↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large language models (LLMs) are powerful but require significant resources for fine-tuning to specific tasks or users. Parameter-efficient fine-tuning (PEFT) methods aim to reduce this cost, but even these methods can be expensive in terms of storage and transmission. This creates a bottleneck for deploying personalized LLMs.
VB-LoRA tackles this problem by using a new “divide-and-share” approach. It breaks down the parameters into smaller components and shares them across different parts of the model via a vector bank. This results in extreme parameter efficiency while maintaining high performance, with VB-LoRA using only a fraction of the parameters required by other methods. The study shows impressive performance on several tasks, demonstrating its effectiveness and potential to revolutionize PEFT.
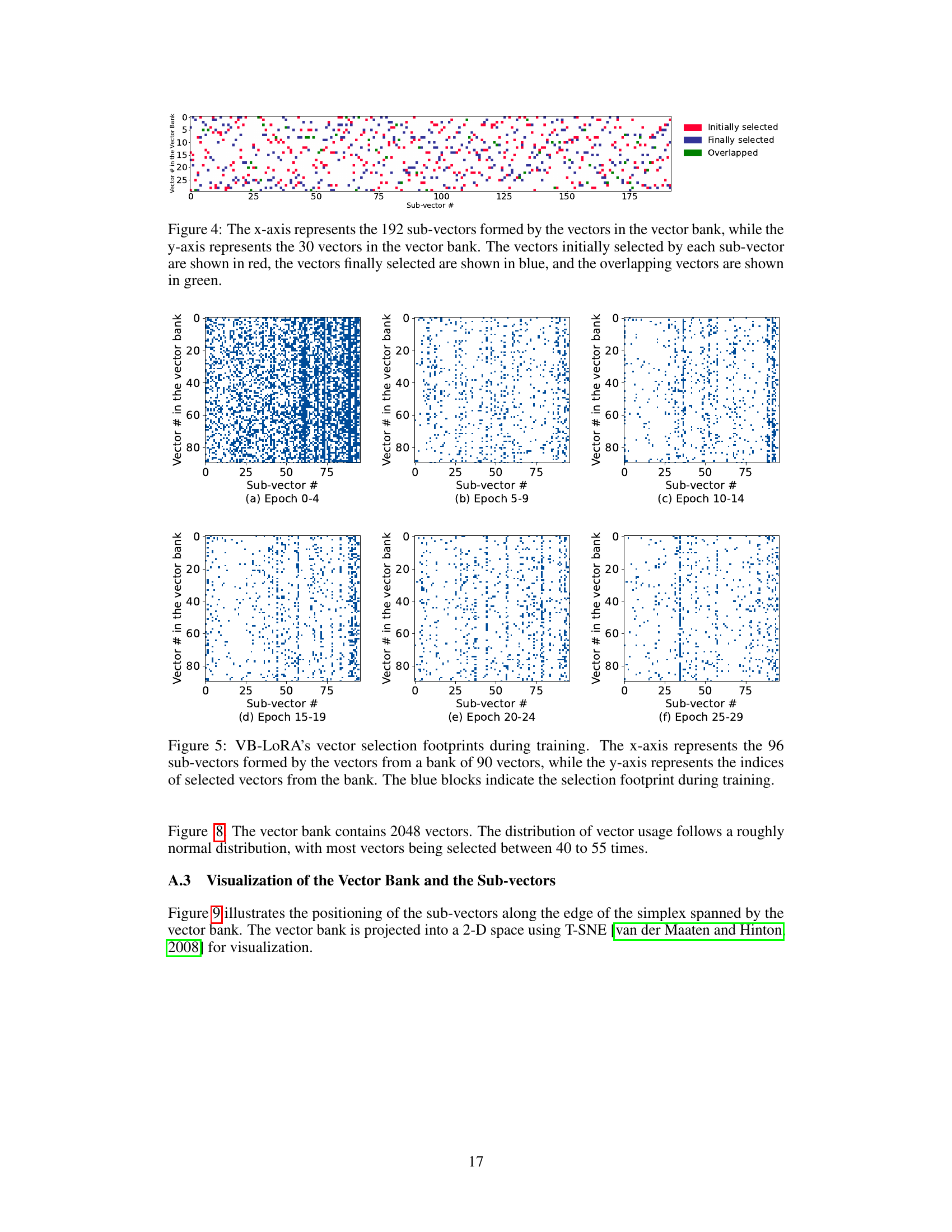
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on parameter-efficient fine-tuning (PEFT) of large language models. It introduces VB-LoRA, a novel method that drastically reduces the storage and transmission costs associated with PEFT, opening new avenues for deploying customized LLMs on resource-constrained devices. The extreme parameter efficiency achieved by VB-LoRA addresses a significant challenge in the field and promotes further research into efficient LLM customization.
Visual Insights#
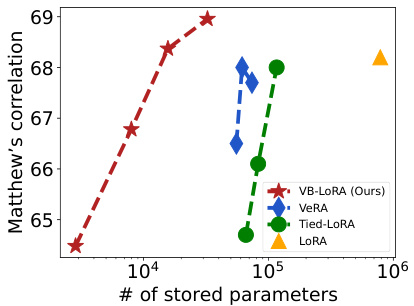
This figure compares the performance and parameter efficiency of several parameter-efficient fine-tuning (PEFT) methods on the RoBERTa-Large model. The x-axis represents the number of stored parameters used by each method, while the y-axis represents Matthew’s correlation, a metric used to evaluate the performance on a specific task (not specified in the caption). The figure shows that VB-LORA (the proposed method) significantly outperforms other methods such as LoRA, Tied-LoRA, and VeRA, while using considerably fewer parameters. This demonstrates the superior parameter efficiency of VB-LORA.

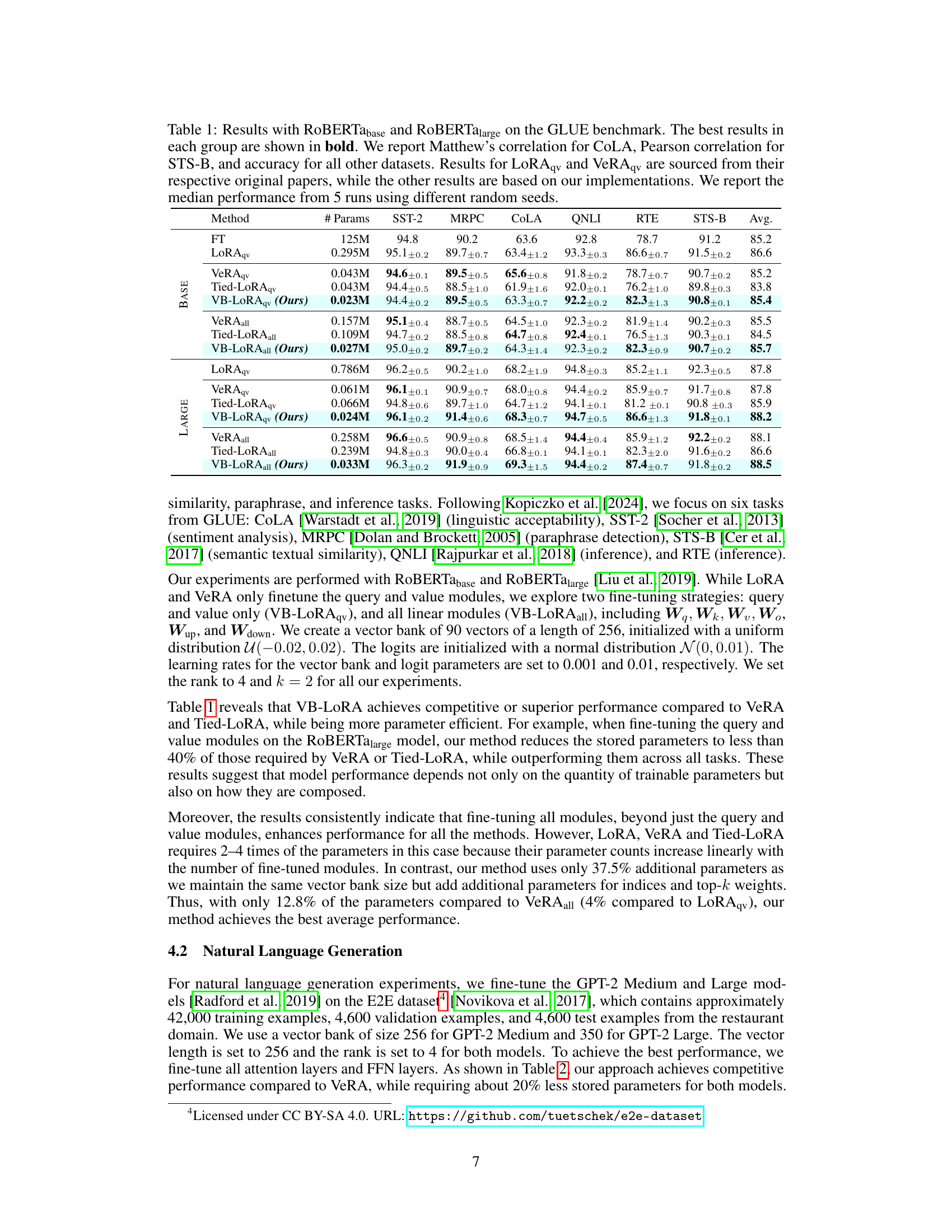
This table presents the results of the experiments conducted on the GLUE benchmark using different parameter-efficient fine-tuning methods: LoRA, VeRA, Tied-LoRA, and the proposed VB-LoRA. The table compares the performance of these methods on six tasks from GLUE (SST-2, MRPC, CoLA, QNLI, RTE, and STS-B) using both RoBERTabase and RoBERTalarge models. The results are presented as the median accuracy or correlation from five runs, and the best-performing method for each task is highlighted in bold. The table also shows the number of parameters used by each method, highlighting the efficiency of VB-LORA.
In-depth insights#
VB-LoRA Overview#
VB-LoRA presents a novel approach to parameter-efficient fine-tuning (PEFT) of large language models (LLMs). Its core innovation lies in a ‘divide-and-share’ paradigm, breaking down the low-rank matrices of traditional LoRA into smaller sub-vectors and sharing these across layers and modules via a global vector bank. This extreme parameter efficiency is achieved by reparameterizing LoRA’s low-rank decomposition into a rank-one form, then dividing component vectors into sub-vectors, enabling the use of a differentiable top-k admixture module to select a sparse combination from the shared bank. The resultant model boasts significantly reduced storage and transmission costs while maintaining, and often exceeding, the performance of existing PEFT methods. This method’s effectiveness is demonstrated across various NLP tasks. The introduction of the vector bank and sub-vector approach is particularly noteworthy, demonstrating a potential pathway towards even more extreme parameter compression in future LLMs.
Divide-and-Share#
The proposed ‘Divide-and-Share’ paradigm presents a novel approach to parameter-efficient fine-tuning, pushing the boundaries of existing methods like LoRA. Its core innovation lies in breaking down the barriers of low-rank decomposition across various dimensions: matrix dimensions, modules, and layers. By doing so, it enables global parameter sharing through a vector bank, significantly reducing the number of trainable parameters. This strategy leverages the redundancy inherent in model parameters by partitioning vectors into sub-vectors and learning a shared representation. The use of a differentiable top-k admixture module allows for flexible, sparse selection of vectors from the shared bank, further enhancing efficiency while maintaining performance. Extreme parameter efficiency is achieved, as demonstrated by results that surpass state-of-the-art models using significantly fewer parameters. The ‘Divide-and-Share’ approach represents a paradigm shift in PEFT, opening doors for more efficient model customization and deployment.
Empirical Results#
An effective empirical results section should present findings clearly and concisely, focusing on the most relevant metrics. Strong visualizations are crucial, such as graphs and tables, to make the data easily understandable. The results should be discussed in the context of the research questions and hypotheses, with a clear explanation of whether the findings support or contradict the claims. It’s important to include error bars or confidence intervals to demonstrate the reliability and statistical significance of the results. Any limitations of the experimental setup should be acknowledged transparently and discussed thoroughly. Comparisons to prior work or baseline models are necessary to establish the novelty and impact of the presented results. A thoughtful and detailed analysis of the findings would strengthen the section significantly, leading to a more impactful and convincing research paper. It is also important to keep in mind that the results section should be carefully structured and written in a way that is easy to read, and that the findings are presented in a way that makes it easy for the reader to understand their significance. A well-written empirical results section is therefore essential for a convincing research paper.
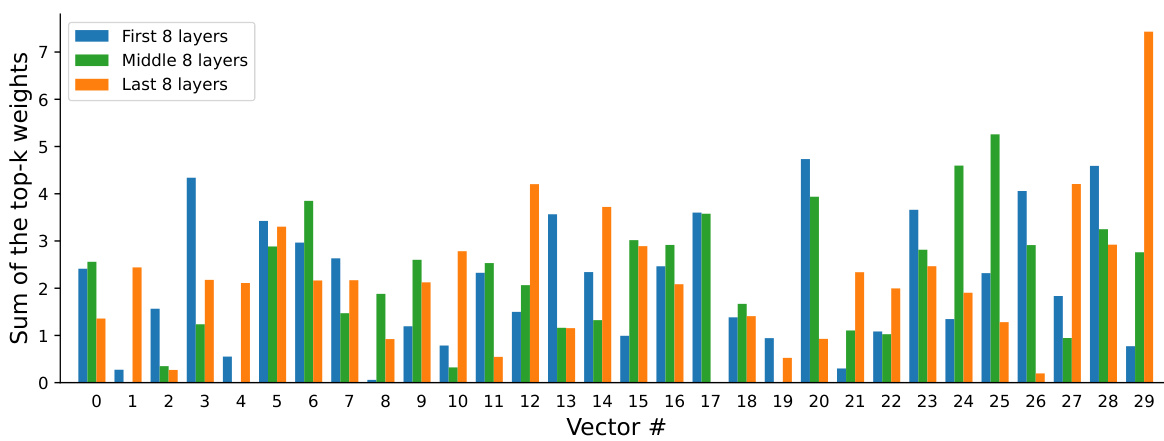
Ablation Studies#
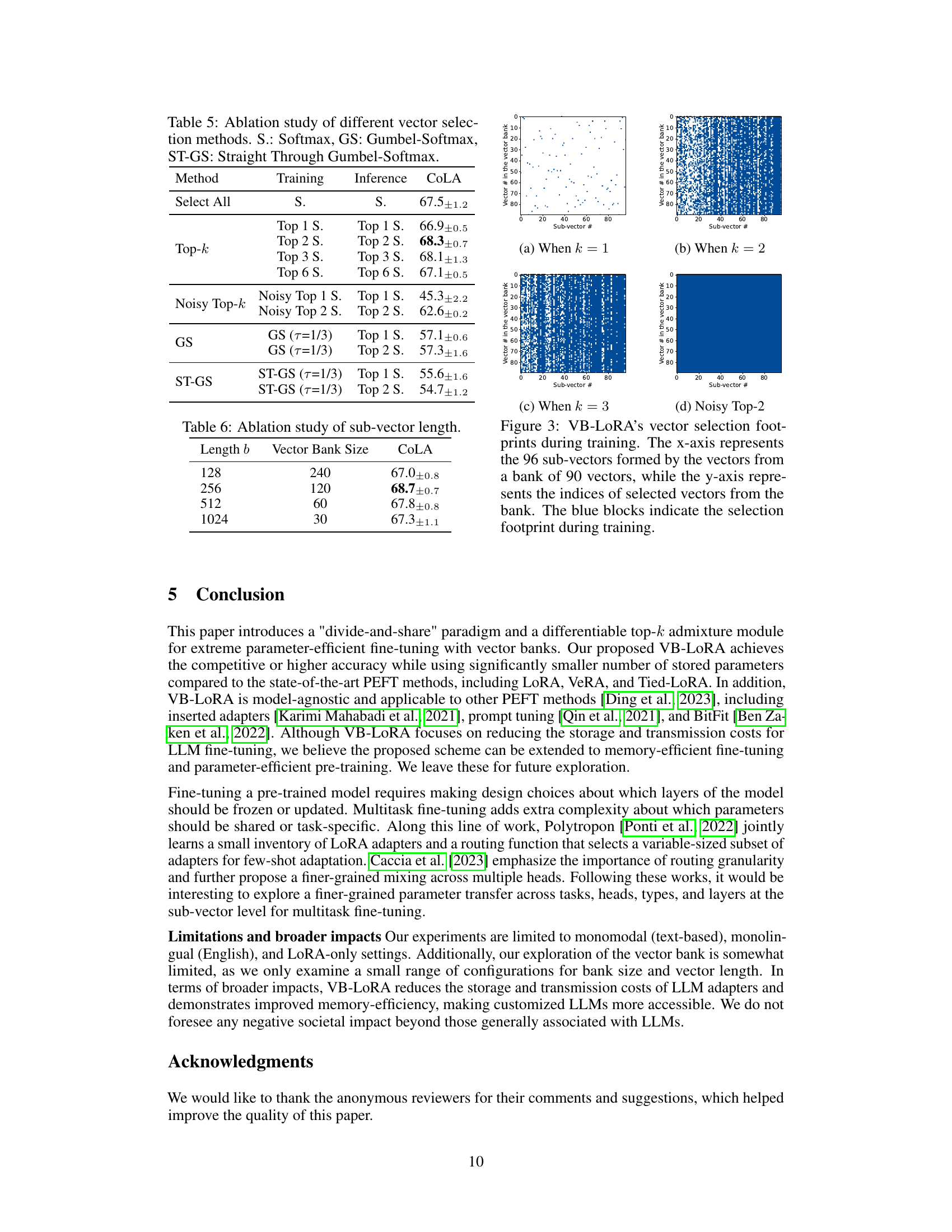
Ablation studies systematically remove components of a model to assess their individual contributions. In this context, it is crucial to isolate each component’s impact and analyze the results comprehensively. For example, removing a specific module or layer allows for direct evaluation of its effect on the overall performance. Careful selection of what to remove is critical, as the chosen components should be relevant to the paper’s claims, and chosen judiciously to avoid confounding results. Quantifiable metrics are crucial to measure the performance impact of removing each element and should be clearly reported and interpreted. Adequate controls and comparisons are vital, such as comparing performance against a baseline model and other comparable methods. The results should offer significant insights into the system’s architecture, revealing the relative importance and contribution of its different parts. This analysis leads to a deeper understanding and potentially to improvements, informing future iterations and designs. Finally, clearly explaining the rationale behind each ablation and the choice of metrics used to assess the performance changes is paramount for ensuring transparency and reproducibility.
Future Works#
The paper’s ‘Future Works’ section could explore several promising avenues. Extending VB-LoRA to other PEFT methods beyond LoRA, such as prefix-tuning or adapter methods, could significantly broaden its applicability and impact. Investigating different vector bank initialization strategies and the influence of bank size on performance warrants further study. A deeper investigation into the theoretical underpinnings of VB-LORA, including a formal analysis of its convergence properties and generalization capabilities, would enhance its credibility and provide a deeper understanding. Furthermore, exploring the impact of different quantization techniques on the model’s performance and memory efficiency, and evaluating the method’s robustness to various data distributions and noise levels, are essential next steps. Finally, scaling up VB-LoRA for larger models and more demanding tasks while maintaining its parameter efficiency is a crucial aspect that necessitates further research. Addressing these research questions would establish VB-LoRA as a robust and versatile technique within the PEFT landscape.
More visual insights#
More on figures
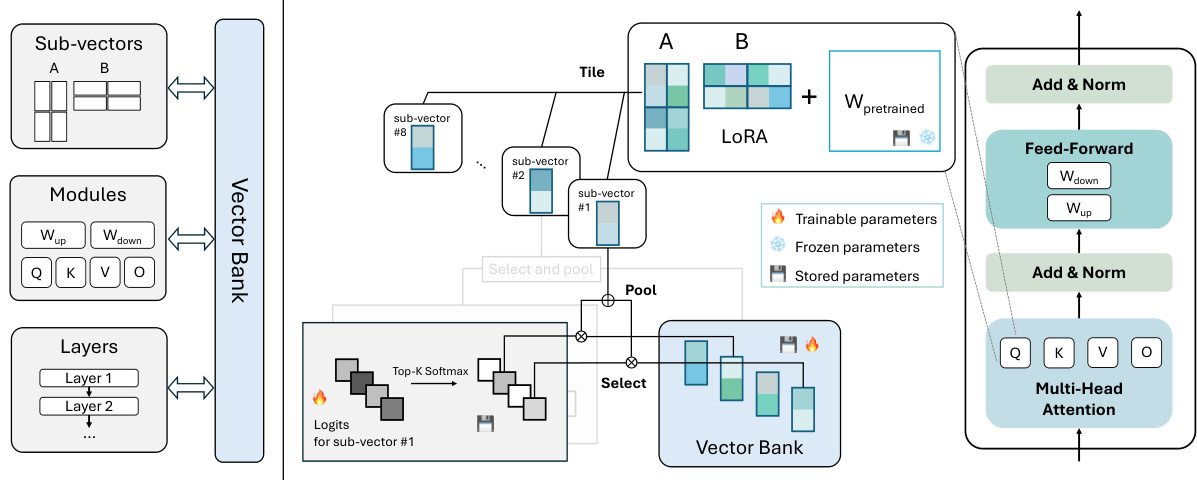
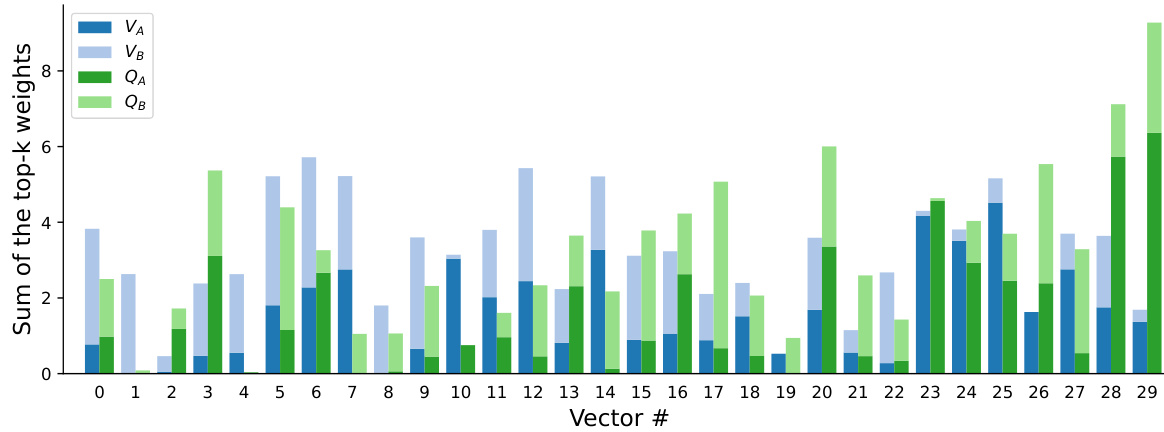
The figure illustrates the concept of VB-LoRA. The left side shows how model parameters are composed of vectors from a shared vector bank across different layers, modules, and sub-vectors. The right side details the VB-LoRA architecture. It shows how a top-k softmax module selects k vectors from the vector bank, pools them into sub-vectors, and then uses these sub-vectors to form the LoRA parameters. This approach enables extreme parameter efficiency by sharing parameters globally.
This figure compares the performance and the number of stored parameters of several parameter-efficient fine-tuning (PEFT) methods on the RoBERTa-Large model. The x-axis represents the number of stored parameters (log scale), and the y-axis represents the Matthew’s correlation coefficient for the model’s performance. The figure shows that VB-LoRA achieves a higher score (better performance) while using a significantly smaller number of stored parameters compared to other methods such as LoRA, Tied-LoRA, and VERA. This demonstrates the extreme parameter efficiency of VB-LoRA.

This figure compares the performance and the number of stored parameters of several parameter-efficient fine-tuning (PEFT) methods on the RoBERTa-Large model. The x-axis represents the number of stored parameters (log scale), and the y-axis represents the Matthew’s correlation, a performance metric. The figure shows that VB-LoRA outperforms other methods (LoRA, Tied-LoRA, VERA) while using significantly fewer parameters, demonstrating its extreme parameter efficiency.
This figure compares the performance and the number of stored parameters of various parameter-efficient fine-tuning (PEFT) methods on the RoBERTa-Large model. The x-axis represents the number of stored parameters (log scale), and the y-axis shows the Matthew’s correlation score. The figure demonstrates that VB-LoRA achieves a higher score (better performance) with significantly fewer parameters compared to other methods like LoRA, Tied-LoRA, and VERA.
This figure compares the performance and the number of stored parameters of various parameter-efficient fine-tuning (PEFT) methods on the RoBERTa-Large model. The x-axis represents the number of stored parameters (on a logarithmic scale), and the y-axis represents Matthew’s correlation, a metric assessing the model’s performance. VB-LoRA outperforms other methods such as LoRA, Tied-LoRA, and VERA while using significantly fewer parameters.
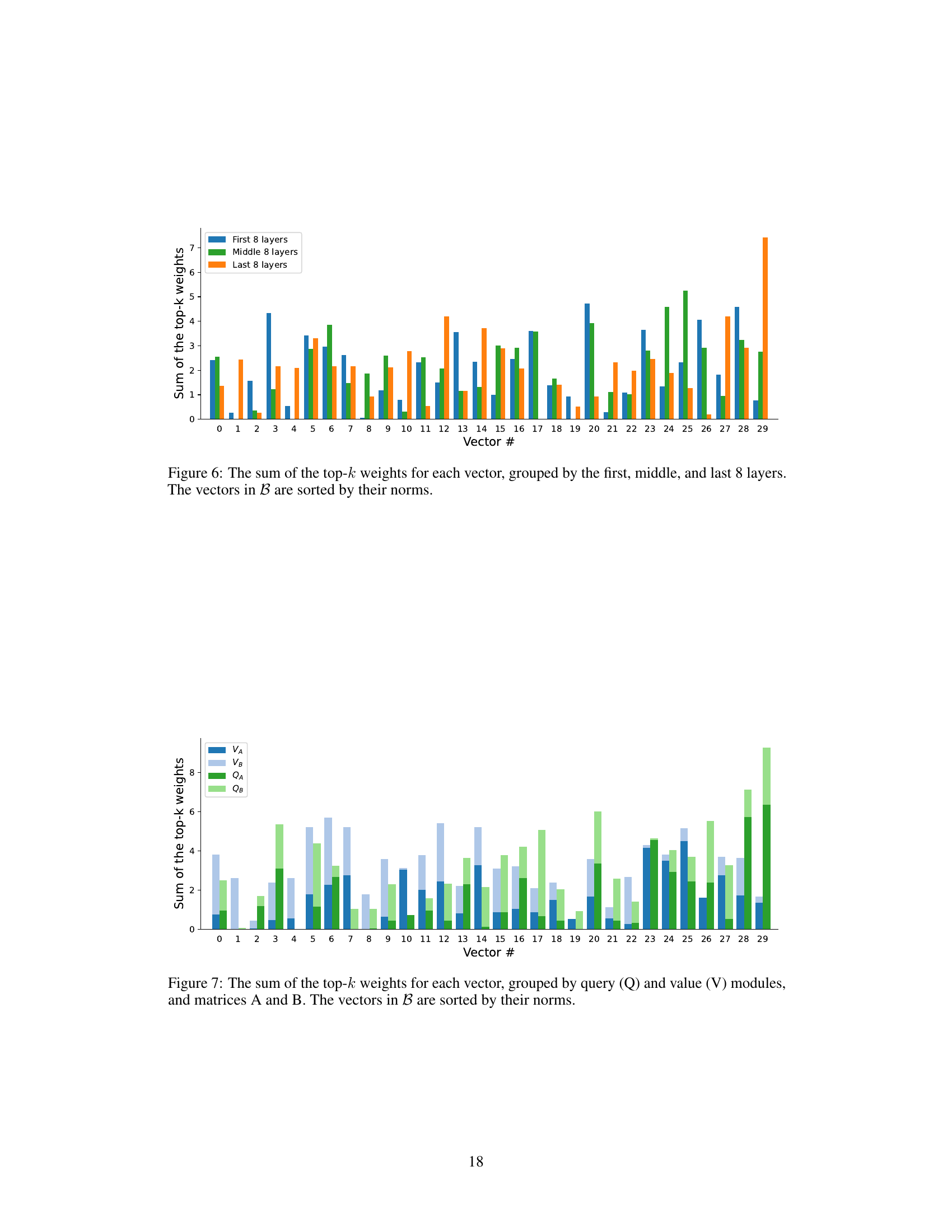
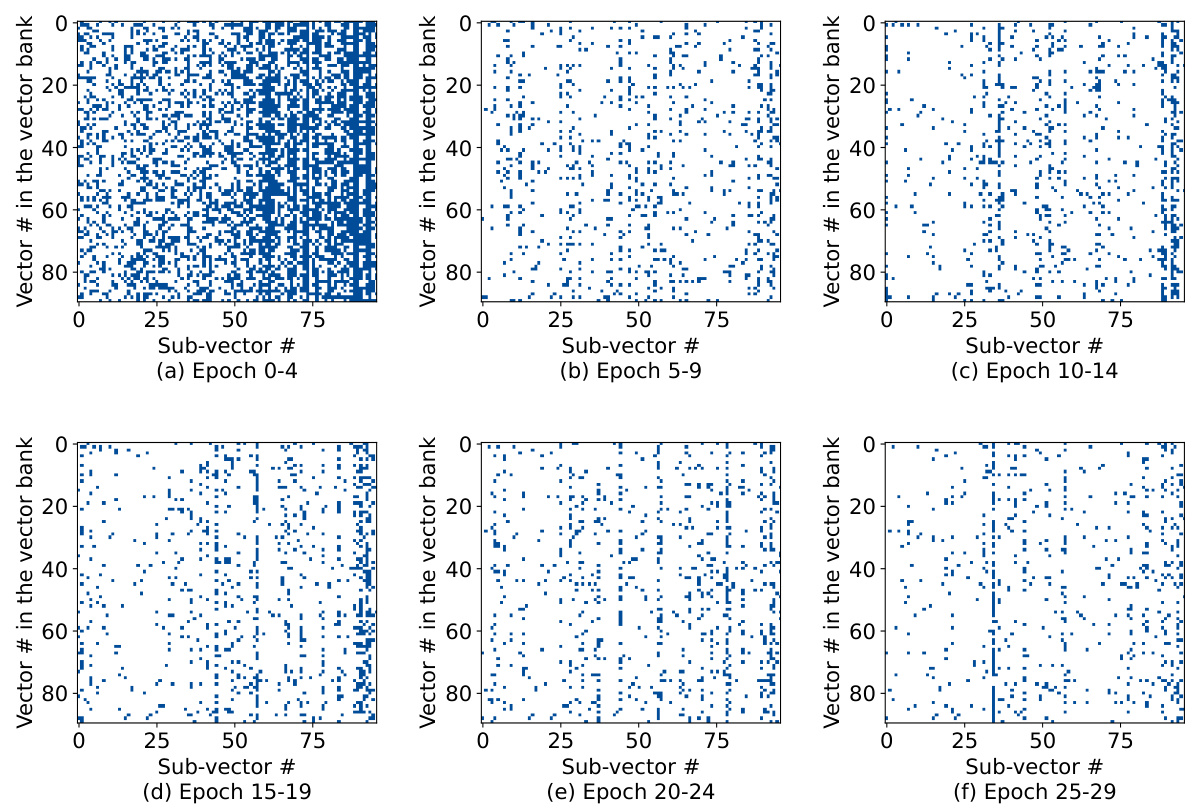
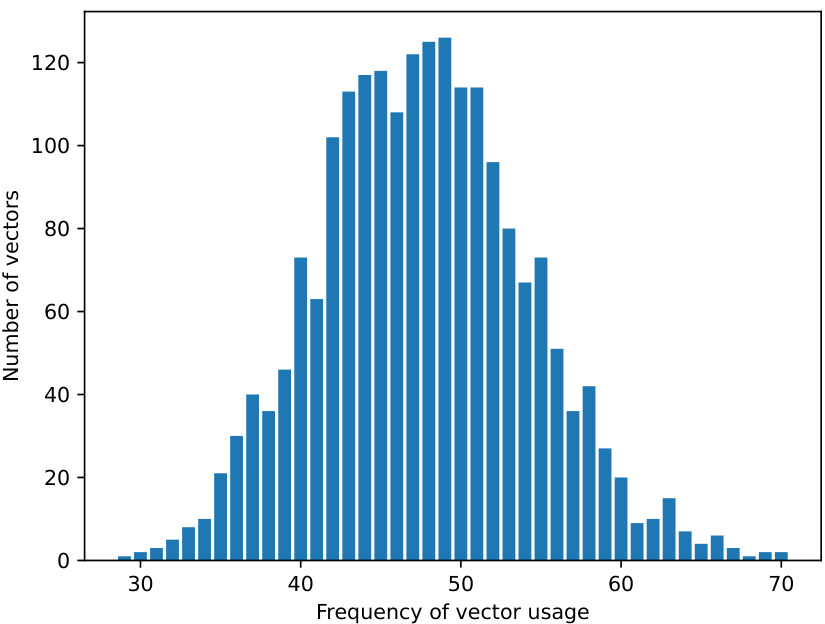
This figure visualizes the vectors selected by VB-LORA during training. The x-axis represents the 96 sub-vectors, and the y-axis shows the indices of the selected vectors from the vector bank. The blue blocks represent the selection footprint at different epochs. Each sub-vector selects a subset of vectors from the bank. The visualization helps understand how the vector selection dynamics change during training, showing the interplay between sub-vectors and the vector bank.
This figure compares the performance and the number of stored parameters of several parameter-efficient fine-tuning (PEFT) methods on the RoBERTa-Large model. The x-axis represents the number of stored parameters (log scale), and the y-axis represents Matthew’s correlation, a metric used to evaluate the performance of the model. The graph shows that VB-LORA outperforms other methods such as LoRA, Tied-LoRA, and VERA while using significantly fewer parameters, demonstrating its extreme parameter efficiency.
The figure illustrates the VB-LoRA architecture. The left panel shows how model parameters are composed of vectors from a shared vector bank across different layers, modules, and sub-vectors. The right panel details VB-LoRA’s architecture, showing how a top-k softmax function selects k vectors from the vector bank and combines them into a sub-vector that is then used to form the parameters of LoRA. This illustrates the ‘divide-and-share’ paradigm of VB-LoRA, where parameters are shared globally via the vector bank to improve parameter efficiency.
More on tables
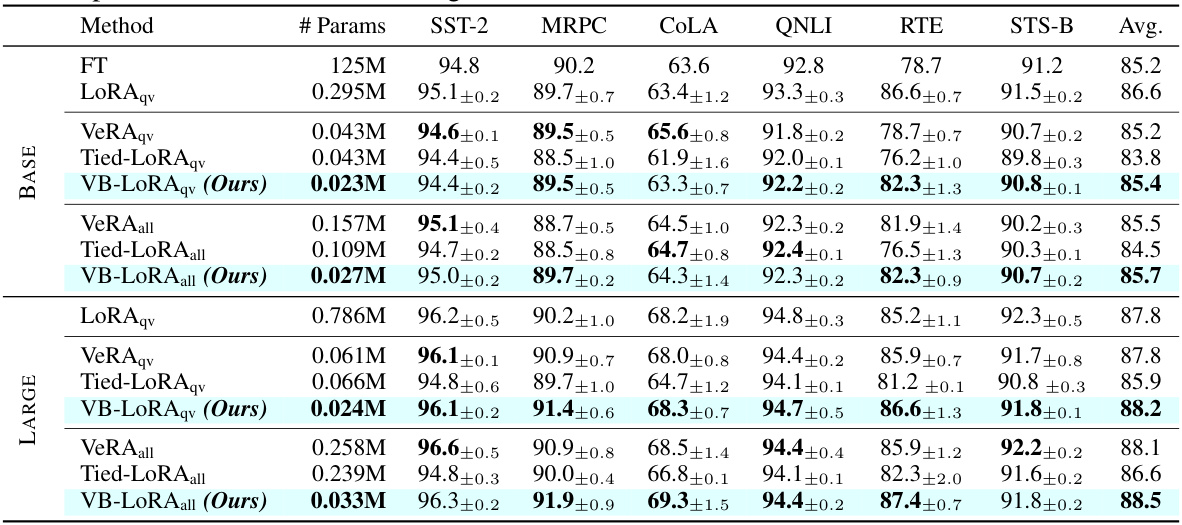
This table presents the results of experiments conducted on the GLUE benchmark using different parameter-efficient fine-tuning (PEFT) methods: Full Fine-Tuning (FT), LoRA, VeRA, Tied-LoRA, and VB-LoRA. Results are shown for both RoBERTa-base and RoBERTa-large models. The table shows performance on six GLUE tasks (SST-2, MRPC, CoLA, QNLI, RTE, and STS-B), reporting Matthew’s correlation for CoLA, Pearson correlation for STS-B, and accuracy for the other tasks. Results are the median of five runs, and the best result for each model size is highlighted in bold. The ‘# Params’ column indicates the number of trainable parameters for each PEFT method. Query and value only (qv) and all linear layers (all) variations are included for comparison.
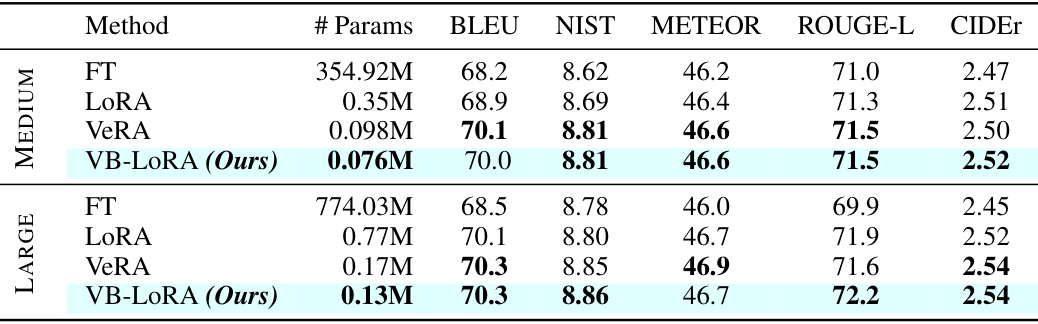
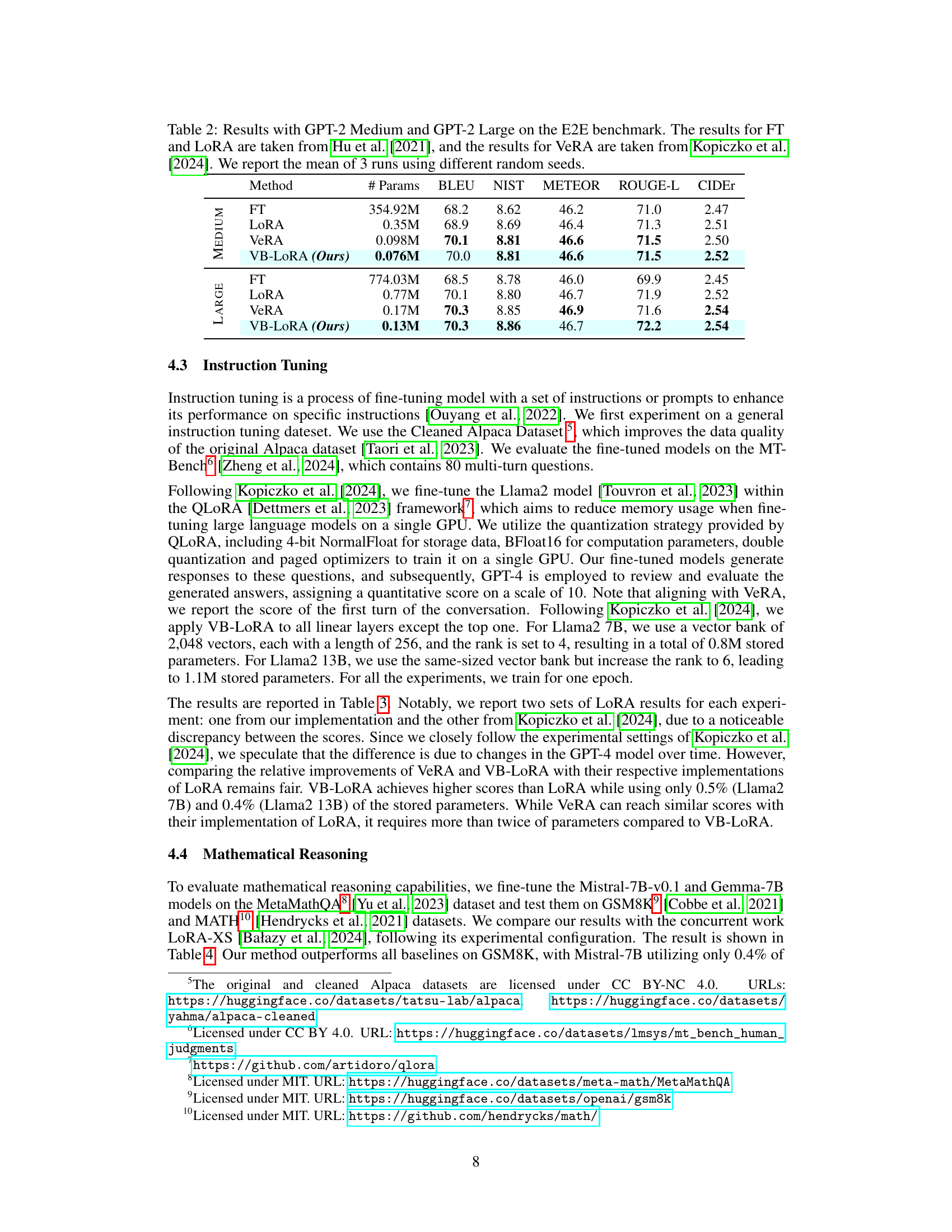
This table compares the performance of different parameter-efficient fine-tuning (PEFT) methods on the E2E dataset for natural language generation using the GPT-2 Medium and Large language models. It shows the number of parameters used by each method (Full Fine-tuning, LoRA, VeRA, and VB-LORA), along with their respective BLEU, NIST, METEOR, ROUGE-L, and CIDEr scores. The results highlight the parameter efficiency of VB-LORA compared to other methods while maintaining competitive performance.
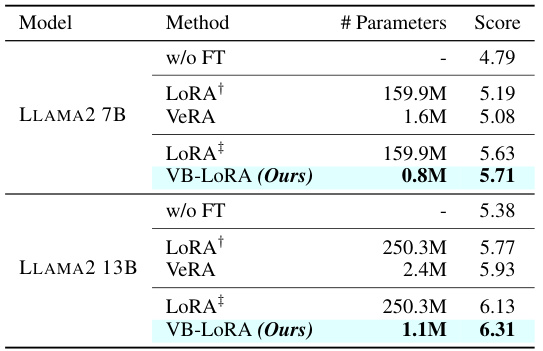
This table presents the results of instruction tuning experiments using the Llama2 model (7B and 13B parameters) on the MT-Bench dataset. The models were fine-tuned using different parameter-efficient fine-tuning (PEFT) methods: LoRA, VeRA, and the authors’ proposed VB-LoRA. The evaluation metric is a score out of 10, assigned by GPT-4. The table highlights the performance of VB-LoRA in achieving comparable or better results than other methods while using significantly fewer parameters. Note that slight discrepancies exist between the LoRA scores reported in this table and those reported by Kopiczko et al. [2024], likely due to variations in the GPT-4 model over time.
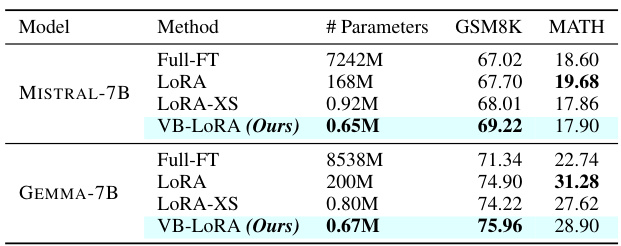
This table presents the results of experiments conducted on the GLUE benchmark using different parameter-efficient fine-tuning (PEFT) methods, including the proposed VB-LoRA. The table compares the performance of VB-LoRA against LoRA, VeRA, and Tied-LoRA on six tasks from the GLUE benchmark (SST-2, MRPC, CoLA, QNLI, RTE, and STS-B). Both RoBERTa-base and RoBERTa-large models were used, and the results are reported as the median across five runs with different random seeds, showing accuracy for most tasks, Matthews correlation for CoLA, and Pearson correlation for STS-B. Results for LoRAqv and VeRAqv were obtained from their original papers, while the others were reproduced by the authors using their own implementations.
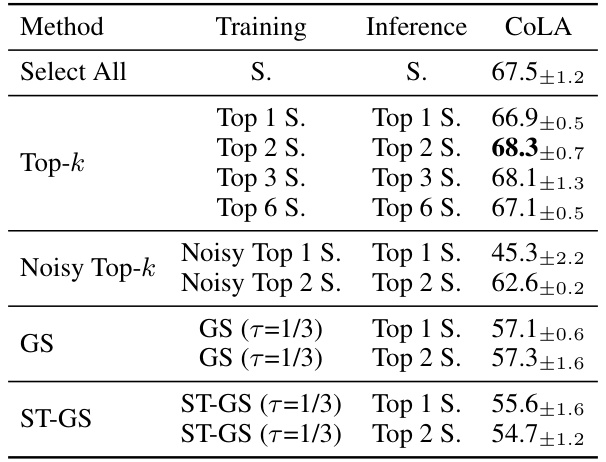
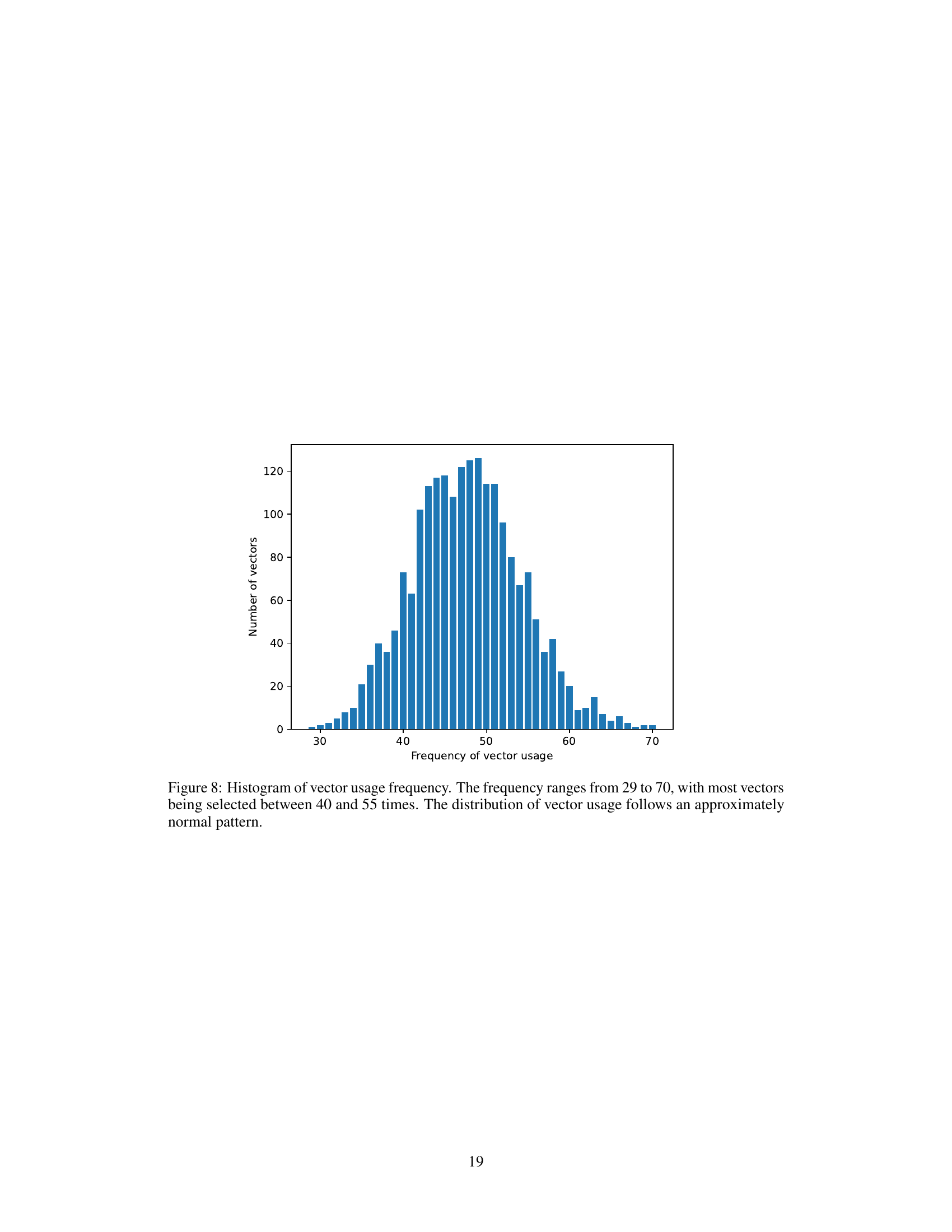
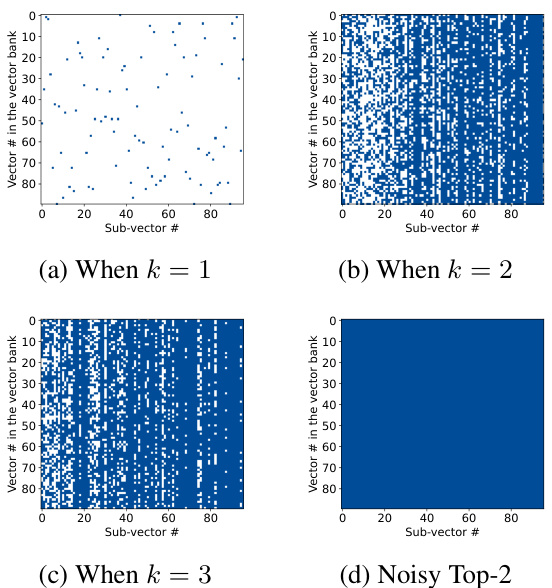
This ablation study compares the performance of different vector selection methods used in VB-LoRA on the CoLA dataset. It evaluates several approaches, including using all vectors, selecting the top k vectors using Softmax (Top-k), a noisy version of the top k selection, Gumbel-Softmax (GS), and Straight-Through Gumbel-Softmax (ST-GS). The results highlight the importance of a careful choice of vector selection method in achieving good performance.
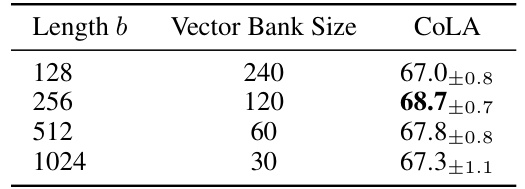
This table presents the results of experiments on the GLUE benchmark using different parameter-efficient fine-tuning (PEFT) methods: full fine-tuning (FT), LoRA, VeRA, Tied-LoRA, and the proposed VB-LoRA. The benchmark includes six tasks: CoLA, SST-2, MRPC, STS-B, QNLI, and RTE. Results are shown for both RoBERTa-base and RoBERTa-large models, with metrics varying across tasks (Matthew’s correlation, Pearson correlation, or accuracy). The number of parameters used by each method is also given, along with the median performance over five runs with different random seeds. The table highlights VB-LoRA’s competitive performance with significantly fewer parameters compared to existing methods.
This table presents the results of experiments comparing different parameter-efficient fine-tuning (PEFT) methods on the GLUE benchmark using RoBERTa-base and RoBERTa-large models. The methods compared are full fine-tuning (FT), LoRA, VERA, Tied-LoRA, and the proposed VB-LORA. The table shows the performance of each method on six different GLUE tasks (SST-2, MRPC, CoLA, QNLI, RTE, and STS-B), measured using metrics appropriate to each task (accuracy, Matthews correlation, Pearson correlation). The number of parameters used by each method is also provided. The results are averages over 5 runs, with the best results highlighted in bold.
This table presents a comparison of the performance of several parameter-efficient fine-tuning (PEFT) methods on the GLUE benchmark using two different sizes of RoBERTa models. It shows the median performance (across 5 runs with different random seeds) for each method on six tasks, including the number of trainable parameters used by each method. The results for LoRAqv and VeRAqv are taken from the original papers, while the rest were obtained via the authors’ implementations. The best results for each model size are highlighted in bold.
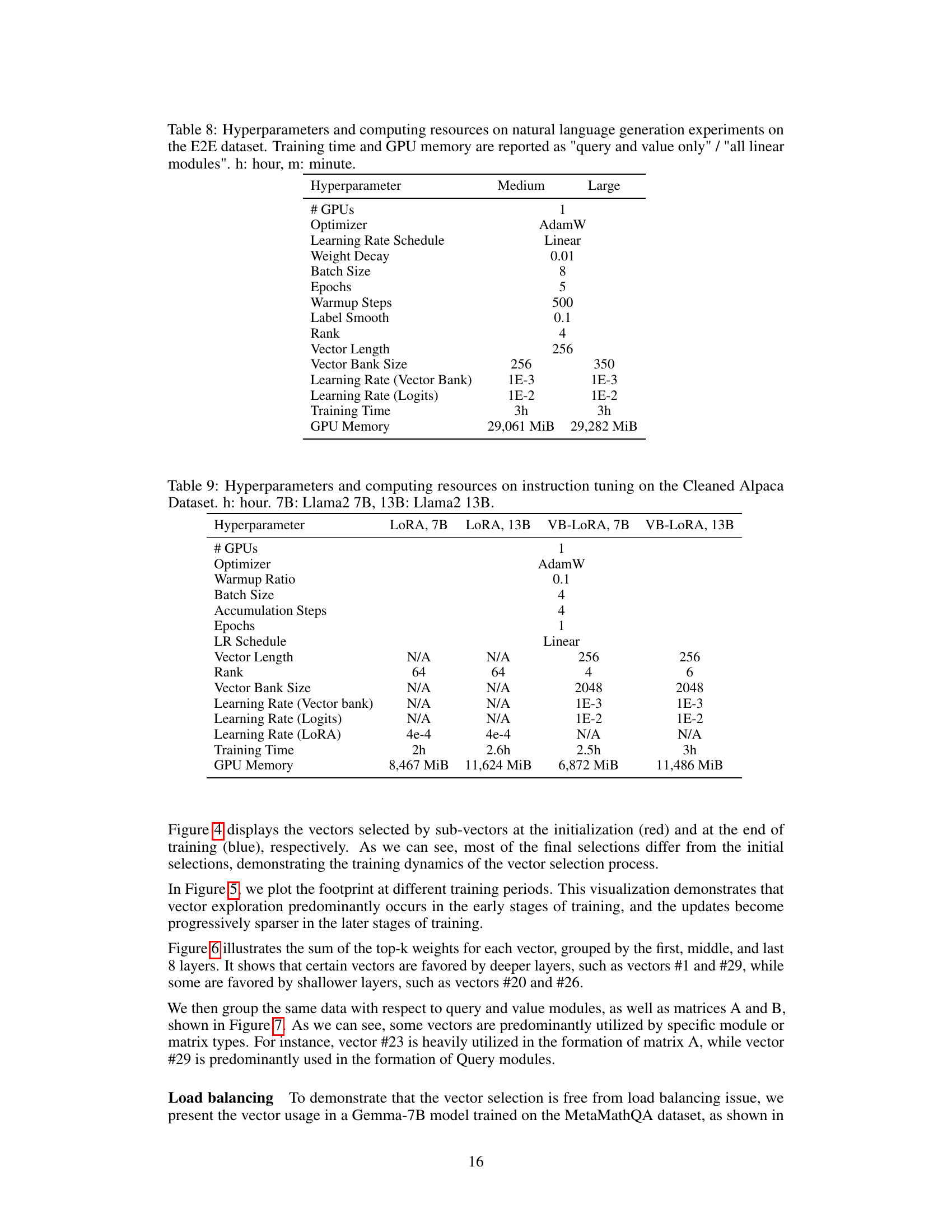
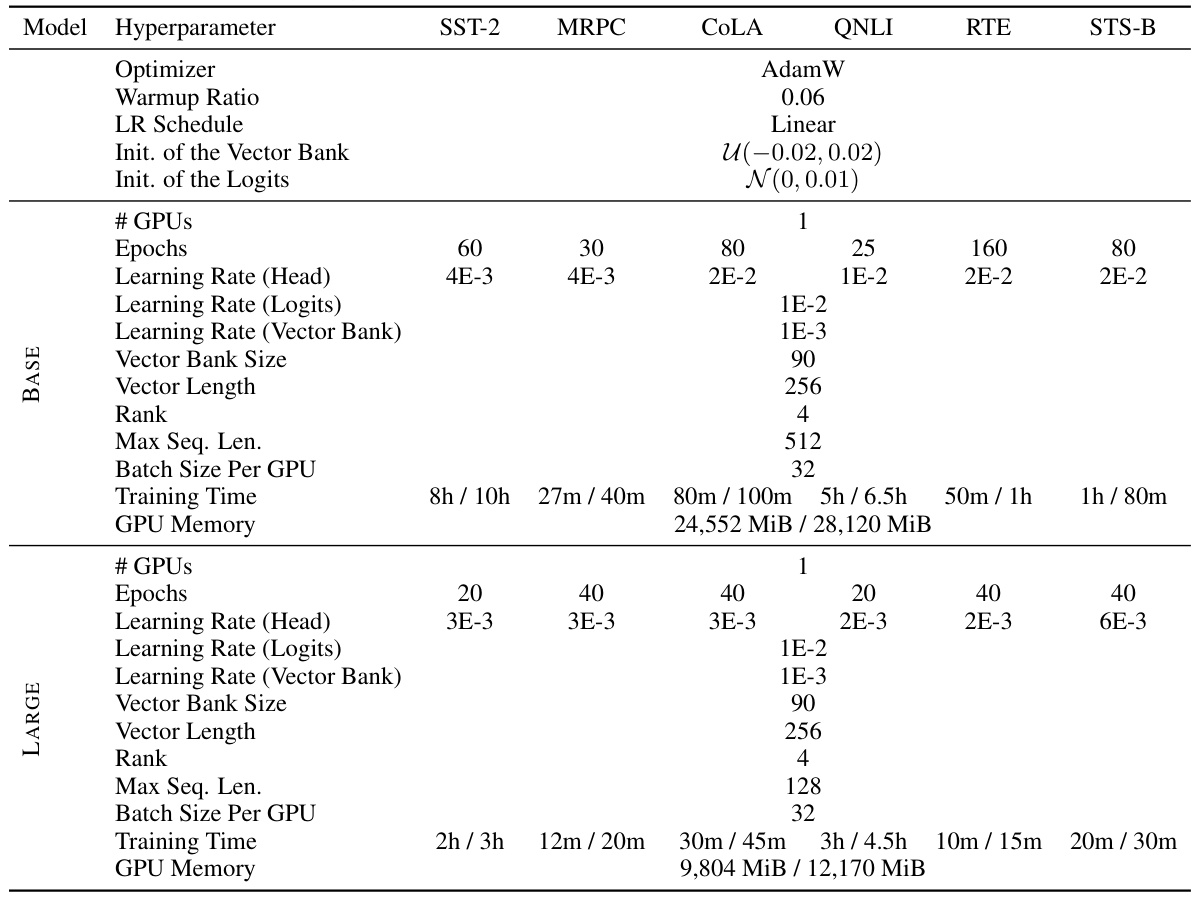
This table presents the hyperparameters and computational resources used in the natural language understanding experiments conducted on the GLUE benchmark. It details settings for both RoBERTa base and large models, comparing two fine-tuning strategies: fine-tuning only the query and value modules (VB-LoRAqv), and fine-tuning all linear modules (VB-LoRAall). The table includes optimizer, warmup ratio, learning rate schedule, vector bank initialization, and logit parameters’ initialization methods. It also shows the number of GPUs used, the number of epochs, batch sizes, maximum sequence length, training time, and GPU memory consumption for each configuration. Training time and GPU memory usage are reported separately for the two fine-tuning strategies, providing a comprehensive overview of the resources required for each experimental setup.

This table presents the results of the experiments conducted on the GLUE benchmark using RoBERTa Base and Large models. It compares the performance of VB-LoRA against other parameter-efficient fine-tuning (PEFT) methods (LoRA, VeRA, and Tied-LoRA) across six GLUE tasks: CoLA, SST-2, MRPC, STS-B, QNLI, and RTE. The table shows the number of parameters used by each method, and their performance (Matthew’s correlation for CoLA, Pearson correlation for STS-B, and accuracy for the rest). Results for LoRAqv and VeRAqy are taken from the original papers. VB-LoRA results are the median of 5 runs with different random seeds.

This table presents the results of experiments conducted on the GLUE benchmark using different parameter-efficient fine-tuning (PEFT) methods: full fine-tuning (FT), LoRA, VeRA, Tied-LoRA, and VB-LoRA. The experiments were performed on two different sized RoBERTa models: RoBERTa-base and RoBERTa-large. The table shows the performance of each method on six GLUE tasks: SST-2, MRPC, CoLA, QNLI, RTE, and STS-B. Performance is measured using accuracy (for most tasks), Matthew’s correlation (for CoLA), and Pearson correlation (for STS-B). The table also reports the number of parameters used by each method. The best results for each model size are shown in bold, and the results are averages of 5 runs with different random seeds.
Full paper#