↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Real-time decision-making AI often struggles with sparse feedback and limited time. Human guidance can greatly improve learning, but continuous human input is resource-intensive. Current methods for incorporating human feedback are often limited to discrete values or small datasets. This presents significant limitations in real-world applications.
This paper introduces GUIDE, a novel framework that uses continuous human feedback grounded into dense rewards, enabling faster policy learning. A key innovation is a simulated feedback module that learns human feedback patterns and continues improving the policy in the absence of direct human input. Experiments show that GUIDE significantly improves performance in challenging tasks with only 10 minutes of human feedback and also examines how individual differences affect agent learning. The larger human subject pool used in the study enhances the reliability and generalizability of the findings.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in real-time decision-making and human-in-the-loop machine learning. It presents a novel framework, GUIDE, that significantly improves learning speed and performance by integrating continuous human feedback and a simulated feedback module. This work is relevant to current trends in AI safety and human-AI collaboration, offering a practical and effective solution for challenging real-world tasks. Furthermore, the study of individual differences and their impact on agent learning opens up new avenues for future research.
Visual Insights#

This figure illustrates the GUIDE framework, which is a novel approach for creating real-time human-shaped agents. The key features highlighted are the use of continuous human feedback to accelerate learning and a simulated feedback module that reduces reliance on human input while enabling continual training. The framework aims to improve agent performance and investigate how individual differences in human feedback affect the learning process. The image shows a diagram of the system, indicating the flow of information between the human, simulated human, agent, and environment.
In-depth insights#
Human-AI Synergy#
The concept of ‘Human-AI Synergy’ in real-time decision-making systems centers on leveraging human strengths to overcome AI limitations, and vice versa. Humans excel at tasks requiring intuition, common sense reasoning, and adaptability in unpredictable environments; AI excels at processing vast amounts of data, identifying patterns, and executing precise actions quickly. A synergistic approach, therefore, necessitates designing systems that seamlessly integrate human feedback to guide and refine AI learning, creating a collaborative process where humans provide high-level direction and oversight while AI handles complex data processing and execution. Successful Human-AI synergy hinges on clear communication and a well-defined role for each entity. The challenge lies in creating intuitive interfaces that facilitate smooth interaction, translating human intentions into actionable feedback for the AI, and ensuring the AI’s actions remain aligned with the human’s overall goals. Moreover, addressing potential biases in human feedback and ensuring equitable participation are crucial ethical considerations in the design of such systems. The effectiveness of Human-AI synergy ultimately depends on the specific task and the careful design of the interaction between humans and the AI agents.
Real-time Feedback#
The concept of real-time feedback in reinforcement learning is crucial for bridging the gap between simulated environments and real-world applications. Real-time feedback allows for immediate adjustments to agent behavior, improving learning speed and performance, especially in complex and dynamic settings. This contrasts with traditional offline methods that rely on batch processing of feedback data, often suffering from delays and reduced adaptability. The effectiveness of real-time feedback hinges on the quality and consistency of human input, which can be challenging to maintain over extended periods. Therefore, mechanisms for simulating human feedback patterns and reducing reliance on continuous human interaction are essential for practical implementation. Approaches focusing on continuous feedback signals rather than discrete ones provide richer information and allow for more nuanced adjustments to agent policies. This is particularly important in tasks with sparse rewards, where subtle cues are vital to successful learning. The challenge lies in balancing the need for human guidance with the goal of minimizing the human effort required.
GUIDE Framework#
The GUIDE framework presents a novel approach to real-time human-guided reinforcement learning (RL). Its core innovation lies in enabling continuous human feedback and translating this feedback into dense rewards, thereby accelerating policy learning. Unlike methods that rely on discrete or sparse feedback, GUIDE leverages a more natural and expressive feedback mechanism. A key strength is its parallel training module, which learns to simulate human feedback patterns, reducing the need for constant human input and enabling continued learning even in the absence of human interaction. This simulation reduces human workload while maintaining continual improvements. Furthermore, the framework demonstrates effectiveness on complex tasks with sparse rewards and high-dimensional visual input, showcasing its potential for real-world applications. The incorporation of cognitive tests within its human study further enhances the understanding of how individual differences might impact learning, making it a more robust and adaptable framework.
Cognitive Factors#
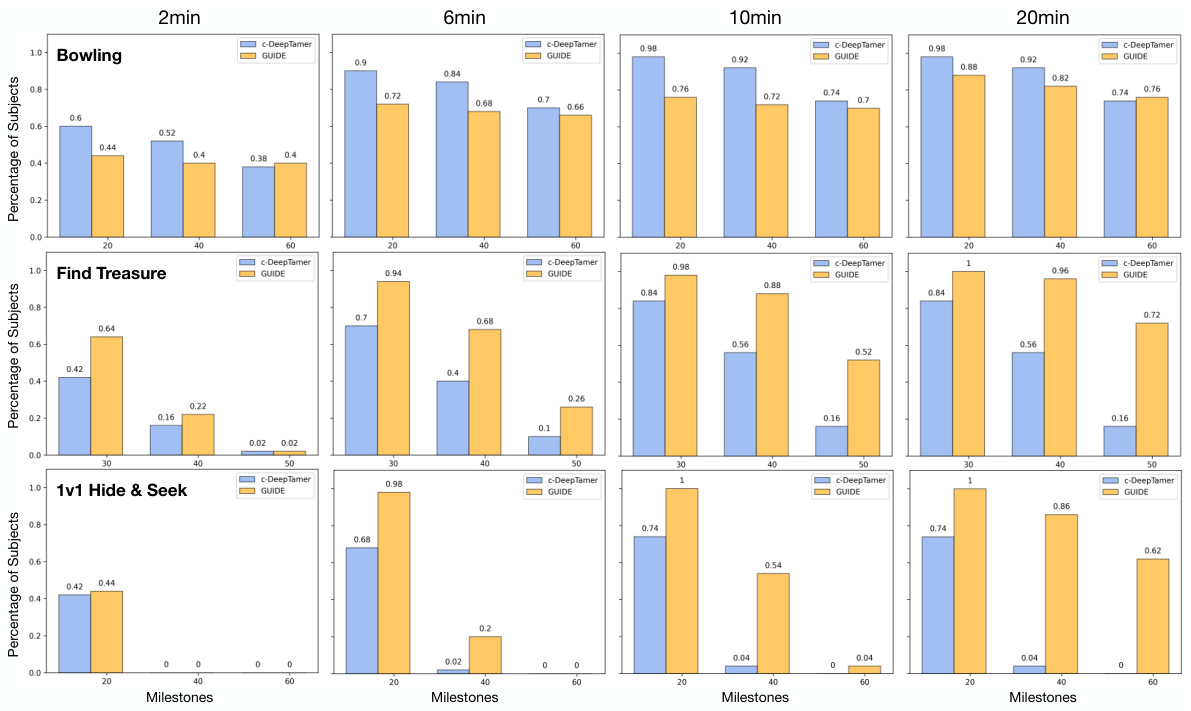
The study explores how individual cognitive differences influence the effectiveness of human-guided reinforcement learning. It investigates whether variations in cognitive abilities, such as spatial reasoning, reaction time, and mental rotation, correlate with the quality of human feedback provided and, consequently, the performance of the trained AI agents. This is a crucial aspect because it acknowledges that human feedback isn’t uniform; it’s shaped by individual cognitive strengths and weaknesses. The research uses a battery of cognitive tests to assess participants’ skills and then correlates test scores with the success rate of the AI agents they guided. Stronger performers on these cognitive tests tended to yield better-performing AI agents, suggesting that human cognitive capacity significantly impacts AI training outcomes in human-in-the-loop settings. This highlights the need for understanding individual differences in human feedback to improve the efficiency and reliability of human-guided AI learning. Further research into personalized AI training methods that leverage these individual differences is suggested.
Future of GUIDE#
The future of GUIDE hinges on addressing its current limitations and exploring new avenues. Extending GUIDE to more complex tasks and large-scale deployments is crucial to demonstrate its real-world applicability. Mitigating individual differences in human feedback, perhaps through personalized feedback mechanisms or advanced feedback modeling, is key for robust and consistent performance. Furthermore, developing explainable learning techniques to understand the inner workings of the human feedback simulator and its interaction with the agent will be important for building trust and improving the overall system. Finally, integrating GUIDE with other AI paradigms such as active learning or hierarchical reinforcement learning could lead to more efficient and powerful real-time human-guided agents. Investigating these areas will enhance GUIDE’s capabilities and solidify its position as a leading framework in human-in-the-loop AI.
More visual insights#
More on figures
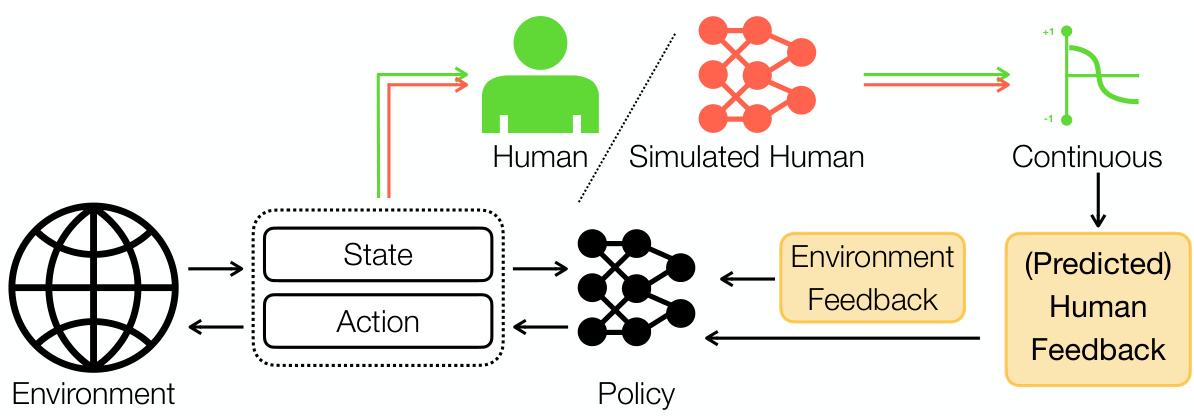
This figure illustrates the GUIDE framework, which consists of two stages: human guidance and automated guidance. In the human guidance stage, a human trainer provides continuous feedback to the agent based on its state and actions. This feedback is integrated with environmental rewards to train the agent’s policy. Simultaneously, a simulated human feedback module is trained to learn and replicate human feedback patterns. In the automated guidance stage, the trained simulator takes over from the human, providing feedback to enable continued policy improvement. This reduces the need for human input and allows for continuous training.

This figure compares two feedback mechanisms: conventional discrete feedback and the proposed continuous feedback. Panel A shows a histogram representing the discrete feedback distribution, highlighting its limited information content. Panel B illustrates the distribution of continuous feedback using a histogram and a curve, revealing more nuanced human assessments. The caption emphasizes the increased information conveyed by the new continuous feedback method.

This figure shows a comparison of conventional discrete feedback and the novel continuous feedback method used in the GUIDE framework. Panel A displays a histogram showing a discrete distribution of human feedback values, likely representing a scale such as {positive, neutral, negative}. Panel B shows a histogram with a continuous distribution, demonstrating that the novel method allows for a more nuanced and detailed feedback signal from human trainers, enabling a richer representation of human assessment of the agent’s behavior.

This figure compares two feedback mechanisms: conventional discrete feedback and the proposed continuous feedback method. Panel (A) shows a histogram of discrete feedback values (+1, 0, -1) given by a human participant. Panel (B) shows a histogram of continuous feedback values from the same participant for the same task. The histograms illustrate that continuous feedback provides richer and more nuanced information about the agent’s performance than discrete feedback.

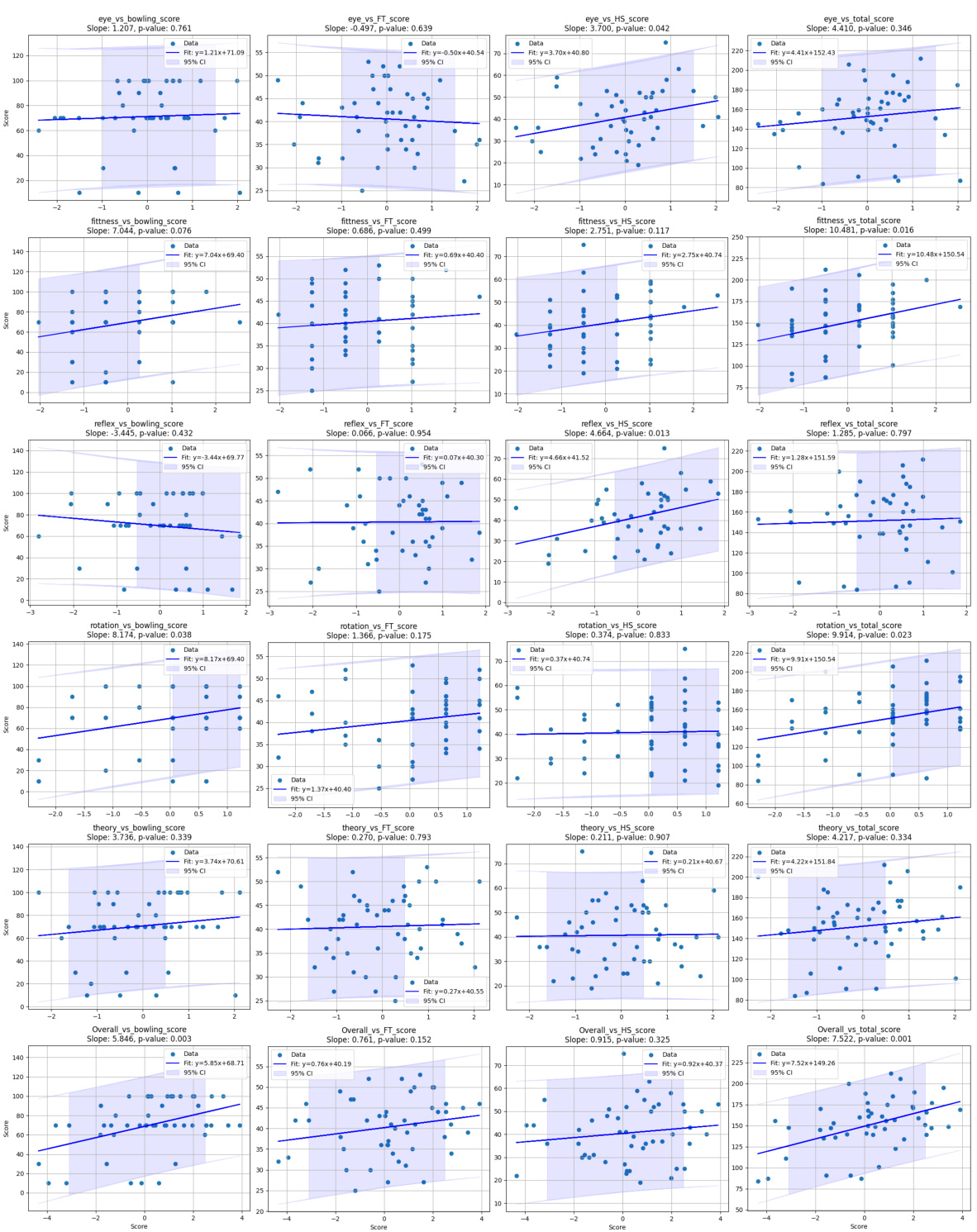
This figure shows six different cognitive tests used in the study. Each test measures a specific cognitive skill, such as eye-hand coordination, reaction time, predictive reasoning, spatial reasoning, and spatial memory. The results of these tests were used to analyze how individual differences in cognitive abilities affected the performance of the human-guided AI agents.
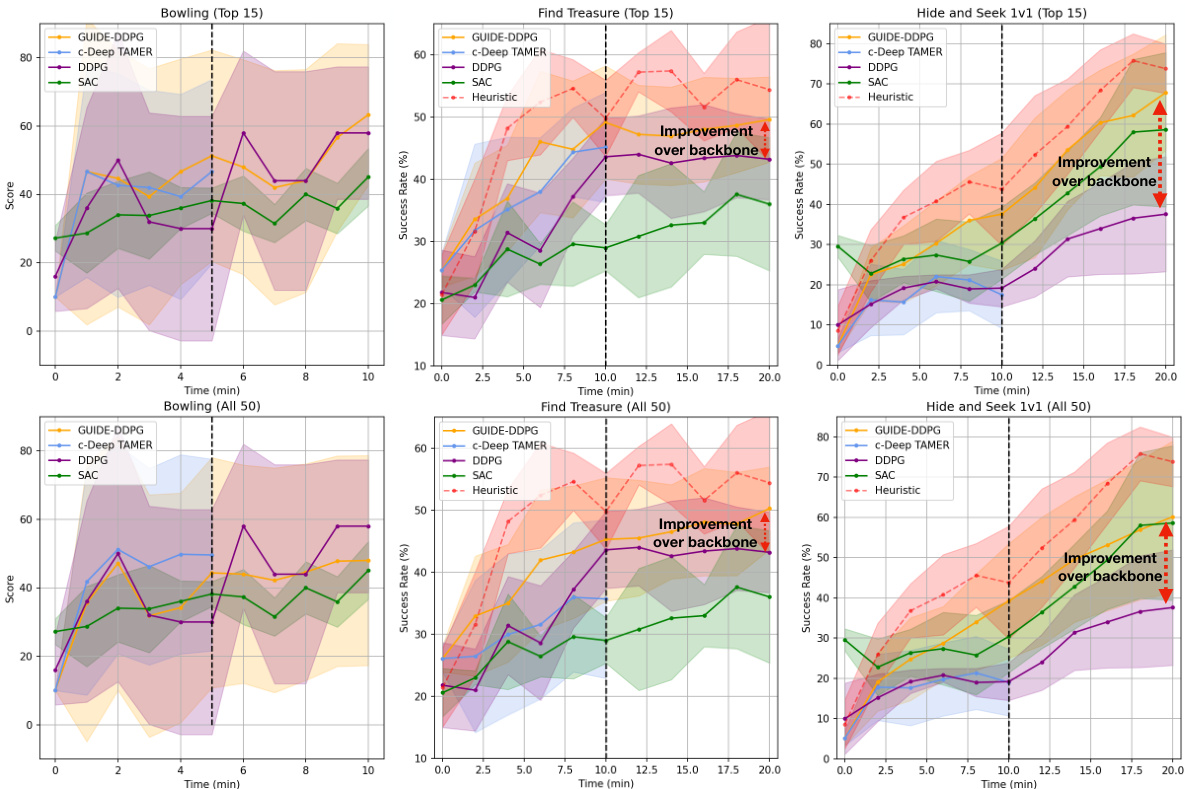
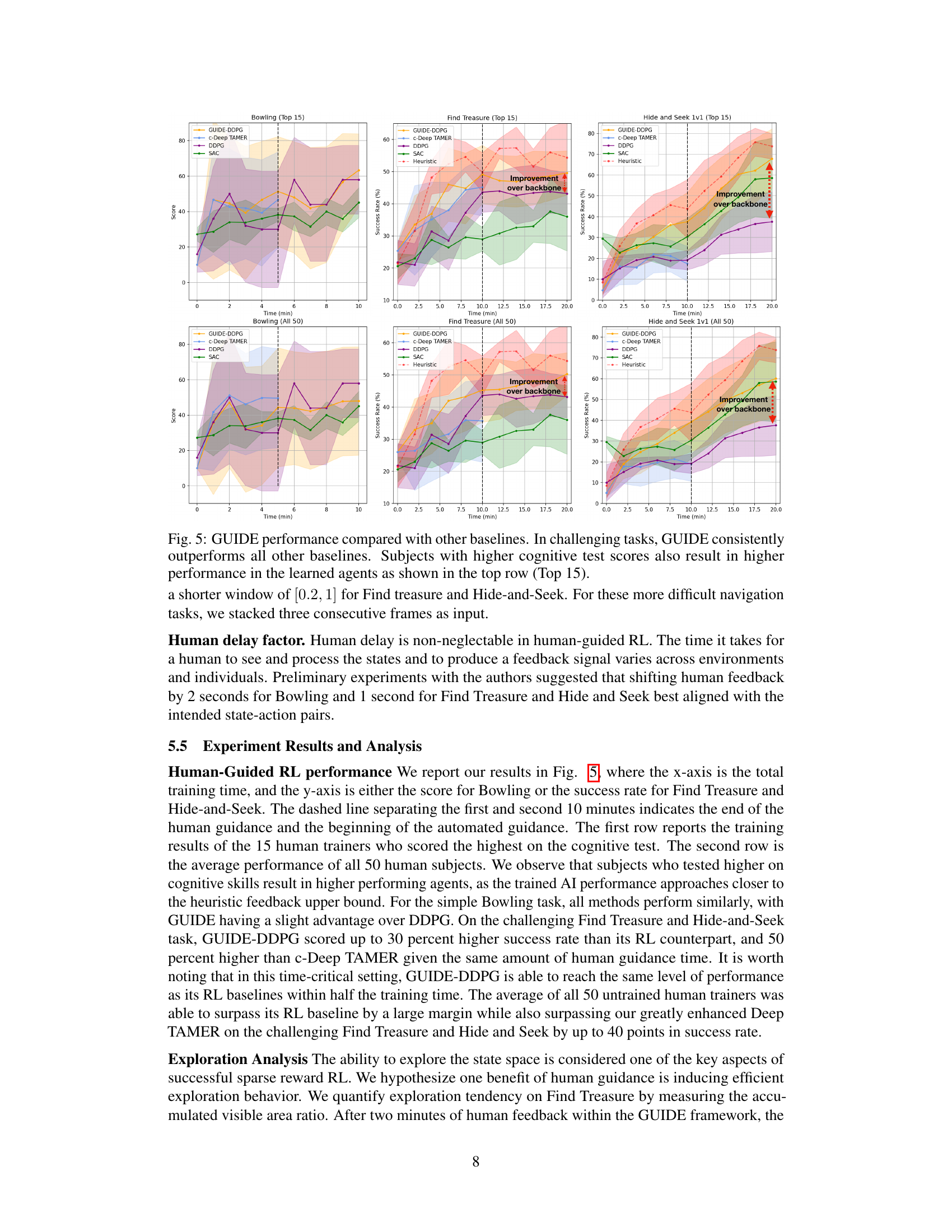
This figure presents the results of experiments comparing the performance of GUIDE with other baselines (c-Deep TAMER, DDPG, SAC, and Heuristic) across three different tasks: Bowling, Find Treasure, and Hide-and-Seek. The results are shown separately for the top 15 subjects and all 50 subjects. The x-axis represents training time (in minutes), and the y-axis represents either the score (for Bowling) or success rate (for Find Treasure and Hide-and-Seek). The shaded areas represent the standard deviation across multiple runs or subjects. The figure demonstrates that GUIDE consistently outperforms other baselines in more complex tasks (Find Treasure and Hide-and-Seek). It also shows a correlation between the subjects’ cognitive test scores and their corresponding AI agent’s performance.
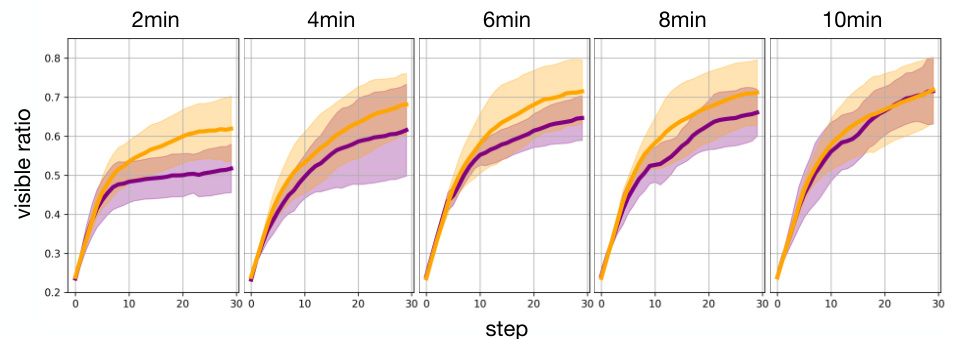
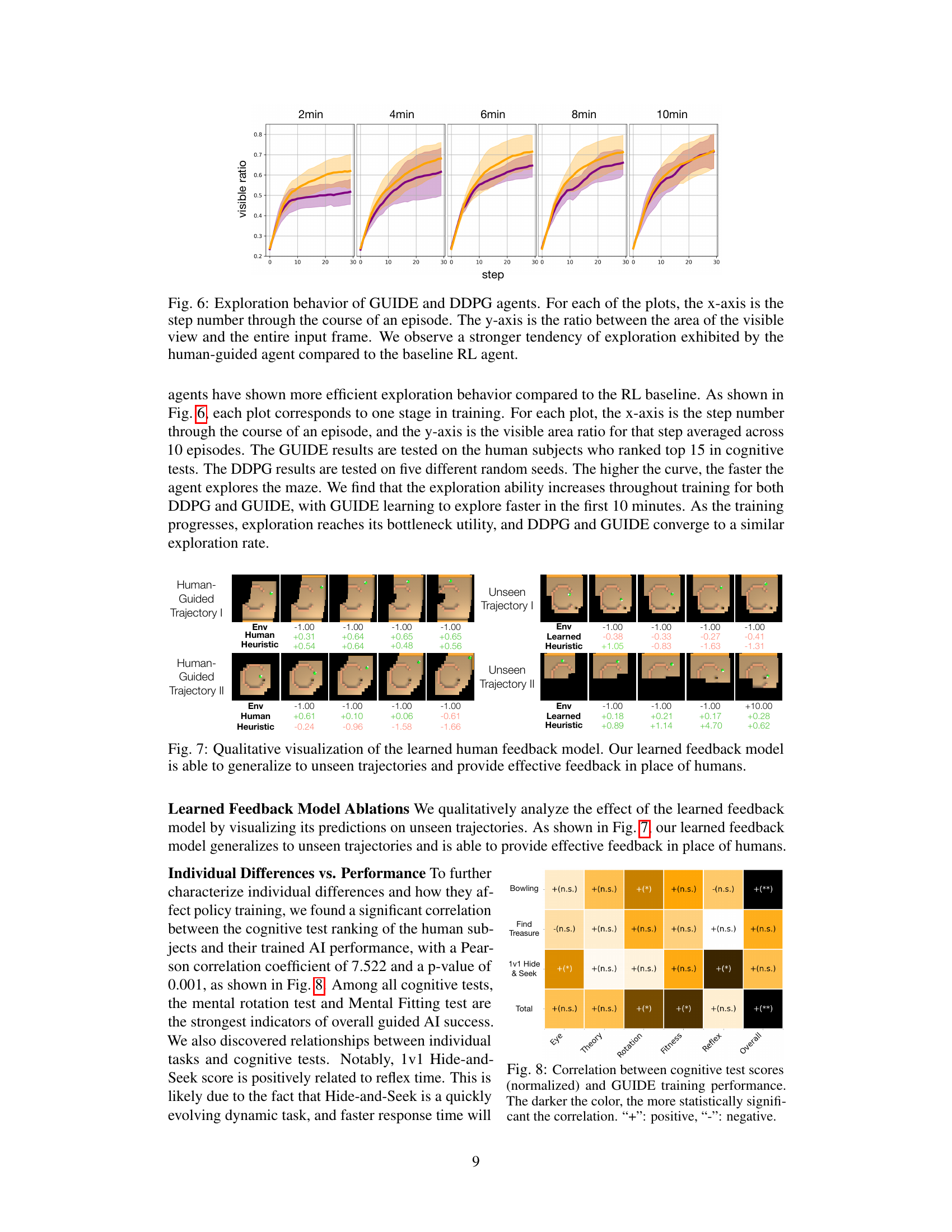
This figure compares the exploration behavior of agents trained with GUIDE and DDPG methods across different training times (2, 4, 6, 8, and 10 minutes). The x-axis represents the step number within an episode, and the y-axis shows the ratio of the visible area to the total frame area. The shaded regions represent the variability in exploration behavior across different runs. The figure demonstrates that GUIDE agents exhibit a higher tendency for exploration than DDPG agents, suggesting the effectiveness of human guidance in encouraging thorough exploration of the environment.
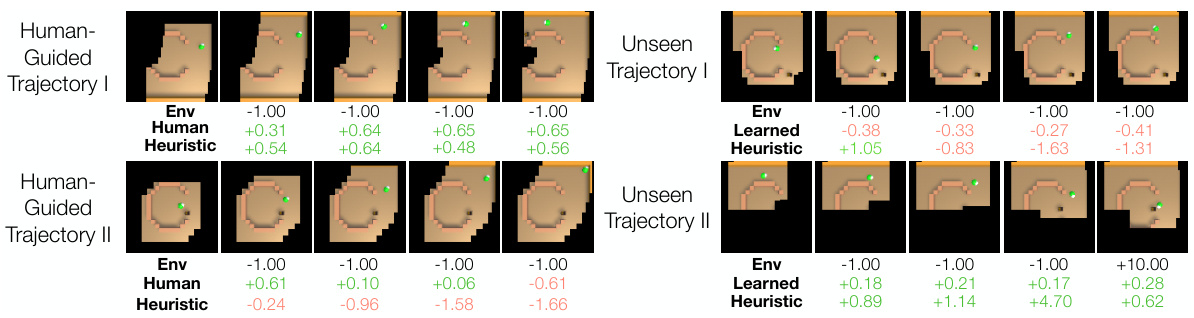
This figure visualizes the performance of the learned human feedback model on unseen trajectories. It compares the environment reward, human feedback, and the learned heuristic feedback for two unseen trajectories. The results show that the learned model can generalize well and provide feedback similar to human feedback, demonstrating its effectiveness in replacing human input.

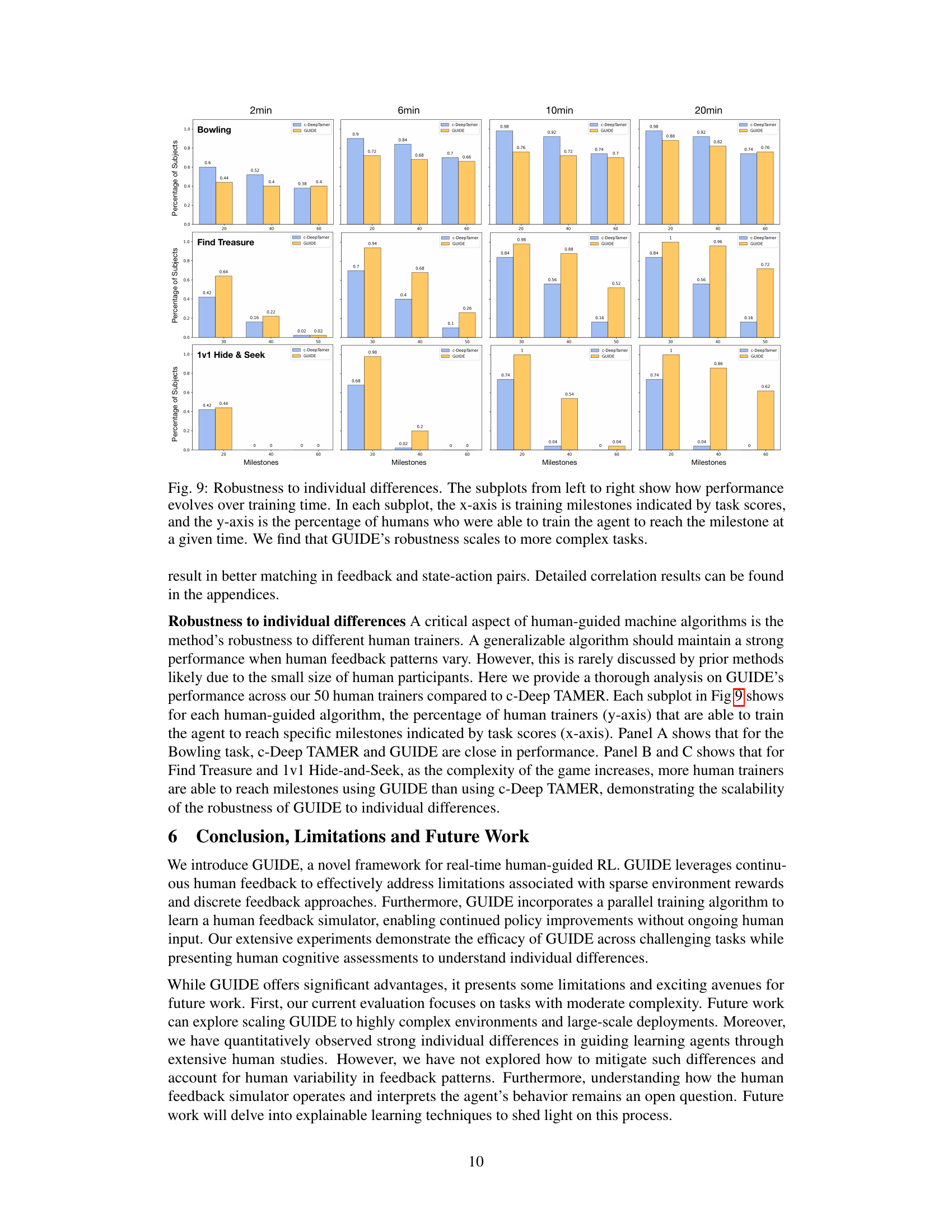
This figure shows the correlation between the results of six cognitive tests (Eye Alignment, Theory of Behavior, Mental Rotation, Mental Fitting, Reflex, and Spatial Mapping) and the performance of the AI agents trained using the GUIDE framework. The color intensity represents the statistical significance of the correlation, with darker colors indicating stronger correlations. Positive correlations are denoted by a ‘+’ symbol and negative correlations by a ‘-’ symbol. The results are broken down by task (Bowling, Find Treasure, 1v1 Hide & Seek) and an overall performance score.
This figure presents a comparison of GUIDE’s performance against other reinforcement learning baselines (c-Deep TAMER, DDPG, SAC) and a heuristic method across three different tasks (Bowling, Find Treasure, 1v1 Hide and Seek). The results are shown separately for the top 15 performing subjects (based on cognitive tests) and all 50 subjects. The figure demonstrates GUIDE’s superior performance, especially in complex tasks, and highlights the positive correlation between subject cognitive abilities and agent performance. The use of a shorter feedback window for Find Treasure and Hide-and-Seek is also noted, along with the input stacking technique used for these tasks.
This figure displays the performance comparison between GUIDE and several baselines (c-Deep TAMER, DDPG, SAC, and Heuristic) across three tasks: Bowling, Find Treasure, and Hide-and-Seek. It shows success rates over time (in minutes), differentiating between the top 15 performing subjects (based on cognitive tests) and all 50 subjects. GUIDE consistently outperforms baselines, particularly in the more complex Find Treasure and Hide-and-Seek tasks. The top row illustrates a correlation between higher cognitive test scores and better agent performance.
Full paper#