↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
High-resolution text-to-image (T2I) models like Stable Diffusion XL (SDXL) demand significant computational resources, hindering accessibility and reproducibility. The high inference costs and reliance on expensive GPUs are major obstacles for many researchers. This paper tackles these challenges by exploring ways to build more memory-efficient and faster T2I models using only publicly available datasets and open-source models.
The authors present KOALA, two types of efficient T2I models (KOALA-Turbo and KOALA-Lightning), leveraging three key practices: knowledge distillation, utilizing high-resolution images with detailed captions for training, and using step-distilled teacher models to reduce the number of denoising steps. KOALA-Lightning-700M achieves a 4x speedup over SDXL while maintaining quality, and runs on consumer-grade GPUs with 8GB VRAM, unlike SDXL. This demonstrates significant progress towards making high-quality T2I synthesis more accessible and practical.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in text-to-image synthesis due to its focus on memory efficiency and speed. By providing practical solutions for building efficient models, it opens avenues for researchers with limited resources, thereby broadening the field’s accessibility and fostering innovation.
Visual Insights#

This figure showcases eight images generated by the KOALA-Lightning-700M model. Each image is 1024x1024 pixels and was produced using only 10 denoising steps, a significant reduction compared to other models. The generation time was remarkably fast (0.65 seconds) using an NVIDIA 4090 GPU. The prompts used to generate these specific images, and more detailed comparisons of the model’s output quality, are provided in Appendix C of the paper.

This table compares the U-Net architecture of several models: SDM-v2.0, SDXL-1.0, BK-SDXL, KOALA-1B, and KOALA-700M. It shows the number of parameters, checkpoint file size, the number of transformer blocks in each stage, the presence of a mid block, and inference latency. The comparison highlights the reduction in model size and latency achieved by the KOALA models compared to the original SDXL.
In-depth insights#
Efficient T2I Models#
The pursuit of efficient text-to-image (T2I) models is crucial due to the high computational cost of existing large models. Reducing inference time and memory footprint is paramount for broader accessibility and practical applications. Several strategies are explored to achieve this efficiency, such as knowledge distillation, which trains a smaller student model to mimic the behavior of a larger teacher model. The choice of teacher model significantly impacts performance; step-distilled teachers prove effective in reducing denoising steps and improving efficiency. Data characteristics also play a critical role, with high-resolution images and detailed captions proving more beneficial than large datasets of low-resolution images. Lastly, model architecture optimization, specifically focusing on the U-Net, is vital, particularly exploring techniques to reduce parameters without sacrificing image quality. This includes strategic removal of layers or blocks and leveraging the power of self-attention to distill crucial features. The outcome is a family of significantly smaller and faster KOALA models that achieve comparable performance to state-of-the-art models, demonstrating significant progress toward creating efficient and widely deployable T2I systems.
KD Strategies#
The effectiveness of knowledge distillation (KD) hinges on strategic choices. Self-attention-based KD outperforms other methods, focusing on distilling self-attention features which capture semantic relationships and object structures better than simply using the last feature layer. This highlights the importance of selecting the right features for distillation. The choice of teacher model also significantly impacts the student’s capabilities; step-distilled teachers (SDXL-Turbo, SDXL-Lightning) are particularly effective, leading to faster and more efficient models. Finally, high-resolution images with detailed captions are crucial for effective KD training, even if it means using a smaller dataset. The findings demonstrate the interplay between feature selection, teacher selection, and data quality in achieving superior KD performance.
Data & Teacher Impact#
The paper investigates the impact of data and teacher model selection on the performance of efficient text-to-image diffusion models. High-resolution images with rich captions prove more valuable than a large quantity of low-resolution images with short captions, even with fewer samples. This highlights the importance of data quality over quantity in knowledge distillation. The choice of teacher model significantly influences the student model’s ability. Using step-distilled teacher models like SDXL-Turbo and SDXL-Lightning allows for a reduction in denoising steps, resulting in faster inference speeds while maintaining satisfactory generation quality. Self-attention based knowledge distillation emerges as a crucial technique, enhancing the student model’s ability to learn discriminative representations and generate more distinct objects. These findings demonstrate the critical interplay between data quality, teacher model selection, and knowledge distillation techniques in achieving efficient and high-quality text-to-image synthesis.
KOALA Model Results#
The KOALA model results demonstrate significant improvements in efficiency and speed compared to existing text-to-image models. KOALA-Lightning-700M, in particular, shows a 4x speed increase over SDXL while maintaining comparable image quality. This is achieved through a combination of knowledge distillation, optimized data usage, and a step-distilled teacher model. The reduced model size (up to 69% smaller than SDXL) makes KOALA suitable for consumer-grade GPUs, unlike its predecessors. These results highlight the successful implementation of the three key lessons outlined in the paper, showing that significant gains are achievable in T2I models while utilizing only publicly available datasets and open-source models. KOALA represents a cost-effective and accessible alternative for both academic researchers and general users. Further analysis is required to fully assess the generalization capabilities and limitations of the model in various scenarios, such as prompts requiring complex compositional details or those including text generation.
Limitations & Future#
The research paper’s limitations section would likely discuss the model’s shortcomings in generating high-quality images with complex prompts, especially those involving legible text or intricate object relationships. The reliance on publicly available datasets might constrain the model’s performance compared to those trained on proprietary, high-quality datasets. Specific architectural choices, such as the method of U-Net compression, may also introduce limitations. Future work could address these limitations by exploring alternative training data sources, refining the model architecture for improved performance, particularly in generating more complex scenes, and potentially investigating more sophisticated knowledge distillation techniques. Investigating methods to improve text generation and overall image fidelity is crucial. Additionally, exploring the trade-offs between model size and generation quality would be beneficial. Addressing ethical concerns through enhanced NSFW detection and filtering is also critical for future development.
More visual insights#
More on figures
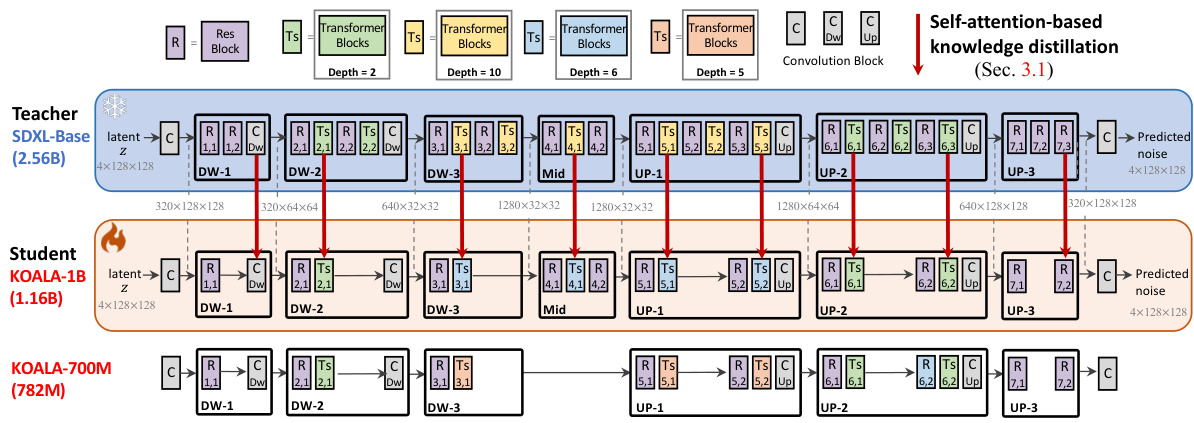
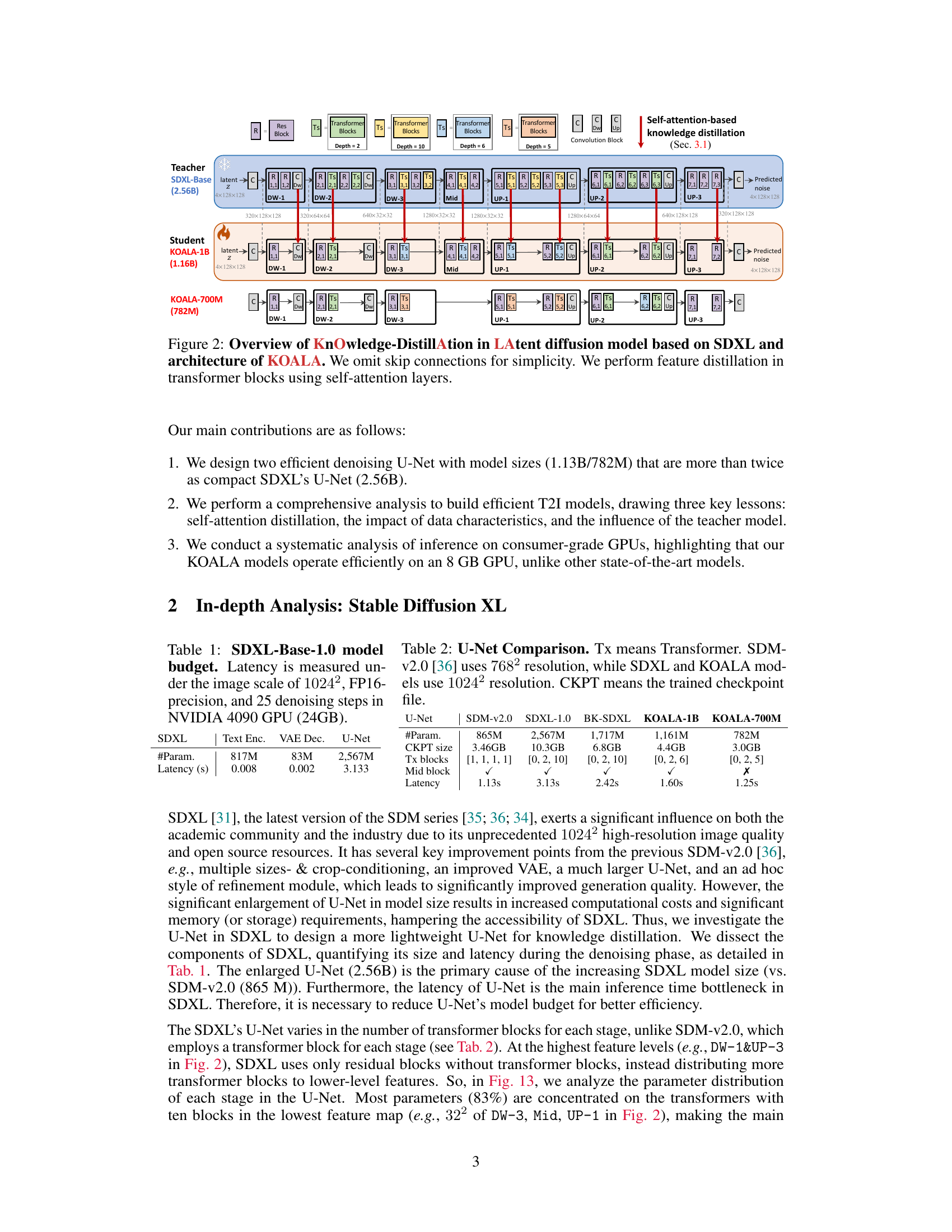
This figure illustrates the knowledge distillation process used to create the KOALA model. It shows the architecture of the teacher model (SDXL-Base), and two student models (KOALA-1B and KOALA-700M). The diagram highlights how knowledge is distilled from the teacher’s transformer blocks, specifically targeting self-attention layers to improve the efficiency and performance of the student models. Skip connections are omitted for clarity.

This figure demonstrates the effectiveness of self-attention-based knowledge distillation. It compares the results of using only the last feature map (LF) for distillation (as in BK-SDM) versus using self-attention (SA) features. The (a) section shows generated images highlighting the appearance leakage in the LF approach. The (b) section shows PCA analysis of self-attention maps, demonstrating the improved discrimination in the SA-based approach. Finally, the (c) section visualizes self-attention maps from different stages of the U-Net, illustrating how the SA approach attends to the rabbit more distinctively.

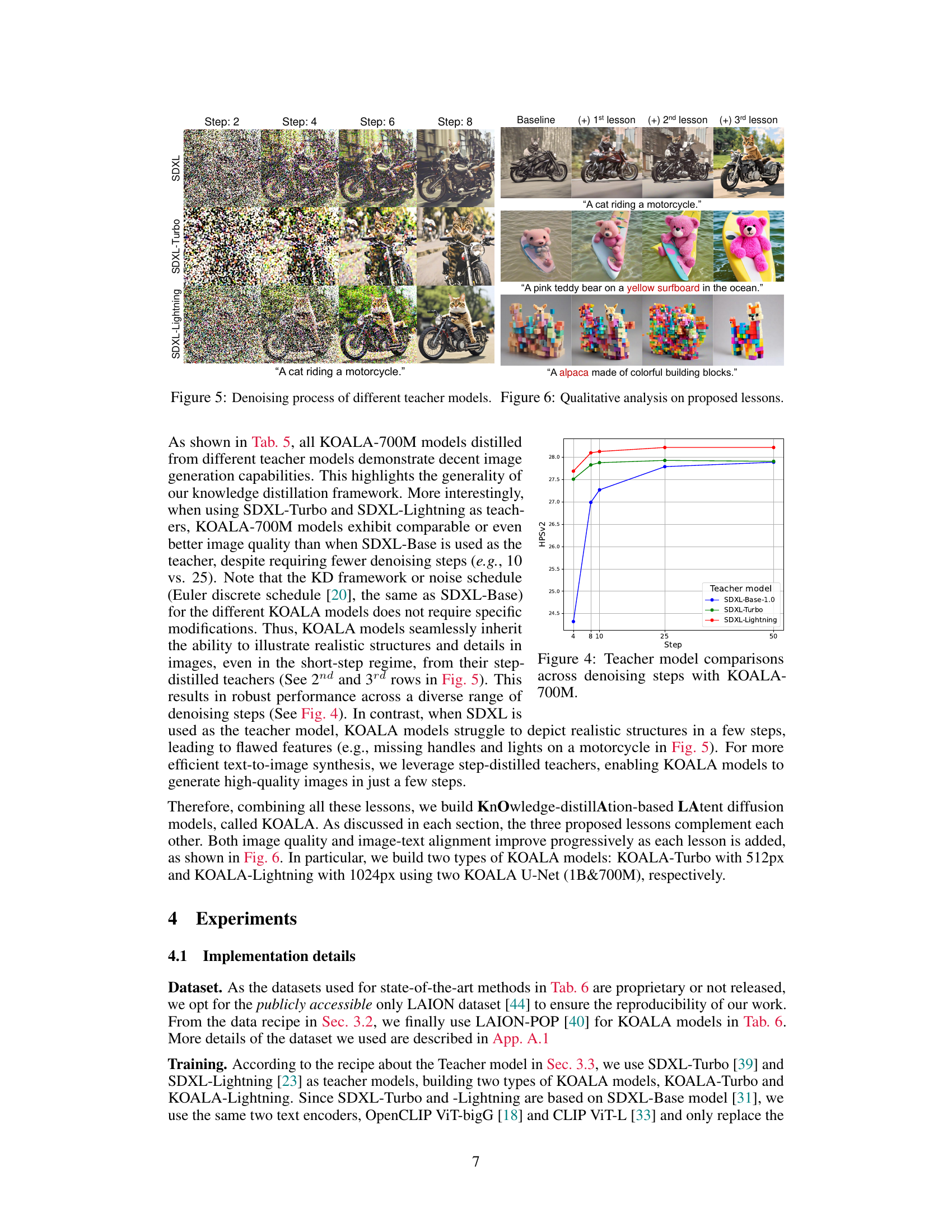
This figure shows the denoising process of three different teacher models (SDXL, SDXL-Turbo, and SDXL-Lightning) for generating images of three different prompts. Each row represents a different teacher model, and each column represents a different denoising step (2, 4, 6, and 8). The rightmost column shows the final generated images after completing all steps. The figure visually demonstrates the influence of each teacher model on the generated image quality at different stages of the denoising process.
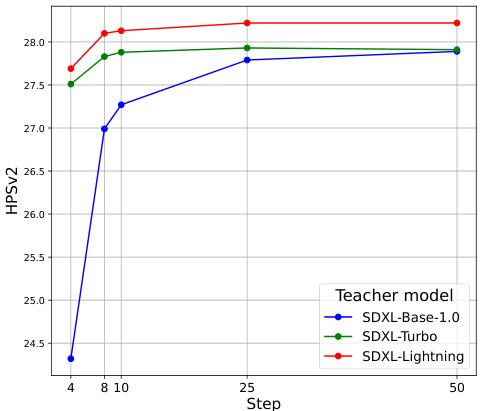
This figure shows how the performance of the KOALA-700M model varies when trained with different teacher models (SDXL-Base-1.0, SDXL-Turbo, SDXL-Lightning) and different numbers of denoising steps. The HPSv2 score, a measure of visual aesthetic quality, is plotted against the number of denoising steps. The graph allows for a comparison of the model’s performance across different teachers and step counts, highlighting the impact of teacher model selection and step reduction on image generation quality.
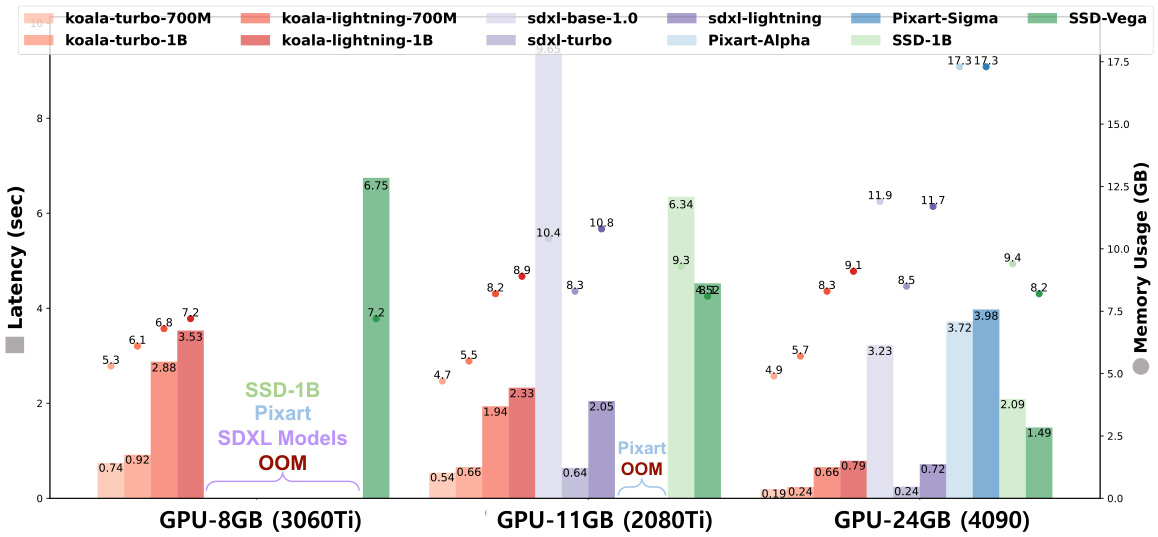
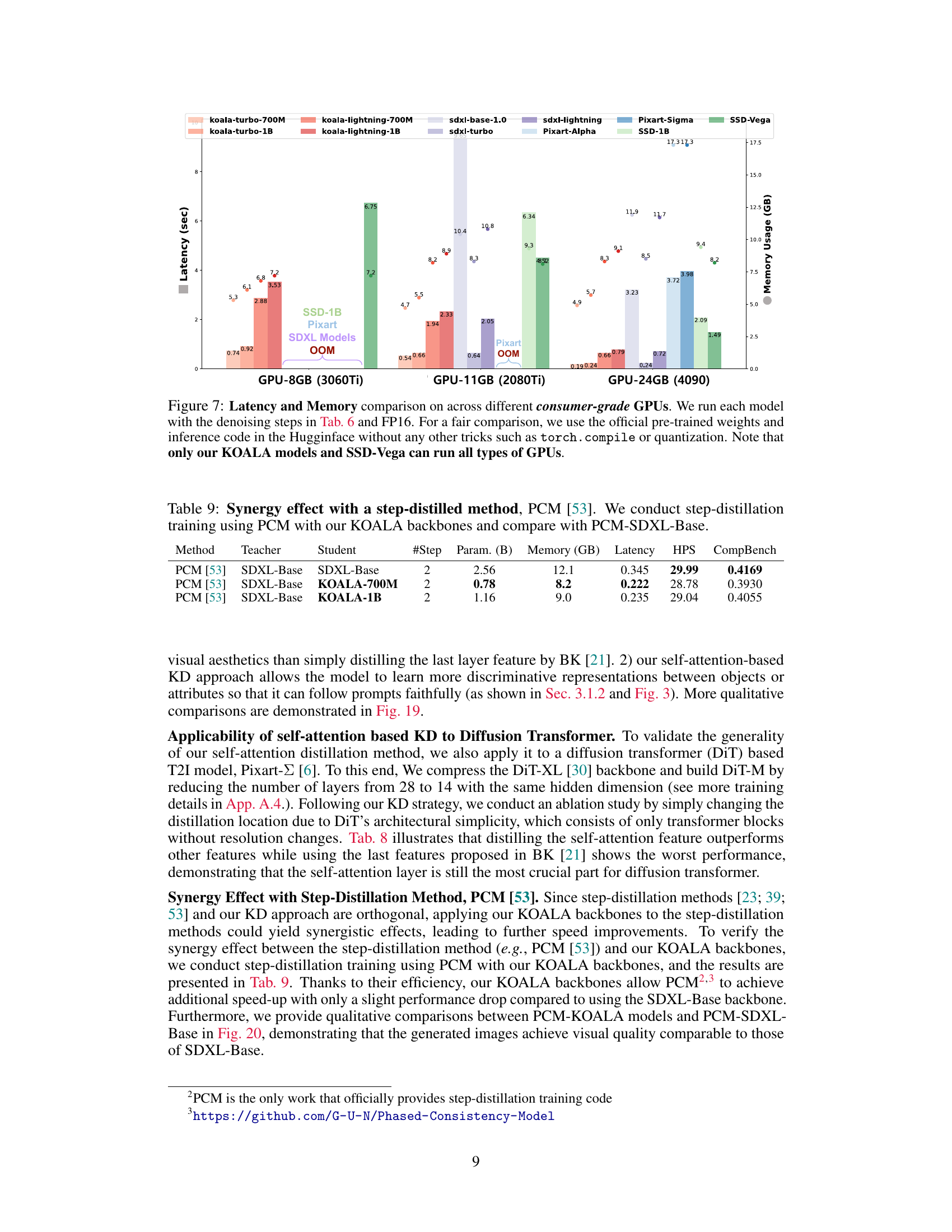
This figure compares the latency and memory usage of various text-to-image models (including the authors’ KOALA models and several state-of-the-art models) across different consumer-grade GPUs with varying VRAM capacities (8GB, 11GB, and 24GB). The results highlight the superior performance of the KOALA models, especially on GPUs with limited memory, demonstrating their efficiency and accessibility in resource-constrained environments.

This figure shows two examples where the KOALA-700M model struggles. The first example shows a failure to generate legible text in an image. The second example demonstrates difficulty generating an image with complex attributes and object relationships as described in the prompt.

This figure showcases example images generated by the KOALA-Lightning-700M model. The images demonstrate the model’s ability to produce high-quality (1024x1024 pixels) images in a very short time (0.65 seconds on a high-end GPU). Additional examples and prompt details are available in Appendix C.

This figure shows the comparison of self-attention maps between the BK-SDM model and the proposed KOALA model. The top row shows the generated images and the PCA analysis of the UP-1 stage self-attention map highlighting how the SA-based model (KOALA) attends to the rabbit more distinctly compared to the LF-based model (BK-SDM), leading to improved generation of objects. The bottom row shows representative self-attention maps from different U-Net stages in KOALA, visually demonstrating the more discriminative attention mechanism in KOALA.
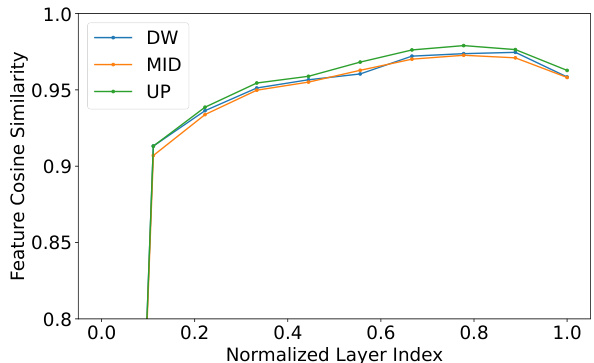
The figure shows the cosine similarity between the features of consecutive transformer layers within each stage (DW, MID, UP) of the SDXL U-Net model. The x-axis represents the normalized layer index within each stage, ranging from 0 to 1. The y-axis represents the cosine similarity. The plot reveals that the cosine similarity increases rapidly for the initial layers within each stage and then plateaus or slightly decreases in later layers. This suggests that the initial layers within each stage of the transformer blocks contribute more significantly to the overall feature representation than the later layers, supporting the authors’ design choices in their knowledge distillation method.
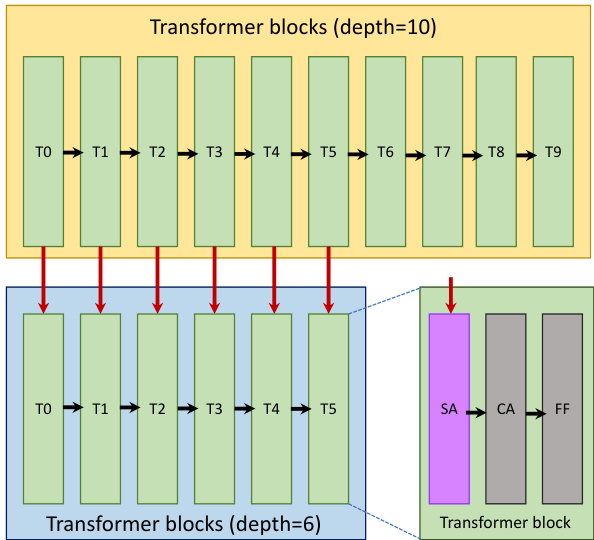
This figure illustrates the knowledge distillation process from the teacher model (SDXL) to the student model (KOALA). It shows how the self-attention layers within the transformer blocks of SDXL’s U-Net are used to distill knowledge into the smaller U-Nets of the KOALA models (KOALA-1B and KOALA-700M). The figure highlights the architecture of KOALA’s U-Net, which is a compressed version of SDXL’s U-Net, achieved by removing blocks and layers to reduce the model’s size and computational cost. The key idea is to use knowledge distillation, specifically focusing on self-attention features to transfer the generative capabilities of the larger model to the smaller models effectively.
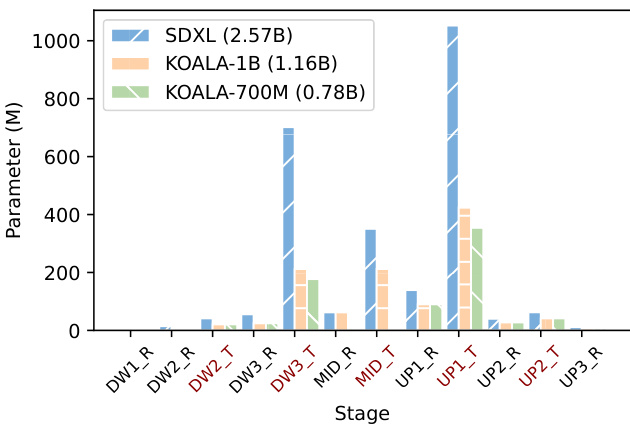
This figure shows a detailed breakdown of the U-Net architecture in Stable Diffusion XL (SDXL). It illustrates the different stages (DW1 to UP3) with their corresponding components: residual blocks (R) and transformer blocks (T). The colored bars represent the parameter count for each component in SDXL, KOALA-1B, and KOALA-700M, highlighting the significant reduction in parameters achieved by the KOALA models. The figure provides valuable insights into the architectural modifications made to create the more efficient KOALA models.

This figure showcases sample images generated by the KOALA-Lightning-700M model. The images are 1024x1024 pixels and were generated using only 10 denoising steps, highlighting the model’s efficiency. The generation time of 0.65 seconds on an NVIDIA 4090 GPU emphasizes speed. Appendix C provides more details and additional comparative results.

This figure shows example images generated by the KOALA-Lightning-700M model. The images are 1024x1024 pixels and were generated using only 10 denoising steps, resulting in a generation time of 0.65 seconds on a high-end NVIDIA 4090 GPU. The speed and quality of generation highlight the efficiency of the KOALA model. More detailed information about the prompts used and additional image comparisons are available in Appendix C.

This figure shows example images generated by the KOALA-Lightning-700M model. The model produced these 1024x1024 pixel images in just 0.65 seconds using an NVIDIA 4090 GPU. Only 10 denoising steps were used. Appendix C contains more examples and details about the prompts used to generate these images.

This figure shows the knowledge distillation process from the teacher model (SDXL) to the student model (KOALA). It illustrates how the self-attention layers in the transformer blocks of SDXL’s U-Net are used to distill knowledge into the smaller, more efficient U-Net of KOALA. The figure highlights the architecture of KOALA-1B and KOALA-700M, demonstrating how the model size is reduced by removing blocks and layers, while maintaining the performance via the knowledge distillation.

This figure showcases sample images generated by the KOALA-Lightning-700M model. The images, at a 1024x1024 pixel resolution, were produced using only 10 denoising steps, demonstrating the model’s speed and efficiency. The generation time of 0.65 seconds on an NVIDIA 4090 GPU highlights the significant performance improvement achieved. Further details and comparisons can be found in Appendix C.

This figure displays sample images generated by the KOALA-Lightning-700M model. The images are 1024 x 1024 pixels and were generated in 0.65 seconds using an NVIDIA 4090 GPU. Only 10 denoising steps were used, demonstrating the model’s efficiency. The prompts used to generate each image, along with additional qualitative comparisons, can be found in Appendix C of the paper.

This figure shows example images generated by the KOALA-Lightning-700M model. The model generated these 1024x1024 pixel images in just 0.65 seconds using an NVIDIA 4090 GPU. The generation used only 10 denoising steps. More examples and the prompts used are available in Appendix C.

This figure shows example images generated by the KOALA-Lightning-700M model. The images are high-resolution (1024x1024 pixels) and were produced using only 10 denoising steps, resulting in fast generation time (0.65 seconds on an NVIDIA 4090 GPU). The figure highlights the model’s ability to generate high-quality images. More detailed descriptions of the prompts used and additional comparisons can be found in Appendix C.

This figure showcases example images generated by the KOALA-Lightning-700M model. The model produced 1024x1024 pixel images in just 0.65 seconds using an NVIDIA 4090 GPU. Only 10 denoising steps were used. Appendix C provides further details on the prompts used and a more extensive qualitative comparison of the generated images.

This figure demonstrates the effectiveness of self-attention-based knowledge distillation. It compares the results of a baseline knowledge distillation method (BK-SDM) with the proposed self-attention method. The image shows that the self-attention method better distinguishes objects, preventing issues like ‘appearance leakage’ where a rabbit is misidentified as a hippopotamus. The PCA analysis and visualizations of self-attention maps across different U-Net stages further support the superior performance of the self-attention approach.

This figure showcases instances where the KOALA-700M model struggles. The left image shows limitations in generating legible text, while the right image demonstrates difficulties in handling complex prompts with multiple attributes or object relationships. These limitations highlight areas where the model’s capabilities require further improvement.

This figure shows a comparison between two different knowledge distillation methods for text-to-image synthesis models: one using only the last layer’s features (LF) and another using self-attention (SA) features. The results indicate that SA-based KD leads to better object discrimination and avoids appearance leakage, resulting in more distinct and accurate image generation.

This figure showcases example images generated by the KOALA-Lightning-700M model. The model produced these 1024x1024 pixel images in just 0.65 seconds using an NVIDIA 4090 GPU. Only 10 denoising steps were used. More examples and a detailed comparison are provided in Appendix C.

This figure showcases image samples generated by the KOALA-Lightning-700M model. Each image is 1024x1024 pixels and was generated using only 10 denoising steps, a significant reduction compared to other models. The generation time was exceptionally fast, at just 0.65 seconds on a high-end NVIDIA 4090 GPU. Appendix C contains the prompts used to create these images and more detailed comparisons.

The figure shows two examples where the KOALA-700M model struggles. In the left example, the model has difficulty generating legible text. In the right example, the model has problems generating complex prompts with multiple attributed or object relationships.

This figure showcases example images generated by the KOALA-Lightning-700M model. The model produced 1024x1024 pixel images in 0.65 seconds using an NVIDIA 4090 GPU with only 10 denoising steps. The prompts used to generate these images, and further qualitative comparisons, can be found in Appendix C of the paper.

This figure compares the latency and memory usage of various text-to-image models, including KOALA and several state-of-the-art models, across different consumer-grade GPUs with varying memory capacities (8GB, 11GB, and 24GB). The results highlight KOALA’s superior efficiency and ability to run on lower-memory GPUs, unlike other models which often experience out-of-memory errors. The experiment used standard settings without additional optimization techniques for a fair comparison.

This figure demonstrates the effectiveness of self-attention-based knowledge distillation. It compares the results of two methods: one using only the last feature (LF) map of the teacher model (BK-SDM), and the other using self-attention (SA) maps. The results show that the SA-based method generates more distinct objects, avoiding the ‘appearance leakage’ observed in the LF-based method. The figure includes visualizations of generated images, PCA analysis of self-attention maps, and representative self-attention maps from different stages of the U-Net, highlighting the improved discriminative ability of the SA-based approach.

This figure showcases example images generated by the KOALA-Lightning-700M model. The model generated these 1024x1024 pixel images in just 0.65 seconds using an NVIDIA 4090 GPU. The image generation used only 10 denoising steps. Appendix C of the paper contains the prompts used to generate these images and more detailed qualitative comparisons.

This figure showcases image samples generated by the KOALA-Lightning-700M model. The images are 1024x1024 pixels and were created using only 10 denoising steps, a significant reduction compared to other models. The generation speed is highlighted as 0.65 seconds on an NVIDIA 4090 GPU, demonstrating the model’s efficiency. Appendix C provides further details on the prompts used and additional qualitative comparisons.

This figure showcases example images generated by the KOALA-Lightning-700M model. The model produced high-resolution (1024x1024 pixels) images in just 0.65 seconds using an NVIDIA 4090 GPU. Only 10 denoising steps were required. More examples and comparisons are available in Appendix C.

This figure showcases example images generated by the KOALA-Lightning-700M model. The images demonstrate the model’s ability to produce high-resolution (1024x1024 pixels) outputs in a short timeframe (0.65 seconds on an NVIDIA 4090 GPU) using only 10 denoising steps. A wider range of examples and prompts used to generate the images are provided in Appendix C.

This figure showcases example outputs generated by the KOALA-Lightning-700M model. The images demonstrate the model’s ability to produce high-resolution (1024x1024 pixels) images in a short amount of time (0.65 seconds on a high-end GPU). The diversity of the generated images highlights the model’s capacity to interpret a range of text prompts, with more examples detailed in Appendix C.

This figure displays several example images generated by the KOALA-Lightning-700M model. Each image is 1024x1024 pixels and was generated using only 10 denoising steps, highlighting the model’s speed and efficiency. The generation time for each image was 0.65 seconds on an NVIDIA 4090 GPU. Appendix C contains a more detailed analysis of the results, including the prompts used for each image.

This figure showcases example images generated by the KOALA-Lightning-700M model. The images demonstrate the model’s ability to produce high-resolution (1024x1024 pixels) outputs in a very short time (0.65 seconds on a high-end NVIDIA 4090 GPU) using only 10 denoising steps. The captions for each image are detailed in Appendix C, along with further qualitative comparisons.

This figure showcases sample images generated by the KOALA-Lightning-700M model. The images are 1024x1024 pixels and were created using only 10 denoising steps, resulting in a generation time of just 0.65 seconds on an NVIDIA 4090 GPU. The figure highlights the model’s efficiency and speed. More detailed image descriptions and comparisons are provided in Appendix C.

This figure showcases example images generated by the KOALA-Lightning-700M model. The images demonstrate the model’s ability to produce high-resolution (1024x1024 pixels) outputs with good quality, even with only 10 denoising steps, and in a very short time (0.65 seconds on an NVIDIA 4090 GPU). Further examples and prompts used are available in Appendix C.

This figure shows the analysis of self-attention maps in distilled student U-Nets, comparing the results of the proposed self-attention-based method with the baseline method. The results highlight the importance of self-attention for knowledge distillation, enabling more distinct generation of objects and avoiding appearance leakage.

This figure illustrates the knowledge distillation process from the teacher model (SDXL-Base) to the student models (KOALA-1B and KOALA-700M). It shows the architecture of the two KOALA models, highlighting the reduction in the number of layers and blocks compared to SDXL. The key aspect is the self-attention-based knowledge distillation strategy employed, focusing on distilling knowledge from the self-attention layers of the teacher model to improve the performance of the smaller student models.

This figure displays a qualitative comparison of image generation results between the BK-Base-700M model and the KOALA-700M model. Both models used the same training recipe and data (LAION-A+6 dataset and SDXL-Base-1.0 as the teacher model). The comparison highlights the superior image quality and adherence to prompts demonstrated by the KOALA-700M model.

This figure shows example images generated by the KOALA-Lightning-700M model. The model is highlighted for its speed and efficiency, generating 1024x1024 pixel images in under a second on a high-end GPU using only 10 denoising steps. Appendix C provides more examples and detailed descriptions of the prompts used.

This figure displays several images generated by the KOALA-Lightning-700M model. Each image is 1024 x 1024 pixels and was generated in 0.65 seconds using an NVIDIA 4090 GPU with only 10 denoising steps. The prompts used to create each image, along with additional qualitative comparisons, can be found in Appendix C of the paper. This showcases the model’s speed and efficiency in generating high-resolution images.

This figure shows a qualitative comparison of image generation results between BK-SDM’s 700M model and the KOALA-700M model. Both models used the same training data (LAION-A+6 dataset) and teacher model (SDXL-Base-1.0). The images generated demonstrate KOALA’s superior ability to generate images that closely align with the text prompts, suggesting improved image quality and a stronger ability to follow the prompt’s instructions.

This figure displays a qualitative comparison of image generation results between BK-Base-700M and KOALA-700M models. Both models were trained using the same settings (LAION-A+6 dataset and SDXL-Base-1.0 teacher model). The comparison showcases the visual differences in image generation quality between the two models, highlighting KOALA-700M’s improved performance.

This figure shows example images generated by the KOALA-Lightning-700M model. The model generated these 1024x1024 pixel images in just 0.65 seconds using an NVIDIA 4090 GPU, demonstrating its speed and efficiency. The prompts used to generate each image, as well as additional qualitative comparisons, are available in Appendix C.

This figure displays example images generated by the KOALA-Lightning-700M model. The images are 1024x1024 pixels in resolution and were generated using only 10 denoising steps, which is significantly faster than the original SDXL model. The generation time was 0.65 seconds on an NVIDIA 4090 GPU. Appendix C contains a more detailed description of the prompts used and additional qualitative comparisons.

This figure showcases sample images generated by the KOALA-Lightning-700M model. The images, at a resolution of 1024x1024 pixels, were produced using only 10 denoising steps, demonstrating the model’s efficiency. The generation time was a mere 0.65 seconds on an NVIDIA 4090 GPU. Appendix C provides further details on the prompts used and additional comparative analyses.

This figure showcases example outputs generated by the KOALA-Lightning-700M model. Each image demonstrates the model’s ability to create high-resolution (1024x1024 pixels) images from text prompts within a short timeframe (0.65 seconds on an NVIDIA 4090 GPU). The images depict diverse scenes, highlighting the model’s versatility. More detailed examples and comparisons are available in Appendix C.

This figure displays several example images generated by the KOALA-Lightning-700M model. Each image is 1024x1024 pixels and was generated using only 10 denoising steps, resulting in a generation time of just 0.65 seconds on an NVIDIA 4090 GPU. The figure showcases the model’s ability to generate high-quality images quickly and efficiently. More examples and a detailed comparison of the prompts used are available in Appendix C.

This figure presents a comparative analysis of self-attention maps from different U-Net models (BK-SDM and the proposed model). It shows that using self-attention for knowledge distillation allows the model to generate objects more distinctly, unlike the BK-SDM model, which exhibits appearance leakage (e.g., a rabbit depicted as a hippopotamus). The analysis includes generated images, PCA analysis of self-attention maps, and visualizations of self-attention maps from various U-Net stages.

This figure compares the latency and memory usage of various models, including KOALA and SDXL models, on different consumer-grade GPUs with varying memory capacities (8GB, 11GB, and 24GB). It highlights that KOALA models are more efficient and can run on lower-memory GPUs, unlike other models which often fail due to memory limitations. The comparison is done using official pretrained weights and standard inference code without any optimization techniques to ensure fair evaluation.

This figure analyzes self-attention maps in distilled U-Net models to show the effectiveness of self-attention-based knowledge distillation. It compares the results of using only the last feature (LF) for distillation (as in BK-SDM) versus using self-attention (SA) features. The figure shows that SA-based distillation leads to more discriminative object generation, as evidenced by the more distinct representation of the rabbit in the generated image compared to the BK-SDM model, which shows appearance leakage. PCA analysis further supports this, showing better separation of objects in SA-based models. Visualizations of the self-attention maps at different U-Net stages also demonstrate that SA-based models attend to objects more effectively.

This figure shows example images generated by the KOALA-Lightning-700M model. The images demonstrate the model’s ability to generate high-resolution (1024x1024 pixels) images with good quality in a very short time (0.65 seconds on an NVIDIA 4090 GPU), using only 10 denoising steps. The prompts used to generate these images, and further qualitative comparisons, are available in Appendix C of the paper.

This figure displays several example images generated by the KOALA-Lightning-700M model. These images demonstrate the model’s capability to produce high-resolution (1024x1024 pixels) images with good quality in a relatively short timeframe (0.65 seconds on a high-end NVIDIA 4090 GPU). The prompts used to generate each image and additional qualitative comparisons are detailed in Appendix C of the paper.

This figure showcases example images generated by the KOALA-Lightning-700M model. The images demonstrate the model’s ability to generate high-resolution (1024x1024 pixels) images in a short amount of time (0.65 seconds on an NVIDIA 4090 GPU). The images are the result of 10 denoising steps, highlighting the efficiency of the model. More examples and the prompts used are provided in Appendix C.

This figure displays example images generated by the KOALA-Lightning-700M model. The model efficiently produces 1024x1024 pixel images in only 0.65 seconds using an NVIDIA 4090 GPU. The generation used only 10 denoising steps, demonstrating the model’s speed and efficiency. Appendix C provides further details on the prompts used and additional qualitative comparisons.

This figure shows several example images generated by the KOALA-Lightning-700M model. The model produced 1024x1024 pixel images in 0.65 seconds using an NVIDIA 4090 GPU. Only 10 denoising steps were used. The figure showcases the model’s ability to generate high-quality and diverse images from a variety of text prompts. More examples and a detailed comparison can be found in Appendix C.

This figure showcases sample images generated by the KOALA-Lightning-700M model. The images are 1024 x 1024 pixels and were generated using only 10 denoising steps, resulting in a fast generation time of 0.65 seconds on a high-end NVIDIA 4090 GPU. The prompts used to generate each image and more detailed qualitative comparisons are provided in Appendix C.

This figure showcases sample images generated by the KOALA-Lightning-700M model. The images are 1024x1024 pixels in resolution and were created using only 10 denoising steps, demonstrating the model’s speed and efficiency. The generation time of 0.65 seconds on an NVIDIA 4090 GPU highlights its performance. More detailed prompts and additional qualitative comparisons can be found in Appendix C.
More on tables

This table presents the results of an ablation study on different feature levels for knowledge distillation in the U-Net of Stable Diffusion XL (SDXL). It investigates which features (self-attention (SA), cross-attention (CA), residual (Res), feed-forward network (FFN), and last feature (LF)) and at which stage (DW-2, DW-3, Mid, UP-1, UP-2) of the U-Net are most effective for knowledge distillation. The results are evaluated using the Human Preference Score (HPSv2).

This table compares three different training datasets used in the paper, showing the number of images, average resolution (AR), average caption length (ACL), and the resulting HPSv2 and CompBench scores. It also shows how synthetic captions generated by the LLaVA-v1.5 model were used to augment the dataset. The results highlight the impact of data quality (resolution and caption length) on the performance of the text-to-image models.
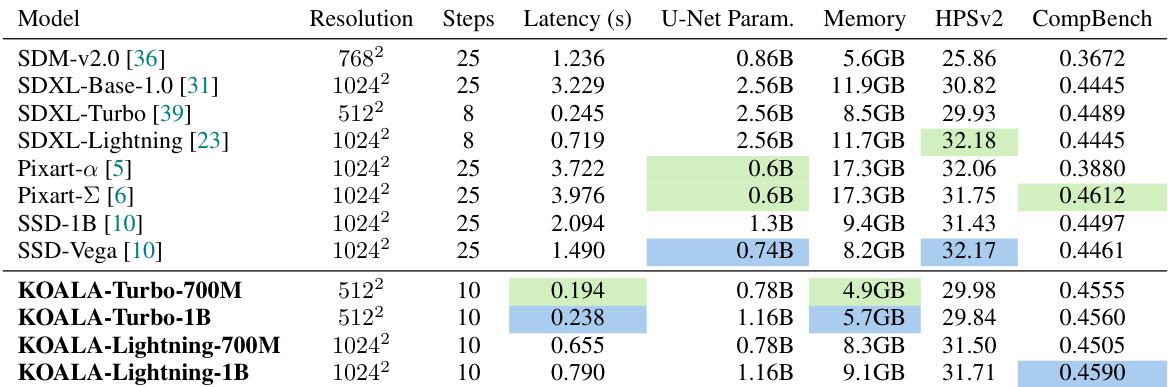
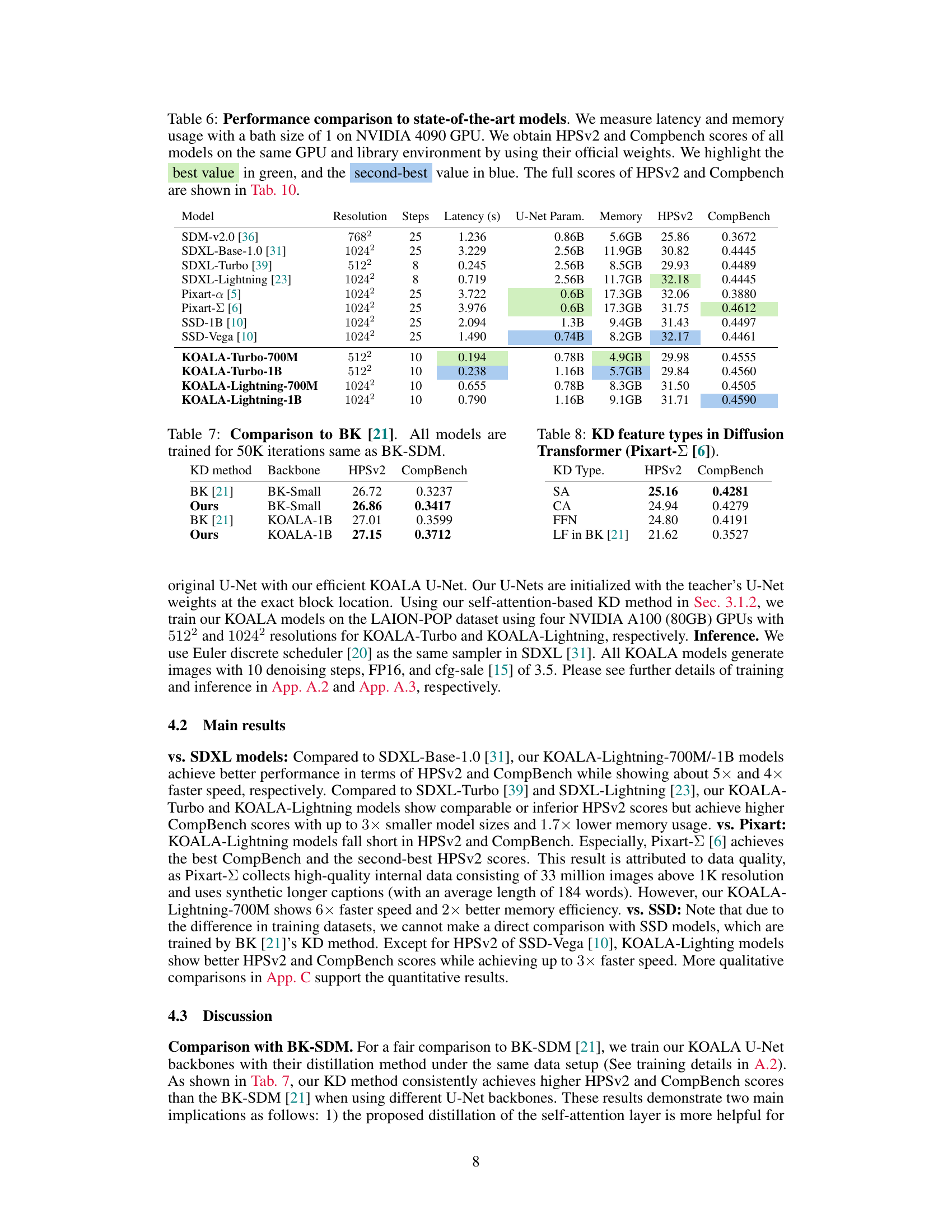
This table presents a quantitative comparison of the KOALA models with other state-of-the-art text-to-image synthesis models. The comparison includes model size (U-Net parameters), memory usage, inference latency (on an NVIDIA 4090 GPU), and two evaluation metrics (HPSv2 and CompBench). The best and second-best results for each metric are highlighted.
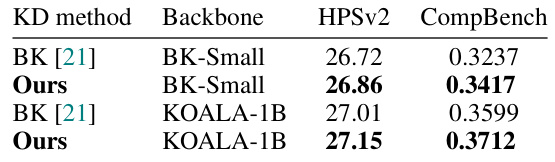
This table compares the performance of the proposed KOALA models with the BK-SDM model [21] which is a baseline for architectural model compression using knowledge distillation. Both models are trained for 50,000 iterations on the same dataset and backbone to ensure a fair comparison. The results illustrate the effectiveness of the proposed knowledge distillation method by comparing the HPSv2 and CompBench scores achieved by both KOALA-1B and BK-Small models.

This table presents a comparison of knowledge distillation (KD) feature types used in the Pixart-Σ model for text-to-image synthesis. It shows the HPSv2 and CompBench scores achieved by using self-attention (SA), cross-attention (CA), feed-forward network (FFN) features, and the last feature (LF) used by BK [21] for distillation. The results highlight the superior performance of using self-attention features for knowledge distillation compared to other methods.

This table presents the results of experiments that combined the step-distillation method (PCM) with the KOALA backbones. It shows the synergy effect, comparing the performance of models trained using PCM with SDXL-Base as the backbone against those trained using PCM with the lighter KOALA-700M and KOALA-1B backbones. The metrics evaluated include the number of steps, model parameters, memory usage, latency, Human Preference Score (HPS), and Compbench.
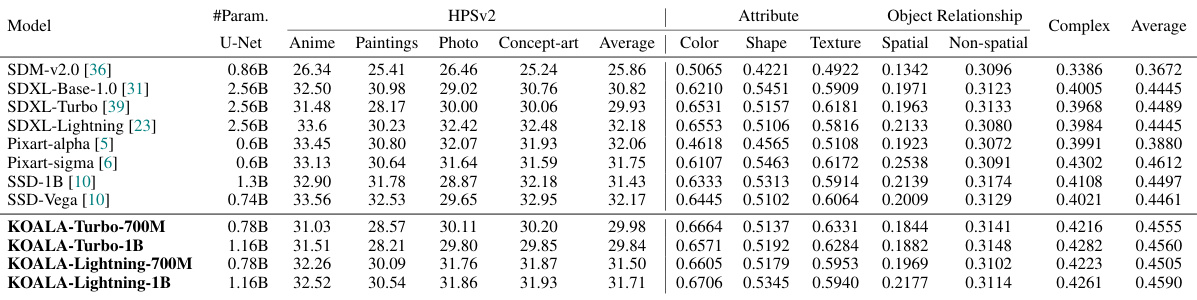
This table compares the performance of the KOALA models (KOALA-Turbo-700M, KOALA-Turbo-1B, KOALA-Lightning-700M, KOALA-Lightning-1B) against several state-of-the-art text-to-image synthesis models (SDM-v2.0, SDXL-Base-1.0, SDXL-Turbo, SDXL-Lightning, Pixart-a, Pixart-Σ, SSD-1B, SSD-Vega). The comparison is based on latency, memory usage, HPSv2 (Human Preference Score), and Compbench scores. Latency and memory usage were measured using a batch size of 1 on an NVIDIA 4090 GPU. The best and second-best scores for HPSv2 and Compbench are highlighted in green and blue, respectively. Complete HPSv2 and Compbench scores are available in Table 10.

This table presents an analysis of different feature-level knowledge distillation strategies applied to the U-Net of the Stable Diffusion XL model. It explores which types of features (self-attention, cross-attention, feed-forward network, residual block, last feature) and at which stages (down-sampling, middle, up-sampling) are most effective for knowledge distillation. The results are evaluated using the Human Preference Score (HPSv2).
Full paper#