↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current language model alignment methods primarily focus on pairwise preference data, limiting their ability to leverage fully annotated reward datasets. Existing methods like Direct Preference Optimization (DPO) are tailored for this pairwise data, and utilizing reward datasets often involves suboptimal pruning techniques, which leads to information loss and reduced performance. This creates a need for more versatile alignment techniques capable of effectively utilizing both data types.
This paper proposes InfoNCA and NCA, two novel algorithms that bridge this gap using Noise Contrastive Estimation (NCE). These algorithms directly optimize language models using explicitly annotated reward data and are also adaptable for pairwise preference data. InfoNCA is shown to be a generalization of the DPO loss, thus integrating and extending current alignment theories. NCA addresses the decreasing likelihood issue commonly seen in DPO/InfoNCA by optimizing absolute likelihoods rather than relative ones. Experiments with large language models demonstrate significant performance improvements over existing methods, particularly in complex tasks like math and coding, showcasing the efficacy of the proposed methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on language model alignment because it offers a novel framework that handles both explicit reward and preference data, addresses limitations of existing methods, and provides strong theoretical guarantees. It opens new avenues for research by integrating and extending current alignment theories and offering practical performance improvements in complex tasks.
Visual Insights#
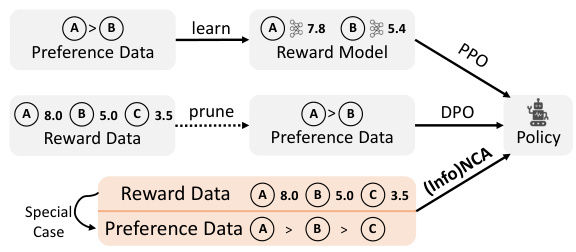
This figure illustrates the InfoNCA/NCA framework’s ability to directly optimize language models (LMs) using both reward and preference data. The top section shows the traditional approach of using preference data (pairwise comparisons) to train a reward model, which is then used with PPO or DPO to extract the LM policy. The middle section shows how reward datasets, where each response is explicitly annotated with a scalar reward, can be used with InfoNCA/NCA to achieve the same goal. The bottom section highlights that the DPO loss used in preference-based methods is a special case of the proposed InfoNCA objective. This allows InfoNCA/NCA to seamlessly handle both types of data.

This table compares the InfoNCA and NCA algorithms, focusing on their model definitions, target, loss functions for both reward and preference datasets, and the resulting optimal reward model. It highlights the differences in how they approach the likelihood ratios (relative vs. absolute) and the theoretical guarantees each offers. The table also provides a reference to the appendix for further details on the algorithms’ pseudocode.
In-depth insights#
Reward Alignment#
Reward alignment in language models (LMs) focuses on aligning the LM’s behavior with human intentions, typically expressed through rewards. Direct Preference Optimization (DPO) is a prominent method, but it relies on pairwise comparisons, limiting its use with scalar reward data. This paper introduces a novel framework using Noise Contrastive Estimation (NCE) to directly learn from explicitly annotated rewards. Two algorithms, NCA and InfoNCA, are proposed, allowing for optimization from both reward and preference datasets. InfoNCA extends DPO, demonstrating its loss function as a special case. A key finding highlights that NCA effectively mitigates the decreasing likelihood trend often seen in DPO/InfoNCA by optimizing absolute instead of relative likelihoods. This is particularly beneficial in complex tasks like math and coding. The work provides a unified approach, bridging theory and practice in LM alignment with both reward and preference data, showcasing improved performance compared to existing baselines.
NCA vs. DPO#
The comparison of Noise Contrastive Alignment (NCA) and Direct Preference Optimization (DPO) reveals crucial differences in their approach to language model alignment. DPO excels in pairwise preference settings, leveraging relative likelihoods to optimize model preferences. Conversely, NCA directly tackles reward datasets, optimizing absolute likelihoods for each response, making it suitable for richer reward data than DPO. NCA’s strength lies in preventing likelihood decay—a common issue in DPO—by focusing on absolute likelihood, resulting in improved performance on complex reasoning tasks. Although both share theoretical convergence guarantees, NCA’s practical advantages shine in scenarios with diverse, multi-response data and tasks demanding precise reasoning, whereas DPO remains a strong contender for scenarios with simpler preference data. The choice between the two depends heavily on the nature of the available data and the desired task complexity.
InfoNCA Framework#
The InfoNCA framework presents a novel approach to language model alignment by directly leveraging explicitly annotated scalar rewards, unlike previous methods primarily designed for implicit pairwise preferences. InfoNCA elegantly bridges the gap between reward and preference-based alignment, demonstrating that the Direct Preference Optimization (DPO) loss is a special case within the InfoNCA framework. This unification of existing alignment theories is a significant contribution, providing a more generalized and flexible framework for LM alignment tasks. By directly extracting an LM policy from reward data, InfoNCA avoids the limitations of methods that rely on pairwise comparisons or suboptimal data pruning techniques, leading to more efficient and potentially more effective alignment. A key advantage of InfoNCA is its seamless integration with both reward and preference data, making it highly adaptable to diverse scenarios and datasets. The framework’s theoretical foundation in Information Noise Contrastive Estimation (InfoNCE) offers strong theoretical guarantees, which adds to its robustness and reliability.
Likelihood Trends#
Analysis of likelihood trends in language model alignment reveals crucial insights into model behavior and optimization strategies. A common observation is the decreasing likelihood of preferred responses during training with methods like Direct Preference Optimization (DPO). This phenomenon, also seen in InfoNCA, suggests a focus on relative likelihood adjustments rather than absolute likelihood optimization. In contrast, Noise Contrastive Alignment (NCA) directly addresses this issue by optimizing absolute likelihoods, preventing the decline and potentially improving performance, especially in complex reasoning tasks. Understanding these trends is vital for developing effective alignment techniques; NCA’s focus on absolute likelihoods offers a potential advantage over methods solely concentrating on relative comparisons, leading to more robust and reliable model optimization. Further investigation into the interplay between relative and absolute likelihoods is needed to fully understand the dynamics of language model alignment.
Future Directions#
Future directions for research in this area could explore more sophisticated reward models that better capture the nuances of human preferences, moving beyond simple scalar ratings. Addressing the limitations of current preference datasets is also crucial, as these datasets often lack diversity and generalizability. Investigating methods for efficiently scaling reward-based alignment to larger language models is key, as current methods can be computationally expensive. Finally, a deeper theoretical understanding of the relationship between alignment techniques and the underlying mechanisms of language models would provide a solid foundation for future advancements, enabling the development of more robust and effective alignment strategies.
More visual insights#
More on figures
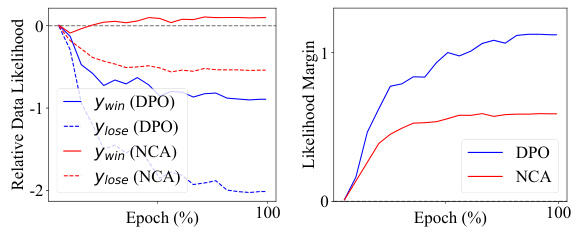
This figure compares the behavior of Direct Preference Optimization (DPO) and Noise Contrastive Alignment (NCA) in a pairwise setting. The left panel shows the relative data likelihood of winning and losing responses over training epochs. DPO exhibits a decreasing trend in the likelihood of the chosen response, while NCA maintains a relatively stable likelihood. The right panel highlights the difference in likelihood margins between the two methods. This demonstrates that NCA effectively prevents the likelihood of chosen responses from decreasing, unlike DPO.
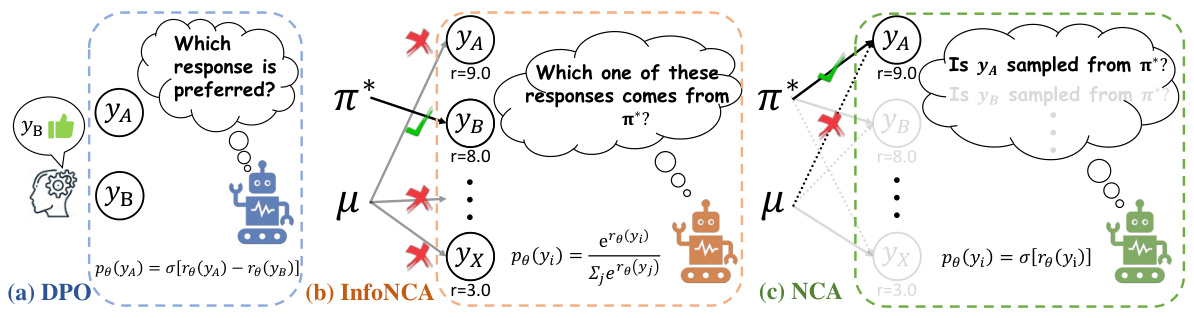
This figure illustrates the core difference between DPO, InfoNCA, and NCA in terms of their approach to optimizing language models. DPO uses a pairwise comparison, InfoNCA uses a multi-class classification approach to identify the optimal response from multiple candidates given their rewards, and NCA uses a binary classification to predict the model source of a single response given its reward.

This figure shows the impact of the number of suboptimal responses (K) on the performance of InfoNCA and NCA models on two different benchmarks: MT-bench and Alpaca. The left panel shows that increasing K leads to improved performance in both benchmarks. The right panel visualizes the trade-off between performance (MT-bench score) and KL divergence (KL(πθ||μ)) for various values of α and β, further confirming the positive impact of including more suboptimal responses during training.

This figure compares the changes in data likelihood during training for InfoNCA/DPO and NCA. The plots show the model reward for chosen responses (those preferred by human evaluators or given high rewards) and rejected responses over the training epochs (or steps). The key observation is that InfoNCA/DPO often shows a decrease in the likelihood of the chosen responses, whereas NCA maintains or increases this likelihood. This demonstrates NCA’s ability to prevent the likelihood of correct responses from decreasing during training, a problem observed with InfoNCA/DPO.
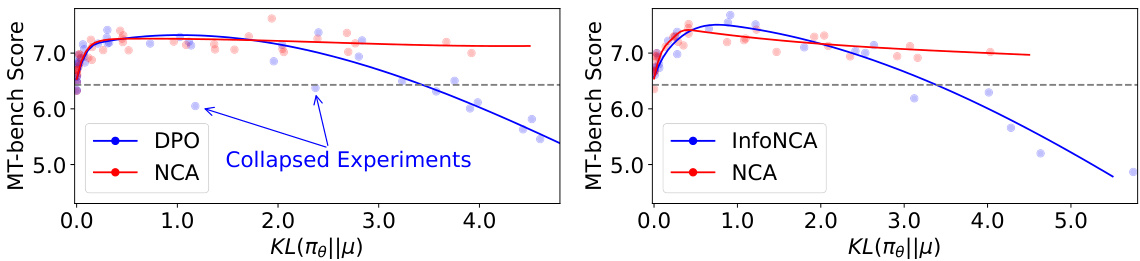
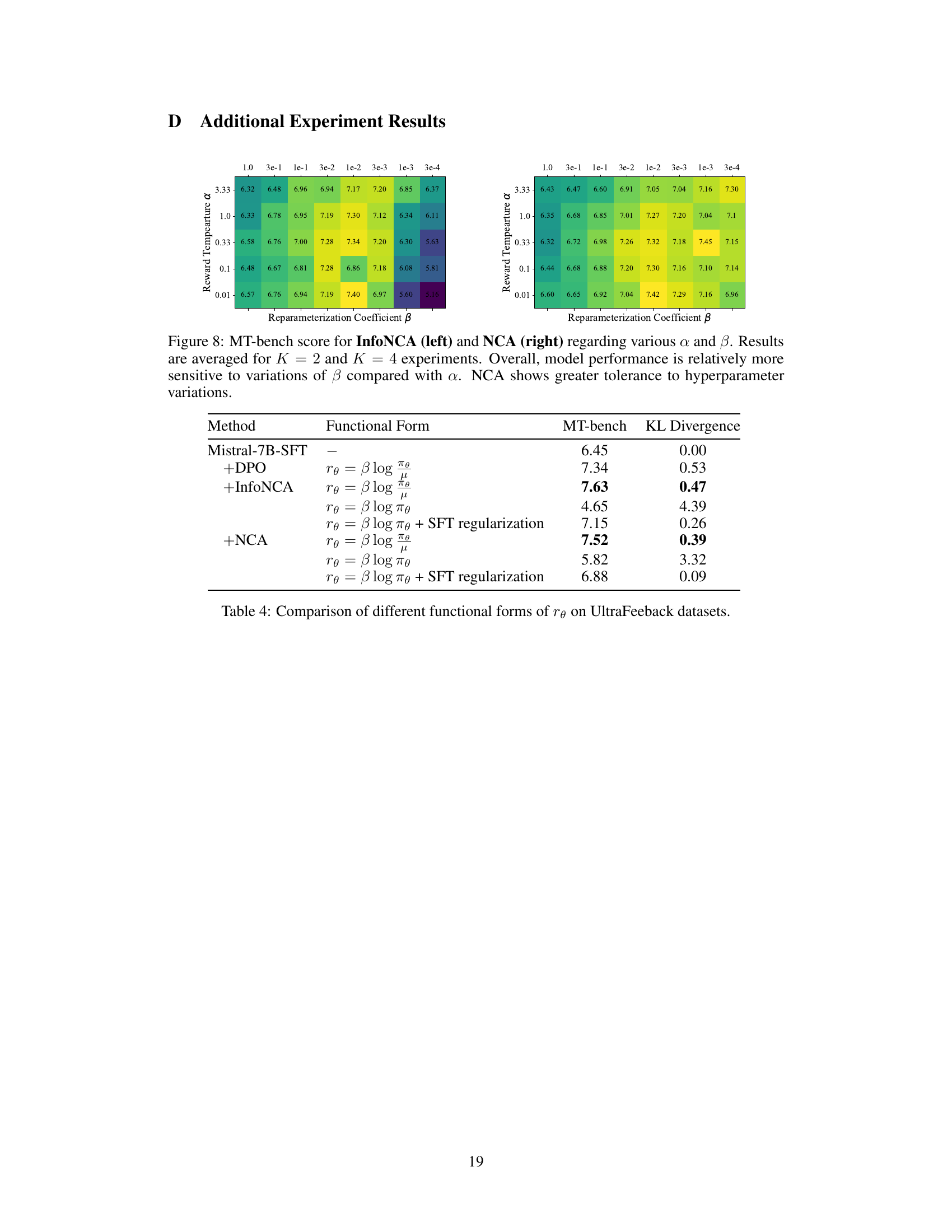
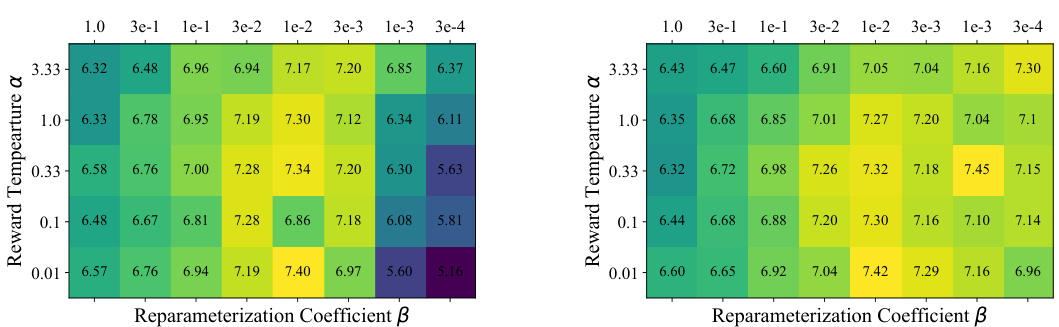
This figure shows the robustness of NCA compared to DPO and InfoNCA methods regarding hyperparameter sensitivity. The left panel displays the results of ablating α and β for a binarized version of the UltraFeedback dataset. The right panel shows the results for the full UltraFeedback reward dataset with K=4. The plots demonstrate that NCA’s performance is less affected by changes in α and β compared to DPO and InfoNCA. The x-axis represents the KL divergence between the learned policy (πθ) and the pretrained language model (μ), and the y-axis shows the MT-bench score.
The figure illustrates how InfoNCA and NCA, two novel algorithms introduced in the paper, enable direct language model (LM) optimization using both reward and preference data. It contrasts these methods with existing approaches like DPO and PPO, which primarily handle preference data. The diagram highlights that InfoNCA/NCA directly optimize the LM policy from the available rewards or pairwise preferences, unlike other methods which involve indirect approaches or limitations in handling reward data.
This figure illustrates the differences in how three different language model alignment methods (DPO, InfoNCA, and NCA) approach the problem. DPO uses a binary classification approach, comparing two responses to determine which is preferred. InfoNCA, on the other hand, handles multiple responses by attempting to identify the one response that comes from the optimal distribution. Finally, NCA uses a binary classification approach to determine whether a single response comes from the optimal or pretrained language model.
More on tables
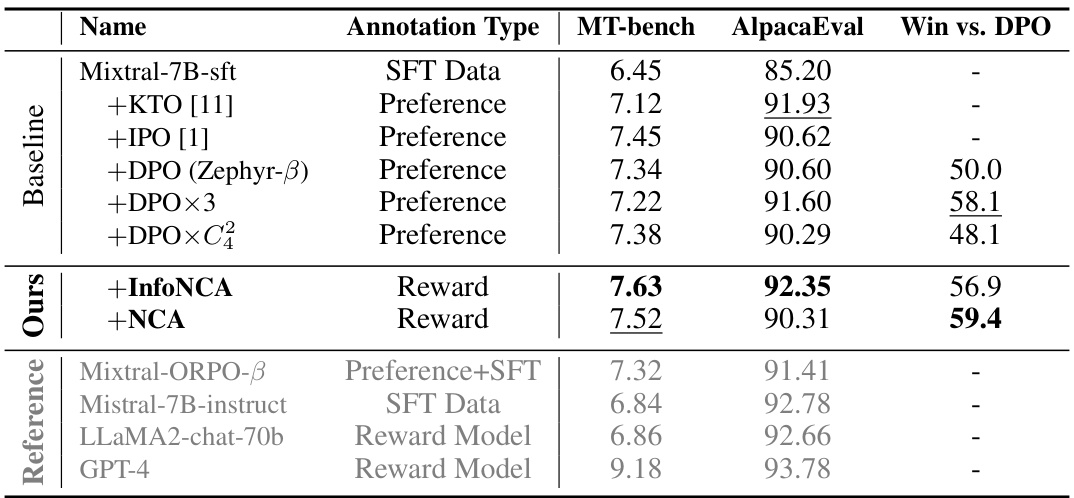
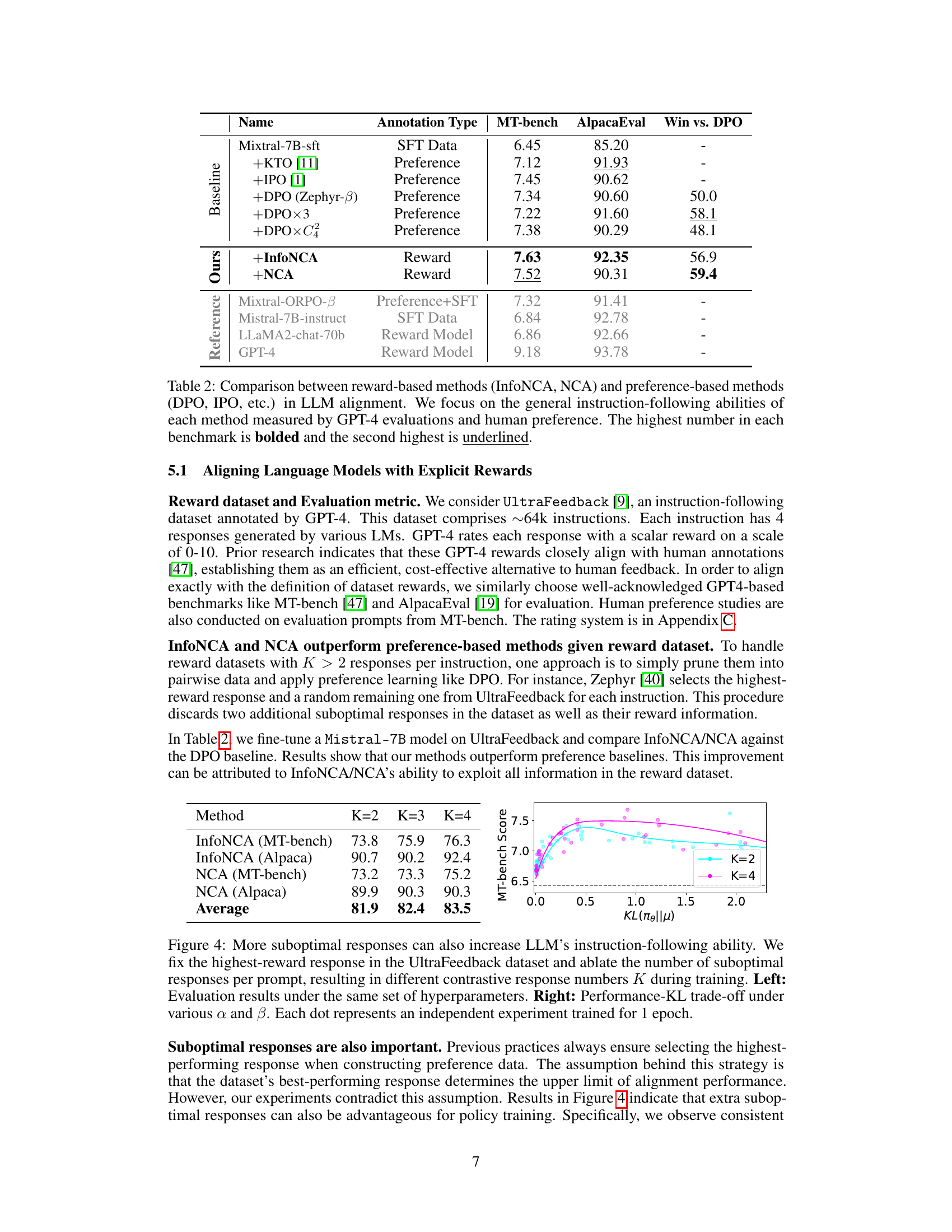
This table compares the performance of reward-based language model alignment methods (InfoNCA and NCA) against several preference-based methods (DPO, IPO, etc.). The comparison is based on two metrics: MT-bench and AlpacaEval, which assess general instruction-following ability. The ‘Win vs. DPO’ column shows the percentage of wins for each method against DPO. The highest score for each metric is bolded, and the second-highest is underlined. The results show that the reward-based methods generally outperform the preference-based ones.

This table presents the performance comparison of different language model alignment methods (DPO and NCA) on the UltraInteract benchmark. It shows the scores achieved by the Mistral-7B-SFT and Mistral-8x7B-SFT models before and after applying DPO and NCA algorithms. The benchmark includes various reasoning tasks (BBH (CoT)), coding tasks (LeetCode, HumanEval), and mathematical tasks (GSMPLUS, MATH, TheoremQA, SVAMP, ASDiv). The downward arrow (↓) indicates that the score has decreased after applying a specific algorithm. The table highlights the impact of NCA on reasoning performance.

This table compares the InfoNCA and NCA algorithms for aligning language models. It details the model definition, reward and preference datasets used, the loss functions (for both K>1 and the special case of K=2 which reduces to DPO), the loss type, the target of optimization, and the optimal solution for rθ*. The pseudocode for both algorithms is available in Appendix B.
This table compares the performance of reward-based language model alignment methods (InfoNCA, NCA) against preference-based methods (DPO, IPO, etc.) on general instruction-following tasks. The evaluation metrics used are GPT-4 scores and human preference ratings. The highest score in each benchmark is highlighted in bold, with the second-highest underlined. This allows for a clear comparison of the relative effectiveness of each method in aligning language models with human intent.

This table compares different language model alignment methods using the MT-bench and AlpacaEval benchmarks. It shows the performance of reward-based methods (InfoNCA and NCA) against preference-based methods (DPO, IPO, etc.) when aligning language models with explicit rewards and preference data. The best and second-best performing methods are highlighted for each benchmark.
This table compares the InfoNCA and NCA algorithms for aligning language models. It shows how both algorithms handle reward datasets (x → {Yi, ri}1:K) and preference datasets (x → {Yw > yı}). The table details the model definitions, loss functions (for both reward and preference data), loss types, optimization targets, and optimal solutions for both algorithms. It highlights the key differences between the two approaches and how they relate to the DPO algorithm. Pseudocode for both algorithms is provided in Appendix B.

This table compares two algorithms, InfoNCA and NCA, used for aligning language models. It shows how they differ in their model definitions, the type of datasets they handle (reward and preference), the loss functions they employ, and their optimization targets. It highlights that InfoNCA subsumes DPO as a special case and notes that pseudocode for both algorithms is available in Appendix B.
Full paper#