↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current video-to-audio generation methods struggle with a lack of controllability and context understanding, often producing audio that doesn’t perfectly match the video’s semantics. For example, a video of a cat fight may generate calm meowing sounds, ignoring the conflict. This paper addresses these shortcomings.
The proposed VATT framework uses a large language model (LLM) to bridge visual and textual information with audio generation. Text prompts guide the process, improving compatibility and allowing control over the generated audio. VATT outperforms existing methods in evaluations, demonstrating improved audio quality and alignment with videos. The introduction of the ‘V2A Instruction’ dataset significantly contributes to this success.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces VATT, a novel framework for controllable video-to-audio generation. This addresses a key limitation in existing methods by enabling text-based control over audio generation, leading to more refined and relevant audio outputs. It opens up new avenues for research in text-guided audio generation, offering improvements in both objective metrics and subjective user preference. The creation of a large-scale synthetic audio captions dataset further aids in training and evaluation, advancing the field.
Visual Insights#

This figure illustrates the architecture of the proposed Video-to-Audio Through Text (VATT) model, highlighting its two main operational modes. The first mode takes only a silent video as input and generates corresponding audio along with an automatically generated caption describing the audio. The second mode adds a user-provided text prompt as an additional input, enabling more refined control over the generated audio by aligning it with both the visual content and the textual description.
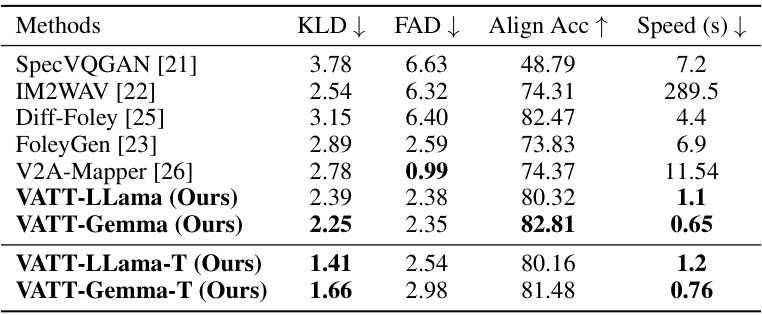
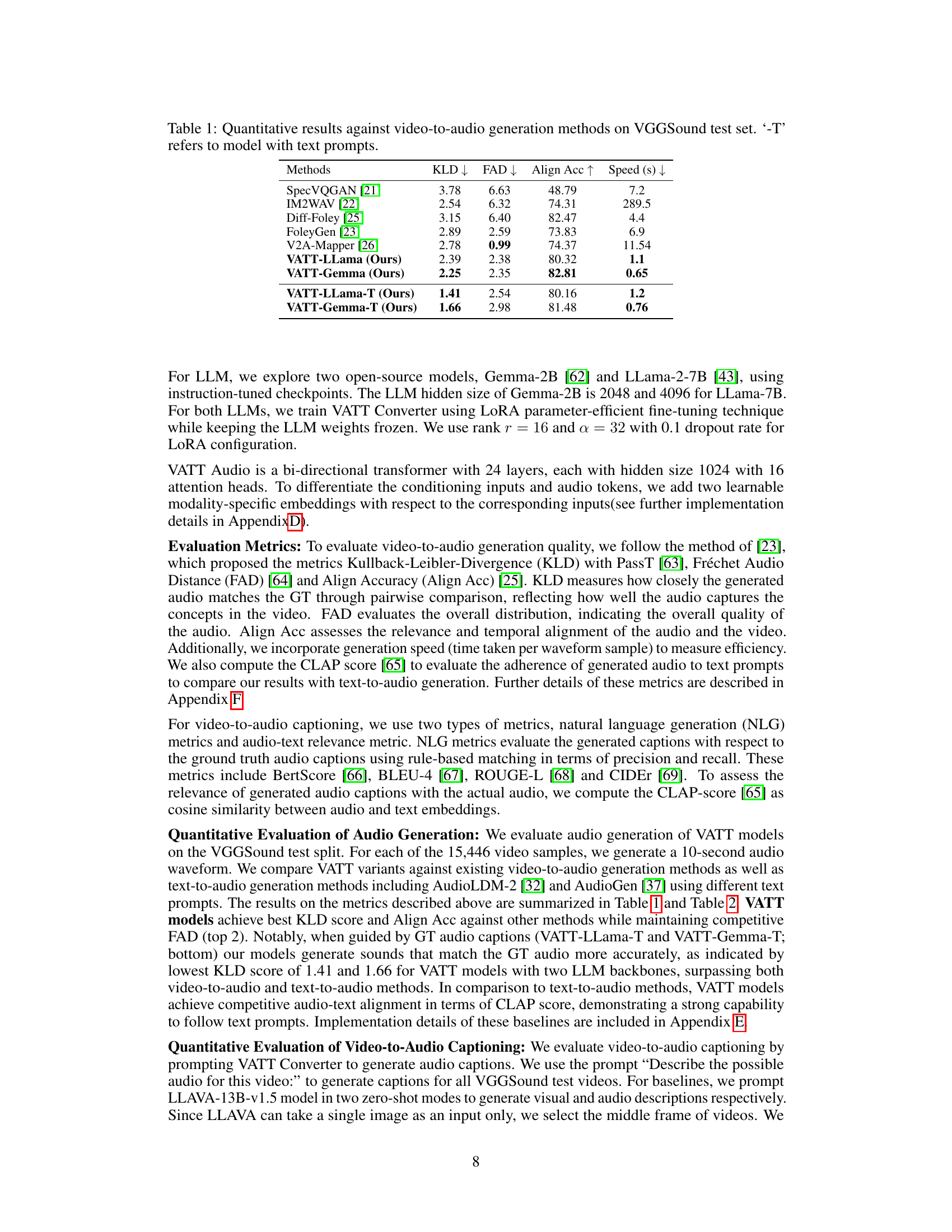
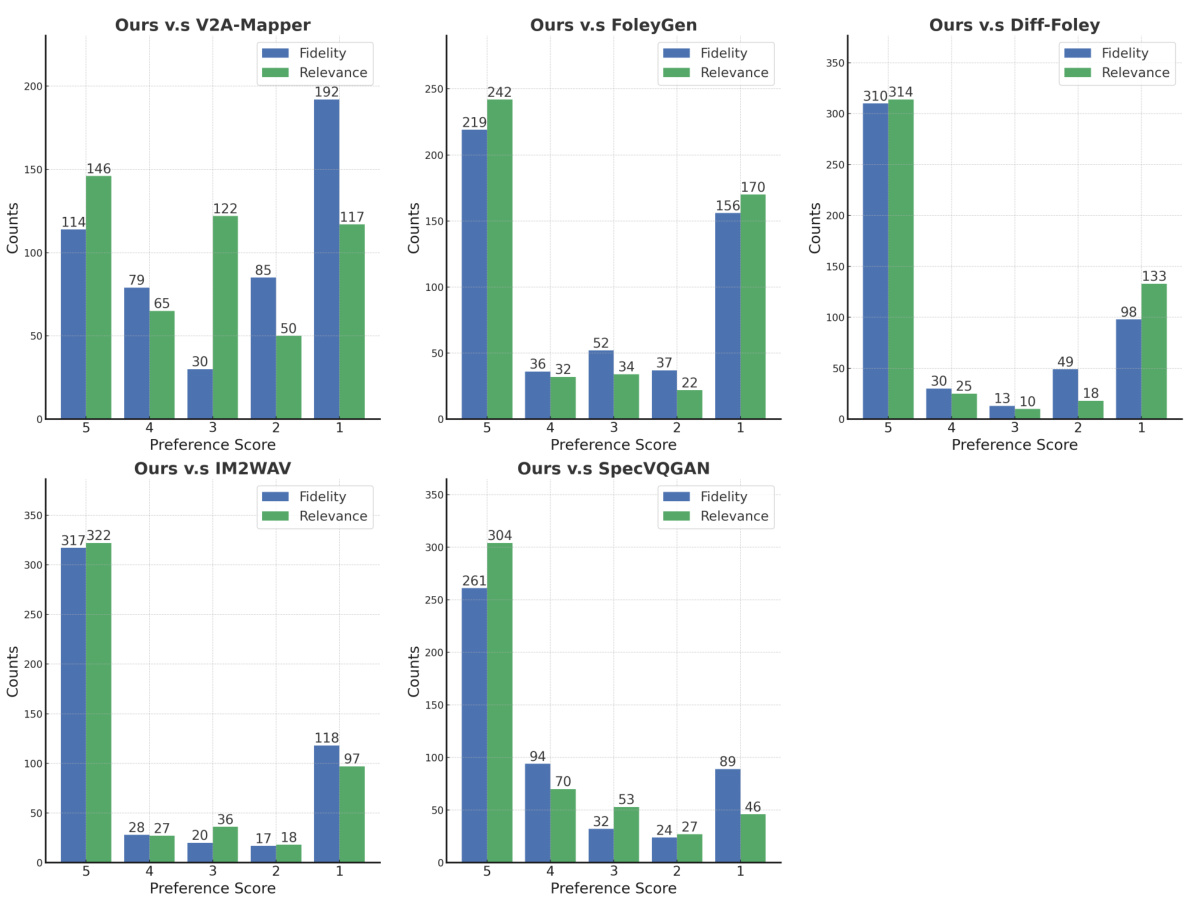
This table presents a quantitative comparison of various video-to-audio generation methods on the VGGSound test dataset. The methods are evaluated using four metrics: Kullback-Leibler Divergence (KLD), Fr´echet Audio Distance (FAD), Align Accuracy, and generation Speed. Lower KLD and FAD scores indicate better performance, while higher Align Accuracy suggests improved audio-visual alignment. Lower speed indicates faster generation. The table includes results for models both with and without text prompts (’-T’). The results show VATT outperforming other methods, particularly when text prompts are used.
In-depth insights#
VATT Framework#
The VATT framework represents a novel approach to video-to-audio generation, uniquely integrating text as a control mechanism. Unlike prior methods which primarily relied on visual information, VATT leverages the strengths of large language models (LLMs) to refine audio generation based on both visual and textual inputs. This dual modality allows for greater control and semantic alignment between the generated audio and the video’s content. A key innovation is VATT’s ability to generate audio captions, offering an automatic summarization of the audio characteristics and suggesting appropriate text prompts, further enhancing the framework’s utility. The framework’s architecture cleverly combines a fine-tuned LLM (VATT Converter) with a bi-directional transformer (VATT Audio) for efficient audio generation. The use of masked token modeling within VATT Audio promotes efficient parallel decoding. Overall, VATT demonstrates a significant leap forward in controllable and semantically richer video-to-audio generation.
LLM Integration#
Integrating Large Language Models (LLMs) into video-to-audio generation presents a powerful opportunity to enhance both the quality and controllability of the synthesized audio. LLMs offer a rich semantic understanding of text, enabling the system to generate audio that closely matches textual descriptions or instructions provided as prompts. This text-based steering mechanism significantly improves control over the generated audio’s content, style, and even emotional tone, surpassing the capabilities of purely visual-based approaches. The LLM can act as a bridge between visual features and audio generation, mapping visual information onto a semantic representation that’s more easily processed by the audio generation module. This multi-modal integration allows for more nuanced and accurate audio generation based on both visual and textual cues. A key challenge lies in effectively aligning the disparate feature spaces of video, text, and audio, requiring careful design of the LLM integration architecture and training strategies. The success of this integration hinges on the LLM’s ability to capture relevant auditory information from the video and to effectively incorporate this information into the audio generation process.
Audio Generation#
This research paper explores audio generation, focusing on a novel approach to video-to-audio generation. A key innovation is the integration of a large language model (LLM) to enhance controllability and context understanding. The model, termed VATT, leverages the LLM to map video features into a textual representation, allowing text prompts to guide the audio generation process. This multi-modal approach enables more refined audio generation that aligns with both visual and textual information, offering significant advantages over existing methods that rely solely on visual data. The effectiveness of VATT is demonstrated through experiments on large-scale datasets, showing competitive performance with existing models and surpassing them when text prompts are provided. The results highlight the potential of VATT in applications like text-guided video-to-audio generation and video-to-audio captioning. Furthermore, the research delves into efficient audio generation techniques using masked token modeling and parallel decoding. This approach significantly reduces inference time compared to traditional autoregressive models. The paper’s thorough experimental evaluation using both objective and subjective metrics supports the proposed framework’s capabilities. Future work may extend this framework toward more conversational interfaces and investigate the capacity for informative iterative video-to-audio interactions.
Experimental Setup#
A well-defined “Experimental Setup” section is crucial for reproducibility and understanding the paper’s findings. It should detail the datasets used, specifying their size, characteristics (e.g., balanced or imbalanced), and any preprocessing steps. The specifics of the model architecture, including any hyperparameters and their selection rationale, are essential. Training procedures must be clearly described, including the optimization algorithm, learning rate, batch size, and stopping criteria. Furthermore, evaluation metrics used should be rigorously defined and justified, along with a discussion of why they are appropriate for the task. Finally, the computational resources used (hardware, software, etc.) should be documented to aid reproducibility. Addressing potential biases or limitations within the datasets or methodologies strengthens the experimental setup, enhancing the credibility and trustworthiness of the research.
Future Works#
The paper’s ‘Future Works’ section would ideally explore improving the diversity and controllability of generated audio. Current methods, while showing promise, often lack the nuance to match the rich variability of real-world sounds. Further research should focus on enhancing the model’s understanding of context and subtle audio cues, possibly through more sophisticated multi-modal fusion techniques. Investigating different model architectures, such as incorporating diffusion models or exploring hybrid approaches, could unlock further advancements. Additionally, exploring efficient inference methods is crucial for practical applications. The potential for real-time audio generation is vast, and efforts to reduce computational complexity would significantly broaden the impact of this research. Finally, addressing ethical considerations surrounding the generation of realistic audio is paramount. Developing safeguards against misuse and promoting responsible use are essential to ensure the technology’s positive impact.
More visual insights#
More on figures

This figure illustrates the two-stage training pipeline of the VATT model. Stage 1 (Video-to-Caption) uses an LLM with a projection layer to map video features into an audio caption. The LLM is fine-tuned using LoRA on V2A instruction data to enable audio caption generation. Stage 2 (Video + Text to Audio) uses a bi-directional transformer to generate audio tokens conditioned on video and textual features (or generated captions in Stage 1). Masked parallel decoding is employed in this stage. The generated audio tokens are then converted into a waveform using a neural audio codec. The figure highlights the flow of information, including video frames, textual prompts, features from the visual encoder and LLM, masked audio tokens, and final audio waveforms.
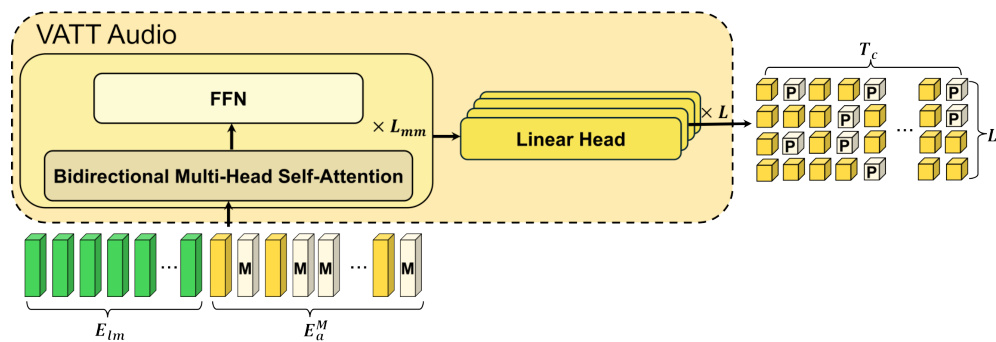
The figure shows the architecture of the VATT Audio, which is a bi-directional transformer decoder. It takes as input masked audio tokens and the hidden states from the last layer of the VATT Converter (which processes video and text features). The decoder uses multi-head self-attention to model the relationship between the audio tokens and the conditioning inputs. A feed-forward network (FFN) further processes the output of the self-attention layer. Finally, L linear layers are used in parallel to classify the masked audio tokens at each codebook layer of the Encodec neural audio codec. This process is used to generate audio waveforms.
This figure illustrates the two-stage training pipeline of the proposed Video-to-Audio Through Text (VATT) model. Stage 1, Video-to-Caption, uses an LLM to generate an audio caption from video features. Stage 2, Video + Text to Audio, takes the caption (or an optional user-provided text prompt) and the video features as input to a bi-directional transformer decoder. This decoder uses masked token modeling to generate audio tokens, which are subsequently converted to an audio waveform.
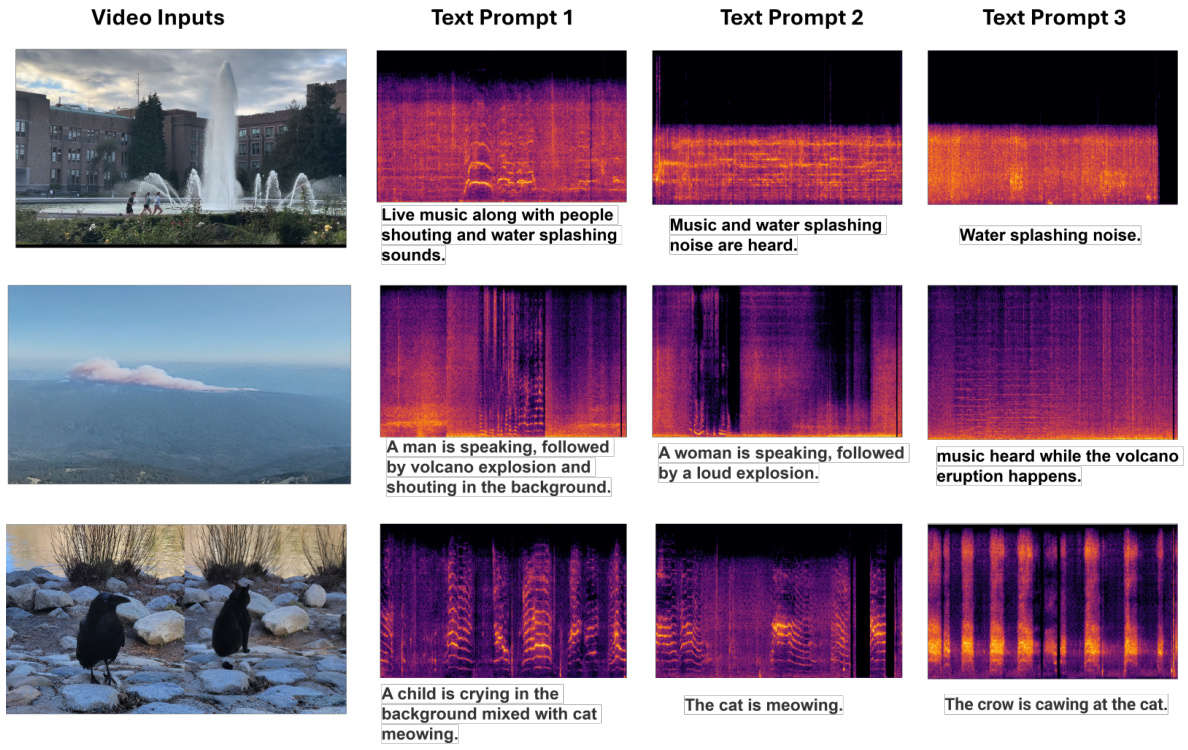
This figure demonstrates VATT’s ability to generate different audio outputs from the same video input by using different text prompts. Three video clips are presented, each paired with three different text prompts. The resulting spectrograms of the generated audio for each prompt-video pair are displayed. This illustrates how VATT leverages text to refine audio generation, providing control over the final output’s characteristics.
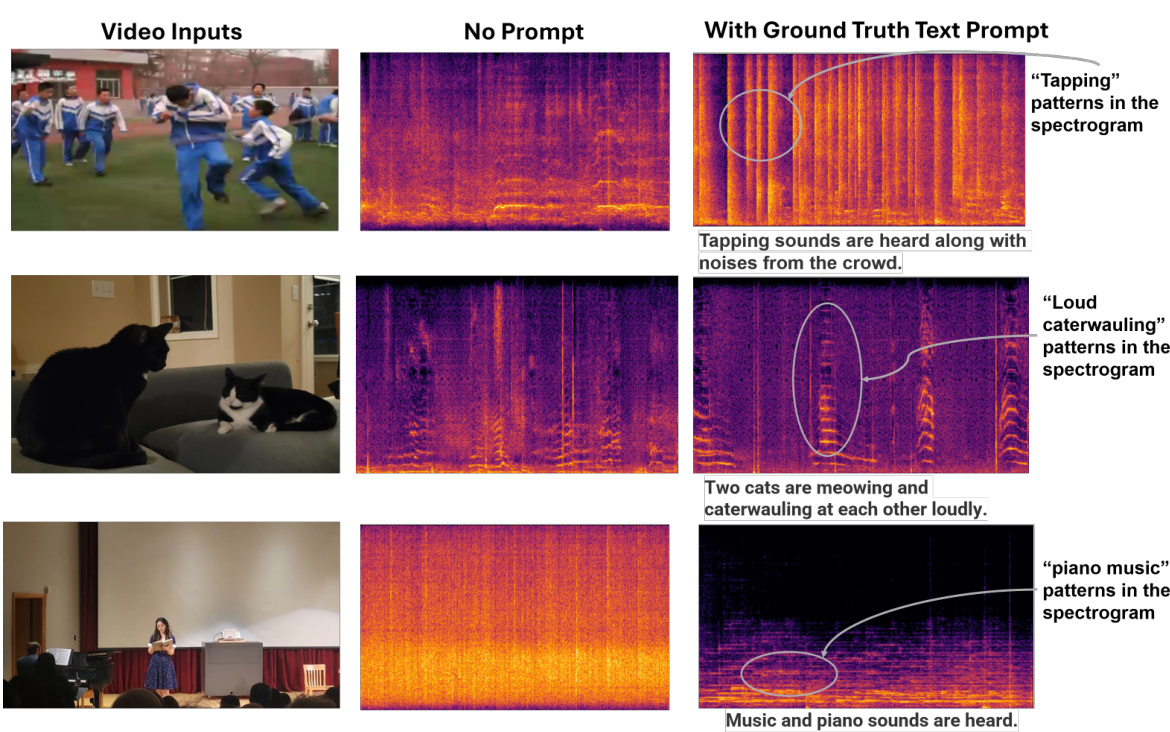
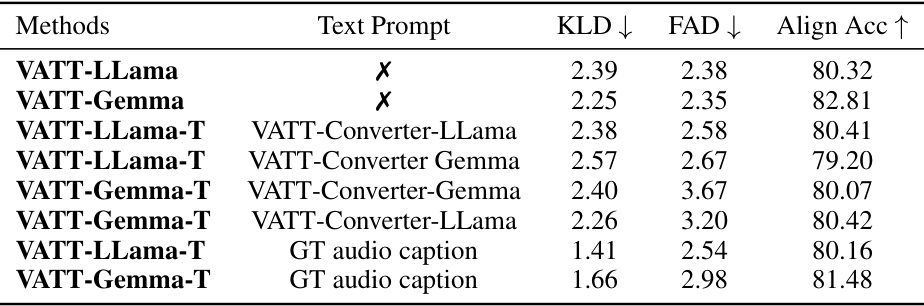
This figure compares the audio generated by the VATT model with and without ground truth audio captions as input. The left column shows the video input. The middle column shows the spectrogram of audio generated without ground truth captions (no prompt). The right column shows the spectrogram of audio generated with ground truth captions (with prompt), along with a textual description of the generated audio. This illustrates how the model’s output can be steered towards more accurate and relevant audio when ground truth captions are provided.
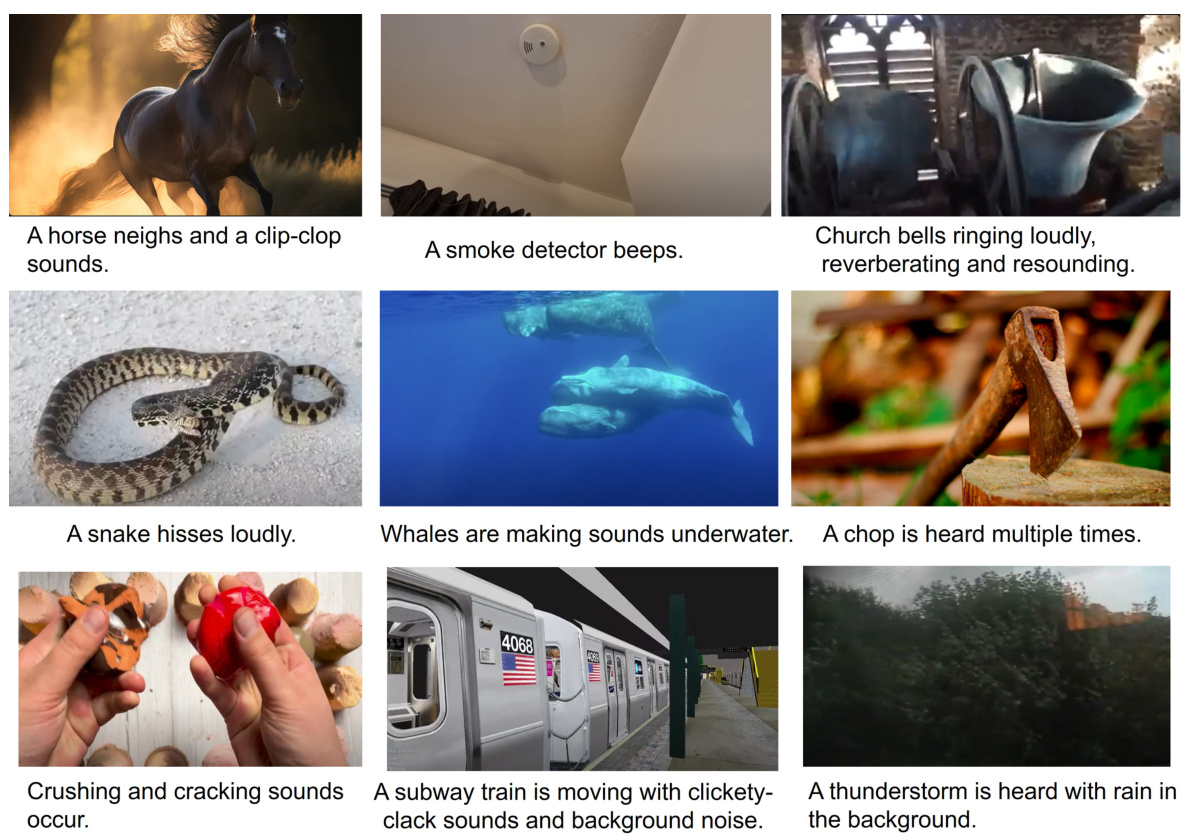
This figure shows nine example images from the VGGSound dataset used to evaluate the VATT model. Each image is accompanied by a caption describing the sounds that could be heard in the video. These examples highlight the model’s ability to generate audio captions that accurately reflect the acoustic events occurring in the videos.
This figure illustrates the two-stage training pipeline of the VATT model. Stage 1 (Video-to-Caption) uses a large language model (LLM) with a projection layer to convert video features into audio captions. This stage is used to generate text descriptions of the audio for a given video. Stage 2 (Video + Text to Audio) uses an encoder-decoder architecture where the encoder is the finetuned LLM from Stage 1, and the decoder is a bi-directional transformer that generates audio tokens. The decoder is trained using masked token modeling to predict masked audio tokens given the context from the video and text prompts. This stage generates the actual audio waveform conditioned on the video and optional text.
More on tables

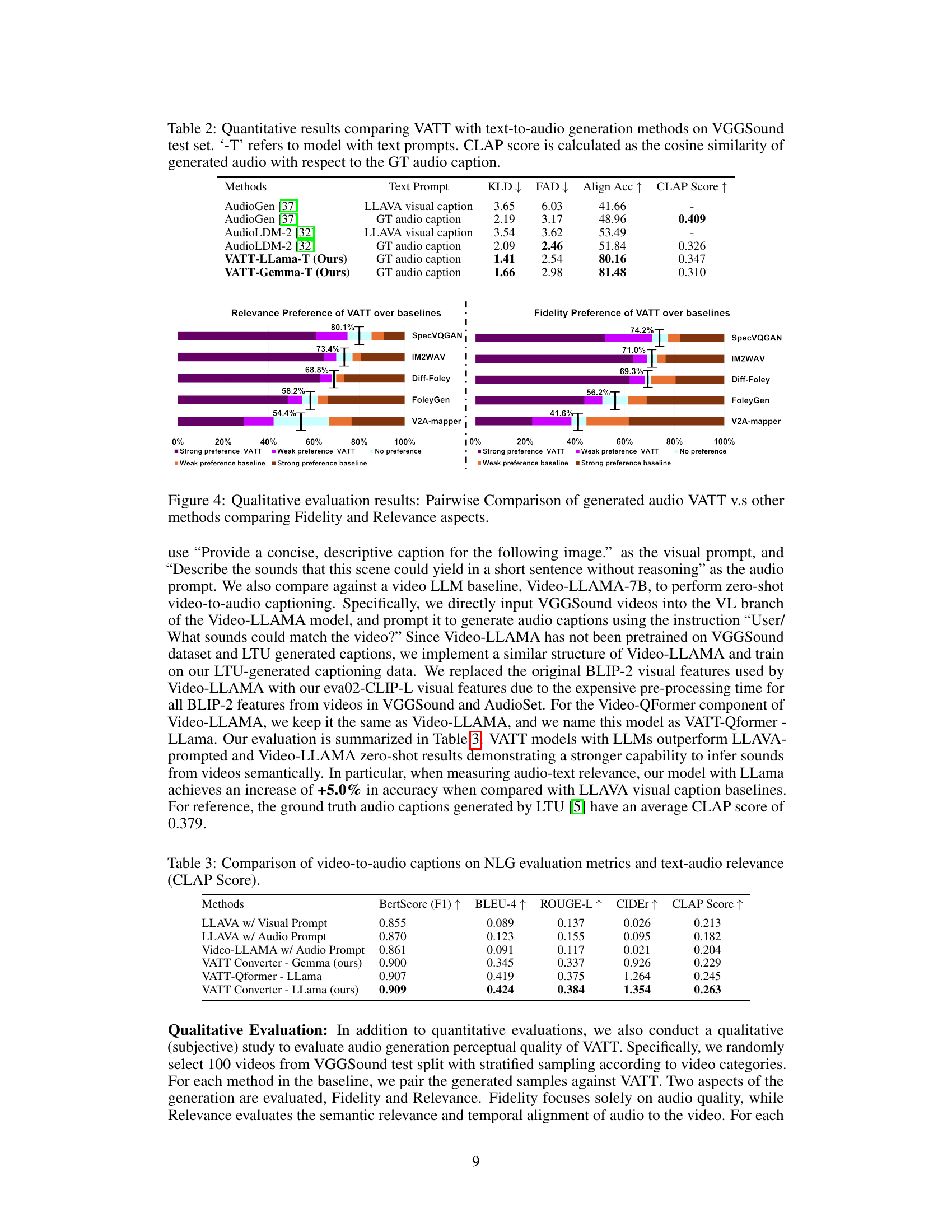
This table presents a quantitative comparison of video-to-audio captioning performance between different methods. It shows the BertScore, BLEU-4, ROUGE-L, CIDEr, and CLAP scores achieved by several approaches, including LLAMA using both visual and audio prompts and the proposed VATT model using different LLMs. The scores assess the quality of the generated captions in terms of natural language generation and their semantic relevance to the actual audio content. Higher scores indicate better caption generation performance.
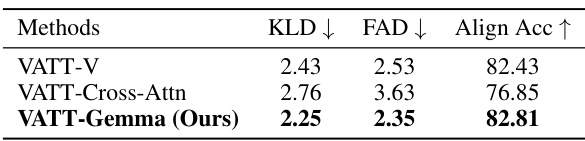
This table presents the results of an ablation study comparing different variants of the VATT model. The variants are: VATT-V (without the LLM), VATT-Cross-Attn (with interleaving attention blocks instead of the bi-directional transformer), and the full VATT-Gemma model. The comparison is based on three metrics: Kullback-Leibler Divergence (KLD), Fr échet Audio Distance (FAD), and Align Accuracy (Align Acc). Lower KLD and FAD scores indicate better performance, while a higher Align Acc score indicates better alignment between generated audio and video. The results show that the full VATT-Gemma model achieves the best performance.

This table presents the results of an ablation study on different masking ratio distributions used in the audio token decoder of the VATT model. The study compares Uniform, Arc cosine, and Gaussian distributions with varying means and a moving mean, evaluating the impact on KLD, FAD, and Align Acc metrics. The results demonstrate that a Gaussian distribution with a mean of 0.75 achieves the best overall performance.
This table presents a quantitative comparison of the proposed VATT model against several existing video-to-audio generation methods on the VGGSound test dataset. The comparison uses four metrics: Kullback-Leibler Divergence (KLD), Fr échet Audio Distance (FAD), Alignment Accuracy (Align Acc), and generation speed. Lower KLD and FAD scores indicate better performance, while higher Alignment Accuracy signifies a stronger match between the generated audio and the video. Faster generation speed is also preferred. The table shows results for both text-prompt based (’-T’) and non-text prompt-based versions of the VATT model along with other video-to-audio baselines, allowing a comprehensive performance evaluation.

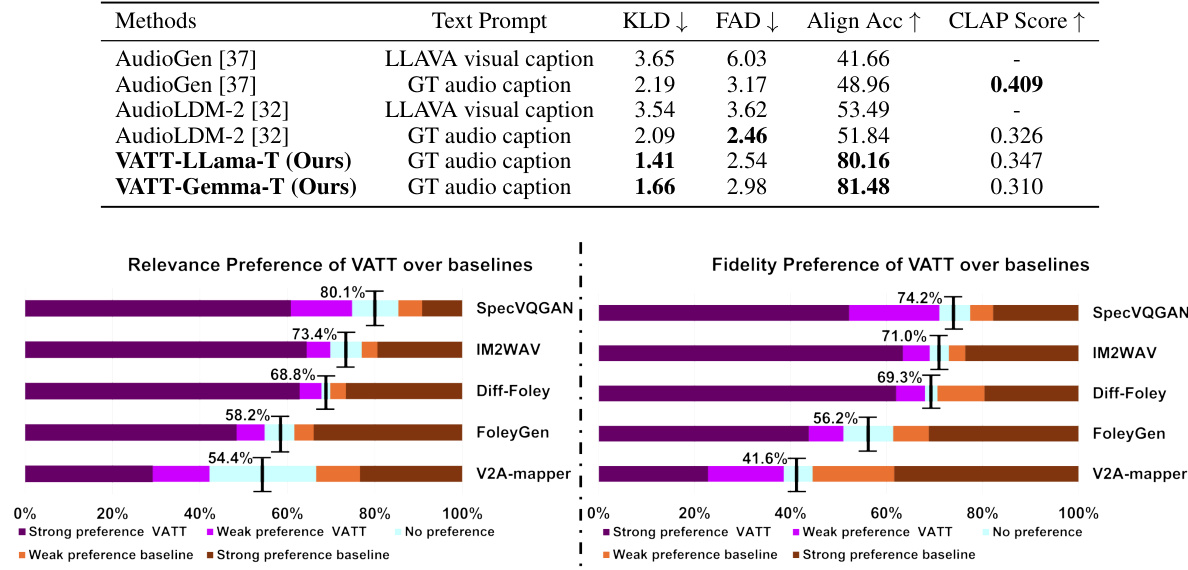
This table presents a quantitative comparison of VATT’s audio generation performance against other text-to-audio methods on the AudioCaps test dataset. The comparison considers four metrics: Kullback-Leibler Divergence (KLD), Fr´echet Audio Distance (FAD), Alignment Accuracy (Align Acc), and CLAP score. Lower KLD and FAD scores indicate better audio generation quality, while higher Align Acc signifies better temporal alignment between the generated audio and the video. CLAP score measures the semantic similarity between generated audio and the ground truth audio caption. The results showcase VATT’s performance with and without text prompts (’-T’).

This table presents a quantitative comparison of VATT against other state-of-the-art video-to-audio generation methods. The comparison is performed using the VGGSound test set, and the table shows several metrics including KLD (Kullback-Leibler Divergence), FAD (Fréchet Audio Distance), Align Acc (Alignment Accuracy), and Speed. The ‘-T’ suffix indicates models that utilize text prompts, which VATT uniquely utilizes to enhance its performance. This allows for a comparison of VATT’s performance both with and without the added control of text prompts.

This table presents a quantitative comparison of the proposed VATT model against several state-of-the-art video-to-audio generation methods. The comparison is done using the VGGSound test dataset. The table shows performance metrics including Kullback-Leibler Divergence (KLD), Fr´echet Audio Distance (FAD), Alignment Accuracy (Align Acc), and generation speed (in seconds). The ‘-T’ suffix denotes results where a text prompt was provided to guide audio generation. Lower KLD and FAD scores indicate better performance.
Full paper#