↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current personalized image generation methods often involve computationally expensive fine-tuning or pre-training stages which limits flexibility and efficiency. The reliance on specialized classifiers further hinders practical application. This necessitates a training-free method that is both flexible and reliable.
RectifID leverages classifier guidance, utilizing a simple fixed-point solution within a rectified flow framework to resolve the classifier limitations. By anchoring the flow trajectory to a reference, RectifID provides a convergence guarantee. Experiments show successful personalization results on various tasks, including human faces and objects, demonstrating the effectiveness and broad applicability of this method.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a training-free method for personalizing image generation, overcoming the limitations of existing approaches that require extensive training data. This offers increased flexibility and efficiency, and opens new avenues for research in personalized image generation and other related areas. The method is also theoretically well-founded and provides convergence guarantees, enhancing its reliability and practical applicability.
Visual Insights#
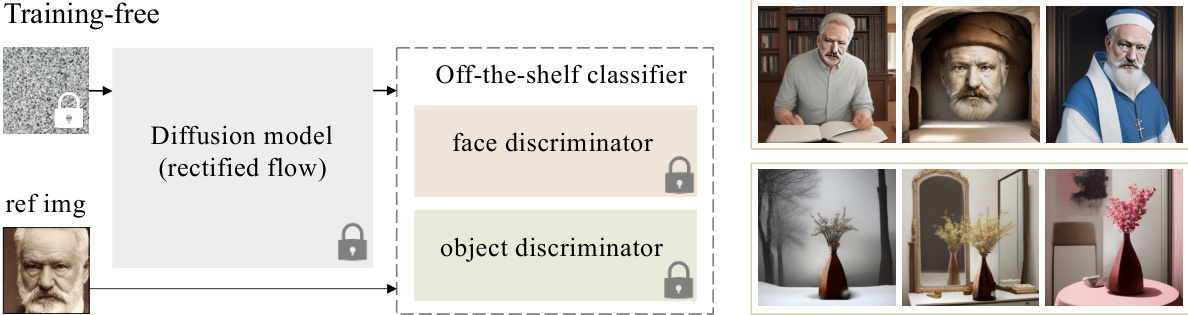
The figure illustrates the proposed training-free classifier guidance method. The left panel shows the process: A user provides a reference image (‘ref img’). A pre-trained diffusion model (based on rectified flow) is used, guided by an off-the-shelf classifier (either a face or object discriminator). This avoids the need for training a domain-specific classifier. The right panel displays example results of the personalized image generation for both human faces and objects, demonstrating the effectiveness of the method.
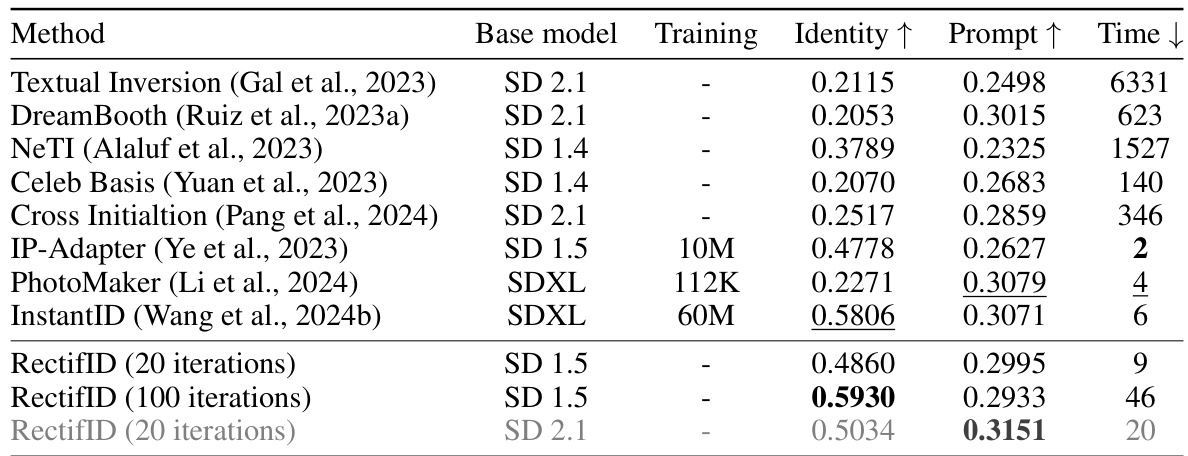
This table presents a quantitative comparison of different methods for face-centric personalization. It compares the proposed RectifID method to several existing methods, showing metrics such as identity preservation (Identity ↑), prompt consistency (Prompt ↑), and inference time (Time ↓). A key aspect highlighted is that RectifID achieves superior performance without requiring training on large face datasets, unlike many of the other methods compared.
In-depth insights#
RectifID: Anchored Flow#
RectifID, based on the concept of “Anchored Flow,” presents a novel approach to personalized image generation. It cleverly leverages classifier guidance without requiring any extra training, directly integrating user-provided references into a rectified flow framework. This training-free method enhances flexibility across various use cases. The core innovation lies in its stable fixed-point solution, which overcomes limitations of vanilla classifier guidance by approximating the rectified flow as ideally straight and anchoring it to a reference trajectory. This ensures both efficiency and a theoretical convergence guarantee. The method is shown to successfully personalize image generation across different subject types, including human faces and objects, demonstrating its robustness and versatility. The technique’s major strength lies in its training-free nature and use of off-the-shelf discriminators, making it a highly practical and adaptable solution for personalized image generation tasks.
Classifier Guidance#
Classifier guidance, a training-free technique, uses a pre-trained classifier to steer a diffusion model’s generation process. This avoids the need for extensive domain-specific training data, making the approach flexible and adaptable across various use cases. The method’s effectiveness relies on the classifier’s ability to discriminate between desired and undesired features, implicitly guiding the model towards identity-preserving images. A major limitation is the conventional need for a specially trained classifier that understands the model’s internal noise representation. However, this limitation can be overcome by using a simple fixed-point solution within a rectified flow framework, thereby leveraging readily available off-the-shelf discriminators. Anchoring the classifier-guided trajectory to a reference improves stability and convergence. This approach effectively leverages existing discriminators’ knowledge for image personalization, offering a cost-effective and flexible alternative to traditional training-based methods. The resulting method is shown to achieve advantageous personalization results in various settings.
Fixed-Point Solution#
The concept of a “Fixed-Point Solution” within the context of a research paper likely revolves around iterative algorithms. The core idea is to find a point where an iterative process converges, meaning that further iterations do not significantly change the solution. In the context of a machine learning algorithm, this often involves finding model parameters that minimize a loss function. Finding this fixed point efficiently is crucial for computational reasons and for ensuring the algorithm’s stability. The approach may involve techniques like gradient descent, but tailored to converge to the fixed point rather than merely finding a local minimum of the loss function. The paper likely demonstrates or analyzes the conditions under which this fixed-point solution is guaranteed to exist and how quickly the algorithm converges to it. This is especially important for complex models where naive iterative methods might be unstable or slow. The theoretical analysis of the fixed-point solution’s properties, such as convergence rate and stability, would be a central focus. A practical algorithm implementing this fixed-point solution might also be presented, including a discussion of its computational complexity and performance on benchmark datasets. Therefore, exploring this section would reveal core insights into the algorithm’s efficiency and reliability.
Convergence Guarantee#
A convergence guarantee in the context of a machine learning model, particularly one employing iterative optimization, is a crucial theoretical result. It signifies that the model’s learning process, perhaps involving classifier guidance or rectified flow, will reliably reach a solution or a stable state within a defined timeframe. This is important because iterative methods, while flexible, can sometimes oscillate, fail to converge, or become trapped in suboptimal solutions. A formal convergence guarantee enhances the reliability and predictability of the algorithm. The proof of such a guarantee usually relies on specific mathematical properties of the model and its optimization strategy—for instance, the ‘straightness’ property of rectified flow. The conditions under which this guarantee holds are critical; they specify the constraints on model architecture, data characteristics, and hyperparameter settings. Therefore, understanding these conditions is vital, as they inform the practical applicability and limitations of the model. Establishing a convergence guarantee increases confidence in a model’s robustness and trustworthiness, making it more suitable for deployment in sensitive applications or situations where stable performance is paramount.
Future Work#
The paper’s exploration of a training-free approach to personalize rectified flow using classifier guidance presents a promising direction, but several avenues for future work emerge. Extending the theoretical guarantees beyond the idealized straightness assumption of rectified flow is crucial for broader applicability. While the anchored method improves stability, investigating alternative anchoring strategies or incorporating techniques for handling non-straight trajectories could enhance performance and robustness. The current implementation demonstrates flexibility across various tasks, but thorough investigation of its limitations with complex or irregularly shaped objects would be beneficial. A comprehensive comparison against other training-free methods under different evaluation metrics and datasets would provide more robust validation. Finally, exploring the integration of this approach with more advanced diffusion models and studying its scalability for high-resolution image generation is vital for demonstrating its real-world potential. Addressing the computational cost compared to training-based methods remains a challenge and could be investigated through algorithmic optimizations or hardware acceleration.
More visual insights#
More on figures
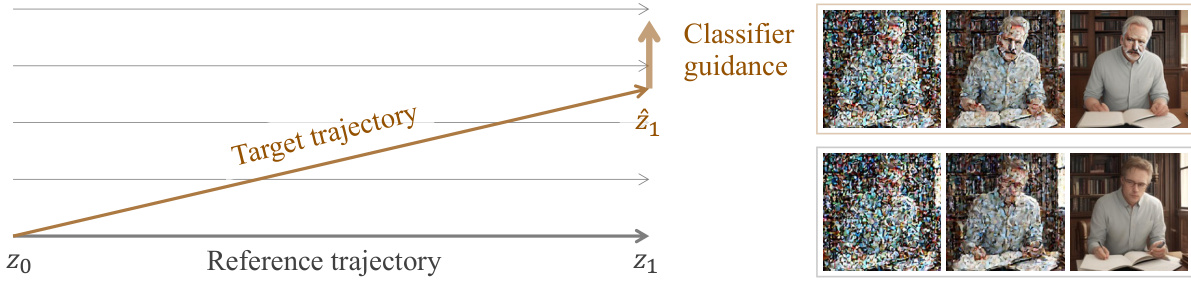
This figure illustrates the concept of anchored classifier guidance in the context of rectified flow. The left panel shows a schematic representation of how a target trajectory is guided towards a desired endpoint (z1) by incorporating classifier guidance, while simultaneously being constrained to remain close to a reference trajectory. This constraint helps to ensure the stability and convergence of the process. The right panel presents visual results, showcasing the last three steps of the sampling process, where the new trajectory (resulting from anchored classifier guidance) is compared to the reference trajectory. This comparison highlights the effectiveness of the approach in achieving both accurate guidance and stable convergence.

This figure compares the results of face-centric personalization using different methods. It shows a set of input images, and the results generated by the Celeb Basis, IP-Adapter, PhotoMaker, InstantID, and RectifID methods. The caption indicates that more examples can be found in figures 9 through 12 of the paper.

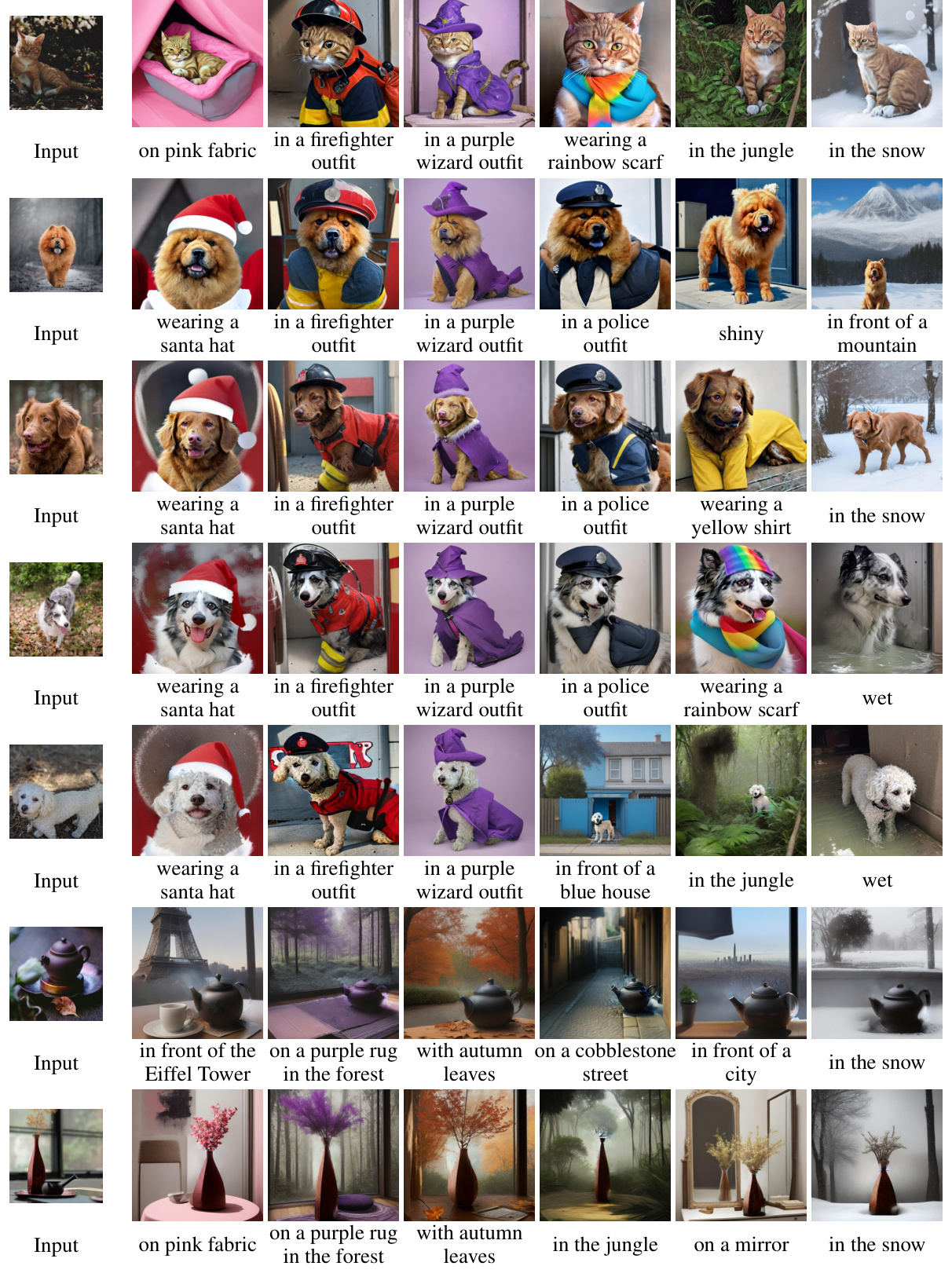
This figure compares the results of several methods for generating images with a user-specified subject. The methods compared include Textual Inversion, DreamBooth, BLIP-Diffusion, Emu2, and the proposed RectifID method. The top row shows the input reference image for each subject, and the subsequent rows show the generated images for different prompts. The asterisk (*) indicates that fine-tuning was performed on multiple images of the subject. The figure highlights the ability of the proposed RectifID method to generate images that accurately preserve the identity of the subject and are consistent with the given prompt, even when compared to methods that use finetuning.

This figure compares the results of multi-subject image generation using three different methods: FastComposer, Cones2, and the proposed RectifID method. The input shows two different reference images, one of a person and one of a dog. Each column shows the generation results for each method, demonstrating how each approach handles the task of integrating multiple subjects into a single generated image.

This ablation study compares the proposed anchored classifier guidance against two alternatives: gradient descent on the noise and classifier guidance without an anchor. Three different guidance scales (s × 0.5, s × 1, s × 2) and three different numbers of iterations (N = 20, N = 50, N = 100) are tested for each method. The results demonstrate that the proposed method is more stable, converges faster, and achieves better results in terms of identity preservation and prompt consistency.

This figure demonstrates the flexibility of the proposed method by incorporating guidance functions from Universal Guidance. The leftmost column displays the guidance (segmentation map or style transfer). The remaining columns present images generated using the method with different guidance types. This shows the method’s capability to extend beyond simple identity preservation to more controlled image generation scenarios.

This figure demonstrates the generalization of the proposed method to different diffusion models. Two few-step diffusion models (SD-Turbo and Phased Consistency Model) were tested. The results show that the method effectively personalizes these models to generate identity-preserving images, highlighting its adaptability and broader applicability beyond the initially used rectified flow model.

This figure shows a qualitative comparison of face-centric personalization results between the proposed RectifID method and several baselines (Celeb Basis, IP-Adapter, PhotoMaker, InstantID). The comparison is based on the generation of images according to a set of prompts, using a face as the reference image. The figure highlights the RectifID method’s superior ability to maintain identity while fulfilling the prompt’s requirements.

This figure shows a qualitative comparison of face-centric personalization results between RectifID and other methods. The input column shows the reference image and prompt used. The remaining columns display the generated images from different methods, allowing visual comparison of identity preservation and prompt adherence. The caption directs the reader to figures 9-12 for more generated image samples.

This figure compares the results of face-centric personalization using different methods. It shows several example images generated from the same input prompt by different methods. The goal is to generate images that accurately preserve the identity of the target face while also matching the provided text prompt. RectifID is shown along with other state-of-the-art methods for comparison. The additional figures mentioned (9-12) likely provide a more extensive set of examples.

This figure compares the results of face-centric personalization using different methods. The input is a reference image. The results show generated images of the same person in various styles, demonstrating the ability of each method to maintain identity consistency while varying the style. Additional examples are available in Figures 9-12.

This figure presents a qualitative comparison of face-centric personalization results from several different methods. It shows several examples of the input image (reference image), and results generated from different methods. The methods shown include Celeb Basis, IP-Adapter, PhotoMaker, InstantID, and the method proposed in this paper (RectifID). The images are meant to illustrate the capabilities of each method in creating identity-preserving images, highlighting differences in quality, accuracy of identity preservation, etc.

This figure compares the results of face-centric personalization using different methods. The input is a reference image and text prompt. Each column represents a different method (Celeb Basis, IP-Adapter, PhotoMaker, InstantID, and RectifID). The results show the generated images for each method, allowing for a visual comparison of identity preservation and adherence to the prompt. Further samples are provided in Figures 9-12.

This figure shows a qualitative comparison of face-centric personalization results between several different methods including the proposed RectifID method. The input is the reference image, while the output of different methods for generating images using the same prompt is shown. The RectifID method demonstrates successful preservation of identity and flexibility.

This figure shows a qualitative comparison of face-centric personalization results between several methods, including the proposed RectifID method. It displays generated images for various prompts, allowing a visual comparison of identity preservation and adherence to the prompt’s style. The additional figures mentioned (9-12) likely contain further examples.

This figure shows a qualitative comparison of face-centric personalization results between the proposed RectifID method and several other state-of-the-art methods. Different prompts are used as input, and the generated images from each method are displayed alongside the original input image and prompt. This allows for visual comparison of identity preservation and overall image quality.

This figure shows a qualitative comparison of face-centric personalization results between RectifID and other methods. Each method is given the same input (a text prompt and reference image), and the generated results are displayed. This allows for a visual comparison of identity preservation and prompt consistency.

This figure shows a qualitative comparison of face-centric personalization results using different methods. The input is a reference image. The columns show results from several different state-of-the-art methods along with the results from the proposed RectifID method. The results demonstrate the ability of RectifID to generate high-fidelity images while preserving the identity of the subject.

This figure shows a qualitative comparison of face-centric personalization results between RectifID and several other methods. It visually demonstrates the ability of RectifID to generate images that accurately preserve the identity of the input face, even when applying different prompts. The additional figures referenced (9-12) contain more examples of the generated images for a more thorough comparison.
This figure illustrates the concept of anchored classifier guidance. The left panel shows how the proposed method guides the flow trajectory while keeping it close to a reference trajectory to maintain stability. The right panel presents a visual comparison, highlighting how the new trajectory stays close to the reference in its final stages.

This figure shows example results of applying the RectifID method to generate images with multiple subjects. The method successfully integrates multiple subjects into a single image while preserving the identity of each subject, demonstrating the capability of the method for multi-subject personalization tasks. The results are based on the piecewise rectified flow model (Yan et al., 2024) built on Stable Diffusion 1.5 (Rombach et al., 2022).
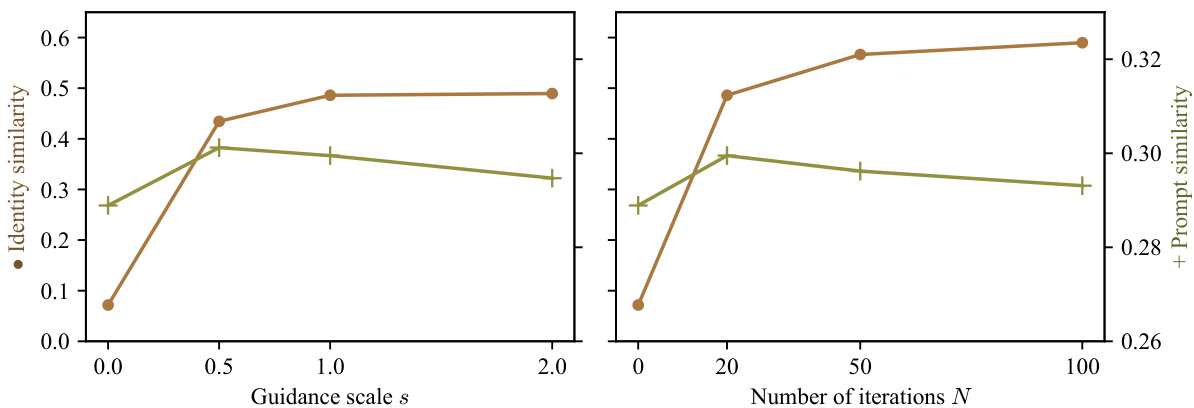
This figure shows the results of an ablation study on the hyperparameters of the proposed method. The left panel shows how identity and prompt similarity change as the guidance scale (s) varies, while keeping the number of iterations (N) constant at 20. The right panel shows how these metrics change as N varies, while keeping s constant at 1.0. The results demonstrate the robustness of the method to changes in both hyperparameters within a reasonable range.

This figure shows a qualitative comparison of face-centric personalization results between different methods, including the proposed RectifID method. Each row represents a different prompt, and each column showcases the output images from various methods. The RectifID method is shown to produce images with higher identity preservation and better prompt consistency compared to the other methods.

This figure shows a qualitative comparison of face-centric personalization results between several methods including the proposed RectifID. Each row represents a different prompt and each column a different method. The results illustrate the ability of RectifID to generate images that maintain identity consistency while adhering to the prompt.
Full paper#



















