↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Reinforcement Learning from Human Feedback (RLHF) is key for aligning large language models (LLMs) with human values but suffers from reward overoptimization. This happens because the reward model, used as a proxy for human feedback, is imperfect, leading to LLMs exploiting flaws in the reward model instead of truly aligning with human values. Existing solutions often involve training multiple reward models which is computationally expensive.
This paper introduces ADVPO, which uses a lightweight uncertainty quantification method to estimate the reliability of the reward model using only its last-layer embeddings. This efficient method is incorporated into ADVPO, a novel distributionally robust optimization procedure that mitigates overoptimization. Experiments showed that ADVPO significantly improves the performance of LLMs in aligning with human values compared to existing methods on the Anthropic HH and TL;DR summarization datasets. The method is more efficient than existing solutions and has theoretical backing.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in RLHF due to its novel lightweight uncertainty estimation method and the ADVPO algorithm. It directly tackles the overoptimization problem, a significant hurdle in aligning LLMs with human values. The efficiency and generalizability of the proposed method make it highly relevant to current research, potentially impacting future advancements in RLHF and similar alignment techniques. Furthermore, the theoretical analysis and empirical validation significantly enhance the reliability and applicability of the proposed solutions.
Visual Insights#
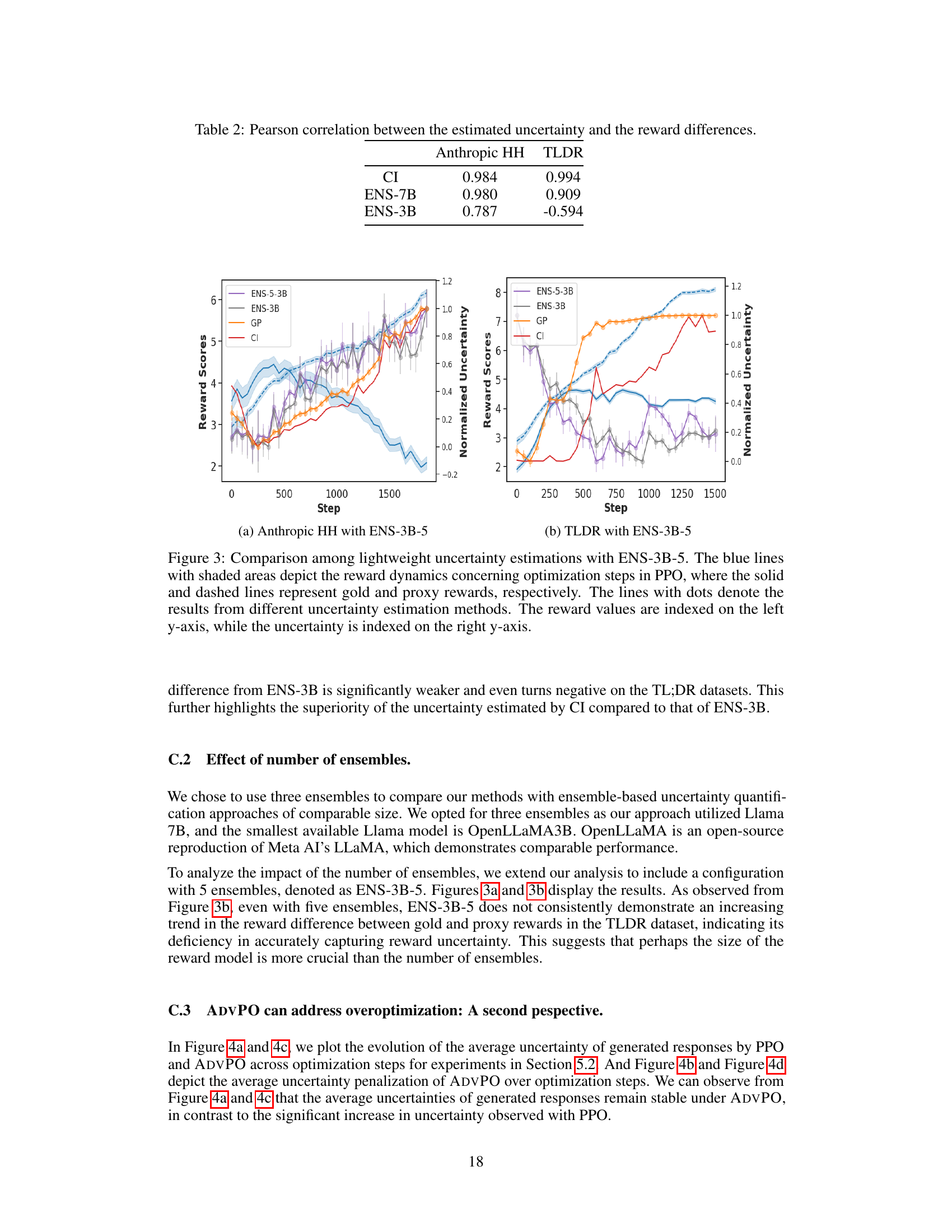
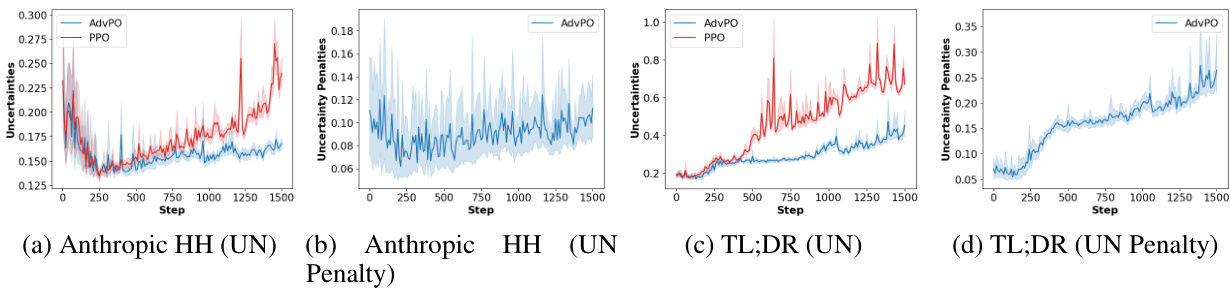
This figure compares different methods for estimating reward uncertainty during reinforcement learning from human feedback (RLHF). The left-hand side plots (a and c) show the reward dynamics over training steps for the Anthropic HH and TL;DR datasets, comparing the gold-standard reward (human judgments) with proxy reward estimates from different methods (including the proposed lightweight method ‘CI’). The right-hand side plots (b and d) show the correlation between the estimated uncertainty and the difference between the gold-standard and proxy rewards for each method.

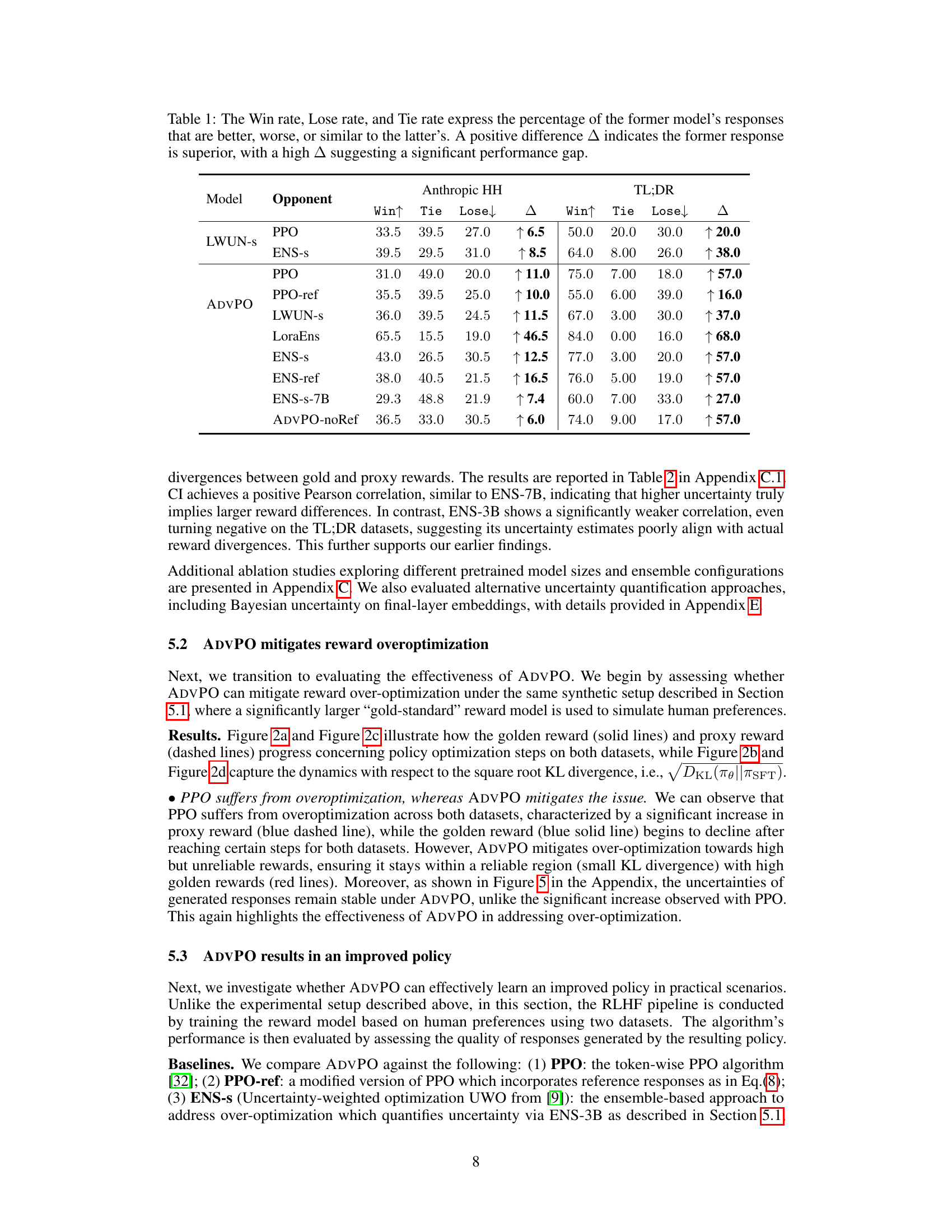
This table presents the results of human evaluation comparing different RLHF methods. For each method, it shows the win rate (percentage of times the method’s response was better than the opponent’s), lose rate (percentage of times it was worse), and tie rate (percentage of times they were equally good). The Δ column represents the difference between the win rate and lose rate, indicating the overall superiority of one method over another. A larger positive Δ indicates a more significant performance advantage.
In-depth insights#
Lightweight RLHF#
Lightweight RLHF methods aim to reduce the computational and memory costs associated with traditional RLHF, which often involves large language models and extensive training. This is achieved through techniques like efficient uncertainty quantification using only a subset of reward model parameters, such as last-layer embeddings, avoiding the need for large ensembles. Adversarial training methods can also make the training process more robust while reducing the overall computational burden. These approaches strive for improved efficiency without significant performance sacrifices, making RLHF more accessible for researchers with limited resources and enabling scaling to larger models and datasets. Focusing on robustness rather than simply minimizing uncertainty during policy optimization is key. The success of lightweight RLHF depends on the effectiveness of its uncertainty quantification methods and the ability of its optimization procedures to handle the reduced information. A critical challenge lies in balancing efficiency with the accuracy and reliability of the reward model, which is crucial for aligning language models effectively with human values.
ADVPO Algorithm#
The ADVPO algorithm, proposed to mitigate reward overoptimization in RLHF, is a distributionally robust optimization method. Unlike previous approaches that penalize individual samples based on their uncertainty, ADVPO adopts a more holistic strategy by considering the entire uncertainty region around the estimated reward. This approach is less pessimistic, leading to more effective policy improvement. ADVPO cleverly leverages a lightweight uncertainty quantification method that relies only on last-layer embeddings of the reward model, making it efficient and broadly applicable. The algorithm incorporates reference responses to prevent excessive pessimism, thereby enhancing policy performance in real-world scenarios. By contrasting with sample-wise uncertainty penalization, ADVPO demonstrates superior performance and improved policy quality. Its core innovation lies in its adversarial approach, optimizing against the worst-case scenarios within the uncertainty region, instead of simply penalizing high-uncertainty samples. This robust strategy makes it particularly effective in handling the complexities and noise inherent in human feedback.
Uncertainty Estimation#
The concept of ‘Uncertainty Estimation’ is crucial for evaluating the reliability of a model’s predictions, especially in complex scenarios. Lightweight methods are particularly valuable as they reduce computational costs and improve efficiency without sacrificing accuracy. Quantifying uncertainty in a reward model is key for RLHF, as it allows for the identification of unreliable rewards which can lead to over-optimization. The choice of uncertainty quantification method (e.g., ensemble methods, last-layer embeddings) greatly impacts the accuracy and computational efficiency of the process. Therefore, selecting an appropriate method is crucial, balancing model accuracy against computational resource constraints. Theoretical guarantees are also desirable to ensure that the chosen uncertainty estimation method is not overly optimistic or pessimistic. Ultimately, a robust uncertainty estimation technique is vital for ensuring reliable and trustworthy model behavior in the real world.
Overoptimization Issue#
The overoptimization issue in reinforcement learning from human feedback (RLHF) arises from the inherent limitations of using a proxy reward model to approximate human preferences. The proxy model, trained on a finite dataset, may not perfectly capture the nuances of human judgment, leading to the model exploiting loopholes and gaming the reward system. This results in the model achieving high proxy rewards but potentially performing poorly according to true human preferences. Overoptimization manifests as the model focusing on maximizing the proxy reward, even if this behavior deviates significantly from what humans would consider desirable or optimal. This issue highlights the critical need for robust reward modeling and methods to quantify and mitigate reward uncertainty, like those proposed in the paper, which involve techniques like ensemble methods and uncertainty estimation to guide the policy optimization process towards more aligned and human-centric outcomes. Addressing the overoptimization issue is paramount to ensure the reliability and ethical alignment of RLHF-trained models. Without effective mitigation strategies, the resulting models may exhibit unexpected and potentially undesirable behavior, undermining the benefits of RLHF.
Future Research#
Future research directions stemming from this work on mitigating reward overoptimization in RLHF could explore several promising avenues. Extending uncertainty quantification beyond the last layer of the reward model to incorporate information from deeper layers may yield more robust uncertainty estimates. Investigating the use of uncertainty not just for model training, but also for active data selection in RLHF, could significantly improve efficiency and data usage. Furthermore, scaling experiments to much larger language models (e.g., 70B parameters) is crucial to confirm the generalizability and practical impact of these findings in real-world applications. Finally, a deeper theoretical exploration of the interplay between network architecture, neural tangent kernel properties and reward uncertainty is needed. This could pave the way for more principled and efficient methods for reward modeling and policy optimization within RLHF.
More visual insights#
More on figures

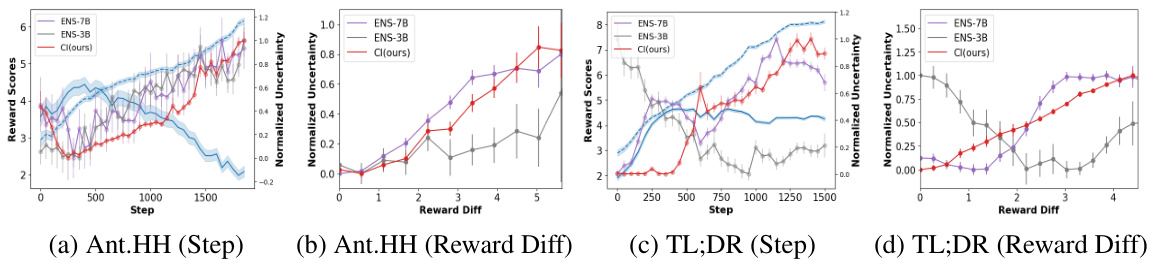
This figure shows the results of experiments comparing the performance of standard Proximal Policy Optimization (PPO) and the proposed Adversarial Policy Optimization (ADVPO) method on two datasets: Anthropic HH and TL;DR. The graphs illustrate the dynamics of gold rewards (true human preference) and proxy rewards (estimated reward from the model) over training steps (left panels) and KL divergence (right panels). ADVPO demonstrates mitigation of the reward overoptimization problem by more closely tracking the gold reward and showing smaller KL divergence.
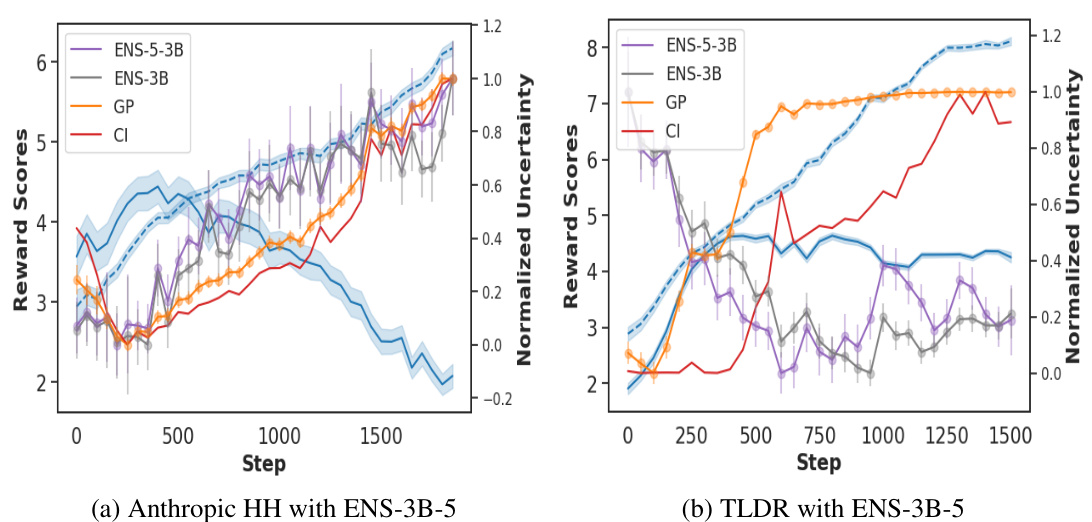
This figure compares different methods for estimating reward uncertainty during policy optimization. The left side shows reward dynamics over optimization steps, comparing gold-standard rewards, proxy rewards, and results from various uncertainty estimation methods. The right side plots the correlation between uncertainty estimates and the differences between gold-standard and proxy rewards. The results illustrate the effectiveness of the lightweight uncertainty estimation method in capturing discrepancies between gold and proxy rewards.
This figure shows the mitigation of reward overoptimization by ADVPO in comparison to PPO. The plots show the gold reward (solid line), proxy reward (dashed line), and KL divergence over optimization steps on two datasets (Anthropic HH and TL;DR). ADVPO effectively prevents the proxy reward from diverging significantly from the gold reward and keeps the KL divergence lower than PPO, indicating better policy optimization and mitigation of reward hacking.
This figure compares different methods for estimating reward uncertainty during reinforcement learning from human feedback (RLHF). Subfigures (a) and (c) show the reward dynamics (gold standard vs. proxy) over training steps for two datasets (Anthropic HH and TL;DR). Subfigures (b) and (d) show the correlation between the estimated uncertainty and the difference between gold and proxy rewards. The goal is to evaluate how well each uncertainty estimation method captures discrepancies between the estimated and true rewards, indicating potential overoptimization.

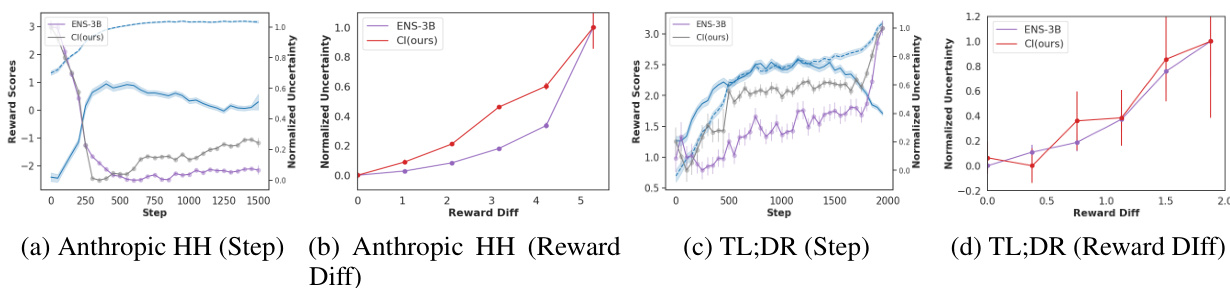
This figure compares four different methods for estimating reward uncertainty during reinforcement learning from human feedback (RLHF). The top row shows the reward dynamics (gold vs proxy) over training steps on two datasets, Anthropic HH (left) and TL;DR (right), along with the uncertainty estimates from each method. The bottom row shows the correlation between the estimated uncertainty and the difference between gold and proxy rewards. It demonstrates that a lightweight uncertainty estimation method (CI) is effective at identifying when proxy rewards diverge from ground truth, indicating over-optimization. The comparison with ensemble-based methods shows that CI achieves a comparable performance with significantly fewer computational requirements.

This figure compares four methods for estimating reward uncertainty during reinforcement learning from human feedback (RLHF): a lightweight method (CI), and three ensemble methods (ENS-3B, ENS-7B). The top row shows the reward dynamics over training steps (left) and the correlation between uncertainty and the difference between gold (human) and proxy rewards (right) for the Anthropic HH dataset. The bottom row shows the same for the TL;DR dataset. The lightweight method (CI) demonstrates a strong correlation between increasing uncertainty and reward over-optimization, performing comparably to the larger ensemble methods.
Full paper#