↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing vision LLMs often struggle with multimodal generalization, insufficient visual granularity, and limited task coverage. They mostly focus on either images or videos and lack the ability to perform a wide range of vision tasks. This necessitates the development of more unified models.
VITRON addresses these limitations by introducing a novel universal pixel-level vision LLM. It incorporates encoders for various visual inputs, uses a hybrid method integrating textual and continuous signal embeddings for effective task instruction, and employs a cross-task synergy module to maximize the shared fine-grained visual features. Extensive experiments across various datasets show VITRON outperforming existing models in several vision tasks, demonstrating its capabilities in image and video understanding, generation, segmentation, and editing.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on multimodal large language models (MLLMs) and computer vision. It presents a novel approach to unifying image and video understanding, generation, and editing tasks within a single framework, opening new avenues for creating more versatile and powerful AI systems. The findings provide valuable insights into hybrid instruction passing, pixel-level visual grounding, and cross-task synergy learning, offering several directions for future research in MLLMs.
Visual Insights#

This figure shows the four main task clusters that VITRON supports. These clusters cover a wide range of vision tasks, from low-level visual semantics (like panoptic, instance, and semantic segmentation) to high-level visual semantics (like image and video question answering, captioning, and retrieval). The tasks are categorized into four clusters: visual understanding, vision segmentation & grounding, visual synthesis & generation, and vision editing & inpainting. Each cluster contains several specific tasks with example images or video clips demonstrating those tasks. The figure visually represents the comprehensive capabilities of VITRON in handling various vision tasks.
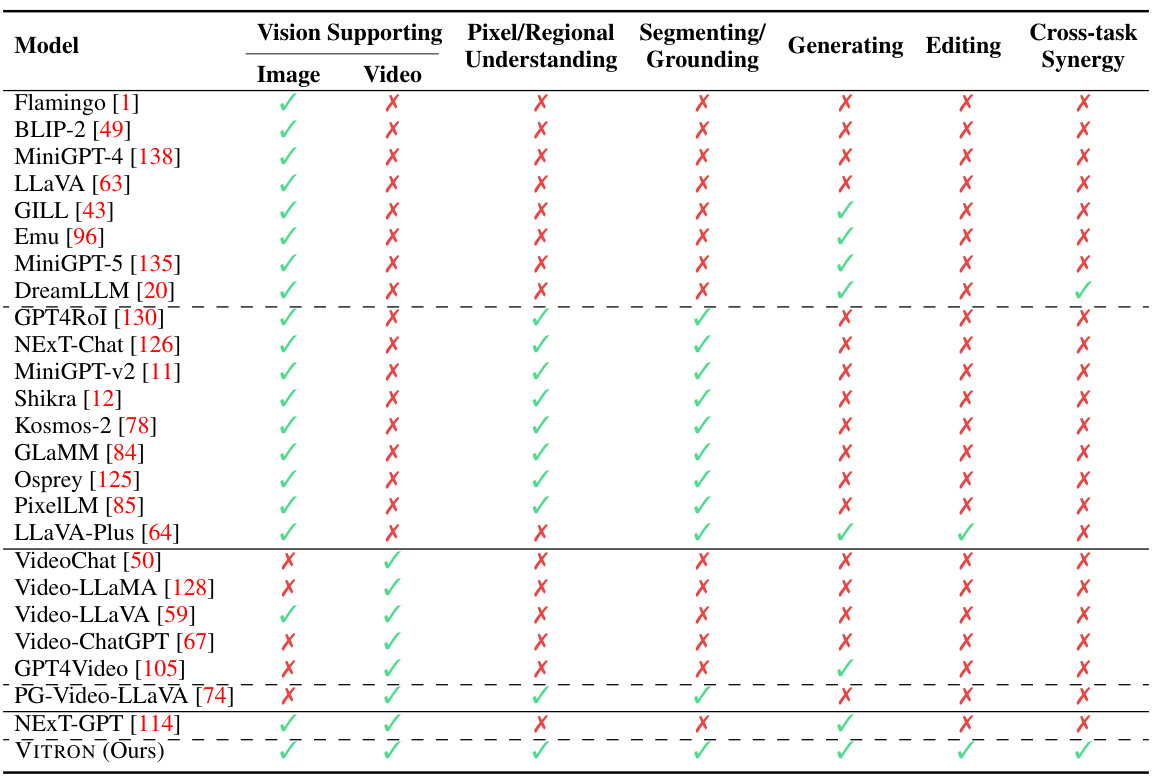
This table compares various vision LLMs based on their capabilities in understanding, generating, segmenting, and editing both images and videos. It highlights the differences in pixel/regional understanding, grounding abilities, and support for cross-task synergy. The table helps to position VITRON within the existing landscape of vision LLMs by showing its more comprehensive capabilities compared to others.
In-depth insights#
Unified Vision LLM#
A Unified Vision LLM represents a significant advancement in artificial intelligence, aiming to overcome the limitations of current, specialized vision models. Its unifying characteristic lies in its ability to handle diverse vision tasks—image and video understanding, generation, segmentation, and editing—within a single, integrated framework. This contrasts sharply with existing approaches that typically focus on a narrow set of tasks. The key to this unification is likely a robust, large-scale language model backbone enhanced with specialized visual modules. This architecture enables seamless transfer of knowledge and information between different visual domains, leading to more effective and efficient processing. A hybrid approach—combining discrete textual instructions with continuous signal embeddings—could facilitate better communication between the LLM and specialized modules. Pixel-level processing enables fine-grained visual understanding and manipulation, surpassing the limitations of coarser, instance-level methods. Overall, a Unified Vision LLM promises a more versatile, powerful, and human-like understanding of visual information.
Pixel-Level grounding#
Pixel-level grounding in vision-language models represents a significant advancement, moving beyond coarser object-level or region-based understanding. It allows for a more precise and detailed alignment between visual information and textual descriptions. This fine-grained understanding is crucial for tasks requiring precise localization, such as referring expression comprehension, visual question answering, and image editing. Challenges in pixel-level grounding include computational cost, the need for high-resolution feature maps, and effectively handling variations in image quality and visual complexity. Success in pixel-level grounding often relies on sophisticated attention mechanisms or transformer-based architectures that can capture long-range dependencies and intricate spatial relationships. Moreover, effective training strategies that leverage large-scale datasets and suitable loss functions are vital for achieving strong performance. The future of pixel-level grounding likely involves exploring more efficient architectures, incorporating advanced learning paradigms, and focusing on robust generalization across diverse visual domains.
Cross-Task Synergy#
The concept of ‘Cross-Task Synergy’ in a vision-language model (VLM) focuses on improving performance across various visual tasks by enabling interactions between different modules specialized for specific tasks (e.g., image generation, segmentation, editing). Instead of treating these modules as isolated units, a synergistic approach aims to share knowledge and leverage task-invariant features, which are common across multiple visual tasks, to enhance overall performance. This is often achieved through architectural designs that promote information flow and feature sharing between modules, and training techniques that encourage the learning of shared representations. A key benefit is that the model can generalize better to unseen tasks and situations. Adversarial training is one technique used to facilitate this synergy. By using a discriminator to distinguish between task-specific and task-invariant features, the model learns to focus on task-invariant information useful for multiple tasks. Overall, cross-task synergy is a significant aspect of building robust and efficient multimodal models capable of performing several visual tasks with unified performance.
Vision Task Clusters#
The concept of ‘Vision Task Clusters’ in a research paper suggests a structured categorization of computer vision tasks, grouping similar functionalities to facilitate a comprehensive understanding and evaluation. This approach is particularly insightful when assessing a new model’s capabilities. By organizing tasks into these clusters, researchers can better analyze the model’s performance across different aspects of vision, such as understanding, generation, segmentation, and editing. This structured approach allows for a deeper exploration of strengths and weaknesses across various task complexities, and ultimately leads to a more nuanced and insightful evaluation than a task-by-task approach. It highlights the model’s overall proficiency and reveals potential areas for future improvements. Furthermore, the use of clusters helps to define a model’s position within the broader computer vision landscape, facilitating meaningful comparisons with existing state-of-the-art models.
Future Directions#
Future research could explore improving the efficiency and scalability of the model, perhaps through architectural optimizations or more efficient training techniques. Addressing the limitations in handling complex, real-world scenarios is also crucial. This might involve incorporating more robust mechanisms for handling noisy or ambiguous inputs, as well as developing methods for better generalization to unseen data. The model’s ability to reason and generate creative content could be significantly enhanced by integrating more sophisticated reasoning modules and exploring techniques such as reinforcement learning. Furthermore, the development of effective methods for evaluating and benchmarking the model’s performance across a wider range of tasks and datasets would be a valuable contribution. Finally, investigating potential ethical concerns and developing mitigation strategies to prevent misuse is paramount for responsible development and deployment.
More visual insights#
More on figures

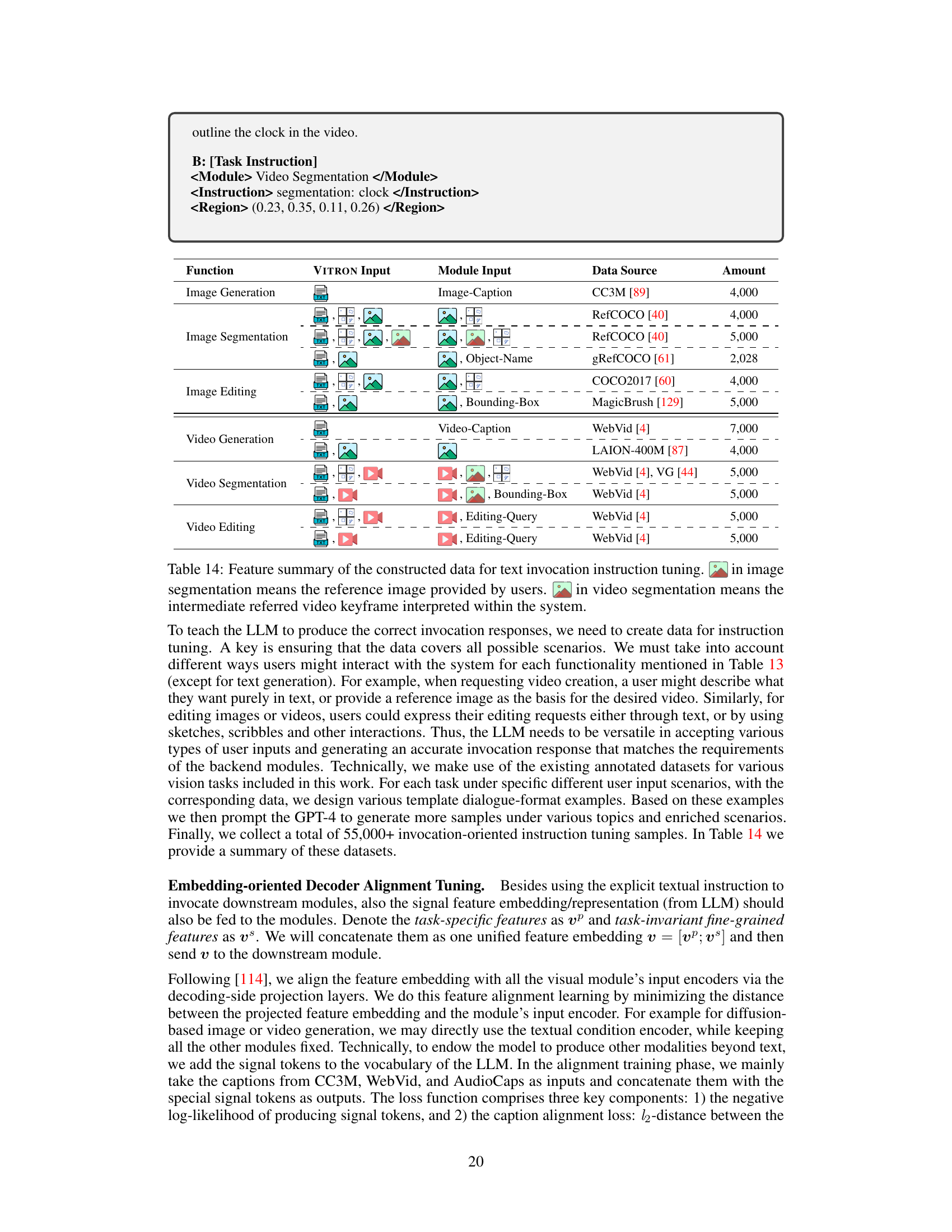
The figure illustrates the architecture of VITRON, a unified pixel-level vision LLM. It shows the frontend modules (image, video, and sketch encoders) that process various visual inputs. These inputs are then passed to a central Large Language Model (LLM), which is responsible for understanding and generating textual responses. The LLM interacts with backend visual specialists (via projections of task-specific and task-invariant features) to perform various vision tasks, including segmentation, generation, and editing. The LLM utilizes a hybrid approach for precise message passing, combining discrete textual instructions and continuous signal embeddings. Finally, a cross-task synergy module is implemented to enhance the synergy between different visual tasks.

This figure illustrates the synergy module used in VITRON. The module aims to maximize the use of shared task-invariant features among various visual tasks. A discriminator is used in adversarial training to decouple task-specific features from the shared task-invariant features. The goal is to enhance synergy between different tasks by maximizing the use of the shared features.

The figure provides a technical overview of the VITRON framework, illustrating its key components and their interactions. It shows the frontend vision and language encoders processing image, video, and sketch inputs. These encoders pass information to a central large language model (LLM), which interacts with task-specific and task-invariant feature projections. The LLM then outputs textual responses and instructions for backend specialist modules (e.g., for image/video generation, segmentation, and editing). This visual representation helps clarify the architecture and workflow of the VITRON system, highlighting the interplay between language understanding and various vision tasks.

The figure is a diagram that shows the four main task clusters that VITRON supports. These clusters are visual understanding, visual segmentation and grounding, visual generation, and vision editing and inpainting. Each cluster contains a number of subtasks. The diagram visually represents the hierarchical relationships between these task clusters and subtasks, showcasing VITRON’s broad capabilities in visual processing.
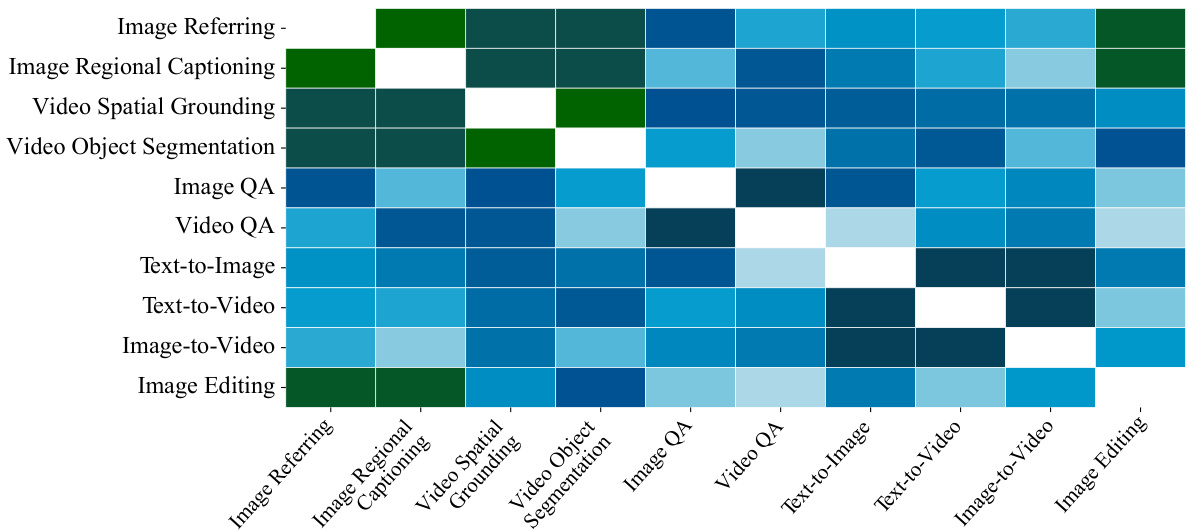
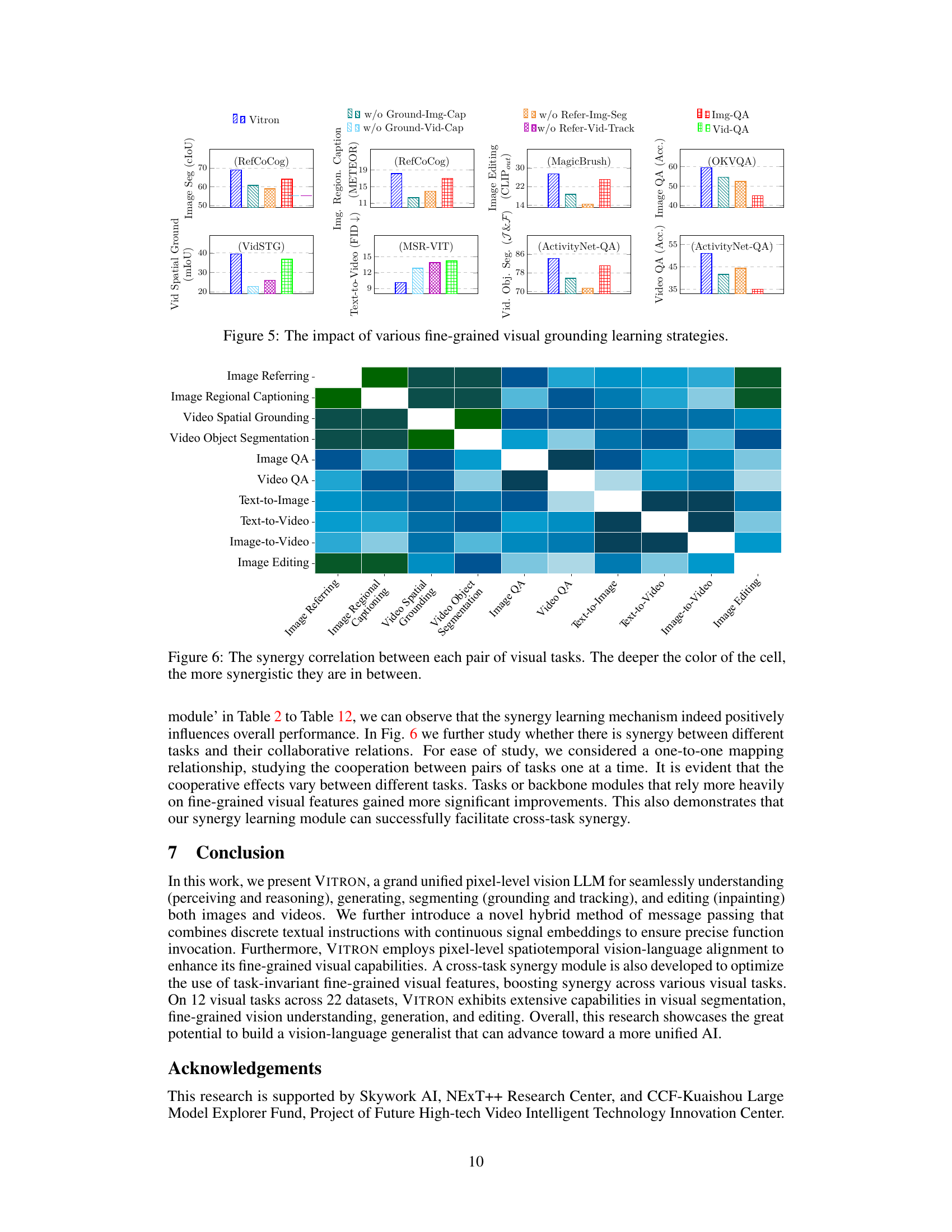
This figure shows a heatmap illustrating the degree of synergy between different pairs of visual tasks performed by the VITRON model. The color intensity of each cell represents the level of synergy, with darker colors indicating stronger synergy and lighter colors indicating weaker synergy. The tasks are grouped into four main clusters: visual understanding, visual generation, visual segmentation, and visual editing. The heatmap helps to visualize the relationships between these task clusters and identify which tasks benefit most from collaboration within the VITRON framework.

This figure shows the four main task clusters that VITRON supports. These clusters cover a wide range of vision tasks, from low-level visual semantics (like instance, semantic, and panoptic segmentation) to high-level visual semantics (like image and video question answering, captioning, and retrieval). The tasks are categorized into visual understanding, visual segmentation and grounding, visual generation, and vision editing & inpainting. The figure illustrates the breadth of VITRON’s capabilities, spanning from basic image and video understanding to complex generation and editing tasks. It visually demonstrates the system’s unified pixel-level approach to handling various vision problems.

This figure provides a visual overview of the capabilities of the VITRON model. It’s categorized into four main task clusters: Visual Understanding, Vision Segmentation & Grounding, Visual Generating, and Vision Editing & Inpainting. Each cluster further breaks down into various subtasks, showcasing the model’s versatility in handling a wide range of vision-related tasks, from low-level semantic understanding to high-level image and video generation and manipulation.

This figure shows the four main task clusters that VITRON supports. These clusters cover a wide range of vision tasks, from low-level visual semantics (like understanding basic image features) to high-level visual semantics (like answering complex questions about images and videos). The tasks are grouped into visual understanding, vision segmentation & grounding, visual generating, and vision editing & inpainting. Each category includes multiple specific vision tasks such as image captioning, video object segmentation, text-to-image generation, and image inpainting. This illustrates the model’s comprehensive capabilities across various vision-related applications.

This figure shows the four main task clusters that VITRON supports. These clusters cover a wide range of vision tasks, from low-level visual semantics (like panoptic, instance, and semantic segmentation) to high-level visual semantics (like image and video captioning, question answering, and retrieval). The tasks are categorized into four main clusters: Visual Understanding, Vision Segmentation & Grounding, Visual Generating, and Vision Editing & Inpainting. The figure visually represents the capabilities of VITRON across these diverse visual tasks, highlighting its ability to handle both images and videos.
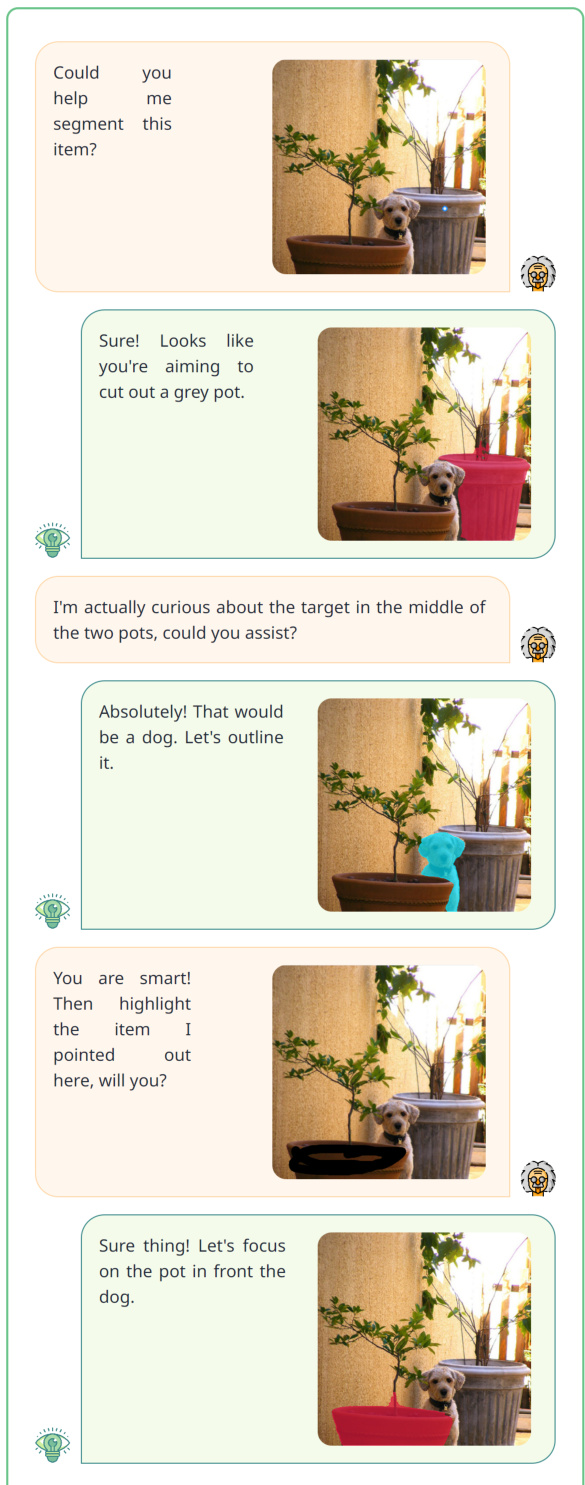
This figure shows the four main task clusters that VITRON supports. These clusters span a range of vision tasks from low-level to high-level, encompassing visual comprehension and visual generation. The low-level tasks include visual semantics (panoptic, instance, semantic, referring, phrase grounding, video grounding, and video object segmentation) and visual synthesis & generation (text-to-image, text-to-video, and image-to-video generation). High-level tasks include image/video referring, captioning, image QA, video QA, language-image retrieval, and language-video retrieval. Finally, vision editing and inpainting are included, encompassing tasks such as adding, removing, replacing, moving, style changing, and color changing.
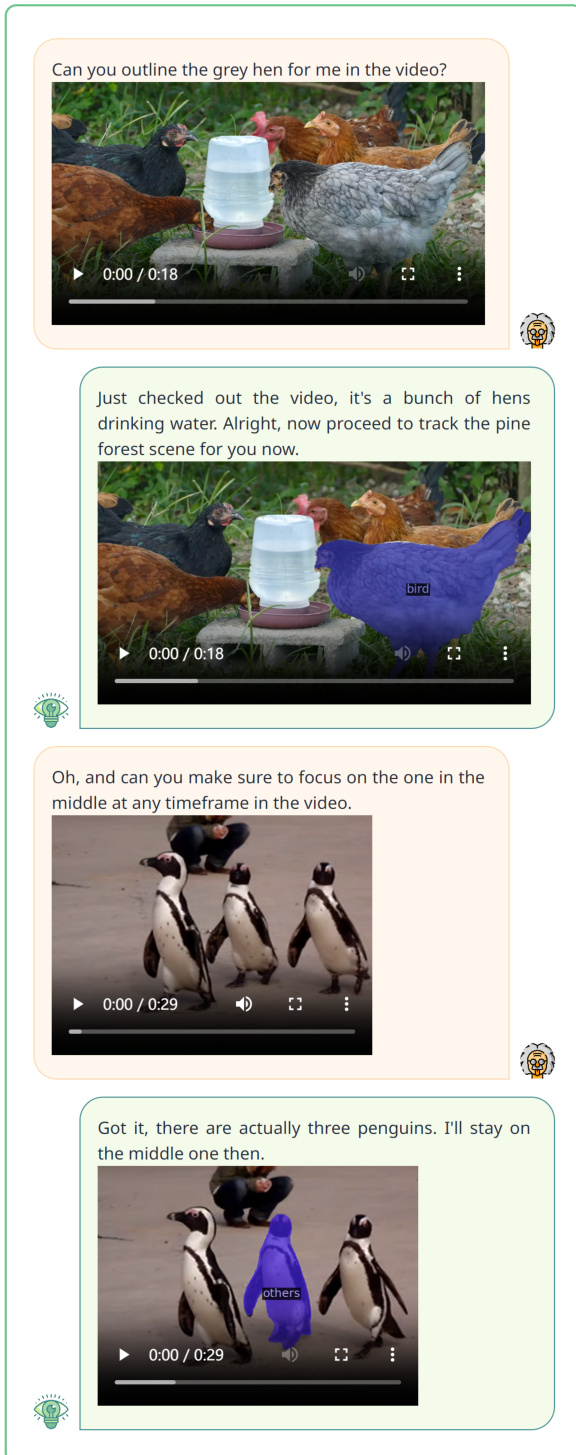
This figure shows the four main task clusters that VITRON supports. These clusters are visual understanding, vision segmentation & grounding, visual generating, and vision editing & inpainting. Each cluster contains various sub-tasks, ranging from low-level (e.g., semantic segmentation, panoptic segmentation, phrase grounding) to high-level tasks (e.g., text-to-image generation, image-to-video generation, video editing). The figure visually represents how VITRON integrates and unifies these tasks through a comprehensive framework.

This figure shows the four main task clusters that VITRON supports. These clusters cover a range of vision tasks, from low-level visual semantics (like panoptic, instance, semantic, and referring image segmentation) to high-level visual semantics (like image and video QA, captioning, and retrieval). The tasks are grouped into visual understanding, vision generation, vision segmentation & grounding, and vision editing & inpainting. The image illustrates the comprehensive capabilities of VITRON across various vision tasks and levels of abstraction.

This figure shows the four main task clusters that VITRON supports. These clusters span visual comprehension to visual generation tasks, and range from low-level (e.g., low-level visual semantics, pixel-level vision understanding) to high-level (e.g., high-level visual semantics) tasks. The clusters include visual understanding, visual generation, vision segmentation & grounding, and vision editing & inpainting. Each cluster contains several sub-tasks, and examples of the sub-tasks are included in the figure.
The VITRON framework consists of three key components: frontend vision and language encoders, central LLM for semantic understanding and text generation, and backend decoder modules for user response and vision manipulation. The frontend encoders process image, video, and sketch inputs. The central LLM processes these inputs and generates textual responses as well as instructions and feature embeddings for the backend modules. The backend modules are specialized models for various vision tasks, including segmentation, generation, and editing. A hybrid approach is used for message passing, combining discrete textual instructions and continuous signal feature embeddings.

This figure shows the four main task clusters that VITRON supports. These clusters span visual comprehension (understanding) to visual generation (creating) and range from low-level tasks (like pixel-level understanding) to high-level tasks (like generating videos from text). The image displays a diagram categorizing various vision tasks under these four main clusters.

The figure provides a visual representation of the VITRON framework’s architecture. It shows how various components, including image and video encoders, a large language model (LLM), and backend decoder modules, work together to process different visual tasks. The flow of information and the task-specific and task-invariant features are also depicted. The figure helps illustrate the overall pipeline of processing an image/video query and generating a response or manipulating the image/video content.
This figure shows the four main task clusters that VITRON supports. These clusters are Visual Understanding, Vision Segmentation & Grounding, Visual Generating, and Vision Editing & Inpainting. Each cluster contains various low-level and high-level tasks, demonstrating the wide range of capabilities of the VITRON model.

The figure provides a technical overview of the VITRON framework, illustrating its main components and the flow of information. It shows the frontend modules (image, video, and sketch encoders) processing user inputs, passing the results to the Large Language Model (LLM) backbone. The LLM then makes decisions and outputs textual responses or instructions for function invocation and feature embeddings to backend modules (visual specialists). These specialists execute specific vision tasks (segmentation, generation, editing) and provide task-specific and task-invariant features that are further utilized by the LLM. The interaction between the different components highlights the system’s unified approach to various visual tasks.

This figure provides a visual overview of the capabilities of VITRON, illustrating its ability to handle four main task clusters: Visual Understanding, Visual Segmentation & Grounding, Visual Generating, and Vision Editing & Inpainting. Each cluster contains various subtasks, progressing from low-level visual semantics (e.g., panoptic segmentation) to high-level semantics (e.g., image captioning) and demonstrating the model’s versatility in processing and generating visual information.
More on tables

This table presents the results of the referring image segmentation task, comparing VITRON’s performance against several other methods on three benchmark datasets: RefCOCO, RefCOCO+, and RefCOCOg. The cIoU (Intersection over Union) metric is used to evaluate the accuracy of the models in segmenting the target objects specified by referring expressions. The table also includes a comparison row showing VITRON’s performance without the synergy learning module, highlighting its contribution to improved results.

This table compares the performance of VITRON against other state-of-the-art models on two video spatial grounding datasets: VidSTG [134] and HC-STVG [98]. The mIoU (mean Intersection over Union) metric is used to evaluate the accuracy of grounding. The table highlights that VITRON achieves superior performance compared to other models, and also shows the impact of the synergy module by showing results with and without it (w/o syng.).
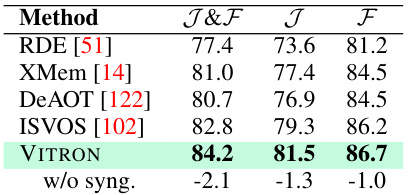
This table presents the results of video object segmentation on the DAVIS 17 Test-Dev dataset. It compares the performance of VITRON against several state-of-the-art methods, including VidSTG [134], HC-STVG [98], RDE [51], XMem [14], DeAOT [122], ISVOS [102] and PG-Video-LLaVA [74]. The metrics used are J&F, J, and F. The ‘w/o syng.’ row shows the performance of VITRON without the cross-task synergy module, highlighting the impact of this module on performance.

This table presents the results of image regional captioning on the RefCOCOg dataset. It compares the performance of VITRON against several other models, including GRIT, Kosmos-2, NEXT-Chat, MiniGPT-v2, GLaMM, and Osprey. The metrics used for comparison are METEOR and CIREr. The results show that VITRON achieves the highest scores on both metrics, indicating its superior performance in accurately generating captions for image regions.

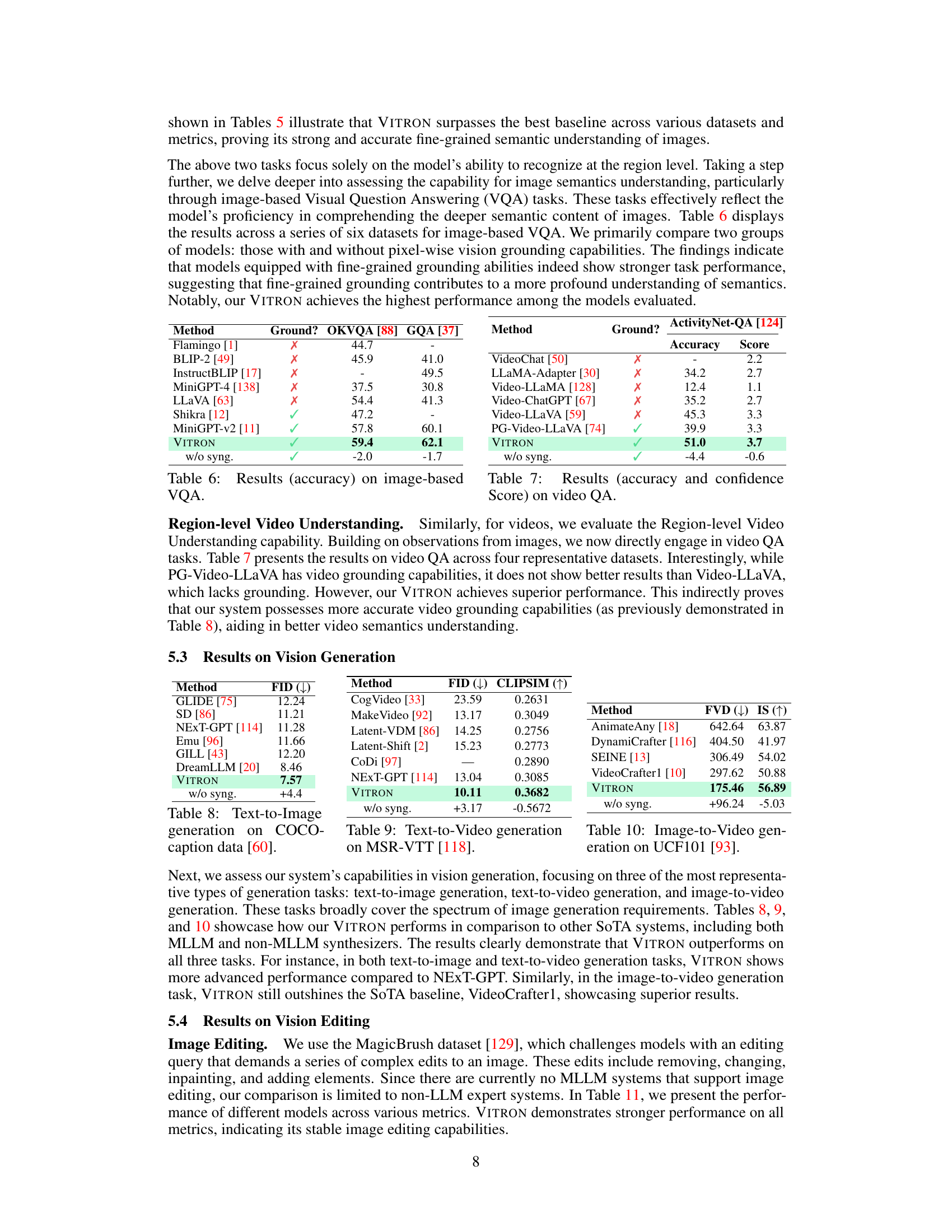
This table presents the results of image-based Visual Question Answering (VQA) experiments, comparing the performance of various models. The ‘Ground?’ column indicates whether the model incorporates pixel-wise vision grounding. The results are shown as accuracy scores on six different datasets: OKVQA [88], GQA [37], VSR [62], IconVQA [66], VizWiz [32], and HM [41]. VITRON, with its pixel-level grounding, achieves superior performance compared to other models.

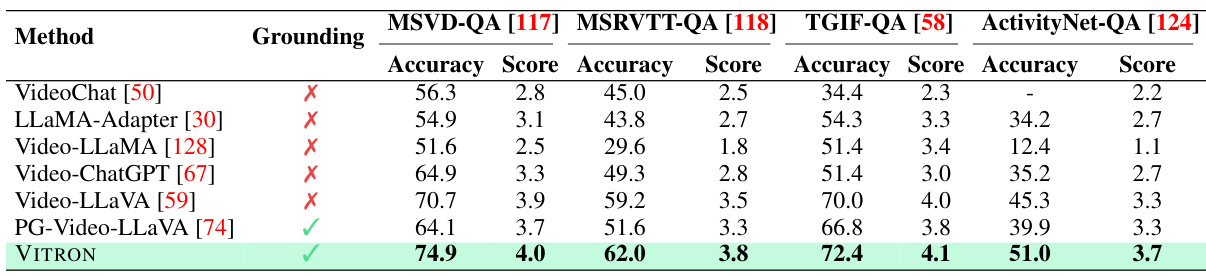
This table compares the performance of various vision LLMs on the ActivityNet-QA dataset, a benchmark for video question answering. The ‘Ground?’ column indicates whether the model incorporates pixel-level grounding. The table shows accuracy and confidence scores for each model. VITRON achieves the highest accuracy (51.0) and score (3.7), demonstrating superior performance, particularly when compared to models without grounding.
This table compares several existing vision-language models (MLLMs) based on their capabilities in understanding, generating, segmenting, and editing both images and videos. It highlights the lack of unification in current models, showing that many only support either images or videos, and often lack a comprehensive range of functionalities. The table serves to illustrate the need for a unified, pixel-level vision LLM like VITRON, which the paper introduces.

This table presents the quantitative results of image editing experiments conducted on the MagicBrush dataset. It compares the performance of VITRON against several state-of-the-art image editing methods. The metrics used to evaluate the performance include CLIP similarity scores (CLIPdir, CLIPimg, and CLIPout), and the L1 distance between the edited image and the target image (L1). The results demonstrate VITRON’s superior performance in image editing tasks.
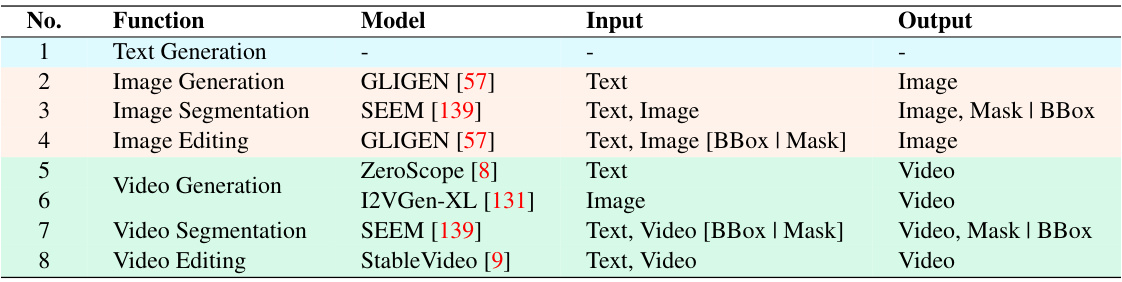
This table compares several existing vision-language models (MLLMs) based on their capabilities. It shows which models support image or video understanding, pixel-level or regional grounding, segmentation, generation, or editing tasks, and whether they include cross-task synergy. The table highlights the lack of a unified model that supports all these tasks comprehensively. VITRON, the model proposed in the paper, is shown as having support across all these capabilities.
This table compares several existing vision-language models (MLLMs) across various criteria, including their ability to process images and videos, perform pixel-level understanding, and handle various tasks such as segmentation, grounding, generation, and editing. The table highlights the limitations of existing models in terms of unified support for both images and videos, insufficient coverage across different vision tasks, and the lack of pixel-level understanding. It sets the stage for introducing VITRON, which aims to address these limitations.
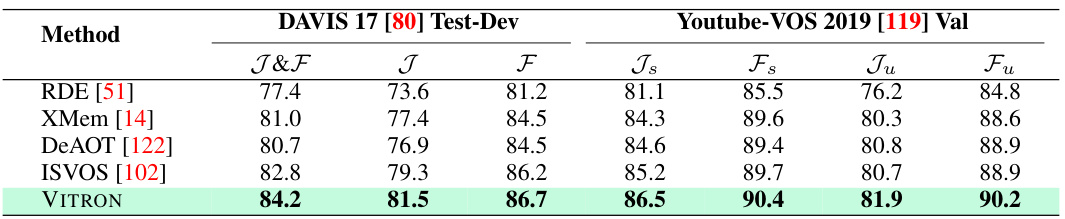
This table compares the performance of VITRON against other state-of-the-art models on video object segmentation tasks using two benchmark datasets: DAVIS 17 and Youtube-VOS 2019. The results are broken down by different metrics (J&F, J, F, Js, Fs, Ju, Fu), which likely represent variations in the evaluation criteria.

This table presents the results of the referring image segmentation task, comparing the VITRON model’s performance against several other models on three datasets: RefCOCO, RefCOCO+, and RefCOCOg. The cIoU (Intersection over Union) metric is used to evaluate the performance. A comparison is also made showing the effect of removing the synergy learning component of the VITRON model.
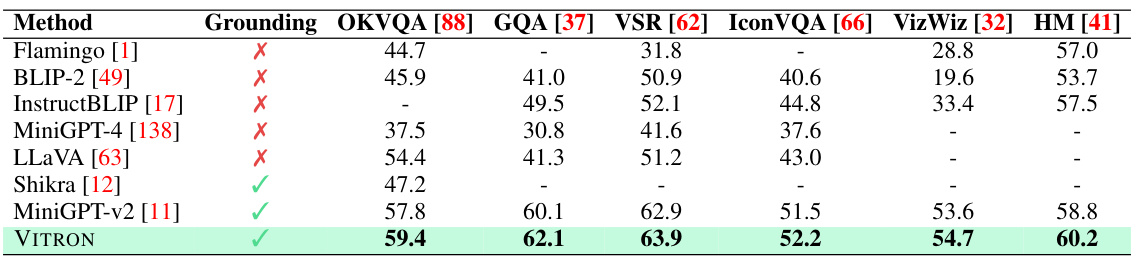
This table presents the accuracy scores of different vision language models on six image-based Visual Question Answering (VQA) datasets. It compares models with and without pixel-wise vision grounding capabilities, demonstrating the impact of fine-grained grounding on VQA performance. VITRON achieves the highest accuracy across all datasets.
This table compares various vision-language large models (MLLMs) based on their capabilities in understanding, generating, segmenting, and editing both images and videos. It highlights the limitations of existing models, such as the lack of unified support for both image and video modalities, insufficient coverage across various vision tasks, and insufficient pixel-level understanding. The table also shows that VITRON, proposed by the authors, is a pioneering model in achieving a unified and comprehensive vision MLLM framework.
Full paper#