TL;DR#
Visual relationship understanding is crucial in computer vision but existing methods often focus on separate tasks like human-object interaction detection, scene graph generation, and referring relationships. This fragmentation limits the flexibility and scalability of these models. Furthermore, existing models struggle to handle open-vocabulary scenarios and dynamic prompts.
FleVRS overcomes these limitations by introducing a unified one-stage framework capable of handling all three tasks simultaneously. It leverages the synergy between image and text modalities, allowing for both standard and promptable relationship segmentation, as well as open-vocabulary recognition. Empirical results across multiple datasets showcase significant performance improvements compared to existing state-of-the-art methods, demonstrating the effectiveness and scalability of the proposed approach.
Key Takeaways#
Why does it matter?#
This paper is important because it presents FleVRS, a novel unified framework for visual relationship segmentation that significantly advances the field by seamlessly integrating three key aspects: standard, promptable, and open-vocabulary relationship segmentation. This addresses limitations of existing models, offering improved flexibility and generalization capabilities. The results demonstrate state-of-the-art performance across various benchmarks, opening new avenues for research in visual relationship understanding and its diverse applications.
Visual Insights#

🔼 This figure showcases the FleVRS model’s ability to perform visual relationship segmentation in three different modes: standard, promptable, and open-vocabulary. The standard mode segments all relationships present in an image without any prompts. In the promptable mode, user-provided prompts guide the segmentation, allowing users to focus on specific relationships. Lastly, the open-vocabulary mode allows the model to identify relationships with previously unseen objects or predicates.
read the caption
Figure 1: FleVRS is a single model trained to support standard, promptable and open-vocabulary fine-grained visual relationship segmentation (). It can take images only or images with structured prompts as inputs, and segment all existing relationships or the ones subject to the text prompts.

🔼 This table compares FleVRS with other relevant methods across three key aspects: handling of standard visual relationship segmentation tasks (HOI, SGG), ability to handle promptable segmentation (using textual prompts), and capacity for open-vocabulary segmentation (generalizing to unseen relationships). It highlights FleVRS’s unique position as the first one-stage model to achieve all three capabilities.
read the caption
Table 1: Comparisons with previous representative methods in three aspects of model capabilities. To the best of our knowledge, our FleVRS is the first one-stage model capable of performing standard, promptable, and open-vocabulary visual relationship segmentation all at once.
In-depth insights#
Flexible VRS Model#
A flexible visual relationship segmentation (VRS) model offers significant advantages in scene understanding by unifying various VRS tasks. It seamlessly integrates human-object interaction (HOI) detection, scene graph generation (SGG), and referring relationships (RR), handling diverse relationship types within a single framework. This flexibility is crucial for adapting to novel scenarios and open-vocabulary relationships, making it superior to previous models that typically focused on one or two specific tasks. The model’s capacity for handling varied input modalities, such as images only or images with structured prompts, enhances usability and adaptability. Furthermore, its ability to manage open-vocabulary segmentation reduces the need for exhaustive annotation. The key innovation lies in the unified architecture integrating text and image features effectively, allowing for prompt-based and open-vocabulary relationship recognition. This approach achieves superior performance across various datasets and task types and represents a notable step towards comprehensive visual relationship understanding.
VRS Benchmarks#
A robust evaluation of visual relationship segmentation (VRS) models necessitates a comprehensive benchmark. Such a benchmark should encompass diverse aspects, including the types of relationships (e.g., human-object interaction, generic object pairs), the granularity of annotation (e.g., bounding boxes, segmentation masks), and the vocabulary size (e.g., closed-vocabulary, open-vocabulary). The benchmark should ideally include multiple datasets, each representing a different visual domain and complexity level to assess generalization capability. Further, the benchmark should consider performance metrics beyond standard average precision (mAP), potentially incorporating metrics that capture the quality of relationship predictions and the model’s ability to handle challenging scenarios such as occlusion or ambiguity. Finally, a well-designed benchmark should facilitate easy reproducibility and comparison of results across different models, thereby promoting progress in VRS research. Data availability and clear evaluation guidelines are crucial for its success. The ultimate goal is to establish a standardized benchmark that drives the development of more accurate and robust VRS models, contributing significantly to real-world applications.
Prompt Engineering#
Prompt engineering, in the context of this research paper, likely focuses on optimizing the textual prompts used to guide the model’s visual relationship segmentation. Effective prompt design is crucial for achieving flexibility and control over the model’s output, allowing it to segment various types of relationships (human-object interaction, scene graph generation) as well as handle open-vocabulary scenarios. The authors probably explore different prompt structures, investigating the impact of specifying subject, predicate, or object, or combinations thereof. They likely also examine the use of natural language prompts, comparing their performance to more structured, template-based prompts. A key aspect would be the model’s ability to generalize to unseen relationships and objects based on well-crafted prompts, highlighting the synergy between textual input and visual understanding. The success of prompt engineering directly correlates with the model’s capacity for flexible and intuitive visual relationship segmentation.
Open Vocabulary VRS#
The section on “Open Vocabulary VRS” would ideally explore the model’s capacity to generalize to unseen relationships and objects. A key aspect would be demonstrating how the model handles novel predicates (relationship types) and objects not encountered during training. The approach used to achieve this generalization is crucial; does it leverage large-scale vision-language models like CLIP for semantic understanding and zero-shot prediction? Or are other techniques like data augmentation or transfer learning employed? Evaluation metrics in this section are essential and should include comparisons to alternative methods on standard open-vocabulary benchmarks, if applicable. The analysis should quantify performance differences on seen vs. unseen relationships. Detailed qualitative examples illustrating the model’s success and failures in handling truly novel concepts would further enhance understanding. Finally, the discussion should address the limitations of the open-vocabulary approach, perhaps acknowledging challenges posed by the long-tail distribution of relationships or the potential for hallucination (incorrectly predicting unseen relationships).
Future of VRS#
The future of Visual Relationship Segmentation (VRS) hinges on addressing its current limitations. Open-vocabulary VRS, enabling generalization to unseen relationships and objects without retraining, is crucial. This requires advancements in vision-language models and more robust methods for handling noisy or incomplete data. Improved efficiency and scalability are also essential, as current models are computationally expensive. This may involve exploring more efficient architectures or leveraging techniques like transfer learning more effectively. Integration with other vision tasks will also enhance VRS’s practical applications. Combining VRS with tasks like object detection and scene graph generation will provide a more holistic understanding of images, leading to more robust and versatile AI systems. Finally, the development of standardized benchmarks and evaluation metrics is necessary to facilitate fair comparison and encourage progress in the field. Addressing these key areas will lead to more accurate, efficient, and applicable VRS systems, significantly impacting various fields such as autonomous driving, robotics, and visual question answering.
More visual insights#
More on figures

🔼 This figure shows example results of the proposed FleVRS model on different visual relationship segmentation tasks. The top row demonstrates standard HOI (Human-Object Interaction) segmentation, where the model segments objects and relationships without any textual prompt. The middle row shows promptable HOI segmentation, where a textual prompt specifies the relationship of interest. The bottom row shows promptable panoptic scene graph generation, where a textual prompt helps to ground various types of visual relationships.
read the caption
Figure 1: FleVRS is a single model trained to support standard, promptable and open-vocabulary fine-grained visual relationship segmentation (). It can take images only or images with structured prompts as inputs, and segment all existing relationships or the ones subject to the text prompts.
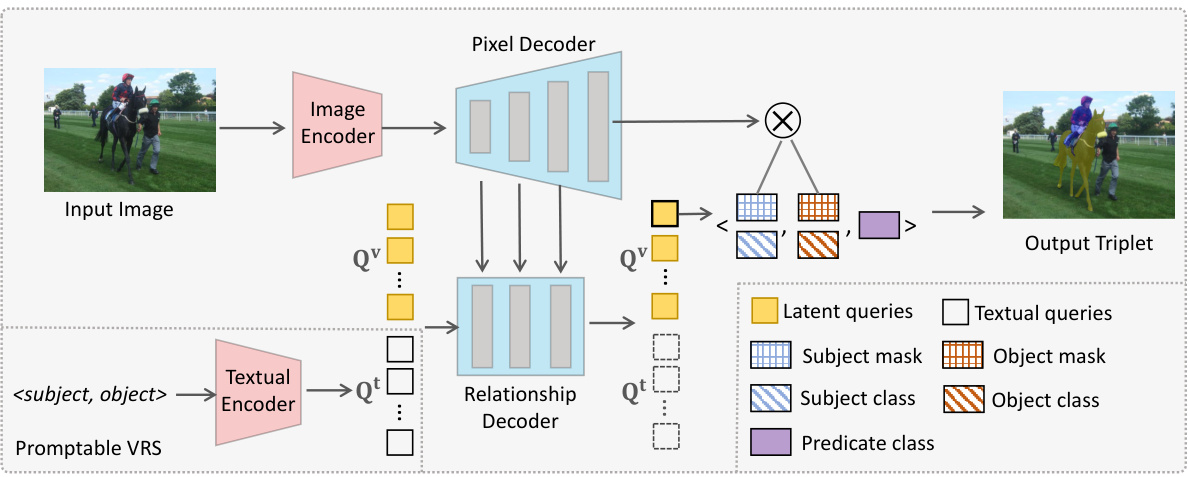
🔼 This figure shows the architecture of FleVRS, a flexible one-stage framework for visual relationship segmentation. The model consists of an image encoder, a pixel decoder, a textual encoder (used for promptable VRS), and a relationship decoder. The relationship decoder uses latent queries (for standard VRS) or latent queries combined with textual queries (derived from textual prompts, for promptable VRS) to predict triplets which include subject and object masks and classes, along with predicate class. This shows how the model integrates standard, promptable, and open-vocabulary visual relationship segmentation in a single framework.
read the caption
Figure 3: Overview of FleVRS. In standard VRS, without textual queries, the latent queries perform self- and cross-attention within the relationship decoder to output a triplet for each query. For promptable VRS, the decoder additionally incorporates textual queries Qt, concatenated with Q. This setup similarly predicts triplets, each based on Q outputs aligned with features from the optional textual prompt Qt.

🔼 This figure demonstrates the qualitative results of the proposed FleVRS model on the HICO-DET test set for promptable visual relationship segmentation (VRS). It showcases the model’s ability to accurately segment subject and object masks and predict relationship categories based on three different types of textual prompts: (a) specifying the object and predicate, (b) specifying the subject and predicate, and (c) specifying the subject and object. The use of bold and red text highlights predicted predicates and unseen objects/predicates, respectively, showcasing the model’s flexibility in handling various prompt formats and its capability for open-vocabulary relationship segmentation.
read the caption
Figure 4: Qualitative results of promptable VRS on HICO-DET [4] test set. We show visualizations of subject and object masks and relationship category outputs, given three types of text prompts. In (c), we show the predicted predicates in bold characters. Unseen objects and predicates are denoted in red characters.

🔼 This figure shows example results of the model’s promptable visual relationship segmentation (VRS) capabilities on the HICO-DET dataset. It demonstrates the model’s ability to segment and classify relationships based on three types of text prompts: 1. Providing only the predicate, asking the model to identify the subject and object. 2. Providing the subject and predicate, asking the model to identify the object. 3. Providing the subject and object, asking the model to identify the predicate. The use of red characters highlights instances where the model successfully identifies unseen objects or predicates, showcasing the model’s generalization to novel concepts.
read the caption
Figure 4: Qualitative results of promptable VRS on HICO-DET [4] test set. We show visualizations of subject and object masks and relationship category outputs, given three types of text prompts. In (c), we show the predicted predicates in bold characters. Unseen objects and predicates are denoted in red characters.

🔼 This figure shows qualitative results of the proposed FleVRS model on the HICO-DET test set for promptable visual relationship segmentation (VRS). It demonstrates the model’s ability to segment relationships based on different types of text prompts (missing subject, missing object, or missing predicate). The use of bold and red text highlights the model’s performance on unseen object and predicate categories. This showcases the model’s flexibility and capacity for handling novel relationships.
read the caption
Figure 4: Qualitative results of promptable VRS on HICO-DET [4] test set. We show visualizations of subject and object masks and relationship category outputs, given three types of text prompts. In (c), we show the predicted predicates in bold characters. Unseen objects and predicates are denoted in red characters.

🔼 The figure showcases the FleVRS model’s capabilities in three scenarios: standard, promptable, and open-vocabulary visual relationship segmentation. In the standard setting, it segments all relationships present in an image. In the promptable setting, it segments relationships based on textual prompts provided as input. Finally, the open-vocabulary setting demonstrates the model’s ability to segment relationships involving unseen object and predicate categories not present in its training data.
read the caption
Figure 1: FleVRS is a single model trained to support standard, promptable and open-vocabulary fine-grained visual relationship segmentation (). It can take images only or images with structured prompts as inputs, and segment all existing relationships or the ones subject to the text prompts.

🔼 This figure shows examples of how the authors convert Human-Object Interaction (HOI) detection bounding boxes into segmentation masks. The process uses the Segment Anything Model (SAM) to generate masks, and then filters out low-quality masks by calculating the Intersection over Union (IoU) between the generated mask and the original bounding box. Only masks with sufficient overlap (above a certain IoU threshold) are retained for training. This step helps to improve the quality of the training data and reduce noise caused by inaccurate bounding box annotations.
read the caption
Figure 2: Examples of converting HOI detection boxes to masks. We filter out low-quality masks during training by computing IoU between the mask and box.
More on tables
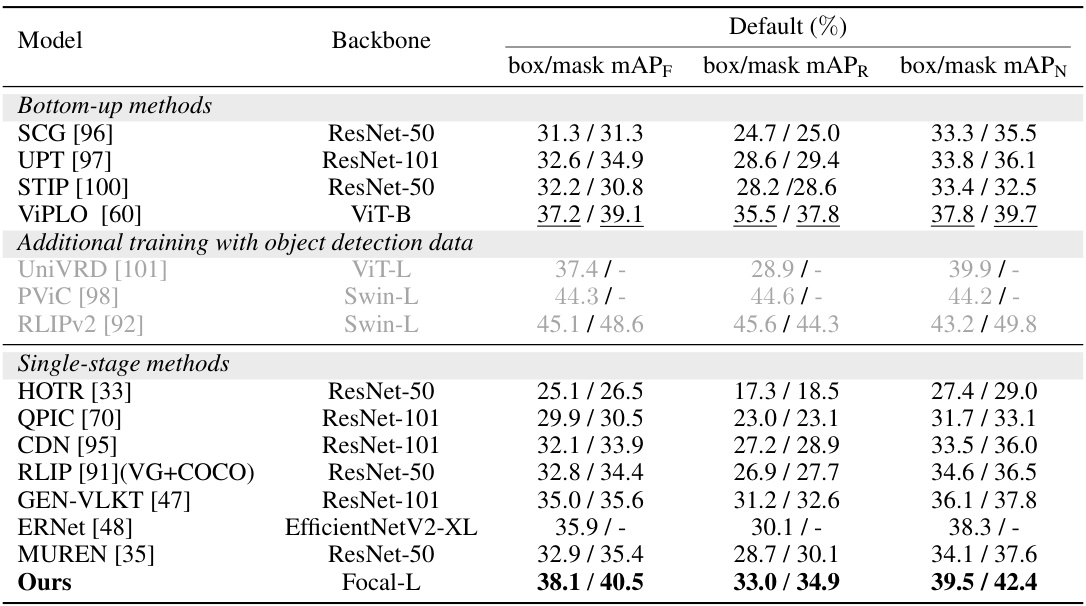
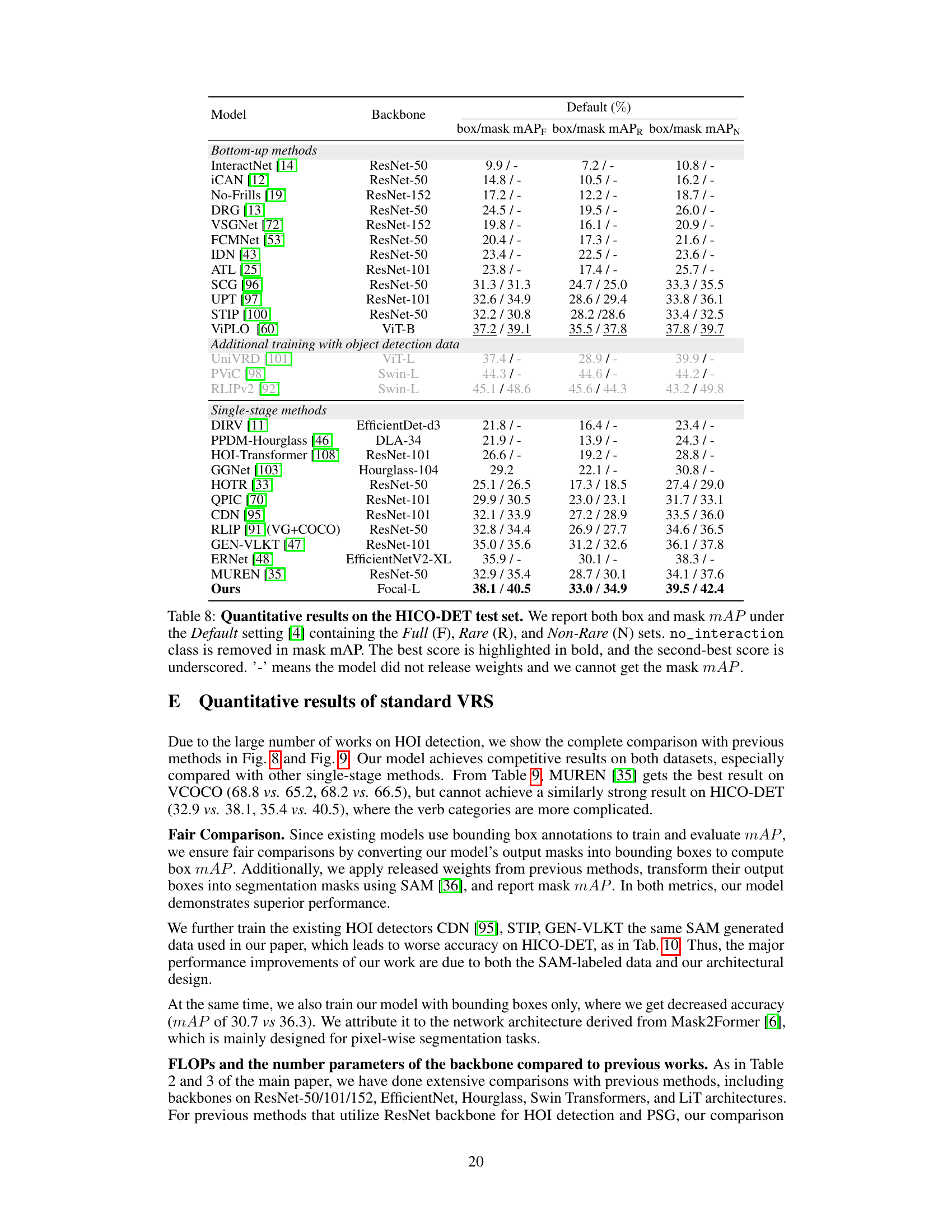
🔼 This table presents a quantitative comparison of the proposed FleVRS model with various existing methods for human-object interaction (HOI) segmentation on the HICO-DET dataset. It evaluates performance using both box and mask mAP metrics across three sets of HOI categories: Full, Rare, and Non-Rare. The results highlight FleVRS’s superior performance in both box and mask mAP compared to other state-of-the-art models.
read the caption
Table 2: Quantitative results on the HICO-DET test set. We report both box and mask mAP under the Default setting [4] containing the Full (F), Rare (R), and Non-Rare (N) sets. no_interaction class is removed in mask mAP. The best score is highlighted in bold, and the second-best score is underscored. '-' means the model did not release weights and we cannot get the mask mAP. Due to space limit, we show the complete table with more models in the appendix.
🔼 This table compares the performance of various models on the V-COCO dataset for visual relationship detection. The metrics used are box mAP and mask mAP. The table highlights the best performing model and indicates when mask mAP data was unavailable due to the model not releasing its weights.
read the caption
Table 3: Quantitative results on V-COCO. We report both box and mask mAP.The best score is highlighted in bold, and the second-best score is underscored. '-' means the model did not release weights and we cannot get the mask mAP. Due to space limit, we show the complete table with more models in the appendix.
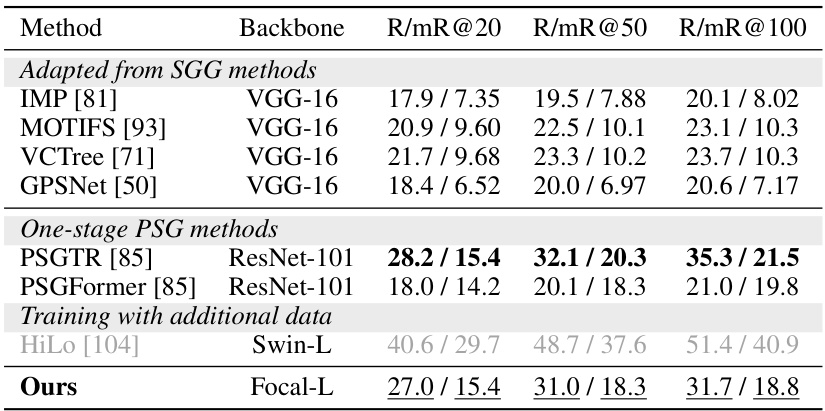
🔼 This table presents a comparison of the proposed FleVRS model’s performance on the Panoptic Scene Graph Generation (PSG) task with several existing methods. The results are shown for Recall (R) and mean Recall (mR) at different top-K thresholds (K=20, 50, 100). The table is categorized into methods adapted from SGG methods, one-stage PSG methods, and methods that utilize additional training data. It shows the backbone used for each method and highlights the best performing model for each metric.
read the caption
Table 4: Quantitative results on PSG. The best score is highlighted in bold, and the second-best score is underscored.
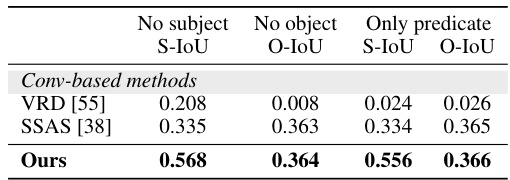
🔼 This table compares the performance of the proposed FleVRS model with existing methods (VRD [55] and SSAS [38]) on the VRD dataset [55] for the promptable visual relationship segmentation task. It specifically evaluates the ability of each method to localize the subject and object when only part of the triplet information (subject, predicate, object) is provided. The metrics used are S-IoU (subject Intersection over Union) and O-IoU (object Intersection over Union) for different scenarios: when the subject is missing, when the object is missing, and when only the predicate is known. The results show that FleVRS significantly outperforms previous methods in all these scenarios.
read the caption
Table 5: Comparison of promptable VRD results with the baseline on VRD dataset [55].

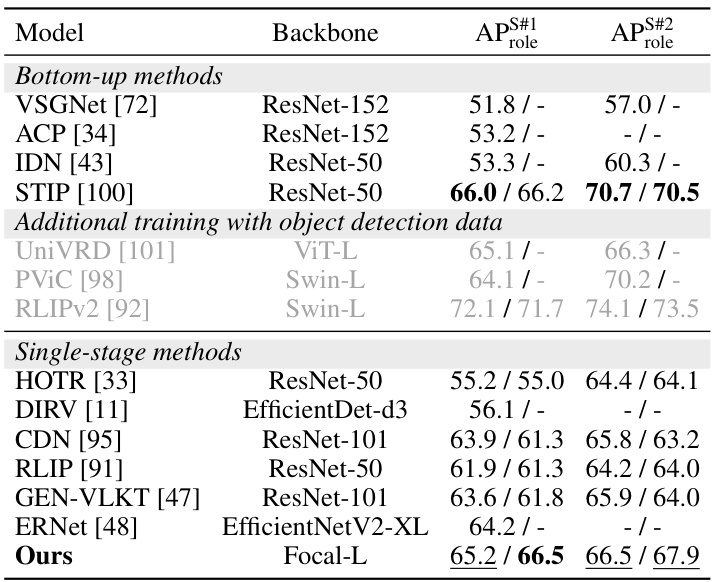
🔼 This table presents a comparison of the proposed FleVRS model’s performance on open-vocabulary HOI detection against several other state-of-the-art models. The results are broken down by three different scenarios (Rare First Unseen Composition, Non-rare First Unseen Composition, Unseen Object, and Unseen Verb), each evaluating the model’s ability to generalize to unseen object or predicate categories. The metrics used are mask mAP for HICO-DET and role mAP for VCOCO and PSG.
read the caption
Table 6: Results of open-vocabulary HOI detection on HICO-DET.

🔼 This table presents ablation studies on the FleVRS model. It examines the impact of various design choices, including different loss functions (disentangled CE loss, triplet CE loss, and a combination), visual backbones (Focal Tiny and Focal Large), design choices (using only box heads, only mask heads, or both), and training datasets (using a single dataset or multiple datasets). The results are evaluated using mask mAP on HICO-DET, mask AP on V-COCO, and R/mR@20 on PSG, showcasing the impact of each modification on overall model performance. The study helps determine the optimal configuration for FleVRS.
read the caption
Table 7: Ablations of different loss types, backbones, design choices and training sets. We adopt the Focal-L backbone by default.
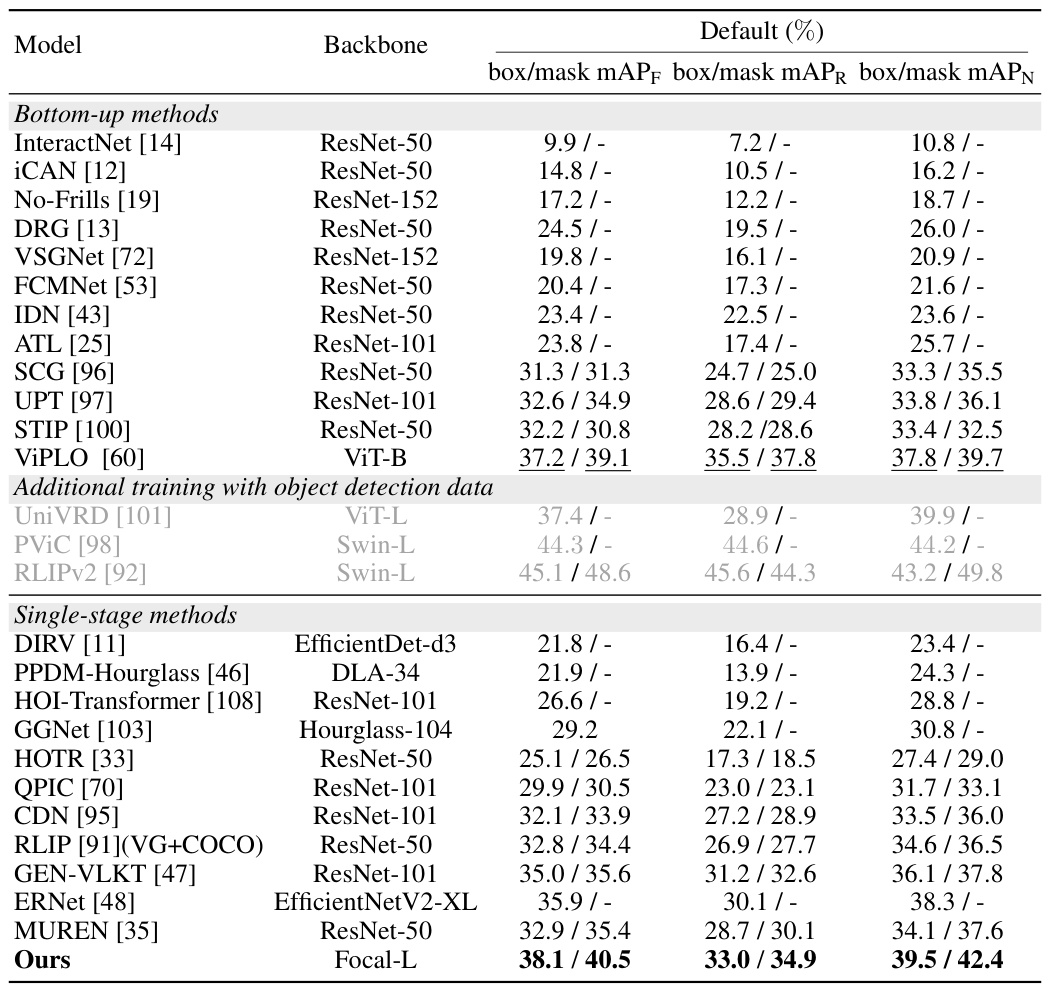
🔼 This table presents a quantitative comparison of the proposed FleVRS model with several existing methods for Human-Object Interaction (HOI) segmentation on the HICO-DET dataset. It shows the performance (box and mask mean Average Precision - mAP) broken down by three subsets of the dataset (Full, Rare, and Non-Rare), highlighting the model’s superior performance compared to state-of-the-art models.
read the caption
Table 2: Quantitative results on the HICO-DET test set. We report both box and mask mAP under the Default setting [4] containing the Full (F), Rare (R), and Non-Rare (N) sets. no_interaction class is removed in mask mAP. The best score is highlighted in bold, and the second-best score is underscored. '-' means the model did not release weights and we cannot get the mask mAP. Due to space limit, we show the complete table with more models in the appendix.
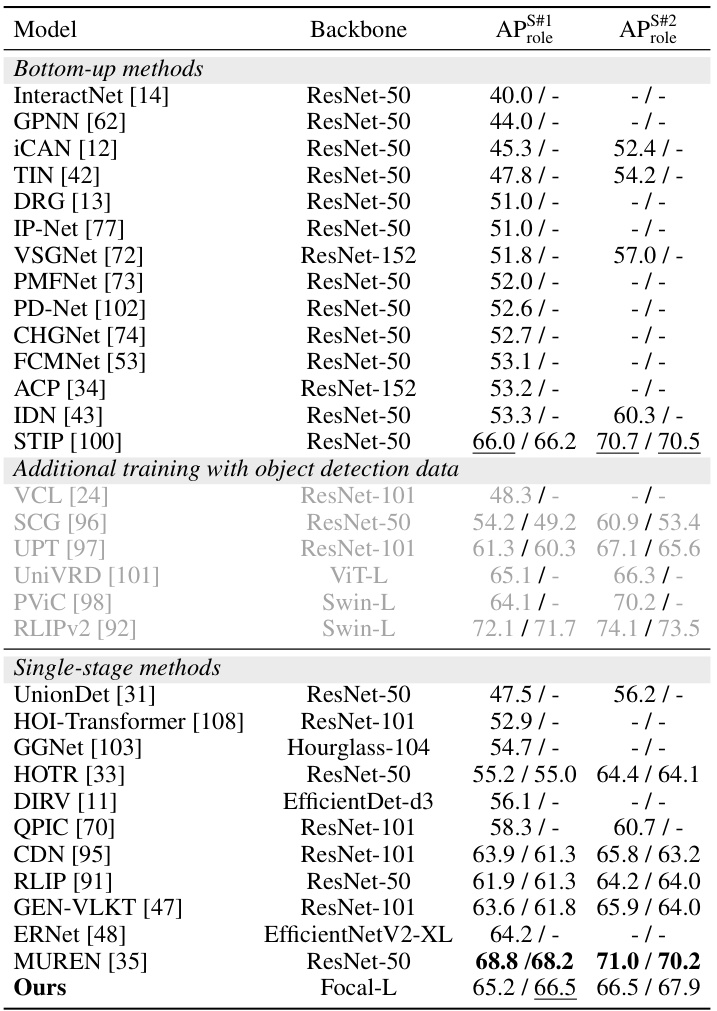
🔼 This table presents a comparison of various models’ performance on the V-COCO dataset for visual relationship detection. The metrics used are box and mask mean Average Precision (mAP). The table highlights the best performing model and indicates models which did not release their weights.
read the caption
Table 3: Quantitative results on V-COCO. We report both box and mask mAP.The best score is highlighted in bold, and the second-best score is underscored. '-' means the model did not release weights and we cannot get the mask mAP. Due to space limit, we show the complete table with more models in the appendix.

🔼 This table presents a comparison of the proposed FleVRS model’s performance on the HICO-DET dataset against various other state-of-the-art methods for HOI segmentation. It shows the box and mask mean average precision (mAP) for different subsets of the dataset (Full, Rare, and Non-Rare) and highlights the best and second-best performing models. The table also notes when mask mAP data was unavailable from the source publication.
read the caption
Table 2: Quantitative results on the HICO-DET test set. We report both box and mask mAP under the Default setting [4] containing the Full (F), Rare (R), and Non-Rare (N) sets. no_interaction class is removed in mask mAP. The best score is highlighted in bold, and the second-best score is underscored. '-' means the model did not release weights and we cannot get the mask mAP. Due to space limit, we show the complete table with more models in the appendix.
Full paper#