↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Object detection models often suffer from a lack of sufficient training data, especially in niche domains. Existing data augmentation techniques have limitations in generating diverse and realistic images, particularly for complex scenes with multiple objects and occlusions. This has hampered the development of robust and accurate object detectors.
The researchers introduce ODGEN, a novel method that leverages diffusion models to generate high-quality synthetic images. ODGEN addresses the limitations of previous methods by fine-tuning a pre-trained diffusion model on domain-specific data and employing a new object-wise conditioning strategy using both visual (synthesized foreground patches) and textual (object-wise descriptions) prompts. The results demonstrate that using synthetic data generated by ODGEN significantly enhances the performance of object detectors, improving mAP by up to 25.3%, showcasing the effectiveness and generalizability of their approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in object detection due to its novel approach to data synthesis using diffusion models. It directly addresses the problem of limited and insufficient training data, a major bottleneck in achieving state-of-the-art results. The proposed method of generating high-quality, domain-specific synthetic data offers a significant advancement, potentially revolutionizing training methodologies and leading to more accurate and robust object detectors. The evaluation protocol and benchmark results provide strong evidence of the method’s effectiveness and encourage further exploration of diffusion models for data augmentation across various computer vision tasks.
Visual Insights#
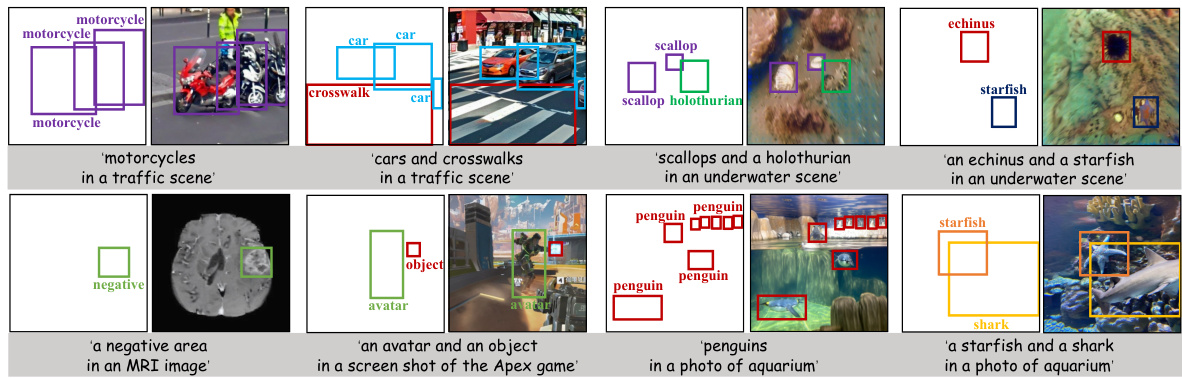
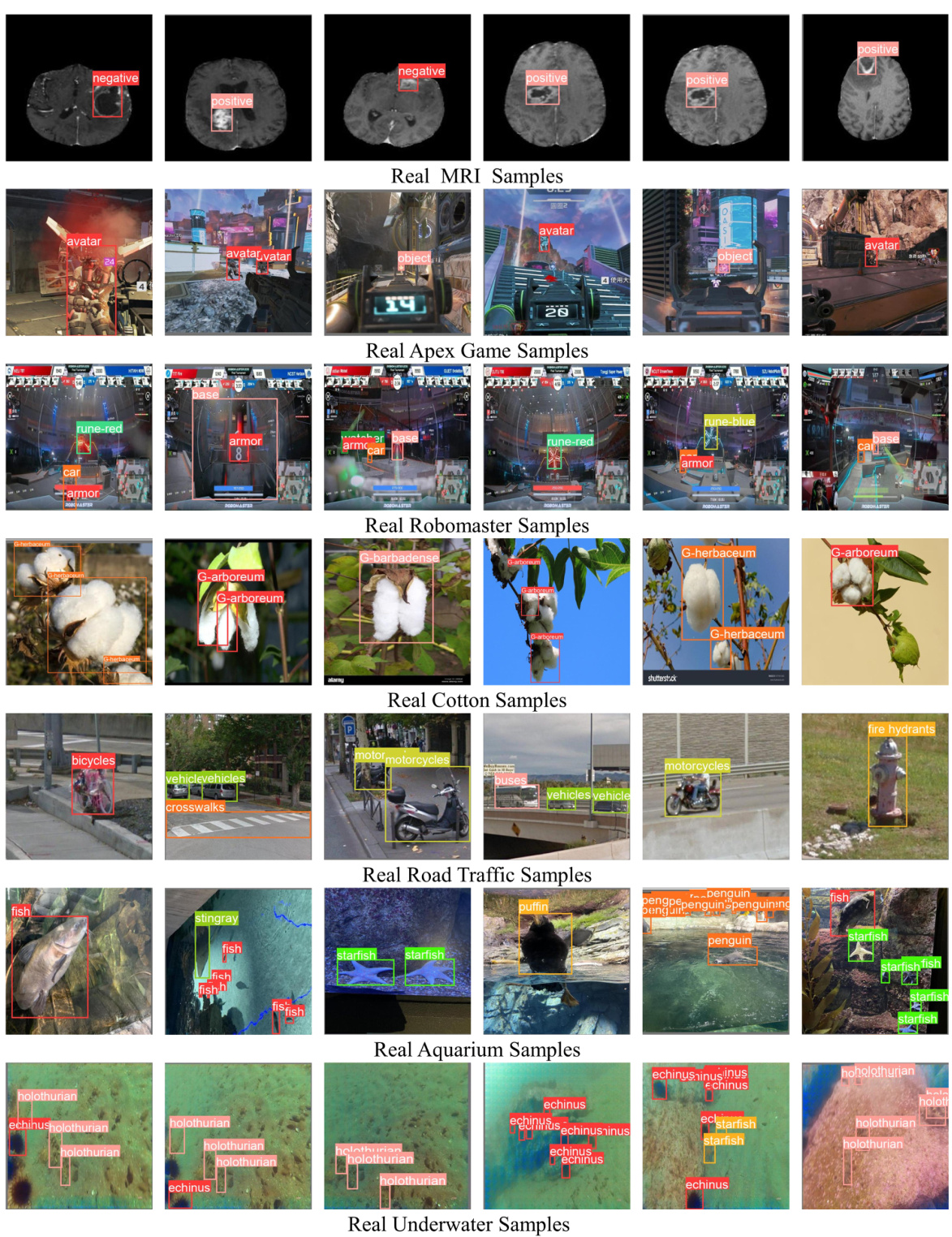
This figure showcases several examples of images generated by the ODGEN model. Each image demonstrates the model’s ability to generate images conditioned on bounding boxes and text descriptions. The examples include diverse scenes and object types, highlighting the model’s capacity to handle complex scenarios with multiple objects, dense arrangements, and occlusions. These capabilities make ODGEN suitable for enriching training datasets for object detection.
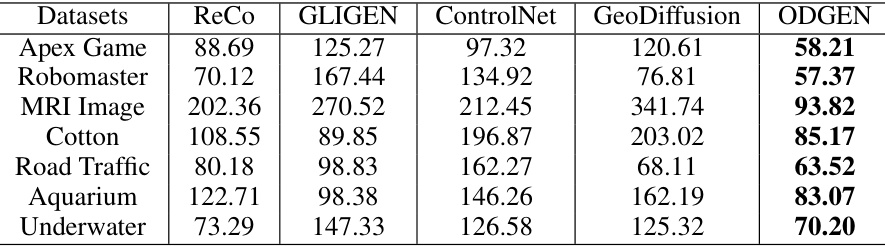
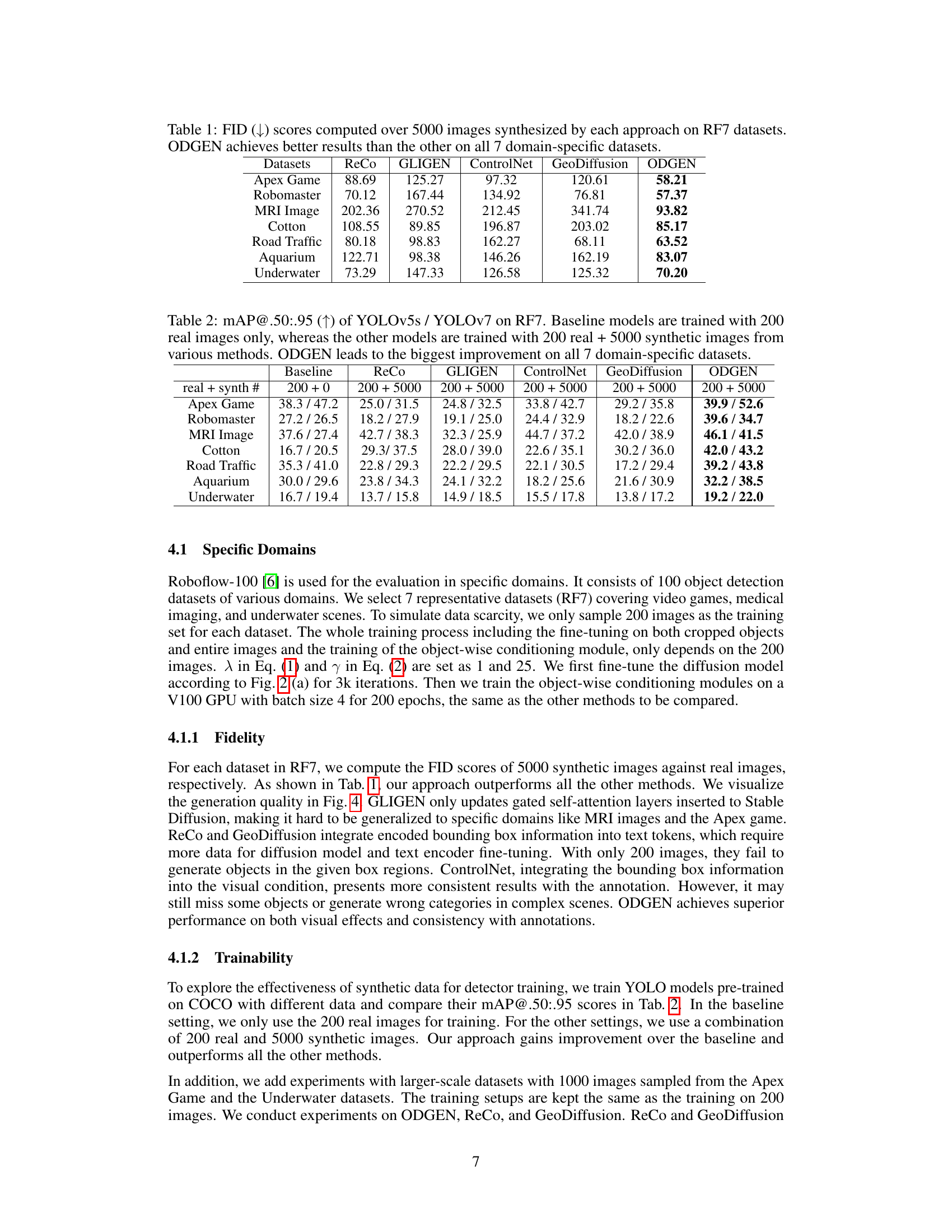
This table presents the Fréchet Inception Distance (FID) scores, a metric for evaluating the quality of generated images, for seven different domain-specific datasets (RF7). Lower FID scores indicate higher-quality generated images. The table compares the FID scores achieved by ODGEN against four other methods (ReCo, GLIGEN, ControlNet, and GeoDiffusion) across these seven datasets. The results show that ODGEN consistently achieves the lowest FID scores, indicating superior image generation quality compared to the other approaches.
In-depth insights#
ODGEN: Diffuser#
The heading ‘ODGEN: Diffuser’ suggests a system, ODGEN, utilizing diffusion models for image generation. A diffuser, in this context, likely refers to a diffusion model fine-tuned for specific tasks. The name implies ODGEN is not simply using pre-trained models, but rather adapts and potentially improves upon existing diffusion models. This suggests a focus on controllability and quality, possibly addressing limitations of standard diffusion models in generating complex scenes or adhering to specific domain characteristics. The system’s ability to ‘diffuse’ may involve generating images from various inputs, such as bounding boxes and textual descriptions, achieving a high degree of control over the generated content. The ‘ODGEN’ portion indicates a domain-specific approach, meaning the model’s training and application are tailored to particular image categories or datasets, likely enhancing both the accuracy and the realism of the synthesized images compared to general-purpose diffusion models. Overall, ‘ODGEN: Diffuser’ points to a novel method with strong potential for generating high-quality, controlled synthetic images useful for enriching training datasets in computer vision tasks.
Domain Tuning#
Domain tuning, in the context of a research paper on object detection data generation, likely refers to adapting a pre-trained model to a specific domain. This involves fine-tuning a large, general-purpose model (like a diffusion model) on a dataset representing the target domain (e.g., medical imagery, aerial photography). This process aims to overcome the challenge of domain shift, where the distribution of the pre-trained model’s data differs from the target domain. Effective domain tuning is crucial for generating synthetic data that accurately reflects the target domain’s characteristics, ensuring that the generated data benefits the downstream object detection task without introducing bias or artifacts. Successful domain tuning bridges the gap between general-purpose models and domain-specific needs, leading to better-performing object detectors. The specifics of the approach might involve techniques to handle complex scenes, multiple object classes, and dense object arrangements that commonly appear in real-world object detection datasets.
Object Control#
Object control in image generation models is a crucial aspect influencing the quality and utility of the generated outputs. Effective object control enables precise manipulation of objects within a scene, including their position, size, attributes, and relationships with other elements. This level of control is essential for various applications such as data augmentation for object detection, creating realistic synthetic datasets, and generating images based on complex user specifications. Achieving fine-grained control often involves incorporating additional information into the generation process, such as bounding boxes, segmentation masks, or textual descriptions. However, challenges remain in handling complex scenes with occlusions, multiple objects, and diverse object interactions. The success of object control hinges on the model’s ability to disentangle object representations and understand spatial relationships, requiring advanced architectural designs and training strategies. Future research should explore novel techniques for more robust and intuitive object control to address the limitations of current methods and expand the application of generative models in various domains.
Synthesis Pipeline#
A robust synthesis pipeline is crucial for generating high-quality, domain-specific data for object detection. It should begin with accurate estimation of object distributions within the target domain, using existing datasets to model parameters like bounding box sizes, aspect ratios, and locations. These distributions then guide the sampling of pseudo-labels, which are used as inputs to the generative model. A key innovation lies in the method of conditioning the generative model. This isn’t simply done via text prompts, but through a combination of object-wise text and visually synthesized prompts, which allow for precise spatial control and mitigate the concept-bleeding problem that often plagues multi-object synthesis. Finally, a robust filtering step is essential, leveraging discriminators to identify and remove any synthetic samples where the generated objects don’t accurately match the pseudo-labels. This ensures high fidelity and enhances the trainability of the synthesized dataset for improved object detection performance.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Improving the fidelity of synthetic data generation is paramount; advancements in diffusion models and generative AI are crucial for creating highly realistic images that better bridge the domain gap between synthetic and real-world datasets. Developing more sophisticated control mechanisms for object attributes like texture, pose, and occlusion will significantly enhance the quality and diversity of synthetic datasets. Addressing computational limitations is another key area; optimization techniques and leveraging hardware acceleration will be vital for scaling the synthetic data generation process to handle massive datasets efficiently. Finally, investigating the impact of synthetic data on different object detection model architectures and exploring techniques to mitigate potential biases introduced by synthetic data will broaden the applicability and robustness of the proposed methods.
More visual insights#
More on figures
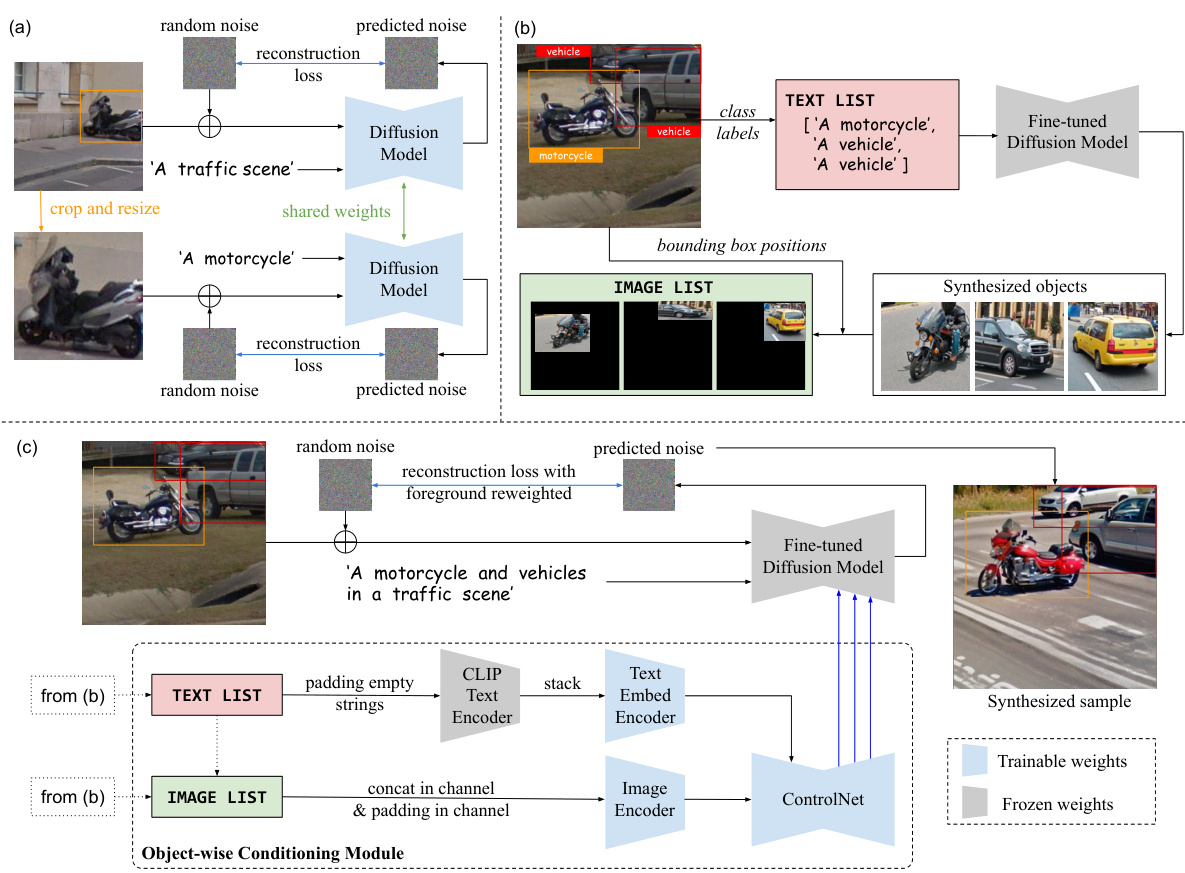
This figure illustrates the ODGEN training pipeline. It shows the fine-tuning of a pre-trained diffusion model on a detection dataset using both full images and cropped foreground objects (a). Next, it details how class labels are used to create a text list, which then generates synthetic object images (b). These images are resized, placed on a canvas according to bounding box positions, and formed into an image list. Finally, the image list and the encoded text list are used as conditions for ControlNet, the final step of the synthesis pipeline (c).

This figure illustrates the pipeline used for synthesizing datasets for object detection. First, Gaussian distributions are estimated for bounding box attributes (number, area, aspect ratio, location) based on statistics from the training dataset. Then, pseudo labels are sampled from these distributions. These labels, along with text and image lists (created from the class names and generated object images), are used as input to a fine-tuned diffusion model (ControlNet). A foreground/background discriminator is trained to filter out any pseudo-labels where the model failed to synthesize an object successfully. Finally, the filtered labels and generated images form the synthetic dataset.
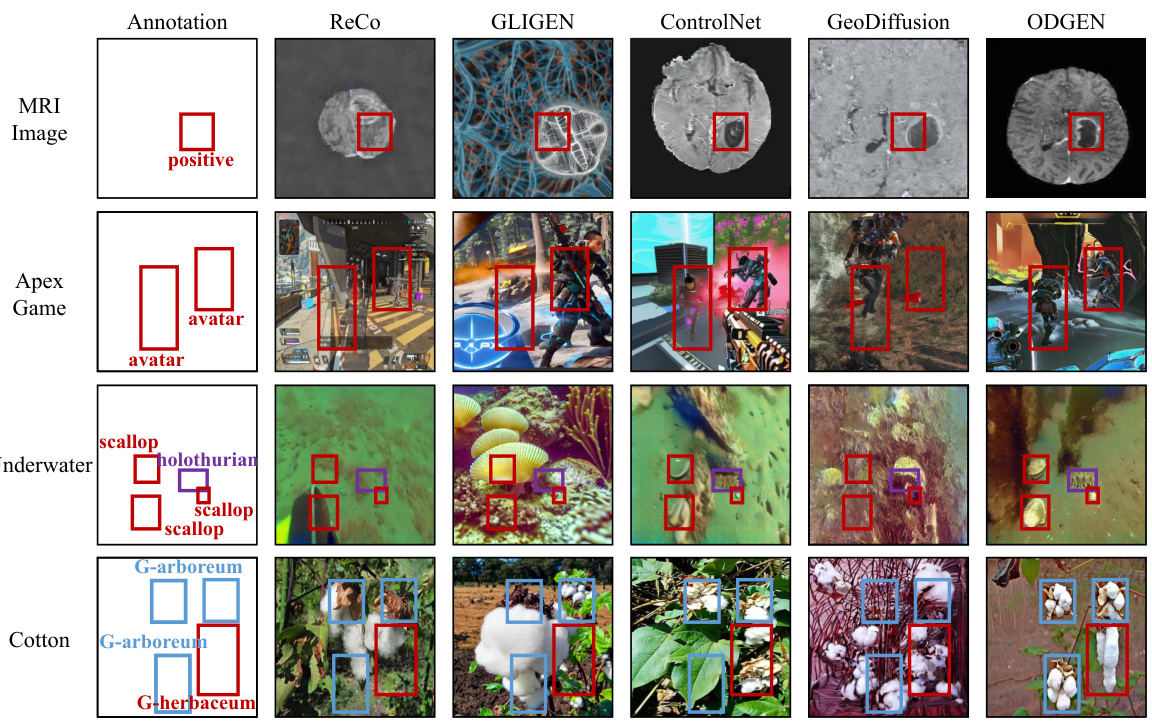
This figure compares the image generation results of ODGEN against four other methods (ReCo, GLIGEN, ControlNet, and GeoDiffusion) across five different domains (MRI, Apex Game, Underwater, Cotton, and G-arboreum). Each row represents a different domain, with the leftmost column showing the ground truth annotations (bounding boxes and class labels). The remaining columns illustrate the generated images by each method, given the same input annotations. The figure highlights ODGEN’s ability to generate images with accurate layout control and generalization capability across various domains.

This figure shows ablation studies on the impact of using image lists and text lists in the ODGEN model. The leftmost image demonstrates the failure of the model to generate correct results without either image or text lists. The center image shows the failure of the model to generate correct results when only the text list is used. The rightmost image shows the failure of the model to generate correct results when only the image list is used. Only when both image and text lists are used does the model generate correct results, highlighting the importance of both visual and textual conditioning for accurate object placement and synthesis.

This figure shows the ablation study of the foreground region enhancement parameter (γ) in the loss function. As γ increases, the foreground objects become more clear and realistic, however, if γ is too large, it leads to blurriness and loss of detail in the background.

This figure illustrates the ODGEN training pipeline. It shows a pre-trained diffusion model fine-tuned on a detection dataset using both full images and cropped foreground objects for improved synthesis. Next, it demonstrates how bounding boxes and class labels are used to create both visual (image list) and textual (text list) prompts to guide the generation of synthetic objects using ControlNet. Finally, it explains how these visual and textual prompts are combined for the final image generation using the fine-tuned diffusion model.
This figure compares the image generation results of ODGEN against four other methods (ReCo, GLIGEN, ControlNet, and GeoDiffusion) under the same input conditions. The input conditions (shown in the leftmost column) consisted of bounding boxes and textual descriptions specifying objects and their locations within a scene. The comparison demonstrates that ODGEN generates images with greater accuracy in terms of object placement and overall scene fidelity, particularly within specific domains (MRI images, video game screenshots, underwater scenes, cotton samples). This highlights ODGEN’s capability to generalize effectively to domain-specific characteristics and achieve precise layout control in image generation.

This figure compares the image generation results of ODGEN against four other methods (ReCo, GLIGEN, ControlNet, and GeoDiffusion) across six different domains (MRI images, Apex Game screenshots, underwater scenes, cotton images, road traffic scenes, and aquarium photos). Each row represents a different domain, with the first column showing the ground truth annotations (bounding boxes and class labels) that were used as input for all five methods. The following columns show the images generated by each method. The figure aims to demonstrate that ODGEN is superior in its ability to generalize to various domains and generate images with accurate spatial layout.

This figure compares the image generation results of ODGEN against other methods (ReCo, GLIGEN, ControlNet, and GeoDiffusion) given the same input conditions. The leftmost column shows the input conditions (annotations). The other columns show the images generated by each method. The results demonstrate that ODGEN produces higher-quality images, particularly in complex scenes and specific domains. It also highlights ODGEN’s ability to accurately control the layout of generated objects.

This figure demonstrates ODGEN’s ability to generate images with novel object categories not present in its training data. Using Stable Diffusion to create foreground object images, the model successfully places these new objects within specified bounding boxes, showcasing its controllability and adaptability.

This figure compares the image generation results of ODGEN against four other methods (ReCo, GLIGEN, ControlNet, and GeoDiffusion) across six different domains (MRI images, Apex Game screenshots, underwater scenes, cotton images, road traffic scenes, and aquarium photos). Each domain has a sample image in the leftmost column, showing the desired object annotations. The other columns show the results produced by each method using these same annotations as input. The comparison highlights that ODGEN is able to produce images that are both more faithful to the given layout (annotations) and that it generalizes better across a range of diverse domains.

This figure illustrates the ODGEN training pipeline, which involves three stages: fine-tuning a pre-trained diffusion model, generating synthetic object images using the fine-tuned model and bounding box information, and using the generated images and object-wise text embeddings as input for the ControlNet for final image synthesis. The process demonstrates how ODGEN controls the generation of images by combining textual and visual prompts.

This figure compares the image generation results of ODGEN against other methods (ReCo, GLIGEN, ControlNet, and GeoDiffusion) given the same input conditions (bounding boxes and class labels). The comparison highlights ODGEN’s superior ability to generate high-quality, domain-specific images while accurately representing the spatial layout of objects. It demonstrates ODGEN’s ability to handle complex scenes and diverse object categories with accurate bounding box placement.

This figure compares the image generation results of ODGEN against other methods (ReCo, GLIGEN, ControlNet, GeoDiffusion) under identical input conditions. The first column shows the input bounding boxes and text prompts. Subsequent columns display the generated images from each method. The comparison highlights ODGEN’s ability to generate higher-quality images, particularly in handling specific domain styles (like MRI scans, video games, etc.) and complex layouts with multiple objects, overcoming limitations seen in the other methods.

This figure compares the image generation results of ODGEN against other methods (ReCo, GLIGEN, ControlNet, and GeoDiffusion) under identical conditions. Each row represents a different domain (MRI, Apex Game, Underwater, and Cotton), and the first column displays the annotation (bounding boxes and class labels) used as input for all methods. The remaining columns show the images generated by each method. The caption highlights ODGEN’s superior performance in generating accurate layouts and its generalizability across diverse domains.

This figure compares the image generation results of ODGEN against other methods (ReCo, GLIGEN, ControlNet, and GeoDiffusion). Each row represents a different domain (MRI, Apex Game, Underwater, and Cotton), and each column showcases the results of a different method, with the first column showing the annotation used as input for all methods. The figure highlights that ODGEN produces images with better layout control and is more generalizable across different domains than other methods.

This figure shows the results of ODGEN on the COCO-2014 dataset. The first column displays the annotations (bounding boxes and class labels) used as input conditions. The remaining columns showcase four different images generated by ODGEN using the same annotation, demonstrating the model’s ability to produce diverse outputs from identical input conditions.
More on tables

This table presents the mean Average Precision (mAP) at IoU thresholds from 0.5 to 0.95 for YOLOv5s and YOLOv7 object detectors. The models were trained on 7 different domain-specific datasets from the Roboflow-100 benchmark (RF7). The ‘Baseline’ column shows the performance when only training on 200 real images. The remaining columns show the mAP when training on those 200 real images plus 5000 synthetic images generated by different methods. The results demonstrate the effectiveness of adding synthetic data generated by ODGEN to improve the performance of object detectors across the seven diverse domains. ODGEN consistently leads to the highest mAP values, indicating its superiority in generating high-quality, domain-relevant synthetic data for object detection training.
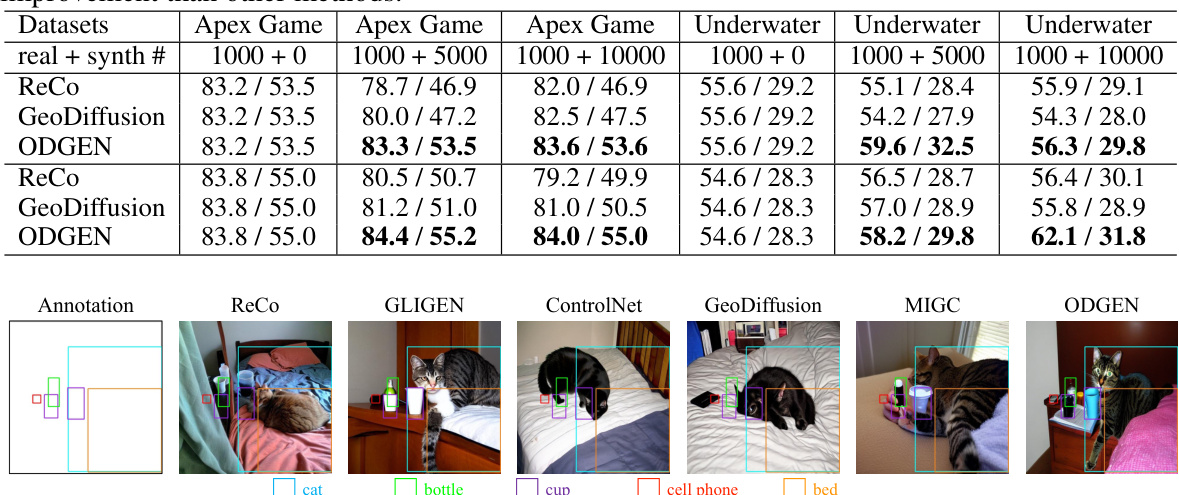
This table shows the mean Average Precision (mAP) at IoU thresholds from 0.5 to 0.95 for YOLOv5s and YOLOv7 object detectors. The models are trained using different synthetic image generation methods (ReCo, GLIGEN, ControlNet, GeoDiffusion, and ODGEN) in addition to 200 real images. The baseline uses only the 200 real images. The table compares the performance gains across seven specific domains (RF7). The results demonstrate that ODGEN significantly improves the mAP compared to other methods across all domains.

This table presents a comparison of the FID (Fréchet Inception Distance) scores and mean Average Precision (mAP) values for the YOLOv5s and YOLOv7 object detectors. The models were trained using synthetic images generated by different methods, including ODGEN, and evaluated on the COCO-2014 dataset. Lower FID scores indicate better image quality, while higher mAP values signify improved object detection accuracy. The results demonstrate that ODGEN outperforms other methods in both image generation quality and object detection performance.
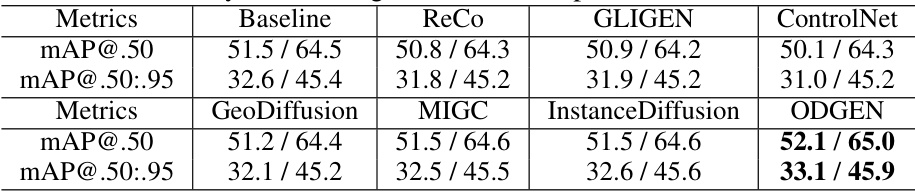
This table presents the mean Average Precision (mAP) at IoU thresholds from 0.5 to 0.95 for the YOLOv5s and YOLOv7 object detectors. The models were trained using 200 real images and 5000 synthetic images generated by different methods (ReCo, GLIGEN, ControlNet, GeoDiffusion, and ODGEN). A baseline is also provided showing results using only 200 real images. The table shows the performance improvement gained by adding synthetic data generated by ODGEN across seven different datasets (RF7). The results indicate that ODGEN outperforms other methods in terms of improving the detector’s mAP.

This table shows the mean average precision (mAP) of YOLOv5s and YOLOv7 models trained on different combinations of real and synthetic COCO validation data. It compares performance when training and validating only on real images, training on real images and validating on synthetic images, training on synthetic images and validating on real images, and training and validating only on synthetic images. The results highlight the impact of using synthetic data generated by ODGEN for object detection model training.

This table presents ablation study results on the impact of using image lists and text lists for generating synthetic images, evaluating the FID and mAP@.50:.95 metrics. It demonstrates that using both image and text lists improves the quality of the generated images (lower FID) and increases the effectiveness of those images in training YOLO models (higher mAP). The effect is particularly noticeable for the complex Road Traffic dataset, which contains multiple object categories and occlusions.
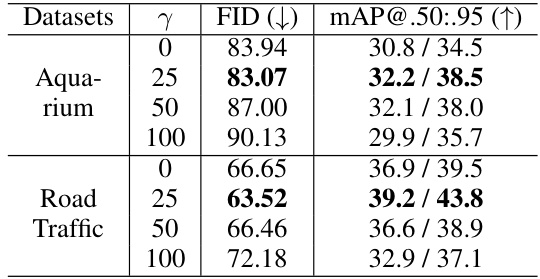
This table presents the ablation study results on the impact of the foreground re-weighting parameter (γ) on the Fréchet Inception Distance (FID) and mean Average Precision (mAP) using YOLOv5s and YOLOv7 object detectors. It shows that appropriately chosen γ values improve both FID and mAP, indicating better quality and trainability of the synthetic images. However, excessively high γ values negatively affect the image quality and detector performance.
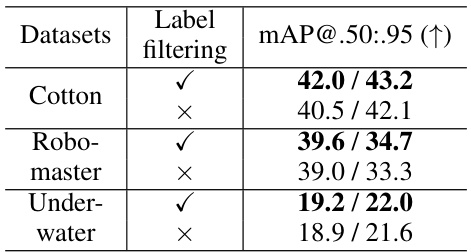
This table presents the results of an ablation study on the impact of the corrupted label filtering step in ODGEN. The study is performed on three specific datasets: Cotton, Robomaster, and Underwater. For each dataset, the table shows the mAP@.50:.95 achieved with and without the corrupted label filtering. The results show that including this filtering step slightly improves the overall mAP, indicating that the step helps remove synthetic images where the generation was not accurate.

This table presents ablation results comparing the performance of YOLOv5s and YOLOv7 object detectors trained using different combinations of real and synthetic data. Specifically, it shows the mAP@.50 and mAP@.50:.95 for models trained with: * 200 real images only: A baseline representing training with a limited amount of real-world data. * 5000 synthetic images only: Evaluates the model’s performance when trained solely on synthetic data generated by the method. * 200 real + 5000 synthetic images: Shows the effect of augmenting a small set of real images with a larger synthetic dataset. The table aims to demonstrate the impact of having real data for training and the effectiveness of the synthetic data augmentation.

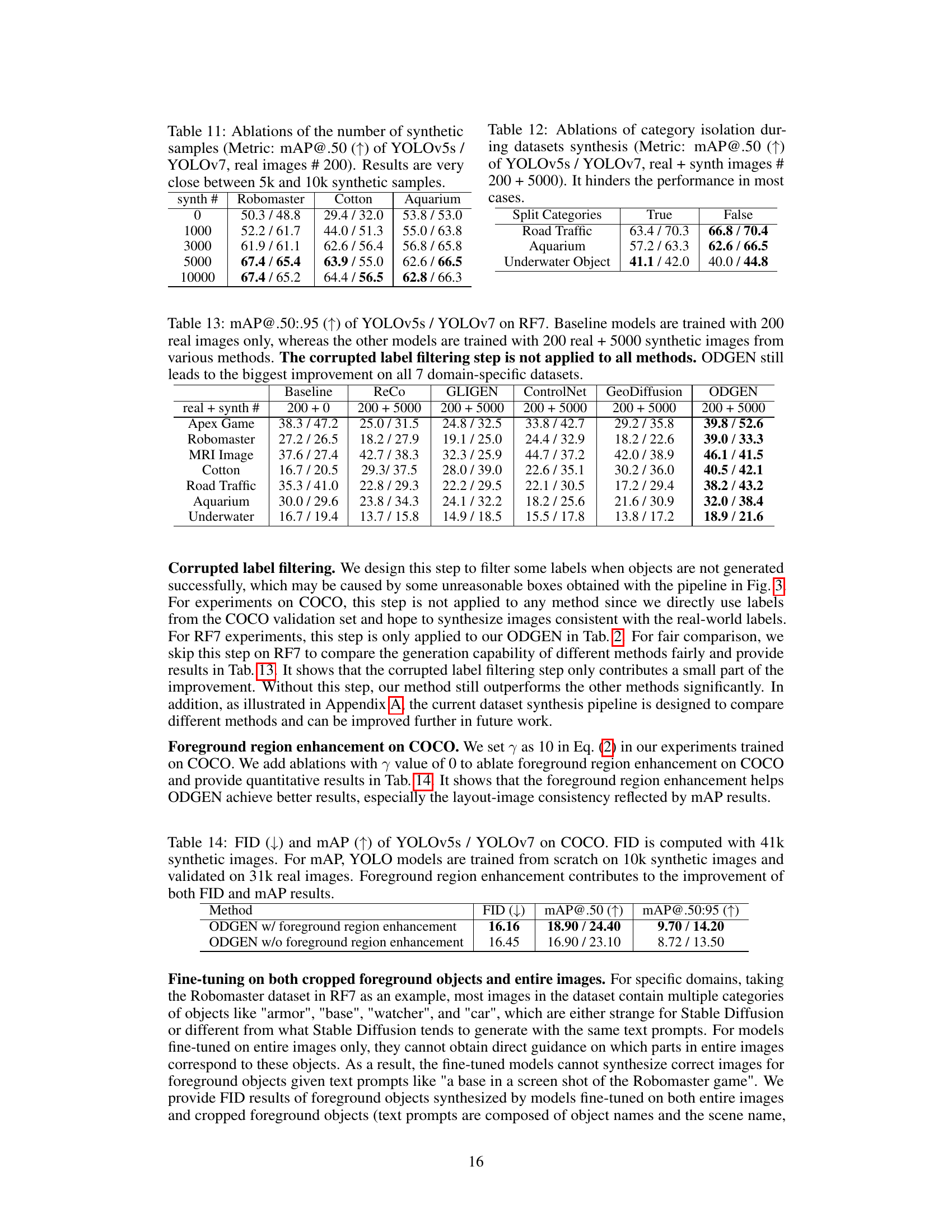
This table presents the ablation study on the number of synthetic samples used for training YOLOv5s and YOLOv7 object detectors. The results show that increasing the number of synthetic samples improves the mAP@.50 scores, with minimal performance difference between using 5000 and 10000 synthetic samples. This suggests that using a larger number of synthetic samples may not significantly improve the results beyond 5000. The table provides results for three different datasets: Robomaster, Cotton, and Aquarium.
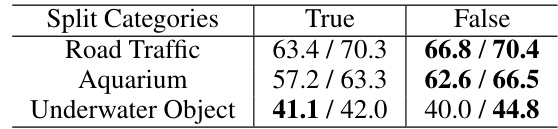
This table presents the results of an ablation study on the impact of isolating object categories during synthetic dataset generation. Two versions of the dataset were created: one where objects were grouped by category (True), and one where they were mixed (False). The performance of YOLOv5s and YOLOv7 object detectors was measured using mAP@.50 to assess the impact of category isolation on the training data. The results show that mixing categories (False) generally performed better than isolating them (True) for the selected datasets, suggesting that the diversity of mixed categories is beneficial for training effective object detectors.
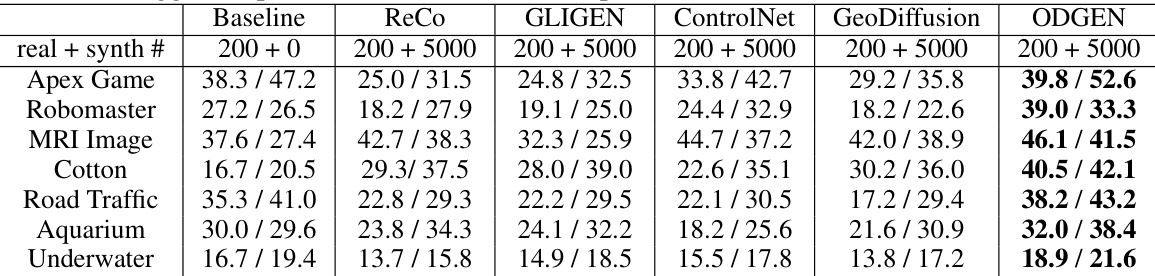
This table presents the mean average precision (mAP) at IoU thresholds from 0.5 to 0.95 for YOLOv5s and YOLOv7 object detectors. The models are trained on 7 different domain-specific datasets from the Roboflow-100 benchmark (RF7). The baseline uses only 200 real images for training, while other models use those 200 real images plus 5000 synthetic images generated by different methods (including ODGEN). The table shows that ODGEN consistently provides the largest improvement in mAP across all seven datasets compared to other methods.

This table presents the results of evaluating the performance of YOLOv5s and YOLOv7 object detectors trained on synthetic images generated using ODGEN, with and without foreground region enhancement. The Fréchet Inception Distance (FID) score, measuring the quality of generated images compared to real images, and mean Average Precision (mAP) at IoU thresholds of 0.5 and 0.5-0.95, measuring the detection accuracy, are reported. The results demonstrate that foreground region enhancement leads to improved FID and mAP scores, indicating better image quality and detection accuracy.

This table presents the Fréchet Inception Distance (FID) scores, a metric for evaluating the quality of generated images, for foreground objects in the Robomaster dataset. The FID scores are shown for models fine-tuned using two different training approaches: one using only entire images and another using both entire images and cropped foreground object patches. Lower FID scores indicate better image quality. The table allows for a comparison of the impact of different fine-tuning strategies on the quality of generated images of specific object categories (watcher, armor, car, base, rune).

This table presents FID scores, a metric for evaluating the quality of generated images, for foreground objects in the Road Traffic dataset. Two model training approaches are compared: one using only entire images and another using both entire images and cropped foreground object patches. Lower FID scores indicate better image quality. The table shows the FID scores broken down by object category (traffic light, motor cycle, fire hydrant, crosswalk, bus, bicycle). The results highlight the improvement in image quality achieved when training the model using both entire images and cropped foreground patches.

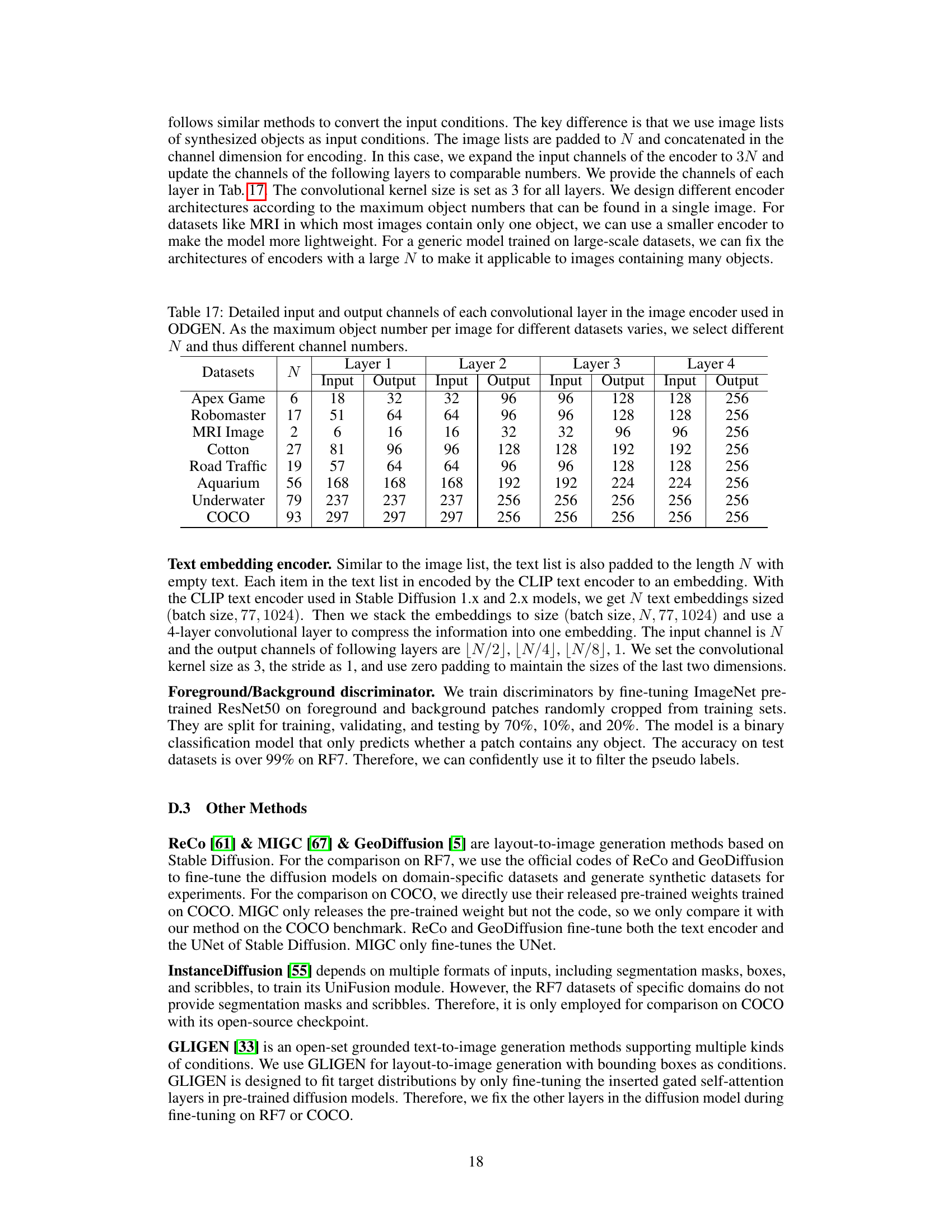
This table details the architecture of the image encoder used in the ODGEN model. The number of input and output channels for each of the four convolutional layers is shown for eight different datasets (Apex Game, Robomaster, MRI Image, Cotton, Road Traffic, Aquarium, Underwater, and COCO). The ‘N’ column represents the number of objects, influencing the channel dimensions.

This table presents the Fréchet Inception Distance (FID) scores for 5000 synthetic images generated by different methods across seven domain-specific datasets (RF7). Lower FID scores indicate better image quality and higher fidelity to real images. The table demonstrates that ODGEN outperforms other methods in generating high-quality synthetic images for all seven datasets.
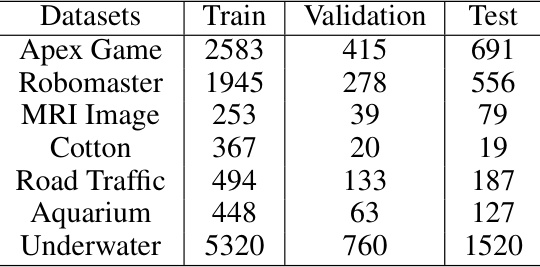
This table shows the number of training, validation, and testing images for each of the seven datasets (Apex Game, Robomaster, MRI Image, Cotton, Road Traffic, Aquarium, and Underwater) that were selected from the Roboflow-100 benchmark to form the RF7 dataset. These numbers are used to evaluate the performance of ODGEN under data scarcity conditions, as only 200 images were initially used for training in each dataset.

This table presents the Fréchet Inception Distance (FID) scores for 5000 synthetic images generated by different methods across 7 domain-specific datasets (RF7). Lower FID scores indicate better image quality and higher fidelity to real images. The results show that ODGEN consistently outperforms other methods (ReCo, GLIGEN, ControlNet, GeoDiffusion) in generating high-fidelity synthetic images across all seven domains.

This table presents the mean Average Precision (mAP) at IoU thresholds from 0.5 to 0.95 for YOLOv5s and YOLOv7 object detectors. The models were trained using 200 real images and 5000 synthetic images generated by different methods, including the proposed ODGEN. A baseline is also provided which uses only the 200 real images for training. The table shows the improvements in mAP achieved by adding the synthetic data generated by each method, with ODGEN showing the largest improvement across all seven domain-specific datasets.

This table shows the training time required for one epoch on the COCO dataset using 8 V100 GPUs for five different methods: ReCo, GLIGEN, ControlNet, GeoDiffusion, and ODGEN. The training times vary significantly across methods, suggesting differences in model complexity and training strategies.

This table presents a comparison of Fréchet Inception Distance (FID) scores and mean Average Precision (mAP) values for YOLOv5s and YOLOv7 models. The models were trained using ODGEN on the COCO dataset, with 41,000 synthetic images generated for FID calculation and 10,000 used for training mAP, which was validated on 31,000 real images. A key aspect is the evaluation of using different offline image libraries during inference, demonstrating ODGEN’s robustness to variations in the image data used for inference.

This table presents the BLIP-VQA scores for different image generation methods. BLIP-VQA measures the consistency between synthesized images and their corresponding text descriptions. Higher scores indicate better alignment between the visual and textual content. The results are averaged across 41,000 images generated using the labels from the COCO validation set. The table compares the performance of several methods, including ReCo, GLIGEN, ControlNet, GeoDiffusion, MIGC, Instance Diffusion, and ODGEN. The Ground Truth (reference) score is also provided for comparison. The results show that ODGEN significantly outperforms the other methods in terms of image-text alignment.

This table shows the Fréchet Inception Distance (FID) and mean Average Precision (mAP) scores for the YOLOv5s and YOLOv7 object detection models trained on synthetic images generated by ODGEN and other methods. The lower FID indicates better image quality, while the higher mAP@0.50 and mAP@0.50:0.95 values indicate better object detection performance. The results are based on the COCO dataset, with 41,000 images used for FID calculation and 10,000 synthetic images used for training, and 31,000 real images for validation. It compares ODGEN’s performance with different versions of Stable Diffusion, highlighting the impact of the method on the quality and usability of the synthetic images generated for model training.
Full paper#