TL;DR#
Large language models (LLMs) excel at generating code for popular programming languages but struggle with very low-resource programming languages (VLPLs) due to limited training data. VLPLs are crucial in domains like formal verification and internal tooling. Existing techniques like prompting and fine-tuning are often insufficient for VLPLs, highlighting the need for novel approaches.
This paper introduces SPEAC, a new technique that leverages synthetic programming elicitation. SPEAC uses an intermediate language familiar to LLMs, which is then automatically compiled to the target VLPL. When the LLM generates code outside this intermediate language, compiler techniques automatically repair it. The authors evaluate SPEAC on UCLID5, a formal verification language, demonstrating a significant improvement in syntactically correct program generation compared to baseline methods, without sacrificing semantic correctness.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with low-resource programming languages (VLPLs) and large language models (LLMs). It directly addresses the challenge of generating syntactically correct VLPL code using LLMs, a significant hurdle in many domains. The proposed SPEAC approach offers a novel solution, paving the way for wider application of LLMs in VLPL-related tasks and potentially unlocking new research avenues in program synthesis and verification.
Visual Insights#

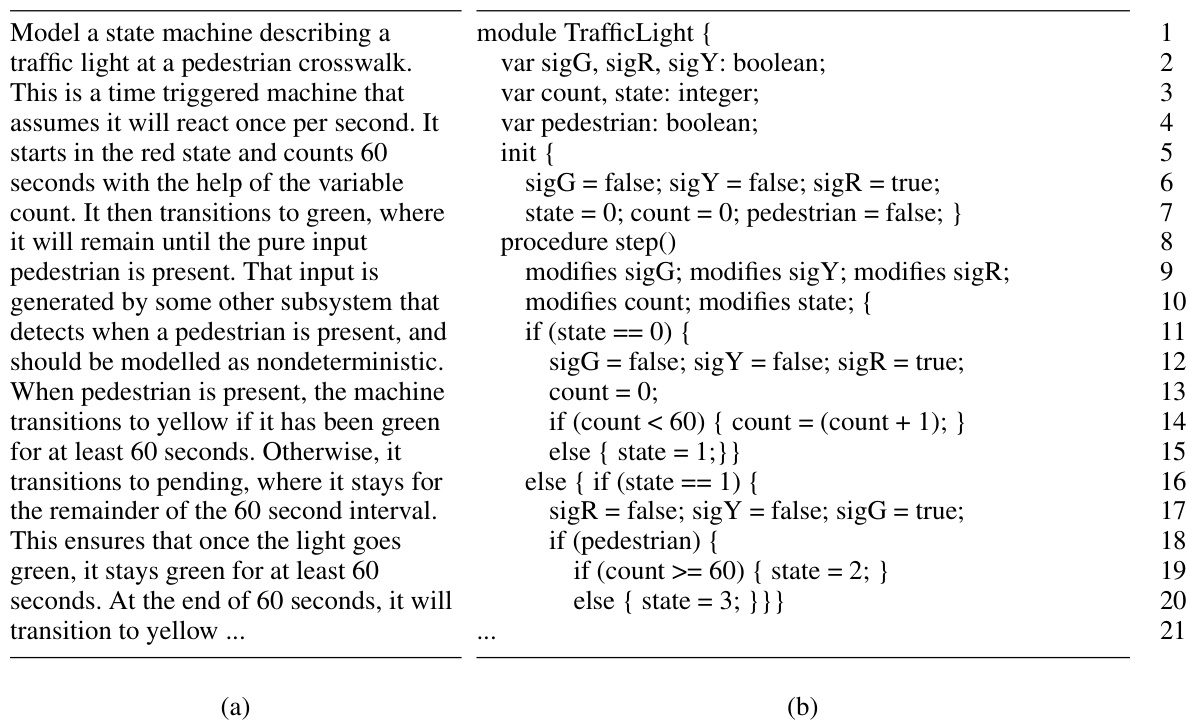
🔼 This figure illustrates the workflow of the Synthetic Programming Elicitation and Compilation (SPEAC) approach. It starts with a user providing a natural language task (q) and a description of an intermediate language (C). A large language model (LLM) then generates a program (p) in a parent language (P). The SPEAC system then attempts to repair this program (p) using formal methods, resulting in a repaired program (p’) in language C. This repaired program may or may not contain holes (unfilled parts of the code). If no holes exist, the system compiles (f) the program to the target language (T) and provides the output. If holes exist, a new prompt (q’) is generated and sent to the LLM to complete the missing parts, iterating this process until a hole-free program is obtained.
read the caption
Figure 2: The SPEAC workflow. Users input q, a task in natural language, and C, a description of the intermediate language. The LLM takes these inputs and generates p, a program in P. We use formal techniques to repair p and produce p', a program in C that possibly contains holes. If p' does not contain holes, SPEAC applies f, a compiler from C to the target language, T, and returns the result. Otherwise, SPEAC generates a new prompt, q', and repeats by asking the LLM to fill in the holes.
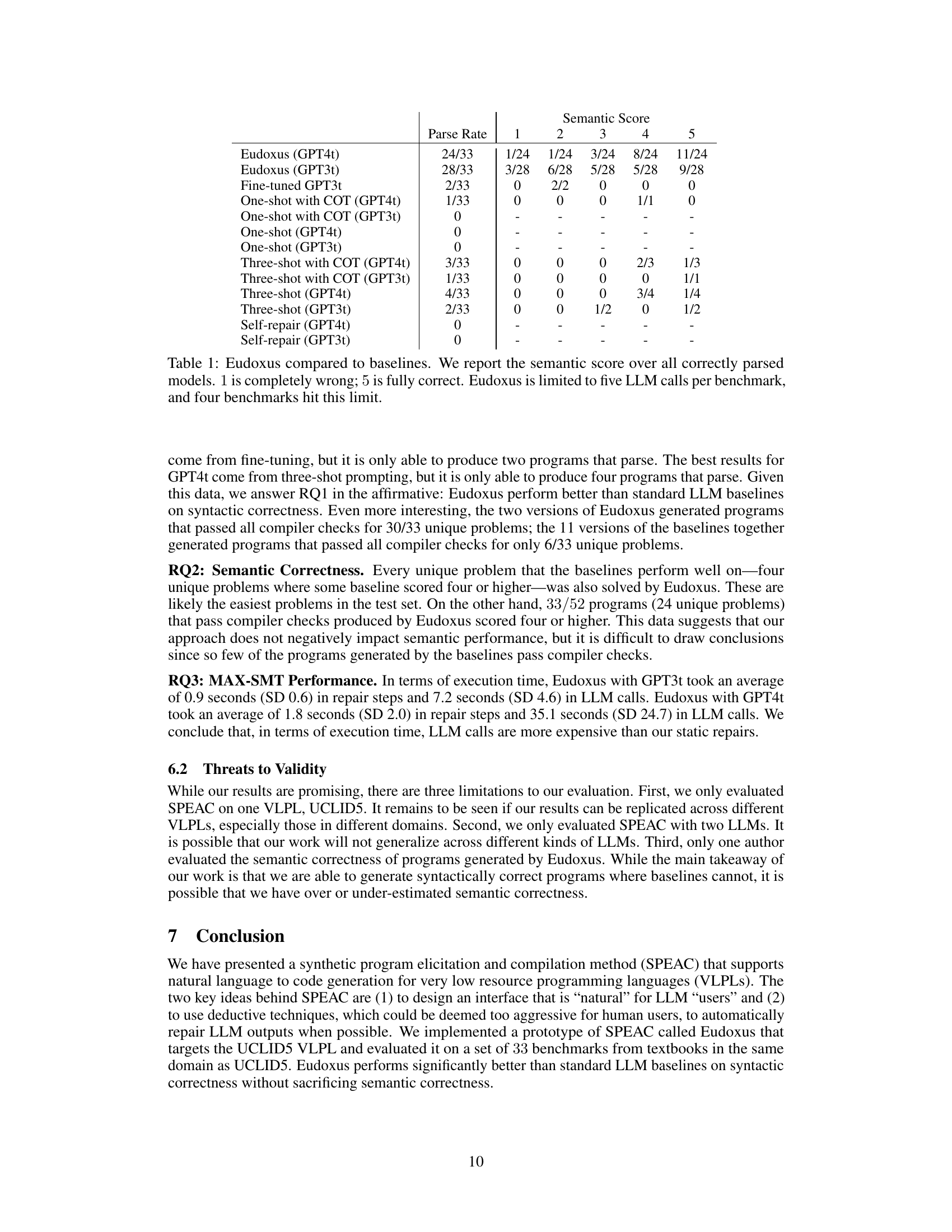
🔼 This table compares the performance of Eudoxus, a prototype implementation of SPEAC, against several baseline methods for generating UCLID5 code from natural language descriptions. The comparison focuses on two key metrics: the percentage of generated programs that pass compiler checks (syntactic correctness) and a semantic correctness score (ranging from 1 to 5, where 5 indicates fully correct). The table shows that Eudoxus significantly outperforms the baselines in terms of syntactic correctness, while maintaining comparable semantic correctness. The limitation of five LLM calls per benchmark is also noted.
read the caption
Table 1: Eudoxus compared to baselines. We report the semantic score over all correctly parsed models. 1 is completely wrong; 5 is fully correct. Eudoxus is limited to five LLM calls per benchmark, and four benchmarks hit this limit.
In-depth insights#
VLPL Code Gen#
The field of VLPL (Very Low-Resource Programming Language) code generation presents unique challenges due to the limited availability of training data for these languages. Existing techniques, such as prompting and fine-tuning, often fall short, especially when dealing with the complexities of formal verification languages or domain-specific languages with unique syntaxes and semantics. Synthetic Programming Elicitation and Compilation (SPEAC) is a promising approach that attempts to overcome these limitations by identifying an intermediate language (parent language) that large language models (LLMs) are adept at generating code for. This intermediate code is then automatically compiled or repaired (child language) into the target VLPL. The key innovation of SPEAC lies in its ability to use compiler techniques to correct LLM-generated code that lies outside the intermediate language, maximizing the frequency of syntactically correct programs without sacrificing semantic correctness. The empirical evaluation of SPEAC demonstrates significant improvements over traditional methods in generating syntactically valid code, particularly in contexts where existing techniques struggle, thus showcasing its potential to significantly advance code generation capabilities for VLPLs.
SPEAC Method#
The SPEAC method is a novel approach for generating syntactically correct code from LLMs, especially in very low-resource programming languages (VLPLs). It leverages synthetic programming elicitation to identify an intermediate language (P) that LLMs can easily generate code in, and a corresponding subset (C) that is easily compilable to the target VLPL (T). When LLMs produce code outside C, SPEAC employs compiler techniques and deductive reasoning to automatically repair the code, generating a program in C that may contain “holes.” These “holes” are filled iteratively by prompting the LLM, until a syntactically correct C program is produced, which is then compiled to the target VLPL T. This iterative refinement process makes SPEAC robust to LLM inaccuracies while still maintaining semantic correctness, significantly outperforming existing retrieval and fine-tuning baselines for VLPLs, as demonstrated in their UCLID5 case study.
Eudoxus System#
The Eudoxus system, as described, is a novel approach to the text-to-code problem in very low-resource programming languages (VLPLs). It leverages large language models (LLMs) to generate code in a high-level, LLM-friendly language, which is then automatically translated to the target VLPL. A key innovation is its use of formal techniques to repair syntactically invalid code, ensuring the output is correct. This two-stage process combines the strengths of LLMs for code generation with the rigor of formal methods for ensuring correctness, thereby addressing the challenges of VLPLs. The system’s effectiveness is demonstrated through a case study using UCLID5, a VLPL used for formal verification, showing a significant improvement over baseline methods. Eudoxus is notable for its ability to generate syntactically correct programs more frequently without compromising semantic correctness, a significant leap forward in handling the scarcity of training data and the complexities of VLPLs. It opens avenues for applying LLMs to a broader range of programming languages.
MAX-SMT Repair#
The heading ‘MAX-SMT Repair’ suggests a technique leveraging the power of Max-SAT solvers for program repair. This approach likely involves formulating program repair as a weighted satisfiability problem, where constraints represent the program’s syntax, semantics, and the desired modifications. Each constraint is assigned a weight reflecting its importance. The Max-SAT solver then finds a solution that satisfies the maximum weight of constraints, effectively generating a repaired program that is both syntactically correct and, ideally, semantically sound. The use of weights allows for prioritizing certain aspects of the repair; for instance, semantic correctness might be weighted more heavily than stylistic preferences. This method’s effectiveness hinges on precisely encoding the repair problem as a weighted satisfiability instance. The challenges lie in efficiently representing complex program semantics and handling potential ambiguities or inconsistencies in the problem description. The process likely involves abstract syntax trees (ASTs) to represent the program and its structure, enabling a more fine-grained approach to constraint definition and manipulation. The success of this technique depends critically on the expressiveness and efficiency of the constraint generation process. It likely offers a powerful tool for automated program repair, particularly in situations with complex constraints or those needing sophisticated handling of various weights and preferences.
Future Works#
Future work could explore extending SPEAC to a wider range of VLPLs, investigating the impact of different parent languages P, and developing more sophisticated repair strategies. Improving the efficiency of the MAX-SMT solver is crucial for practical applications. A more comprehensive evaluation across diverse benchmarks would solidify the approach’s generalizability. Exploring the integration of SPEAC with other LLMs and different prompting techniques is key. Furthermore, research into automatic selection of optimal intermediate languages C based on LLM behavior analysis would improve automation and efficiency. Finally, studying the relationship between LLM architecture and SPEAC’s performance could unveil new insights for improving text-to-code generation in low-resource settings.
More visual insights#
More on tables

🔼 This table compares the performance of Eudoxus, a prototype implementation of SPEAC, against various LLM baselines on syntactic and semantic correctness for UCLID5 code generation. It shows the percentage of outputs that successfully passed compiler checks (parse rate) and a semantic score (1-5, with 5 being fully correct) for each approach. The baselines include different prompting techniques (few-shot, chain-of-thought, three-shot) and fine-tuning with both GPT3t and GPT4t LLMs. The table highlights Eudoxus’s superior performance in syntactic correctness, achieving a much higher parse rate than all baselines. Note that Eudoxus’s performance is limited by a maximum of five LLM calls per benchmark, and this limit was reached in four cases.
read the caption
Table 1: Eudoxus compared to baselines. We report the semantic score over all correctly parsed models. 1 is completely wrong; 5 is fully correct. Eudoxus is limited to five LLM calls per benchmark, and four benchmarks hit this limit.

🔼 This table compares the performance of Eudoxus, a prototype implementation of the SPEAC approach for generating UCLID5 code, against several Large Language Model (LLM) baselines. The metrics used are the percentage of generated programs that are syntactically correct (pass all compiler checks, ‘Parse Rate’) and a semantic correctness score (1-5, where 5 is fully correct). The baselines include various prompting strategies (few-shot, three-shot, with and without Chain-of-Thought), self-repair, and fine-tuning. The table demonstrates that Eudoxus significantly outperforms the baselines in terms of generating syntactically correct code, with a smaller, but still positive impact on semantic accuracy.
read the caption
Table 1: Eudoxus compared to baselines. We report the semantic score over all correctly parsed models. 1 is completely wrong; 5 is fully correct. Eudoxus is limited to five LLM calls per benchmark, and four benchmarks hit this limit.
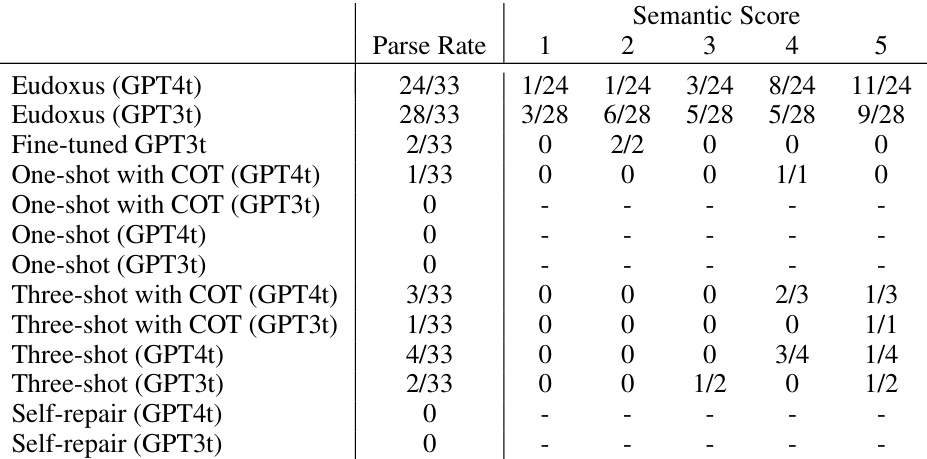
🔼 This table compares the performance of Eudoxus, a prototype implementation of the SPEAC approach, against several LLM baselines on two metrics: syntactic correctness (passing compiler checks) and semantic correctness (manual assessment of the generated code). It shows the number of benchmarks (out of 33) that passed compiler checks and the distribution of semantic scores (1-5) for each approach. The table highlights that Eudoxus significantly outperforms the baselines in terms of syntactic correctness, while maintaining comparable semantic correctness. The limitation of Eudoxus to five LLM calls per benchmark is also noted.
read the caption
Table 1: Eudoxus compared to baselines. We report the semantic score over all correctly parsed models. 1 is completely wrong; 5 is fully correct. Eudoxus is limited to five LLM calls per benchmark, and four benchmarks hit this limit.
Full paper#