↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current diffusion models for image generation often struggle with effectively capturing both local details and global relationships within images. Existing methods like Mamba, while efficient, often have limitations in designing optimal scanning strategies for 2D image data, especially when aiming for high-quality image generation. Additionally, most approaches primarily focus on spatial information, overlooking the potential benefits of incorporating frequency domain information which is rich with long-range relationships. These limitations hinder their ability to produce high-quality and diverse images efficiently.
DiMSUM directly tackles these issues by integrating wavelet transformations to process the image data in both spatial and frequency domains. It cleverly fuses this spatial-frequency information through a cross-attention mechanism, thus improving the model’s ability to capture both local details and global context. Through extensive experimentation, the researchers demonstrate that DiMSUM significantly outperforms existing state-of-the-art methods in terms of image generation quality and training speed, opening exciting new avenues for research in efficient and high-quality image generation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image generation because it presents DiMSUM, a novel and scalable method that significantly improves the quality and efficiency of image synthesis. By cleverly combining spatial and frequency information processing, DiMSUM achieves state-of-the-art results on benchmark datasets, while also showcasing faster training convergence. This opens up exciting new avenues for research in generative models, particularly for those seeking to improve the efficiency and scalability of training high-quality generative models.
Visual Insights#

The figure provides a detailed overview of the DiMSUM architecture, illustrating the dynamic interactions between different sequential states. It showcases the input tokens, conditioning, and the core components of the DiMSUM block, including the Spatial-Frequency Mamba, Cross-Attention fusion layer, and the globally shared transformer blocks. The figure visually represents the flow of information through the network, highlighting the integration of spatial and frequency features, as well as the use of a selective mechanism to enhance the dynamic interactions of different sequential states.
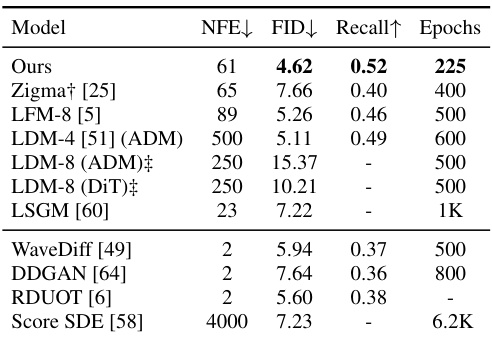
This table compares the performance of the proposed DiMSUM model against other state-of-the-art image generation models on the CelebA-HQ dataset. The metrics used for comparison are FID (Fréchet Inception Distance), Recall, and the number of forward diffusion steps (NFE). The table also includes the number of training epochs required for each model. The results demonstrate the superior performance of DiMSUM, achieving lower FID scores and higher recall rates with fewer NFEs and training epochs. Note that some results for baseline models are reproduced from the original papers.
In-depth insights#
Wavelet Mamba Fusion#
The proposed “Wavelet Mamba Fusion” method cleverly integrates wavelet transformations with the Mamba state-space model to enhance image generation. Wavelet decomposition effectively disentangles spatial and frequency information from input images, providing the Mamba model with both local structural details (high-frequency components) and global relationships (low-frequency components). This dual-input approach addresses the limitations of Mamba’s sequential processing, which often struggles with capturing long-range dependencies prevalent in frequency data. The fusion of spatial and wavelet features, likely through a sophisticated attention mechanism, allows for a more comprehensive representation of image content. This fusion is key to optimizing the order-awareness of the Mamba model, directly affecting the generation quality and detail. The enhanced inductive bias towards both local and global features, resulting from this fusion, likely contributes to superior image generation quality compared to models relying solely on spatial information. The method’s novelty lies in the synergistic combination of frequency analysis and state-space modeling, representing a significant advancement in diffusion-based image generation.
DiMSUM Architecture#
The DiMSUM architecture represents a novel approach to image generation, uniquely integrating spatial and frequency information within a state-space model framework. Unlike conventional methods that primarily focus on spatial processing, DiMSUM leverages wavelet transforms to decompose input images into frequency subbands. This allows the model to capture long-range dependencies present in the frequency spectrum, a feature often overlooked in spatial-only approaches. By seamlessly merging spatial and frequency features via a cross-attention fusion layer, DiMSUM enhances sensitivity to both local structures and global relationships, achieving a more comprehensive understanding of the input. The inclusion of globally shared transformer blocks further boosts performance by enabling efficient global context integration. This sophisticated architecture ultimately yields high-quality image outputs with faster training convergence, exceeding the performance of existing methods. The key novelty lies in the synergistic combination of spatial and frequency processing, demonstrating how wavelet features can improve Mamba-based diffusion models.
Frequency Awareness#
The concept of ‘Frequency Awareness’ in image generation models is crucial for capturing both local and global image information. Standard spatial-only approaches often struggle with long-range dependencies, limiting the model’s ability to understand the overall structure. By incorporating frequency information, such as through wavelet transforms, models gain access to a richer representation, disentangling high and low-frequency components. This allows for better disentanglement of textures and details from broader structural elements. The fusion of spatial and frequency features, often using techniques like cross-attention, is key to unlocking superior performance. High-frequency components enhance detail awareness, while low-frequency components capture the larger context and structure. This approach leads to models that can generate images with sharper details and a better overall sense of coherence, achieving a more natural and realistic outcome than those relying solely on spatial information. The effective integration of frequency awareness often leads to faster training convergence and higher-quality results. Ultimately, frequency awareness provides a more complete representation of image data, leading to significant improvements in image generation tasks.
Global Context#
The concept of ‘Global Context’ in the context of image generation models is crucial for producing coherent and realistic outputs. Effective global context integration allows the model to understand the relationships between different parts of an image, going beyond localized feature extraction. This holistic understanding is key to generating images with proper object composition and structural integrity. The paper’s proposed method, incorporating a globally-shared transformer block, addresses this challenge effectively. By sharing weights across multiple sections of the network, the transformer facilitates information flow and context aggregation across the entire image, leading to a stronger sense of global coherence. Furthermore, the global context mechanism is important in the context of image generation using frequency-based models, as it allows the network to reconcile information across different frequency bands and capture long-range frequency relationships that might otherwise be missed in spatial processing alone. The effectiveness of a globally-shared architecture in promoting global context has been demonstrated through improved results on standard benchmarks, highlighting the importance of this mechanism for improving image generation quality and training efficiency. The use of a globally-shared transformer could be considered a significant advancement, particularly compared to previous methods that relied solely on sequential or local feature processing for global context integration.
Scalable Diffusion#
Scalable diffusion models address the challenge of efficiently generating high-resolution images. Traditional diffusion models often struggle with computational costs that grow exponentially with image size, hindering scalability. Key advancements focus on improving efficiency through architectural innovations, such as using state-space models (SSMs) which offer linear time complexity compared to the quadratic complexity of transformers. Wavelet transforms are also employed to efficiently process both spatial and frequency information in images, improving the model’s ability to capture fine details and global structure. Another crucial aspect is the development of optimized training strategies which reduce the overall training time, allowing for faster iteration and improved scalability. These techniques collectively enable the generation of high-resolution images with improved quality and at a significantly reduced computational cost, making diffusion models more practical for a broader range of applications.
More visual insights#
More on figures

This figure illustrates the Wavelet Mamba architecture, a key component of the DiMSUM model. It shows how an input image is processed through multiple levels of wavelet decomposition, resulting in wavelet subbands representing different frequency components. These subbands are then processed using a windowed scanning approach within each subband, which combines spatial and frequency information. The figure visually demonstrates the process, highlighting the decomposition into wavelet subbands and the subsequent window-based scanning.
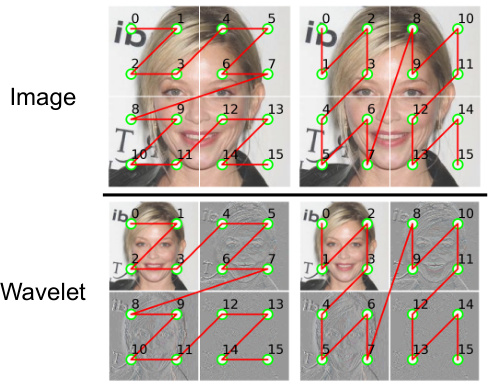
This figure illustrates the Wavelet Mamba, a key component of the DiMSUM architecture. It shows how an input image is decomposed into wavelet subbands using a two-level Haar wavelet transform. The image is then processed by the Wavelet Mamba module, which uses a sliding window across wavelet subbands to capture spatial and frequency information. The green dots highlight the scanning path, showing how the window moves across the different wavelet levels and subbands to capture local and long-range dependencies.

This figure presents a comparison of the proposed DiMSUM model’s performance against other state-of-the-art models on the CelebA-HQ dataset. The comparison includes quantitative metrics (NFE, FID, Recall, Epochs) and qualitative results (sample images). The results demonstrate DiMSUM’s superior performance in terms of both FID and recall, while also showcasing faster training convergence compared to the other models.

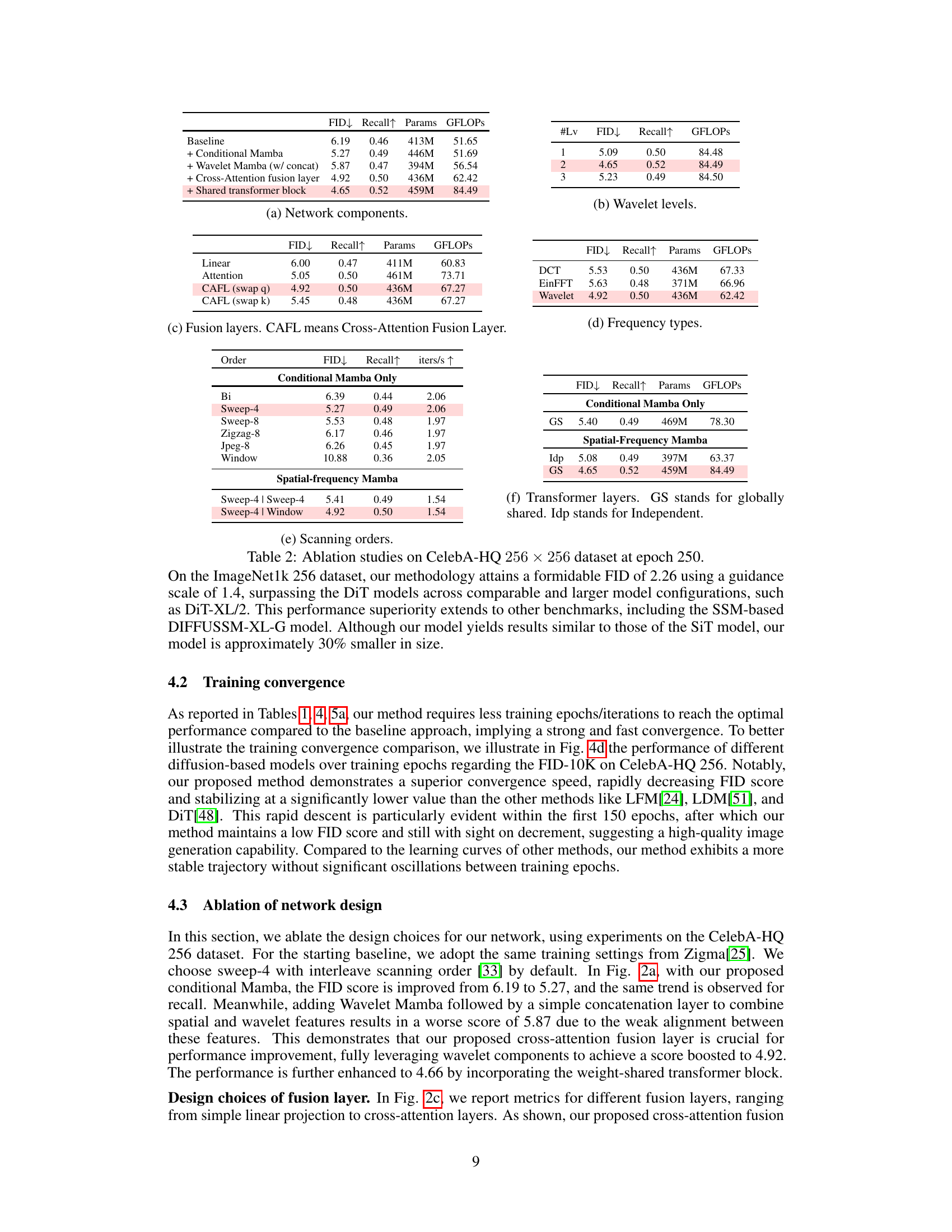
This figure shows the training curve of the DiT model on the CelebA dataset when trained for a longer duration, providing further support to the findings presented in Figure 4d. It specifically illustrates the model’s convergence speed and stability over a larger number of training epochs, highlighting the comparison between DiT and the proposed DiMSUM model in terms of training efficiency.

This figure presents a comparison of the proposed DiMSUM model with other state-of-the-art models on the CelebA-HQ dataset. It shows quantitative results (FID and Recall scores) and qualitative results (sample images generated by each model). The quantitative results demonstrate the superior performance of DiMSUM compared to the other methods. The qualitative results provide a visual comparison of image quality and diversity.
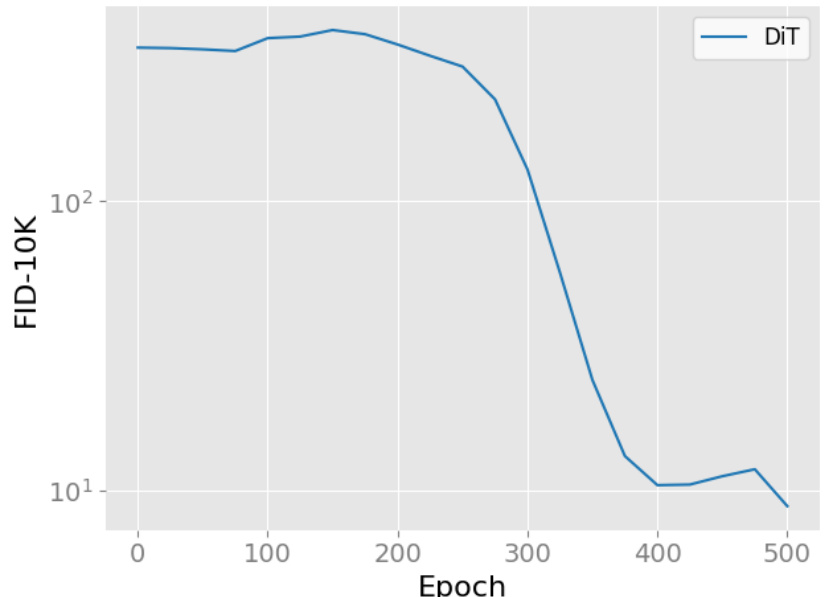
This figure shows the training curve of the DiT model trained on the CelebA dataset for a longer duration than shown in Figure 4d. It demonstrates that DiT’s performance initially improves and then plateaus or even slightly degrades after a certain point, highlighting the faster convergence achieved by the DiMSUM model proposed in the paper.

This figure shows the FID-10K scores obtained using different numbers of function evaluations (NFEs) on the CelebA-HQ 256 dataset. Two different sampling methods, Heun and Euler, were used. The plot illustrates that increasing NFEs beyond a certain point (around 250 in this case) yields minimal improvement in FID-10K scores, demonstrating the efficiency of the flow-matching approach used in the DiMSUM model.
This figure illustrates the Wavelet Mamba module, a key component of the DiMSUM architecture. It shows how an input image is decomposed into wavelet subbands at multiple levels (here, two levels are shown). Each subband is then processed using a windowed scanning method, similar to a convolutional kernel, to capture both local and global features from the frequency domain. This process is different from the traditional spatial scanning methods used in other Mamba models and it is designed to better capture both local and global information within the image.

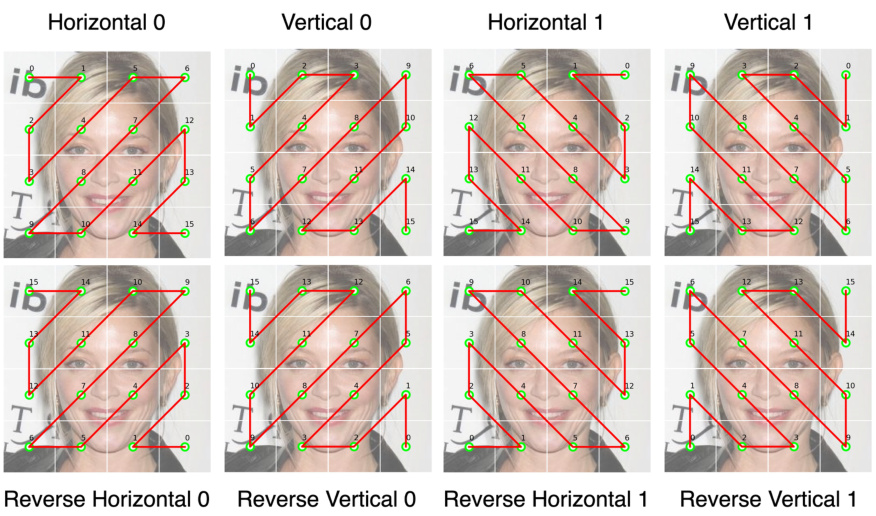
This figure illustrates different scanning orders used in the Wavelet Mamba component of the DiMSUM model. It shows how the input image’s features are processed in various patterns, including bidirectional, Sweep-4, and Sweep-8 methods. Each method involves scanning the image horizontally and vertically, and in reverse directions. The different scanning orders aim to capture diverse local and global relationships between features. Understanding these different scanning methods is crucial to grasp how DiMSUM leverages spatial information at multiple scales and how effectively it fuses this with the frequency data obtained from the wavelet transform.

This figure displays 48 samples of images generated by the DiMSUM model. The images are 256x256 pixels and depict faces. The samples are uncurated, meaning they were not selected or filtered in any way to show only the best results but rather to give a representative sample of the model’s output. This helps to demonstrate the model’s ability to generate diverse and realistic-looking faces.

The figure provides a comprehensive overview of the DiMSUM architecture, illustrating the interconnected components and their workflow. It details how spatial and frequency features from the input image are processed through wavelet transforms and multiple Mamba blocks. These features are then fused using a cross-attention fusion layer, combining spatial and frequency information. A globally-shared transformer block is incorporated to capture global relationships, enhancing the overall image generation quality. The figure clearly shows the sequence of steps, from input processing to output generation, showcasing the innovative integration of Mamba, wavelet transforms, and transformers.

This figure displays twelve examples of high-resolution (512x512 pixels) facial images generated by the DiMSUM model. These images are presented as a demonstration of the model’s ability to generate high-quality and diverse facial images. The diversity is apparent in the different hairstyles, ages, ethnicities, and expressions among the generated faces. The high quality is evident in the fine details, such as individual strands of hair and subtle textural variations in skin tone.

This figure illustrates the Wavelet Mamba module, a key component of the DiMSUM architecture. It shows how an input image is decomposed into wavelet subbands at multiple levels (in this example, 2 levels are shown). Each subband is then processed using a windowed scanning approach, which is analogous to using a convolutional kernel. The green dots represent pixels, and the 2x2 windows show the way the network extracts features from the wavelet subbands by scanning.

This figure provides a detailed overview of the DiMSUM architecture. It illustrates the different components of the model, including the state space model (SSM), wavelet transform, cross-attention fusion layer, and globally shared transformer blocks. The figure also shows how these components interact with each other to generate high-quality images. The flow of image data through the network is clearly depicted, showing how spatial and frequency information are integrated to improve image generation. It provides a comprehensive visual summary of the method’s key aspects.

This figure illustrates the Wavelet Mamba, a core component of the DiMSUM architecture. It shows how an input image is decomposed into wavelet subbands at multiple levels, representing different frequency components. The process mimics a CNN kernel, scanning across subbands to extract features.

The figure shows the architecture of DiMSUM, a novel architecture for diffusion models that integrates spatial and frequency information using wavelet transforms and a cross-attention fusion layer. The architecture consists of multiple DiMSUM blocks, each containing DiM blocks that employ a novel Spatial-Frequency Mamba fusion technique, and globally shared transformer blocks for global context integration. The DiMSUM block receives input tokens and conditions, and processes them using the wavelet transform and Mamba blocks to produce spatial and frequency features. These features are fused using a cross-attention fusion layer, and the resulting features are passed through a globally shared transformer block before being decoded to output tokens.

This figure provides a high-level overview of the DiMSUM architecture, showing the main components and their interactions. It illustrates the flow of data through the model, highlighting the use of Spatial-frequency Mamba, cross-attention fusion layer, and globally shared transformer blocks. The diagram visually represents the integration of spatial and frequency information to enhance image generation.

The figure provides a detailed overview of the DiMSUM architecture, illustrating the dynamic interactions between different sequential states and the fusion of spatial and frequency features through cross-attention mechanisms. It shows the input processing, wavelet transformation, spatial and frequency Mamba blocks, cross-attention fusion, and global transformer integration. The figure highlights the key components of the DiMSUM model, including the state-space model, wavelet transform, and cross-attention, and how they work together to generate high-quality images.

The figure shows the overall architecture of DiMSUM, a novel architecture for diffusion models that integrates spatial and frequency information. It highlights the key components, including the Spatial-Frequency Mamba, Cross-Attention fusion layer, and globally shared transformer block. The diagram illustrates the flow of information through the network, from the input image to the final generated image, showcasing the interplay between spatial and frequency features.

This figure illustrates the Wavelet Mamba method used in the DiMSUM model. It demonstrates how an input image (8x8 pixels) is decomposed into wavelet subbands (4x4, then 2x2). A scanning window moves across these subbands, processing the wavelet features. This contrasts with the standard spatial Mamba method, enhancing local structure awareness and capturing frequency information.
More on tables
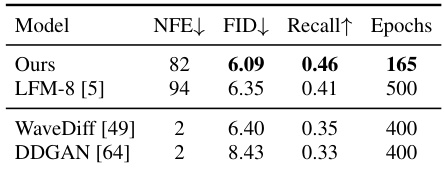
This table compares the performance of the proposed DiMSUM model against several other state-of-the-art models on the CelebA-HQ dataset. The metrics used for comparison are FID (Fréchet Inception Distance), Recall, and the number of function evaluations (NFEs). The table shows that DiMSUM achieves superior performance compared to the other methods in terms of FID and Recall, while also requiring fewer function evaluations. The table also includes epochs used for training to show the comparison in training efficiency.
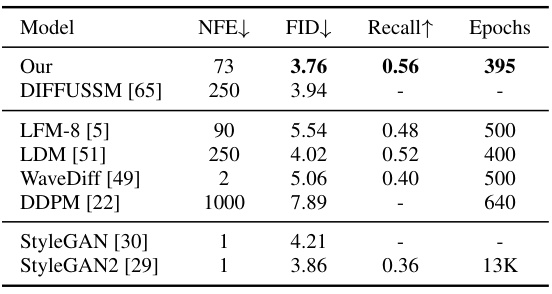
This table presents a comparison of the proposed DiMSUM model’s performance against several other image generation models on the LSUN Church dataset, specifically focusing on the Fréchet Inception Distance (FID) and Recall metrics. The number of network function evaluations (NFE) required and the training epochs are also included for a complete comparison.
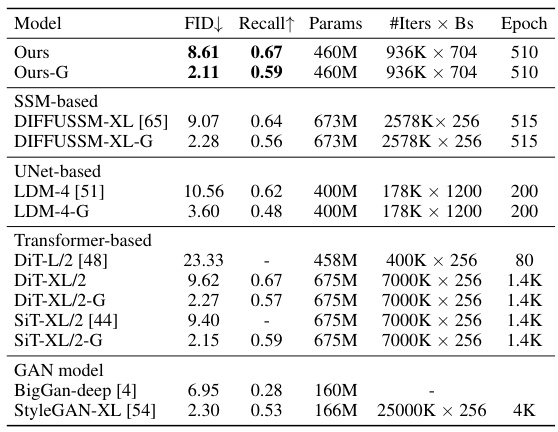
This table presents a comparison of different models’ performance on class-conditional image generation on the ImageNet 256x256 dataset. Metrics include FID (Fréchet Inception Distance), Recall, the number of parameters, the number of iterations multiplied by batch size, and the number of epochs. Models are categorized into SSM-based, UNet-based, Transformer-based, and GAN models to facilitate comparison of different architectural approaches.
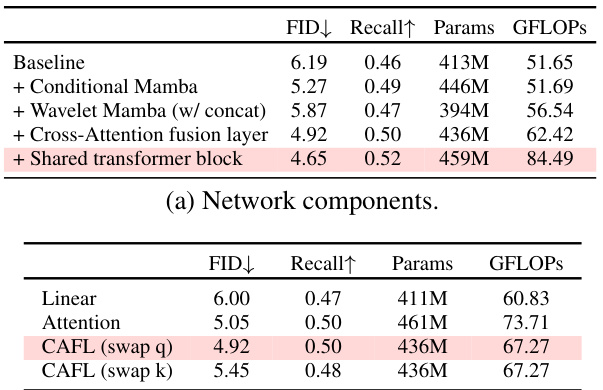
This table presents the ablation study results performed on the CelebA-HQ dataset at epoch 250 with image size of 256 x 256. It shows the impact of different components on the FID and Recall metrics, allowing for a detailed analysis of the contribution of each component (Conditional Mamba, Wavelet Mamba, Cross-Attention Fusion Layer, Shared Transformer Block) to the overall performance. The table also compares different scanning orders (Bi, Sweep-4, Sweep-8, Zigzag-8, Jpeg-8) and fusion layer types (Linear, Attention, CAFL (swap q), CAFL (swap k)) to determine their effectiveness. The results highlight the importance of the proposed Spatial-Frequency Mamba architecture and the cross-attention fusion layer.
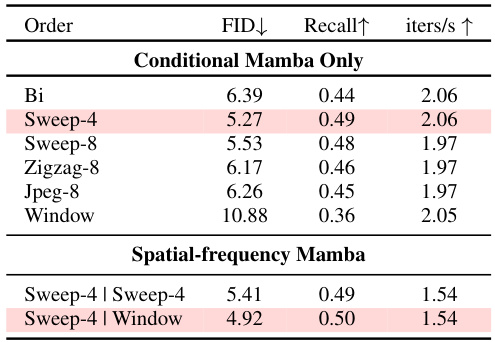
This ablation study analyzes the impact of different scanning orders (Bi, Sweep-4, Sweep-8, Zigzag-8, Jpeg-8, Window) on the performance of the Conditional Mamba model and the Spatial-frequency Mamba model. The table compares the FID score (Fréchet Inception Distance, lower is better), Recall (higher is better), and iterations per second (iters/s, higher is better) for each scanning order. The results show that Sweep-4 is the best performing order for Conditional Mamba, while Sweep-4 combined with Window scanning provides the best performance for the Spatial-frequency Mamba architecture.
This ablation study analyzes the impact of different components of the DiMSUM model on its performance, specifically focusing on the CelebA-HQ dataset. The results are evaluated at epoch 250, showing the FID and Recall scores for different model configurations. The configurations tested include using only Conditional Mamba, adding Wavelet Mamba with different fusion methods (concatenation versus cross-attention), incorporating a shared transformer block, and using different scanning orders in spatial and frequency domains. The analysis aims to determine the relative contributions of each component and to identify the optimal architecture.
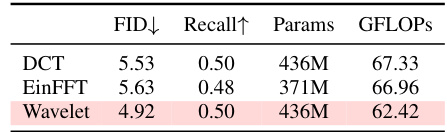
This ablation study on the CelebA-HQ dataset compares the performance of different frequency transformation methods (DCT, EinFFT, and Wavelet) used within the DiMSUM model. The results are evaluated based on FID (Fréchet Inception Distance), Recall, the number of parameters used, and GFLOPs (billion floating-point operations per second). The table helps to determine the optimal frequency transformation technique for DiMSUM.

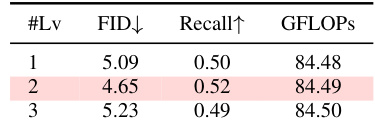
This ablation study on the CelebA-HQ dataset (256x256 resolution) at epoch 250 analyzes the impact of different components on model performance. It compares the FID and Recall scores for different model variations: ‘Conditional Mamba Only’ (with and without a globally shared transformer layer) and ‘Spatial-Frequency Mamba’ (with independent and globally shared transformer layers). The results showcase the improvement achieved by incorporating the Spatial-Frequency Mamba and the globally shared transformer block.
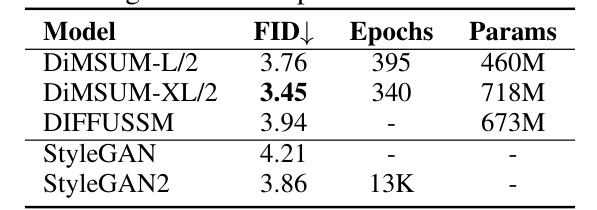
This table demonstrates the scalability of the DiMSUM model by showing the FID scores, training epochs, and model parameters for different model sizes (DIMSUM-L/2 and DIMSUM-XL/2) on the LSUN Church dataset. It also includes results from baseline models (DIFFUSSM, StyleGAN, and StyleGAN2) for comparison. The results highlight the model’s ability to achieve state-of-the-art performance with a reasonable number of parameters and training epochs.

This table compares the speed (time) and computational cost (GFLOPs) of the proposed DiMSUM model and the baseline DiT model for image generation tasks. The comparison is done for two different image resolutions (256x256 and 512x512 pixels), showing the model’s performance and scalability at different scales. Memory usage (MEM) and model parameters (Params) are also listed. The results reveal the efficiency of DiMSUM, particularly its ability to maintain reasonable speed even when generating higher-resolution images.

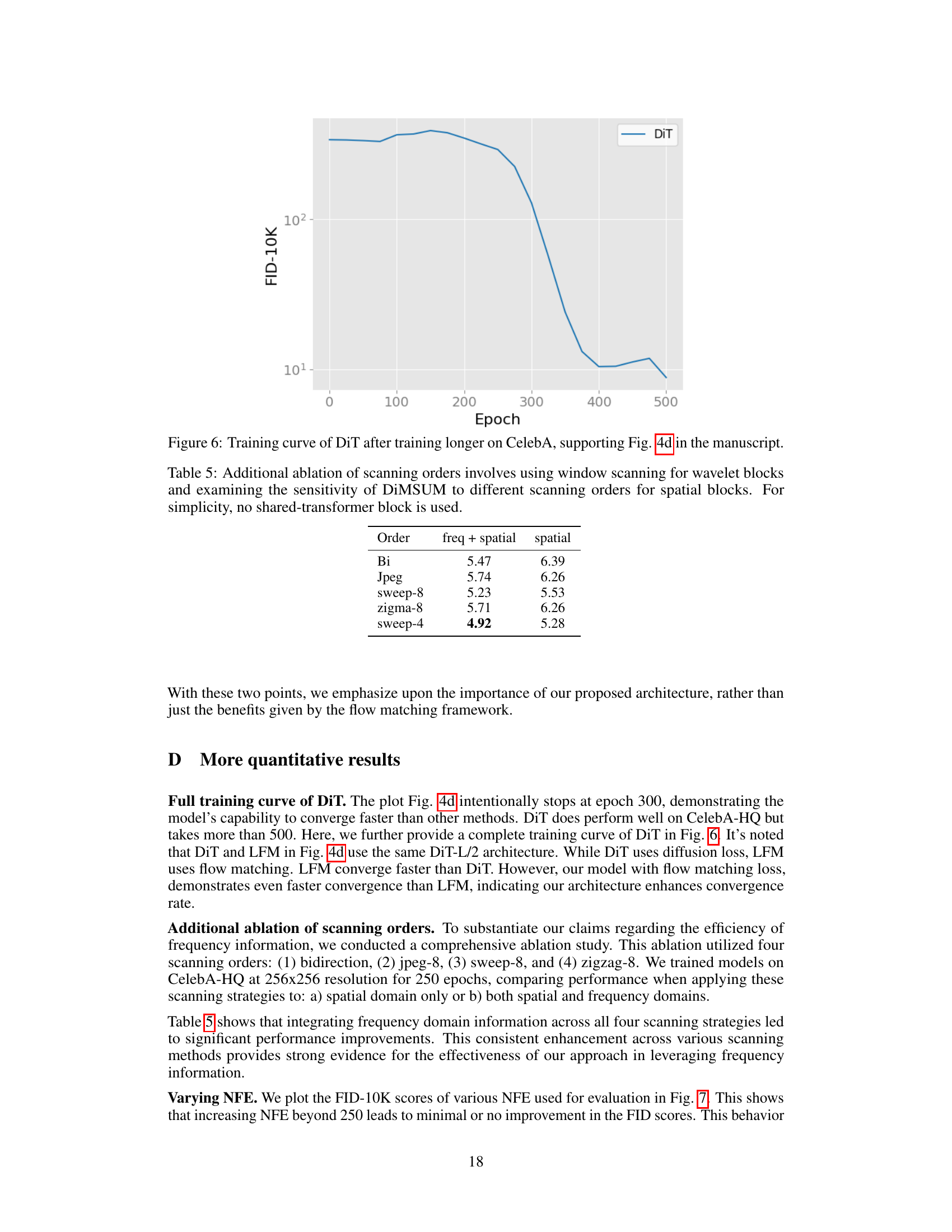
This table presents an ablation study on the effect of different scanning orders on the DiMSUM model’s performance. It compares the model’s FID scores when using various scanning orders (Bi, Jpeg, sweep-8, zigma-8, and sweep-4) for both spatial and frequency components. The results show that the combination of window scanning for wavelet blocks and sweep-4 for spatial blocks (freq + spatial) achieves the best FID score (4.92), indicating the effectiveness of integrating frequency information with a specific spatial scanning order for improved model performance. The experiment was conducted without using the shared transformer block to better isolate the effect of scanning strategies.
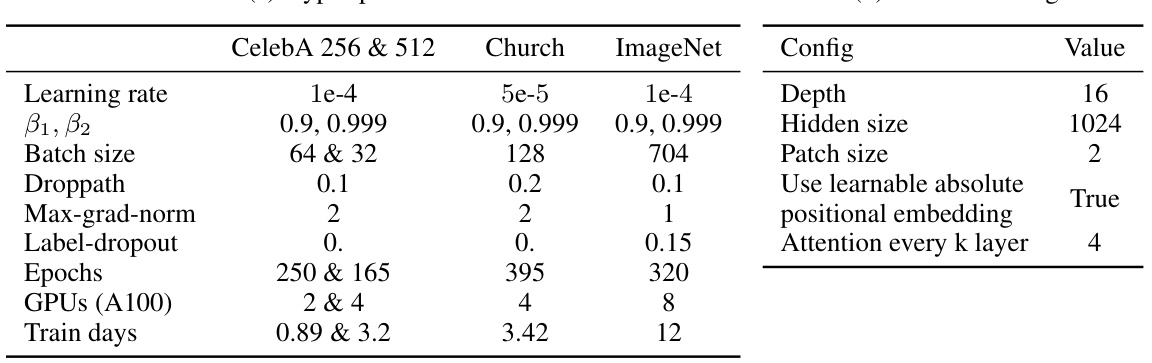
This table shows the hyperparameters and network configuration details used for training the DiMSUM model on three different datasets: CelebA-HQ 256 & 512, LSUN Church, and ImageNet. The hyperparameters include learning rate, beta1 and beta2 parameters for Adam optimizer, batch size, droppath rate, maximum gradient norm, label dropout rate, and the number of epochs trained for each dataset. The network configuration details include the depth of the network, hidden size, patch size, whether learnable absolute positional embedding is used, the attention layer’s interval (every k layers), the number of GPUs used for training, and the total training time in days. The different configurations for each dataset are specified to account for the varying dataset sizes and complexities.
Full paper#