↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current AI agents struggle with accurately completing complex digital tasks due to a lack of large-scale, high-quality training data. Obtaining such data through human annotation is expensive and time-consuming, while automated methods often result in datasets that lack comprehensive coverage and robustness. This paper tackles this critical issue.
The proposed approach, Synatra, innovatively addresses this data scarcity by transforming abundant indirect knowledge sources—like online tutorials and freely available web pages—into direct, high-quality demonstrations for training digital agents. Synatra’s effectiveness is demonstrated through the superior performance of Synatra-CodeLlama, a language model fine-tuned using the synthetic data generated. The method achieves cost savings of 97% compared to human-generated data, while also showing improved performance over models trained with interactive data.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel, cost-effective approach to generate high-quality training data for digital agents, a crucial area in AI research. The method addresses the scarcity of labeled data for complex digital tasks by transforming readily available indirect knowledge (like online tutorials) into direct demonstrations. This has major implications for expanding research into more sophisticated and robust agents.
Visual Insights#

This figure illustrates the Synatra approach. Indirect knowledge, such as online tutorials and random web page observations without associated tasks, is transformed into direct demonstrations. These demonstrations show the next action an agent should take based on past actions and current observations. The goal is to create high-quality training data for digital agents without relying on expensive human annotation or complex reinforcement learning setups.
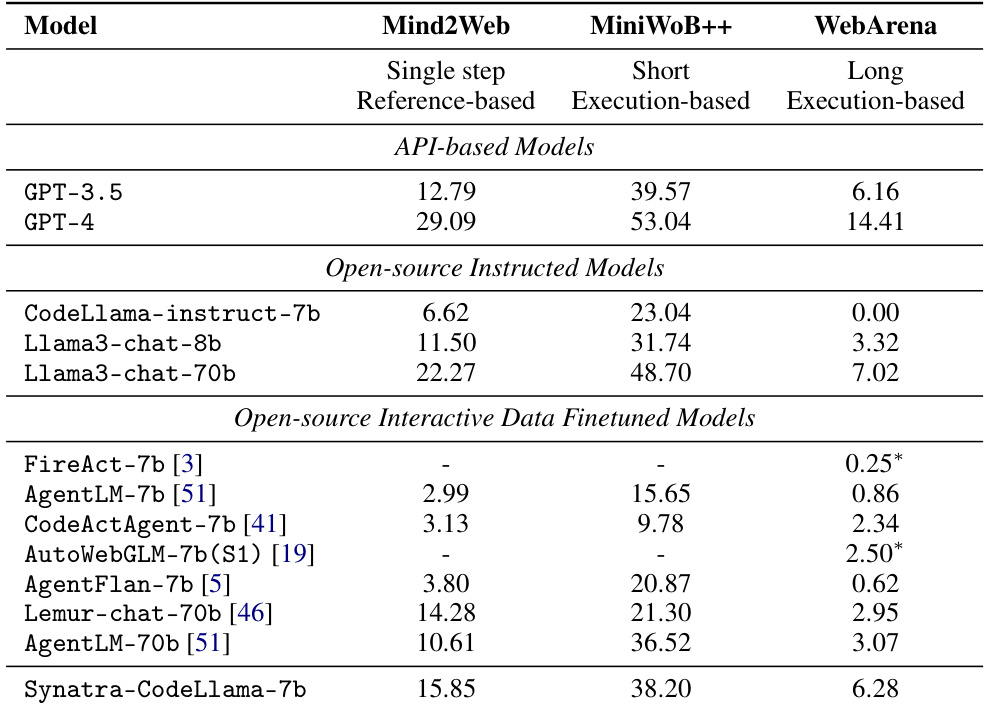
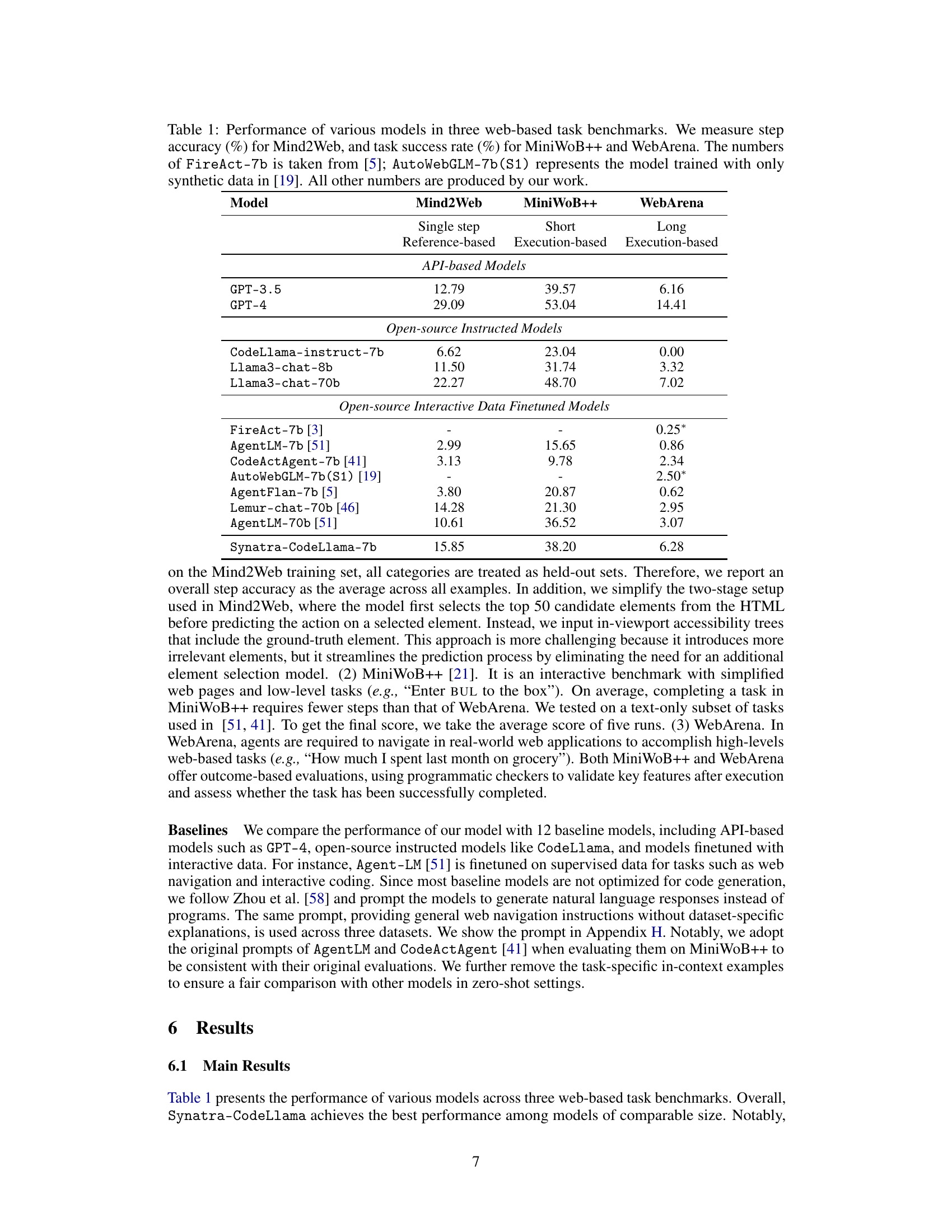
This table presents the performance comparison of various large language models (LLMs) on three web-based benchmarks: Mind2Web, MiniWoB++, and WebArena. The models are categorized into API-based models, open-source instructed models, and open-source interactive data finetuned models. For each benchmark, the table shows the performance of each model using different metrics (step accuracy for Mind2Web and task success rate for MiniWoB++ and WebArena). The table also notes the source of data used for training each model (e.g., synthetic, human annotated) and highlights the model Synatra-CodeLlama-7b, which is the focus of the paper.
In-depth insights#
Indirect Knowledge Use#
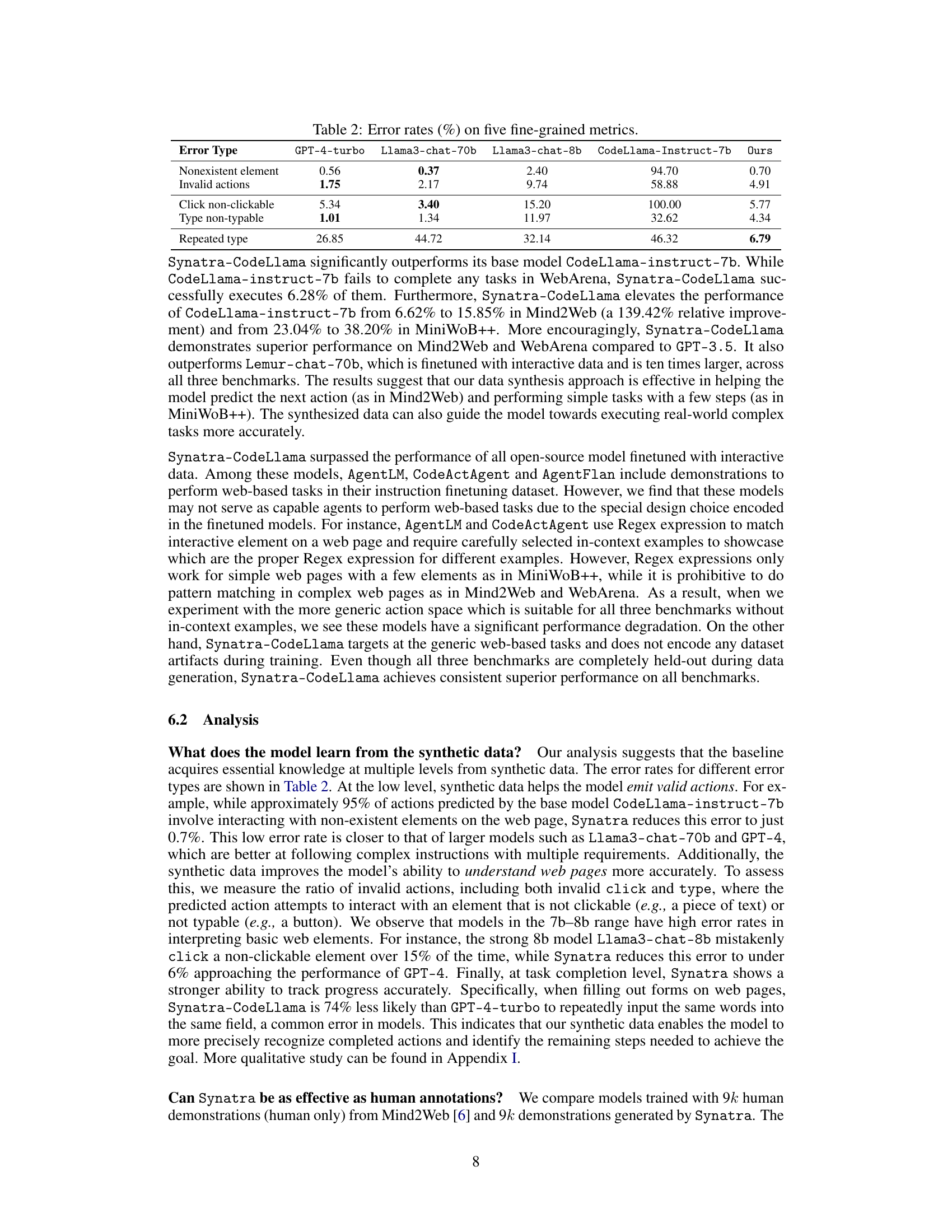
The effective utilization of indirect knowledge is a crucial aspect of this research. The paper highlights the challenges of directly obtaining large-scale, supervised datasets for training AI agents in digital environments. Instead, it explores the potential of leveraging readily available indirect knowledge such as online tutorials and how-to guides. These resources, while not explicitly formatted as direct agent demonstrations, contain valuable procedural information that can be transformed into effective training data. The authors carefully analyze various forms of indirect knowledge and propose techniques for encoding this knowledge in a structure suitable for agent training. This approach represents a significant cost reduction, offering an alternative to expensive human-generated demonstrations. The transformation process itself relies heavily on the capabilities of large language models (LLMs) to understand, interpret and generate instructions from textual sources. The effectiveness of this approach is validated through empirical results demonstrating that agents trained with synthetic demonstrations derived from indirect knowledge significantly outperform similar models trained with fewer, direct human demonstrations.
Synthetic Data Gen#
Synthetic data generation for digital agents presents a compelling solution to overcome the limitations of obtaining real-world datasets, which are often expensive and difficult to acquire. The core idea is to leverage readily available indirect knowledge sources, such as online tutorials and how-to guides, to generate synthetic demonstrations that can effectively train digital agents. This approach involves carefully selecting, processing, and transforming indirect knowledge into the format of direct demonstrations, emulating the sequence of user actions and observations in an interactive environment. The success of this approach is predicated on the ability to accurately encode both the structure and content of digital demonstrations, ensuring that the synthetic data is rich enough to capture the complexities of real-world digital tasks. The availability of indirect knowledge sources is a key enabler at scale, and the quality of the generated synthetic data significantly impacts the performance and generalizability of the resulting digital agents.
WebAgent Benchmarks#
WebAgent benchmarks are crucial for evaluating the capabilities and limitations of AI agents designed to interact with web environments. A robust benchmark should encompass a diverse range of tasks, reflecting the complexity and variability of real-world web interactions. Key considerations include task diversity, encompassing navigation, information retrieval, form filling, and e-commerce operations. The benchmark’s scope should span different websites and web applications, to assess generalizability beyond specific platforms. Evaluation metrics should go beyond simple pass/fail measures, capturing aspects like efficiency, accuracy, robustness, and resource consumption. Furthermore, a good benchmark should address the ethical implications of web agents, considering issues like privacy, security, and fairness in agent behavior. By systematically evaluating agents across diverse and challenging scenarios, these benchmarks provide invaluable insights into the current state-of-the-art and identify areas for future research and development. Ultimately, the goal is to create benchmarks that drive the creation of more capable, reliable, and ethically sound web agents.
Cost-Effective Approach#
A cost-effective approach to data generation for training AI agents is crucial for scalability and accessibility. The paper highlights the high cost of human-annotated data, emphasizing the economic benefits of synthetic data. By leveraging readily available indirect knowledge sources like online tutorials and randomly sampled web pages, and transforming them into direct demonstrations via an LLM, a significant cost reduction is achieved. This strategy not only reduces expenses but also addresses the limitations of traditional methods such as exploration and reinforcement learning. The cost savings are substantial, estimated at approximately 3% that of human-labeled data. This makes the approach particularly appealing for applications where obtaining large, high-quality datasets is challenging due to cost or time constraints. Further research in this area could potentially revolutionize how we train intelligent agents, ensuring broader adoption and accessibility across various sectors.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending Synatra to encompass more diverse digital environments beyond web browsers is crucial, potentially including mobile apps, desktop applications, and even robotic control interfaces. A key challenge would be developing robust methods for representing and handling the diverse action spaces and observation formats across these different environments. Further investigation into the generalizability and robustness of synthetic demonstrations is needed, focusing on methods to mitigate biases introduced during the data synthesis process. This could involve techniques like data augmentation, adversarial training, or incorporating real-world data to enhance the diversity and realism of the training set. Additionally, exploring alternative sources of indirect knowledge could lead to more extensive and diverse datasets. Investigating the potential of using automatically generated videos or other multimodal data sources as indirect supervision would prove valuable. Finally, evaluating the long-term impacts and potential societal implications of this approach, focusing on ethical considerations and fairness, is a vital area for future research.
More visual insights#
More on figures

This figure illustrates the Synatra approach which transforms indirect knowledge (like online tutorials) into direct supervision for training digital agents. The left side shows the indirect knowledge sources (tutorials and random observations without associated actions), while the right side depicts the synthesized direct demonstrations, which are sequences of actions and observations that lead to successful task completion. The arrow visually represents the transformation process performed by the Synatra model.
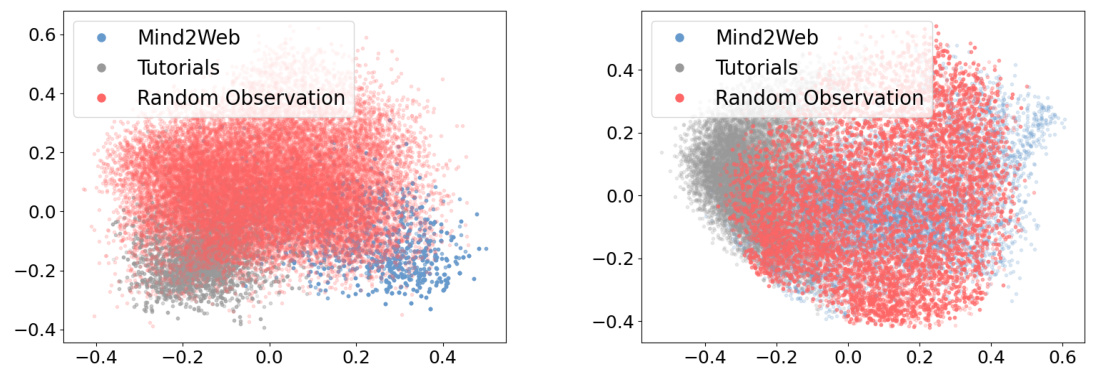
This figure visualizes the task intent and accessibility tree embeddings using t-SNE. The left plot shows the distribution of task intents, demonstrating the diversity of tasks covered in the synthetic data, comparing those from tutorials and random observations. The right plot visualizes the accessibility tree embeddings showing the distribution of observations. It helps illustrate the domain coverage of the synthetic data and how it compares to real-world web pages (from Mind2Web and random samples). The plots show the overlap between data from different sources, indicating the effectiveness of the data synthesis approach.

This figure visualizes the distribution of task intents and accessibility tree embeddings using t-SNE. The left plot shows the distribution of task intents, demonstrating that intents synthesized from random observations exhibit broader coverage than those from tutorials. The right plot shows the distribution of accessibility tree embeddings, indicating that observations from tutorials overlap significantly with real web pages, both from random observations and those in the Mind2Web dataset. This visualization helps to understand the diversity and coverage of the synthetic data generated.

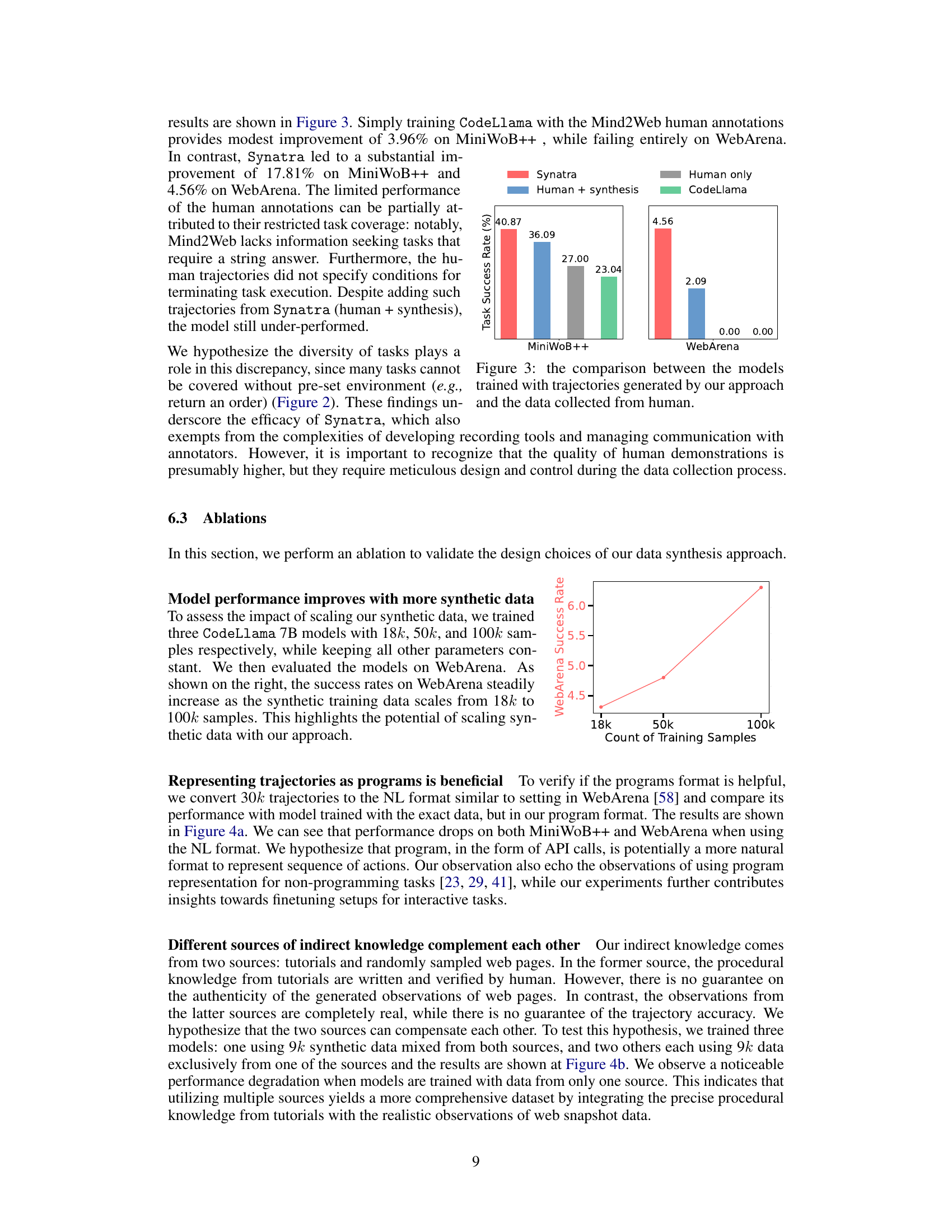
This figure shows the comparison of model performance on MiniWoB++ and WebArena using three different training datasets: Synthetic data generated by Synatra, human-annotated data from Mind2Web, and a combination of both human and synthetic data. It highlights the effectiveness of Synatra’s synthetic data in improving model performance, especially on WebArena where human-only data resulted in 0% success rate, while Synatra achieved a 4.56% success rate.

This figure shows the comparison of model performance between models trained with synthetic data generated using Synatra and models trained with human-annotated data from Mind2Web. The results are presented for three web-based benchmarks: MiniWoB++, WebArena, and Mind2Web. It highlights the significant performance improvement achieved by Synatra-trained models, particularly in WebArena where the human-only model fails completely. The results suggest that synthetic data can be highly effective in training web-based agents, even surpassing models trained with more expensive human-generated data.

This figure presents an ablation study to evaluate design choices in Synatra. Subfigure (a) compares the performance of models trained using trajectories represented as programs versus natural language. (b) compares models trained with indirect knowledge from different sources (tutorials, random web observations, and a combination of both). (c) contrasts the performance of models trained with the generated trajectories from Synatra against the performance of retrieval augmented generation models and baseline LLMs. These results illustrate the importance of program representation for trajectories, the complementary nature of different knowledge sources in generating synthetic data, and the effectiveness of using Synatra to transform indirect knowledge into effective training data.

This figure illustrates the core idea of the Synatra approach. The left side shows the indirect knowledge sources used, such as online tutorials and randomly sampled web page observations (without associated tasks and actions). The right side shows the synthesized direct demonstrations generated from this indirect knowledge. These demonstrations provide direct supervision for training digital agents by specifying the next action an agent should take, given a current state (previous actions and observations).

This figure illustrates the Synatra approach, which transforms indirect knowledge (like online tutorials) into direct demonstrations for training digital agents. The left side shows the indirect knowledge sources, while the right side depicts the synthesized direct demonstrations (next actions given states and observations) used to train the model. The core idea is to use readily available indirect knowledge to create training data, overcoming the limitations and high cost of obtaining large-scale, manually created demonstrations for digital tasks.

This figure shows the HTML code generated by the model to represent the webpage after two consecutive actions (goto and click) in a task of enabling Google Chat in a specific Gmail account. The HTML highlights the webpage’s structure and includes the ’next-action-target-element’ tag to indicate the element relevant to the next action in the task. This showcases the model’s ability to generate realistic and actionable web page representations based on previous actions and the intended next action.

This figure illustrates Synatra’s approach to generating direct demonstrations from indirect knowledge. The left side shows the indirect knowledge sources: tutorials and random observations. These sources lack the direct connection between state, action, and next observation needed for training digital agents. Synatra processes this indirect knowledge (left side of arrow) to generate direct demonstrations (right side of arrow) that explicitly show the sequence of actions and observations for completing a given task. These synthetic demonstrations are then used to train a more effective digital agent.

This figure visualizes the distribution of task intents and accessibility tree embeddings using t-SNE. The left panel shows that intents synthesized from random observations have broader coverage than those from tutorials, likely because humans tend to write tutorials for critical domains. The right panel demonstrates that generated observations from tutorials overlap significantly with real web pages from both random observations and Mind2Web, indicating good domain coverage of the synthetic data.

This figure visualizes the distribution of task intents and accessibility tree embeddings using t-SNE, showing the diversity of the synthetic data generated by Synatra compared to the human-collected Mind2Web dataset. The left plot shows that Synatra generates intents with broader coverage than tutorials alone, while the right plot shows overlap between synthetic observations from both tutorials and random samples, and real web pages from Mind2Web. The diversity of intents and observations highlights the richness of the synthetic dataset.
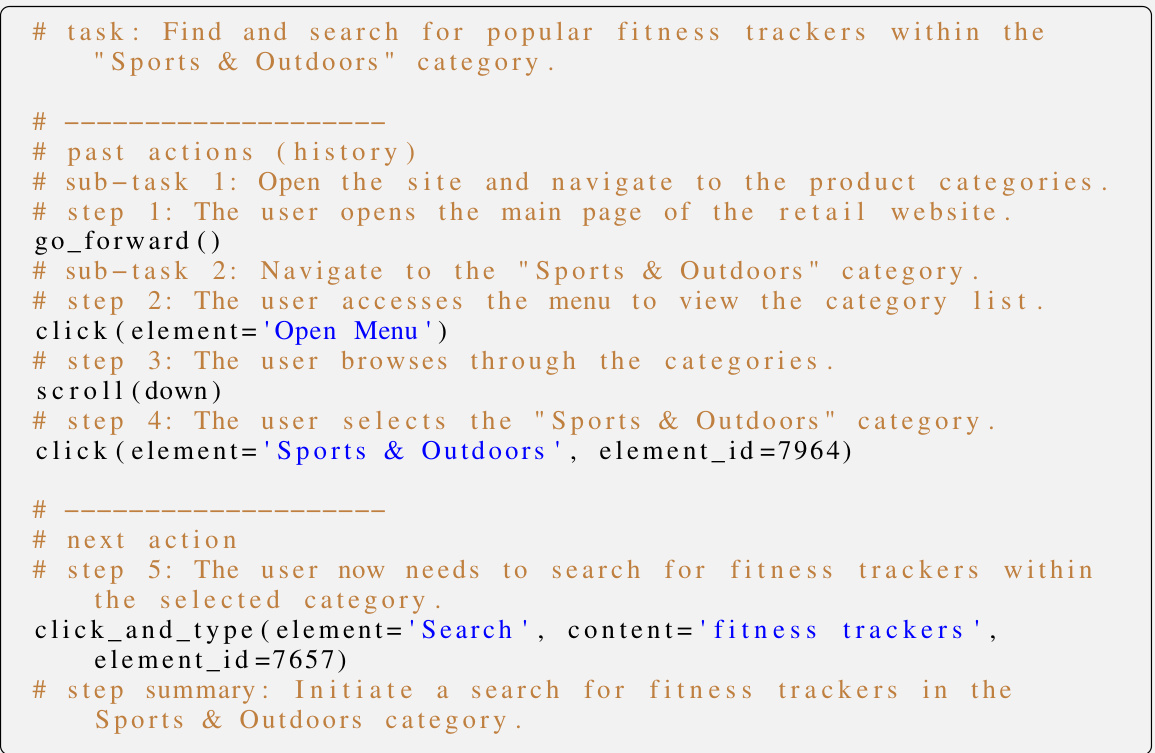
This figure illustrates Synatra’s approach to generating direct demonstrations for digital agents. It shows how Synatra transforms indirect knowledge sources (such as online tutorials meant for human users and randomly collected observations without associated task and action information) into direct demonstrations, which are sequences of actions and corresponding observations that a digital agent can directly learn from. The arrow visually represents this transformation from indirect knowledge to synthesized direct demonstrations which can be used to fine-tune LLMs.

This figure illustrates Synatra’s approach to generating direct demonstrations from indirect knowledge sources. The left side shows indirect knowledge sources, such as tutorials and randomly sampled observations without associated actions. The right side shows the direct demonstrations generated, which specify the next action based on the previous actions and current observations. The arrow signifies the transformation process carried out by Synatra.
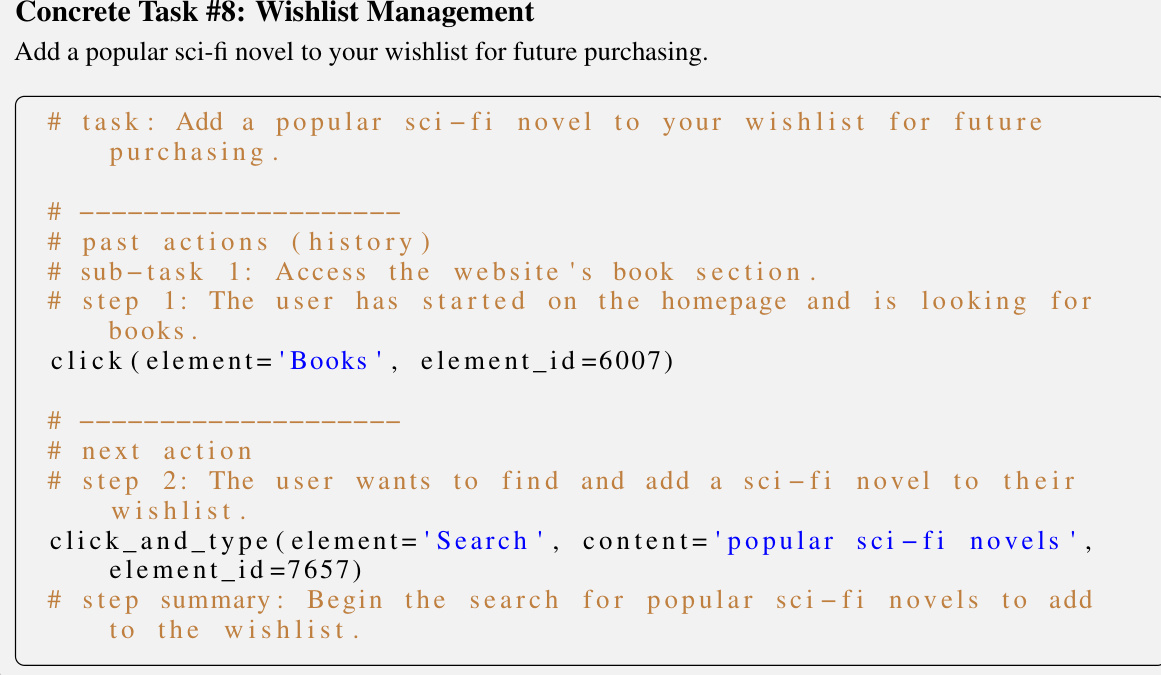
This figure shows the generated HTML code snippet, created by the Synatra model, that represents the webpage’s state between two consecutive actions: going to the Google Chat settings page and then selecting a specific Gmail account. The key element relevant to the next action (selecting the account) has the id ’next-action-target-element’ to illustrate how Synatra generates grounded actions and observations.

This figure illustrates the Synatra approach which transforms indirect knowledge into direct demonstrations for training digital agents. The left side shows the indirect knowledge sources: tutorials for human consumption and randomly sampled observations without associated tasks and actions. The right side shows the generated direct demonstrations which specify the immediate next actions based on the previous actions and current observations.

This figure shows a comparison between Synatra-CodeLlama and GPT-4-turbo’s performance on a web-based task. Both models attempt to find all issues labeled as ‘bug’ on a GitLab issues dashboard. GPT-4-turbo incorrectly tries to use the search box with the keyword ’type:bug’, which is ineffective. In contrast, Synatra-CodeLlama correctly identifies and clicks a link directly displaying the relevant issues, highlighting its superior ability to process information from the web page.

This figure shows a comparison of how Synatra-CodeLlama and GPT-4-turbo approached the task of finding the number of commits made by a specific person on a certain date on a GitLab webpage. Synatra-CodeLlama correctly identifies and clicks the relevant link showing the required information, whereas GPT-4-turbo attempts a less effective search strategy, highlighting Synatra-CodeLlama’s superior ability to accurately interpret webpage content and select appropriate actions.

This figure shows a comparison between GPT-4-turbo and Synatra-CodeLlama in completing a specific task. Both models have correctly entered the start and end dates in a form, but GPT-4-turbo incorrectly predicts that the next step is to re-enter the starting date. Synatra-CodeLlama, however, accurately interprets the status of the web page and executes the correct action. This highlights Synatra-CodeLlama’s superior ability to interpret context and execute actions effectively.

This figure visualizes the embeddings of task intents and accessibility trees using t-SNE. The left plot shows the distribution of task intents, demonstrating that intents generated from random observations have broader coverage than those from tutorials. The right plot visualizes the accessibility tree embeddings, showing significant overlap between observations from tutorials and real web pages from both random observations and the Mind2Web dataset. This suggests that the synthetic data generated by the method covers a similar range of tasks and webpage types as real-world data.
More on tables

This table compares the performance of various Language Models (LLMs) on three web-based benchmark tasks: Mind2Web, MiniWoB++, and WebArena. It shows step accuracy for Mind2Web and task success rate for the other two benchmarks. The table includes both API-based models (like GPT-3.5 and GPT-4), open-source instructed models (like CodeLlama), and open-source models fine-tuned with interactive data. The table highlights the superior performance of the Synatra-CodeLlama model compared to other models of a similar size and even some larger models, demonstrating the effectiveness of the Synatra data synthesis approach.
This table compares the performance of various models (including GPT-3.5 and GPT-4) across three web-based benchmark tasks (Mind2Web, MiniWoB++, and WebArena). For Mind2Web, step accuracy is reported; for MiniWoB++ and WebArena, task success rate is reported. The table highlights the performance of Synatra-CodeLlama in comparison to other models, particularly those of comparable size and those trained using interactive data. It notes that some results for comparison models were obtained from other publications.
Full paper#