↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are increasingly used for code generation, but the generated code often suffers from inefficiency, resulting in longer execution times and higher memory consumption. This inefficiency hinders the practical application of LLMs in various scenarios, especially resource-constrained environments like mobile or embedded systems. Existing research mainly focuses on code correctness, neglecting the critical aspect of efficiency.
To address this, EFFI-LEARNER, a self-optimization framework, is proposed. It leverages execution overhead profiles to iteratively refine LLM-generated code. The framework first generates code, then profiles its execution time and memory usage. These profiles are fed back into the LLM to revise the code, iteratively improving efficiency. Experiments show that EFFI-LEARNER significantly enhances the efficiency of LLM-generated code across various models and benchmarks, substantially reducing execution time and memory consumption.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) for code generation. It directly addresses the critical issue of inefficient LLM-generated code, a significant hurdle in practical applications. By introducing a self-optimization framework, the research offers a practical solution and opens new avenues for improving LLM efficiency and pushing the boundaries of automated code generation.
Visual Insights#
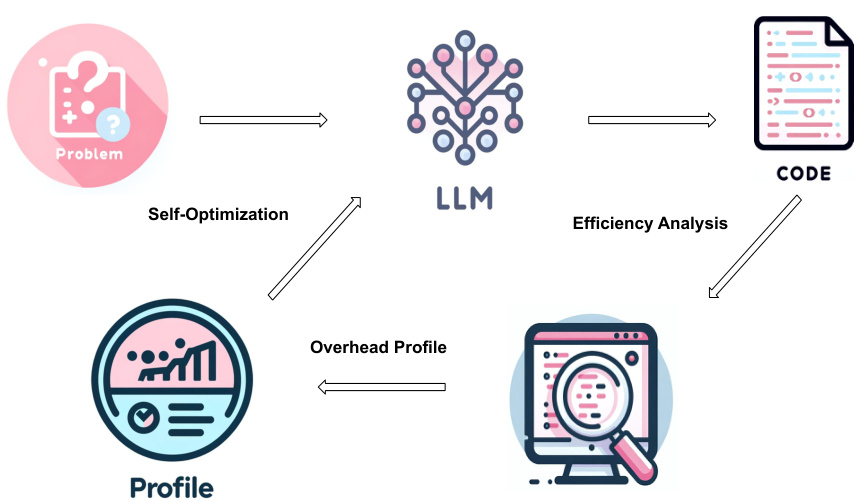
This figure illustrates the workflow of the EFFI-LEARNER framework. It begins with an LLM generating code for a given problem. This code is then executed to create an overhead profile (execution time and memory usage). This profile is fed back into the LLM, which then refines the code to improve efficiency. This iterative process of code generation, profiling, and refinement continues until the desired level of efficiency is achieved. The appendix contains more detailed diagrams illustrating specific aspects of this process.

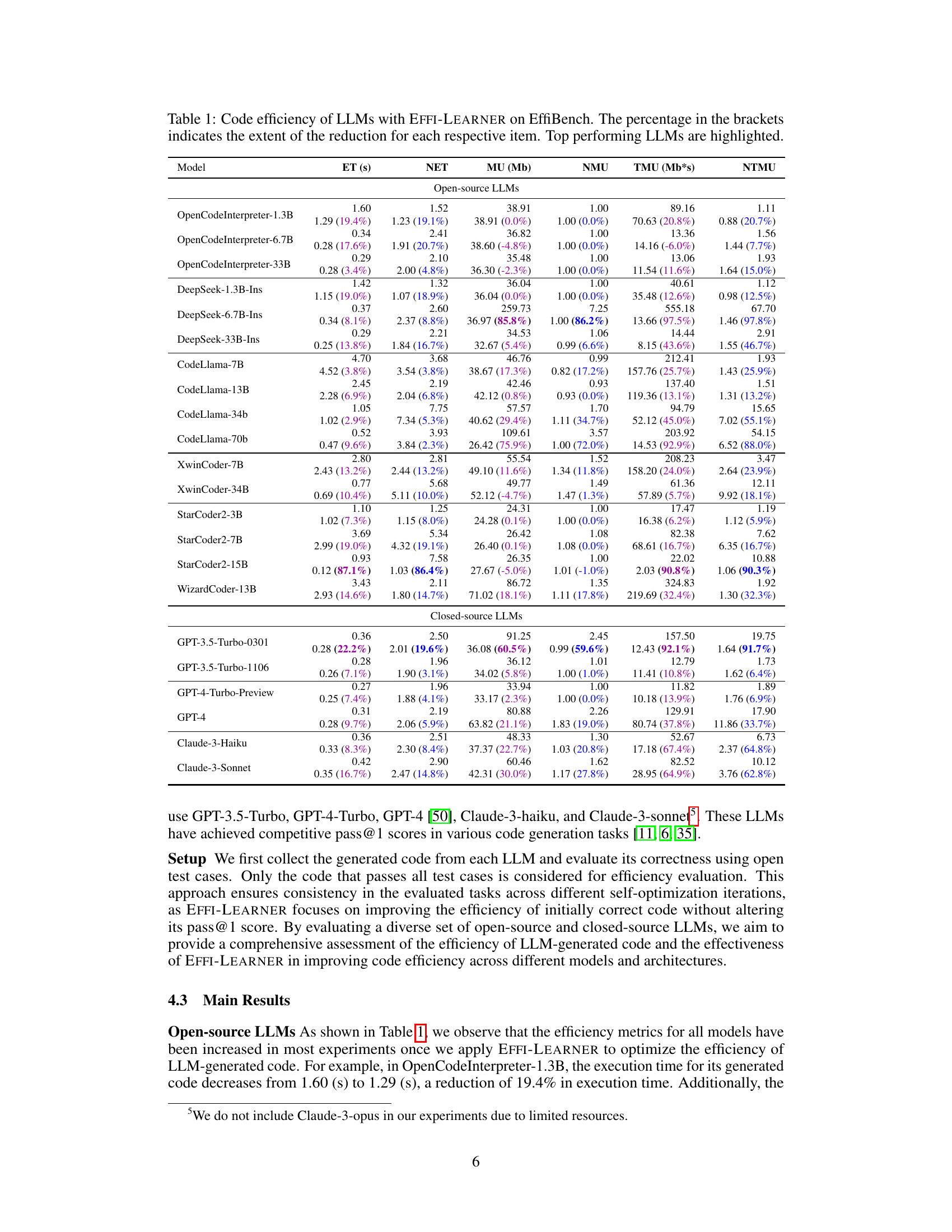
This table presents the results of evaluating the code efficiency of various LLMs (Large Language Models) on the EffiBench benchmark, both before and after optimization using the proposed EFFI-LEARNER framework. The metrics used to evaluate efficiency include Execution Time (ET), Normalized Execution Time (NET), Max Memory Usage (MU), Normalized Max Memory Usage (NMU), Total Memory Usage (TMU), and Normalized Total Memory Usage (NTMU). The percentage values in parentheses represent the reduction in each metric achieved after optimization by EFFI-LEARNER. The table highlights the top-performing LLMs after optimization.
In-depth insights#
LLM Code Inefficiency#
Large language models (LLMs) have made significant strides in code generation, but a critical challenge remains: inefficient code generation. LLM-produced code often suffers from suboptimal performance, exhibiting longer execution times and higher memory consumption than human-written equivalents. This inefficiency stems from several factors, including LLMs’ tendency to generate verbose or suboptimal algorithms, their lack of understanding of hardware constraints, and their reliance on patterns learned from diverse, possibly inefficient codebases. Addressing this issue is crucial for making LLM-generated code practical, particularly in resource-constrained environments like mobile apps or embedded systems. Overcoming LLM code inefficiency necessitates a multi-faceted approach, combining techniques like self-optimization strategies (where the LLM refines its initial code based on execution profiles), careful prompt engineering to guide the LLM towards more efficient solutions, and perhaps even incorporating domain-specific knowledge into the model’s training data. Efficient code generation is key to unlocking the full potential of LLMs in software development and automation.
Self-Opt Framework#
A self-optimization framework for code improvement centers around iterative refinement. It begins with a Large Language Model (LLM) generating initial code. This code is then executed, profiling its performance (execution time, memory usage). The profile, highlighting inefficiencies, is fed back to the LLM, guiding its revision of the code. This iterative cycle continues, enhancing efficiency with each iteration. The framework’s efficacy depends on the LLM’s ability to interpret performance profiles and translate these insights into effective code changes. A key advantage is its model-agnostic nature, potentially working across various LLMs. However, the iterative approach introduces overhead, creating a tradeoff between optimization time and final efficiency gains. The effectiveness is dependent on task complexity and the LLM’s capabilities. The framework’s broader impact involves improved developer productivity, and resource savings, although potential limitations like job displacement and overreliance on LLMs also need careful consideration.
EffiBench Experiments#
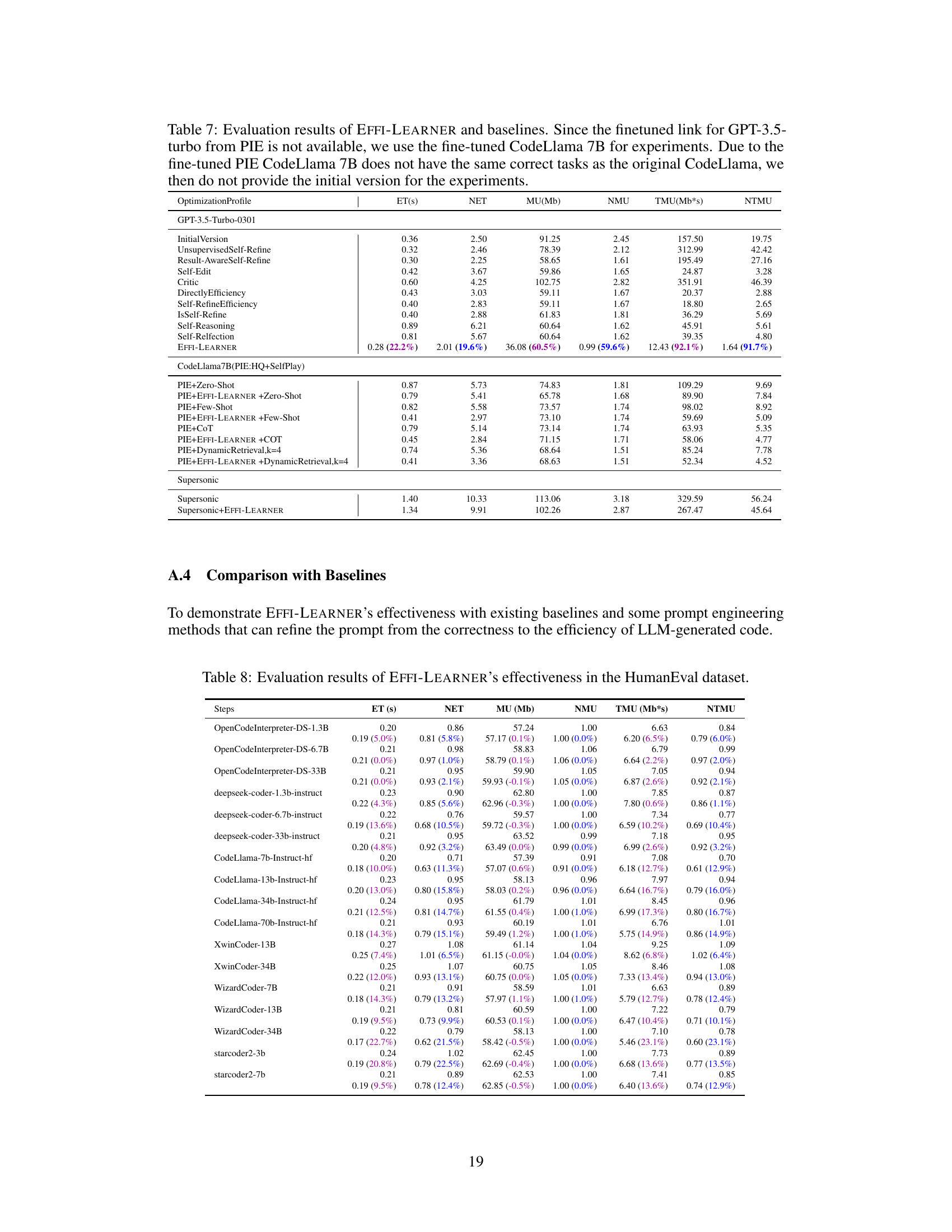
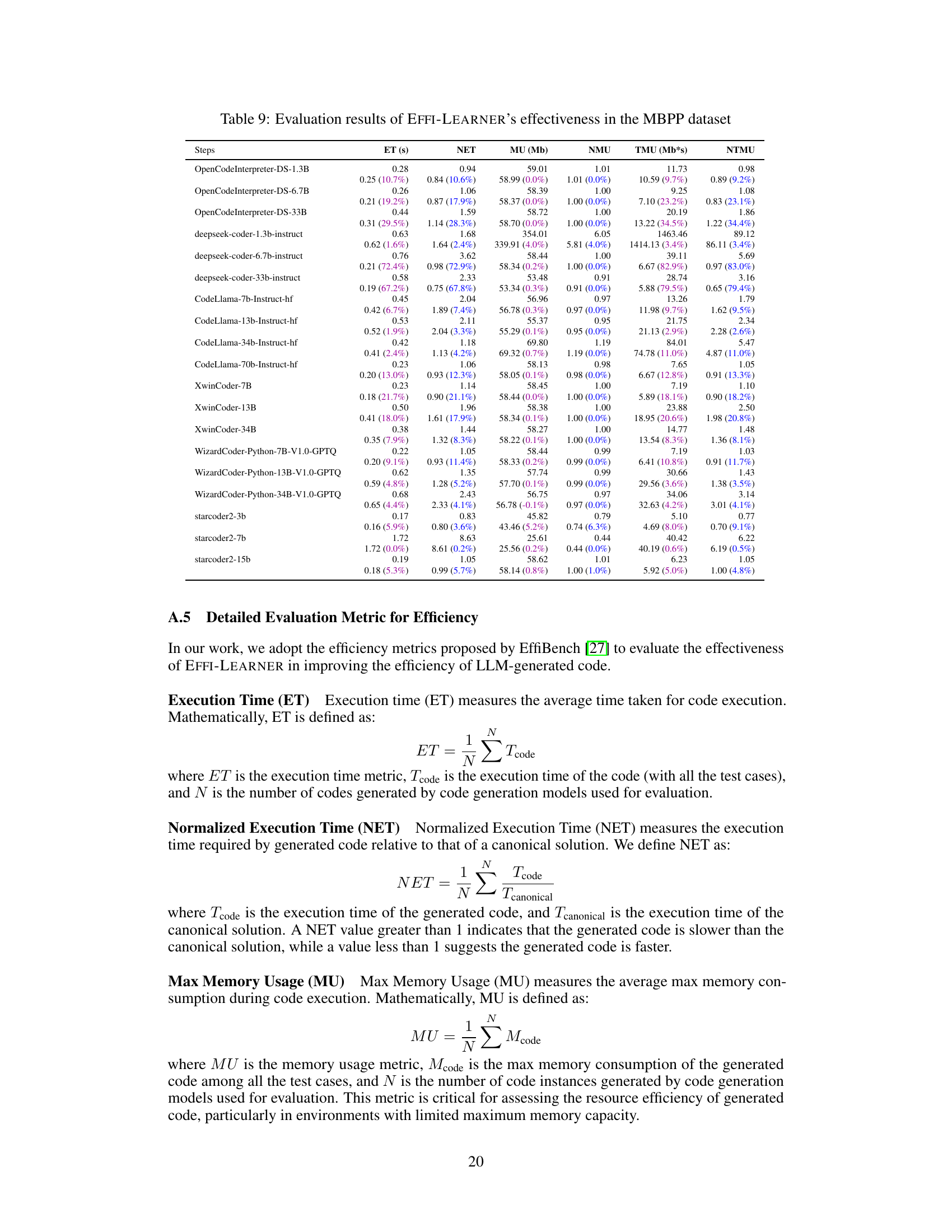
Hypothetical “EffiBench Experiments” section would likely detail the empirical evaluation of the EFFI-LEARNER framework. This would involve applying EFFI-LEARNER to a range of code generation tasks from the EffiBench benchmark. Key aspects to consider are the specific metrics used to assess efficiency (e.g., execution time, memory usage), the choice of LLMs tested, and a comparison between EFFI-LEARNER’s optimized code and baselines. Statistical significance of improvements would need strong emphasis, along with analysis of any trade-offs between code efficiency and correctness. The results section should likely present quantitative data, possibly visualized in tables or charts, showing improvements in efficiency metrics. Crucially, the discussion should explain the reason for observed efficiency gains or limitations, possibly by analyzing the nature of the optimizations made by EFFI-LEARNER and the characteristics of the initial LLM-generated code. Detailed analyses of certain tasks (or LLMs) could provide deeper insights, comparing the characteristics of both the original and optimized outputs. A discussion on the limitations of the experiments (e.g., dataset scope, LLM selection) and how these impact generalizability is essential for robust research.
Overhead Profiling#
Overhead profiling, in the context of optimizing LLM-generated code, is a crucial step that involves executing the generated code and meticulously capturing performance metrics. Profiling tools measure execution time at a granular level (even down to individual lines) and memory usage. This detailed information is invaluable. By pinpointing specific code segments responsible for significant execution time overhead or excessive memory consumption, developers gain actionable insights for optimization. The effectiveness of this technique hinges on the choice of profiling tools, which should provide line-by-line performance data to identify bottlenecks accurately. Furthermore, the profile must account for the context in which the code is being used, considering factors such as input data, dataset size, and the testing environment. Finally, effective overhead profiling requires careful planning and execution to ensure that the gathered data are reliable and truly representative of the code’s performance characteristics.
Future Work#
The ‘Future Work’ section of a research paper on code efficiency enhancement using LLMs would naturally discuss extending the current framework, EFFI-LEARNER, to encompass a broader range of programming languages beyond Python and to explore diverse coding paradigms and problem types. Investigating the benefits of incorporating domain-specific knowledge into the optimization process is crucial. This could involve techniques like utilizing code comments, docstrings, or external knowledge bases to guide the LLM’s optimization efforts. A significant area of focus should be on developing more robust methods to manage the trade-off between optimization time and the overall efficiency gains. Addressing potential limitations such as over-reliance on LLMs and the impact on human coders’ skills would necessitate further research and possibly the development of integrated human-in-the-loop approaches. Finally, a thorough exploration into the implications of the proposed method on fairness, security, and privacy within code generation is highly recommended. This will be essential to understand and mitigate any potential negative consequences.
More visual insights#
More on figures

The figure illustrates the workflow of EFFI-LEARNER, a self-optimization framework for improving the efficiency of LLM-generated code. It shows three main stages: (1) Code Generation, where an LLM generates initial code; (2) Overhead Profiling, where the generated code is executed locally to capture its execution time and memory usage; (3) Code Refinement, where the overhead profiles are fed back into the LLM to iteratively revise and optimize the code. This iterative process continues until the code reaches a satisfactory level of efficiency, significantly enhancing its performance.

This figure illustrates the workflow of the EFFI-LEARNER framework. It starts with an LLM generating code for a given problem. This code is then executed, and an overhead profile (execution time and memory usage) is created. This profile is fed back into the LLM, which then refines the code. This iterative process continues until the LLM produces an efficient code. The Appendix contains more detailed illustrations of this process.
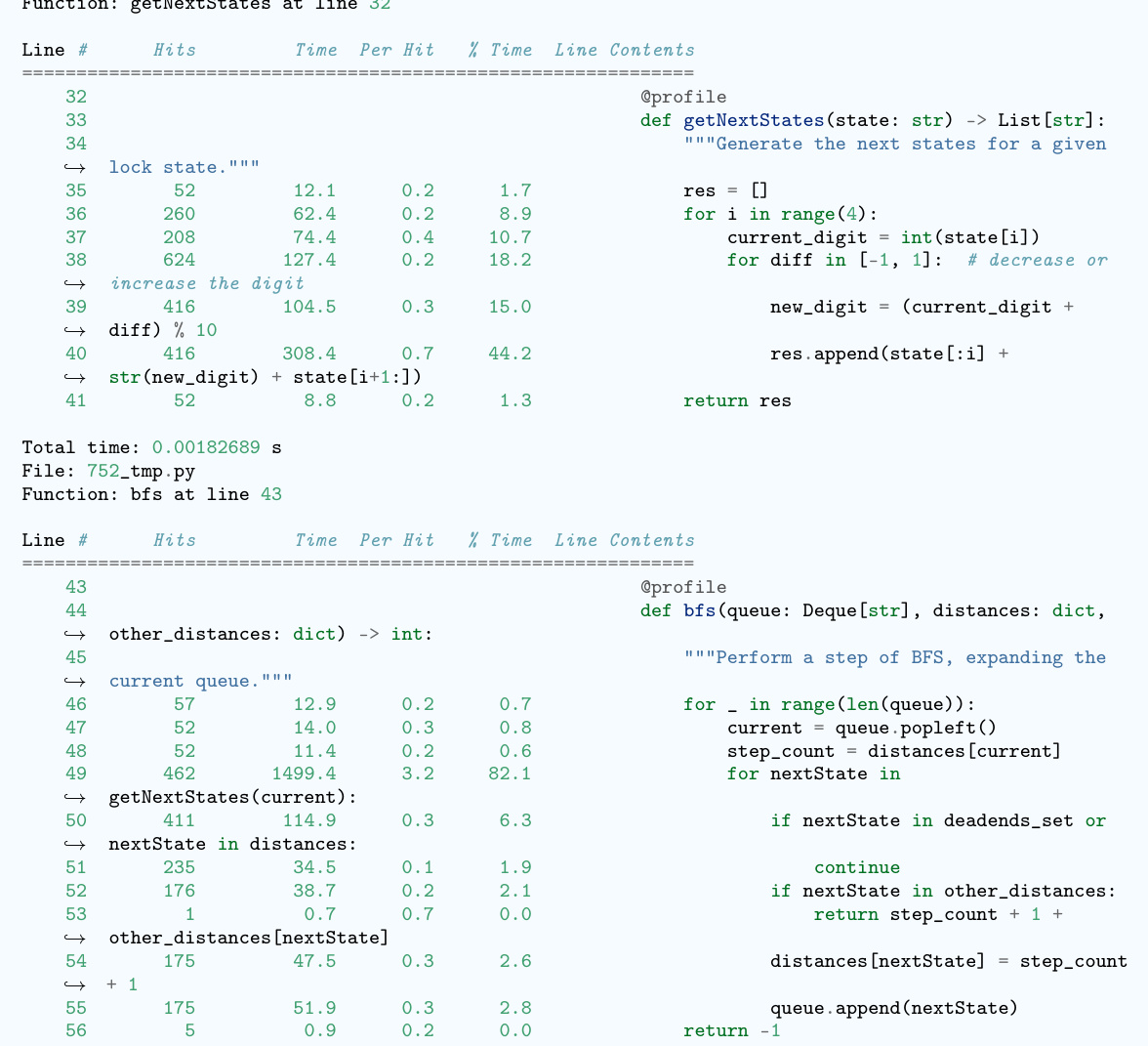
This figure illustrates the workflow of the EFFI-LEARNER framework. It starts with an LLM generating code for a given problem. This code is then executed, and its execution time and memory usage are profiled. These profiles (overhead profiles) are fed back into the LLM, which then refines the code. This iterative process of code generation, profiling, and refinement continues until the efficiency of the generated code is satisfactory. The Appendix contains more detailed illustrations of this process.
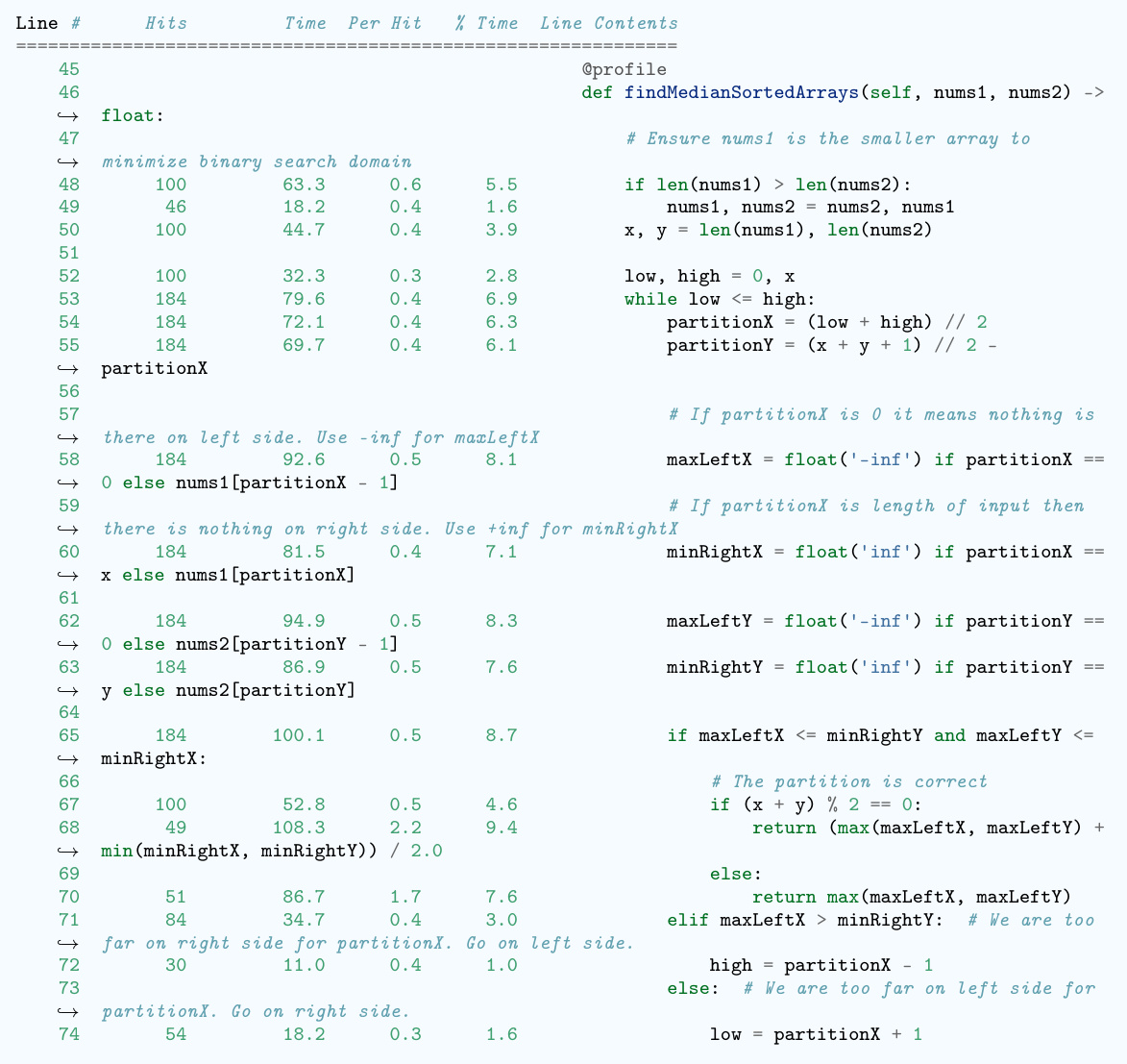
This figure illustrates the workflow of EFFI-LEARNER, a self-optimization framework for improving the efficiency of LLM-generated code. It shows three main stages: 1) Code Generation, where an LLM generates initial code; 2) Overhead Profiling, where the generated code is executed to obtain execution time and memory usage profiles; and 3) Code Refinement, where the profiles are fed back to the LLM to iteratively refine the code for better efficiency. The process repeats until a satisfactory level of efficiency is reached. This iterative feedback loop is the key to EFFI-LEARNER’s effectiveness. Appendix figures 4-11 provide a more detailed breakdown of the process.

This figure illustrates the pipeline of the EFFI-LEARNER framework. It starts with an LLM generating code for a given problem. This code is then executed, and an overhead profile (execution time and memory usage) is generated. This profile is fed back into the LLM, which uses it to refine the code. This iterative process repeats until the LLM produces an efficient solution. The appendix contains more detailed illustrations of this process.
More on tables

This table presents the results of evaluating the code efficiency of various Large Language Models (LLMs) using the EFFI-LEARNER framework on the EffiBench benchmark. For each LLM, it shows the execution time (ET), normalized execution time (NET), maximum memory usage (MU), normalized maximum memory usage (NMU), total memory usage (TMU), and normalized total memory usage (NTMU) before and after optimization by EFFI-LEARNER. The percentage reduction achieved by EFFI-LEARNER for each metric is indicated in parentheses. The table also highlights the top-performing LLMs after optimization.
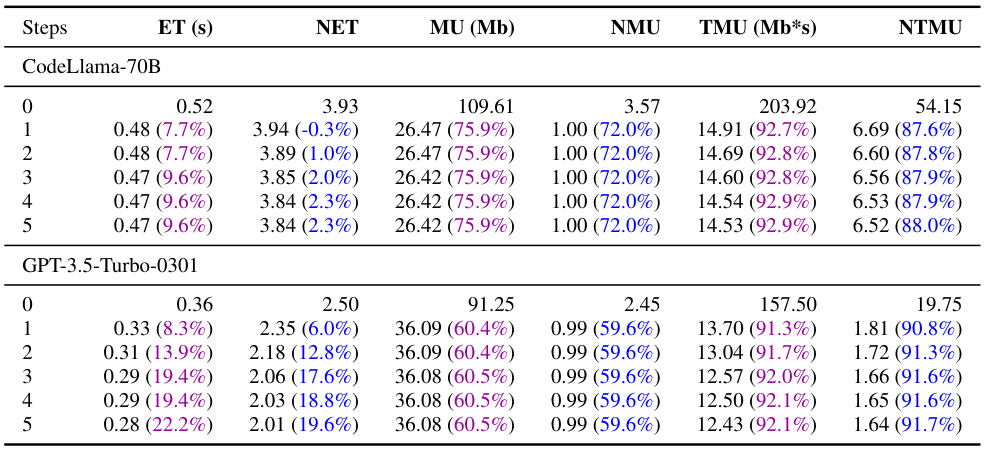
This table presents the results of evaluating the code efficiency of various Large Language Models (LLMs) using the EFFI-LEARNER framework on the EffiBench benchmark. It shows the execution time (ET), normalized execution time (NET), maximum memory usage (MU), normalized maximum memory usage (NMU), total memory usage (TMU), and normalized total memory usage (NTMU) for each LLM both before and after optimization with EFFI-LEARNER. The percentage reduction in each metric after optimization is shown in parentheses. Top-performing LLMs in terms of efficiency gains are highlighted.
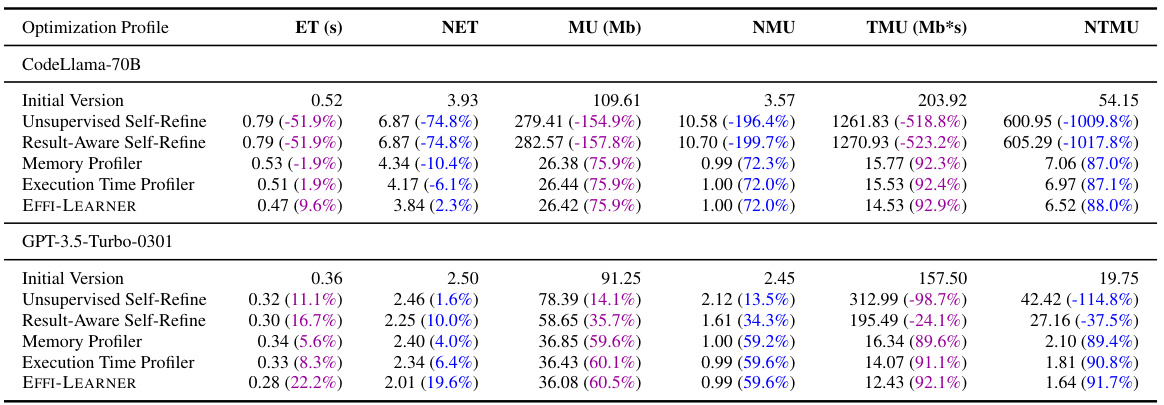
This table presents the results of evaluating the code efficiency of various Large Language Models (LLMs) using the EFFI-LEARNER framework on the EffiBench benchmark. It shows the execution time (ET), normalized execution time (NET), maximum memory usage (MU), normalized maximum memory usage (NMU), total memory usage (TMU), and normalized total memory usage (NTMU) for each LLM before and after optimization with EFFI-LEARNER. The percentage reduction in each metric is shown in parentheses. The top-performing LLMs in terms of efficiency gains are highlighted.
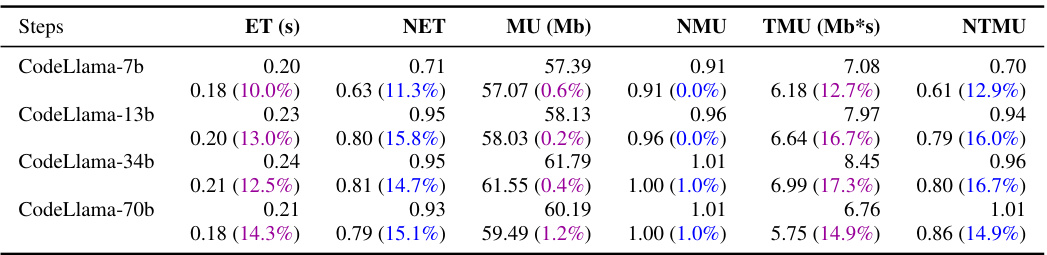
This table presents the code efficiency results of various LLMs (both open-source and closed-source) evaluated on the EffiBench benchmark, before and after applying the EFFI-LEARNER optimization framework. It shows the execution time (ET), normalized execution time (NET), maximum memory usage (MU), normalized maximum memory usage (NMU), total memory usage (TMU), and normalized total memory usage (NTMU). The percentages in parentheses indicate the percentage reduction in each metric achieved by EFFI-LEARNER. Top-performing LLMs, in terms of efficiency improvements after optimization, are highlighted.
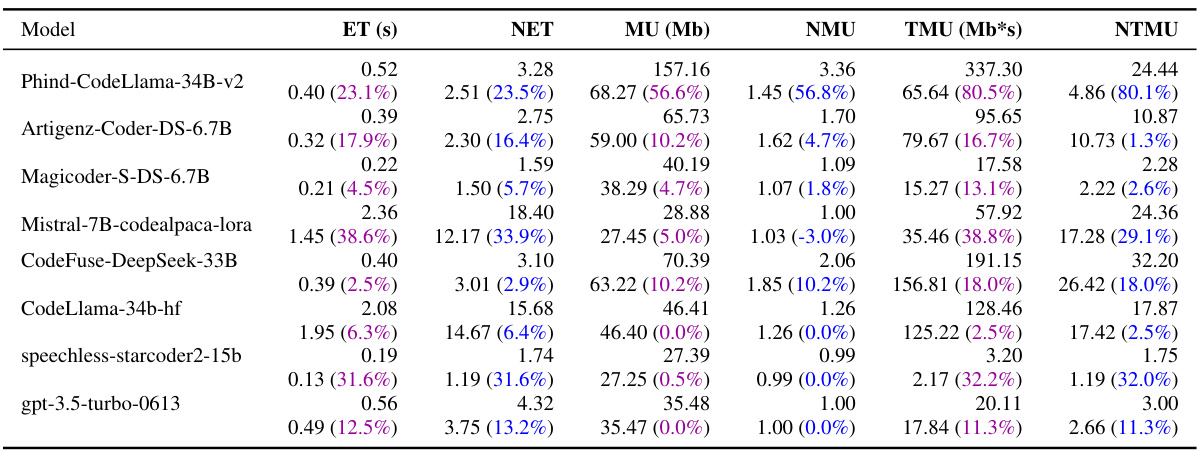
This table presents the code efficiency results of various LLMs (large language models) evaluated using the EffiBench benchmark, both before and after applying the EFFI-LEARNER optimization framework. The table shows the execution time (ET), normalized execution time (NET), maximum memory usage (MU), normalized maximum memory usage (NMU), total memory usage (TMU), and normalized total memory usage (NTMU) for each LLM. The percentages in parentheses indicate the percentage reduction in each metric achieved by EFFI-LEARNER. Top-performing LLMs after optimization are highlighted.

This table presents the results of evaluating the code efficiency of various Large Language Models (LLMs) before and after applying the EFFI-LEARNER optimization framework. It uses the EffiBench benchmark, showing the execution time (ET), normalized execution time (NET), maximum memory usage (MU), normalized maximum memory usage (NMU), total memory usage (TMU), and normalized total memory usage (NTMU) for each LLM. The percentages in parentheses indicate the performance improvement achieved by EFFI-LEARNER. Top-performing LLMs in terms of efficiency gains are highlighted.

This table presents the results of evaluating the code efficiency of various Large Language Models (LLMs) using the EffiBench benchmark, both before and after applying the EFFI-LEARNER optimization framework. The table shows the execution time (ET), normalized execution time (NET), maximum memory usage (MU), normalized maximum memory usage (NMU), total memory usage (TMU), and normalized total memory usage (NTMU) for each LLM. The percentage reduction in each metric after EFFI-LEARNER optimization is shown in parentheses. The LLMs with the highest performance improvements are highlighted.

This table presents the results of the EFFI-LEARNER’s effectiveness on EffiBench benchmark. It shows the execution time (ET), normalized execution time (NET), maximum memory usage (MU), normalized maximum memory usage (NMU), total memory usage (TMU), and normalized total memory usage (NTMU) for various LLMs both before and after applying EFFI-LEARNER. The percentage reduction in each metric after optimization is shown in parentheses, highlighting the improvements achieved by EFFI-LEARNER. Top-performing LLMs are visually highlighted in the table.

This table presents the results of evaluating the efficiency of various Large Language Models (LLMs) in generating code, specifically focusing on the EffiBench benchmark. The table compares the execution time (ET), normalized execution time (NET), maximum memory usage (MU), normalized maximum memory usage (NMU), total memory usage (TMU), and normalized total memory usage (NTMU) for LLMs both before and after optimization using the proposed EFFI-LEARNER framework. The percentage reduction achieved by EFFI-LEARNER is shown in brackets, highlighting the efficiency improvements obtained. Top-performing LLMs after optimization are highlighted.

This table presents the results of evaluating the code efficiency of various Large Language Models (LLMs) before and after applying the EFFI-LEARNER optimization framework on the EffiBench benchmark. The metrics used include execution time (ET), normalized execution time (NET), maximum memory usage (MU), normalized maximum memory usage (NMU), total memory usage (TMU), and normalized total memory usage (NTMU). For each LLM, the table shows the initial values of these metrics and the improved values after optimization, with the percentage reduction indicated in parentheses. Highlighted LLMs represent the top performers after the optimization process.
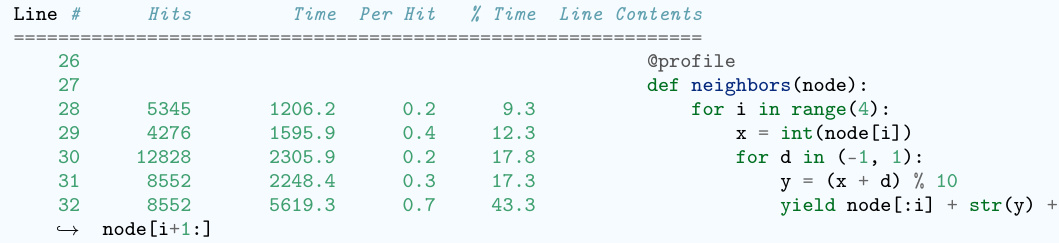
This table presents the results of evaluating the efficiency of various Large Language Models (LLMs) when used with the EFFI-LEARNER framework on the EffiBench benchmark. It compares the execution time (ET), normalized execution time (NET), maximum memory usage (MU), normalized maximum memory usage (NMU), total memory usage (TMU), and normalized total memory usage (NTMU) of LLMs both before and after applying EFFI-LEARNER. The percentage reduction in each metric after optimization is shown in parentheses. Top-performing models are highlighted to show which LLMs experienced the greatest efficiency gains.

This table presents the results of evaluating the efficiency of various LLMs (large language models) for code generation using the EffiBench benchmark, both before and after applying the EFFI-LEARNER self-optimization framework. The metrics used to measure efficiency include Execution Time (ET), Normalized Execution Time (NET), Max Memory Usage (MU), Normalized Max Memory Usage (NMU), Total Memory Usage (TMU), and Normalized Total Memory Usage (NTMU). The table shows the improvement achieved by EFFI-LEARNER in each metric for a variety of LLMs (both open-source and closed-source), with the percentage improvement in parentheses, highlighting the most efficient models.

This table presents the code efficiency results obtained using EFFI-LEARNER on the EffiBench benchmark. It compares the performance of various LLMs (both open-source and closed-source) before and after applying EFFI-LEARNER. The metrics used include execution time (ET), normalized execution time (NET), maximum memory usage (MU), normalized maximum memory usage (NMU), total memory usage (TMU), and normalized total memory usage (NTMU). The percentage improvement in each metric achieved by EFFI-LEARNER is shown in parentheses. The table highlights the LLMs that showed the most significant efficiency improvements after optimization.
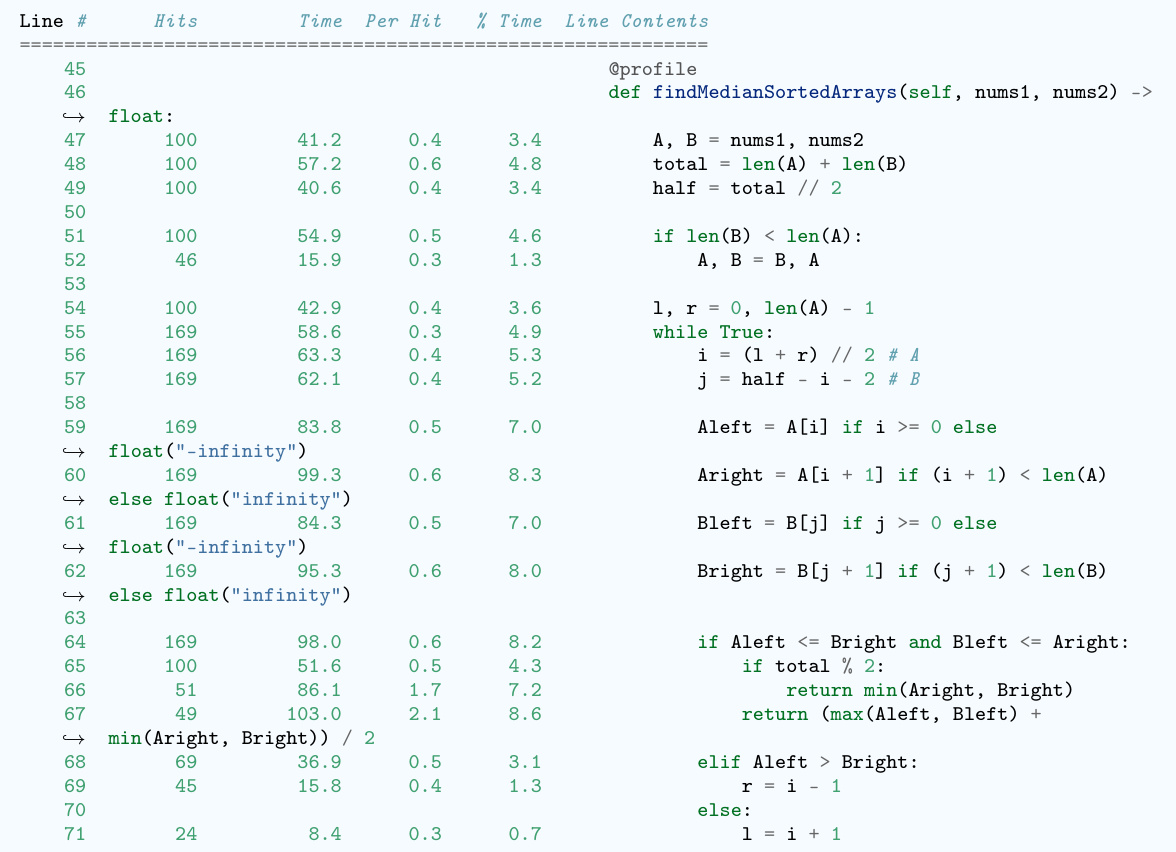
This table presents the results of evaluating the code efficiency of various LLMs (large language models) on the EffiBench benchmark, both before and after applying the EFFI-LEARNER optimization framework. The table shows the execution time (ET), normalized execution time (NET), maximum memory usage (MU), normalized maximum memory usage (NMU), total memory usage (TMU), and normalized total memory usage (NTMU) for each LLM. The percentage improvement achieved by EFFI-LEARNER is shown in parentheses for each metric. The LLMs with the best performance after optimization are highlighted.

This table presents the results of evaluating the code efficiency of various Large Language Models (LLMs) on the EffiBench benchmark, both before and after applying the EFFI-LEARNER optimization technique. For each LLM, it shows the execution time (ET), normalized execution time (NET), maximum memory usage (MU), normalized maximum memory usage (NMU), total memory usage (TMU), and normalized total memory usage (NTMU). The percentage reduction in each metric after optimization is indicated in parentheses. Top-performing LLMs are highlighted to emphasize the effectiveness of EFFI-LEARNER.
Full paper#