↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current zero-shot temporal action detection methods struggle with integrating text and visual information effectively, leading to a common-action bias where models over-focus on frequent sub-actions. This limits their ability to accurately detect less common actions. Foreground-based approaches further restrict the integration of modalities.
To address this, the paper proposes Ti-FAD, which leverages Text-infused Cross Attention (TiCA) to focus on text-relevant sub-actions. Ti-FAD also incorporates a foreground-aware head to distinguish actions from background noise. This results in superior performance compared to state-of-the-art methods on standard benchmarks, showcasing the effectiveness of this novel approach.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly improves zero-shot temporal action detection, a challenging task in video understanding. The proposed Ti-FAD model outperforms state-of-the-art methods by a large margin, opening new avenues for applications such as video search and automated video content analysis. Its simple yet effective approach of integrating text and visual information throughout the detection process offers a valuable contribution.
Visual Insights#
The figure compares three approaches for temporal action detection. (a) shows a previous foreground-based approach which only uses visual features from pre-extracted proposals. (b) shows the proposed cross-modal baseline which integrates text and visual features throughout the detection process using cross-attention. The bottom part illustrates the common-action bias: the baseline tends to focus on common sub-actions even if the text input specifies a different action, while the Ti-FAD method addresses this issue. The yellow sections highlight the ground truth action segments, while the blue and red lines represent the classification scores of the baseline and Ti-FAD respectively.
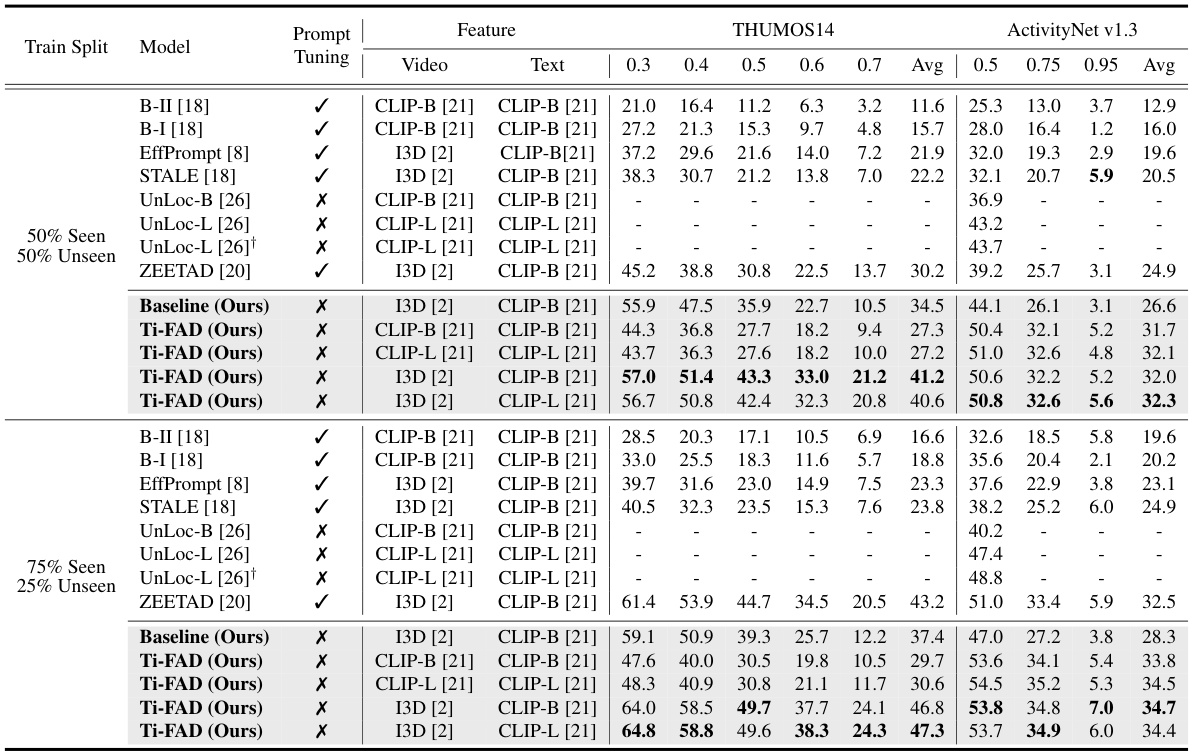
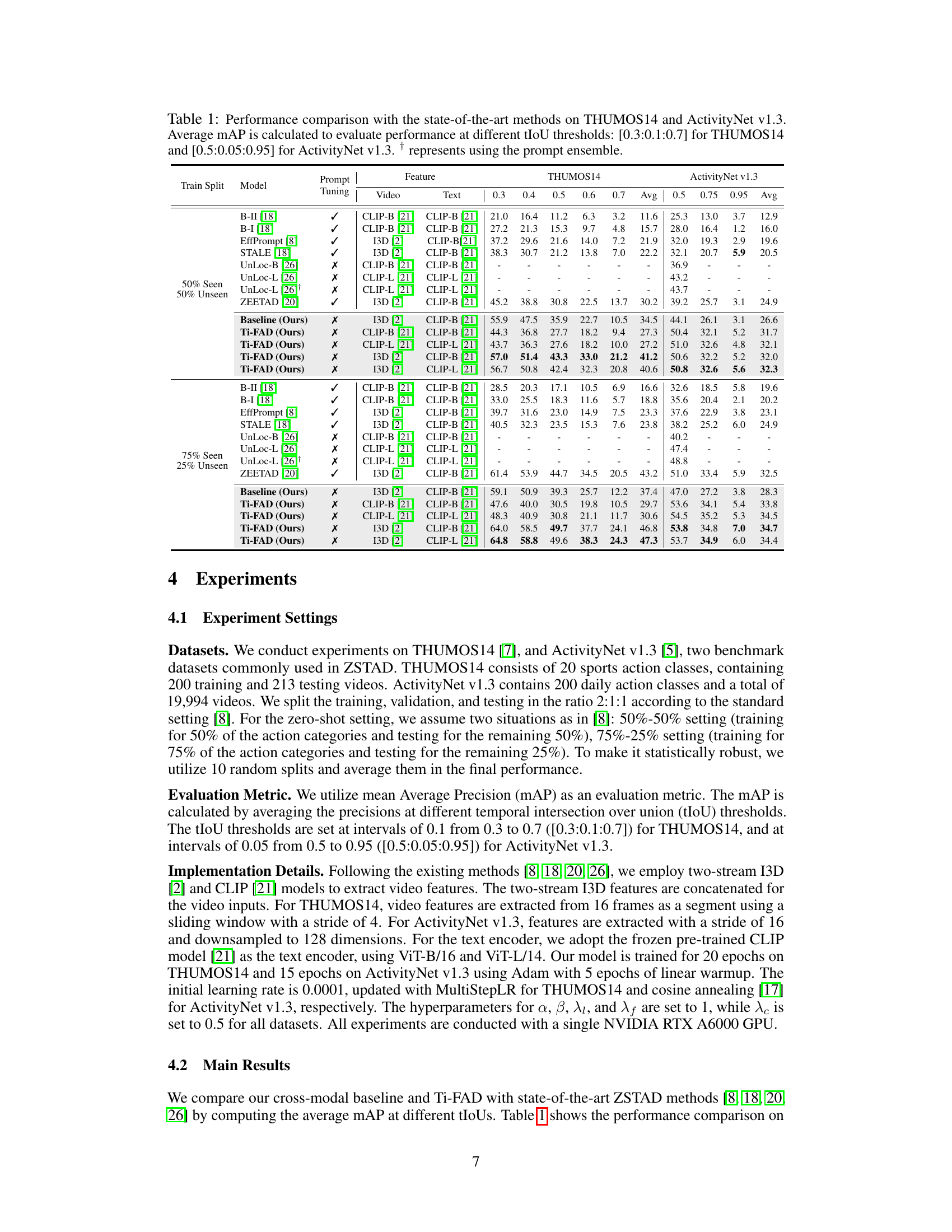
This table presents a comparison of the proposed Ti-FAD model’s performance against several state-of-the-art zero-shot temporal action detection (ZSTAD) methods. The comparison is done using two benchmark datasets, THUMOS14 and ActivityNet v1.3, and considers two experimental settings (50/50% and 75/25% seen/unseen classes). Performance is measured using mean Average Precision (mAP) at various Intersection over Union (IoU) thresholds, providing a comprehensive evaluation of the models’ accuracy and robustness in localizing and classifying actions.
In-depth insights#
Cross-Modal Fusion#
Cross-modal fusion, in the context of a research paper on zero-shot temporal action detection, is a critical technique for effectively integrating textual and visual information to enhance performance. A thoughtful approach to this would involve analyzing various fusion strategies, including early fusion (concatenating features), late fusion (combining predictions), and intermediate fusion (fusing features at different levels of a network). Early fusion is simple but may not capture the nuanced relationships between modalities. Late fusion might ignore subtle interaction, whereas intermediate fusion offers a balance but increases complexity. The choice of fusion method significantly impacts the model’s ability to understand the relationship between action descriptions and their corresponding visual representations. The effectiveness also depends on the types of visual and textual features used, the architectural design of the fusion layer, and the training strategy employed. A successful cross-modal fusion approach should demonstrate improved performance on zero-shot action detection tasks compared to unimodal approaches, highlighting the synergistic benefits of combining text and video information.
Common-Action Bias#
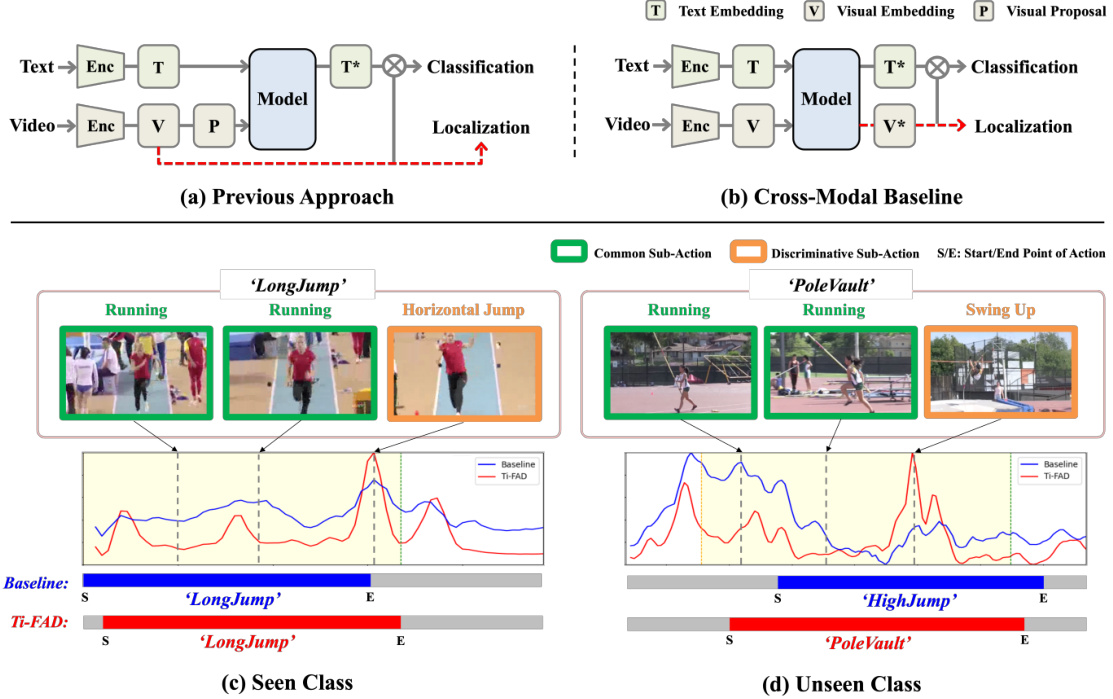
The concept of “Common-Action Bias” in zero-shot temporal action detection (ZSTAD) highlights a critical limitation of models that rely heavily on cross-modal attention. The bias arises from the models’ tendency to overemphasize common sub-actions present in training data, even when the textual description points to a more specific, less frequent action component. This leads to misclassifications and inaccurate localization, particularly when dealing with unseen action categories. For example, a model might incorrectly classify “pole vault” as “running” because “running” is a more frequently occurring sub-action within the training data for various actions. Addressing this bias requires methods that can effectively distinguish discriminative sub-actions from the visual input based on textual cues. This could involve improved attention mechanisms that prioritize text-relevant visual details, enhanced foreground-aware processing to filter out irrelevant background information, or the incorporation of more nuanced training strategies to reduce the disproportionate influence of common sub-actions. Ultimately, overcoming common-action bias is key to improving the robustness and generalization capabilities of ZSTAD models.
Ti-FAD Framework#
The Ti-FAD framework presents a novel approach to zero-shot temporal action detection (ZSTAD) by synergistically integrating text and visual information throughout the entire detection process. Unlike previous foreground-based methods that rely on pre-extracted proposals, limiting text-visual fusion, Ti-FAD leverages a cross-modal architecture. This allows for a more comprehensive understanding of action instances, particularly in unseen categories. Central to Ti-FAD is the Text-infused Cross Attention (TiCA) mechanism, which enhances the model’s ability to focus on text-relevant sub-actions by dynamically generating a salient attention mask based on text and video features. This addresses the issue of common-action bias, often observed in cross-modal models. Furthermore, the foreground-aware head helps refine localization by distinguishing action segments from irrelevant background, leading to more precise and accurate detection results. Extensive experiments demonstrate Ti-FAD’s superior performance, surpassing state-of-the-art methods on THUMOS14 and ActivityNet v1.3 benchmarks. The framework’s effectiveness stems from its holistic approach to text-visual fusion and its ability to address the shortcomings of previous ZSTAD techniques.
Ablation Studies#
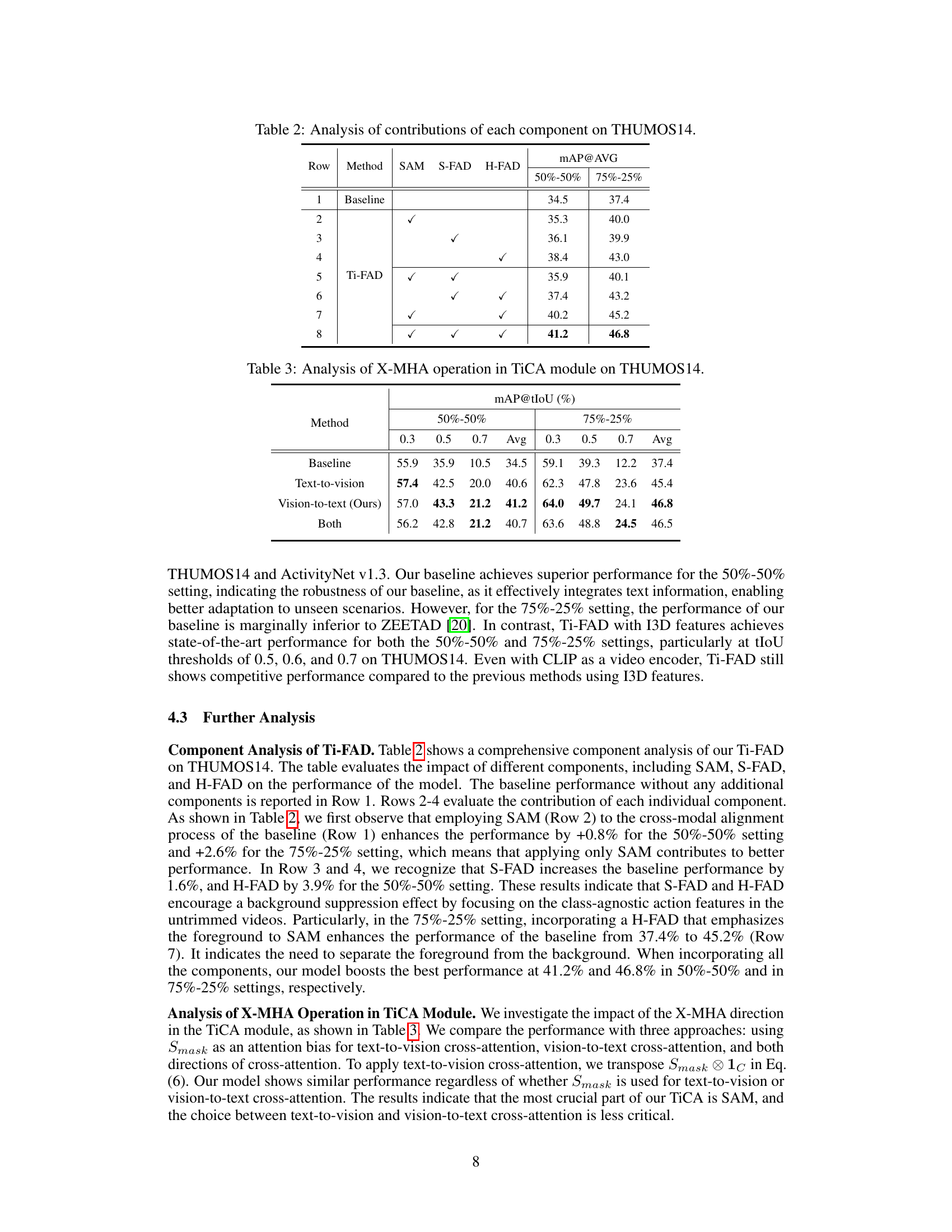
Ablation studies systematically remove components of a model to assess their individual contribution. In this context, the goal is to understand the impact of each module (e.g., Text-infused Cross Attention, foreground-aware head) on the overall performance. By selectively disabling parts, researchers isolate the effects of specific design choices. A well-designed ablation study reveals which components are essential for achieving high performance and which are redundant or even detrimental. Analyzing the results of ablation experiments helps refine model design, leading to a better understanding of the model’s inner workings and potentially improving its efficiency. Analyzing changes in metrics such as mAP (mean Average Precision) across different ablation configurations highlights the relative importance of different components. For instance, a large drop in mAP upon removing a specific module suggests its critical role in the model’s success. Conversely, minimal performance degradation indicates that the removed component is less critical. This structured approach enables a deeper comprehension of the model’s architecture and behavior.
Future Directions#
Future research directions for text-infused attention and foreground-aware modeling in zero-shot temporal action detection could explore several promising avenues. Improving the robustness of the model to noisy or ambiguous text descriptions is crucial, as current methods may struggle with imprecise or unclear language. Investigating alternative attention mechanisms beyond cross-modal attention, such as self-attention or hierarchical attention, could enhance performance. Extending the framework to handle multiple modalities, such as audio and depth information, would significantly improve context awareness. Exploring different architectures, such as transformers or graph neural networks, might lead to more efficient and effective models. Furthermore, research into more sophisticated foreground/background separation techniques could refine the accuracy of action localization. Finally, thorough evaluation on diverse and larger datasets is needed to assess the generalizability of the methods and identify potential limitations. Addressing these challenges would pave the way for more accurate and reliable zero-shot temporal action detection systems.
More visual insights#
More on figures
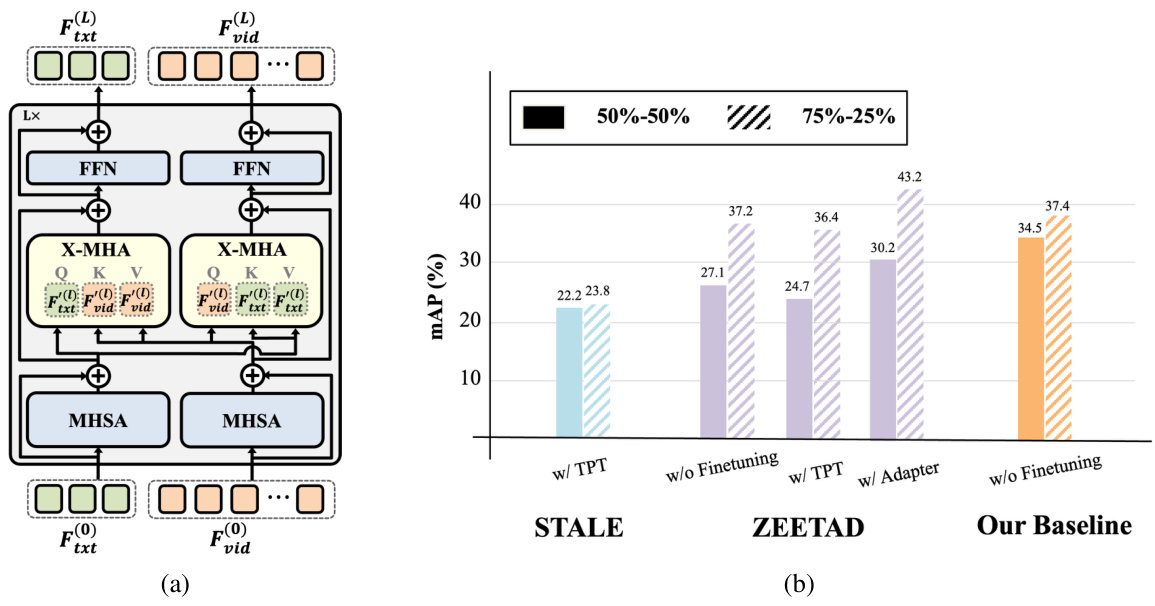
Figure 2(a) shows the architecture of the proposed cross-modal baseline, which consists of multiple layers of multi-head self-attention (MHSA) and multi-head cross-attention (X-MHA) modules to effectively integrate text and visual information. Figure 2(b) presents a comparison of the proposed baseline’s performance against existing state-of-the-art methods (STALE, ZEETAD) on the THUMOS14 benchmark dataset, under two different experimental settings (50% seen/50% unseen actions and 75% seen/25% unseen actions). The results highlight the competitive performance of the proposed cross-modal baseline.
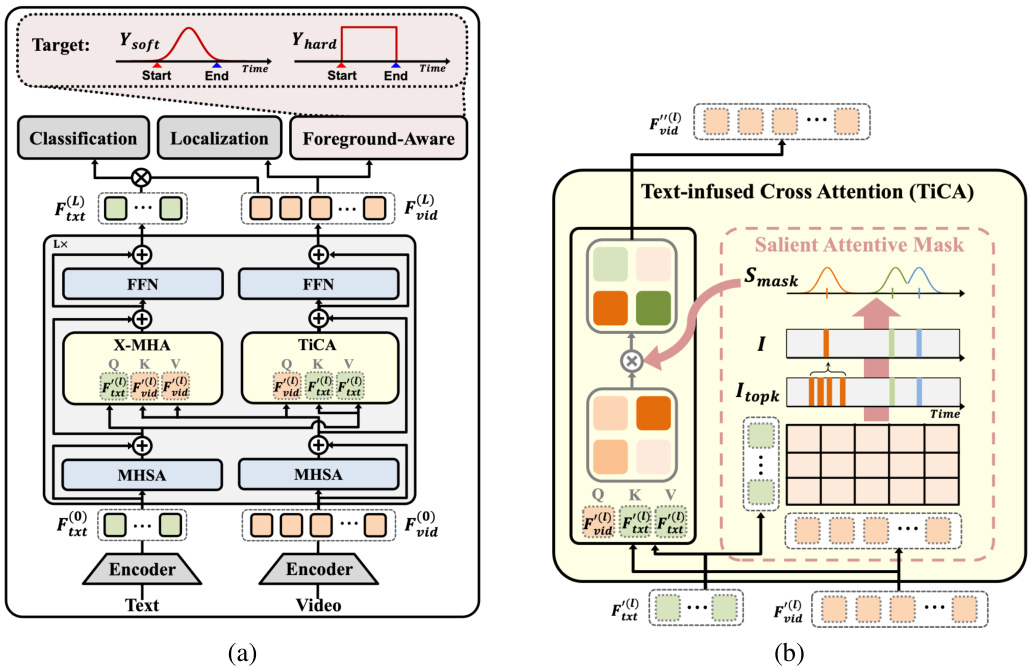
This figure shows the architecture of the proposed Ti-FAD model. (a) illustrates the overall model structure, highlighting the three main components: classification, localization, and foreground-aware head. The foreground-aware head is designed to focus on foreground action segments and suppress background noise. (b) zooms in on the Text-infused Cross Attention (TiCA) module, which employs a Salient Attentive Mask (SAM) to guide the model to focus on the text-relevant, discriminative parts of the visual features.
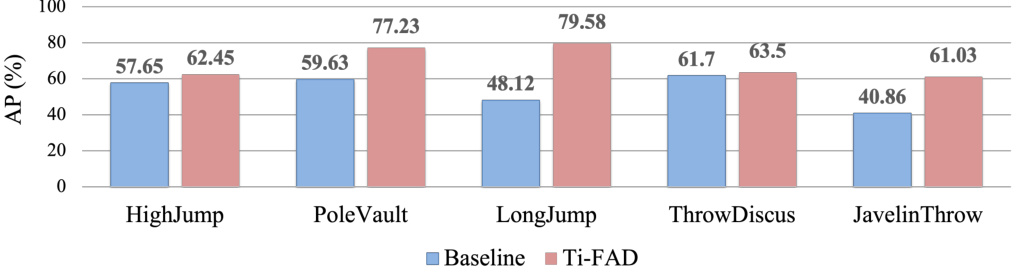
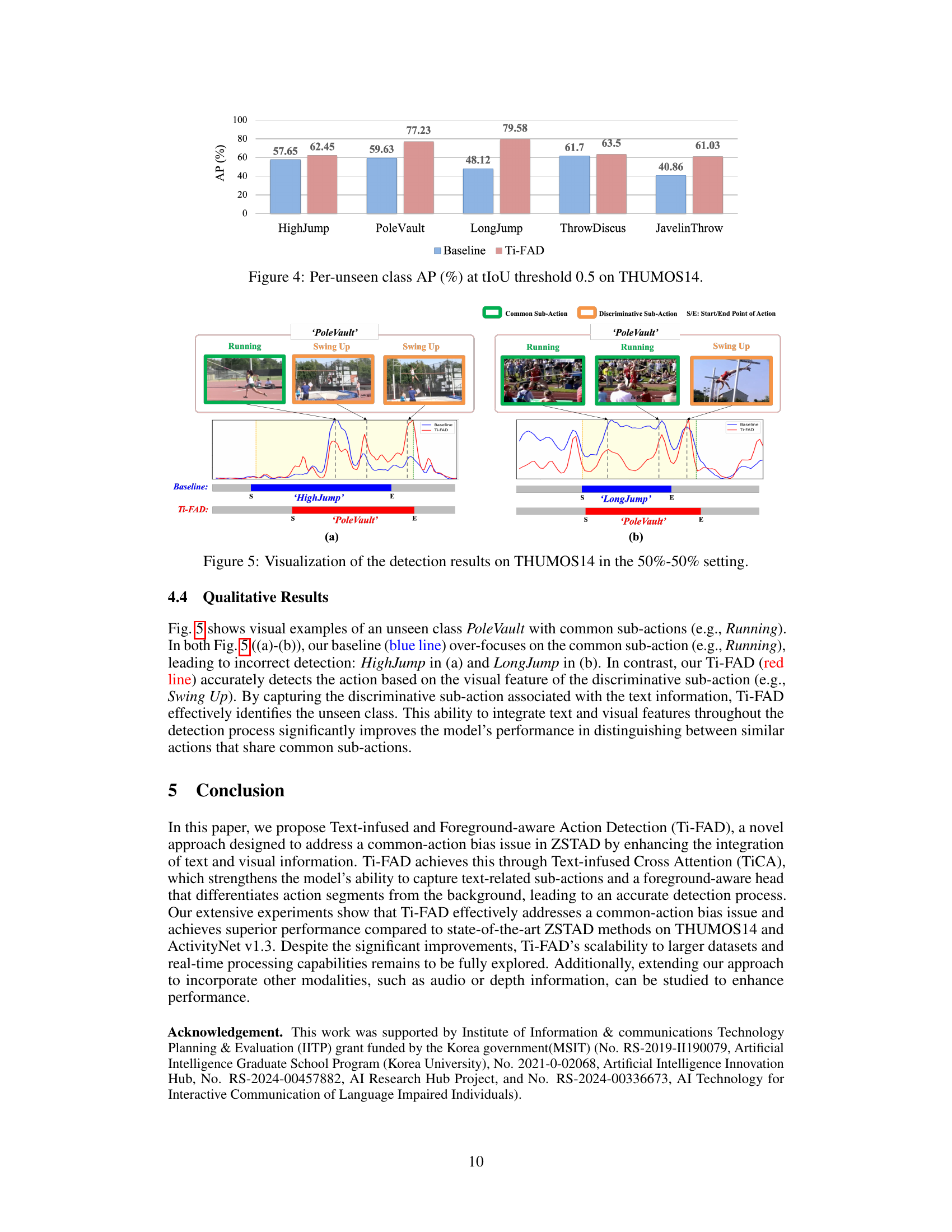
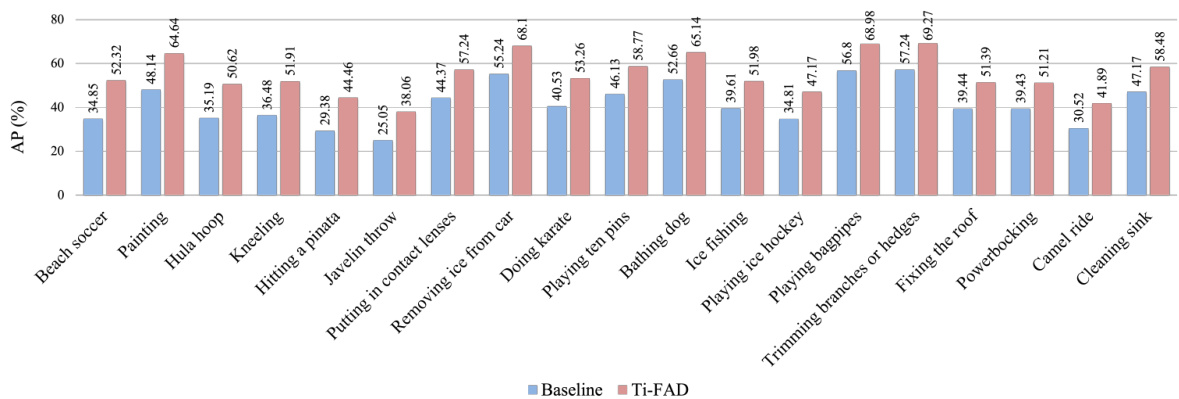
This bar chart compares the Average Precision (AP) at a threshold of 0.5 Intersection over Union (IoU) for the baseline model and the proposed Ti-FAD model across various unseen action classes in the THUMOS14 dataset. It highlights the performance improvement achieved by Ti-FAD, particularly in classes with common sub-actions, indicating its effectiveness in focusing on discriminative sub-actions. The higher AP values for Ti-FAD suggest its superior ability to accurately classify and localize unseen actions.
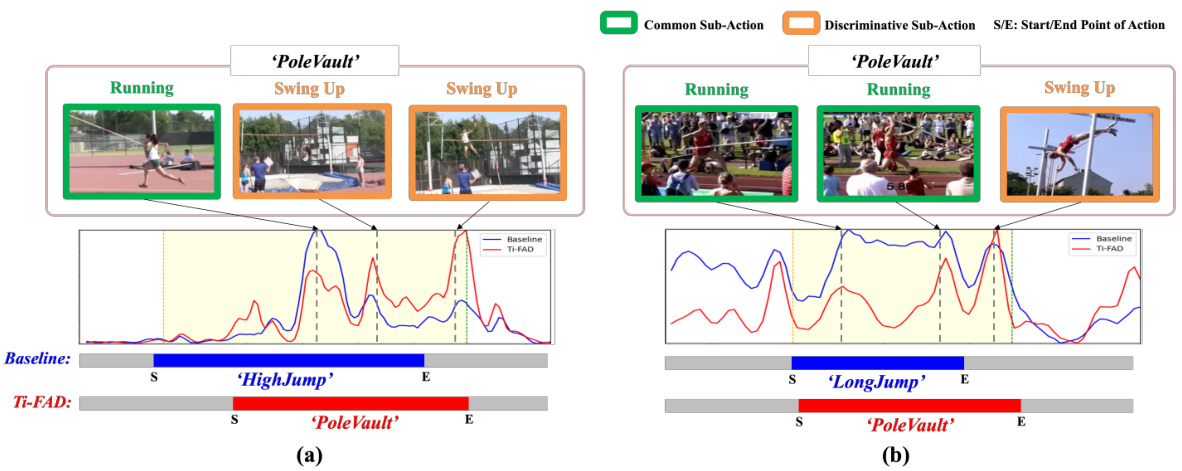
This figure compares the architecture of previous foreground-based ZSTAD methods with the proposed cross-modal baseline. The top part illustrates how previous methods integrate text and visual features only within foreground proposals, limiting the use of complete video information. The bottom part shows an example of ‘common-action bias,’ where the cross-modal baseline over-focuses on common sub-actions (e.g., ‘Running’) rather than distinguishing between discriminative sub-actions relevant to the text description (e.g., ‘Swing Up’ in Pole Vault). Ti-FAD’s improved ability to focus on the relevant parts is highlighted.
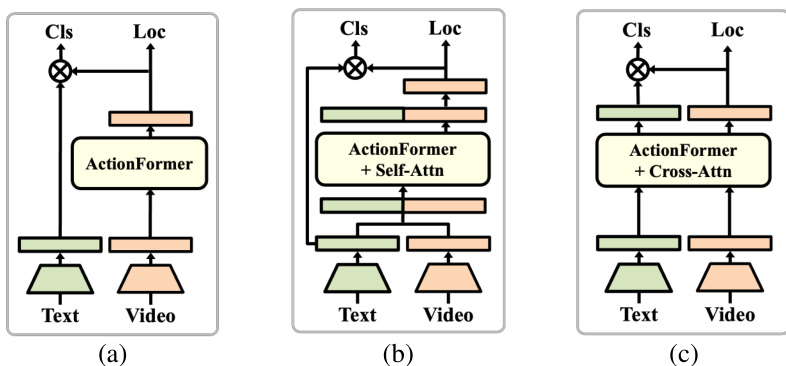
This figure illustrates three different baseline architectures used in the paper for comparison. (a) shows a standard ActionFormer without any cross-modal fusion. (b) depicts an ActionFormer enhanced with a self-attention mechanism for cross-modal integration. Finally, (c) presents the authors’ proposed cross-modal baseline, utilizing cross-attention for improved text and video feature fusion. The figure highlights the architectural differences in how text and video features are integrated, showcasing the progression towards the final model.
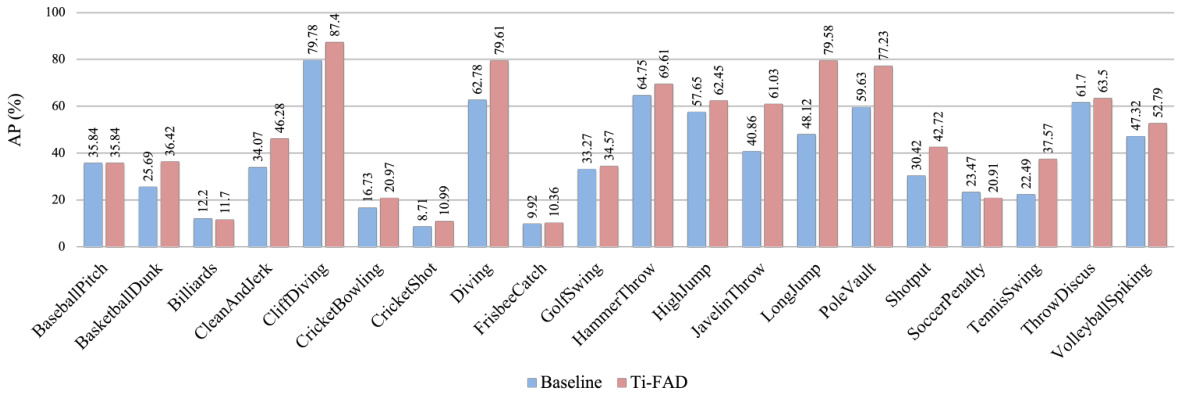
This bar chart compares the Average Precision (AP) at a threshold of 0.5 Intersection over Union (IoU) for each unseen action class in the THUMOS14 dataset, between the baseline model and the proposed Ti-FAD model. It highlights Ti-FAD’s improved performance, particularly for action classes with common sub-actions (e.g., Running).
This figure visually compares the performance of the proposed Ti-FAD model and the baseline model on the THUMOS14 dataset. It specifically focuses on the ‘Pole Vault’ action category, highlighting the differences in how each model identifies the action segments. The baseline model, shown in blue, struggles to accurately distinguish the ‘Pole Vault’ action from similar actions like ‘High Jump’ and ‘Long Jump’, focusing on the common sub-action of running. In contrast, the Ti-FAD model, displayed in red, is able to correctly identify the ‘Pole Vault’ action by focusing on the more discriminative sub-action (Swing Up), effectively demonstrating the ability of the text-infused attention mechanism to improve accuracy by highlighting text-relevant visual features.
More on tables
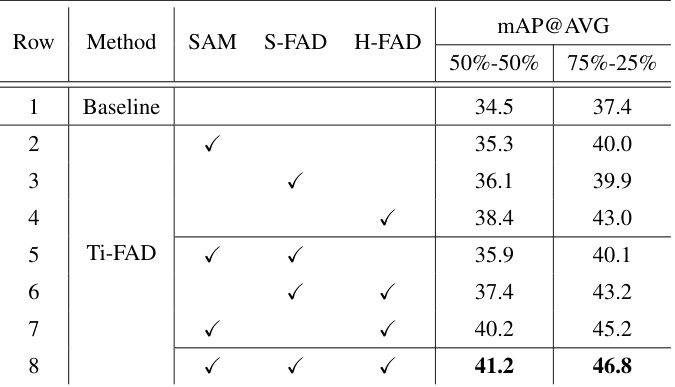
This table presents an ablation study evaluating the impact of individual components of the proposed Ti-FAD model on the THUMOS14 dataset. It shows the performance (mAP@AVG) under two different train/test split settings (50%-50% and 75%-25%) by incrementally adding components: SAM (Salient Attentive Mask), S-FAD (soft foreground-aware head), and H-FAD (hard foreground-aware head). Row 1 represents the baseline model without any of these additions, while subsequent rows progressively incorporate each component to show the contribution of each. The final row (8) displays the full Ti-FAD model’s performance.
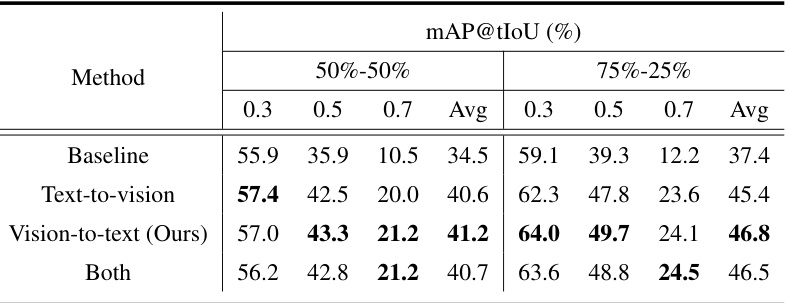
This table presents the results of an ablation study on the THUMOS14 dataset, investigating the impact of different cross-attention mechanisms within the TiCA module on the model’s performance. Specifically, it compares the performance when using only text-to-vision cross-attention, only vision-to-text cross-attention, and both, reporting the average mean Average Precision (mAP) at different Intersection over Union (IoU) thresholds (0.3, 0.5, and 0.7). The results help determine the optimal cross-attention strategy for the TiCA module.
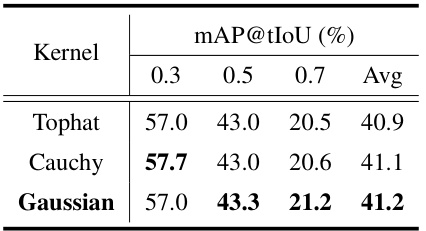
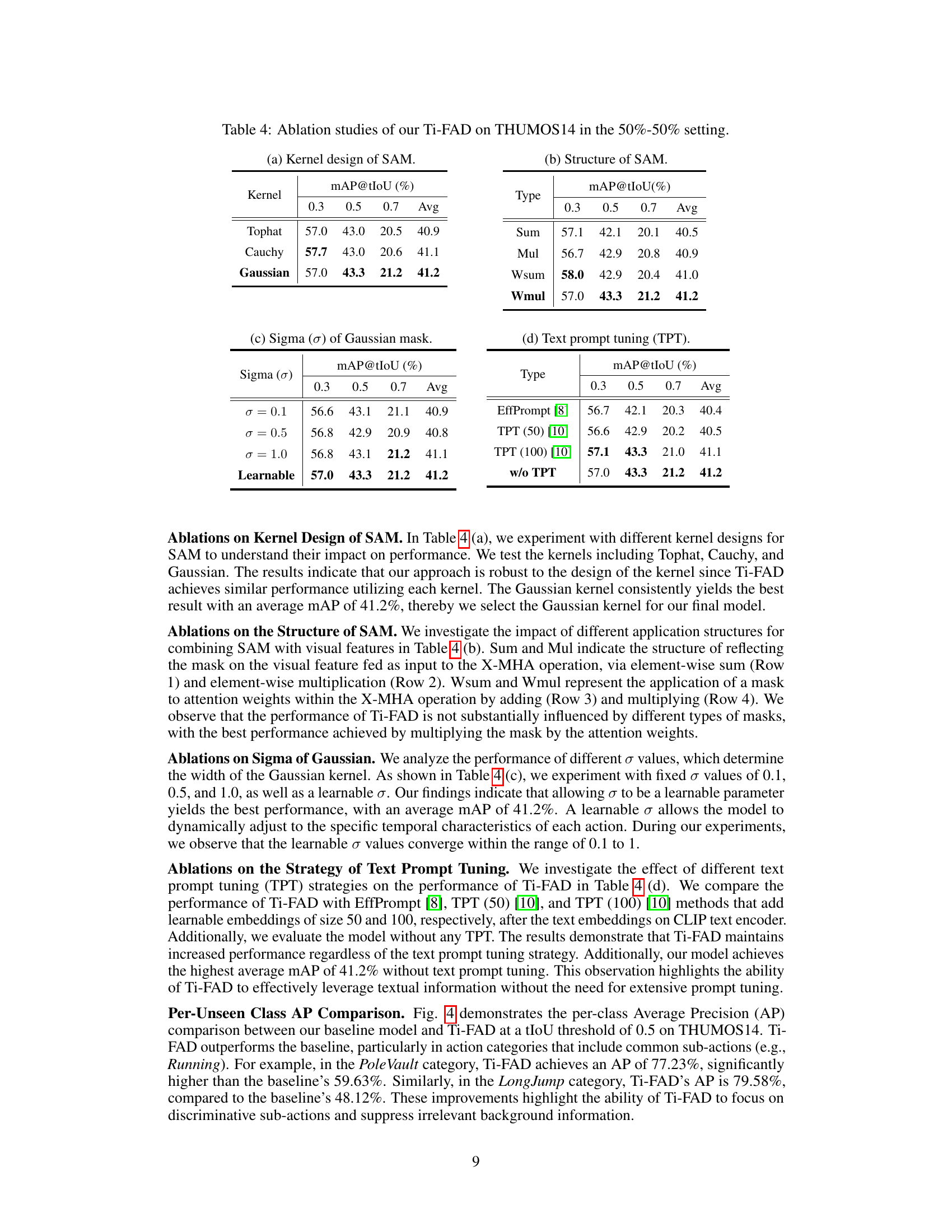
This table presents the ablation study results for the proposed Ti-FAD model on the THUMOS14 dataset under the 50%-50% split setting (50% of classes for training and the rest for testing). The study investigates different design choices of the model’s components by systematically removing or changing various features. Specifically, it looks at the impact of different kernel functions (Tophat, Cauchy, Gaussian) used for the Saliency Attentive Mask (SAM) and the effects of different ways of applying this mask to the cross-attention mechanism, as well as the impact of using fixed or learnable parameters for the Gaussian mask’s standard deviation (σ). The results show the average mean Average Precision (mAP) at different temporal Intersection over Union (tIoU) thresholds (0.3, 0.5, 0.7).
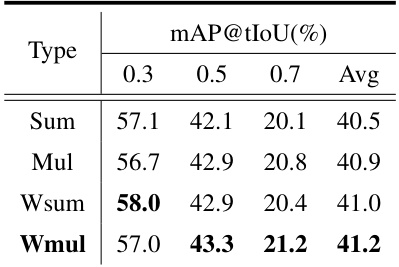
This table presents the ablation study results on the THUMOS14 dataset using the 50%-50% train/test split. It shows the impact of different design choices for the salient attentive mask (SAM) component of the Ti-FAD model on the mean average precision (mAP) at different intersection over union (IoU) thresholds (0.3, 0.5, 0.7). The table is organized to show the effects of different kernel types for SAM, different structures for combining SAM with visual features, different sigma values for the Gaussian kernel, and different text prompt tuning strategies.
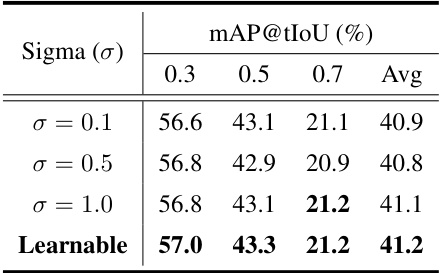
This table presents the ablation study results on the THUMOS14 dataset using a 50/50 train/test split. The study systematically investigates the impact of different design choices within the Ti-FAD model. Specifically, it examines the effects of varying the kernel design of the Saliency Attentive Mask (SAM), the structure used to incorporate SAM with visual features, the sigma (σ) values of the Gaussian mask used in SAM, and the impact of text prompt tuning strategies on model performance. Each row represents a different configuration, allowing readers to assess the contribution of each component to the overall model performance.
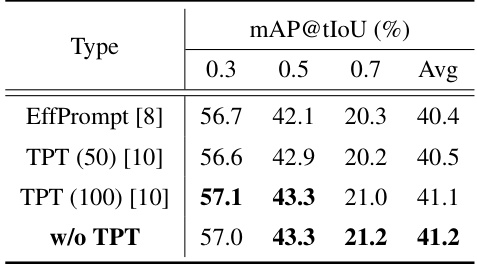
This table presents the ablation study results for the Ti-FAD model on the THUMOS14 dataset using a 50%-50% train-test split. It shows the impact of different design choices on the model’s performance, measured by mAP@tIoU at thresholds of 0.3, 0.5, and 0.7, and the average mAP across these thresholds. Specific ablation studies include variations in the kernel design for the Salient Attentive Mask (SAM), the structure of SAM, the sigma (σ) value of the Gaussian mask in SAM, and the use of text prompt tuning (TPT). This table helps to understand which design choices are crucial for the model’s performance and provides insights into the model’s robustness and the impact of various design elements.
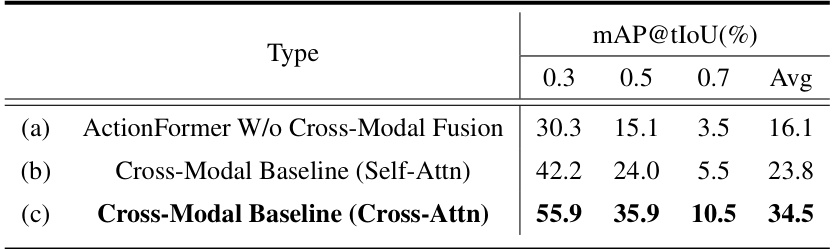
This table presents the ablation study of the cross-modal baseline on the THUMOS14 dataset. It compares the performance of three different models: (a) ActionFormer without cross-modal fusion, (b) a cross-modal baseline using self-attention, and (c) a cross-modal baseline using cross-attention. The results are reported in terms of mean average precision (mAP) at different intersection over union (IoU) thresholds (0.3, 0.5, 0.7). The table shows the significant impact of cross-modal fusion and the superior performance of cross-attention compared to self-attention for this task.
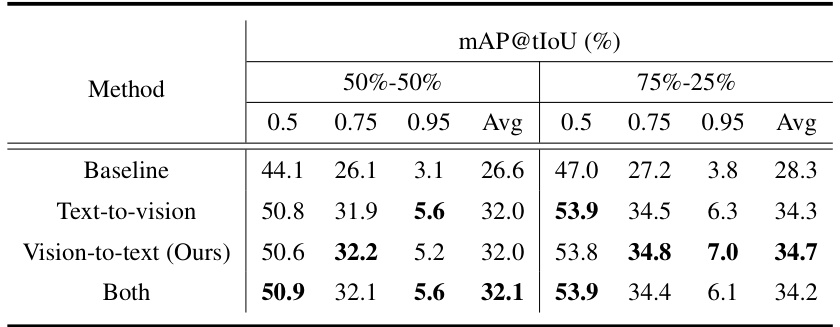
This table presents the results of an ablation study on the THUMOS14 dataset, investigating the impact of different cross-attention mechanisms within the TiCA (Text-infused Cross Attention) module. It compares the performance using text-to-vision, vision-to-text, and both directions of cross-attention, offering insights into the effectiveness of each approach and the optimal configuration for integrating text and video features.
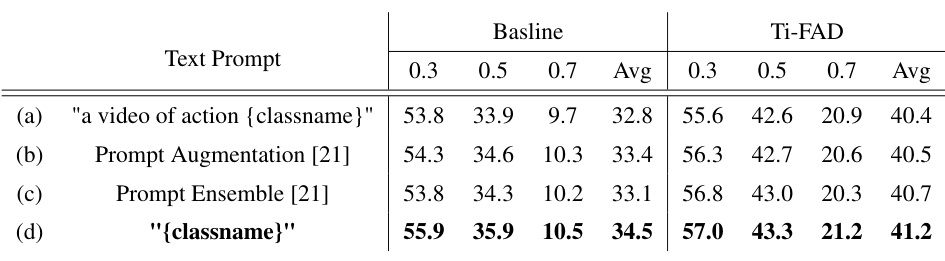
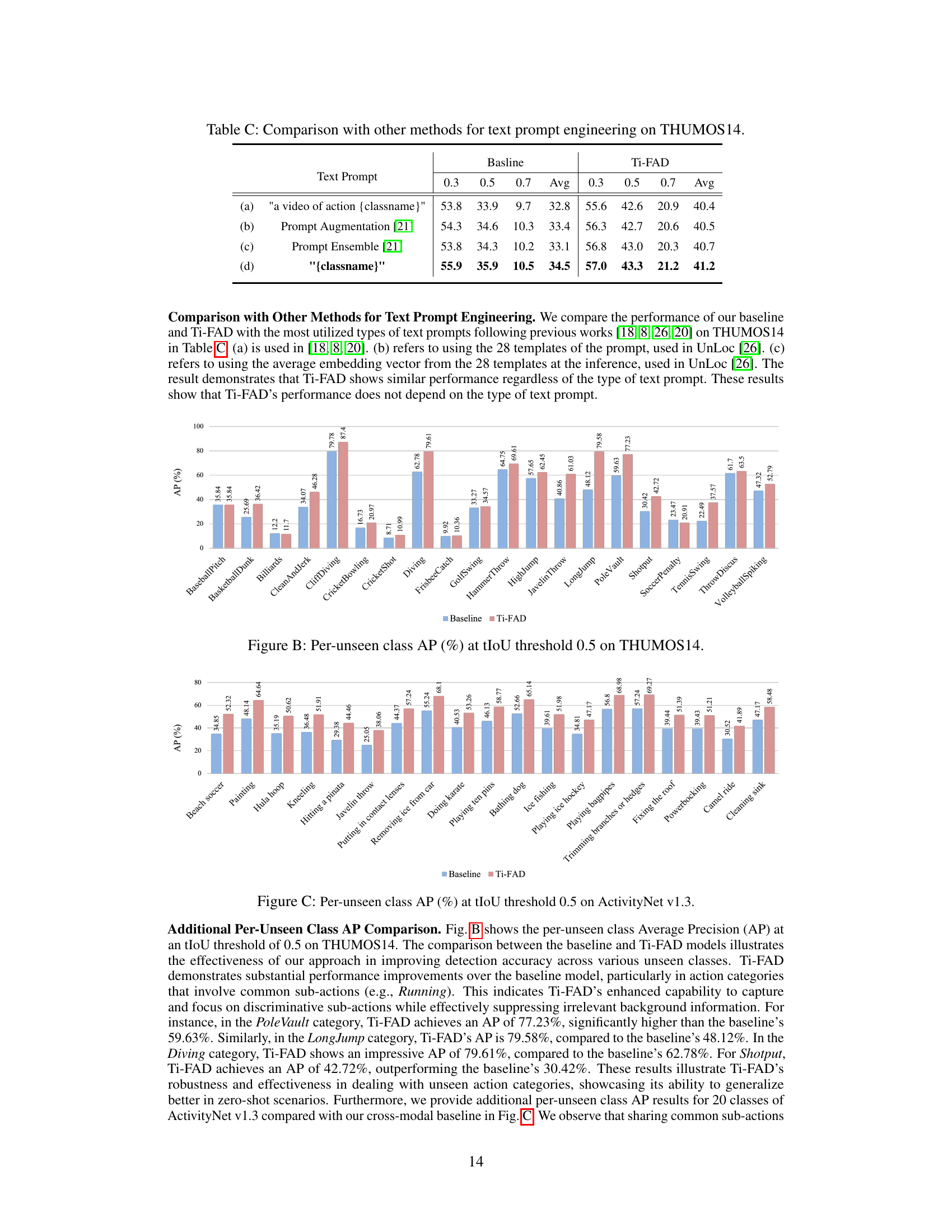
This table compares the performance of the proposed Ti-FAD model and its baseline with several other methods that use different text prompt engineering techniques on the THUMOS14 dataset. The different methods shown are: (a) a simple text prompt, (b) prompt augmentation, (c) prompt ensemble, and (d) the proposed method’s baseline. The table shows mAP values for different tIoU thresholds (0.3, 0.5, 0.7) and the average mAP. This allows for an assessment of how different prompt engineering approaches affect performance on zero-shot temporal action detection.
Full paper#