↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multimodal Large Language Models (MLLMs) demonstrate impressive capabilities but suffer from extremely long pre-training times due to the extensive use of visual tokens. This significantly hinders research progress and resource consumption. The existing methods usually maintain a constant set of visual tokens across pre-training and fine-tuning, which reduces efficiency.
To address this, the researchers propose Chain-of-Sight, which employs a sequence of visual resamplers capturing visual details at multiple scales. This allows for flexible expansion of visual tokens during fine-tuning, while using significantly fewer tokens during pre-training. This drastically reduces the pre-training wall-clock time by around 73% without compromising the final performance. The flexible token scaling strategy also enables fine-tuning with a higher number of tokens for enhanced performance.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multimodal LLMs due to its focus on pre-training acceleration without performance loss. It introduces a novel method with potential for wider adoption, impacting the field’s sustainability and fostering further research into efficient model training techniques, especially with large datasets. The post-pretrain token scaling strategy is particularly significant, paving the way for more adaptable and efficient model training.
Visual Insights#

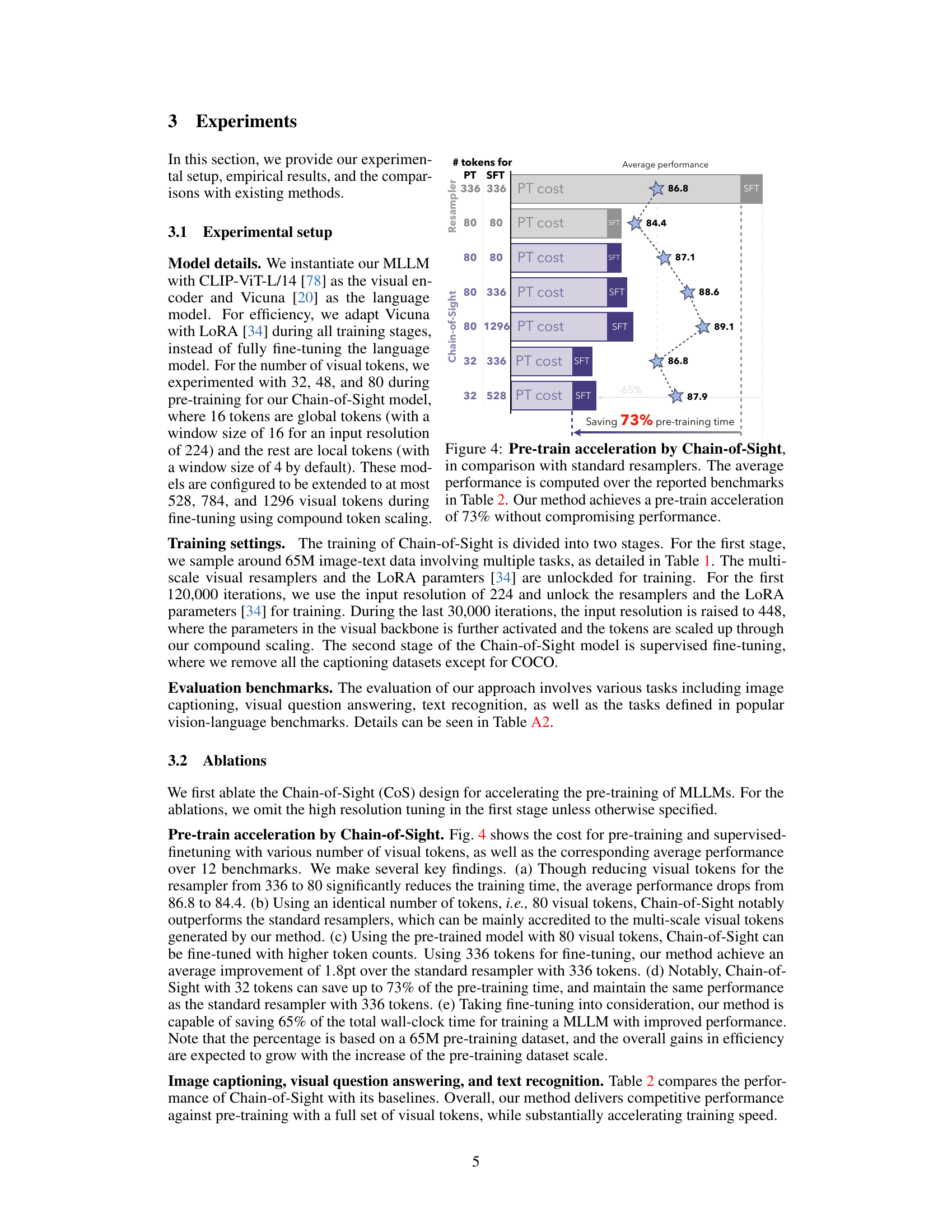
This figure illustrates the core concept of Chain-of-Sight. Existing Multimodal Large Language Models (MLLMs) use a fixed number of visual tokens during both pre-training and fine-tuning. Chain-of-Sight, in contrast, employs a multi-scale approach. It starts with fewer visual tokens in the pre-training phase, capturing visual information at multiple scales. Then, a token scaling strategy increases the number of tokens for the fine-tuning stage. This approach significantly reduces pre-training time (by ~73% as indicated in the figure) without compromising performance.

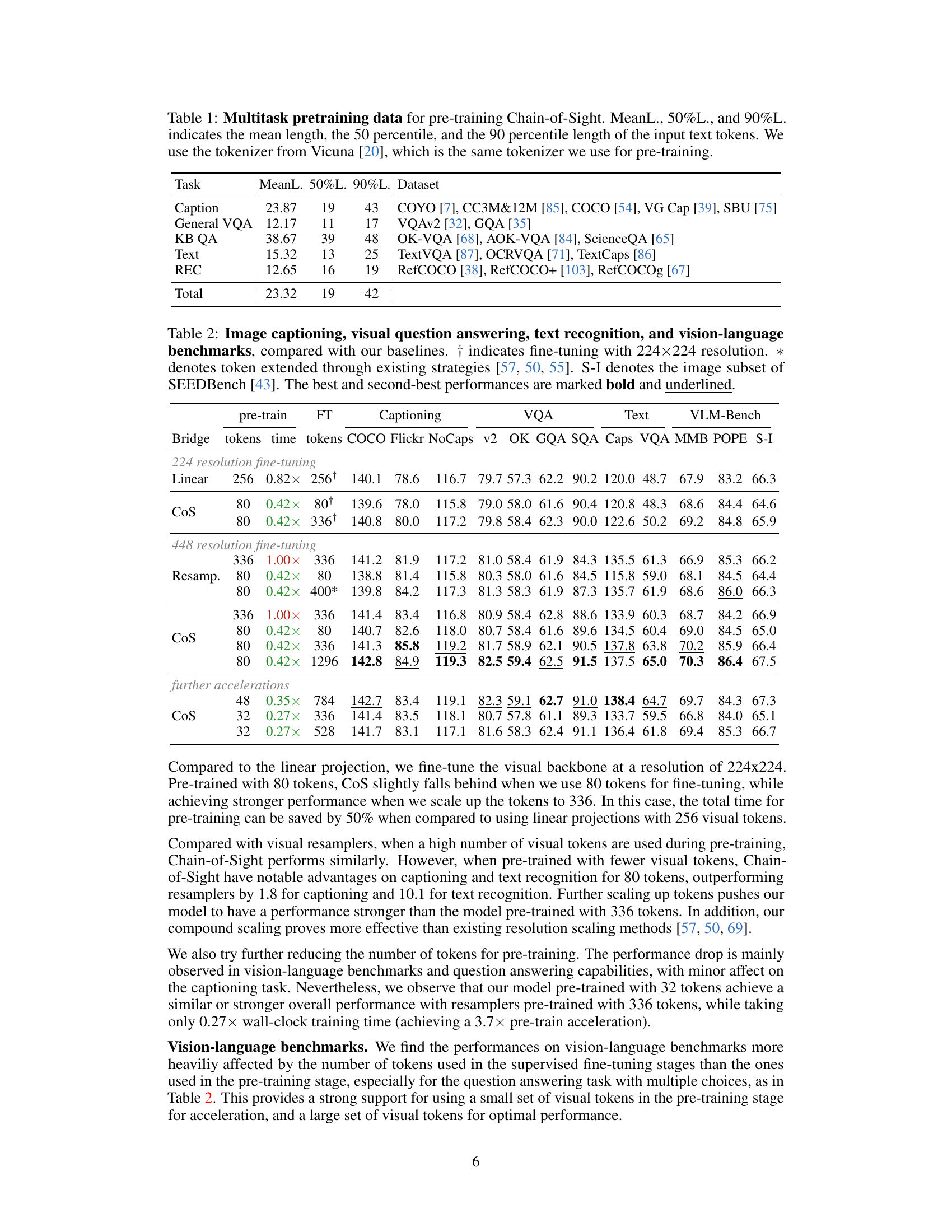
This table presents the dataset statistics used for pre-training the Chain-of-Sight model. It shows the mean, 50th percentile, and 90th percentile lengths of the input text tokens for various tasks included in the multitask pre-training. The datasets used for each task (captioning, general visual question answering, knowledge-based question answering, text-based tasks, and referring expression comprehension) are listed. The tokenizer used is the same as in the Vicuna model.
In-depth insights#
Multimodal LLM Speedup#
The research paper explores methods to accelerate the pre-training of Multimodal Large Language Models (MLLMs). A core challenge is the computational cost associated with processing the vast number of visual tokens typically used. The proposed Chain-of-Sight module tackles this by introducing a multi-scale visual resampling strategy, capturing visual details at various scales. This approach significantly reduces the visual token count during pre-training without compromising performance. A post-pretraining token scaling strategy allows for flexible expansion of visual tokens during fine-tuning, achieving a balance between efficient pre-training and high performance. The results demonstrate substantial speedup, specifically a ~73% reduction in wall-clock training time, making the pre-training process much more efficient. The key is the intentional reduction of visual tokens during pre-training, contrasting with typical approaches that use a consistent number throughout training. This highlights a significant potential for optimization in MLLM training. The multi-scale resampling and compound scaling strategy are key innovations that enable this efficiency gain.
Chain-of-Sight Module#
The Chain-of-Sight module is a novel vision-language bridging component designed to significantly accelerate the pre-training of Multimodal Large Language Models (MLLMs). Its core innovation lies in employing a sequence of visual resamplers that capture visual details at multiple spatial scales, enabling the model to leverage both global and local visual contexts effectively. This multi-scale approach, coupled with a flexible token scaling strategy, allows for a substantial increase in the number of visual tokens during fine-tuning while keeping it minimal during pre-training. This intentional reduction of visual tokens during the computationally expensive pre-training phase drastically cuts down training time without compromising performance, achieving a remarkable ~73% reduction in wall-clock time. The module’s ability to scale tokens post-pre-training ensures the model can capture a rich level of visual detail during fine-tuning, which is crucial for effective vision-language understanding. In essence, Chain-of-Sight cleverly addresses the computational bottleneck of MLLM pre-training by intelligently managing the number of visual tokens processed, demonstrating that strong performance can be achieved through efficient pre-training strategies without sacrificing performance.
Token Scaling Strategy#
The paper introduces a novel “Token Scaling Strategy” to significantly accelerate the pre-training of Multimodal Large Language Models (MLLMs) without sacrificing performance. This strategy cleverly addresses the computational bottleneck inherent in processing a large number of visual tokens during pre-training. By initially using a significantly reduced set of visual tokens, the pre-training phase is accelerated dramatically (~73% reduction in wall-clock time). This reduction is achieved through the introduction of a multi-scale visual resampler and a post-pretrain token scaling strategy. The multi-scale resampler captures visual details at various spatial scales, efficiently encoding both global and local visual contexts. Subsequently, the post-pretrain token scaling mechanism enables a flexible extension of the visual tokens, allowing for a substantial increase (up to 16x) in the number of tokens during the fine-tuning phase. This approach ensures that the model can effectively capture a rich level of visual detail during fine-tuning while still leveraging the efficiency gains from using fewer visual tokens during pre-training. The results demonstrate that this two-stage approach achieves competitive performance against existing methods, highlighting the potential of this innovative token scaling strategy to improve both the efficiency and effectiveness of MLLM pre-training.
Pre-train Efficiency Gains#
The paper’s core innovation lies in accelerating the pre-training of multimodal large language models (MLLMs) by significantly reducing the number of visual tokens processed during this stage. Chain-of-Sight, the proposed method, achieves this through a multi-scale visual resampling strategy and a subsequent token scaling approach. By strategically using fewer visual tokens during pre-training, the computational cost is drastically reduced, resulting in substantial time savings (~73% reduction reported). This efficiency gain is not at the expense of performance; the model’s accuracy on various downstream benchmarks either matches or surpasses traditional methods that utilize a consistent high number of visual tokens throughout training. The key is to selectively increase the number of visual tokens in the fine-tuning phase, allowing the model to capture finer visual details without the excessive computational demands of pre-training. This approach represents a major advance in MLLM training, opening avenues for more efficient and scalable model development.
Future Research#
Future research directions stemming from this work on accelerating multimodal LLMs could explore several promising avenues. Improving the multi-scale visual resamplers is crucial; more sophisticated techniques for capturing visual context at various scales could significantly enhance performance. Investigating alternative token scaling strategies beyond the compound approach presented here could unlock further efficiency gains. Exploring different architectural designs for the vision-language bridge module may reveal more effective ways to integrate visual and textual information. Furthermore, applying Chain-of-Sight to other multimodal LLMs and datasets would broaden its applicability and reveal potential limitations. Finally, a detailed study on the trade-off between training speed and performance across different model sizes and datasets would provide valuable insights for optimizing the pre-training process.
More visual insights#
More on figures
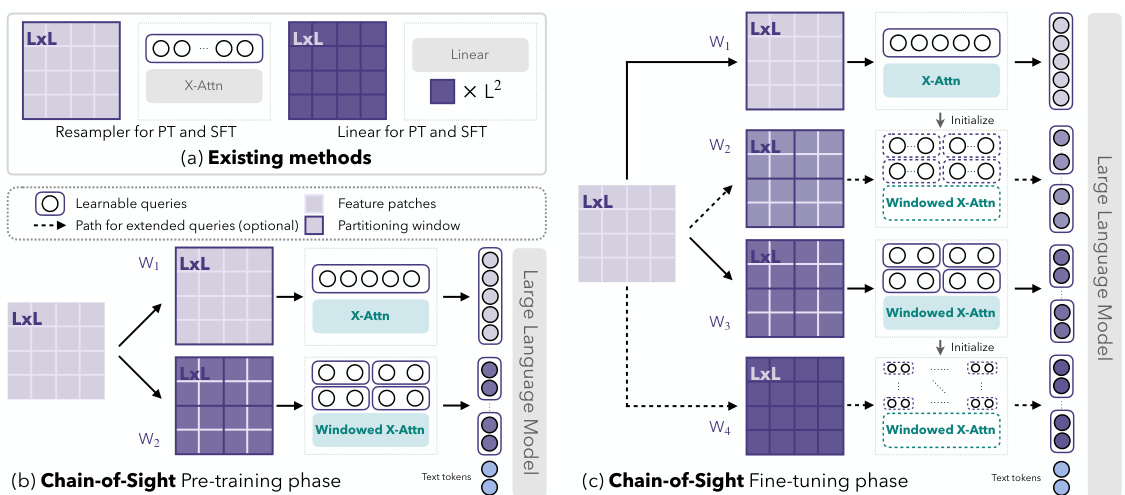
This figure illustrates the Chain-of-Sight framework, comparing it to existing methods. Existing methods use either resamplers or linear layers to generate visual tokens, maintaining a constant number throughout training. In contrast, Chain-of-Sight partitions visual features into windows of various sizes, creating multi-scale visual tokens. The post-pretrain token scaling allows for a reduction in visual tokens during pre-training, accelerating the process without sacrificing performance in fine-tuning. The figure shows the process for both pre-training and fine-tuning phases.
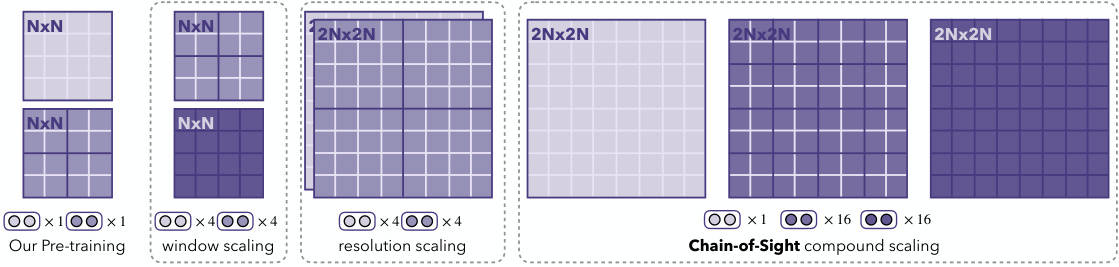
This figure illustrates the Chain-of-Sight’s post-pretrain token scaling strategy. It shows how the number of visual tokens can be increased after the pre-training phase using a combination of resolution scaling and window scaling. The leftmost panel shows the initial visual tokens used during pre-training. The next panel shows how increasing the number of windows within a given resolution increases token numbers (window scaling). The third panel shows how using higher resolution images increases token numbers (resolution scaling). Finally, the rightmost panel combines resolution and window scaling to achieve a significant increase in the number of visual tokens used during fine-tuning, which allows Chain-of-Sight to achieve high performance while significantly reducing the number of tokens needed during the computationally expensive pre-training phase.
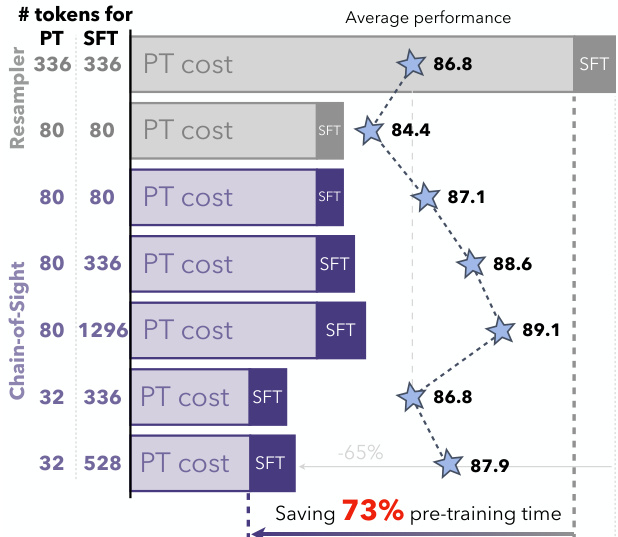
This figure shows the pre-training time and average performance comparison between Chain-of-Sight and standard resamplers. The x-axis represents the different model configurations with varying numbers of visual tokens used during pre-training (PT) and fine-tuning (SFT). The y-axis shows the average performance across multiple benchmarks. Chain-of-Sight achieves a 73% reduction in pre-training time while maintaining comparable or even slightly better performance compared to standard resamplers.
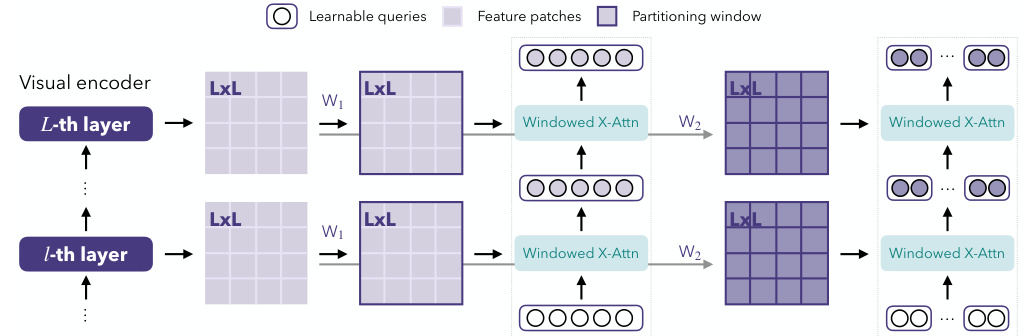
This figure illustrates the Chain-of-Sight framework, comparing it to existing methods. It shows how Chain-of-Sight partitions visual features into windows, uses windowed cross-attention with learnable tokens to generate multi-scale visual tokens, and leverages a post-pretrain token scaling strategy to reduce the number of visual tokens needed during pre-training, thereby accelerating the process. The figure highlights the differences in visual token handling between Chain-of-Sight and existing methods (resampler-based and linear-layer approaches), emphasizing the efficiency gains achieved by Chain-of-Sight.
More on tables

This table presents a comparison of the Chain-of-Sight model’s performance against baseline models across various vision-language benchmarks. The benchmarks include image captioning, visual question answering, text recognition, and several vision-language tasks. The table shows performance metrics (e.g., accuracy scores) for different model configurations (with varying numbers of visual tokens during pre-training and fine-tuning) and compares them to existing methods. The results highlight the model’s performance and efficiency gains, even with significantly fewer visual tokens used during the pre-training stage.
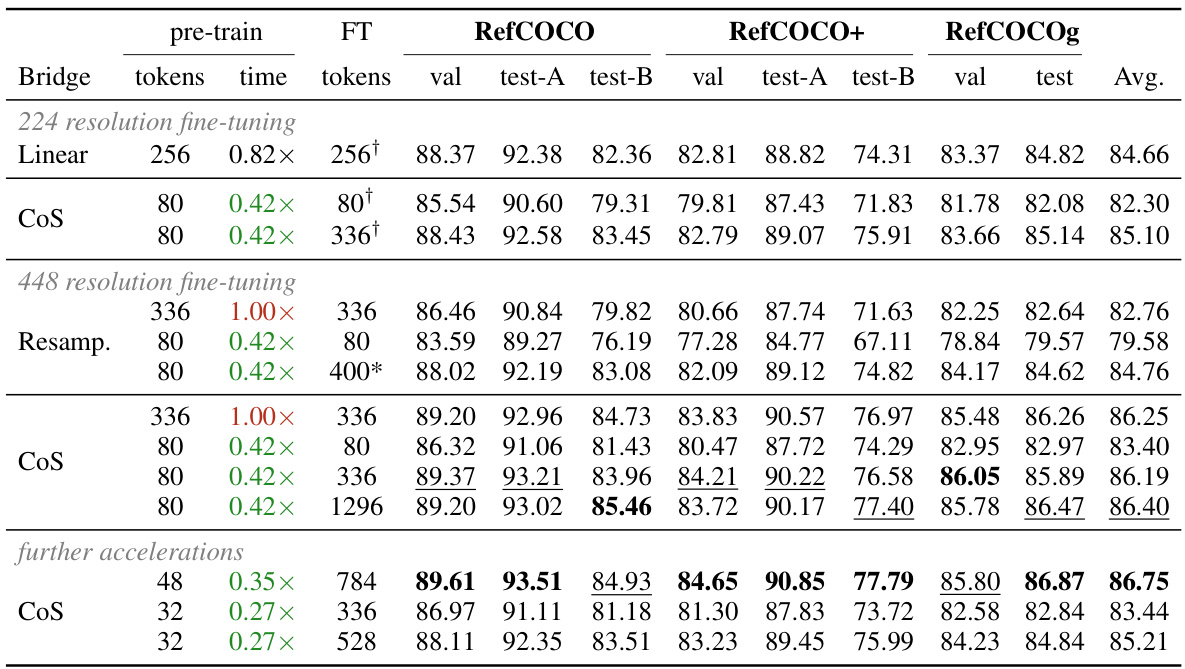
This table presents the results of image captioning, visual question answering, text recognition, and vision-language benchmark experiments. The performance of the Chain-of-Sight model is compared against several baseline methods under different conditions (224x224 and 448x448 resolution fine-tuning, different numbers of tokens). The use of * indicates that token extension was performed using existing strategies, and † indicates fine-tuning with a 224x224 resolution. The best and second-best performing models are highlighted in bold and underlined, respectively. The S-I column represents results from the image subset of the SEEDBench dataset.
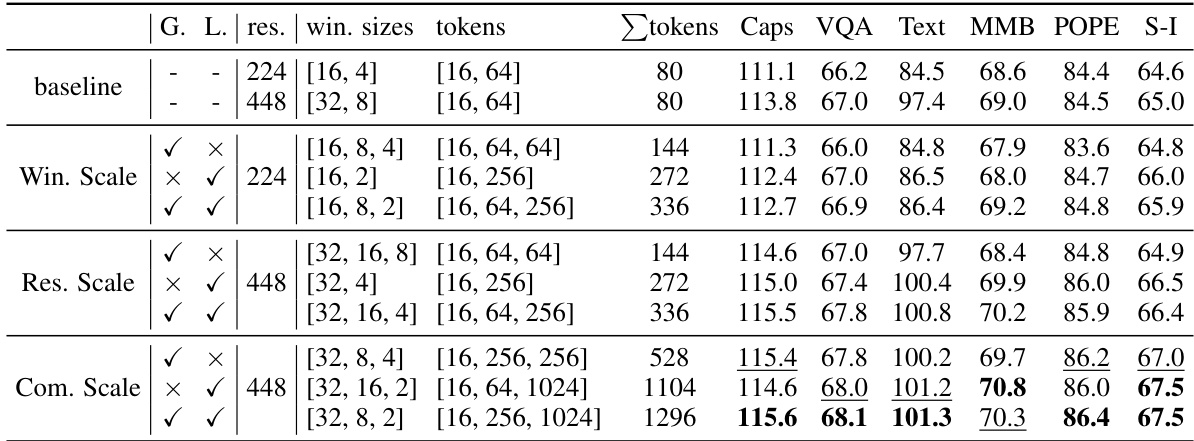
This table presents a comparison of the Chain-of-Sight model’s performance against baseline models across various vision-language benchmarks. The benchmarks cover image captioning, visual question answering, text recognition, and other vision-language tasks. The results show performance with different numbers of visual tokens during fine-tuning, along with a comparison to the standard approach of using all visual tokens throughout the entire training process. The table also highlights the time savings achieved by Chain-of-Sight’s pre-training acceleration.
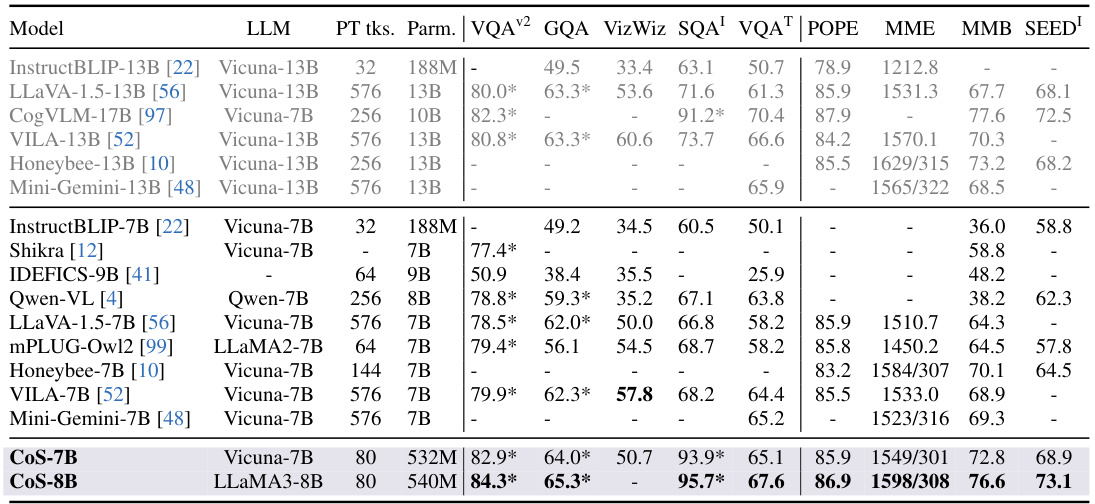
This table compares the performance of the Chain-of-Sight model against several baselines across a range of vision-language benchmarks, including image captioning, visual question answering, text recognition, and other vision-language tasks from the SEEDBench. The results show the performance (measured using various metrics depending on the specific task) of each model under different configurations, considering both the pre-training and fine-tuning phases. Noteworthy is that the table shows the impact of scaling up the token count during the fine-tuning phase.
This table presents a comparison of the Chain-of-Sight model’s performance against several baseline models across various vision-language benchmarks. It shows the results for image captioning, visual question answering, and text recognition tasks. The table highlights the performance gains achieved by Chain-of-Sight, particularly when using a smaller number of visual tokens during pre-training but scaling them up during fine-tuning. The impact of different resolutions (224x224 and 448x448) during fine-tuning is also shown. The use of existing token extension strategies is noted, and the best-performing models are clearly marked.

This table presents the dataset statistics used for pre-training the Chain-of-Sight model. It lists the mean, 50th percentile, and 90th percentile lengths of the input text tokens for various tasks, including captioning, visual question answering, knowledge-based question answering, and referring expression comprehension. The datasets used for each task are also specified. The tokenizer used is the same as the one used in the pre-training phase of the model.
This table presents a comparison of the Chain-of-Sight model’s performance against baseline models across various vision-language benchmarks. It shows results for image captioning, visual question answering, text recognition, and other vision-language tasks. The table highlights the performance gains achieved by Chain-of-Sight, particularly when using different numbers of tokens and resolutions during fine-tuning. The use of existing token-extension strategies is also noted.
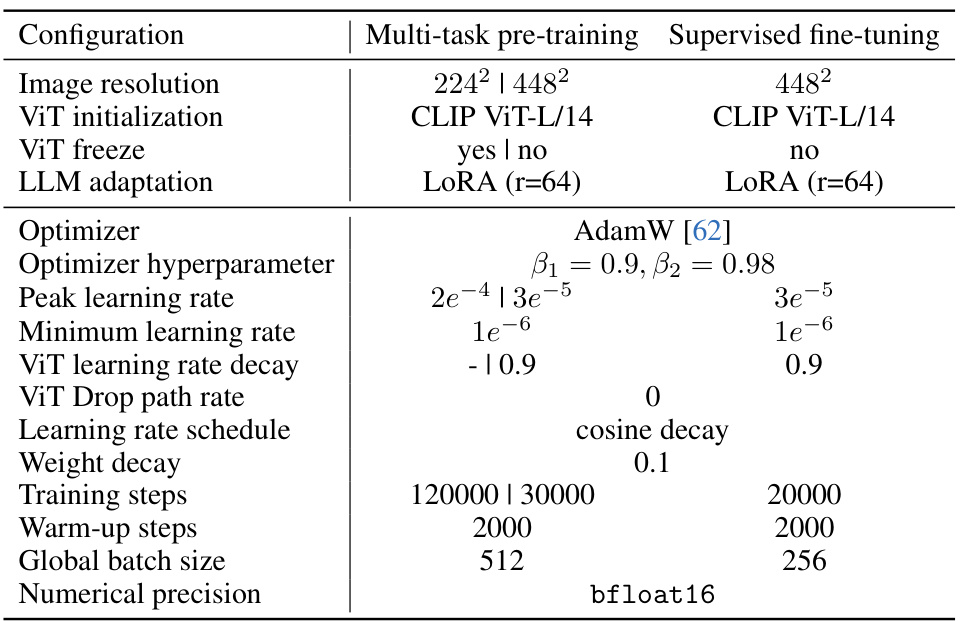
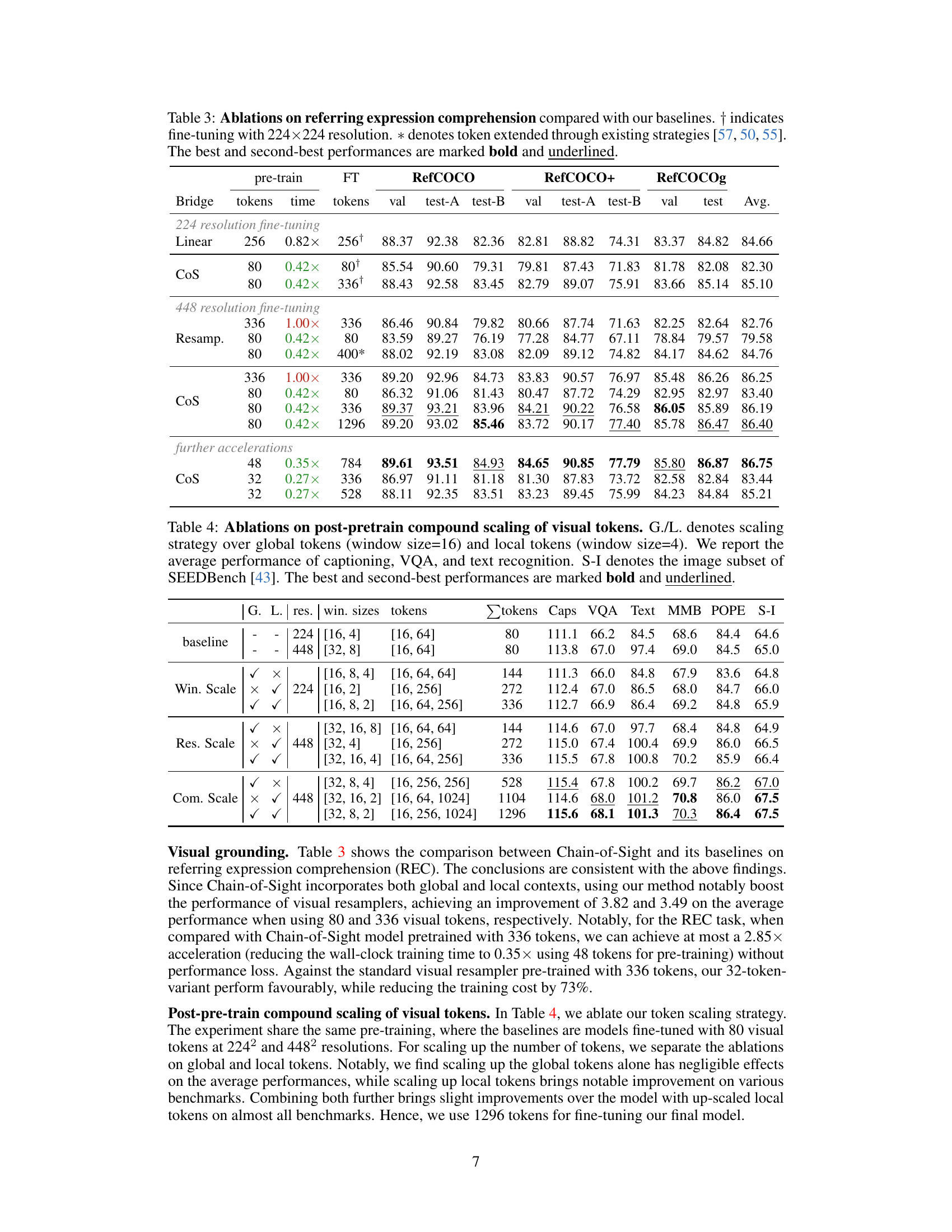
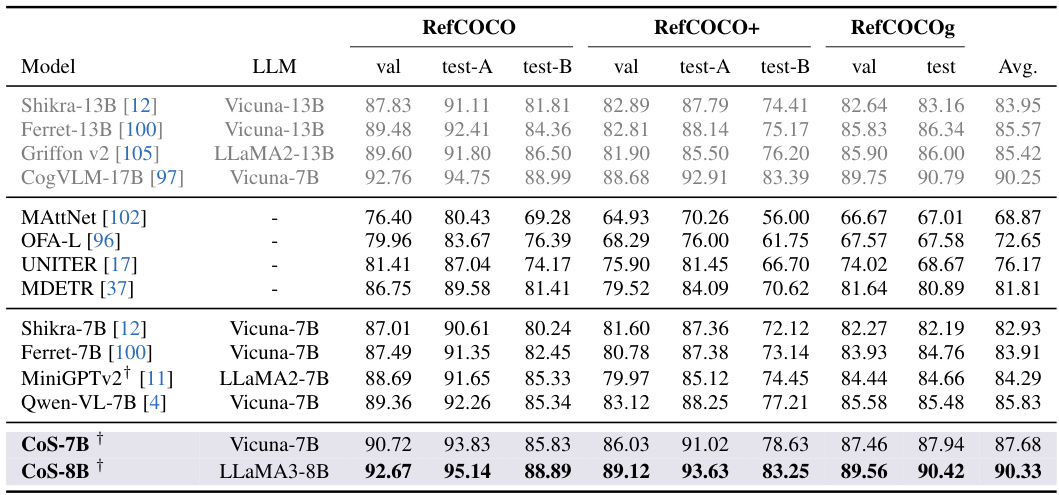
This table presents the ablation study results on referring expression comprehension (REC) task. It compares the performance of Chain-of-Sight (CoS) with baseline methods under different settings of visual token numbers and resolutions. The results demonstrate the impact of different factors such as number of visual tokens, fine-tuning resolution, and usage of existing strategies on the final REC performance.

This table presents further empirical results obtained from the experiments conducted in the paper. It compares the performance of two models, CoS-7B and CoS-8B, across various vision-language benchmarks. The benchmarks are categorized into three groups: Regular, MMBench, and Other. Each group contains multiple tasks, with performance measured using different metrics depending on the task. The abbreviations used in the column headers indicate the specific benchmarks or aspects being evaluated (e.g., OK for OK-VQA, COCO for COCO Captions). The table aims to provide a comprehensive evaluation of the models’ performance across diverse and challenging tasks.
Full paper#