↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Many applications use language models to provide multiple auto-complete options, but generating each draft requires a separate inference pass, making it computationally expensive. This paper addresses this issue by introducing a significant problem in current methods that hinders efficiency and scalability in many applications.
The proposed solution is Superposed Decoding (SPD), a new algorithm that generates multiple drafts simultaneously during a single inference pass. SPD combines token embeddings from multiple drafts, filters out incoherent generations using n-gram interpolation, and significantly improves efficiency compared to existing methods. Experiments demonstrate that SPD is at least 2.44 times faster than Nucleus Sampling for k≥3 and achieves comparable or better coherence and factuality.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Superposed Decoding (SPD), a novel decoding algorithm that significantly speeds up the generation of multiple text drafts by language models. This addresses a critical limitation in many applications requiring diverse text outputs like autocomplete. SPD’s efficiency gains and improved user experience make it highly relevant to current research in efficient large language model inference and open up new avenues for optimizing text generation processes in various applications.
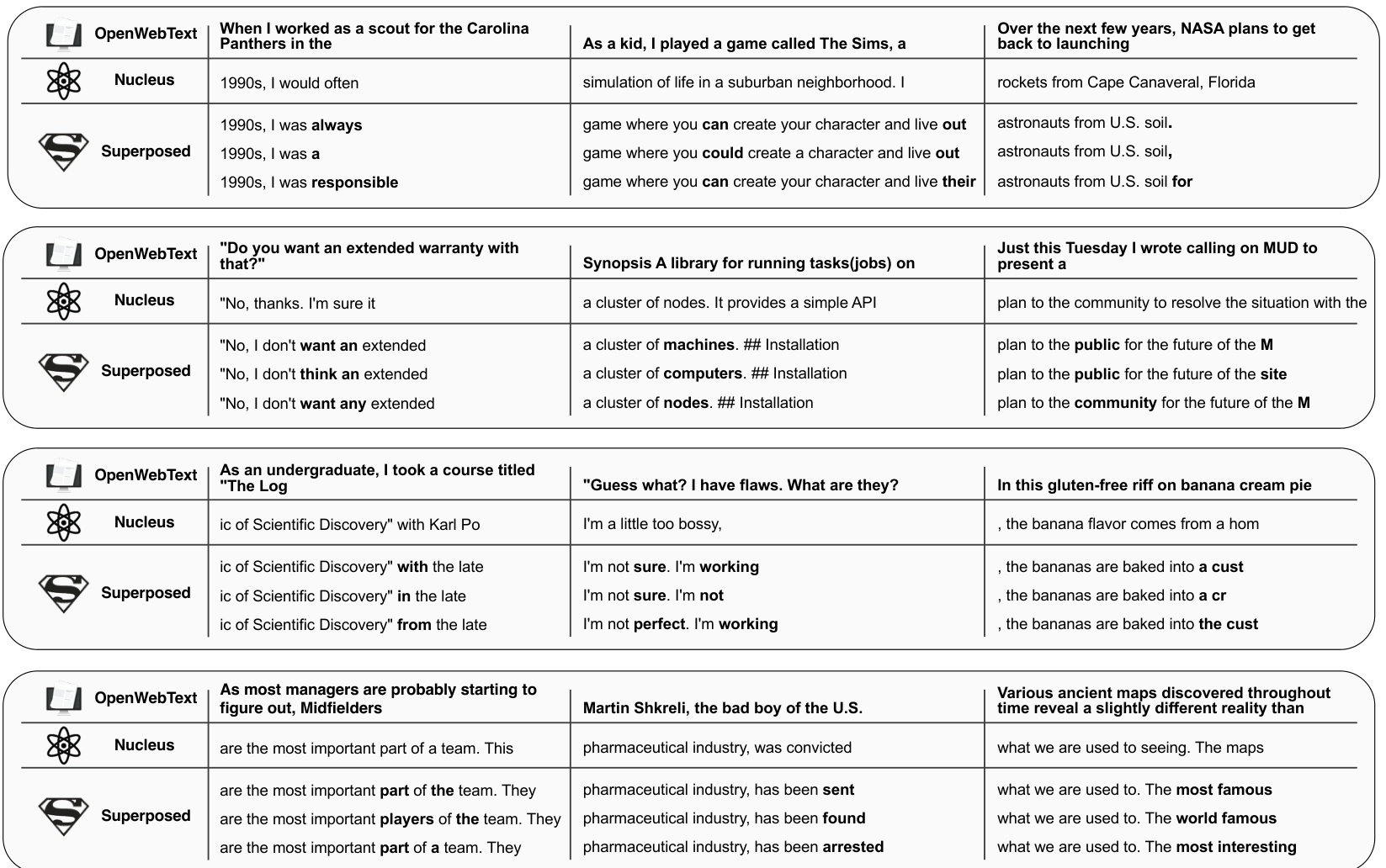
Visual Insights#
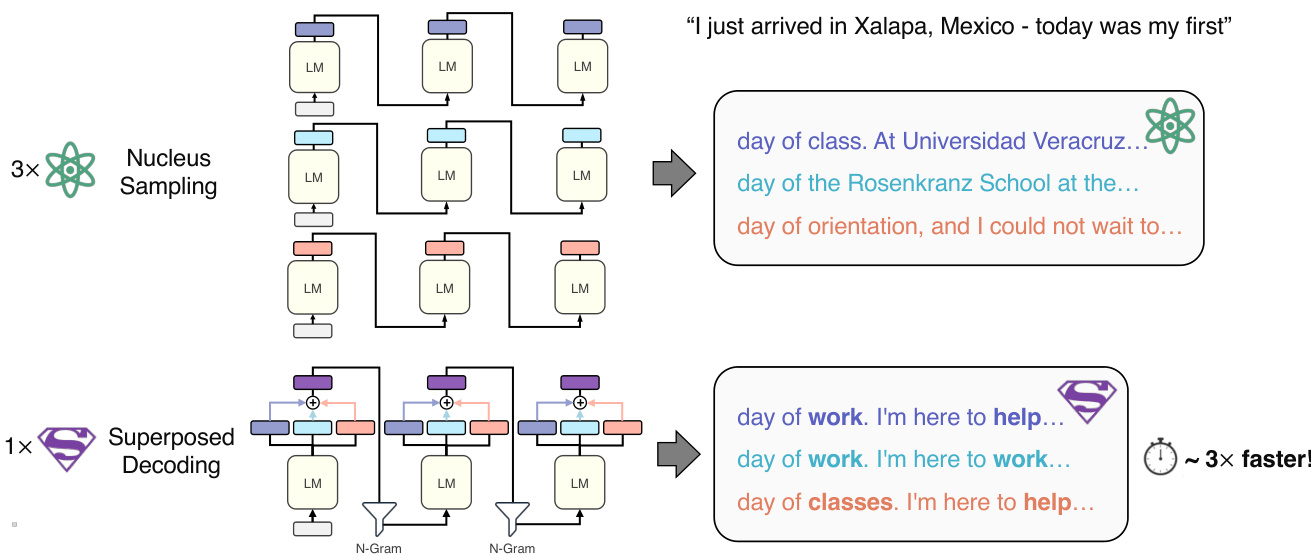
This figure illustrates the difference between traditional decoding methods (like Nucleus Sampling) and the proposed Superposed Decoding method. Traditional methods require running the language model k times to generate k different autocomplete suggestions. Superposed Decoding, however, achieves the same result with only a single inference pass of the language model, making it significantly faster while maintaining coherence and factuality.

This table presents the average perplexity scores for different decoding methods (Nucleus, Beam/Greedy, N-gram, and Superposed Decoding) across three generated drafts. It highlights that Superposed Decoding achieves a lower average perplexity than Nucleus Sampling, indicating that it generates text that is more similar to human writing in terms of its statistical properties. The table demonstrates that Superposed Decoding is competitive with other methods in terms of perplexity, a key metric for evaluating the quality and fluency of generated text.
In-depth insights#
Superposed Decoding#
Superposed Decoding presents a novel approach to autoregressive text generation, aiming to produce multiple coherent drafts from a single inference pass. Its core innovation lies in feeding a weighted superposition of recent token embeddings from all drafts as input to the language model at each decoding step. This contrasts with traditional methods like Nucleus Sampling, which require separate inference passes for each draft, significantly increasing computational cost. The superposition, combined with n-gram interpolation to filter incoherent generations, allows the model to concurrently explore multiple textual possibilities with a speed advantage. Experiments demonstrate comparable coherence and factuality to Nucleus Sampling and Greedy Decoding but at a significantly reduced computational cost. The method’s effectiveness seems to rely on the apparent linearity of representations in large language models, enabling efficient approximation of beam search behavior. While promising, further exploration is needed regarding potential limitations in long-form generation and semantic diversity.
LM Inference Speedup#
LM inference speedup is a critical area of research in large language models (LLMs). Reducing inference time directly impacts the cost and usability of LLMs, making them more accessible for various applications. Superposed Decoding, as presented in the research paper, offers a novel approach to this challenge. By cleverly combining token embeddings from multiple drafts simultaneously, it manages to generate k drafts with the computational cost of only one inference pass. This represents a significant speed improvement, especially when k is larger. However, the method relies on the linearity of representations within the LM. The paper explores this linearity empirically and demonstrates success with Llama 2, but this linearity might not hold universally across all LLMs. Further speed improvements could arise from optimizing the n-gram interpolation and leveraging techniques like suffix arrays for faster lookups. Ultimately, the success of Superposed Decoding hinges on the balance between speed gains and maintaining generation quality comparable to other methods like Nucleus Sampling. The potential of combining Superposed Decoding with other speedup strategies remains an exciting avenue for further research.
N-gram Interpolation#
N-gram interpolation, within the context of language model decoding, is a crucial technique for enhancing the quality and coherence of generated text. It addresses the limitations of solely relying on the language model’s probability distribution by incorporating information from n-gram language models. This interpolation effectively smooths the probability distribution, mitigating the risks of generating incoherent or nonsensical sequences. By weighing the probabilities from both the language model and the n-gram models, the method achieves a balance between leveraging the model’s long-range dependencies and incorporating the strong statistical regularities captured by n-grams. This approach is particularly valuable in scenarios with limited training data or when dealing with specialized domains. The effectiveness of n-gram interpolation hinges on carefully selecting appropriate n-gram model orders and interpolation weights. Finding optimal weights often involves experimentation and might necessitate domain-specific tuning. The computational cost of n-gram interpolation is generally low, making it a practical addition to decoding algorithms, particularly those aiming to generate multiple drafts. This makes the tradeoff of increased accuracy against computational complexity very favorable. However, careful consideration must be given to the size of the n-gram model, as larger models could strain memory and computational resources. In essence, n-gram interpolation is a powerful tool for enhancing text generation quality and fluency in language models by combining the strengths of neural networks and traditional n-gram statistics.
Human Evaluation#
The human evaluation section is crucial for validating the claims of the Superposed Decoding method. It addresses the limitations of relying solely on automatic metrics like perplexity, which don’t fully capture human perception of text quality. The study employs a controlled experiment on Amazon Mechanical Turk, where participants rank generations from Superposed Decoding against Nucleus Sampling. The focus on a compute-normalized setting acknowledges the computational advantage of SPD, ensuring a fair comparison. Results show a preference for Superposed Decoding, highlighting the value of its multiple drafts, even when the total compute is similar to that used by Nucleus Sampling. The inclusion of additional studies with varied comparisons (2v3, 1v1) strengthens the findings and reveals robustness across different compute ratios. Overall, human evaluation provides essential qualitative evidence, complementing the quantitative analysis and ultimately validating the practical benefits and user preference for Superposed Decoding over alternative methods.
Future Work#
Future research directions stemming from this work on Superposed Decoding could explore several promising avenues. Improving the coherence and diversity of generated texts remains a key challenge; investigating more sophisticated methods for smoothing the superposition of token embeddings, or employing alternative superposition techniques, could yield significant improvements. Additionally, extending Superposed Decoding to longer sequences is crucial. The current approach, while efficient for short-form generation, may encounter challenges with longer texts. This could involve incorporating techniques like resetting the superposition to enhance long-term consistency. Furthermore, in-depth investigation into the linearity assumption underlying Superposed Decoding is necessary. While empirical evidence suggests its validity within certain limits, a theoretical underpinning would strengthen the method’s foundation. Finally, exploring the compatibility of Superposed Decoding with various language models and decoding algorithms offers exciting potential for generalizability and broader impact. Thorough experimentation across different model architectures, and its combination with other techniques, would establish its versatility and robustness. In essence, refining the smoothing method, addressing longer-sequence generation, solidifying the theoretical base, and evaluating broader applicability are key directions for future research on Superposed Decoding.
More visual insights#
More on figures

This figure illustrates the Superposed Decoding algorithm. It starts with k initial drafts. At each step, the algorithm creates a ‘superposition’ of the embeddings of the most recent tokens from all k drafts. This superposition is fed into the language model to generate k*k new draft options. Then, n-gram interpolation is used to select the top-k most likely options, which become the new set of k drafts for the next iteration. This process continues until the desired generation length is reached.

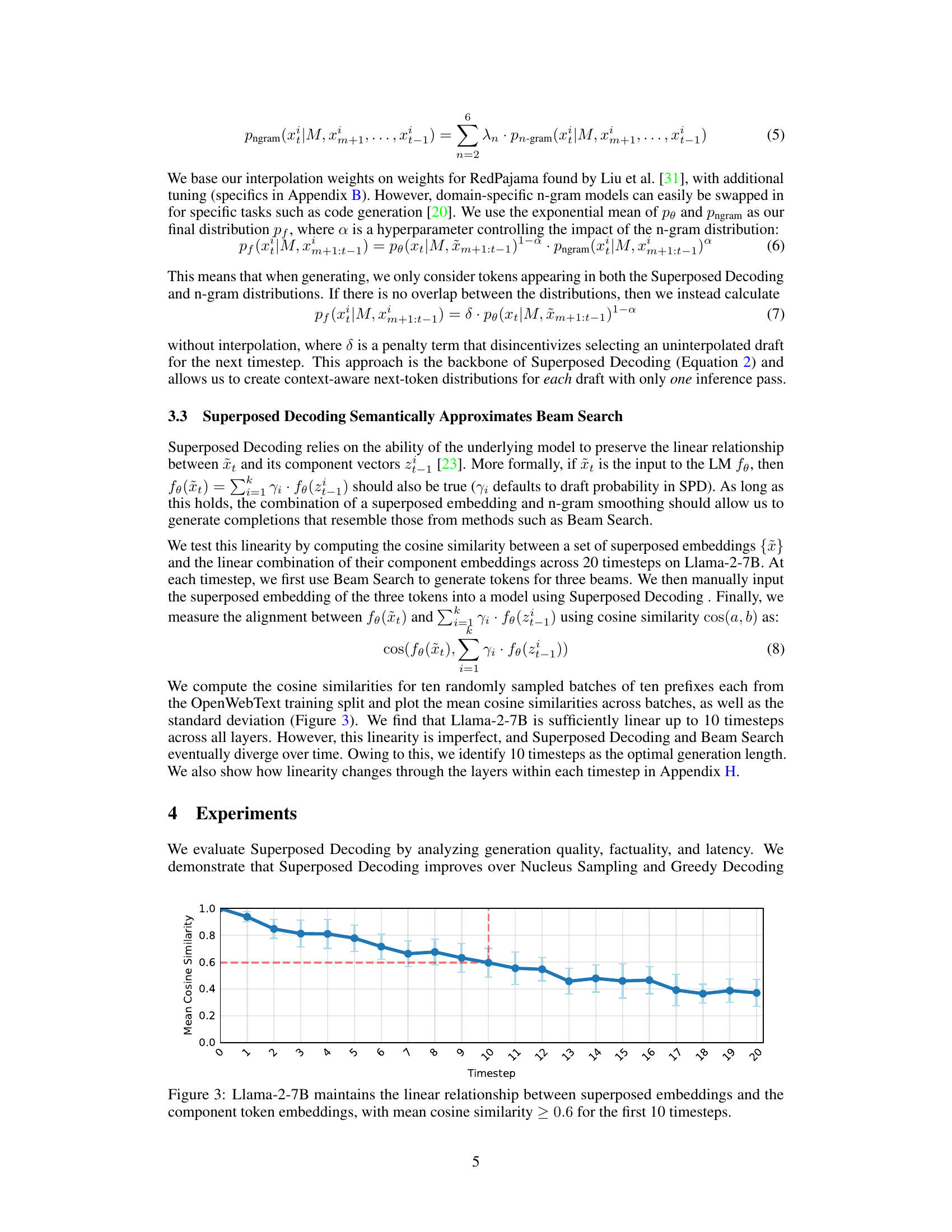
This figure shows the results of an experiment testing the linearity of Llama-2-7B. The experiment measured the cosine similarity between superposed embeddings (a weighted combination of token embeddings from multiple drafts) and the sum of their individual component token embeddings across 20 timesteps. The results show that Llama-2-7B maintains a relatively high cosine similarity (above 0.6) for the first 10 timesteps, indicating a linear relationship between the superposed embeddings and their components. After 10 timesteps, the linearity begins to decrease. This supports the Superposed Decoding method, which relies on this linear relationship to generate multiple text drafts efficiently.
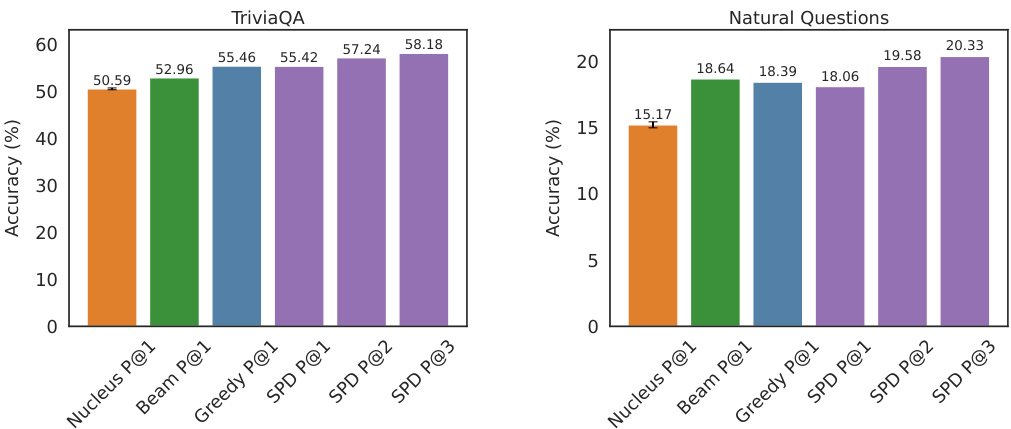
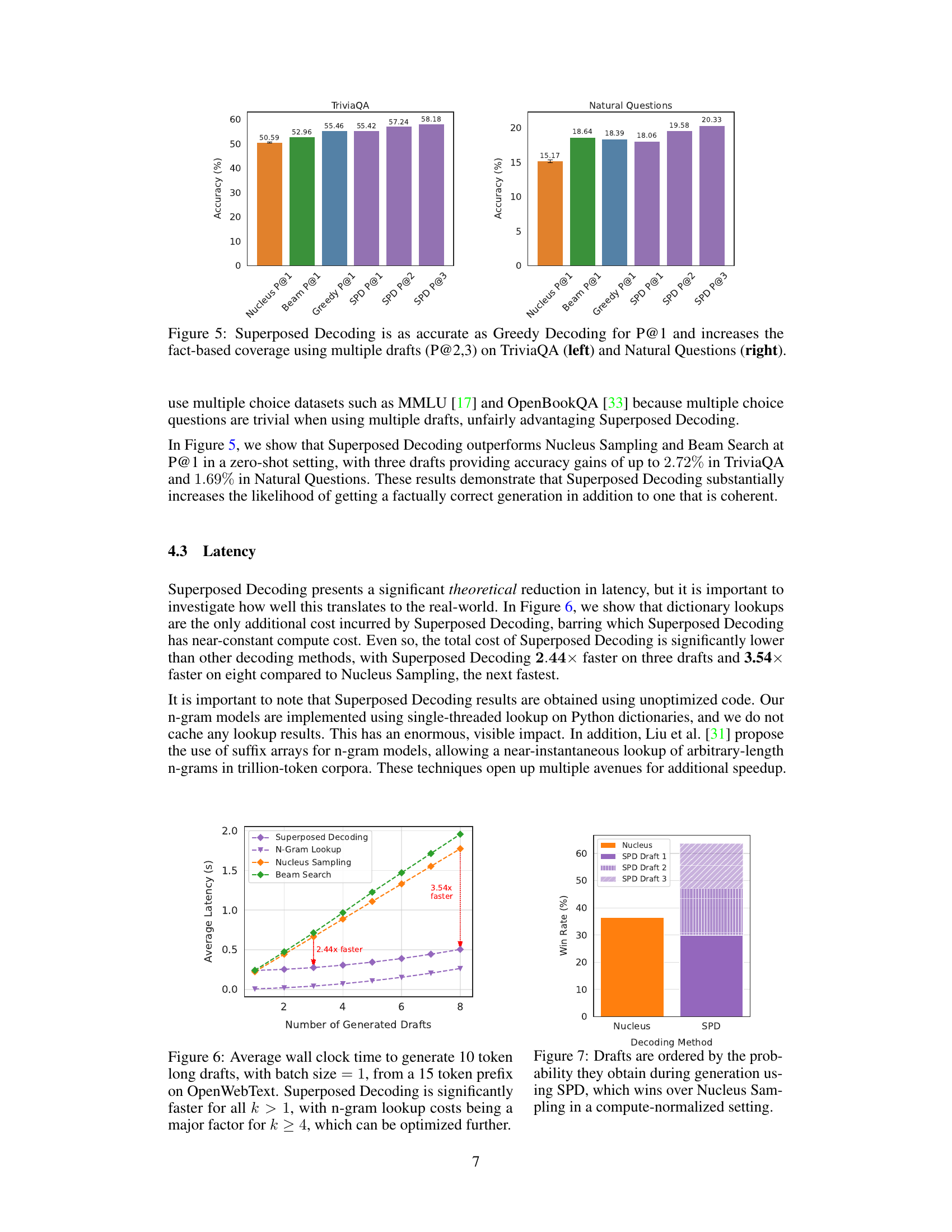
This figure shows the accuracy of different decoding methods (Nucleus, Beam, Greedy, and Superposed Decoding) on two common benchmarks for short-answer generation: TriviaQA and Natural Questions. The accuracy is measured by exact match precision at k (P@k), where k represents the number of generated drafts considered. The figure demonstrates that Superposed Decoding achieves similar or better accuracy compared to Greedy Decoding for P@1 (considering only the best draft) and shows significantly higher accuracy for P@2 and P@3 (considering the top 2 and top 3 drafts, respectively), indicating that generating multiple drafts improves the likelihood of obtaining a correct answer. This highlights Superposed Decoding’s ability to increase fact-based coverage by generating multiple drafts.

The figure shows the average latency in seconds for generating different numbers of drafts (k) using various decoding methods: Superposed Decoding, Nucleus Sampling, and Beam Search. Superposed Decoding consistently shows significantly lower latency compared to other methods, especially as the number of drafts increases. The increase in latency for all methods is roughly linear as k increases. A notable aspect is the influence of n-gram lookup cost on the latency of Superposed Decoding for larger k values. This suggests that optimization of n-gram lookup could lead to even greater speed improvements for Superposed Decoding.
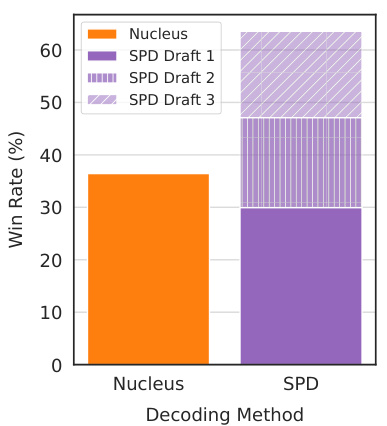
This figure displays the results of a user study comparing Superposed Decoding (SPD) and Nucleus Sampling in a compute-normalized setting. The x-axis represents the decoding method used (Nucleus or SPD), while the y-axis shows the win rate (percentage of times the method’s generation was preferred). The figure shows that SPD outperforms Nucleus Sampling when considering the compute used to generate drafts. The chart also breaks down individual draft rankings for SPD, demonstrating that, on average, at least one of SPD’s drafts is preferred to the Nucleus Sampling draft. The overall better performance of SPD indicates the usefulness of generating multiple drafts, even if only one is ultimately selected by the user.
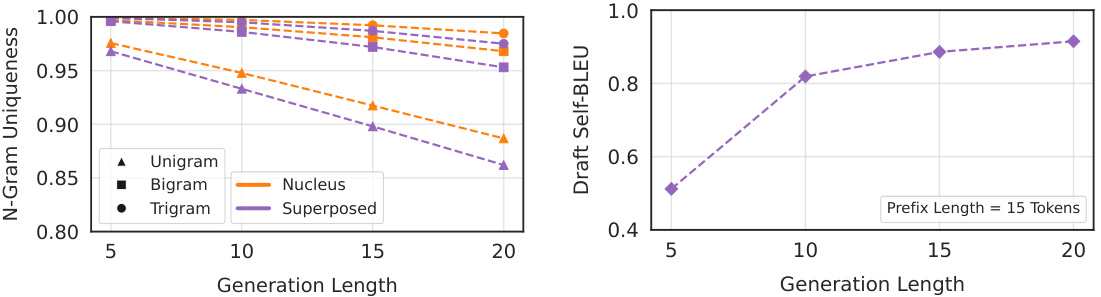
The figure is composed of two subfigures. The left subfigure shows the n-gram uniqueness for different generation lengths. The right subfigure shows the draft self-BLEU score for different generation lengths. Both subfigures compare Superposed Decoding with Nucleus Sampling. The left subfigure shows that Superposed Decoding and Nucleus Sampling have similar levels of repetition for short generations. The right subfigure shows that shorter generations lead to higher diversity (lower Self-BLEU scores) for both methods.

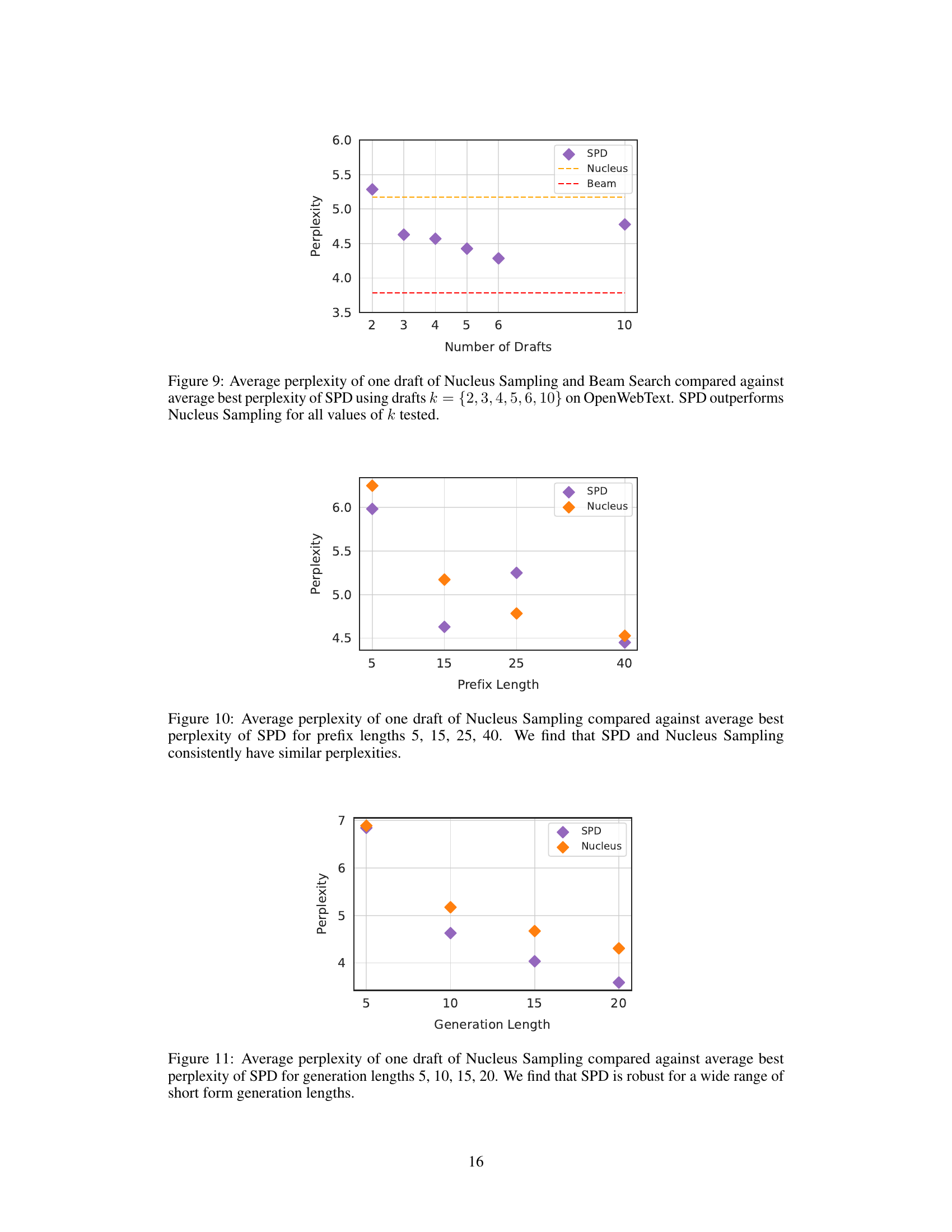
This figure shows the average perplexity for one draft generated by Nucleus Sampling and Beam Search methods, compared to the average best perplexity achieved by Superposed Decoding (SPD) for different numbers of drafts (k). The results demonstrate that SPD consistently outperforms Nucleus Sampling across all tested values of k, indicating that SPD is more efficient in generating high-quality text.

This figure shows the average perplexities of single drafts generated by Nucleus Sampling and the best draft generated by Superposed Decoding (SPD) for different prefix lengths. The results indicate that the average perplexity of SPD’s best draft is comparable to that of Nucleus Sampling across various prefix lengths, demonstrating the comparable quality of SPD’s generated text. The y-axis represents perplexity, and the x-axis represents the length of the input prefix.

This figure compares the average perplexity of a single draft generated by Nucleus Sampling and Beam Search against the average best perplexity achieved by Superposed Decoding (SPD) across varying numbers of drafts (k). The results demonstrate that SPD consistently achieves lower perplexity than Nucleus Sampling, indicating superior generation quality, for all tested values of k.

This figure shows the results of a human evaluation comparing Superposed Decoding (SPD) and Nucleus Sampling. The bar chart displays the win rate for each method in a compute-normalized setting, where the number of generations from each method are balanced to equate computational cost. SPD outperforms Nucleus Sampling in this setting, indicating that the diversity of outputs produced by SPD is preferred by users.

This figure illustrates the difference between traditional decoding methods (like Nucleus Sampling) and the proposed Superposed Decoding method. Traditional methods require multiple passes of the language model to generate multiple text suggestions (k suggestions require k passes). In contrast, Superposed Decoding generates k suggestions in a single pass, achieving comparable coherence and factuality.
The figure illustrates the difference between traditional decoding methods (like Nucleus Sampling) and the proposed Superposed Decoding method in generating multiple auto-complete suggestions. Traditional methods require running the language model k times (where k is the number of suggestions) to produce k suggestions. Superposed Decoding, in contrast, achieves the same outcome with a single language model inference pass, resulting in significant computational savings while maintaining coherence and factual accuracy.

This figure illustrates the core difference between traditional decoding methods (like Nucleus Sampling) and the proposed Superposed Decoding method. Traditional methods require running the language model multiple times to generate multiple auto-complete suggestions (one pass per suggestion). Superposed Decoding, however, achieves the same result in a single pass, making it significantly more efficient while maintaining coherence and factual accuracy.

This figure shows the layer-wise linearity analysis for the first five time steps on Llama-2-7B language model with three tokens. The x-axis represents the layers of the model, and the y-axis represents the mean cosine similarity between superposed embeddings and the linear combination of their component embeddings. The plot shows that the relationship between these two is initially highly linear, then it deteriorates in the first few layers before recovering gradually in subsequent layers.
More on tables

This table presents a comparison of the average perplexity scores achieved by different decoding methods, including Nucleus Sampling, Beam Search/Greedy Decoding, N-gram, and Superposed Decoding. The perplexity is a measure of how well a language model predicts a given sequence of words, with lower scores indicating better prediction and fluency. The table shows that Superposed Decoding achieves a lower average perplexity than Nucleus Sampling and is on par with the best draft of the Superposed Decoding method. This suggests that Superposed Decoding generates more natural-sounding text compared to the baseline method.

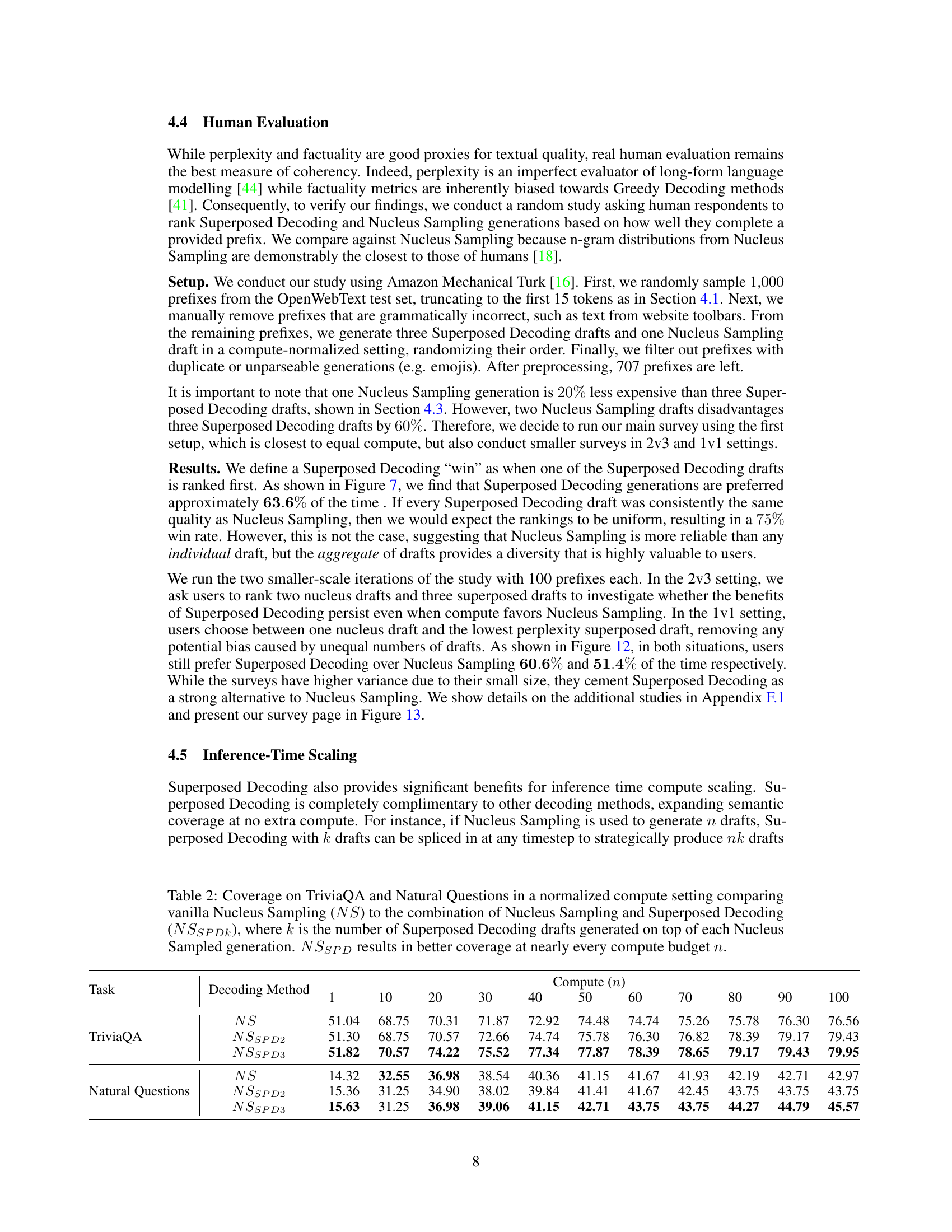
This table presents the results of an experiment comparing the coverage of two decoding methods: vanilla Nucleus Sampling (NS) and a combination of Nucleus Sampling and Superposed Decoding (NSSPDK). The experiment evaluates performance on two question answering datasets, TriviaQA and Natural Questions, across various compute budgets (n). NSSPDK consistently demonstrates improved coverage compared to NS for different numbers of Superposed Decoding drafts (k) added on top of the Nucleus Sampling drafts. The results show that combining both methods yields better overall coverage.

This table presents the average perplexity scores achieved by Nucleus sampling and Superposed decoding on the Mistral 7B language model. The perplexity is a measure of how well the generated text matches human language. Lower perplexity indicates better fluency and coherence. The table shows that Superposed Decoding, despite producing multiple drafts, achieves comparable average perplexity to Nucleus sampling, and in its best-performing draft, even outperforms Nucleus sampling. This demonstrates the generalizability of the Superposed decoding approach across different language models.

This table presents the average perplexity scores for different decoding methods, including Superposed Decoding, Nucleus Sampling, and Greedy Decoding. The perplexity metric measures how well a language model predicts a sequence of words. Lower perplexity generally indicates better generation quality, and the table shows that Superposed Decoding achieves comparable or better perplexity to the other methods, particularly when considering the ‘best’ draft among multiple generations. The results suggest Superposed Decoding generates text that is as natural sounding as human writing and achieves comparable quality.

This table compares the average perplexity scores achieved by different decoding methods on a dataset of text generation tasks. The methods compared are Nucleus Sampling, Beam Search/Greedy Decoding, N-gram, and Superposed Decoding. For each method (except Superposed Decoding), a single draft’s perplexity is reported. For Superposed Decoding, perplexities for three individual drafts and the best of the three drafts are provided. The table shows that Superposed Decoding achieves comparable or better average perplexity than Nucleus Sampling, while significantly outperforming other methods like N-gram.

This table presents the standard deviation of generation perplexities for different decoding methods, including Nucleus Sampling, Beam Search/Greedy Decoding, N-gram, and Superposed Decoding. The perplexities were calculated on the OpenWebText test split, as detailed in Section 4.1 of the paper. The data shows the variability in perplexity scores across different drafts generated by each method.

This table presents the standard deviation of perplexity scores for generations produced by Nucleus Sampling and Superposed Decoding on the Mistral 7B language model. The perplexity values were calculated on the OpenWebText test set, as detailed in Section 5.1 of the paper. The table shows that Superposed Decoding, while having a lower average perplexity in the main study, exhibits higher standard deviations compared to Nucleus Sampling. This indicates that Superposed Decoding’s generation quality might vary more widely across different inputs compared to Nucleus Sampling.
Full paper#