↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large vision-language models (LVLMs) are prone to object hallucination, generating objects not present in images. This is particularly problematic when multiple objects are involved. Current benchmarks focus on single-object classes, failing to fully capture the complexity of multi-object scenarios.
This paper introduces a new automated evaluation protocol, Recognition-based Object Probing Evaluation (ROPE), specifically designed for assessing multi-object hallucination. ROPE considers object class distribution within images and uses visual prompts to reduce ambiguity. The study reveals that LVLMs hallucinate more frequently when dealing with multiple objects and that hallucination behavior is influenced by object class distribution, model-intrinsic behaviors, and data-specific factors. The findings offer valuable insights for developing more reliable and accurate LVLMs capable of handling complex real-world visual scenes.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large vision-language models (LVLMs). It addresses the prevalent issue of object hallucination, particularly in multi-object scenarios, offering a novel evaluation protocol and insightful analysis of contributing factors. These findings are vital for improving the reliability and accuracy of LVLMs in real-world applications. The work also suggests promising avenues for future research, including exploring data biases and mitigating LVLMs’ tendency to take shortcuts.
Visual Insights#

This figure shows an example from the Recognition-based Object Probing Evaluation (ROPE) dataset. It illustrates a heterogeneous sample, meaning the five objects to be identified all belong to different classes (apple, knife, fork, apple, jar). The image shows a table with various food items and kitchen utensils. Red bounding boxes highlight the objects. The caption indicates that this example uses the Default multi-object query setting within the ROPE evaluation protocol and labels each identified object as either correctly identified or incorrectly hallucinated by the model.

This table provides a comparison of different object hallucination benchmarks. It highlights key differences in their design, including whether they consider multiple objects, the distribution of object classes, the image source (seen during training or unseen), the type of visual referencing used (textual descriptions or visual cues), the evaluation method (neural models, humans, or automated pipelines), and the number of test images. This allows for a better understanding of the strengths and weaknesses of each benchmark in evaluating object hallucination.
In-depth insights#
Multi-Object Hallucination#
Multi-object hallucination in vision-language models (LVLMs) presents a significant challenge, going beyond the single-object scenario. LVLMs often fabricate or misinterpret multiple objects within a single image, exhibiting behaviors like inventing nonexistent objects or getting distracted from relevant ones. This is a crucial area of research because real-world scenes rarely contain just one object; accurately interpreting multiple objects simultaneously is vital for practical applications. The issue is further compounded by the fact that object class distribution within the image significantly influences hallucination rates, suggesting that LVLMs might exploit spurious correlations and shortcuts instead of robust reasoning. Addressing this requires not only improving model architectures but also carefully curating training data to avoid skewed distributions and encourage robust, holistic scene understanding. A key challenge is in developing better evaluation metrics which can effectively assess and quantify multi-object hallucinations, going beyond simple object presence/absence checks.
ROPE Benchmark#
The ROPE benchmark is a novel automated evaluation protocol designed to rigorously assess multi-object hallucination in large vision-language models (LVLMs). Its key innovation lies in employing visual referring prompts to eliminate ambiguity in object identification, unlike prior benchmarks focusing on single object classes. ROPE’s focus on simultaneous multi-object recognition helps uncover subtle model failures missed by simpler evaluation schemes. By considering the distribution of object classes within each image, ROPE provides a more nuanced understanding of LVLMs’ hallucination behaviors in realistic scenarios. The four subsets of ROPE (In-the-Wild, Homogeneous, Heterogeneous, and Adversarial) allow for comprehensive analysis, revealing how object class distribution affects hallucination rates. The benchmark’s design encourages the development of LVLMs that excel not only in individual object recognition but also in complex multi-object reasoning tasks, paving the way for more robust and reliable LVLMs in real-world applications.
Hallucination Factors#
Analyzing hallucination factors in large vision-language models (LVLMs) reveals a complex interplay of data-driven and model-intrinsic elements. Data-specific factors, such as the distribution of object classes within an image (homogeneous vs. heterogeneous), significantly influence hallucination rates. Models exhibit biases towards frequent or salient objects in training data, potentially due to spurious correlations learned during training. Model-intrinsic factors also play a crucial role, with models demonstrating higher hallucination rates when dealing with uncertainty, as reflected by increased token entropy and lower visual modality contribution in their attention mechanisms. Investigating these factors is crucial for improving the robustness and reliability of LVLMs, especially in handling multi-object scenes. Addressing these challenges requires a multifaceted approach, potentially involving data augmentation, improved training strategies, and architectural innovations to enhance attention mechanisms and reduce model reliance on shortcut learning.
Future Directions#
Future research should explore more nuanced methods for evaluating multi-object hallucination, moving beyond simple accuracy metrics to assess the quality and coherence of generated descriptions. Addressing the issue of spurious correlations learned by models necessitates further investigation into how models weigh visual information versus contextual cues, potentially using techniques like attention analysis to identify biases. Improving data annotation and diversity is critical; datasets should include more complex scenes and balanced object distributions to better reflect real-world environments. A focus on prompt engineering techniques that can guide models toward more accurate multi-object reasoning is also necessary. Finally, exploring the use of techniques such as iterative refinement or reinforcement learning, to mitigate hallucination in a controlled manner is a significant future direction. The development of new benchmarks that specifically target the challenges of multi-object scenes, providing detailed metrics beyond simple object presence or absence, is crucial for tracking progress in this area.
Method Limitations#
The method’s limitations center on three key aspects. Firstly, the reliance on a fixed set of object classes for evaluation introduces a potential bias, potentially overlooking hallucinations involving classes not included in the predefined set. Secondly, the evaluation protocol’s inherent reliance on visual cues, while effective in mitigating ambiguity, might not fully capture the nuances of real-world object recognition, especially in cases of highly ambiguous or occluded objects. Thirdly, the computational cost, which involves multiple inferences per image for different query settings, significantly limits the scalability of the evaluation process. Addressing these limitations would require exploring more open-ended evaluation methods, incorporating context and uncertainty into the evaluation framework, and developing more efficient querying and inference strategies.
More visual insights#
More on figures

This figure demonstrates the limitations of existing benchmarks for evaluating object hallucination, particularly in scenarios involving multiple objects. It shows how the GPT-4V model can correctly identify individual objects when queried separately but hallucinates an object when asked to identify multiple objects simultaneously. The Recognition-based Object Probing Evaluation (ROPE) benchmark introduced in the paper addresses these limitations by using visual prompts and a controlled output format to eliminate ambiguity.
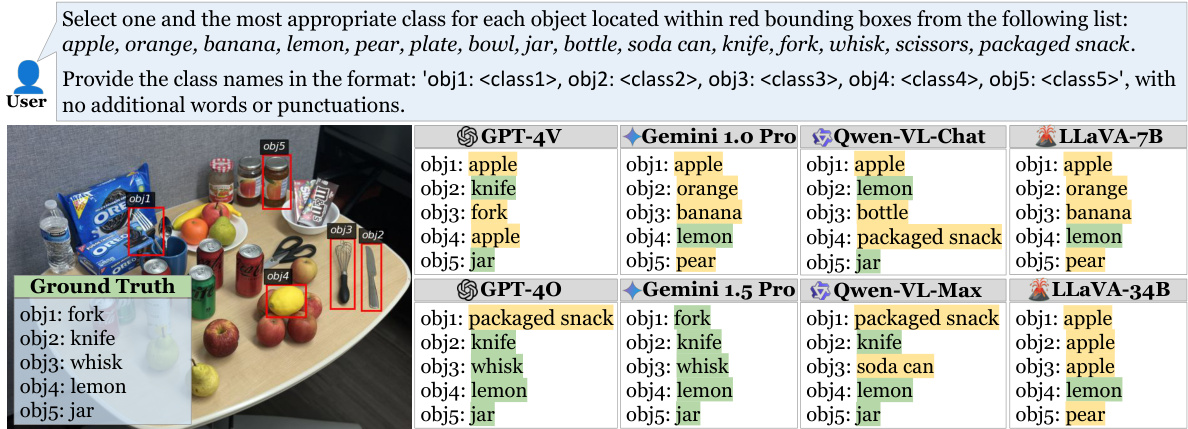
This figure shows a sample from the Recognition-based Object Probing Evaluation (ROPE) dataset used to evaluate multi-object hallucination in vision-language models. The image contains five objects belonging to different classes (fork, knife, whisk, lemon, jar). The figure demonstrates the outputs of several vision-language models (GPT-4V, Gemini 1.0 Pro, Qwen-VL-Chat, LLaVA-7B, GPT-4O, Gemini 1.5 Pro, Qwen-VL-Max, LLaVA-34B) when asked to identify the class of each object. The ground truth is provided for comparison, highlighting which model predictions are correct and which are hallucinatory (incorrect). This helps in analyzing the performance of various models and identifying the types of errors they tend to make when dealing with multiple objects in a single image.

This figure shows an example from the Recognition-based Object Probing Evaluation (ROPE) dataset. The image contains five objects belonging to different classes (fork, knife, whisk, lemon, jar). The figure compares the ground truth object classes with the classes predicted by various vision-language models (LLaVA-7B, Gemini 1.0 Pro, Qwen-VL-Chat, GPT-4V, Gemini 1.5 Pro, Qwen-VL-Max, LLaVA-34B). The purpose is to illustrate how different models perform in identifying multiple objects simultaneously and showcases the occurrence of hallucination, where the model predicts an object class that is not actually present in the image.

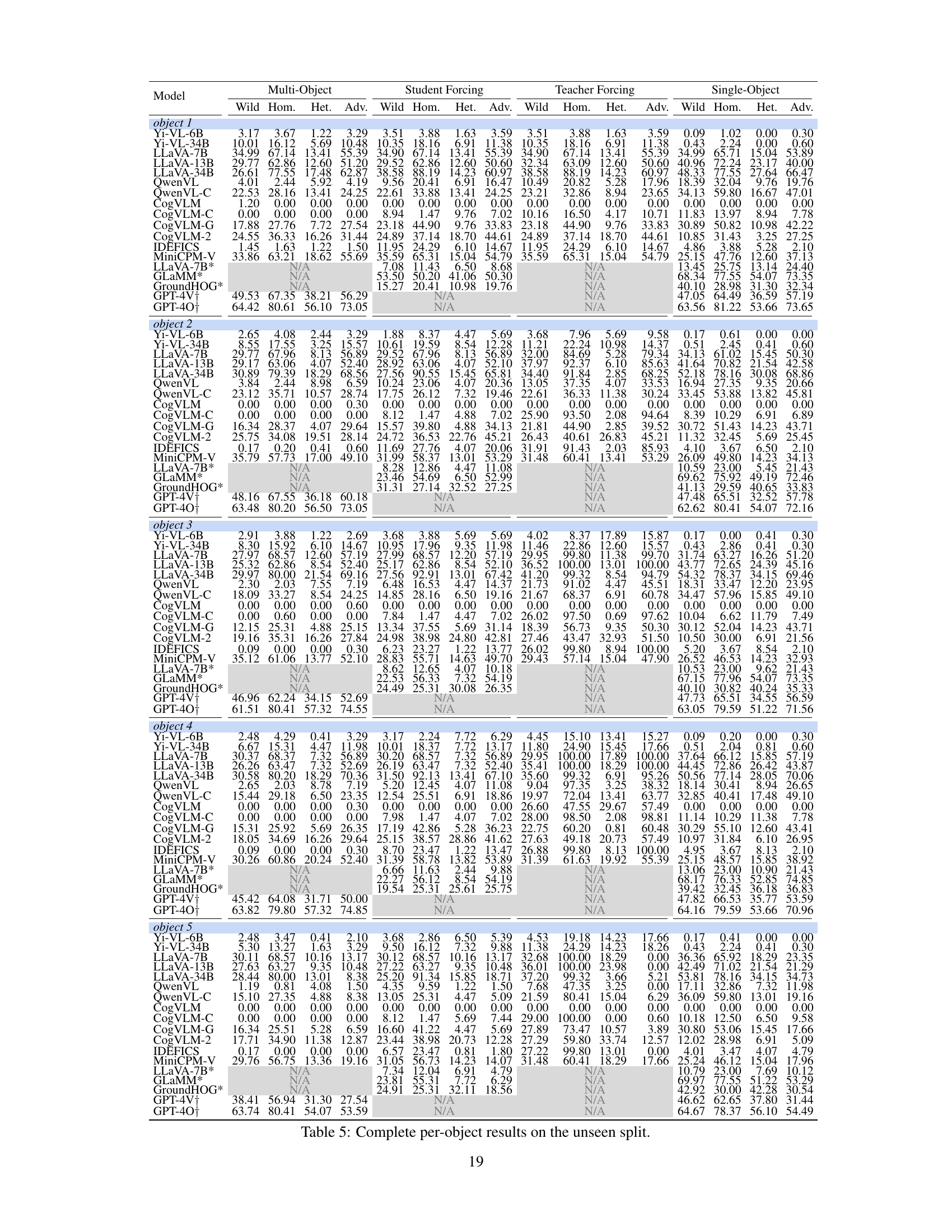
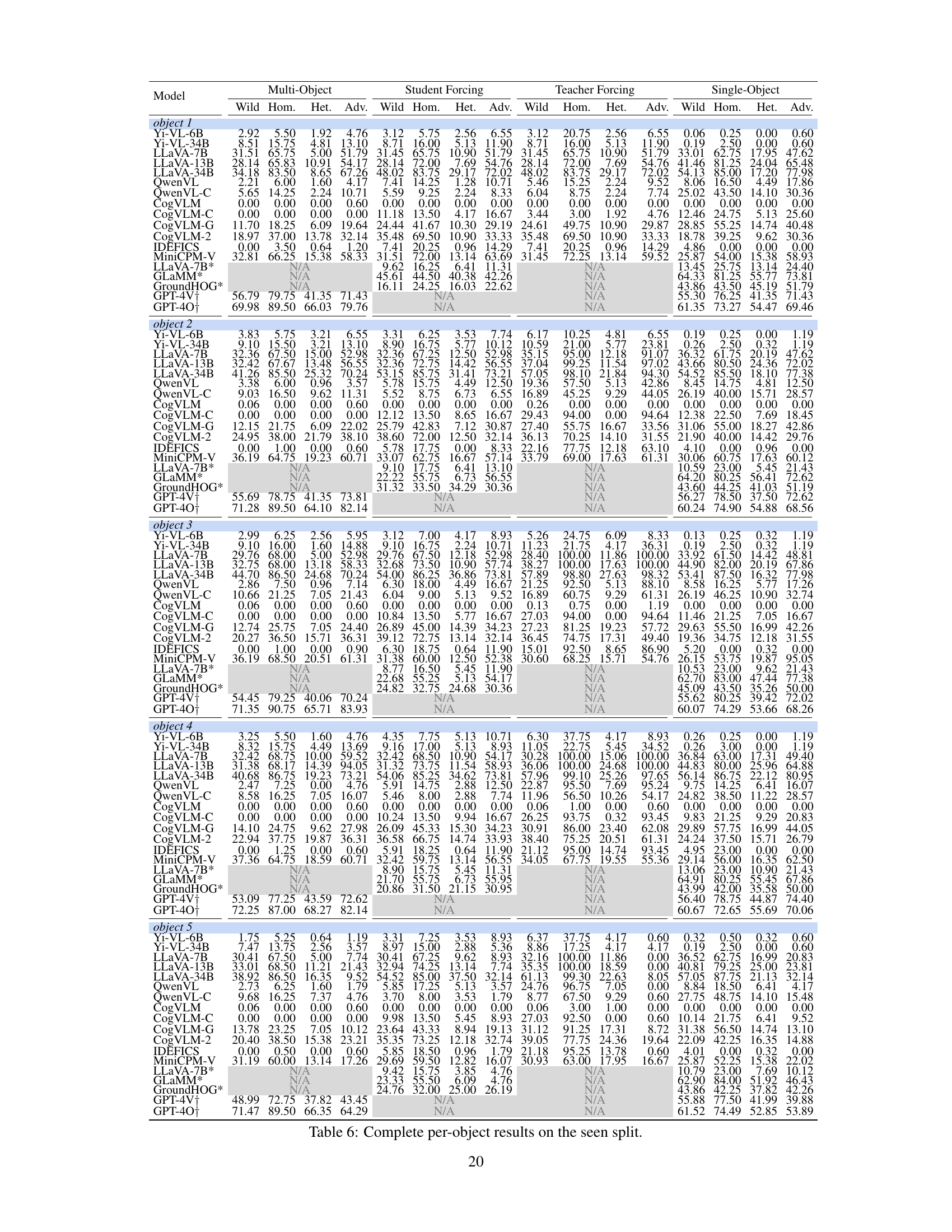
This figure shows the performance of three different sizes of LLaVA models (7B, 13B, and 34B) on an adversarial subset of the Recognition-based Object Probing Evaluation (ROPE) dataset. The adversarial subset contains image-object sets where four of the five objects belong to the same class, and the last object belongs to a different class (AAAAB). The figure compares the performance of single-object probing (SO) and teacher-forcing probing (TF) for each object position. It reveals a significant drop in accuracy when using the AAAAB query sequence, especially for the fifth object (object B), highlighting the model’s vulnerability to this type of adversarial scenario.
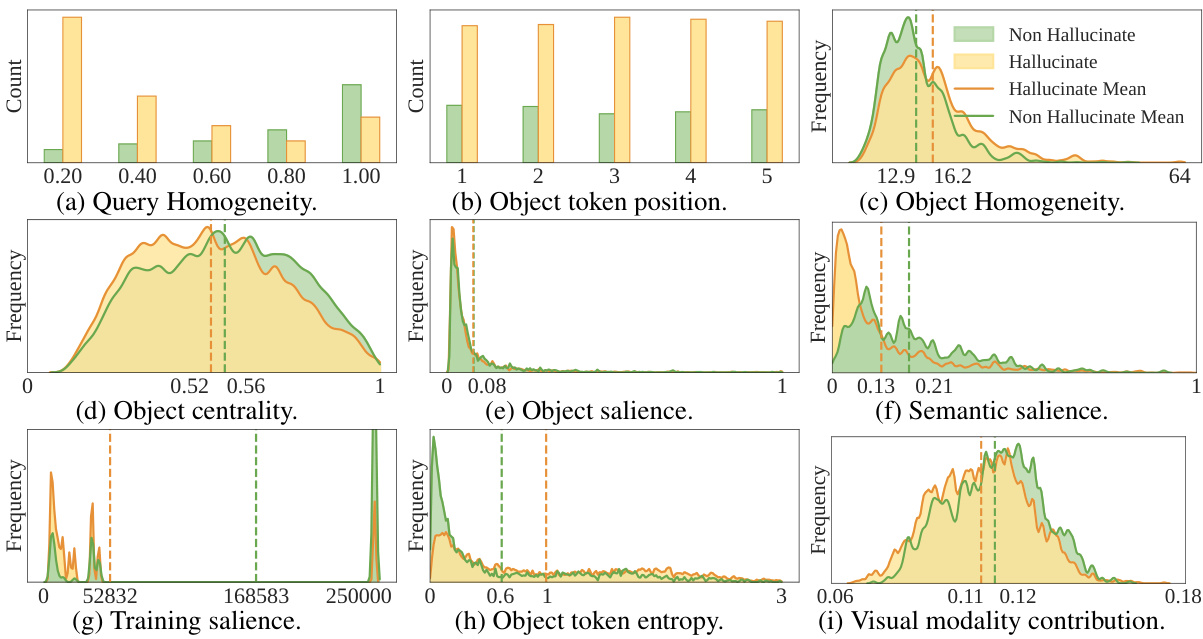
This figure displays the distribution of several factors for both hallucinatory and non-hallucinatory object classes within the LLaVA-13B model. The data used is from the unseen split of the dataset and uses the student forcing method. The factors analyzed include query homogeneity, object token position, object homogeneity, object centrality, object salience, semantic salience, training salience, object token entropy, and visual modality contribution. The distributions are visualized using bar charts and ridgeline plots to illustrate the differences between the two classes of objects.

This figure compares the distribution of actual versus predicted object classes for all hallucinatory objects in the LLaVA-13B model, specifically focusing on the unseen split and using the student-forcing setting. It visually represents the frequency of actual and predicted object classes across three key data-specific factors: semantic salience, training salience, and input order. The plots show how often the model hallucinates certain classes based on these factors, providing insights into the model’s behavior and potential biases.

This figure illustrates the different prompting strategies used in the Recognition-based Object Probing Evaluation (ROPE) benchmark. It contrasts single-object probing (a) with multi-object probing (b), showing how the task of identifying multiple objects simultaneously changes the model’s behavior. It also demonstrates the ‘student forcing’ (c) and ’teacher forcing’ (d) methods which help isolate and analyze various sources of error in the model’s responses.

This figure shows an example of a heterogeneous Recognition-based Object Probing Evaluation (ROPE) sample. The image contains five objects, each belonging to a different class (fork, knife, whisk, lemon, jar). The figure displays the ground truth class labels for each object and illustrates how different vision language models (VLMs) responded to the query of identifying all five objects simultaneously. By examining the model’s responses, we can assess the presence of hallucinations, where a model incorrectly identifies an object’s class or hallucinates a class that isn’t present in the image.

This figure shows a comparison of single-object and multi-object hallucination results using various vision-language models (VLMs) on the nuScenes dataset. The task was to identify the class of objects within bounding boxes in an image. The ‘Single-object’ scenario presented each object individually for classification, while the ‘Multi-object’ scenario presented multiple objects simultaneously. The figure highlights how VLMs perform differently when handling multiple objects compared to single objects, demonstrating the challenge of multi-object hallucination.

This figure shows a comparison of single-object and multi-object hallucination using the nuScenes dataset. Five objects are identified within bounding boxes. The results from different LLMs (GPT-40, Claude 3.5, LLaVA-13B, GPT-4V, Qwen 2.5, LLaVAPhi3Mini) are displayed, highlighting the variations in accuracy and instances of hallucination when identifying multiple objects compared to single objects.
More on tables
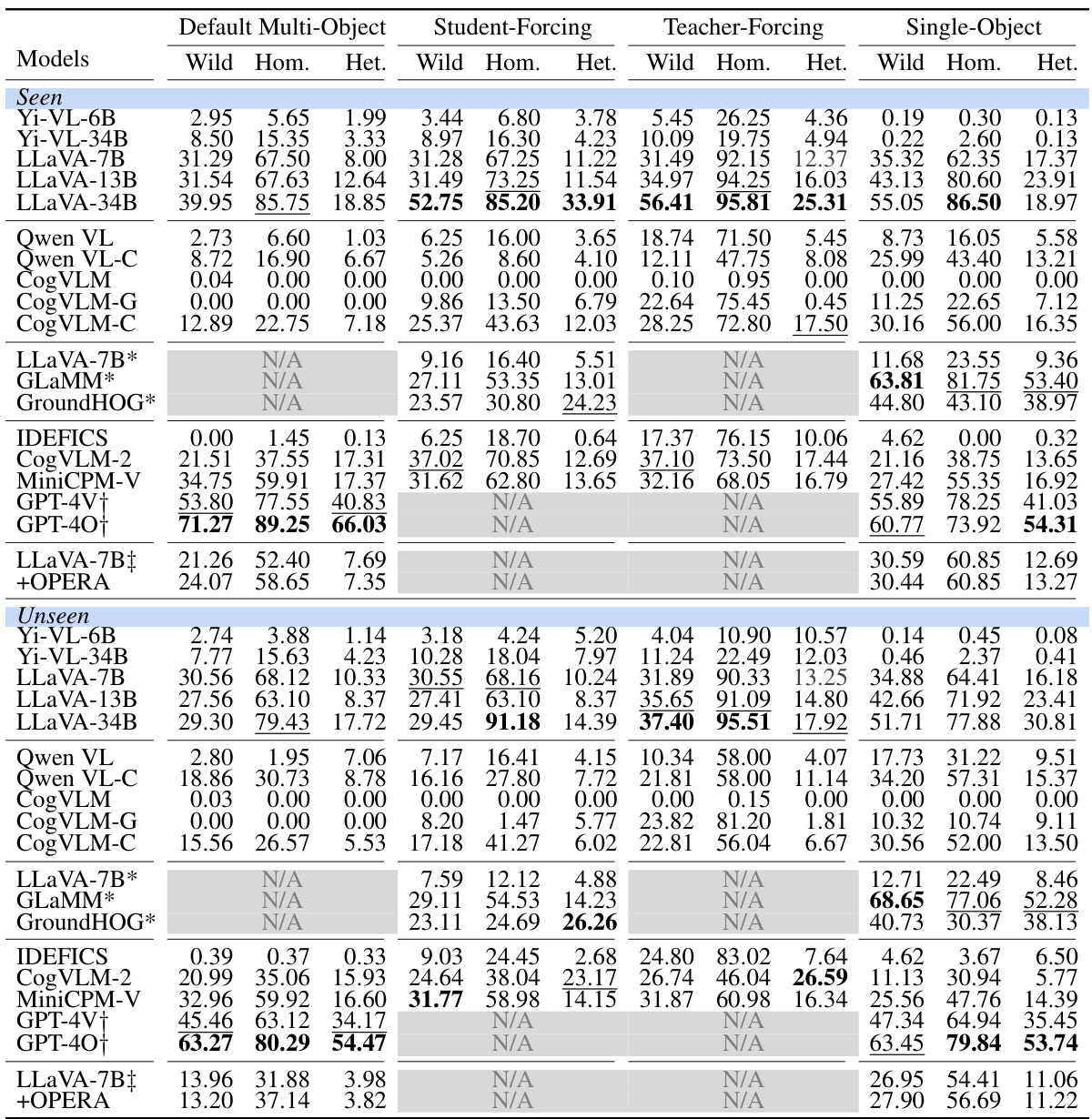
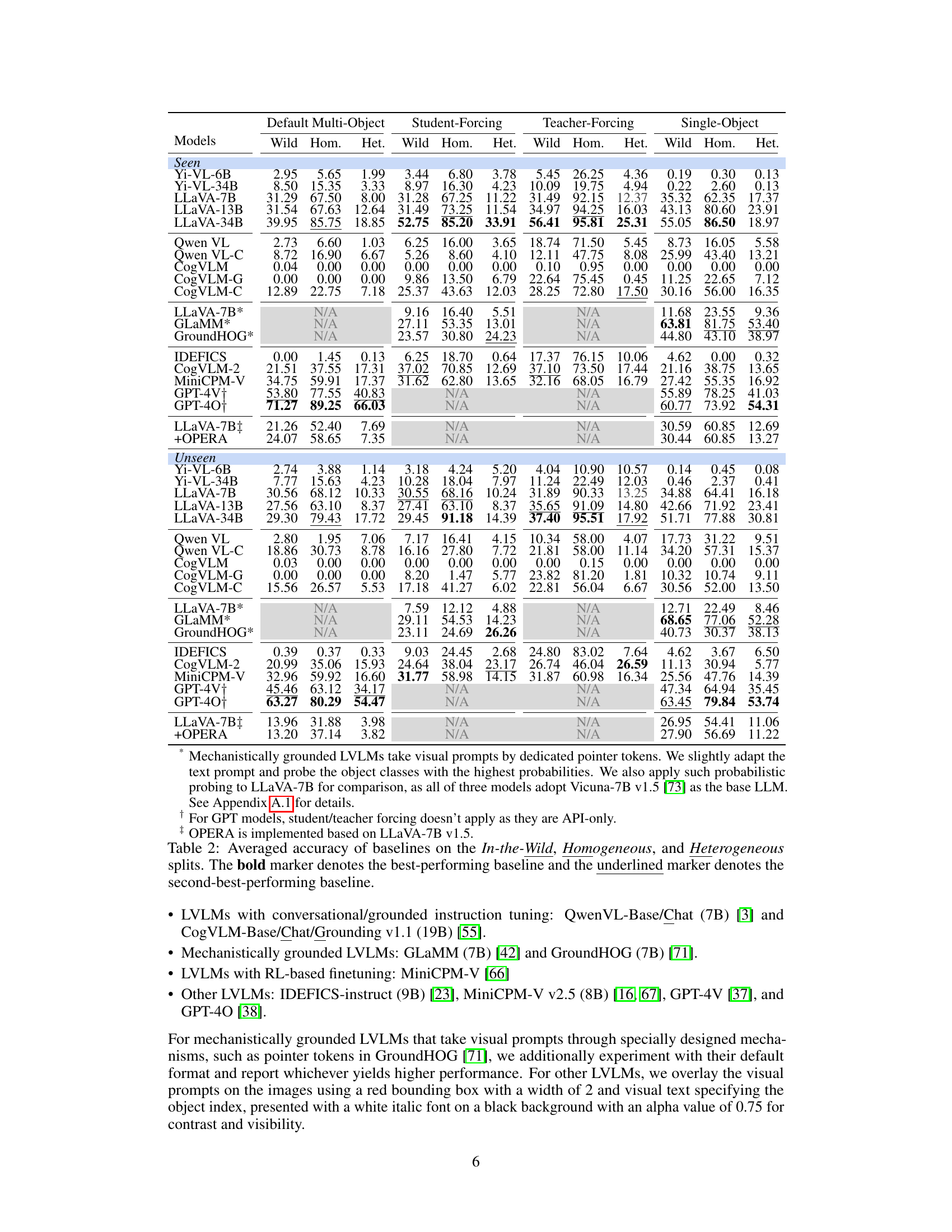
This table presents the averaged accuracy results for various vision-language models (LVLMs) across three different object class distribution settings: In-the-Wild, Homogeneous, and Heterogeneous. The accuracy is calculated using three different querying methods: Default Multi-Object, Student-Forcing, and Teacher-Forcing. For comparison, the table also includes results for Single-Object querying. The best and second-best performing models for each condition are highlighted.
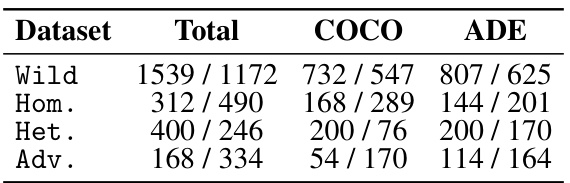
This table compares different object hallucination benchmarks in terms of their design considerations and evaluation methods. It shows the number of test images used, whether multiple object classes or varied distributions were considered (in training and testing), the source of images, and the type of evaluation process employed (textual descriptions, visual cues, neural models, humans, or automated pipelines). This information helps contextualize the authors’ new benchmark (ROPE) and its improvements over existing methods.

This table compares different object hallucination benchmarks. It shows the number of test images, whether multiple classes and varying class distributions were considered, the source of images (seen or unseen in training), how objects were referred to (text or visual cues), and what evaluation methods were used (neural models, humans, or automatic systems).

This table presents the average accuracy results of various vision-language models (LVLMs) across different test sets. The test sets vary in the distribution of object classes within each image: In-the-Wild (mixed distribution), Homogeneous (all objects belong to the same class), and Heterogeneous (objects belong to different classes). The table shows results for three different prompting strategies: Default, Student-Forcing, and Teacher-Forcing. The best and second-best performing models for each condition are highlighted.
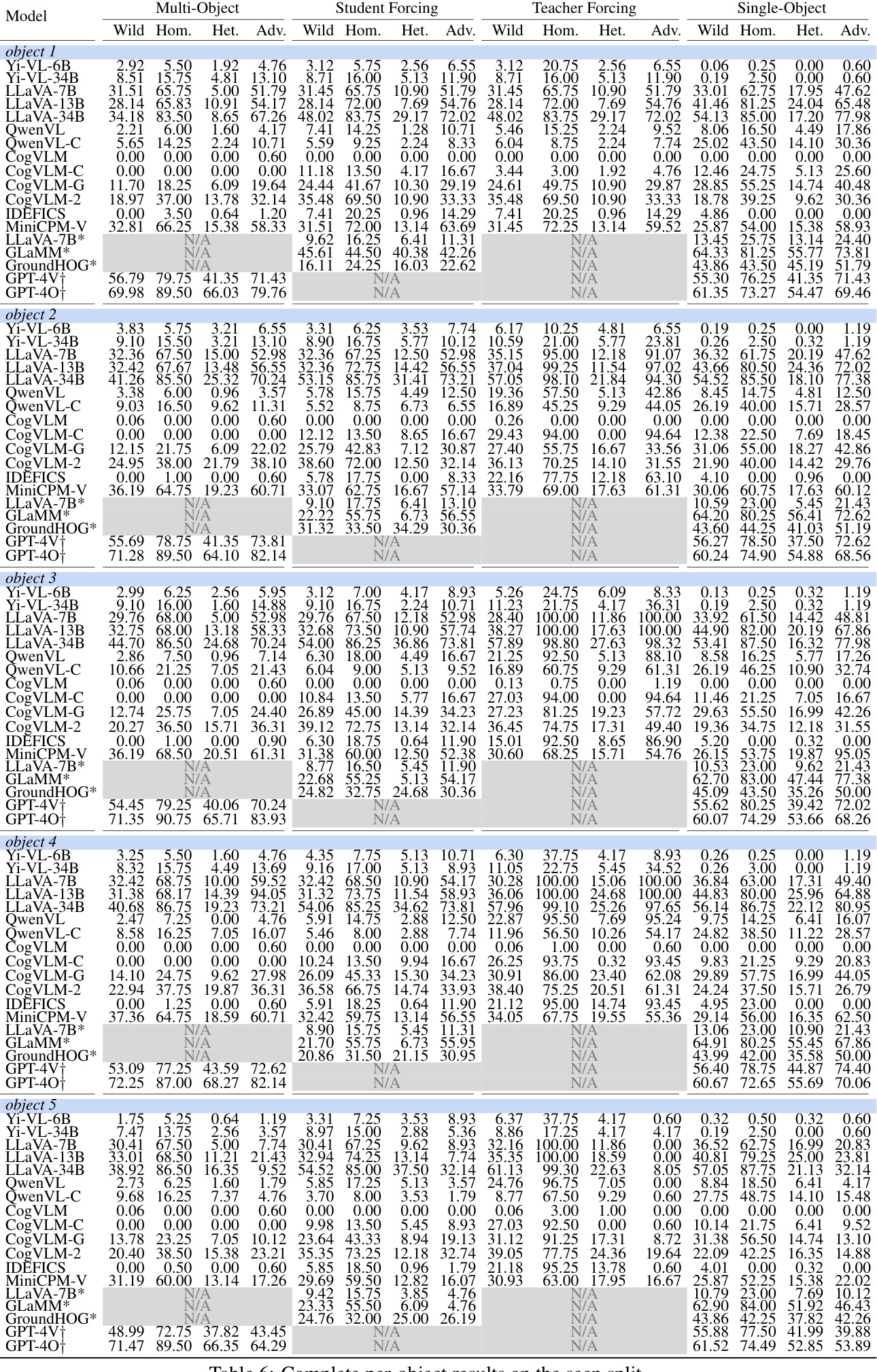
This table presents the average accuracy results for various vision-language models (LVLMs) across three different data splits: In-the-Wild, Homogeneous, and Heterogeneous. The accuracy is evaluated using three different probing methods: Default Multi-Object, Student-Forcing, and Teacher-Forcing. The table allows comparison of model performance under varying conditions of object complexity and instructional methods.
Full paper#