduled for execution in the game environment. The cycle repeats, continually converting game data into text for LLM processing, thus enhancing the performance of the LLM in the TextStarCraft II environment.

This figure shows screenshots from a StarCraft II game, illustrating the actions taken by an LLM-controlled Protoss player during the early and mid-game phases. The screenshots highlight actions such as scouting the enemy’s base with a probe, using shield batteries and photon cannons as defensive structures, and responding to an attack by the Zerg. These actions showcase the LLM agent’s strategic planning and adaptive responses in real-time.
This figure shows screenshots from a StarCraft II game featuring an LLM agent playing as the Protoss race. The screenshots illustrate the agent’s early game defensive strategy, including the construction of Shield Batteries, and proactive scouting using Probes to observe the enemy’s base. The images highlight the agent’s focus on defensive measures and information gathering in the initial stages of the game.

This figure illustrates the interaction process between the LLM and the TextStarCraft II environment using the Chain of Summarization (CoS) method. The process is divided into several stages: initialization, single-frame and multi-frame summarization, directive formulation and action scheduling, action retrieval and execution. Each stage is clearly shown in the diagram and contains important information, such as the interaction between different components and the flow of data. The diagram visually demonstrates how the CoS method improves LLM performance by processing and summarizing game data in real-time, leading to more efficient and effective decision-making within the TextStarCraft II environment.

This figure illustrates the interaction between the LLM and the TextStarCraft II environment using the Chain of Summarization (CoS) method. The process begins with the conversion of raw game observations into text, followed by single-frame and multi-frame summarization to extract key information. This information is then used for strategic planning and decision-making, resulting in the generation of actions that are executed in the game environment. The cycle repeats, continuously feeding new information back into the LLM to enhance performance.

This figure illustrates the interaction process between the LLM and TextStarCraft II using the Chain of Summarization (CoS) method. It shows how the raw observations from the game are converted into text, summarized, and analyzed by the LLM to generate actionable insights and decisions which are then sent back to the game environment for execution.

This figure shows a comparison between AlphaStar and the LLM agent in terms of their ability to anticipate and respond to potential threats. In the left panel (AlphaStar), the AI agent fails to construct preemptive defensive structures, leaving its base vulnerable to attack. In contrast, the right panel (LLM agent) shows the agent proactively constructing defense structures (Shield Batteries) after identifying enemy units. This highlights the superior strategic foresight and decision-making capabilities of the LLM agent.

This figure compares the strategic decision-making capabilities of AlphaStar and the LLM agent in StarCraft II. The left panel (AlphaStar) shows a failure to construct preemptive defensive structures (Spore Crawlers) against an Oracle harassment, resulting in inadequate defensive capabilities. Conversely, the right panel (LLM agent) demonstrates proactive defense by constructing Shield Batteries ahead of time, showcasing the LLM agent’s ability to anticipate and respond to potential threats.
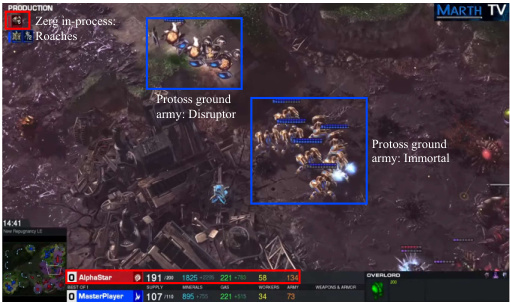
This figure shows a comparison between AlphaStar and the LLM agent’s strategic decision-making in a StarCraft II scenario. The left panel (AlphaStar) depicts a failure to anticipate and defend against an Oracle attack, while the right panel (LLM agent) showcases proactive defense by constructing Shield Batteries before an attack. This highlights the difference in strategic decision-making and interpretability between these two systems.

This figure compares the strategic decision-making abilities of AlphaStar and the LLM agent in a StarCraft II scenario. Panel (a) shows AlphaStar’s failure to anticipate an attack by Oracles, leading to its base being vulnerable. In contrast, panel (b) illustrates the LLM agent’s proactive defensive measures, such as building Shield Batteries before the attack, demonstrating superior strategic thinking and threat anticipation. This highlights a key difference in the strategic reasoning between the two agents, with the LLM agent showing a more comprehensive understanding of strategic defensive strategies.
This figure shows screenshots from a StarCraft II game featuring an LLM agent playing as Protoss. The screenshots illustrate the agent’s early and mid-game strategies, highlighting its defensive measures (such as building Shield Batteries) and proactive scouting efforts (using a Probe to scout the enemy base). The images visually demonstrate the agent’s ability to gather key game information and make strategic decisions in real-time, using text-based commands to interact with the game environment.
This figure uses two screenshots from StarCraft II gameplays to highlight the difference in strategic thinking between AlphaStar and the LLM agent. The left side shows AlphaStar failing to construct defensive structures against an incoming attack, while the right side shows the LLM agent proactively building defenses and anticipating the attack. This illustrates the LLM agent’s superior strategic awareness and forward-thinking capabilities.
This figure illustrates the workflow of the Chain of Summarization (CoS) method used in TextStarCraft II. It shows how the LLM interacts with the game environment, processing observations, generating summaries, making decisions, and executing actions in a continuous loop. The CoS method refines and summarizes observations into actionable insights, improving the LLM’s decision-making efficiency within a complex real-time strategy game environment.
This figure showcases a comparison of AlphaStar and the LLM agent’s strategic decision-making processes in StarCraft II. The left panel depicts AlphaStar’s failure to construct preemptive defensive structures against an Oracle attack, highlighting its inability to proactively assess threats. The right panel shows the LLM agent’s proactive defense, constructing Shield Batteries ahead of time based on its analysis of the enemy’s strategy. This illustrates the LLM agent’s superior ability to anticipate threats and make informed strategic decisions.

This figure illustrates the workflow of the Chain of Summarization (CoS) method used in TextStarCraft II. It shows how the LLM interacts with the game environment, processing observations, generating summaries, formulating directives, and executing actions in a continuous loop. The key components highlighted are the Observation-to-Text Adapter, the Single-Frame Summarization, the Multi-Frame Summarization, the Action Scheduling, and the Text-to-Action Adapter, emphasizing the iterative process between the LLM and the game.
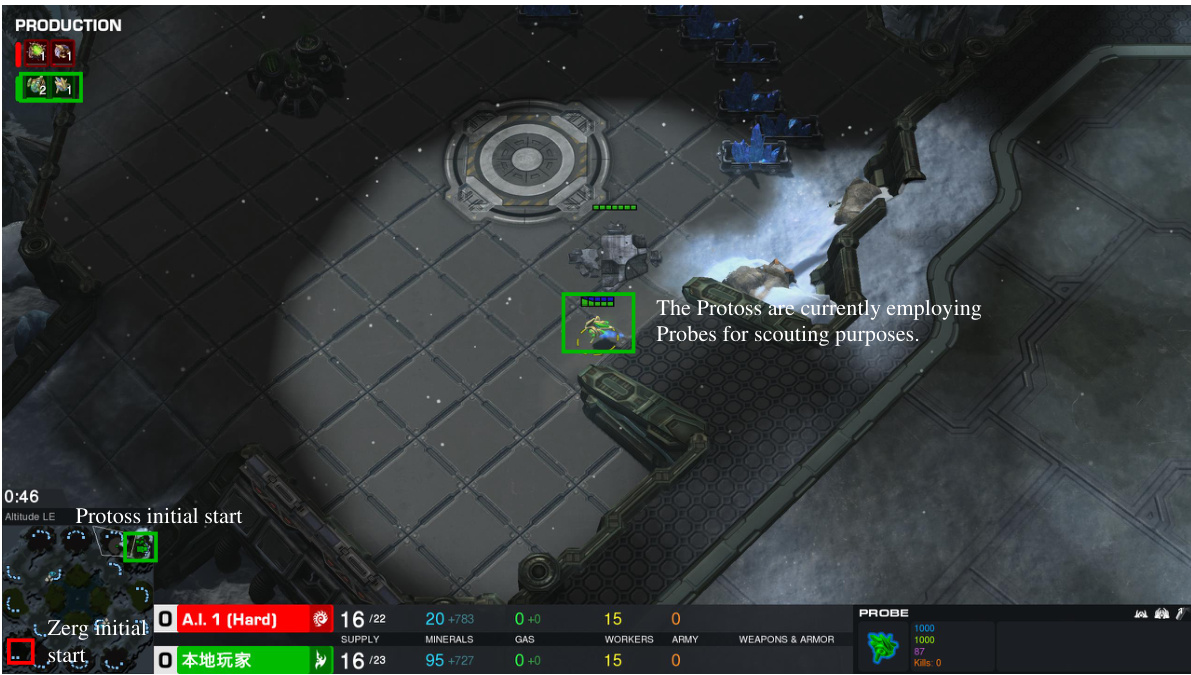
This figure shows two screenshots from a StarCraft II game where an LLM agent is playing as the Protoss race. The first image (a) highlights the early game scouting strategy of the Protoss, using a Probe to scout the enemy’s base location. This demonstrates the agent’s proactive approach to gathering information. The second image (b) showcases the mid-game defensive strategy, with the Protoss constructing Shield Batteries, indicating a focus on protecting their base against potential attacks from the Zerg opponent.

This figure illustrates the process of the Chain of Summarization method in TextStarCraft II environment. The process starts with the initialization of the game, where game data is converted into textual information that the LLM can process. Then the single-frame and multi-frame summarization modules summarize the observation data into concise and actionable insights for decision-making. After the summarization, the directive formulation module formulates actions based on the summarization results, and these formulated actions are queued for execution. In the final step, the action retrieval module retrieves the actions from the queue and executes the actions in the game. The process repeats by continually converting new game data into text for processing, which improves the LLM’s performance.
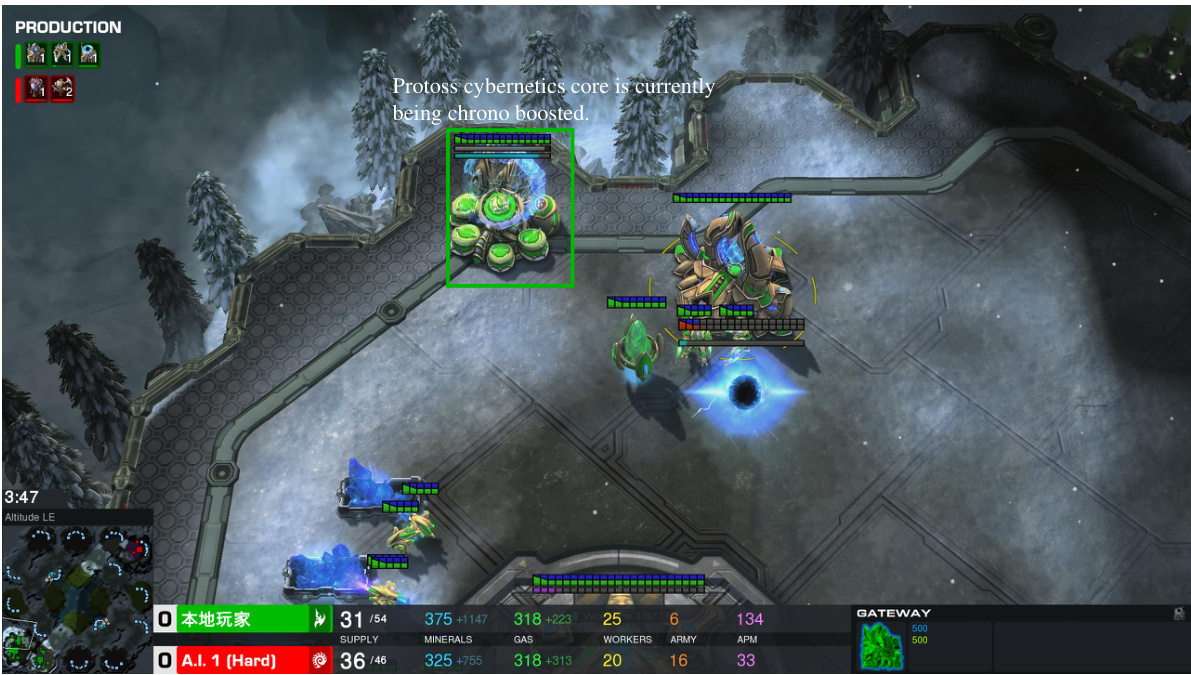
This figure illustrates the interaction between the LLM and the TextStarCraft II environment using the Chain of Summarization (CoS) method. It details the various stages involved in processing observations, forming directives, and executing actions within the game. The cyclical nature of the process, continuously converting game data into text for LLM processing, is emphasized.

This figure illustrates the process of the Chain of Summarization method used in TextStarCraft II. It starts with the initialization of the game state converted into text. Then it goes through Single-Frame and Multi-Frame Summarization, which refine and summarize the observations into actionable insights using advanced LLM reasoning. The actionable insights are then converted into specific actions for the game and queued for execution. The whole cycle demonstrates how the model continually converts new data into text to enhance its performance in the game.
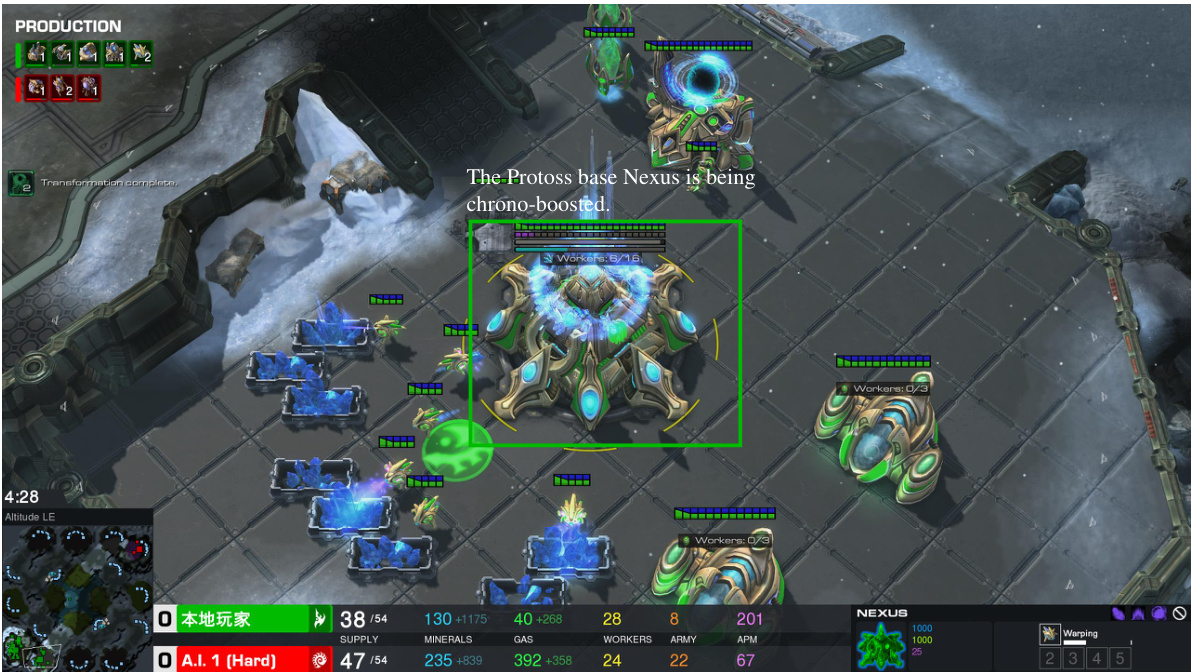
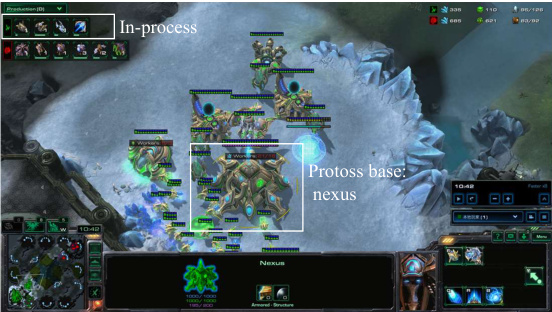
This figure shows a screenshot of the StarCraft II game, highlighting the LLM agent’s decision to use the Chrono Boost ability on the Nexus. The Chrono Boost ability accelerates production and research speed within the game, indicating a strategic decision by the LLM to expedite its base development and potentially counter the opponent’s actions. The specific timing and context surrounding this decision are crucial to understanding its strategic significance within the dynamic gameplay environment.

This figure illustrates the workflow of the Chain of Summarization (CoS) method within the TextStarCraft II environment. The process starts with converting observations into text, summarizing the data using single and multi-frame summarization, formulating actionable directives, and executing actions within the game, which is then used to generate further observations, creating a closed-loop system for LLM interaction within the game.
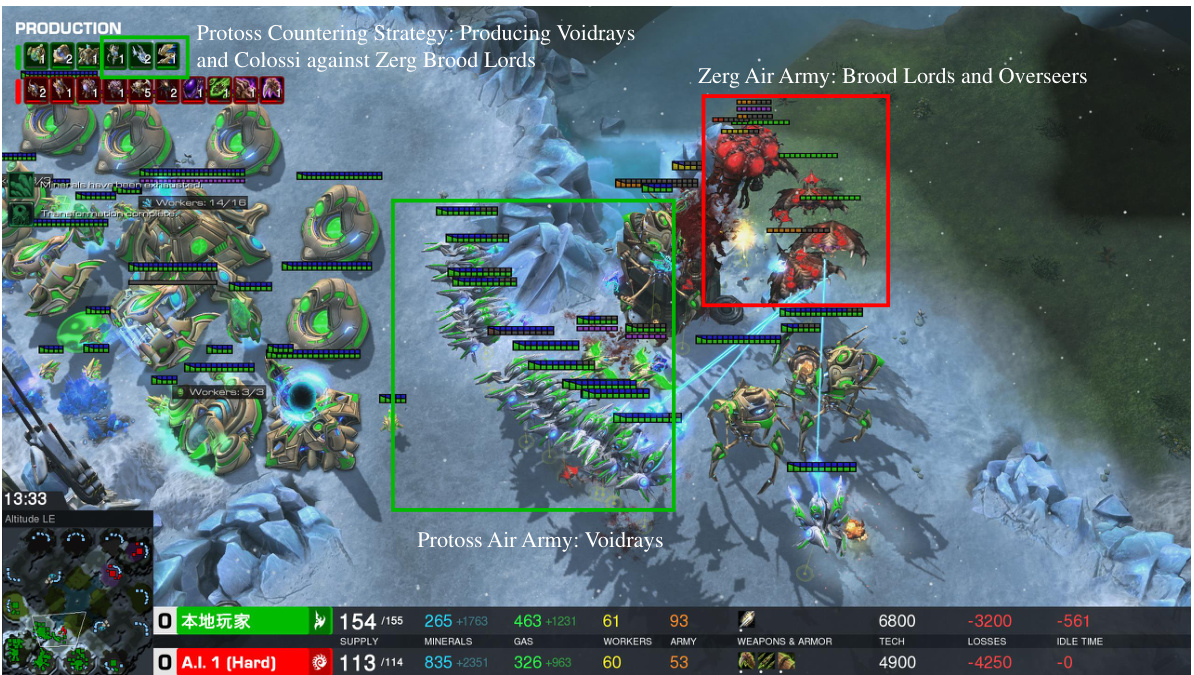
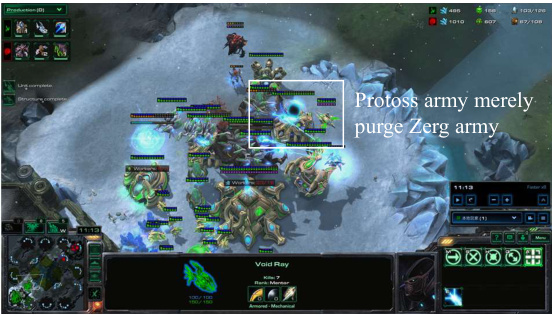
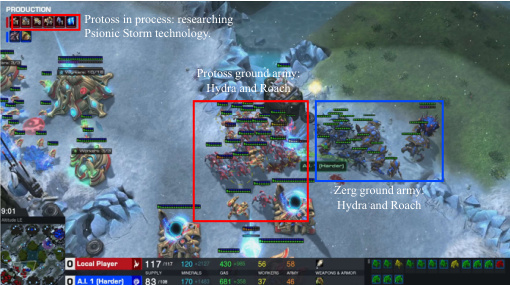
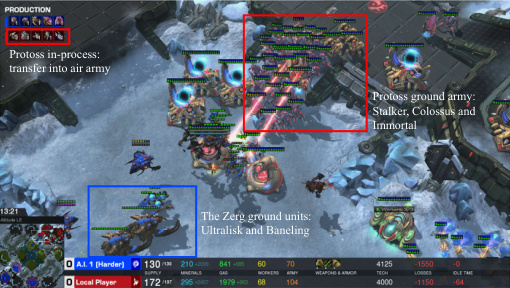
This figure shows a screenshot of a StarCraft II game in progress, illustrating the LLM agent’s (playing as Protoss) strategic response to the opponent’s (Zerg) air-based attack. The Protoss’s response involves a shift in unit production towards Void Rays and Colossi to counter the Zerg’s Brood Lords and Overseers. The image showcases the game’s interface, including resource levels, unit counts, and the ongoing actions. The caption emphasizes the LLM agent’s adaptive strategic decision-making in real-time.
More on tables

This table presents the win rates of various LLMs fine-tuned on different datasets against the level 5 built-in AI in the TextStarCraft II environment. The datasets vary in composition: a full dataset of all games, a dataset containing only winning games, and subsets of winning games categorized by their APU (Average Population Utilization) performance percentile (bottom 25%, 50-75%, 25-50%, top 25%). The win rates illustrate the impact of dataset composition and data quality on the performance of fine-tuned LLMs.

This table presents the results of matches between a fine-tuned Qwen1.8B LLM agent and human players of varying skill levels. The results show the win/loss ratio of the LLM agent against each human player.

This table presents the win rates of an LLM agent playing as Protoss against a Zerg AI opponent in TextStarCraft II at six different difficulty levels (LV1-LV6). Two different prompts (PROMPT 1 and PROMPT 2) were used, each designed to elicit a different level of strategic complexity from the LLM. The win rate is presented as a percentage of games won by the LLM agent out of the total games played at each difficulty level. This table demonstrates how the complexity of the prompt influences the LLM’s performance in the game.

This table presents the performance comparison of various LLMs against the level 5 built-in AI in the TextStarCraft II environment. The LLMs were tested using two different methods: the full Chain of Summarization (CoS) approach and a CoS method without Chain of Thought (CoT). The table shows the win rate, population block ratio (PBR), resource utilization ratio (RUR), average population utilization (APU), and technology rate (TR) for each LLM and method. Appendix A.2 provides detailed explanations of the evaluation metrics.

This table presents the performance of various LLMs (Large Language Models) in the TextStarCraft II environment, which is a game environment based on StarCraft II. The LLMs are tested against the built-in AI at level 5, and their performance is measured using several metrics, such as win rate, PBR (Population Block Ratio), RUR (Resource Utilization Ratio), APU (Average Population Utilization), and TR (Technology Rate). The table compares the performance of LLMs using the full Chain of Summarization (CoS) method and CoS without Chain of Thought (CoT).

This table presents the performance comparison of various LLMs tested against the level 5 built-in AI in the TextStarCraft II environment. The LLMs were evaluated using two different methods: the full Chain of Summarization (CoS) method and the CoS method without Chain of Thought (CoT). The table shows the win rate, Population Block Ratio (PBR), Resource Utilization Ratio (RUR), Average Population Utilization (APU), and Technology Rate (TR) for each LLM and method. Appendix A.2 provides detailed explanations of these metrics.
Full paper#