↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Integrating machine learning (ML) into statistical inference accelerates scientific discovery but current methods struggle with complex tasks. Existing methods require task-specific derivations and software, limiting their scope and hindering widespread use. The lack of methods also makes it difficult to integrate with existing statistical software tools.
This paper introduces PSPS, a post-prediction summary-statistics-based inference protocol. PSPS is task-agnostic, using existing analysis routines to generate summary statistics sufficient for inference. This approach guarantees valid and efficient inference regardless of the ML model. Its simplicity and broad applicability make it highly accessible to researchers across various fields, and it opens new avenues for federated data analysis due to its ability to function with only summary statistics.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers employing machine learning in scientific inference. It offers a task-agnostic framework (PSPS), overcoming limitations of existing methods which are confined to basic tasks. This expands the applicability of ML-assisted inference across diverse fields and encourages further research on improving its computational efficiency and broadening its theoretical foundation.
Visual Insights#

This figure illustrates the three-step workflow of the Post-Prediction Summary-statistics-based (PSPS) inference method. In Step 1, a pre-trained machine learning (ML) model predicts outcomes for both labeled and unlabeled data. Step 2 involves applying standard analysis routines to obtain summary statistics from the labeled data with observed outcomes, labeled data with predicted outcomes, and unlabeled data with predicted outcomes. Finally, Step 3 uses a one-step debiasing technique on these summary statistics to produce valid and efficient ML-assisted inference results.

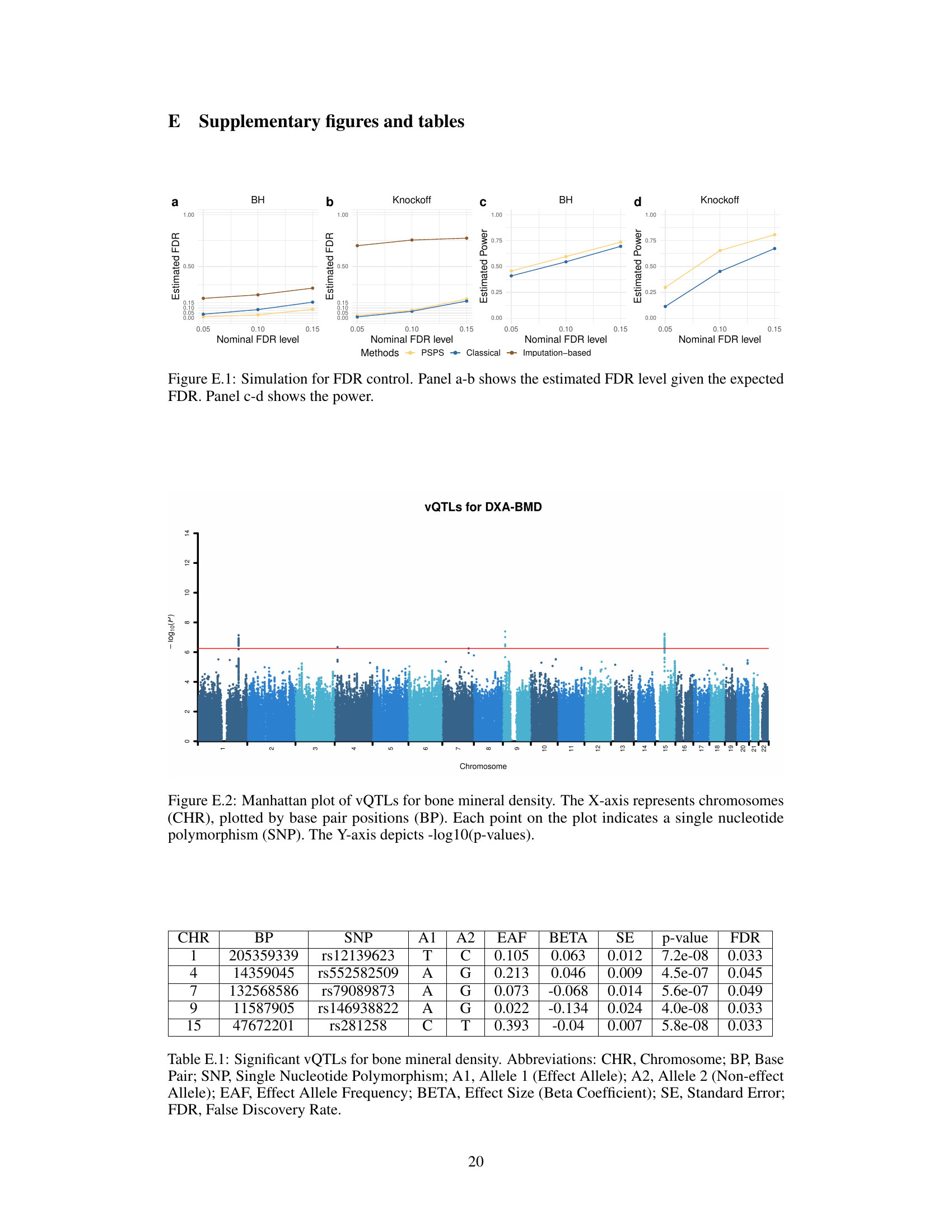
This table presents the results of identifying significant genetic variants (vQTLs) associated with bone mineral density variability using the PSPS method. The table lists the chromosome (CHR), base pair position (BP), SNP identifier (SNP), alleles (A1, A2), effect allele frequency (EAF), effect size (BETA), standard error (SE), p-value, and false discovery rate (FDR) for each significant vQTL.
In-depth insights#
ML Inference Scope#
The scope of machine learning (ML) inference is a crucial aspect of leveraging ML in scientific research. Traditional statistical methods often struggle with the complexities of high-dimensional data and non-linear relationships, which ML excels at handling. However, simply using ML predictions in downstream statistical analyses can lead to invalid results if the inherent uncertainties of the ML model are not properly accounted for. Therefore, methodologies for valid ML-assisted inference are essential, focusing on techniques that accurately quantify and incorporate ML prediction uncertainty. The ideal methods should be task-agnostic, easily adaptable to diverse statistical procedures without requiring extensive task-specific derivations and software implementations. Robustness to model misspecification is also key, ensuring the validity of inferences even when the ML model doesn’t perfectly capture the underlying data-generating process. Finally, an emphasis on computational efficiency is vital for practical applications, as the goal is to accelerate scientific discovery, not hinder it through computationally expensive approaches.
PSPS Protocol#
The PSPS protocol offers a novel, task-agnostic approach to integrating machine learning (ML) predictions into downstream statistical inference. Its strength lies in its simplicity and universality, requiring only summary statistics from existing analyses rather than complex, task-specific derivations. This makes it readily adaptable to diverse statistical tasks, unlike previous methods. Robustness to various ML model choices is another key advantage, expanding the range of applicable ML models. The protocol’s theoretical underpinnings guarantee validity and efficiency, inheriting strengths from established ML-assisted inference techniques while avoiding their limitations. Federated data analysis becomes possible through the use of summary statistics, opening collaboration avenues while preserving privacy. Overall, PSPS is a significant advancement, providing a flexible and powerful framework for harnessing the potential of ML within scientific research.
Theoretical Guarantees#
The section on “Theoretical Guarantees” would ideally delve into the mathematical underpinnings of the proposed method, providing rigorous proofs and establishing its reliability. Key aspects to explore include consistency (does the method converge to the true value as sample size increases?), asymptotic normality (does the estimator’s distribution approach a normal distribution for large samples, facilitating inference?), and efficiency (is the method optimal or near-optimal compared to existing alternatives?). A crucial point would be demonstrating the method’s robustness to mis-specification of the machine learning (ML) model, a common challenge in practice. The theorems presented should clearly outline assumptions made (e.g., data distribution, ML model properties), and proofs should be mathematically sound and detailed. Furthermore, the analysis should address the impact of various factors, such as the amount of labeled and unlabeled data, on the method’s performance. Finally, a discussion of any limitations of the theoretical guarantees in relation to practical settings would add significant value. Strong theoretical backing is essential to establishing confidence in the method’s applicability and reliability.
Empirical Validations#
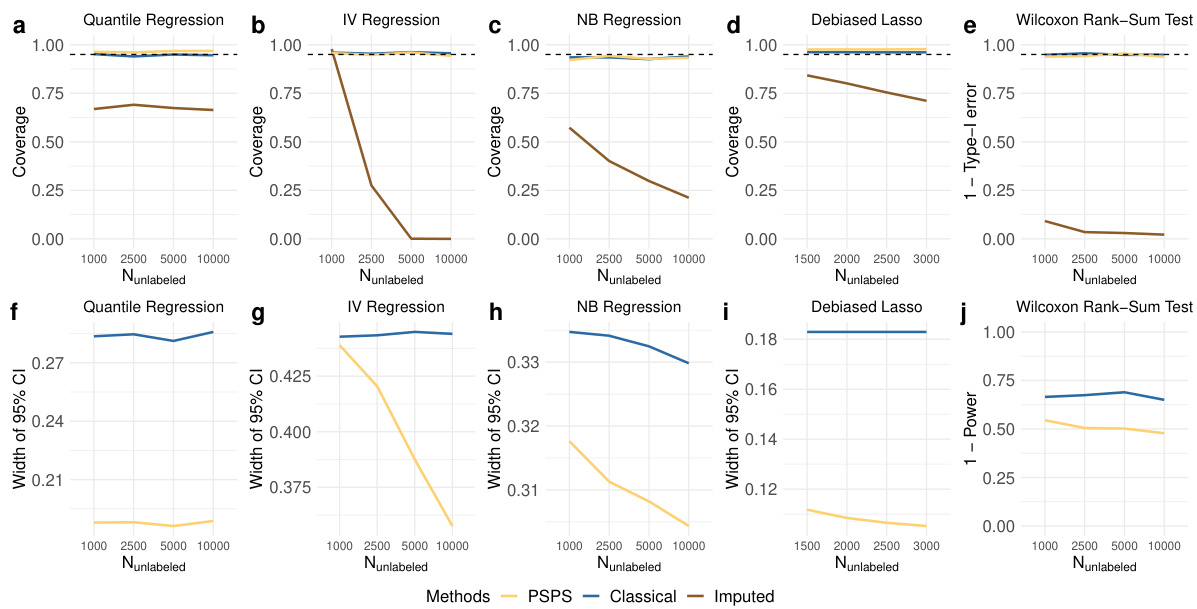
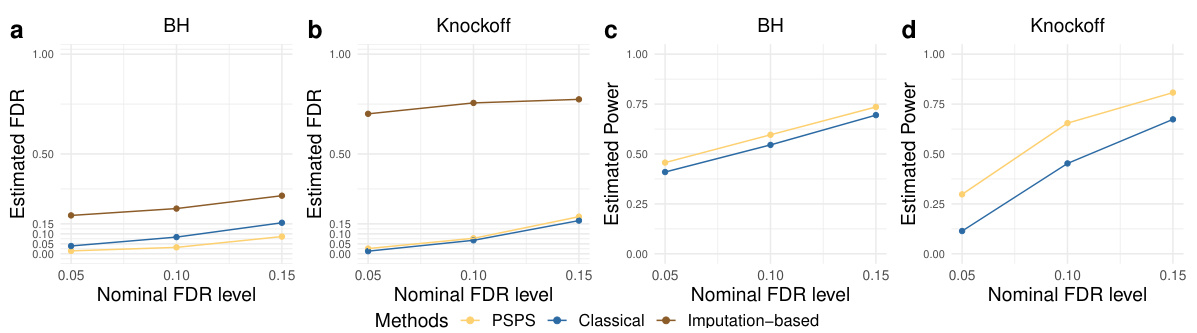
The section on “Empirical Validations” would ideally present a robust evaluation of the proposed task-agnostic ML-assisted inference framework (PSPS). This should go beyond simple demonstrations and delve into a thorough assessment of PSPS’s performance across diverse scenarios. Key aspects would include comparisons with existing ML-assisted methods, analyses under various data conditions (e.g., different sample sizes, noise levels, model misspecification), and explorations of the method’s scalability and computational efficiency. The evaluation should cover a broad range of statistical tasks, extending beyond the basic examples to show its true task-agnostic nature. Rigorous statistical testing (p-values, confidence intervals) is crucial to support claims of improved accuracy and efficiency. Ideally, the validations would involve both simulated and real-world data, ensuring a comprehensive evaluation and strong evidence for PSPS’s practical applicability. Finally, the results should be presented clearly and concisely, using visualizations like plots and tables to facilitate understanding and interpretation. A discussion of limitations and potential areas for future research would further strengthen the section’s value.
Future Directions#
The paper’s core contribution is a novel framework for task-agnostic machine learning (ML)-assisted inference. Future work should focus on improving computational efficiency, perhaps through the development of fast resampling algorithms or exploring alternative debiasing techniques that reduce computational burden. Extending the framework’s applicability to other statistical tasks beyond those explored in this paper, such as survival analysis and time series analysis, is also crucial for broadening its impact. Furthermore, rigorous investigation into the method’s performance with different types of ML models and various levels of label noise would enhance its robustness and reliability. Finally, developing user-friendly software that integrates the method with existing statistical packages is vital for broader adoption and real-world applicability.
More visual insights#
More on figures

The figure illustrates the workflow of the Post-Prediction Summary-statistics-based (PSPS) inference method for task-agnostic machine learning (ML)-assisted inference. It shows a three-step process: (1) using a pre-trained ML model to predict outcomes for both labeled and unlabeled data; (2) applying existing analysis routines (like linear regression, logistic regression, etc.) to the labeled and unlabeled data (with predicted outcomes) to obtain summary statistics; and (3) employing a one-step debiasing procedure to combine these summary statistics and produce statistically valid ML-assisted inference results.
This figure shows the workflow of the proposed method, PSPS, for task-agnostic ML-assisted inference. It consists of three main steps: (1) using a pre-trained ML model to predict outcomes for both labeled and unlabeled data; (2) applying existing analysis routines to generate summary statistics from the labeled and unlabeled data; (3) employing a one-step debiasing procedure to produce statistically valid results using the summary statistics. The figure visually depicts the flow of data and the key steps involved in the PSPS protocol. This diagram helps in understanding the task-agnostic nature of the method, highlighting its ability to incorporate various existing analysis routines.
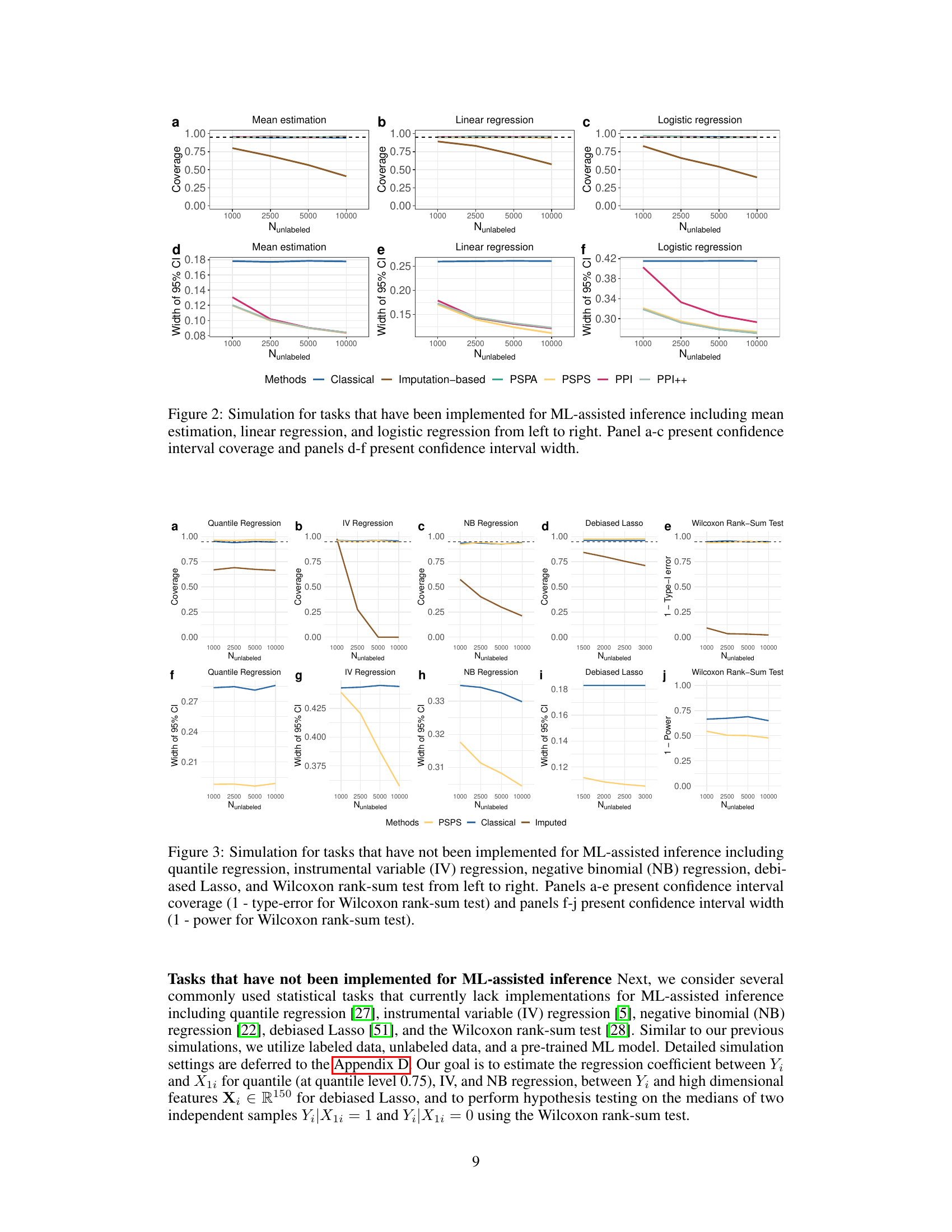
This figure presents simulation results comparing different methods for ML-assisted inference on tasks already established in existing literature: mean estimation, linear regression, and logistic regression. Panels (a-c) illustrate the coverage of 95% confidence intervals, indicating whether the true parameter value falls within the calculated interval at the nominal 95% rate. Panels (d-f) display the width of the 95% confidence intervals for each method, showing the precision of the estimates. The results show that PSPS provides better coverage and narrower intervals than other methods, indicating superior performance.
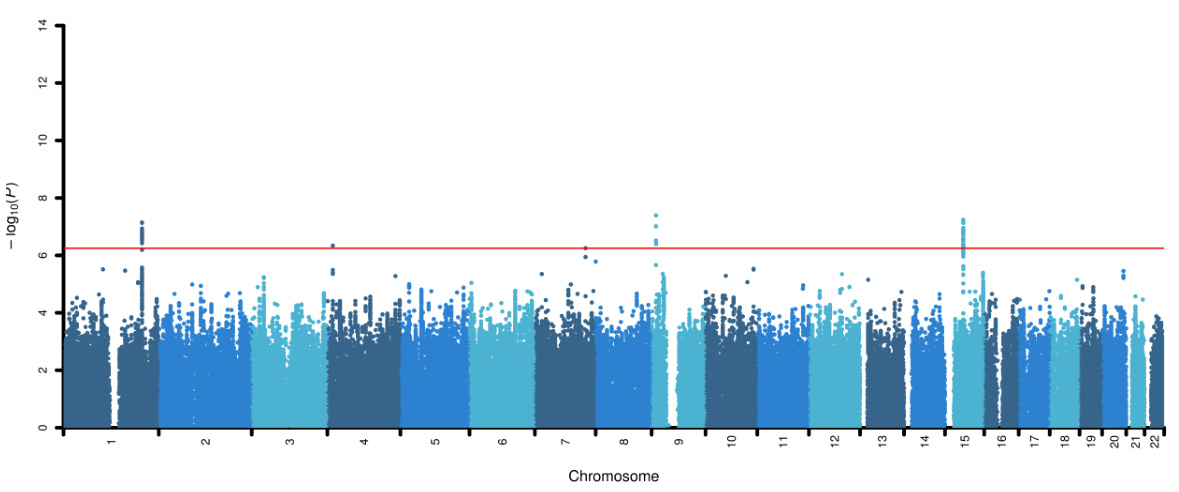
This Manhattan plot visualizes the results of a genome-wide association study (GWAS) to identify genetic variants associated with the variability (vQTLs) of bone mineral density (BMD). The x-axis represents the chromosome, and the y-axis shows the negative logarithm of the p-values for each single nucleotide polymorphism (SNP). Points above the red horizontal line indicate statistically significant associations, revealing specific genomic regions influencing BMD variability.
Full paper#