↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Traditional text line recognition often struggles with handwritten text and complex scripts, relying on methods that are computationally expensive and difficult to interpret. This is because character-level annotation is expensive, and accurately reading characters separately in some handwriting styles and scripts is extremely difficult. This paper tackles the issues by proposing a new generalizable detection-based approach called DTLR.
DTLR utilizes a transformer-based model. It uses a clever three-pronged approach: (1) it leverages synthetic data for pre-training to learn reasonable character localization for any script; (2) it uses modern transformer-based detectors that can detect many instances at once; and (3) it leverages line-level annotations for fine-tuning even with different alphabets. The results show that DTLR significantly improves the state-of-the-art performance in Chinese script and cipher recognition, demonstrating its effectiveness and generalizability across various text types.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel, generalizable approach to text line recognition that significantly improves performance on various scripts, including challenging ones like Chinese and ciphers. This advances the state-of-the-art, offering a new paradigm that’s more interpretable and computationally efficient. It also opens avenues for further research into more robust and generalizable text recognition models.
Visual Insights#

🔼 This figure demonstrates the model’s ability to handle diverse datasets, including challenging handwritten text, Chinese characters, and ciphers. It showcases the generalizability of the proposed approach across different scripts and writing styles.
read the caption
Figure 1: Our model is general and can be used on diverse datasets, including challenging handwritten script, Chinese script and ciphers. From left to right and top to bottom we show results on Google1000 [46], IAM [29], READ [44], RIMES [39], CASIA [27], Cipher [41] datasets.
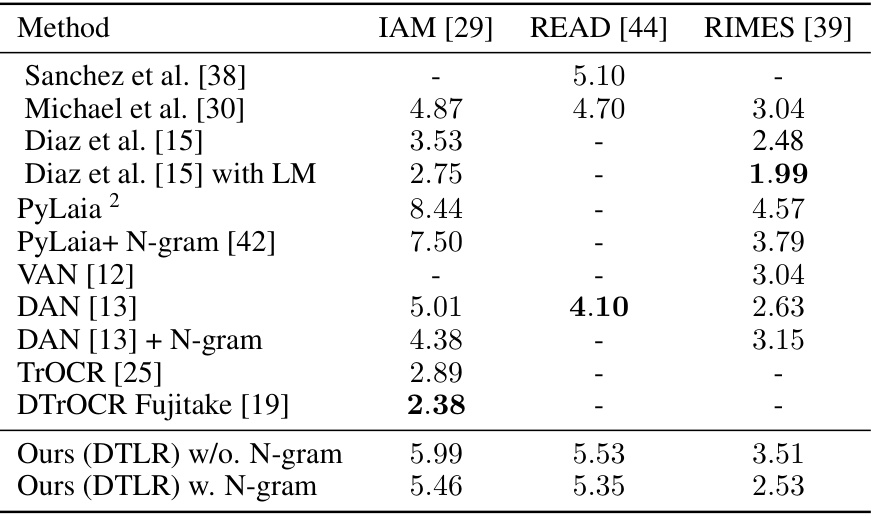
🔼 This table presents a comparison of the Character Error Rate (CER) achieved by various methods on three standard Handwritten Text Recognition (HTR) datasets: IAM, READ, and RIMES. The CER represents the percentage of incorrectly recognized characters. Lower CER values indicate better performance. The table shows the performance of different state-of-the-art methods and the proposed DTLR method (with and without an N-gram language model).
read the caption
Table 1: Character Error Rate (CER, in %) on standard HTR datasets.
In-depth insights#
Detection-based HTR#
Detection-based handwritten text recognition (HTR) presents a compelling alternative to traditional sequence-to-sequence models. By framing HTR as a detection problem, the method directly addresses character localization, eliminating the need for implicit segmentation, which is often a major bottleneck in traditional approaches. This is particularly advantageous for complex scripts like Chinese or those with varied handwriting styles. The use of transformer-based detectors allows for parallel processing of characters, potentially leading to faster inference times and improved efficiency. Synthetic data pre-training is key to achieving robustness and generalization across different scripts, mitigating the need for extensive annotated real-world data which is expensive to obtain and often scarce. Fine-tuning with line-level annotations on real data further refines the model, adapting it to specific characteristics of the target script. While the detection-based method may introduce challenges in handling character ordering, sophisticated techniques such as sorting by x-coordinate can largely overcome this limitation. Overall, this paradigm shift offers a promising avenue for advancing HTR by providing greater interpretability and efficiency, particularly for previously difficult-to-handle scripts.
Synthetic Pretraining#
The use of synthetic pretraining in this research is a crucial innovation, addressing the limitations of traditional handwritten text recognition (HTR) approaches. By generating a large and diverse dataset of synthetic images with character-level annotations, the model can learn robust feature representations and character localization, overcoming challenges posed by the scarcity and cost of real-world, manually annotated HTR data. This strategy allows for generalization across various scripts and styles, making the approach more versatile and less reliant on script-specific datasets. The synthetic data generation pipeline, which includes features like font variation, background noise, and masking, is carefully designed to create challenging yet realistic scenarios, improving model robustness. Fine-tuning on real data further refines the model’s performance, leveraging both synthetic and real-world information for optimal accuracy and generalizability. This clever combination of synthetic and real data effectively bypasses the limitations of traditional HTR datasets and enables the development of a robust, generalizable text line recognition system.
Line-Level Finetuning#
The heading ‘Line-Level Finetuning’ suggests a crucial stage in the model’s training process. This approach likely involves fine-tuning a pre-trained character detection model using only line-level annotations. This is significant because it bypasses the need for expensive and laborious character-level annotation, a common bottleneck in handwriting recognition. The strategy is especially effective when dealing with diverse scripts or languages where character-level datasets might be scarce or non-existent. By training on line-level data, the model learns to capture contextual relationships between characters within a line, improving its ability to handle the ambiguities and variations inherent in handwriting. The success of this method hinges on the effectiveness of the initial pre-training, which should provide a robust foundation for the character localization task. The effectiveness of this fine-tuning is validated by demonstrating improved performance across a variety of scripts, overcoming script-specific challenges. Overall, line-level finetuning represents a powerful and efficient way to adapt a generic character detection model to diverse and challenging handwriting recognition tasks.
Cipher Recognition#
Cipher recognition, a challenging subfield of text recognition, focuses on deciphering encrypted texts. The paper’s approach uses a detection-based model, a departure from traditional methods reliant on sequential decoding. This allows for parallel processing of characters, offering potential computational advantages. The success hinges on a synthetic pre-training strategy, exposing the model to diverse character styles and layouts before fine-tuning on real cipher datasets. This pre-training step is crucial for generalization, particularly important due to the limited availability of annotated cipher data. The results show promising improvements in cipher recognition accuracy, specifically on the Borg and Copiale datasets, highlighting the effectiveness of the detection-based method’s ability to tackle the challenges of varied character sets and noise present in historical documents. The study emphasizes the generalizability of the model across different alphabets, opening exciting possibilities for future research in this historically significant yet computationally complex area.
Future of DTLR#
The future of Detection-based Text Line Recognition (DTLR) looks promising, building on its demonstrated success in handling diverse scripts and challenging datasets. Further improvements in character localization are key; exploring more sophisticated attention mechanisms or incorporating advanced geometric reasoning could enhance robustness, particularly for densely packed or poorly written text. Integrating language models more effectively is crucial. While N-grams show benefit, leveraging more powerful contextual models could drastically reduce error rates, especially in languages with complex grammar or ambiguous characters. Exploring different training strategies beyond synthetic data, such as semi-supervised or weakly supervised methods, could expand applicability and reduce annotation costs. The inherent parallelism of DTLR offers scalability benefits; adapting it for processing high-resolution images or very long documents efficiently would be a significant advancement. Finally, exploring applications beyond traditional OCR and HTR such as analyzing historical documents, deciphering ciphers, or processing complex scene text scenarios, would greatly expand DTLR’s impact.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of the proposed DTLR model, which is based on the DINO-DETR architecture. It shows the process of how CNN-extracted image features are processed through a transformer encoder to produce initial anchors and tokens. These are then fed into a transformer decoder, which uses multi-scale deformable self-attention and self-attention mechanisms to predict character bounding boxes and class probabilities for each character, including whitespace.
read the caption
Figure 2: Architecture. Our architecture is based on DINO-DETR [57]. Given as input CNN image features, a transformer encoder predicts initial anchors and tokens, that are used by a transformer decoder to predict, for each token, a character bounding box and a probability for each character in the alphabet, including white space.

🔼 This figure shows the results of the proposed model on six different datasets, demonstrating its versatility across various text types and languages. The datasets include handwritten Latin scripts (Google1000, IAM, READ, RIMES), handwritten Chinese (CASIA), and ciphered text (Cipher). The results visually demonstrate the model’s ability to handle diverse writing styles and complexities.
read the caption
Figure 1: Our model is general and can be used on diverse datasets, including challenging handwritten script, Chinese script and ciphers. From left to right and top to bottom we show results on Google1000 [46], IAM [29], READ [44], RIMES [39], CASIA [27], Cipher [41] datasets.

🔼 This figure shows examples of synthetic data used for pre-training the model. The left column displays samples generated without any masking, while the right column shows samples with various masking techniques applied. The masking techniques include random erasing, masking complete vertical blocks, and masking small horizontal blocks. This data augmentation strategy aims to improve model robustness and learn an implicit language model.
read the caption
Figure 5: Samples from our synthetic datasets without (left) and with masking (right).

🔼 This figure shows samples of synthetic datasets generated for pre-training the model. The left column displays samples without masking, while the right column shows the same samples with masking applied. Masking, a data augmentation technique, involves randomly erasing portions of the image to make the model more robust to variations in the input data, such as noise or partial occlusions. The figure highlights the difference in image appearance and demonstrates the effectiveness of the masking strategy.
read the caption
Figure 3: Samples from our synthetic datasets without (left) and with masking (right).

🔼 This figure shows examples of synthetic data used for pre-training the model. The left column displays samples generated without any masking, while the right column shows samples with various masking techniques applied (vertical and horizontal blocks). This masking serves as data augmentation and helps make the model more robust to variations and missing parts of characters in real-world data.
read the caption
Figure 3: Samples from our synthetic datasets without (left) and with masking (right).

🔼 This figure shows examples of synthetic data generated for training the model. The left column shows samples without masking, while the right column shows the same samples with different masking applied. The masking helps improve model robustness by forcing it to learn to recognize characters even when parts of them are hidden or obscured. This is crucial because real-world handwritten text often has occlusions or poor writing quality.
read the caption
Figure 3: Samples from our synthetic datasets without (left) and with masking (right).
More on tables

🔼 This table compares the performance of different methods for Chinese handwritten text recognition (HTR) on the CASIA dataset. The performance is measured using two metrics: Accurate Rate (AR) and Correct Rate (CR). The table shows the training data used by each method and the resulting AR and CR values. The ‘Ours (DTLR)’ row highlights the performance of the proposed method in the paper.
read the caption
Table 2: Accurate Rate (AR) and Correct Rate (CR) [56] for Chinese HTR on CASIA [27].
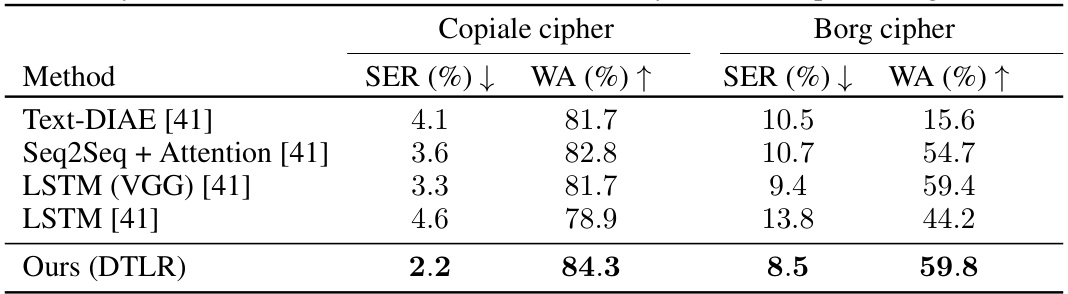
🔼 This table presents the performance comparison of different methods on two cipher recognition datasets: Copiale and Borg. The metrics used are Symbol Error Rate (SER), indicating the percentage of incorrectly recognized symbols, and Word Accuracy (WA), showing the percentage of correctly recognized words. Lower SER and higher WA values signify better performance. The table showcases the proposed DTLR method’s superior performance compared to existing methods, particularly in reducing the symbol error rate while improving word accuracy on both datasets.
read the caption
Table 3: Symbol Error Rates (SER) and Word Accuracy (WA) for cipher recognition [41]

🔼 This table presents the results of ablation studies conducted on two datasets, IAM and Borg, to evaluate the impact of different factors on the model’s performance. Specifically, it compares the Character Error Rate (CER) on the IAM dataset and the Symbol Error Rate (SER) on the Borg dataset across several model variations. These variations include using a general model versus an English-trained model, with and without random erasing during training, and different finetuning strategies (optimizing only class embedding versus end-to-end finetuning), again with and without random erasing.
read the caption
Table 4: Ablation studies on the IAM and Borg dataset

🔼 This table presents the Symbol Error Rates (SER) achieved by different methods in the ICDAR 2024 Competition on Handwriting Recognition of Historical Ciphers. The methods compared include several approaches from previous research and the proposed DTLR method. The SER is reported for five different ciphers: Digits, Borg, Copiale, BNF, and Ramanacoil. Lower SER values indicate better performance.
read the caption
Table 5: Symbol Error Rate (SER, in %) on ICDAR 2024 Competition on Handwriting Recognition of Historical Ciphers.
Full paper#
















