↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) have revolutionized natural language processing, but their high inference latency hinders real-time applications. Blockwise parallel decoding (BPD) offers a promising solution by predicting multiple tokens simultaneously, but the quality of these predictions needs improvement. Existing methods often struggle to produce fluent and natural outputs, limiting the practical effectiveness of BPD.
This work delves into improving BPD. The researchers analyze token distributions across prediction heads in LLMs and propose novel algorithms to enhance the quality of block drafts. This is done by leveraging lightweight task-independent n-gram and neural language models as rescorers. Experiments show that these refined drafts lead to a substantial increase in accepted tokens (5-25%), resulting in a remarkable over 3x speedup in inference time compared to standard autoregressive decoding in open-source LLMs. The findings demonstrate the effectiveness of this approach in accelerating inference, overcoming current limitations of BPD.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs) because it tackles the critical issue of slow inference speeds, a major bottleneck in deploying LLMs for real-time applications. The proposed methods for accelerating blockwise parallel decoding offer significant potential for improving LLM efficiency, opening new avenues of research in optimizing LLM inference and broadening LLM accessibility. The findings are highly relevant to the current focus on making LLMs more computationally efficient.
Visual Insights#
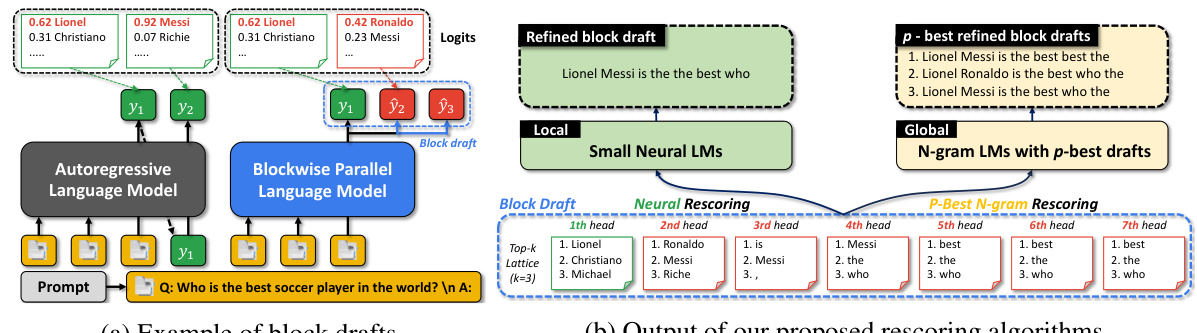
This figure compares autoregressive decoding with blockwise parallel decoding (BPD). Panel (a) shows how autoregressive decoding generates one token at a time, while BPD generates multiple tokens (a block draft) in parallel. Panel (b) illustrates how the proposed rescoring algorithms refine these block drafts by using local neural or global n-gram language models to select the most probable sequences from a top-k lattice, leading to improved decoding speed.
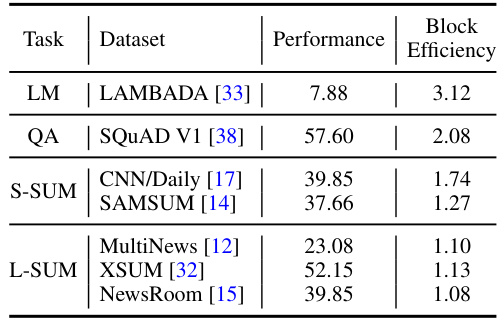
This table presents the performance and block efficiency of different language models across various tasks. The tasks include Language Modeling (LAMBADA), Question Answering (SQuAD v1), and Summarization (CNN/DailyMail, SAMSUM, MultiNews, XSUM, Newsroom). For each task, the table shows the performance metric (perplexity for LM, exact match for QA, ROUGE-L for summarization) and the block efficiency. Block efficiency indicates the average number of tokens decoded per serial call to the blockwise parallel language model.
In-depth insights#
BPD Draft Refinement#
The core concept of “BPD Draft Refinement” revolves around enhancing the efficiency of Blockwise Parallel Decoding (BPD) in large language models (LLMs). Standard BPD suffers from generating suboptimal drafts, impacting overall speed. Refinement techniques aim to improve these drafts’ quality by leveraging lightweight rescorers, such as n-gram or small neural language models. This process filters and reranks initial draft predictions, selecting the most probable and fluent sequences for verification by the autoregressive model. The key advantage is a considerable reduction in latency without modifying the core LLM architecture. The effectiveness of different rescoring methods is analyzed, comparing neural versus n-gram approaches, revealing task-specific performance variations. The study highlights a trade-off between model complexity and efficiency gains, showing that the choice of rescorer depends heavily on factors such as initial draft quality and task characteristics. Ultimately, the strategy shows promise in significantly accelerating LLM inference.
Block Draft Analysis#
Analyzing block drafts involves investigating the properties of token sequences generated by multiple prediction heads in parallel. Consecutive token repetition is a key phenomenon to analyze, as it reveals the independence of head predictions, and thus potential fluency issues. The confidence levels of different heads provide additional insight into draft quality, potentially highlighting the reliability of early tokens versus later ones. Measuring oracle efficiency (the performance of a hypothetical perfect draft selection) quantifies the theoretical potential for improvements and sets a benchmark for algorithms aiming to refine drafts. Understanding these characteristics is critical for developing algorithms that enhance the speed and quality of blockwise parallel decoding in large language models. Lightweight rescoring methods, using n-gram or neural language models, offer potential avenues for improving both efficiency and fluency, by leveraging the strengths of fast rescorers to improve the consistency of independently generated drafts.
Lightweight Rescoring#
Lightweight rescoring, in the context of accelerating language model inference, focuses on improving the quality of blockwise parallel decoding (BPD) drafts using computationally inexpensive methods. The core idea is to refine initially generated text blocks (drafts) without significantly increasing the overall computational cost. This is achieved by leveraging lightweight models like small neural networks or n-gram language models to rescore the candidate drafts. These lightweight models act as efficient filters, prioritizing fluent and contextually appropriate sequences. The key advantage is the speed boost, enabling faster inference speeds compared to standard autoregressive decoding. However, the effectiveness of lightweight rescoring depends heavily on the initial quality of the BPD drafts and the choice of the rescoring method. Careful consideration of the trade-off between accuracy and speed is essential. While n-gram approaches offer efficiency due to their simplicity, neural methods could potentially provide greater accuracy, although at a higher computational cost. The success of this technique hinges on the ability to significantly increase the acceptance rate of the refined drafts, maximizing the latency reduction without sacrificing the quality of the generated text.
Open-Source LLMs#
The rise of open-source Large Language Models (LLMs) is a paradigm shift in the field of AI, democratizing access to powerful language technologies and fostering collaboration. Open-source LLMs reduce the barrier to entry for researchers and developers, enabling them to experiment, innovate, and contribute to the advancement of the field without the constraints of proprietary models. This fosters greater transparency and allows for more robust scrutiny of model behavior and potential biases. However, the open-source landscape also presents challenges. Maintaining the quality and security of open models requires a significant community effort and a robust infrastructure for collaboration. Addressing issues of bias, misinformation, and potential malicious use is crucial in ensuring the responsible development and deployment of open-source LLMs. Furthermore, the open-source environment can also present challenges in terms of licensing and sustainability, especially when dealing with computationally intensive models requiring significant resources.
Future Work#
The paper’s “Future Work” section outlines several promising avenues for enhancing blockwise parallel decoding (BPD). Improving the block drafter’s training is key, potentially through combining lattice rescoring with alternative sampling strategies or incorporating sequential entropy head ordering. Scaling BPD to larger language models (LLMs) is another priority, possibly by adapting the architecture to handle the increased computational demands of such models. More sophisticated training methods could also enhance drafting head performance. Finally, the authors suggest exploring how to leverage the sequential entropy ordering of heads to further optimize the training process, and potentially improve the ability to integrate rescoring LMs more effectively.
More visual insights#
More on figures

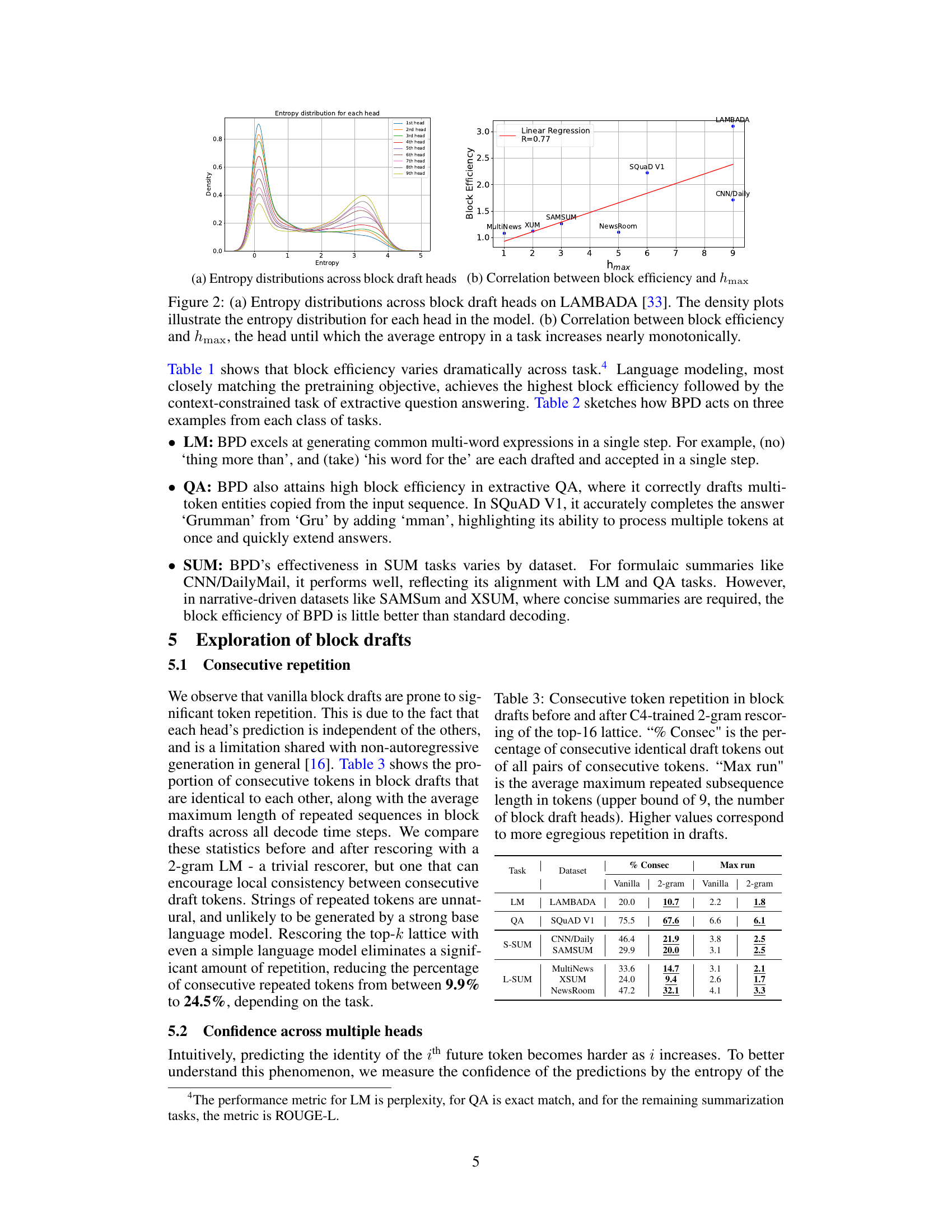
This figure shows two plots. Plot (a) shows the distribution of entropy for each prediction head in a blockwise parallel language model on the LAMBADA dataset. The x-axis represents entropy, and the y-axis represents density. Each line represents a different head, showing how the entropy (uncertainty) changes across heads. Plot (b) shows the correlation between block efficiency (a measure of how quickly the model decodes text) and hmax (the last head where the average entropy increases monotonically). This demonstrates that the confidence of the prediction heads in blockwise parallel language models correlates with block efficiency.

This figure shows a comparison between autoregressive decoding and blockwise parallel decoding (BPD). (a) illustrates how autoregressive decoding generates tokens sequentially, while BPD predicts multiple tokens simultaneously (block drafts). (b) demonstrates the authors’ proposed rescoring methods which improve BPD by refining block drafts using either neural or n-gram language models. These methods select the most likely token sequences for verification by the base autoregressive language model, leading to faster inference.

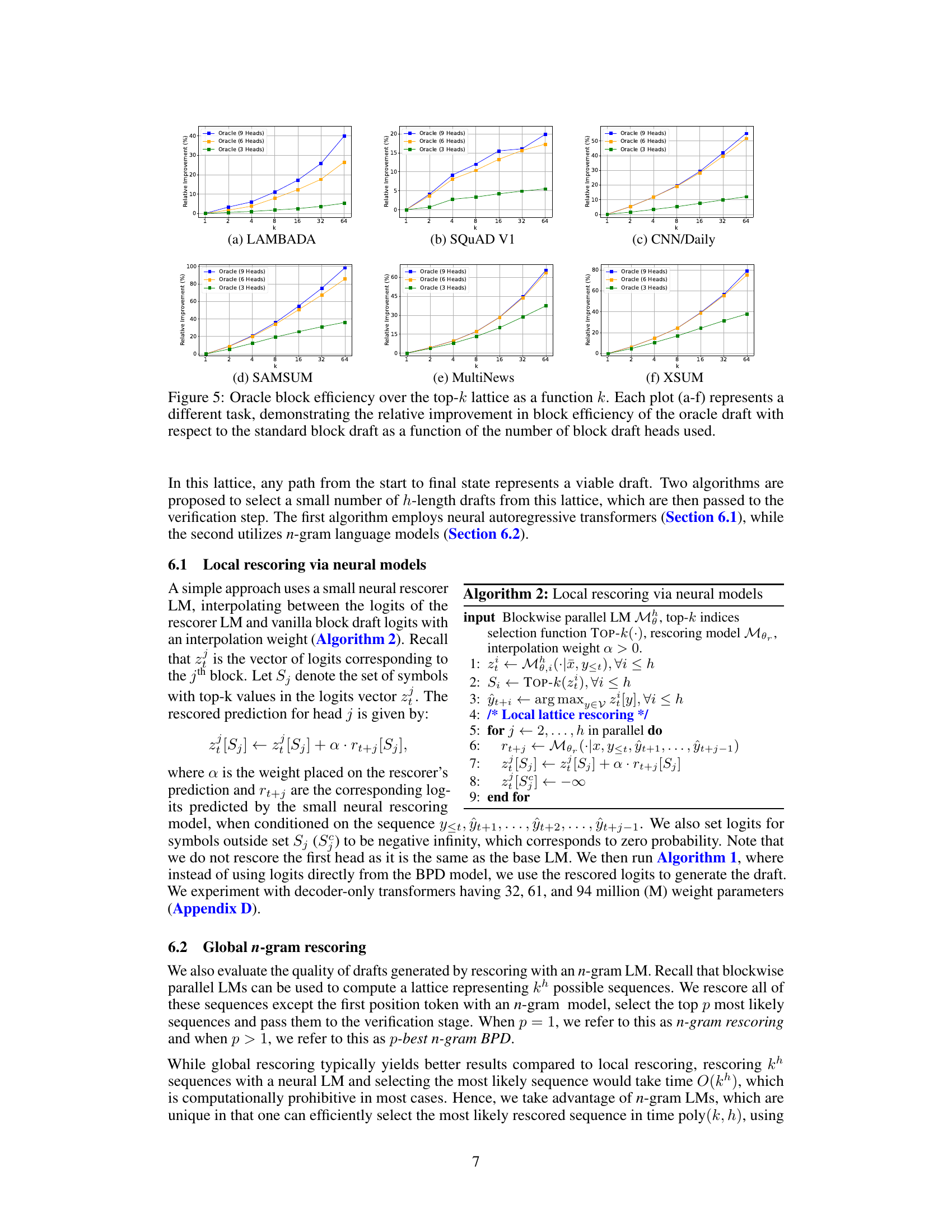
This figure displays the potential gains in block efficiency if the best possible sequence (oracle) is selected from a lattice created by combining the k most probable tokens at each head. The plots show that even with a limited number of heads, significant improvements can be achieved by using this oracle selection method. The improvement varies across tasks, highlighting that some tasks are more conducive to improving efficiency with this approach than others.
This figure shows the potential for improvement in block efficiency by considering the top-k tokens at each head (oracle efficiency). The x-axis represents the value of k (number of top tokens considered), and the y-axis represents the relative improvement in block efficiency compared to the standard approach. Each sub-plot (a-f) corresponds to a different task (LAMBADA, SQUAD V1, CNN/Daily, SAMSUM, MultiNews, XSUM) demonstrating the varying degree of potential improvement across different tasks. The figure highlights the headroom for improvement in block efficiency that can be achieved by selecting a better set of tokens at each head during decoding.
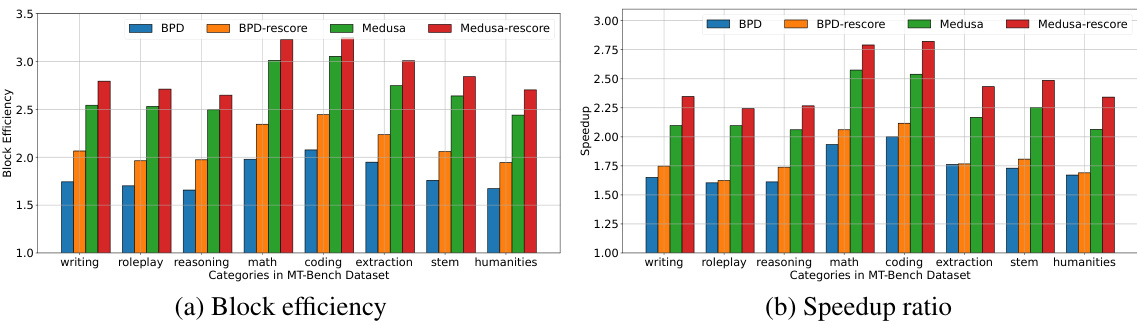
This figure shows the results of experiments comparing the block efficiency and speedup ratio of different decoding methods on various sub-categories of the MT-Bench dataset using the Vicuna 13B language model. The methods compared include standard blockwise parallel decoding (BPD), BPD with local neural rescoring, standard Medusa decoding, and Medusa decoding with local neural rescoring. The x-axis represents the different sub-categories of tasks in the MT-Bench dataset, while the y-axis represents either block efficiency or speedup ratio. The figure demonstrates the improvement in both block efficiency and speedup ratio achieved by incorporating local neural rescoring into both BPD and Medusa decoding methods.
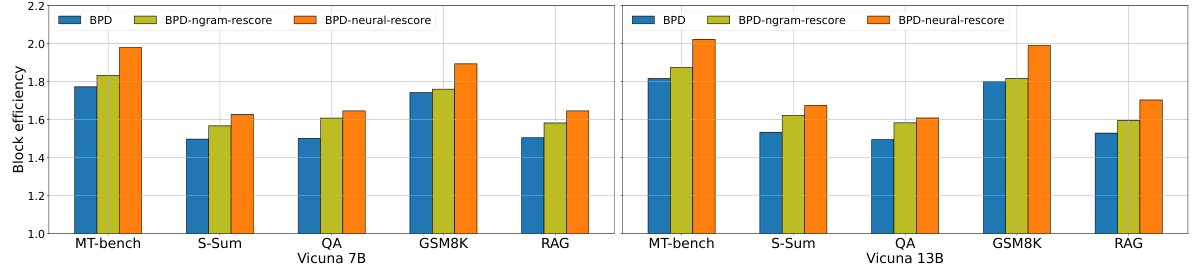
This figure shows the results of applying blockwise parallel decoding (BPD) and the proposed rescoring methods to the Vicuna 13B language model. The left panel (a) presents the block efficiency, which is a metric representing the average number of tokens decoded per serial call to the language model; higher values denote greater efficiency. The right panel (b) displays the speedup ratio relative to standard autoregressive decoding. Both metrics are shown for various sub-categories of the MT-Bench dataset, allowing for a comparison of performance across different task types (e.g., writing, roleplay, reasoning). The figure demonstrates that both BPD and Medusa decoding (an extension of BPD) show significant improvements in efficiency and speedup when using the proposed local rescoring technique. This improvement is consistent across multiple tasks, highlighting the effectiveness of the method.
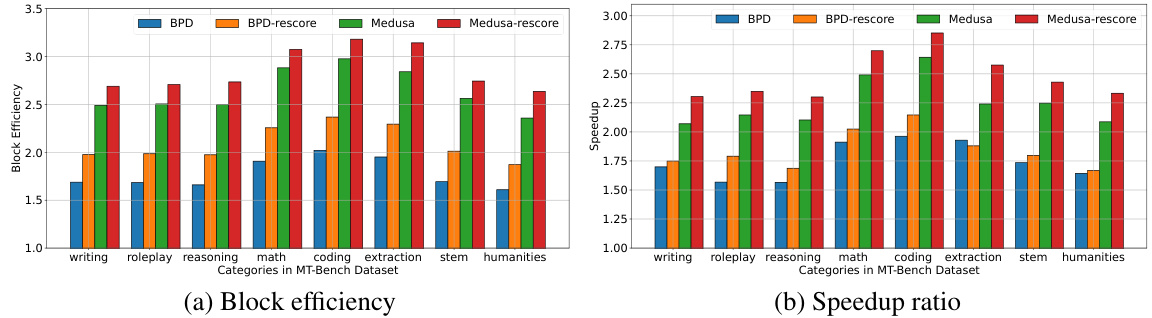
This figure shows a comparison of block efficiency and speedup ratio between different decoding methods (BPD, BPD with rescoring, Medusa, Medusa with rescoring) on various sub-categories of the MT-Bench dataset using the Vicuna 13B language model. The x-axis represents different task categories, and the y-axis shows either block efficiency or speedup ratio compared to standard autoregressive decoding. The results demonstrate the impact of rescoring methods on improving decoding efficiency and speed.
More on tables

This table presents the performance of different models on seven tasks: language modeling, question answering, and summarization. The ‘Performance’ column indicates how well each model performs on the task, while the ‘Block Efficiency’ column shows the average number of tokens decoded per serial call to the blockwise parallel Language Model, indicating the potential speedup compared to traditional decoding. Lower block efficiency means higher speedup potential. The tasks are further divided into subcategories (long vs. short summarization).
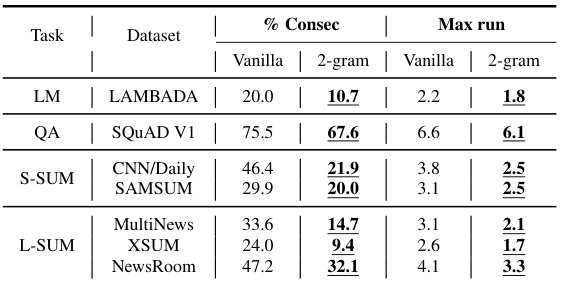
This table presents the results of an analysis of consecutive token repetition in block drafts, both before and after applying a 2-gram language model for rescoring. It shows the percentage of consecutive tokens that are identical and the average maximum length of repeated sequences for various tasks and datasets. Lower values indicate less repetition and better draft quality.
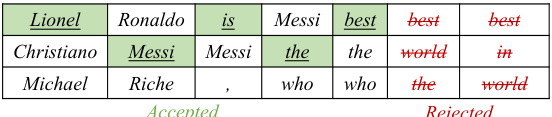
This table displays example outputs from blockwise parallel language models (LMs) fine-tuned for different tasks (language modeling, question answering, summarization). Each row shows the drafts generated by different prediction heads in parallel, indicating how the models simultaneously predict multiple tokens. The ‘accepted’ tokens (in blue) are those that match the output of the standard autoregressive LM. The ‘rejected’ tokens (in red) are those which do not match the standard autoregressive LM. The prompt for each example is in brown. This illustrates how the blockwise parallel decoding process works and the differences in draft quality across different tasks.

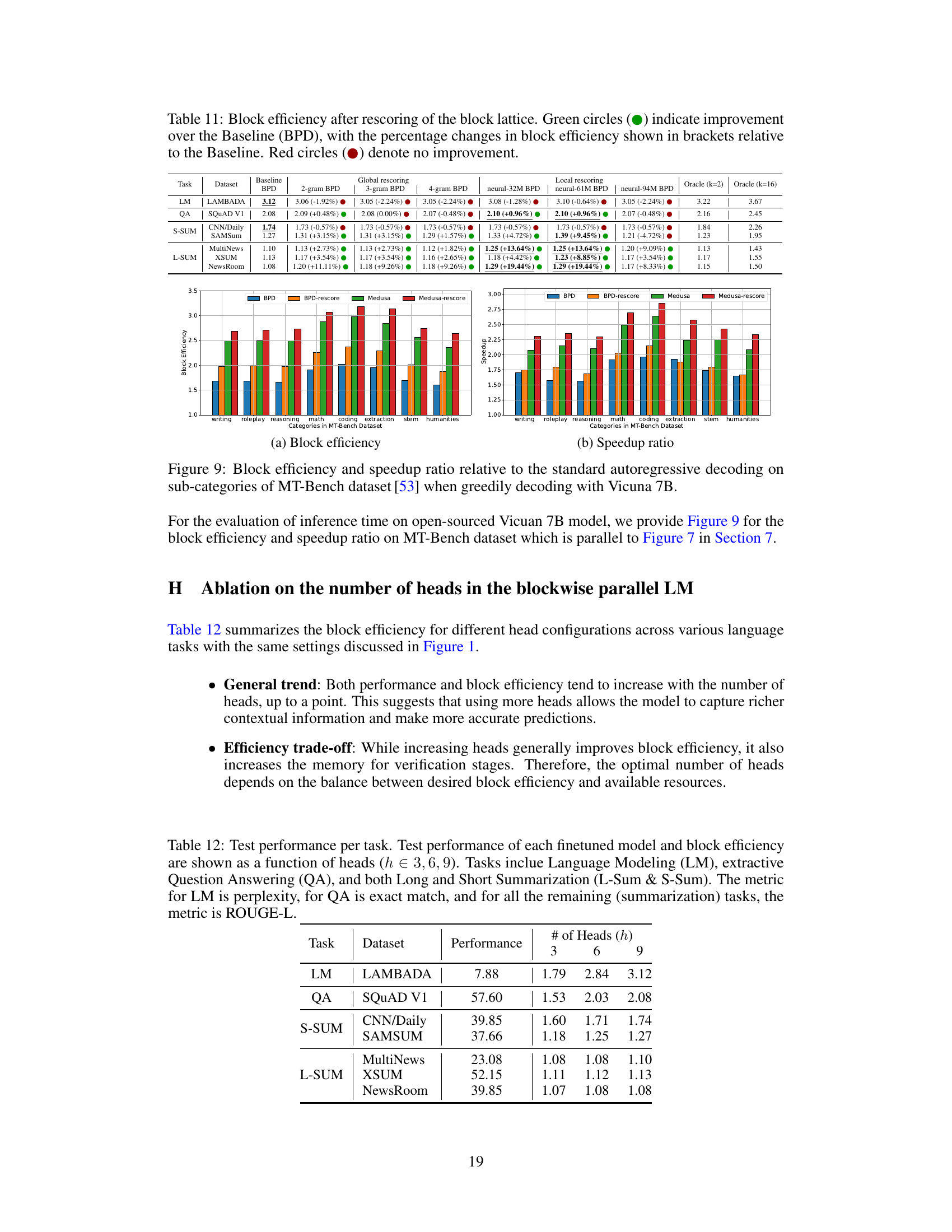
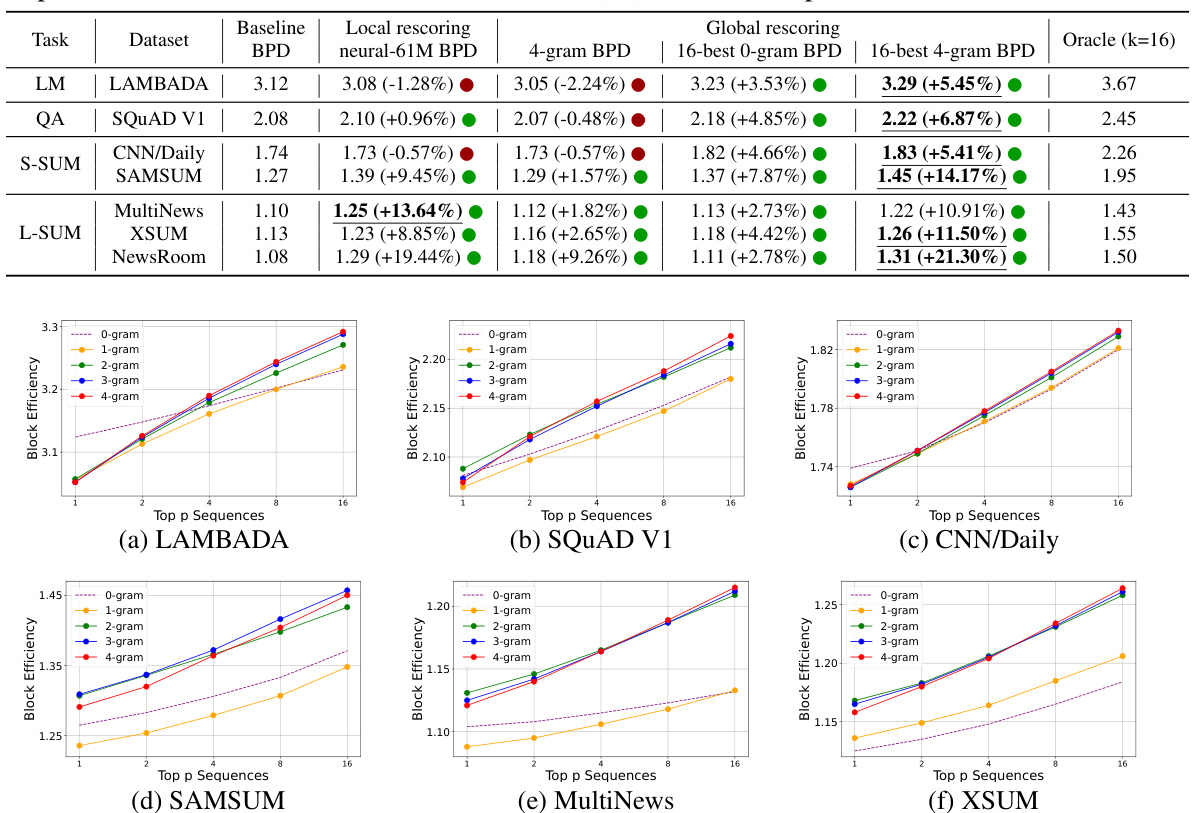
This table presents the block efficiency results for different rescoring methods (local rescoring with neural networks, global rescoring with n-gram language models) compared to the baseline BPD method. The results are shown for various tasks (language modeling, question answering, summarization) and different lattice sizes. The relative improvement over the baseline is shown in parentheses. Green and red circles indicate whether there was an improvement or not over the baseline.
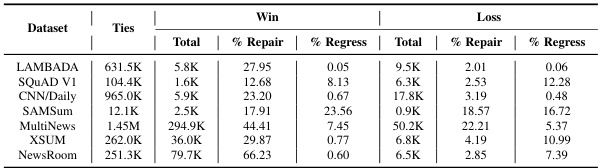
This table shows the block efficiency results for different rescoring methods on seven tasks using a top-16 lattice. It compares the baseline blockwise parallel decoding (BPD) method with several rescoring approaches: local neural rescoring (using different sized models), global n-gram rescoring (using 4-gram language models), and variations on the 16-best draft verification. The table shows percentage improvement or decrease in block efficiency over the baseline for each method on each task. Green circles indicate improvement while red indicates no improvement or negative improvement. The results highlight that local neural rescoring often provides the best performance, especially when the initial block efficiency was low.

This table presents the block efficiency results for various rescoring methods (local neural and global n-gram) and baselines (BPD, 16-best 0-gram BPD) across multiple tasks (LM, QA, S-SUM, L-SUM). It shows the relative improvement of each method compared to the standard BPD method, highlighting which methods yield significant gains. Green circles indicate performance improvements, while red circles indicate no improvement. The results reveal the effectiveness of the different rescoring strategies in enhancing the quality of block drafts and improving decoding speed.

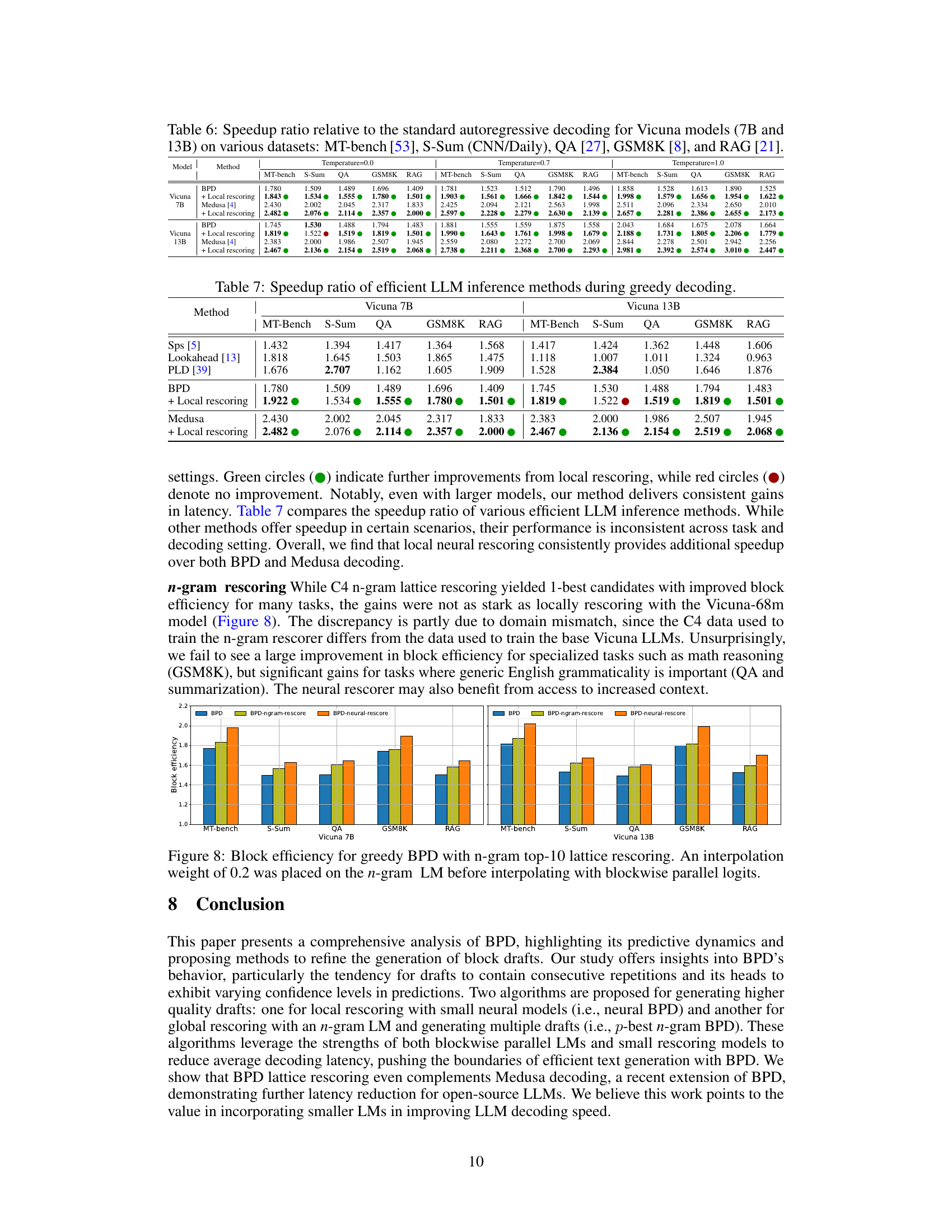
This table compares the speedup ratios achieved by various efficient large language model (LLM) inference methods, including the proposed method, during greedy decoding. It shows the speedup relative to standard autoregressive decoding across several benchmark datasets (MT-Bench, S-Sum, QA, GSM8K, RAG) and for different model sizes (Vicuna 7B and 13B). The table highlights the consistent speed improvements provided by the local rescoring method, particularly when compared to other methods whose performance is less consistent.
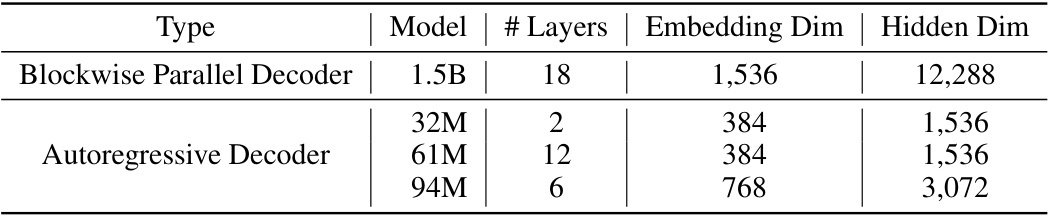
This table lists the architecture hyperparameters for the various transformer-based neural language models used in the paper. It shows the model size, the number of layers, the embedding dimension, and the hidden dimension for both the blockwise parallel decoder and the autoregressive decoder models of different sizes (1.5B, 32M, 61M, and 94M parameters). These details are crucial for understanding the experimental setup and the computational resources required for the different models.

This table shows the block efficiency for different rescoring models (2-gram and neural-61M) using both C4-trained and in-domain-trained models across six downstream tasks. It compares the block efficiency when using models trained on the general-purpose C4 dataset versus those trained specifically on the target task’s dataset. This helps to analyze whether using task-specific rescoring models leads to improved block efficiency compared to using general-purpose models.

This table shows the tuned interpolation weight (alpha) for both neural and n-gram rescoring methods across different datasets. The weights were tuned to maximize block efficiency on a held-out set of examples before evaluating on the remaining data. The weights vary widely by dataset, indicating that optimal rescoring strategies depend on the specific characteristics of the dataset. Lower weights suggest that the base model’s predictions were more accurate and require less adjustment, while higher weights indicate that the rescorer makes a larger contribution.

This table presents the block efficiency results for different rescoring methods applied to the top-16 lattice. The baseline is standard blockwise parallel decoding (BPD). It shows the relative improvement in block efficiency achieved by using local and global rescoring techniques, compared to the baseline. Green circles indicate a positive improvement, while red circles indicate no improvement or a negative impact compared to the baseline.

This table presents the performance and block efficiency of different models across seven tasks (language modeling, question answering, and summarization). For each task, it shows the performance metric (perplexity for LM, exact match for QA, ROUGE-L for summarization) and the block efficiency, representing the theoretical speedup compared to standard greedy decoding.

This table compares the hardware utilization of different decoding methods: autoregressive, base BPD, 4-gram BPD, neural-61M BPD, 16-best 0-gram BPD, and 16-best 4-gram BPD. Metrics include average block efficiency, parameter I/O (in GB), key-value cache I/O (in GB) at different sequence lengths (128, 512, 1024, and 2048), and floating-point operations (FLOPS in trillions). It shows how different methods impact resource usage for decoding.

This table presents the results of experiments evaluating the performance of different language models on various tasks. The ‘Performance’ column shows the scores achieved by the models, while the ‘Block Efficiency’ column indicates the efficiency gains of blockwise parallel decoding (BPD) compared to standard autoregressive decoding for each task. Block efficiency is a key metric for evaluating the speed improvement offered by BPD, with higher values suggesting greater efficiency gains.

This table presents the results of experiments on seven different tasks: language modeling, extractive question answering, and summarization (both long and short). For each task, it shows the performance of the fine-tuned model and the block efficiency. Block efficiency measures how many tokens are decoded per serial call to the blockwise parallel LM, representing a speedup compared to standard greedy decoding. Higher block efficiency indicates faster decoding.
Full paper#