↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Artificial Neural Networks (ANNs), inspired by the human brain, ideally utilize sparse representations where only relevant signals are activated. However, existing activation functions struggle to fully suppress irrelevant signals, impacting network performance. This noise interference hinders accurate decision-making and optimal sparsity in the network.
The paper introduces Dual-Perspective Activation (DPA), a novel, end-to-end trainable mechanism that effectively addresses this issue. DPA leverages both forward and backward propagation to establish a joint criterion for identifying and suppressing irrelevant channels. This parameter-free and fast method improves sparsity, resulting in significant performance improvements across numerous datasets and ANN architectures. The code is publicly available.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation of existing activation mechanisms in artificial neural networks (ANNs). By proposing a novel Dual-Perspective Activation (DPA) mechanism, it provides a more efficient and effective way to suppress noise and improve sparsity, leading to significant performance gains across various tasks and network architectures. This work is highly relevant to current research trends in ANN optimization, and the proposed DPA mechanism offers a promising avenue for further investigation and improvement of ANN performance.
Visual Insights#
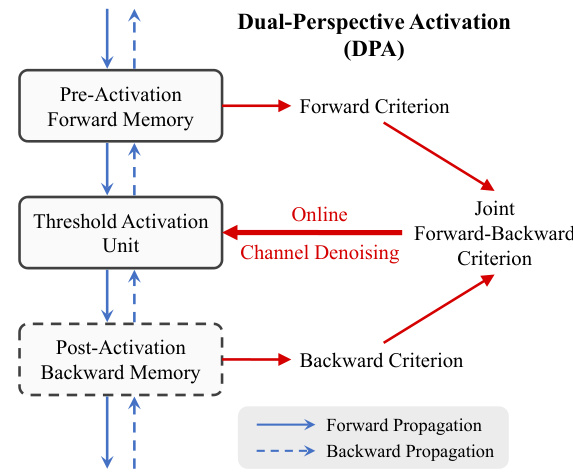
This figure illustrates the Dual-Perspective Activation (DPA) mechanism. DPA consists of three main components working together: Pre-Activation Forward Memory (PreA-FM) which tracks historical activation values; a Threshold Activation Unit (TAU) which processes the input signals; and a Post-Activation Backward Memory (PostA-BM) which tracks historical gradient statistics. These components work together online to identify irrelevant channels. Based on a joint criterion from forward and backward propagation, DPA applies channel denoising, preserving relevant channel activations.
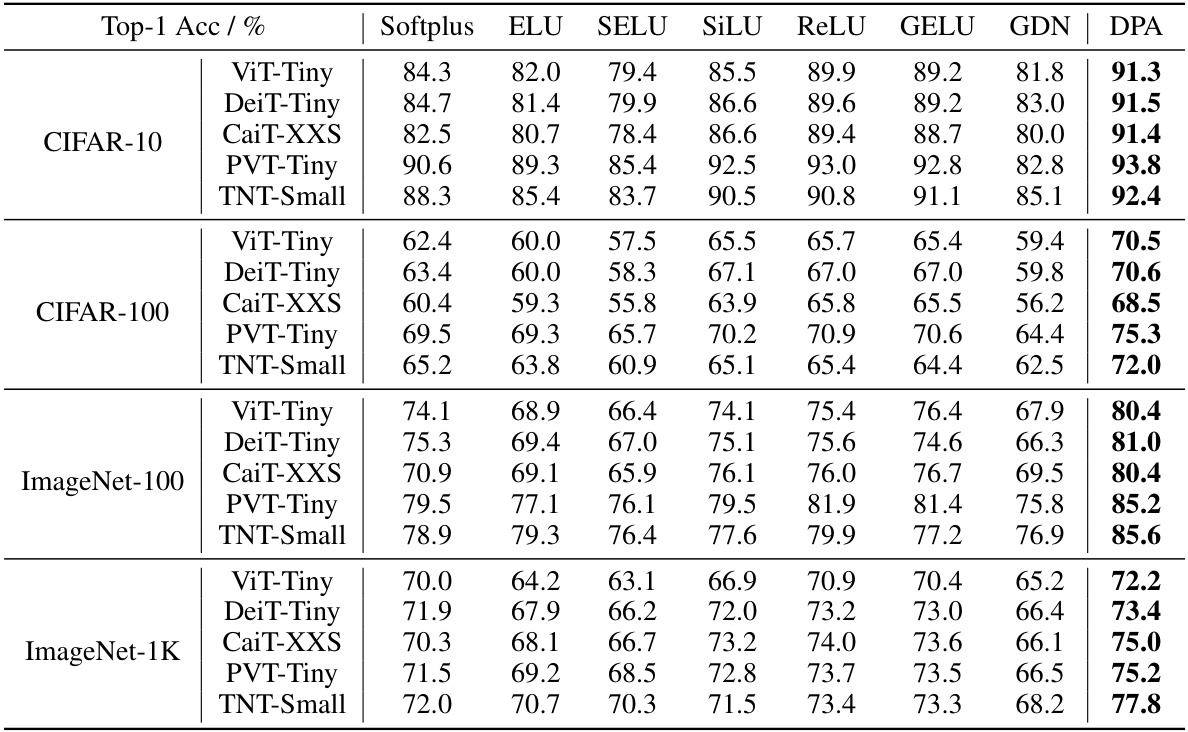
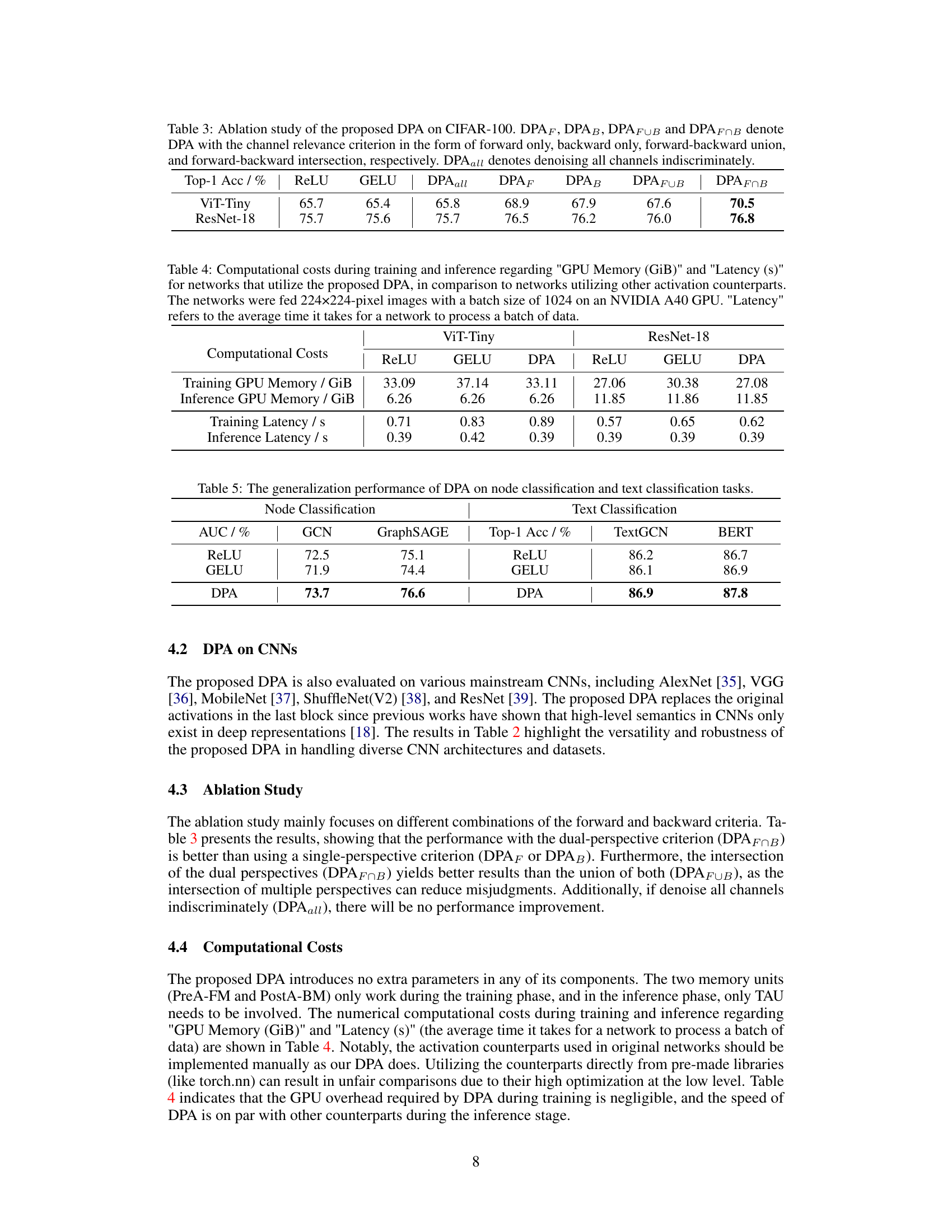
This table presents the Top-1 accuracy results achieved by various Vision Transformer (ViT) architectures (ViT-Tiny, DeiT-Tiny, CaiT-XXS, PVT-Tiny, and TNT-Small) across four image classification datasets (CIFAR-10, CIFAR-100, ImageNet-100, and ImageNet-1K). The results are compared for different activation functions (Softplus, ELU, SELU, SiLU, ReLU, GELU, GDN) and the proposed Dual-Perspective Activation (DPA) mechanism. The table demonstrates DPA’s superior performance compared to other activation functions.
In-depth insights#
Dual-Perspective Activation#
The concept of ‘Dual-Perspective Activation’ presents a novel approach to channel denoising in artificial neural networks. It leverages information from both forward and backward propagation, a dual perspective, to identify and suppress irrelevant channel activations while preserving those deemed important. This joint criterion, established online, offers a dynamic and adaptive mechanism, unlike static thresholding techniques. Efficiency is a key advantage, being parameter-free and computationally fast. The approach’s end-to-end trainability simplifies integration into existing architectures. Furthermore, the method demonstrates enhanced sparsity in neural representations, potentially improving generalization and interpretability. However, the effectiveness might depend on the specific network architecture and task, requiring further investigation into its robustness across diverse applications. The impact of hyperparameters also requires careful analysis to optimize performance.
Channel Denoising#
Channel denoising, in the context of artificial neural networks (ANNs), is a crucial technique to enhance model performance and interpretability. The core idea revolves around identifying and suppressing irrelevant or noisy signals propagating through specific channels within the ANN architecture. This is achieved by employing strategies that selectively attenuate the activations from these less-relevant channels while preserving the activations of important channels. Effective channel denoising is vital for achieving sparse representations, which helps improve model generalization, reduces overfitting, and enhances the model’s ability to extract relevant features. The effectiveness of channel denoising depends heavily on how accurately it identifies irrelevant channels. Methods such as the Dual-Perspective Activation (DPA) leverage both forward and backward propagation information to make such a determination. However, challenges remain in perfecting this process, as determining relevance is not always straightforward. It requires careful consideration of both the activation values and gradients, and it’s essential to avoid excessively suppressing relevant channels. Further research should focus on developing more robust methods for identifying and removing noise effectively, striking a balance between sparsity and preserving crucial information. The ultimate goal is to design mechanisms that lead to more efficient and accurate ANNs.
ANN Sparsity#
Artificial Neural Networks (ANNs), inspired by biological neural networks, often exhibit superior performance with sparse representations. Sparsity, meaning a smaller subset of neurons are activated at any given time, mirrors the efficiency observed in biological systems. This has several advantages for ANNs: improved generalization, enhanced interpretability by highlighting key features, and reduced computational cost. Achieving sparsity is key, and techniques such as using activation functions like ReLU (Rectified Linear Unit) which suppress negative activations, or employing sparsity-inducing regularization methods during training, are commonly used. However, simply achieving sparsity is insufficient. The challenge lies in ensuring that the suppressed neurons are indeed irrelevant, and not valuable information being lost. Therefore, sophisticated methods are required to identify and preserve truly relevant activations while effectively suppressing noise, balancing sparsity with accuracy. The dual-perspective activation method described in this paper demonstrates one approach, and future research should focus on developing even more robust and adaptable strategies to harness the power of sparsity in ANNs.
Experimental Results#
A thorough analysis of the ‘Experimental Results’ section requires a multifaceted approach. It should begin with a clear articulation of the research questions and hypotheses, ensuring the experiments directly address them. The methodology should be meticulously described, including the datasets, evaluation metrics, and experimental setup, enabling reproducibility. Detailed results, presented in tables, figures, and text, are essential, including error bars or confidence intervals to illustrate statistical significance. The discussion should go beyond simply presenting the findings; comparisons with baselines or prior work, including qualitative observations, should provide context and demonstrate advancements. Importantly, limitations should be honestly acknowledged. Any unexpected or contradictory findings should be discussed, offering potential explanations. Finally, a concise summary should reiterate the key findings, highlighting their implications for the broader research area and future directions.
Future Work#
The ‘Future Work’ section of this research paper could explore several promising avenues. Extending DPA to other network architectures beyond the tested CNNs and ViTs is crucial for demonstrating its general applicability. Investigating the impact of different thresholding strategies within the Threshold Activation Unit (TAU) could refine DPA’s performance and sparsity. A detailed analysis of DPA’s computational cost across various datasets and model sizes, especially on resource-constrained hardware, would provide practical insights. Further, exploring DPA’s synergy with other sparsity-inducing techniques could lead to even more efficient and accurate models. Finally, a thorough investigation into the theoretical properties of DPA and its relationship to information theory would deepen our understanding. Empirically evaluating DPA’s robustness on noisy datasets and adversarial examples is important for its real-world deployment. Developing a more sophisticated channel selection criterion using advanced techniques like attention mechanisms could boost performance. Also, comparing DPA to other channel pruning and denoising methods would highlight its advantages and unique capabilities. Additionally, researching applications in other domains beyond image classification is a natural extension.
More visual insights#
More on figures
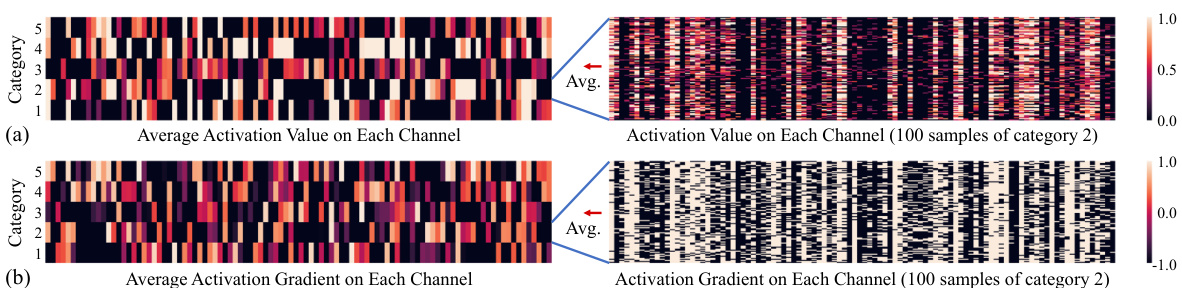
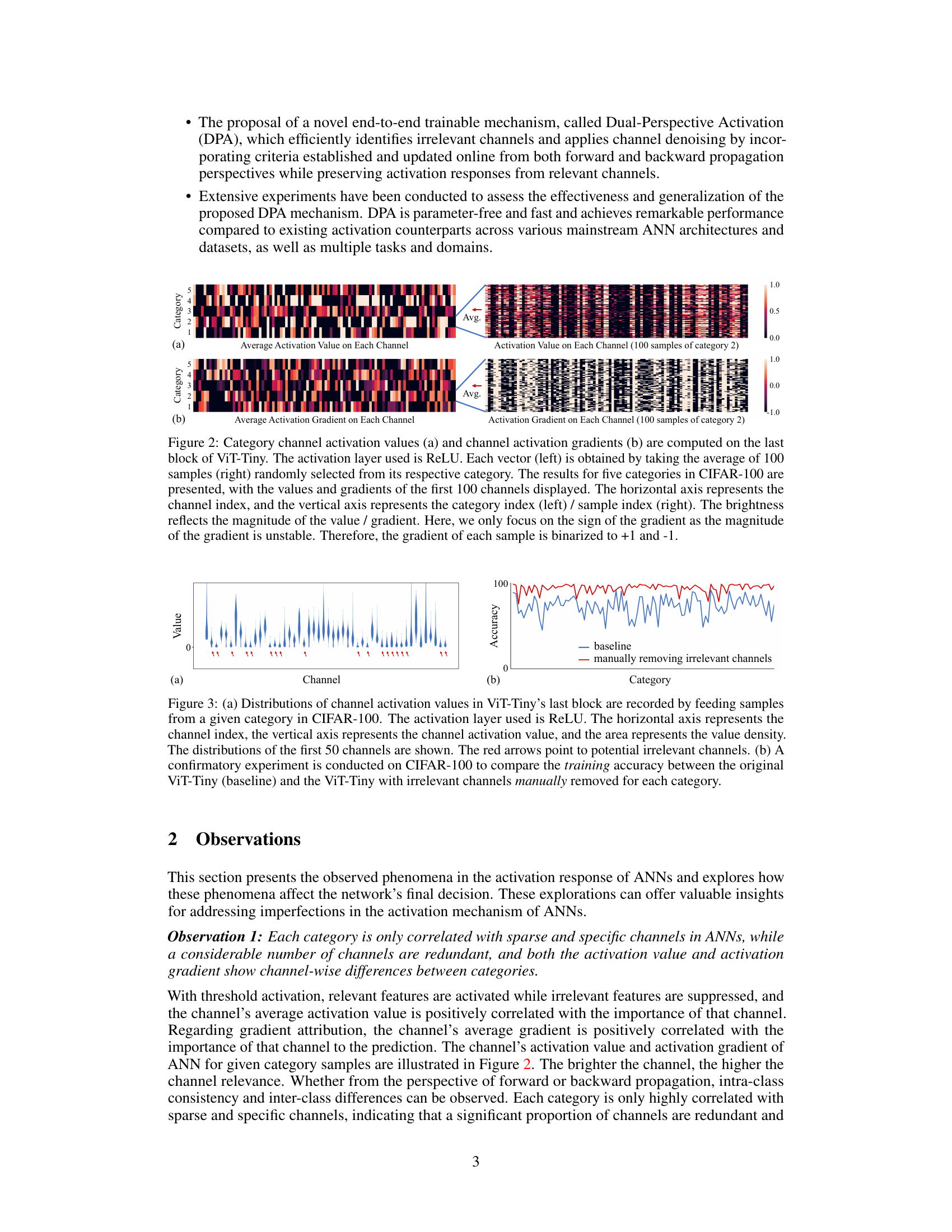
This figure shows the average activation values and gradients across channels for five different categories in the CIFAR-100 dataset, using the ViT-Tiny model with ReLU activation. The left side of each subplot shows the average activation values/gradients across 100 samples for each category, while the right side shows the individual activation values/gradients for 100 samples from a single category. The visualization highlights the correlation between specific channels and different categories. The brightness of the cells represents the magnitude of activation value or gradient.

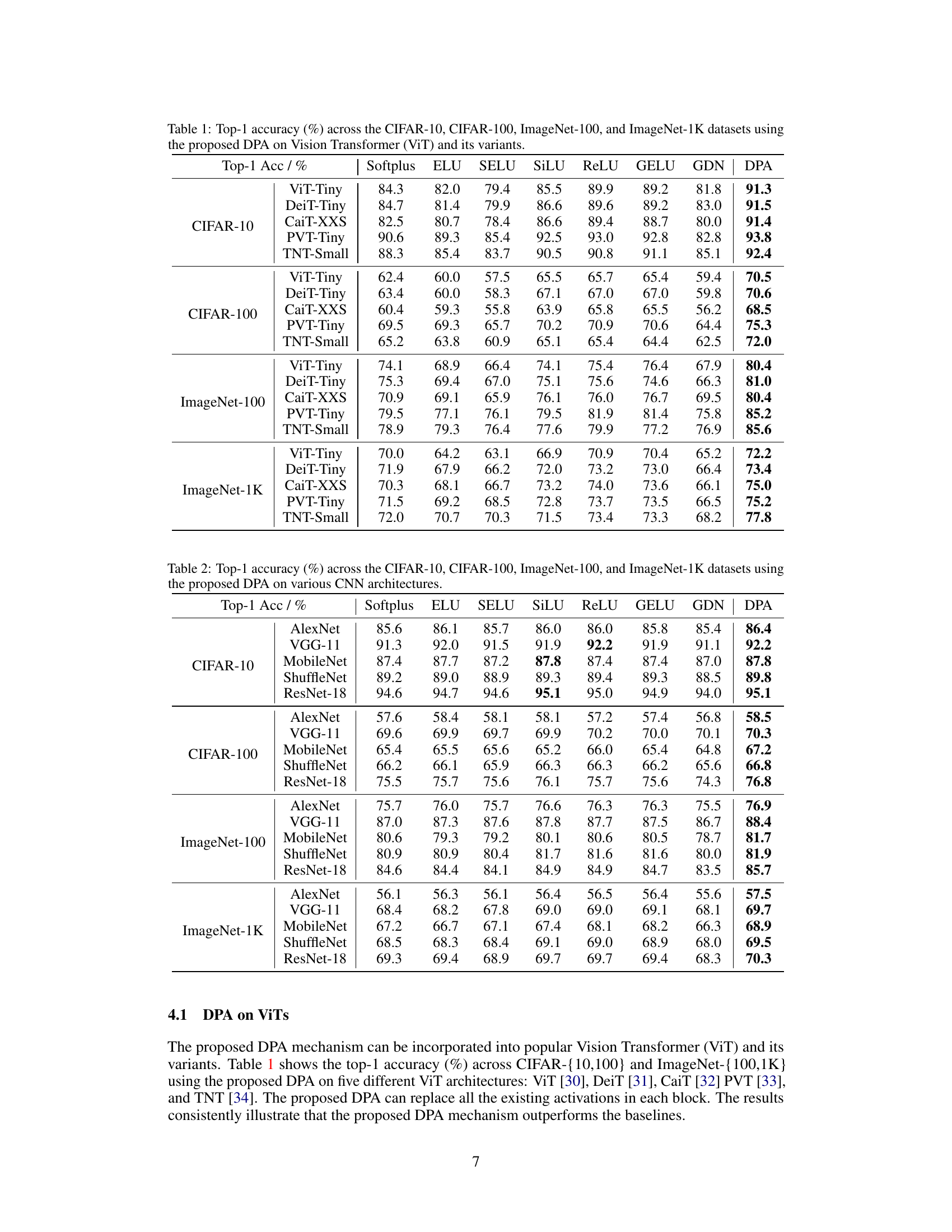
This figure shows the distribution of channel activation values for a given category in CIFAR-100 dataset using ReLU activation function in the last block of ViT-Tiny. Red arrows indicate potential irrelevant channels. Subfigure (b) compares the training accuracy of original ViT-Tiny with that of a modified version where irrelevant channels were manually removed. The results demonstrate the negative impact of irrelevant channels on accuracy.
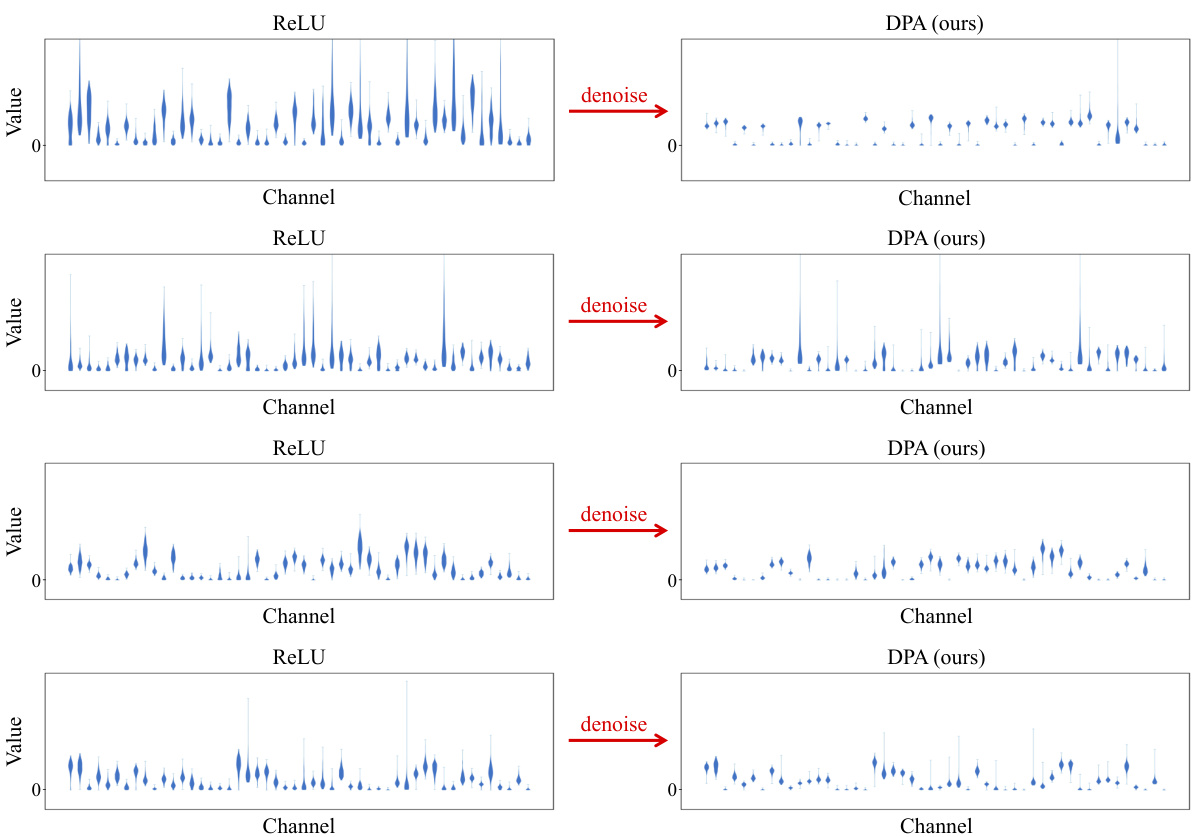
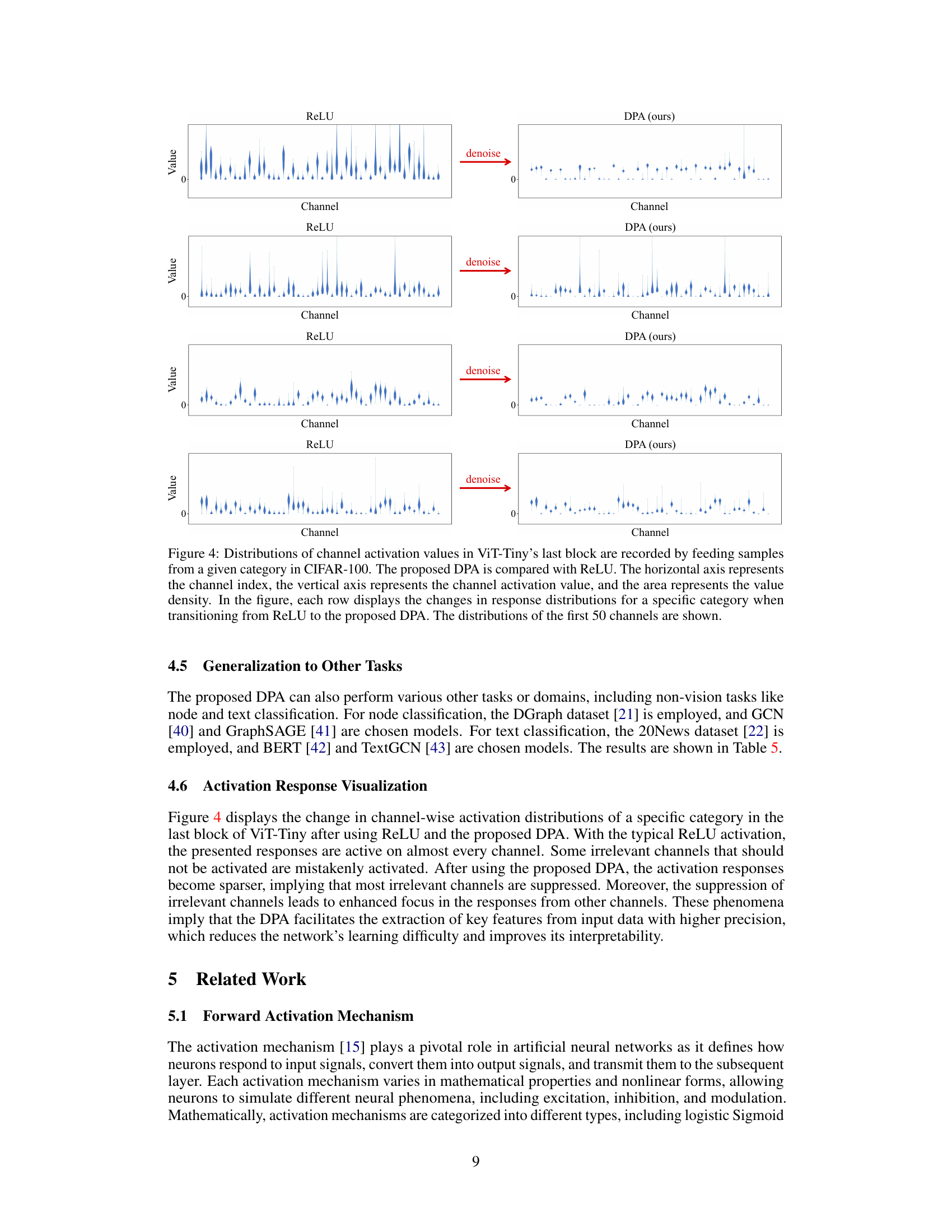
This figure compares the distribution of channel activation values between ReLU and DPA for four different categories in CIFAR-100 dataset. It visually demonstrates how DPA effectively suppresses activations from irrelevant channels, resulting in a sparser and more focused representation.
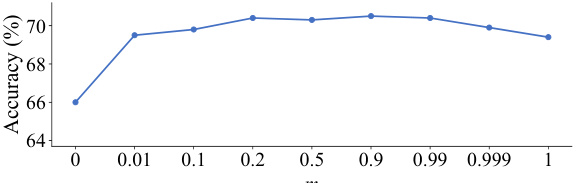
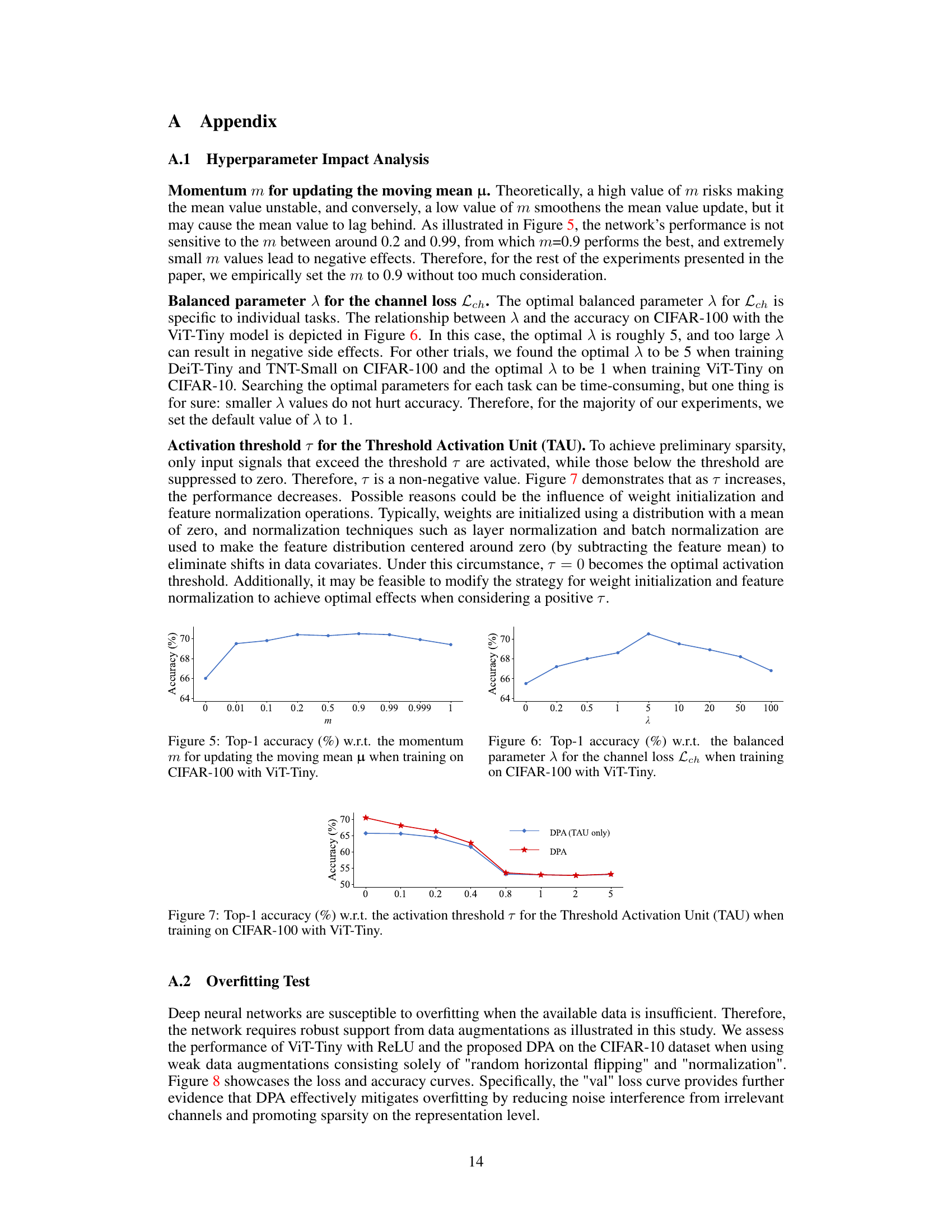
This figure shows the impact of the momentum (m) parameter used in updating the moving mean (µ) on the Top-1 accuracy of the ViT-Tiny model trained on the CIFAR-100 dataset. The x-axis represents different values of the momentum parameter, and the y-axis represents the resulting Top-1 accuracy. The graph indicates that the model’s performance is relatively insensitive to the choice of momentum within a wide range (approximately 0.2 to 0.99), with a peak accuracy around m = 0.9. Extremely low values of m negatively affect performance.
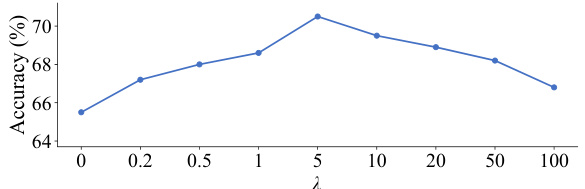
This figure shows the relationship between the balanced parameter λ used in the channel loss calculation and the resulting top-1 accuracy achieved when training the ViT-Tiny model on the CIFAR-100 dataset. The x-axis represents different values of λ, while the y-axis shows the corresponding top-1 accuracy. The graph indicates an optimal range for λ where accuracy is maximized, demonstrating a sensitivity of model performance to the choice of this hyperparameter.
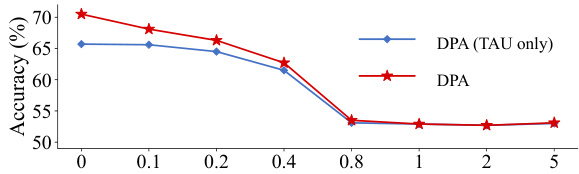
This figure shows the impact of the activation threshold (τ) in the Threshold Activation Unit (TAU) on the model’s accuracy. The experiment was conducted on the CIFAR-100 dataset using the ViT-Tiny model. It demonstrates that as the threshold τ increases, the accuracy decreases, suggesting that setting τ to 0 is optimal for this experiment. The graph compares the accuracy with only TAU and the full DPA mechanism.
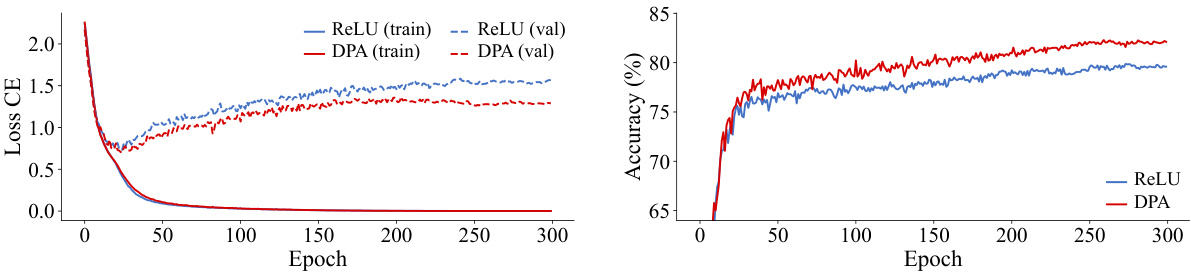
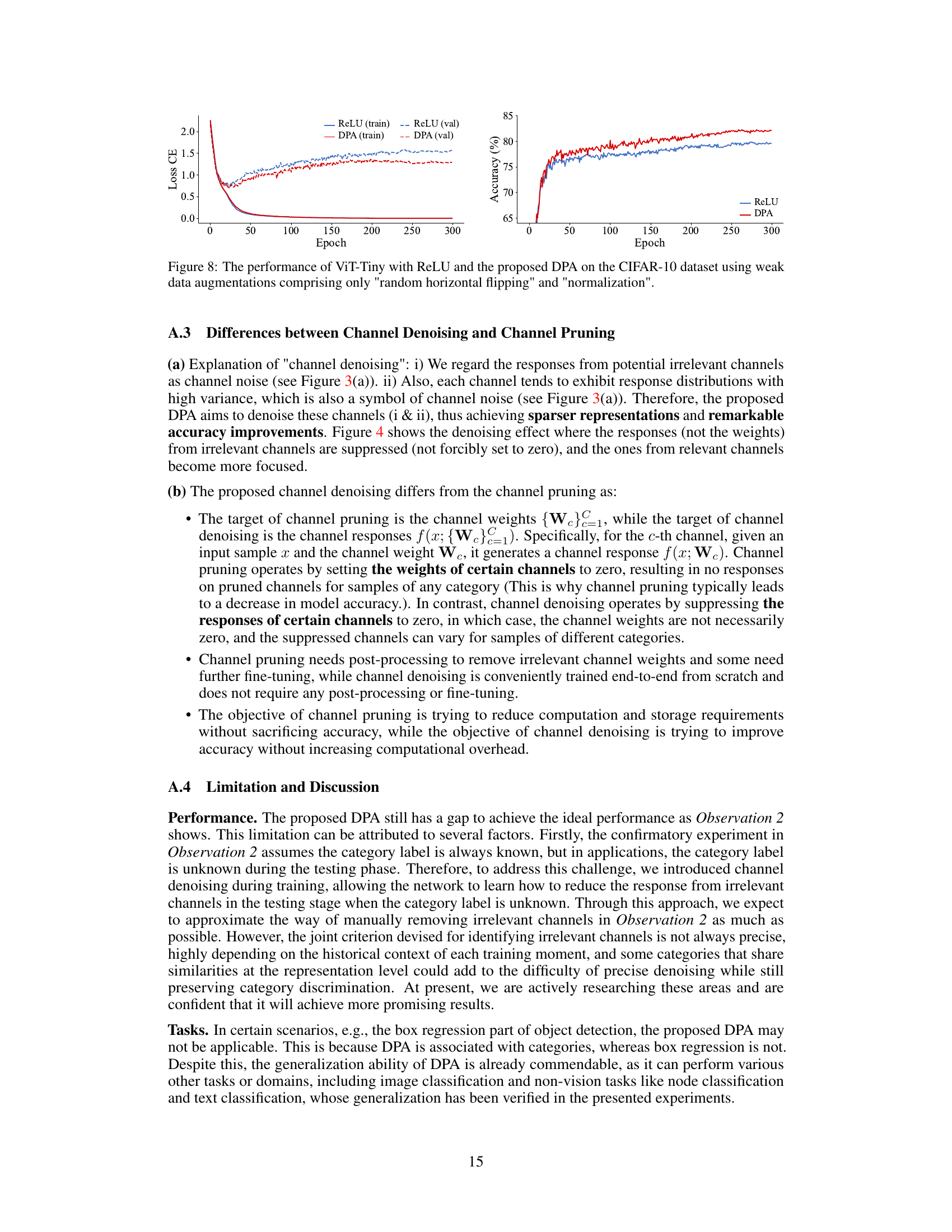
This figure demonstrates the training and validation loss and accuracy curves for ViT-Tiny using ReLU and the proposed DPA activation function on the CIFAR-10 dataset. Only weak data augmentations (random horizontal flipping and normalization) were used. The DPA model shows improved performance, particularly lower validation loss, suggesting better generalization and reduced overfitting.
More on tables
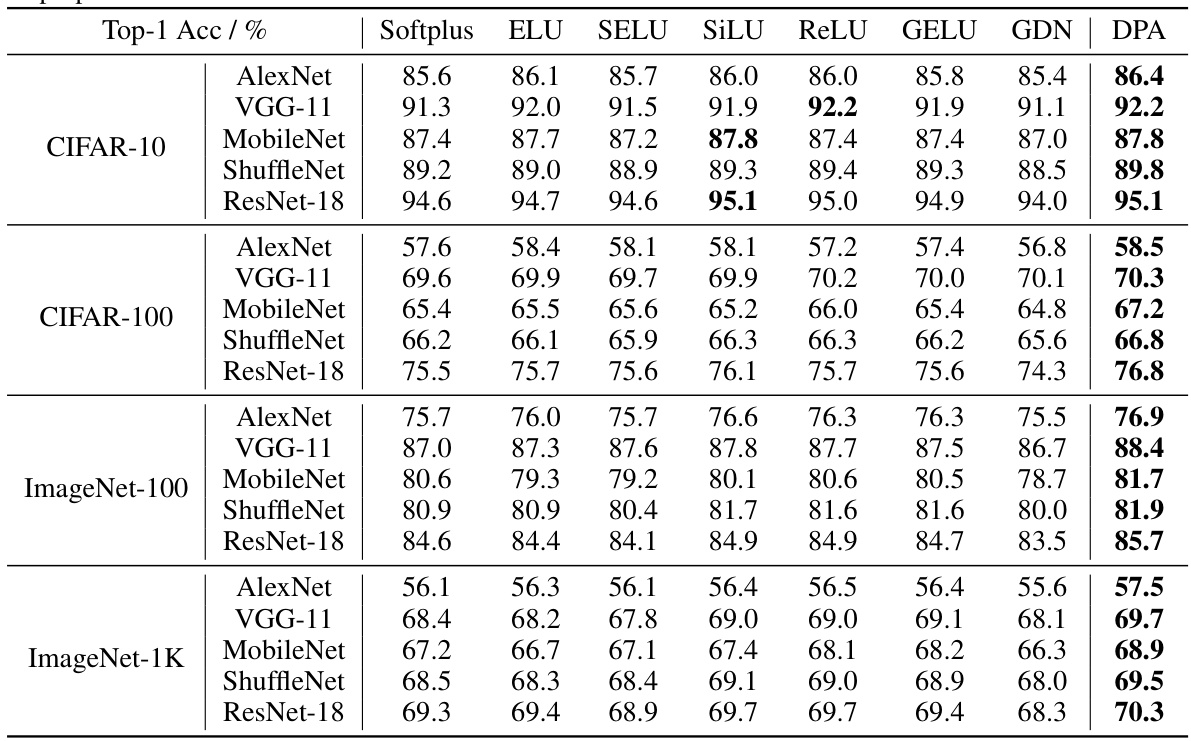
This table presents the Top-1 accuracy results achieved by the proposed Dual-Perspective Activation (DPA) mechanism when compared against several other mainstream activation functions. The comparison is performed across four different image classification datasets (CIFAR-10, CIFAR-100, ImageNet-100, and ImageNet-1K) and five different Convolutional Neural Network (CNN) architectures (AlexNet, VGG-11, MobileNet, ShuffleNet, and ResNet-18). The table demonstrates the performance gains obtained by using DPA over the other activation functions.

This table presents the results of an ablation study conducted on the CIFAR-100 dataset to evaluate the impact of different variations of the Dual-Perspective Activation (DPA) mechanism on the classification accuracy. It compares the performance of DPA using only forward criteria (DPAF), only backward criteria (DPAB), the union of both (DPAFUB), and the intersection of both (DPAFOB). It also includes a baseline where all channels are denoised indiscriminately (DPAall), and compares these to standard ReLU and GELU activations. The results demonstrate the superior performance of DPAFOB, highlighting the importance of considering both forward and backward perspectives when identifying and addressing irrelevant channels.
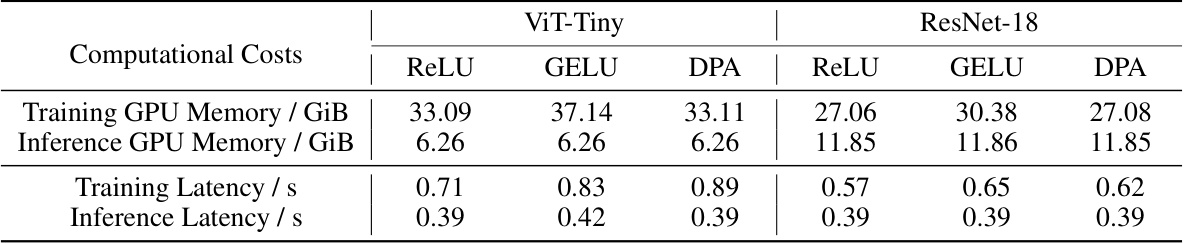
This table presents a comparison of computational costs (GPU memory usage and processing latency) for different activation functions including the proposed DPA and several commonly used activation functions. The experiments were performed on two different network architectures (ViT-Tiny and ResNet-18) using 224x224 pixel images and a batch size of 1024 on an NVIDIA A40 GPU. The results highlight the efficiency of DPA in terms of both memory consumption and processing time.

This table shows the results of applying the Dual-Perspective Activation (DPA) method to node classification and text classification tasks. It compares the Area Under the Curve (AUC) for node classification using Graph Convolutional Networks (GCN) and GraphSAGE, and the Top-1 Accuracy for text classification using TextGCN and BERT. The results are presented for ReLU, GELU, and DPA activation functions, demonstrating the improved performance of DPA across various network architectures and tasks.
Full paper#