↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
The proliferation of pre-trained models online presents significant security risks. Malicious actors can inject “backdoors” into these models, which, when fine-tuned by users, leak sensitive training data at a much higher rate than with standard models. This poses a severe threat to user privacy and data security, especially given the wide adoption of pre-trained models in various applications.
This research introduces a novel black-box attack called the “privacy backdoor.” It involves poisoning pre-trained models to make training data leakage much more likely when the model is used by a victim. The attack was tested extensively across various datasets and models. Experiments show a marked improvement in the success rate of membership inference attacks. Ablation studies reveal the attack’s effectiveness across different fine-tuning methods and inference strategies, indicating a serious threat and the need for enhanced security measures for open-source pre-trained models.
Key Takeaways#
Why does it matter?#
This paper is crucial because it reveals a critical privacy vulnerability in widely used pre-trained models. By showing how easily these models can be poisoned to leak training data, it prompts a reevaluation of security protocols and urges the development of more robust privacy-preserving techniques for machine learning. This has significant implications for data security and the trust placed in open-source models.
Visual Insights#
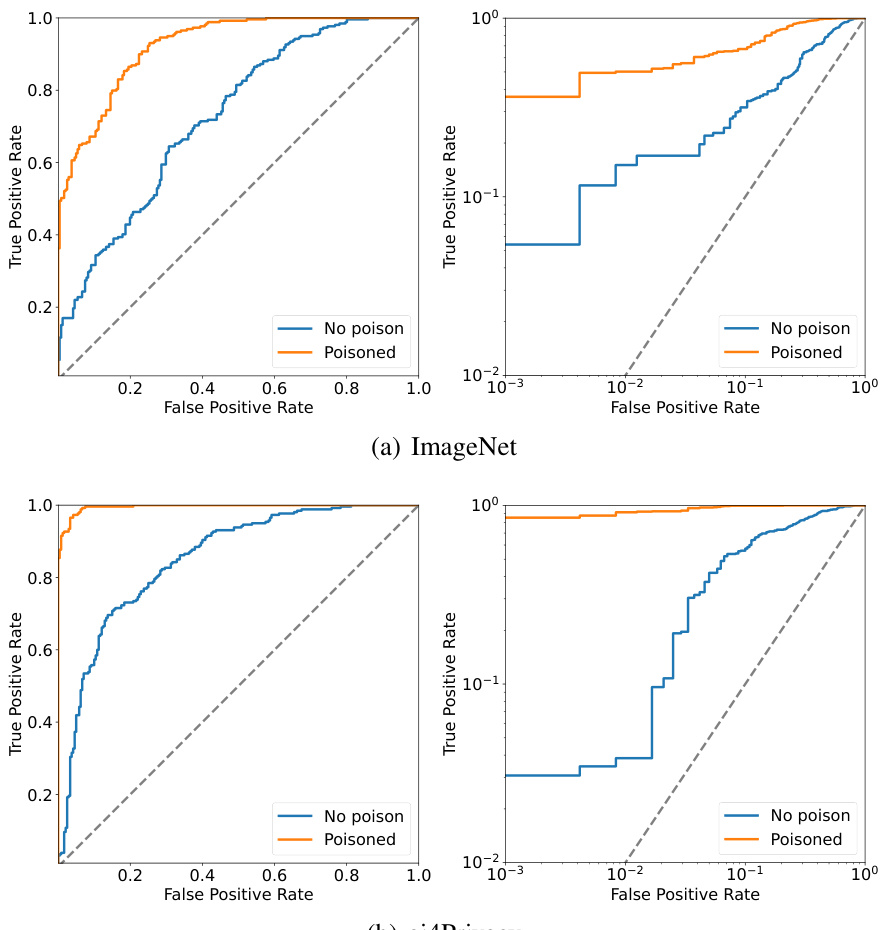
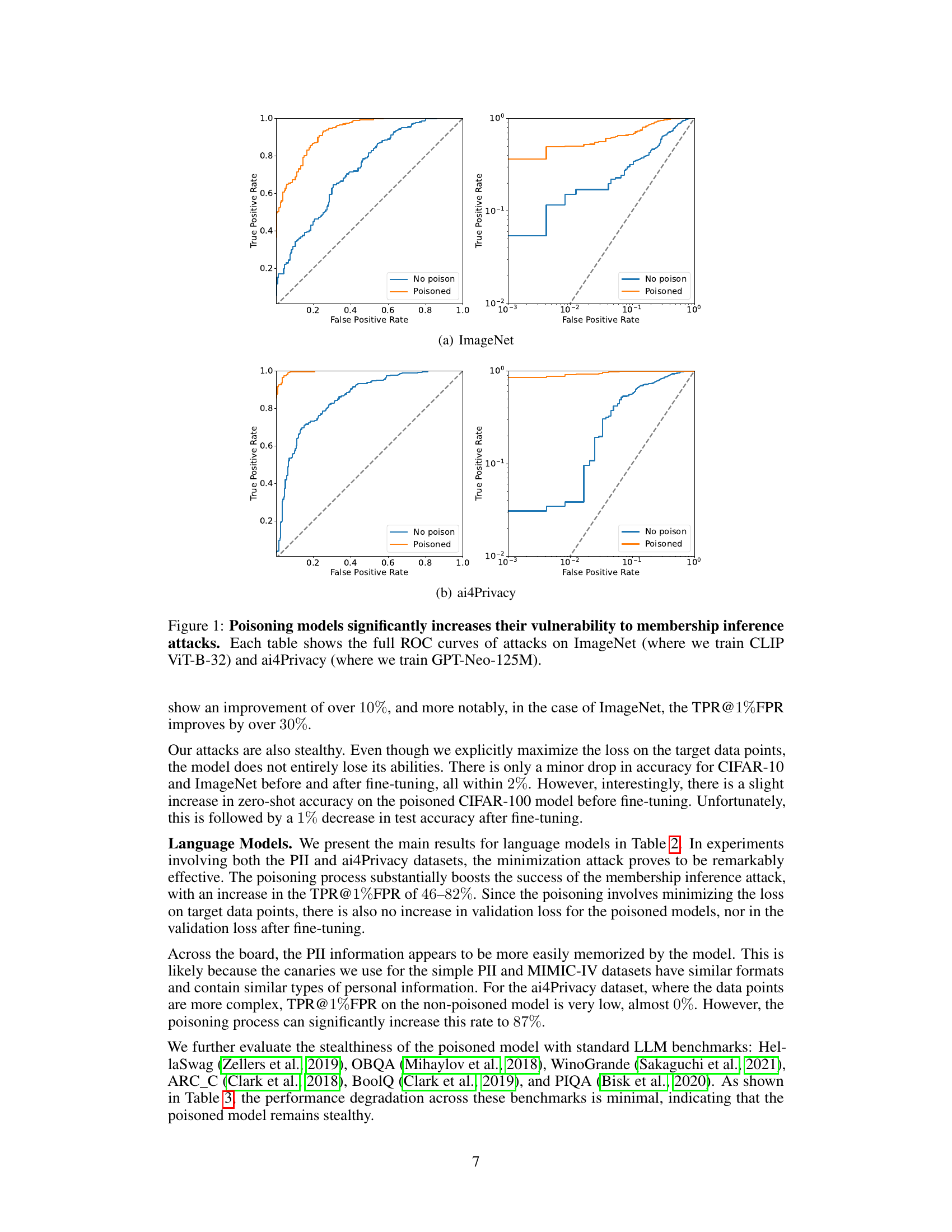
This figure displays Receiver Operating Characteristic (ROC) curves, illustrating the performance of membership inference attacks on two different datasets, ImageNet and ai4Privacy. The left side shows standard ROC curves, while the right side uses a logarithmic scale for the y-axis (True Positive Rate) to better highlight the performance differences at low false positive rates. Each dataset is tested with and without the poisoning attack described in the paper. The results show that the poisoning attack considerably increases the True Positive Rate at a given False Positive Rate, demonstrating its effectiveness in enhancing membership inference attacks.
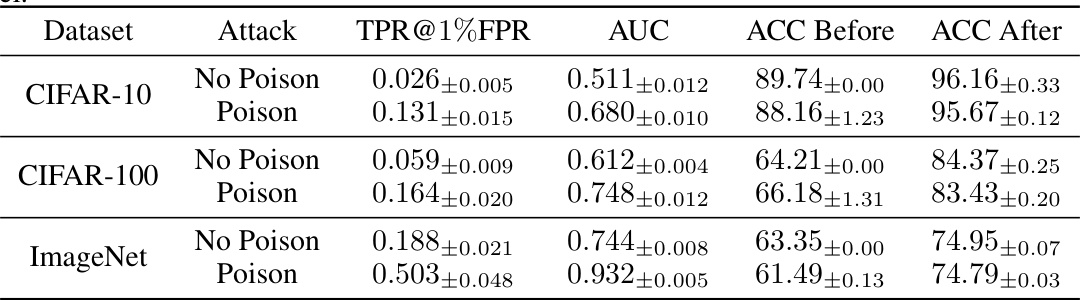
This table presents the results of a poisoning attack on CLIP models, specifically using the ViT-B-32 pre-trained model. It compares the performance of membership inference attacks (MIAs) with and without the poisoning technique. The metrics used for evaluation are the True Positive Rate at 1% False Positive Rate (TPR@1%FPR), the Area Under the Curve (AUC) of the ROC curve, and the accuracy (ACC) of the model before and after fine-tuning. The results are shown for three different datasets: CIFAR-10, CIFAR-100, and ImageNet. The table demonstrates the significant improvement in MIA success rate achieved by the poisoning attack.
In-depth insights#
Privacy Backdoors#
The concept of “Privacy Backdoors” introduces a novel attack vector in machine learning, focusing on the vulnerabilities of pre-trained models. The attack involves poisoning a pre-trained model to amplify privacy leakage during subsequent fine-tuning. This is achieved by subtly modifying model weights to create anomalous loss behavior on specific data points. This manipulation renders fine-tuned models more susceptible to membership inference attacks (MIAs), enabling adversaries to ascertain which data points were used during fine-tuning. The cleverness lies in its stealth; the backdoored model retains normal functionality while significantly boosting MIA success rates. This highlights a critical blind spot in the current security practices surrounding the widespread adoption of pre-trained models, emphasizing the urgent need for improved model safety and enhanced privacy protection within the machine learning community. The research underscores the importance of verifying pre-trained models for backdoors before deployment and calls for a reevaluation of security protocols.
Poisoning Attacks#
Poisoning attacks represent a significant threat to the security and reliability of machine learning models. Adversaries can manipulate the training data of a model by injecting malicious samples, leading to backdoors that cause the model to behave unexpectedly under specific conditions. These attacks are particularly concerning in the context of pre-trained models, as they can be easily disseminated and are difficult to detect. The paper explores a novel type of poisoning attack: the privacy backdoor, which amplifies the leakage of training data during subsequent fine-tuning. This attack subtly modifies the model’s weights, making it vulnerable to membership inference attacks, which reveal the presence or absence of specific data points in the training set. The authors demonstrate the effectiveness of this privacy backdoor attack across various models and datasets, highlighting its potential to compromise sensitive information. The research underscores the need for robust security measures to safeguard pre-trained models from such attacks, and calls for a careful reevaluation of safety protocols and practices in the machine learning community.
MIA Amplification#
Membership Inference Attacks (MIAs) aim to determine if a specific data point was used to train a machine learning model. A novel concept, ‘MIA Amplification,’ focuses on enhancing the effectiveness of MIAs by manipulating the model itself. This is achieved by introducing a backdoor into a pre-trained model that subtly alters the model’s behavior during fine-tuning. This backdoor makes the model more susceptible to MIAs, significantly increasing the likelihood that an attacker can correctly identify training data points. The backdoor is stealthy, meaning the model maintains its original functionality for intended use, thus evading detection. This approach highlights a serious privacy vulnerability in the widely adopted practice of fine-tuning pre-trained models and underscores the need for improved model security and safety protocols.
Model Stealth#
Model stealth, in the context of adversarial attacks against machine learning models, is a crucial aspect that determines the effectiveness and longevity of the attack. A successful attack needs to remain undetected, and model stealth focuses on ensuring that the poisoned or backdoored model behaves similarly to a clean model under normal circumstances. This is essential to avoid raising suspicion and ensuring that the victim does not identify the malicious modification. Maintaining model accuracy on legitimate tasks is paramount, as any significant performance degradation would immediately indicate a potential problem. The subtlety of the attack is also vital, with subtle alterations to the model’s parameters or weights being crucial to avoid detection through standard model inspection or anomaly detection techniques. The challenge of model stealth is substantial, and trade-offs often exist between the strength of the attack and its ability to remain undetected. Achieving high model stealth often requires careful crafting of the attack, potentially using auxiliary datasets to mitigate performance drops and sophisticated strategies to hide backdoor triggers.
Future Directions#
Future research should explore the generalizability of privacy backdoors across diverse model architectures and training paradigms. Investigating the impact of different fine-tuning methods and inference strategies on the effectiveness of the attack is crucial. Quantifying the trade-off between stealthiness and attack efficacy is also vital. Moreover, developing robust detection and mitigation techniques specifically designed to counter privacy backdoors is a high priority. This includes exploring both white-box and black-box approaches. Finally, a deeper investigation into the broader implications of privacy backdoors on data security and privacy regulations in the AI community is essential. Collaboration between researchers, practitioners, and policymakers is key to formulating effective safety protocols for mitigating these threats. The development of novel defense mechanisms that are resistant to these attacks is necessary, especially in scenarios where adversaries may have limited control over the fine-tuning process.
More visual insights#
More on figures
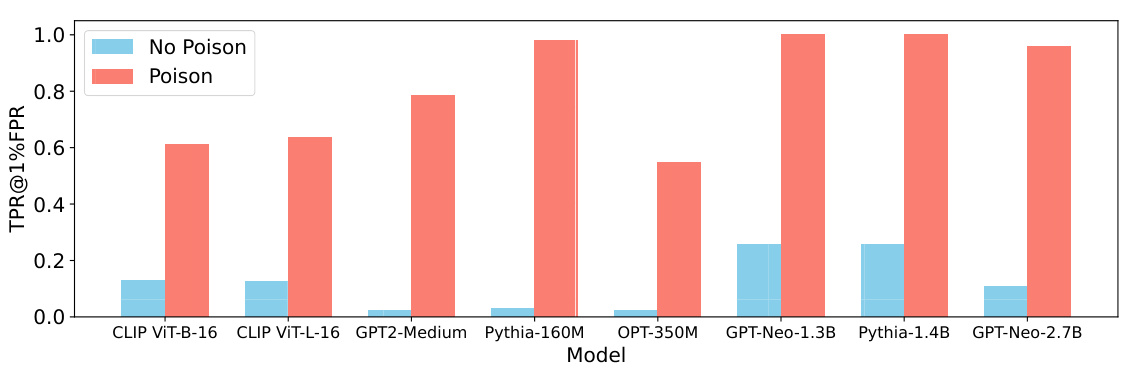
This figure presents the Receiver Operating Characteristic (ROC) curves for membership inference attacks with and without the poisoning attack. The ROC curve plots the true positive rate against the false positive rate. The figure shows that poisoning the models significantly increases the area under the curve (AUC), indicating a much higher true positive rate at a given false positive rate compared to non-poisoned models. Two different models are tested: CLIP ViT-B-32 (image classification model) and GPT-Neo-125M (language model), with different datasets (ImageNet and ai4Privacy).
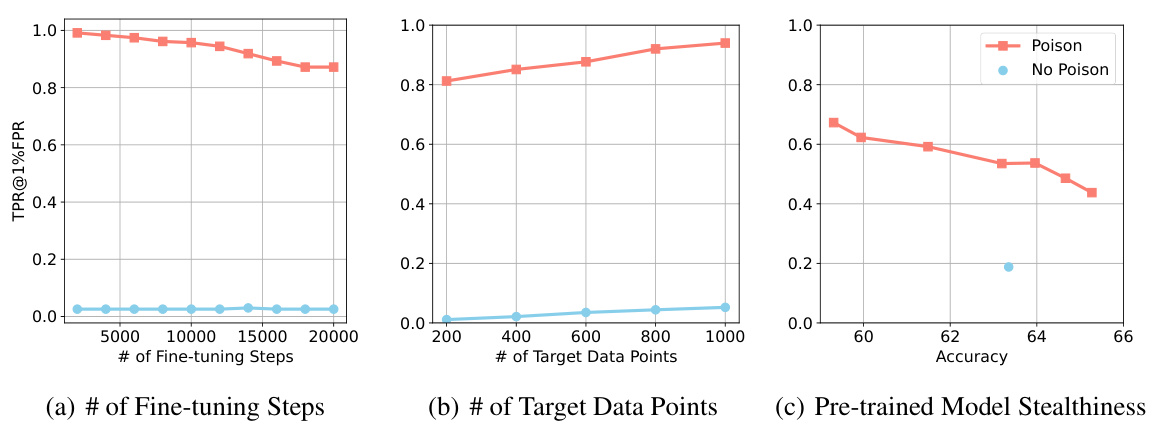
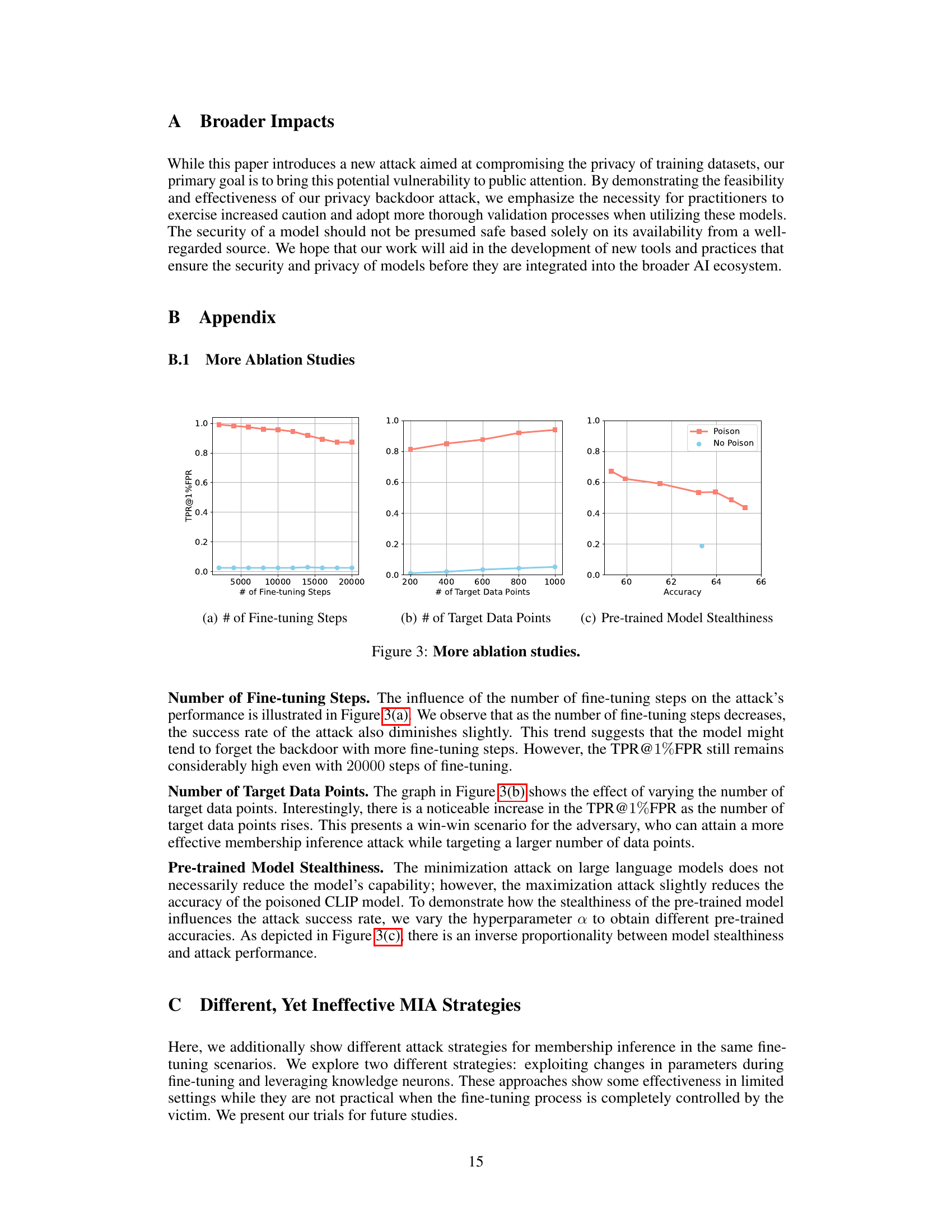
This figure presents three ablation studies on the effectiveness of the proposed attack across different experimental parameters. (a) shows the impact of the number of fine-tuning steps on the attack’s performance, demonstrating a slight decrease in success rate as the number of steps decreases. However, the TPR@1%FPR remains high even with a large number of fine-tuning steps, showing robustness of the attack. (b) illustrates how the number of target data points influences the attack success rate. As the number of target points increases, the TPR@1%FPR also increases, indicating a win-win scenario for adversaries. (c) examines the relationship between the pre-trained model’s stealthiness and the attack’s performance. It reveals an inverse proportionality: higher stealthiness (lower accuracy decrease after poisoning) leads to a lower TPR@1%FPR. This suggests a trade-off between attack effectiveness and maintaining the model’s original functionality.
More on tables
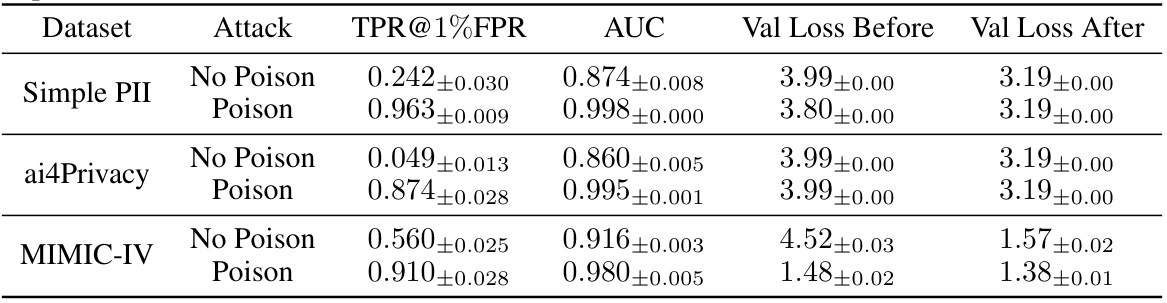
This table presents the results of a privacy backdoor attack on large language models, specifically using GPT-Neo-125M as the pre-trained model. It shows the True Positive Rate at 1% False Positive Rate (TPR@1%FPR), the Area Under the Curve (AUC), and the validation loss before and after fine-tuning for different datasets: Simple PII, ai4Privacy, and MIMIC-IV. Each dataset is evaluated under both ‘No Poison’ (no backdoor attack) and ‘Poison’ (backdoor attack) conditions. The results illustrate the significant increase in membership inference success rates (TPR@1%FPR and AUC) when using poisoned models compared to non-poisoned models across various datasets.

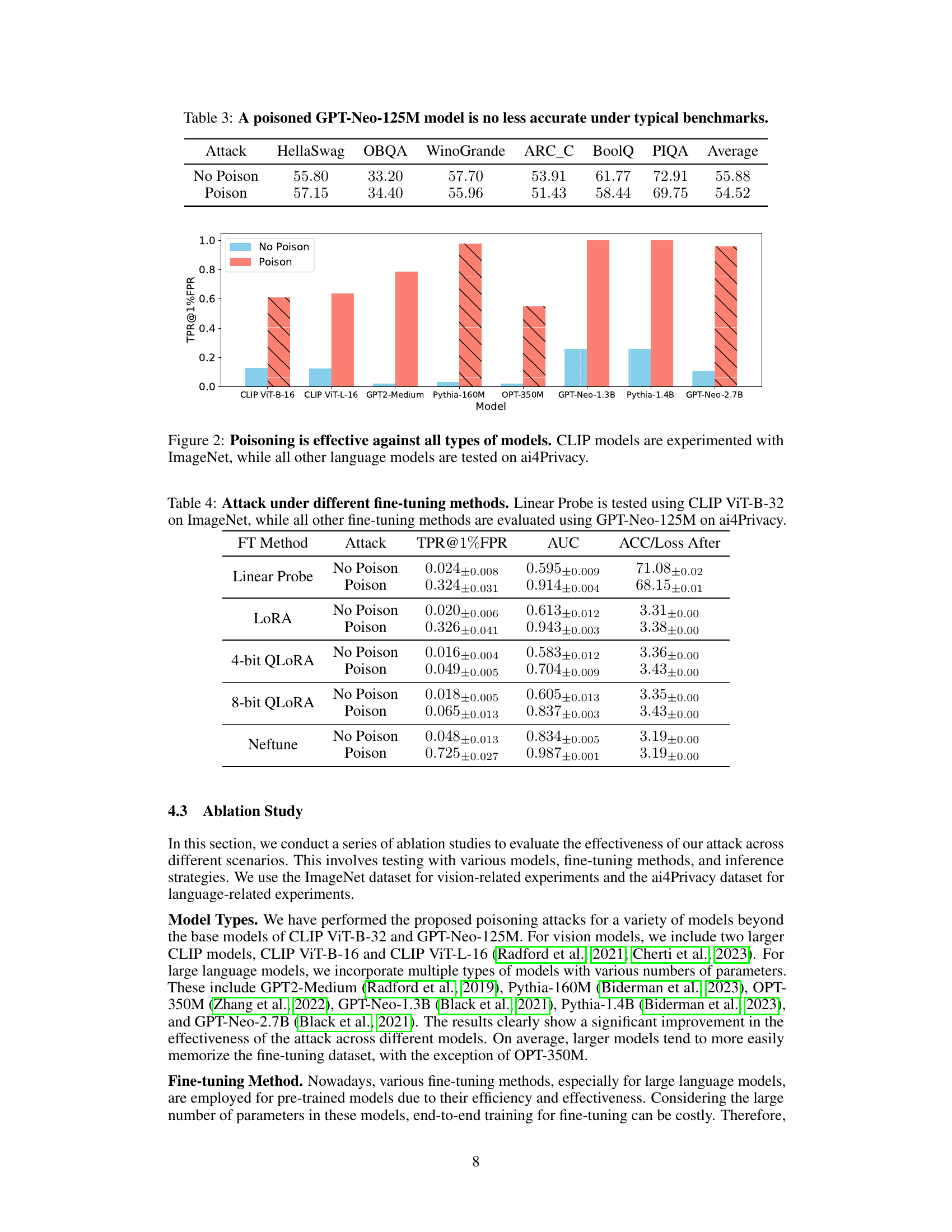
This table presents the results of evaluating a poisoned GPT-Neo-125M language model on several standard benchmarks (HellaSwag, OBQA, WinoGrande, ARC_C, BoolQ, PIQA). The purpose is to demonstrate the ‘stealthiness’ of the poisoning attack—that is, to show that the poisoned model performs comparably to a non-poisoned model on these general tasks. The table compares the performance (accuracy) of both a poisoned and non-poisoned model on each benchmark.
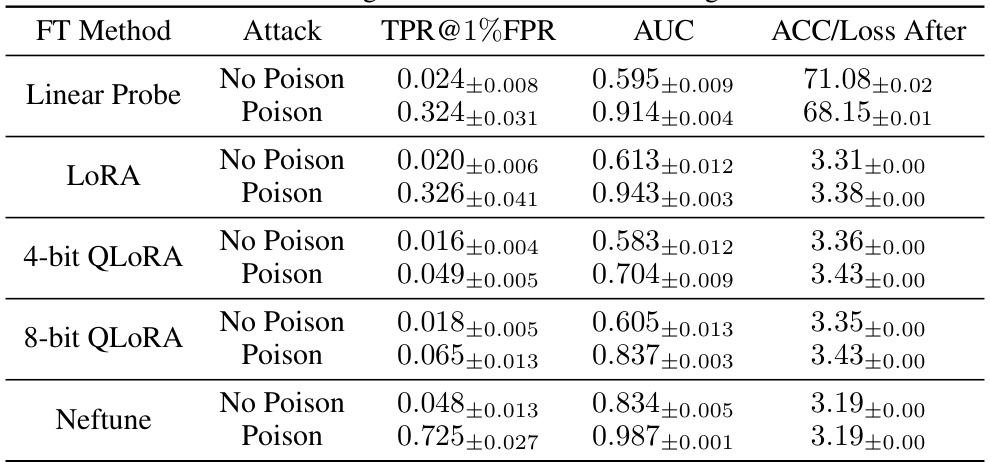
This table presents the results of the privacy backdoor attack under different fine-tuning methods. The first row shows results using Linear Probe with CLIP ViT-B-32 on ImageNet, while the rest use GPT-Neo-125M on the ai4Privacy dataset. For each method, it shows the True Positive Rate at 1% False Positive Rate (TPR@1%FPR), Area Under the Curve (AUC), and the Accuracy or Loss After fine-tuning with and without the poisoned model. The table demonstrates how the effectiveness of the attack varies depending on the fine-tuning method used.
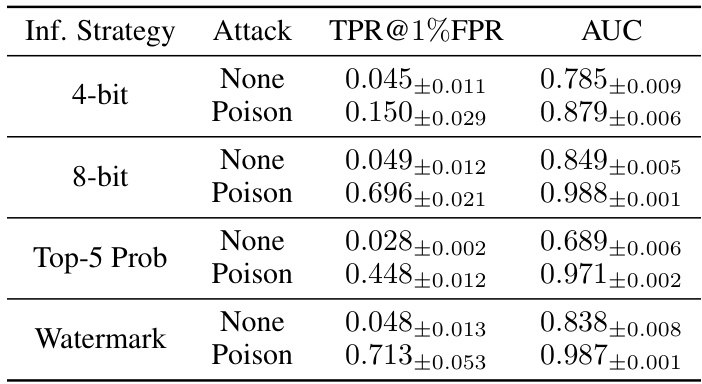
This table presents the results of the privacy backdoor attack under different inference strategies. The experiment uses GPT-Neo-125M model and ai4Privacy dataset. It shows the True Positive Rate at 1% False Positive Rate (TPR@1%FPR) and Area Under the Curve (AUC) for both the non-poisoned and poisoned models, demonstrating the effectiveness of the poisoning attack in enhancing membership inference, even under different inference strategies such as 4-bit quantization, 8-bit quantization, top-5 probabilities, and watermarking.
Full paper#