↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) often struggle with complex reasoning tasks. Chain of Thought (CoT) prompting, a technique that provides intermediate reasoning steps in prompts, has shown promise in improving LLM performance on some tasks, but its effectiveness is still debated. This paper investigates the limits of CoT in solving classical planning problems, using a well-defined domain called Blocksworld and several scalable synthetic tasks to thoroughly evaluate its performance.
The researchers found that CoT only significantly enhances LLM performance when the provided examples and the problem being solved are exceptionally similar. This limited generalizability suggests that LLMs do not learn general algorithmic procedures through CoT. Instead, they appear to rely on pattern matching, raising concerns about the scalability and practical applicability of this prompting technique. The study also extends these findings to other benchmark problems, reinforcing the observed limitations of CoT.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the prevailing assumptions about the effectiveness of Chain of Thought prompting in LLMs. By revealing its limitations, it encourages more rigorous evaluation methods and opens up new avenues for enhancing LLM reasoning abilities. This is vital for the responsible development and application of LLMs in various fields.
Visual Insights#

This figure illustrates the hierarchy of problem sets used in the paper’s experiments. It starts with the broadest category, ‘All PDDL Problems’, encompassing various planning domains. Within this, ‘All Blocksworld Problems’ is a subset focusing on the Blocksworld domain. Further subdivisions include ‘Table to Stack Problems’ (where all blocks begin on a table and the goal is a single stack), and the most specific subset, ‘Table to Lexicographic Stack Problems’ (a subset of Table to Stack Problems where the goal stack is in lexicographical order). This visual helps understand how the different prompt engineering techniques were tested on varying levels of problem complexity and generality, reflecting the intended target distribution of each approach.
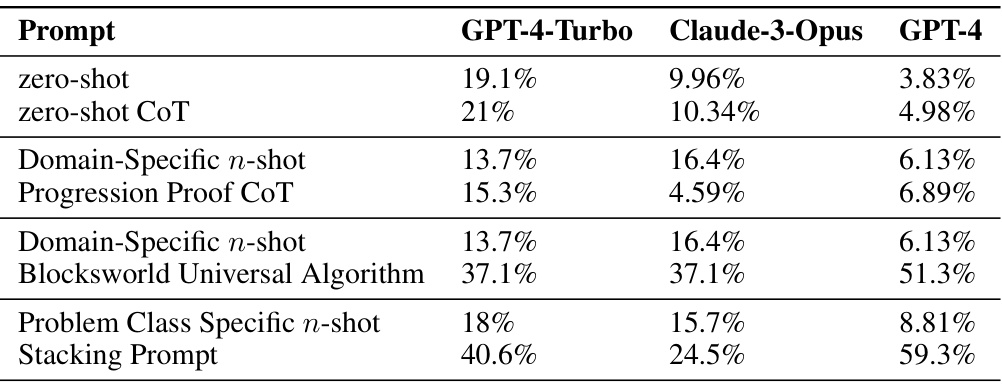
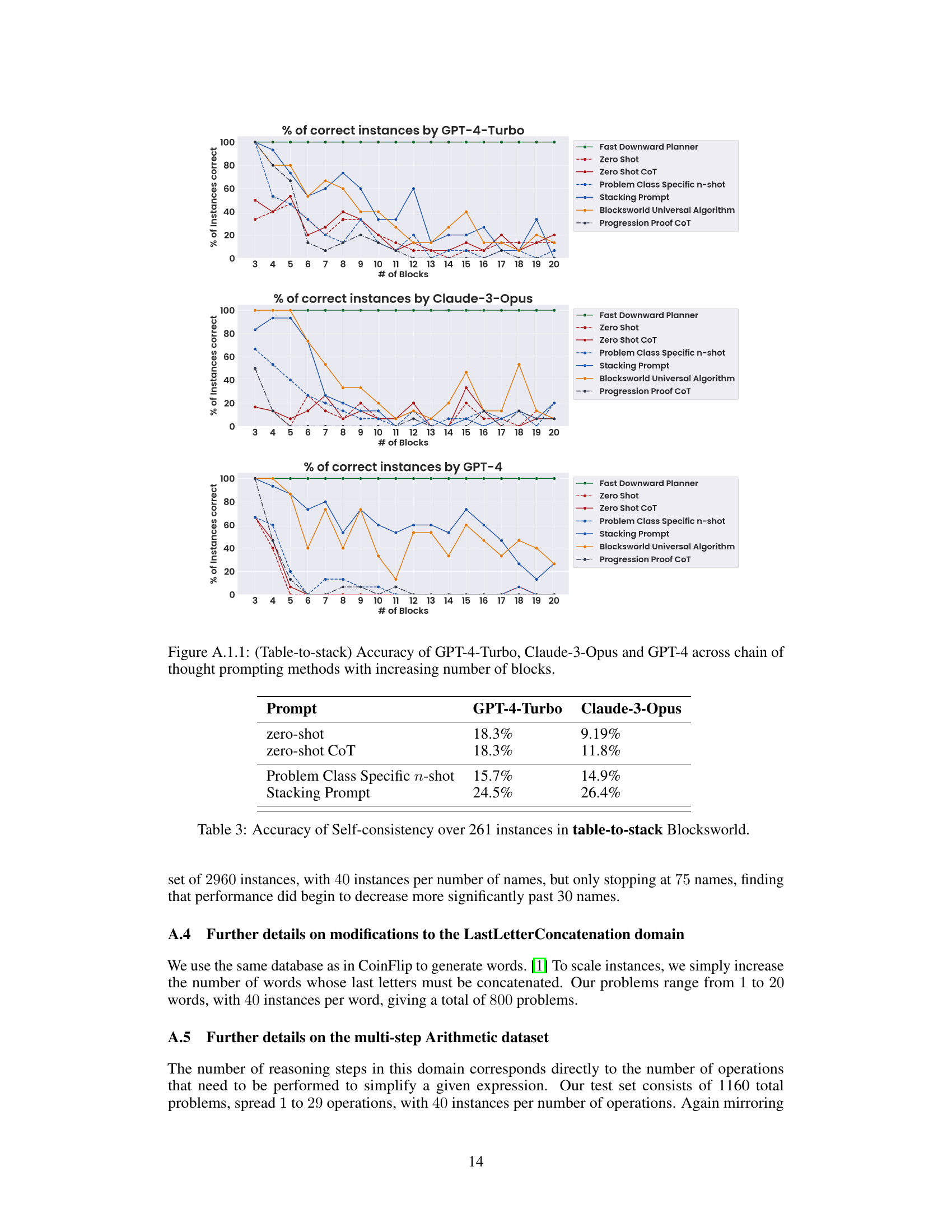
This table presents the accuracy results of different prompting methods on a specific subset of Blocksworld problems, namely, the table-to-stack problems. It compares the performance of zero-shot prompting, zero-shot chain of thought (CoT), different levels of example specificity (n-shot) and varying levels of CoT granularity. The goal is to assess how well the LLMs generalize the provided reasoning strategies to solve increasingly complex problems within the same problem class.
In-depth insights#
CoT’s Limits#
The concept of Chain of Thought (CoT) prompting, while initially promising for enhancing large language model (LLM) reasoning capabilities, reveals significant limitations upon closer inspection. CoT’s effectiveness is heavily dependent on the careful engineering of highly problem-specific prompts, rather than enabling LLMs to learn generalizable algorithmic procedures. The results show that performance gains are highly sensitive to the similarity between the examples in the prompt and the problem being solved. As problem complexity increases, the improvements provided by CoT diminish rapidly, often falling below the performance of standard prompting. This sharp trade-off between potential performance gains and the significant human labor required to construct effective CoT prompts highlights a crucial drawback, suggesting that CoT’s success is less about genuine learning and more about sophisticated pattern matching within a limited context. Furthermore, this pattern holds even for seemingly simple problems, indicating that the reliance on tailored examples rather than generalizable knowledge transfer is a fundamental limitation of CoT prompting. Therefore, the perceived effectiveness of CoT is contingent upon a degree of engineering that limits its general applicability and practical utility for solving complex, out-of-distribution reasoning tasks.
Planning & LLMs#
The intersection of planning and large language models (LLMs) presents exciting possibilities and significant challenges. LLMs, with their capacity for complex pattern recognition and generation, offer a novel approach to automated planning, potentially bypassing the need for explicit programming of planning algorithms. However, the inherent limitations of LLMs, such as lack of true reasoning and generalization beyond training data, pose serious hurdles. Successfully applying LLMs to planning tasks often requires careful prompt engineering, a process that demands significant human intervention and may not generalize effectively across diverse problem instances. Current research highlights the trade-off between potential performance gains and the human effort required for prompt design. Therefore, while LLMs show promise for assisting in or augmenting planning systems, they are not yet a complete replacement for traditional, robust planning algorithms. Further research is crucial to address the limitations of LLMs in planning, focusing on improving their generalization capabilities, reducing reliance on exhaustive prompt engineering, and developing more reliable methods for evaluating their performance in complex and nuanced planning tasks. Ultimately, the success of LLMs in planning will depend on addressing their fundamental limitations and creating frameworks that leverage their strengths while mitigating their weaknesses.
Prompt Engineering#
Prompt engineering, in the context of large language models (LLMs), is the art and science of crafting effective prompts to elicit desired responses. It’s crucial because LLMs’ performance is highly sensitive to input phrasing. Well-designed prompts can unlock impressive capabilities, while poorly-designed ones lead to suboptimal or nonsensical outputs. Key aspects include understanding the model’s strengths and weaknesses, selecting appropriate prompt structures (e.g., few-shot learning, chain-of-thought), and iteratively refining prompts based on observed behavior. The field is rapidly evolving, with ongoing research exploring techniques for improving prompt efficiency and generalization. Challenges include the need for significant human expertise, the difficulty of creating universally effective prompts, and the potential for unintended biases to be amplified by prompt design. Ultimately, prompt engineering is a powerful tool for harnessing LLMs’ potential, but its effectiveness depends heavily on the skill and understanding of the prompt engineer.
Blocksworld Analysis#
A Blocksworld analysis within a research paper would likely involve evaluating the performance of AI planning algorithms in the well-known Blocksworld domain. This domain’s simplicity, involving blocks stacked on a table, makes it ideal for testing and visualizing planning processes. The analysis might compare different search algorithms, such as A*, greedy best-first search, or heuristic search methods, assessing their efficiency and ability to find optimal or near-optimal solutions in various problem instances. Scalability would be a crucial aspect, investigating how algorithm performance changes with an increasing number of blocks and varying goal complexities. The analysis should also examine the impact of different heuristics on search efficiency, comparing their strengths and weaknesses in different scenarios. Furthermore, a robust analysis would delve into the representation of the problem: how the initial state, goal state, and available actions are formally encoded can significantly affect algorithm performance. A good Blocksworld analysis would not only present quantitative results but also offer qualitative insights into the planning processes, perhaps using visualizations to illustrate search trees or execution traces, thereby improving our understanding of AI planning algorithms. Finally, a discussion of the limitations of the chosen approach and future research directions is essential.
Generalization Failure#
The phenomenon of “Generalization Failure” in large language models (LLMs) highlights a critical limitation: the inability of LLMs to apply learned knowledge to new, unseen situations that are structurally similar but not exactly the same as the training data. This failure is particularly pronounced in complex reasoning tasks, where slight variations in problem structure can dramatically impact model performance. A key reason for this failure is the reliance of LLMs on pattern matching rather than true algorithmic understanding. LLMs excel at identifying superficial similarities in input, enabling them to mimic correct reasoning demonstrated in examples. However, when presented with problems outside this narrow pattern, they often fail to generalize the underlying principles and thus produce incorrect solutions. This exposes a crucial weakness in current prompting techniques and showcases the substantial gap between mimicking and genuine comprehension. Addressing generalization failure demands more robust training methods that focus on the underlying principles of reasoning rather than mere pattern memorization. Developing techniques for assessing and enhancing the degree of LLM understanding rather than superficial pattern matching is essential for making progress in this area.
More visual insights#
More on figures
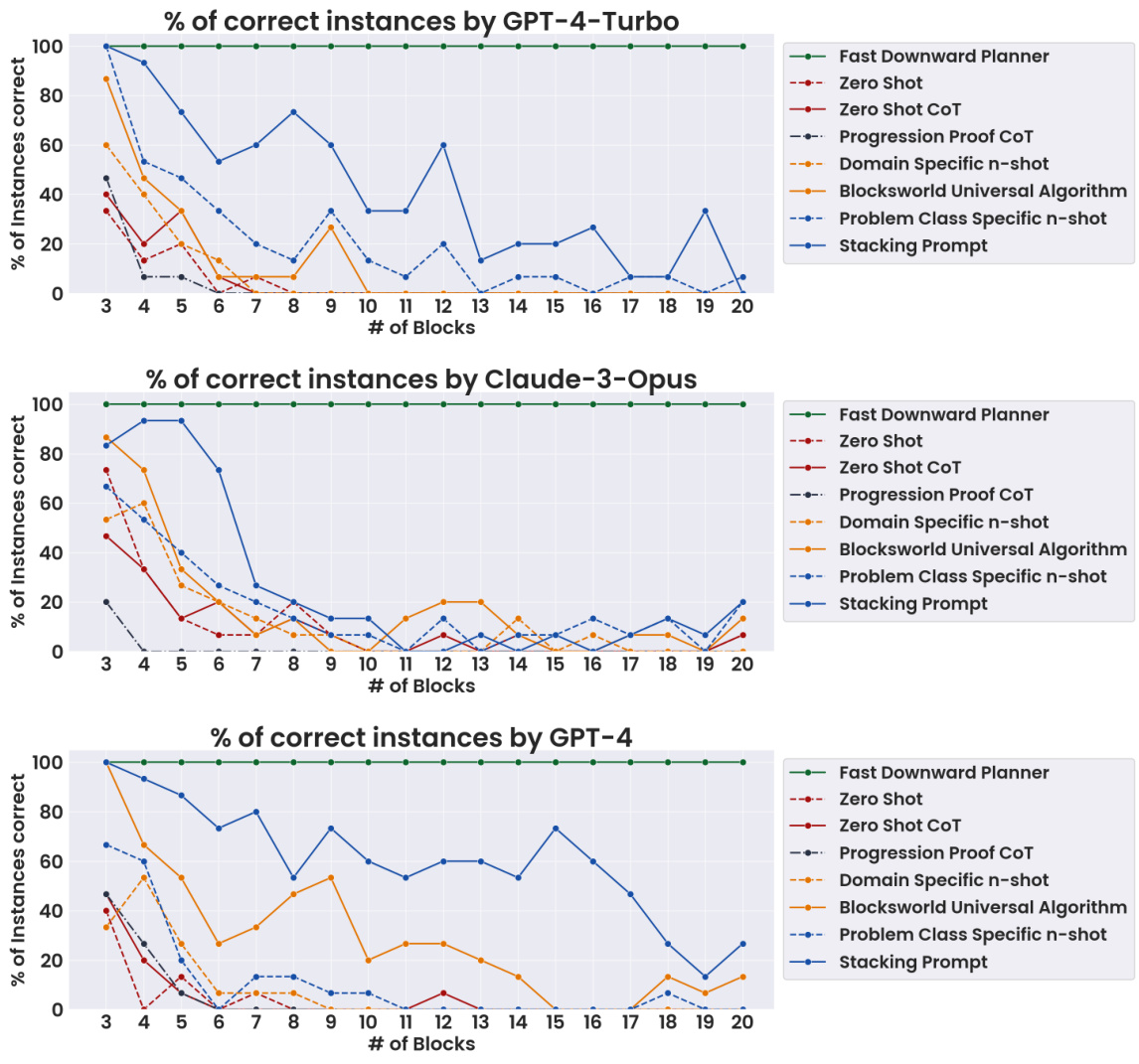
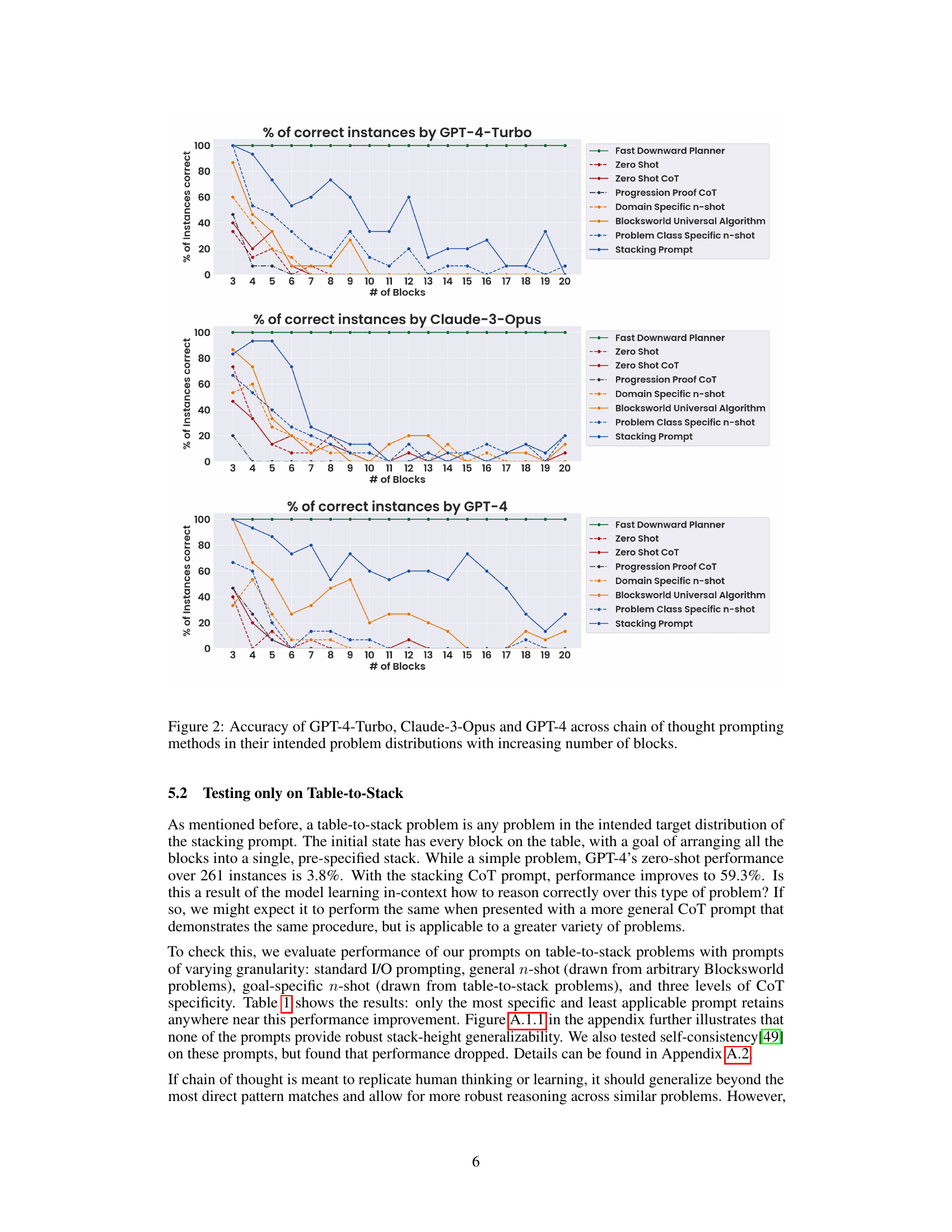
This figure presents the accuracy of three LLMs (GPT-4-Turbo, Claude-3-Opus, and GPT-4) across different prompting methods in solving Blocksworld planning problems. The x-axis represents the number of blocks in the problem, and the y-axis shows the percentage of problems solved correctly. Different lines represent various prompting techniques, including zero-shot, zero-shot chain of thought, progression proof chain of thought, and problem-specific chain of thought approaches. The figure demonstrates how the accuracy of different LLMs changes with increasing problem complexity and across various prompting strategies, highlighting the impact of prompt engineering on LLM performance in planning tasks. A baseline using a perfect planner (Fast Downward) is also included for comparison.

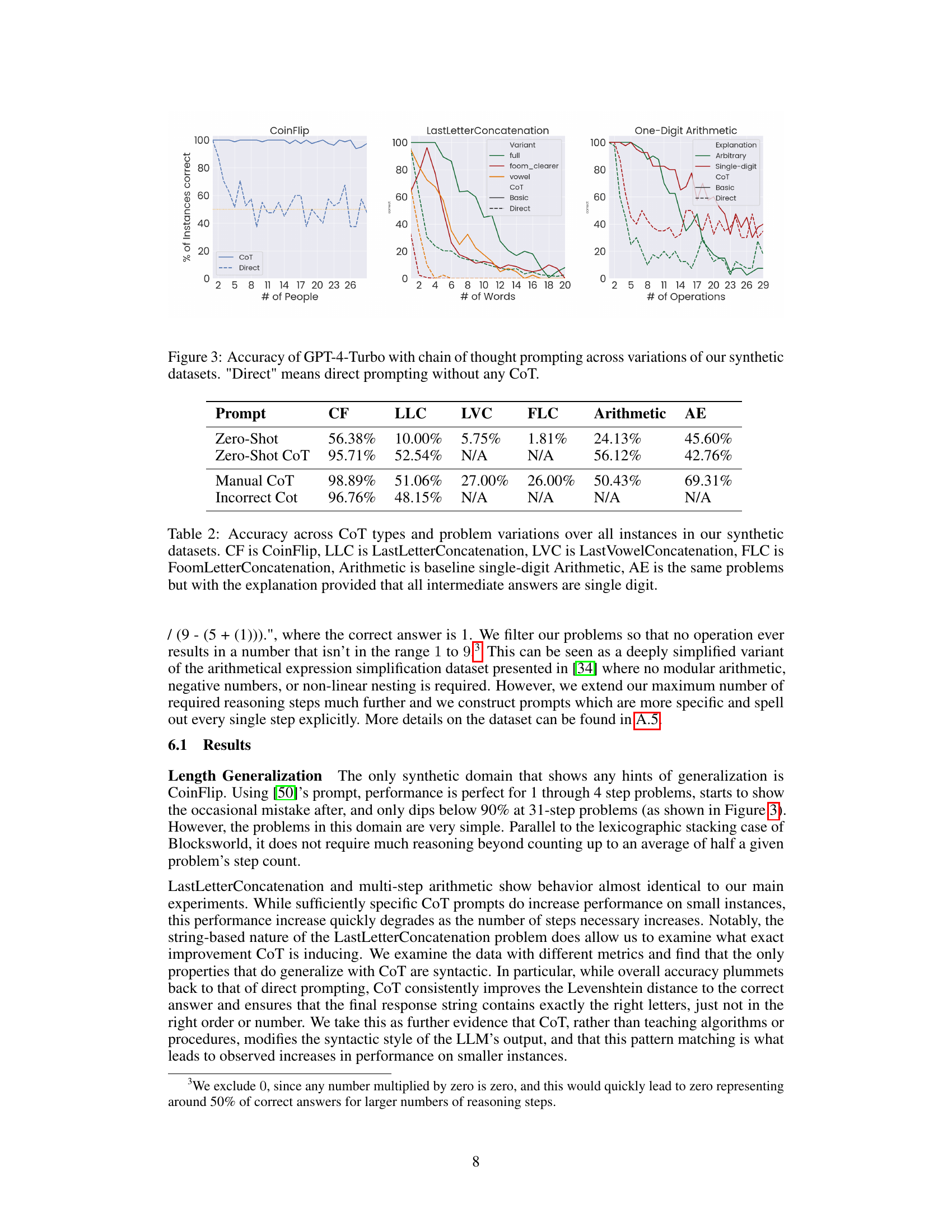
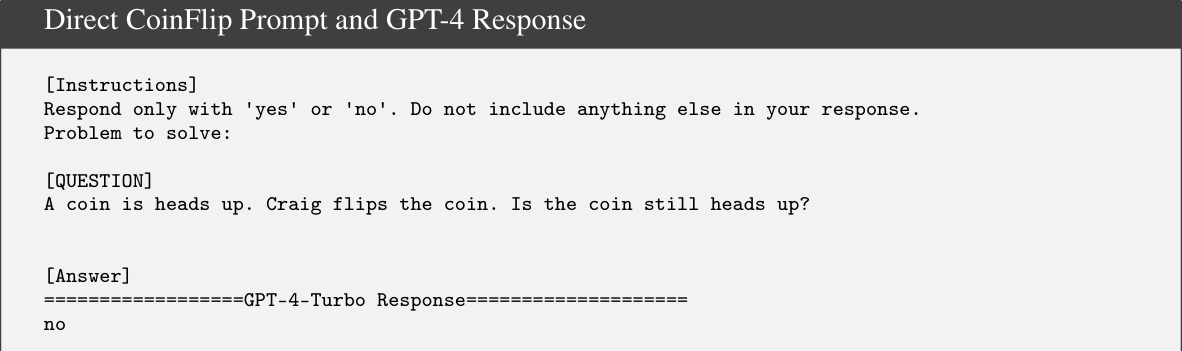
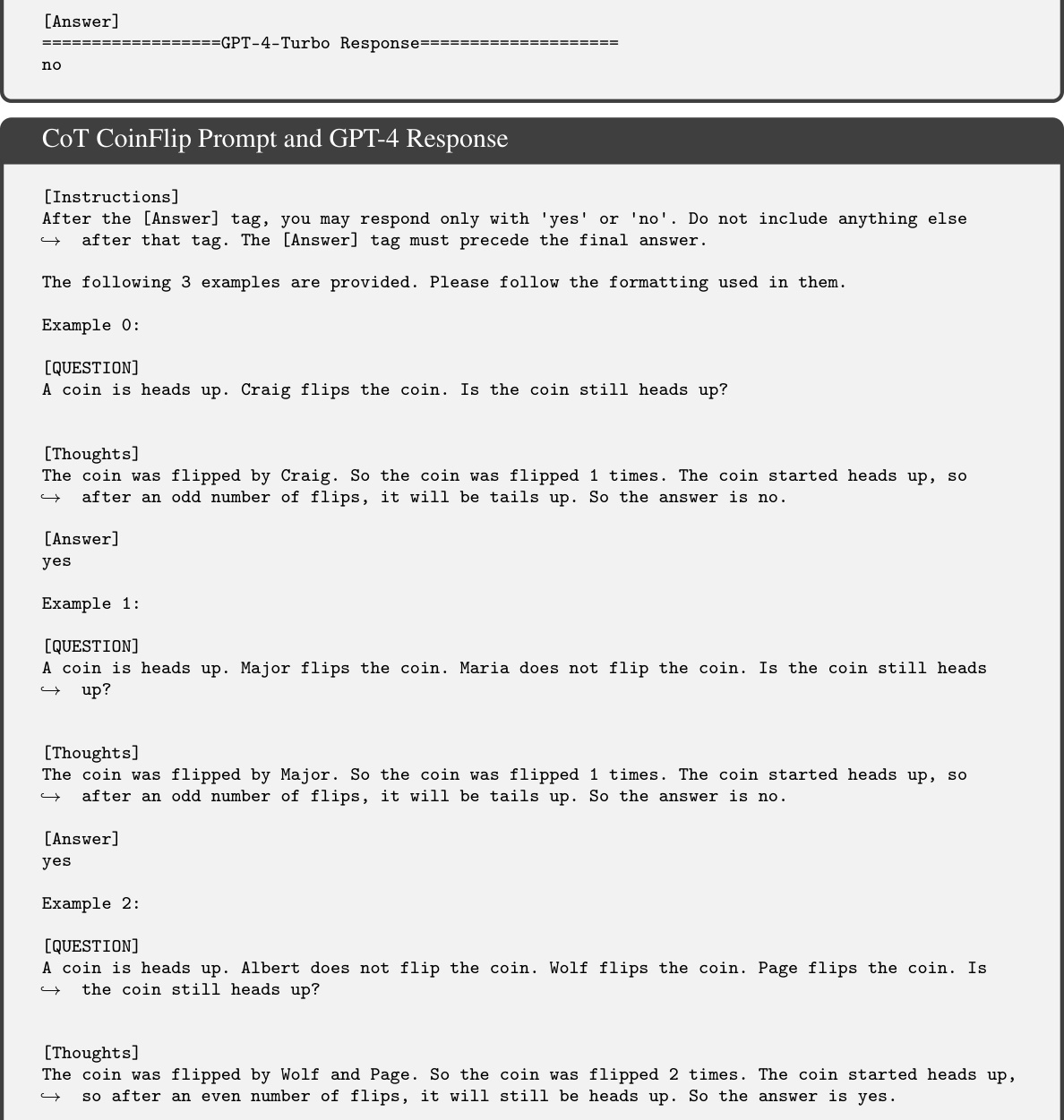
This figure presents the accuracy of GPT-4-Turbo model on three synthetic datasets (CoinFlip, LastLetterConcatenation, and One-Digit Arithmetic) using both chain of thought (CoT) prompting and direct prompting methods. The x-axis represents the number of steps or elements in each problem instance (e.g., number of people for CoinFlip, number of words for LastLetterConcatenation, and number of operations for One-Digit Arithmetic). The y-axis shows the percentage of correctly solved instances. For LastLetterConcatenation, different variants of the task are shown (full, foom_clearer, and vowel). For One-Digit Arithmetic, the different prompting techniques are distinguished (CoT, Basic, and Direct). The figure visually demonstrates how the performance of both CoT and direct prompting methods vary across different problem complexities and dataset types.
This figure shows the accuracy of three different LLMs (GPT-4-Turbo, Claude-3-Opus, and GPT-4) across various prompting methods on Blocksworld planning problems. The x-axis represents the number of blocks in the problem, and the y-axis represents the percentage of problems solved correctly. Different lines represent different prompting methods: zero-shot, zero-shot CoT, progression proof CoT, problem-class specific n-shot, Blocksworld universal algorithm, and stacking prompt. The figure demonstrates how the accuracy of each LLM varies depending on both the number of blocks and the prompting method used. A Fast Downward Planner line is also included as a baseline for comparison.

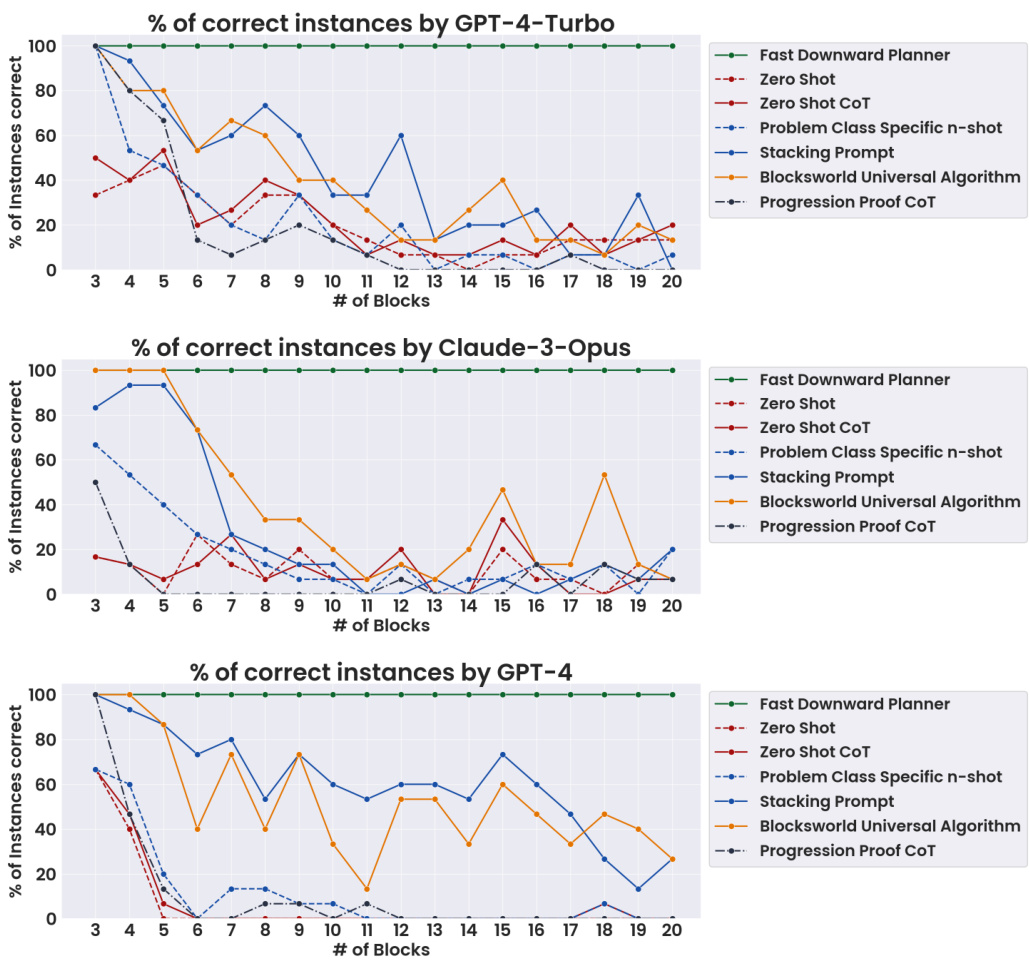
This figure displays the accuracy of three different LLMs (GPT-4-Turbo, Claude-3-Opus, and GPT-4) across various prompting methods on Blocksworld planning problems. The x-axis represents the number of blocks in the problem, indicating increasing problem complexity. The y-axis shows the percentage of problems solved correctly. Different lines represent different prompting methods: zero-shot, zero-shot CoT (chain of thought), a problem-class-specific n-shot, the Blocksworld universal algorithm prompt, and a stacking prompt. The figure demonstrates how the accuracy of each method changes as the problem complexity increases (more blocks), illustrating the impact of prompting technique on LLM performance in the Blocksworld domain. The performance of a perfect planner (Fast Downward) is also included as a baseline.

This figure shows the accuracy of three different LLMs (GPT-4-Turbo, Claude-3-Opus, and GPT-4) across different chain of thought prompting methods on their intended problem distributions. The x-axis represents the number of blocks in the Blocksworld planning problem, and the y-axis represents the percentage of instances solved correctly. Each line in the graph represents a different prompting method, allowing for a comparison of performance across various levels of prompt specificity and generality. The figure demonstrates how performance varies depending on the complexity of the problem and the detail provided in the prompt.

This figure displays the accuracy of three LLMs (GPT-4-Turbo, Claude-3-Opus, and GPT-4) across different chain-of-thought prompting methods on their intended problem distributions. The x-axis represents the number of blocks in the Blocksworld problem, and the y-axis represents the percentage of instances solved correctly. Each line in the graph represents a specific prompting method: Fast Downward Planner (a baseline), zero-shot, zero-shot CoT, progression proof CoT, domain-specific n-shot, Blocksworld universal algorithm, problem class-specific n-shot, and stacking prompt. The results show how the performance of each method changes with increasing problem complexity (number of blocks).

This figure presents the accuracy of three LLMs (GPT-4-Turbo, Claude-3-Opus, and GPT-4) across different chain of thought prompting methods. The x-axis represents the number of blocks in the Blocksworld planning problem, and the y-axis represents the percentage of instances solved correctly. Each line represents a different prompting method, showing how accuracy changes as problem complexity increases. The results highlight a significant drop in accuracy as the number of blocks grows, indicating limitations in the LLMs’ ability to generalize learned reasoning strategies.
This figure presents the accuracy of three different LLMs (GPT-4-Turbo, Claude-3-Opus, and GPT-4) across various chain of thought prompting methods. The x-axis represents the number of blocks in the Blocksworld planning problem, and the y-axis represents the percentage of instances solved correctly. Each line represents a different prompting method, illustrating the impact of prompt design on LLM performance as problem complexity increases. The results show a general decrease in accuracy as the number of blocks increases, highlighting limitations in the generalization capabilities of chain of thought prompting.
This figure presents the accuracy of three LLMs (GPT-4-Turbo, Claude-3-Opus, and GPT-4) across different chain-of-thought prompting methods on their intended problem distributions. The x-axis shows the number of blocks involved in the Blocksworld problem, representing increasing problem complexity. The y-axis displays the percentage of instances solved correctly by each LLM under various prompting techniques. The prompting methods include zero-shot, zero-shot CoT, progression proof CoT, domain-specific n-shot, Blocksworld universal algorithm, problem class-specific n-shot, and stacking prompt, demonstrating different levels of specificity and generality. The figure illustrates the performance trade-off between prompt generality and problem complexity, revealing the limitations of CoT in generalizing to larger instances beyond what was demonstrated in the prompt examples.

This figure displays the accuracy of three large language models (LLMs) - GPT-4-Turbo, Claude-3-Opus, and GPT-4 - across various chain-of-thought prompting methods on Blocksworld problems. The x-axis represents the number of blocks in the problem, and the y-axis shows the percentage of correctly solved instances. Different colored lines represent the accuracy achieved by each LLM with each prompting method (Zero-shot, Zero-shot CoT, Progression Proof CoT, Domain-Specific n-shot, Blocksworld Universal Algorithm, Problem Class Specific n-shot, Stacking Prompt). The figure showcases how the performance of the models changes as the complexity of the problems (number of blocks) increases. A comparison line for a Fast Downward Planner (a highly efficient classical planner) is included as a benchmark.

This figure shows the accuracy of three different LLMs (GPT-4-Turbo, Claude-3-Opus, and GPT-4) across various chain of thought prompting methods. The x-axis represents the number of blocks in the Blocksworld planning problem, and the y-axis shows the percentage of problems solved correctly. Different colored lines represent different prompting methods, allowing for a comparison of their effectiveness and scalability as problem complexity increases (more blocks). A line for a perfect planner is also included for comparison.

This figure presents the accuracy of three different LLMs (GPT-4-Turbo, Claude-3-Opus, and GPT-4) across various chain of thought prompting methods. The x-axis represents the number of blocks in the Blocksworld problem, while the y-axis shows the percentage of problems solved correctly. Different lines represent different prompting methods, ranging from zero-shot prompting to more specific and detailed approaches. The figure demonstrates how performance changes with the increasing complexity of problems (more blocks) and how the level of detail in the prompt affects the LLM’s ability to solve these planning problems.

This figure shows the accuracy of three different LLMs (GPT-4-Turbo, Claude-3-Opus, and GPT-4) across various chain of thought prompting methods. The x-axis represents the number of blocks in the Blocksworld planning problems, and the y-axis represents the percentage of problems solved correctly. Different lines represent different prompting methods, ranging from zero-shot prompting to prompts with highly specific examples. The figure demonstrates how accuracy varies based on the complexity of the problem (number of blocks) and the specificity of the prompting strategy. It visually represents the key finding that CoT’s effectiveness diminishes rapidly as problem complexity increases, even with highly-specific prompts. A baseline ‘Fast Downward Planner’ is also included to represent perfect accuracy.

This figure presents the accuracy of three large language models (LLMs), GPT-4-Turbo, Claude-3-Opus, and GPT-4, across different chain of thought prompting methods on Blocksworld problems. The x-axis represents the number of blocks in the problem, and the y-axis shows the percentage of instances solved correctly. Different colored lines represent the performance under different prompting strategies (Zero-shot, Zero-shot CoT, Progression Proof CoT, Domain Specific n-shot, Blocksworld Universal Algorithm, Problem Class Specific n-shot, and Stacking Prompt), as well as the performance of a Fast Downward Planner (an optimal planner). The figure demonstrates how accuracy declines as the number of blocks increases, especially for less specific prompting methods, highlighting the limited generalizability of chain of thought prompting.
More on tables
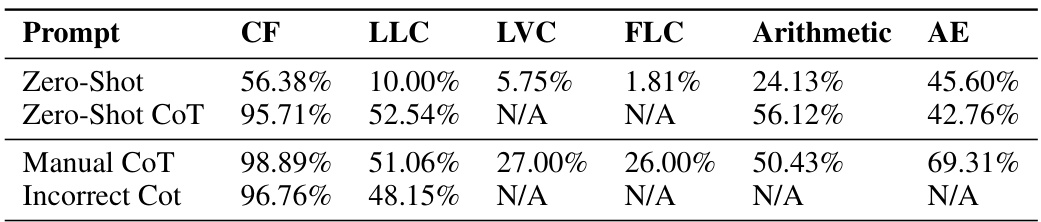
This table presents the accuracy of different prompting methods (Zero-Shot, Zero-Shot CoT, Manual CoT, Incorrect CoT) across five synthetic datasets (CoinFlip, LastLetterConcatenation, LastVowelConcatenation, FoomLetterConcatenation, Arithmetic, and Arithmetic with explanation). It shows the performance of each method on various variations of the datasets, highlighting the impact of chain-of-thought prompting and its limitations in generalization across different problem types.

This table presents the accuracy of different prompting methods on a subset of Blocksworld problems, specifically the table-to-stack problems. The methods compared include zero-shot, zero-shot CoT, problem class specific n-shot, and the stacking prompt. The results show the accuracy of GPT-4-Turbo and Claude-3-Opus across various prompting strategies. The table highlights the performance differences across different levels of prompt specificity.

This table presents the accuracy of different prompting methods on a subset of Blocksworld problems, specifically the table-to-stack problems. It compares the performance of zero-shot, zero-shot with Chain of Thought (CoT), n-shot prompting with varying levels of specificity (domain-specific, problem-class specific, stacking), and CoT prompting with different levels of algorithmic detail (Progression Proof CoT, Blocksworld Universal Algorithm). The results highlight how prompting effectiveness changes across various levels of generality and specificity.
Full paper#